等宽直方图并行构建方法与流程
本发明属于计算机数据处理技术领域,具体地说是涉及一种等宽直方图并行构建方法。
背景技术:
分布式并行计算编程模型(mapreduce)因其高扩展、高可用、适合通用硬件平台等特点,而用于大规模数据的并行处理,从而成为可扩展数据密集型计算领域事实上的标准。直方图因其在统计分析数据时具有直观、简单的特点而被广泛应用于基于代价的查询优化、聚集近似查询、数据挖掘等领域,因此,绝大多数商用数据库系统在关系上都支持一个或多个直方图。直方图所描述数据分布的精确程度直接影响连接、选择等基本关系代数操作的执行顺序,在建立直方图时要对数据集进行扫描、抽样、排序,然后再将数据划分到桶中。根据直方图桶构建方法的不同,直方图划分为等宽(equal-width)、等深(equal-depth)、v-最优(v-optimal)、压缩(compressed)、最大差异(maxdiff)等类型直方图。在基于分布式并行计算架构mapreduce的效率优化方面,直方图的数据分布为连接、选择等操作奠定了优化基础,因此一些学者开始研究mapreduce架构下直方图的构建方法。现有技术中,研究者提出利用元组抽样方法提出基于mapreduce的小波直方图构建算法,基于mapreduce的v-optimal直方图的近似算法,此外,基于mapreduce的maxdiff直方图的精确与近似构建方法与v-optimal直方图构建方法类似,只是直方图类型不同,yingjie等对mapreduce架构进行了拓展,在map之前和reduce之后分别增加了数据的采样和统计阶段,对基于mapreduce的等宽和等深直方图构建算法进行改进。burakyildiz等人通过对分区数据精确直方图的合并设计了近似等高直方图的构建方法。针对数据流快速、时变、不可预测等特点,研究者提出了基于滑动窗口的实时数据流直方图的构建方法。
上述这些研究在mapreduce架构将直方图构建任务划分成多个小任务并行执行,虽然较传统直方图构建算法在性能上有所提升,但是mapreduce对数据的处理过程包括map和reduce阶段,需要将文件中数据在map阶段转换成key-value对形式,进行相应处理后通过哈希分区发送至对应reducer节点,再进行直方图的并行构建,这导致mapreduce中的shuffle阶段存在较大的数据传输量(如图5)。尽管基于元组、基于块的抽样方法能够降低数据传输量,但将文件中抽样数据从map端传输至redcue端也需要一定网络带宽资源开销。
技术实现要素:
本发明的目的在于克服上述缺点而提供一种能降低网络传输量、直方图构建效率高的等宽直方图并行构建方法。
本发明的一种等宽直方图并行构建方法,该mapreduce将数据处理任务抽象为map任务和reduce任务,其中:使用两轮的所述mapreduce数据处理任务完成等宽直方图的构建,具体步骤如下:
步骤1:第一轮mapreduce的任务
1.1map阶段
分别对读取数据块中数据值的比较得到本地最大值、最小值maxl、minl,本地最值与map分割得到的数据进行比较更新最值信息,与inputsplit中所有数据比较后得到此mapper对应数据块的最值;集群中包含多个mapper;
1.2reduce阶段
多个mapper节点比较后得到的最值集,reduce端通过对多个map节点的最值数据的比较得到整个数据文件的全局最大值、最小值maxg、ming;
步骤2:第二轮mapreduce任务
2.1map阶段
map端读取全局最大值、最小值maxg、ming,并发送至集群中所有map节点;各map节点依据全局最大值、最小值maxg、ming及直方图桶数b构建本地等宽子直方图hl;
2.2reduce阶段
reducer从多个mapper节点复制多个子直方图hl,依次将同一分组内多条记录的数据频率值取出进行累加即得到数据文件在对应直方图桶内的总频率值,最后将桶对应左边界值、右边界值、总频率值直接输出至hdfs得到直方图hg,实现对多个子直方图进行合并。
上述的等宽直方图并行构建方法,其中:所述步骤2中的map端读取全局最大值、最小值maxg、ming,通过mapreduce架构的distributedcache(分布式缓存机制)将全局最大值、最小值maxg、ming广播发送至集群中所有map节点。
上述的等宽直方图并行构建方法,其中:所述步骤2中的构建本地等宽子直方图hl,计算等宽子直方图桶边界值bl、br,初始化桶内频率为0;等宽子直方图的边界值计算采用下列公式计算:
bil=ming+i*(maxg-ming)/b
bir=ming+(i+1)*(maxg-ming)/b
其中i为子直方图hl中第i个桶,bil为子直方图hl中第i个桶的左边界值,bir为子直方图hl中第i个桶的右边界值。
上述的等宽直方图并行构建方法,其中:所述步骤1中的map阶段分别对读取数据块中数据值的比较得到本地最大值、最小值maxl、minl的算法:map端读取数据文件file,每个map对应文件的一个inputsplit,为每个map设定一个本地最大值、最小值(line1),map逐条读取inputsplit中每行信息,并对字符串信息进行分割得到对应数据(line2),数据文件中每行第三列为数据值信息,本地最值与map分割得到的数据进行比较更新最值信息(line3ˉ8),与inputsplit中所有数据比较后得到此mapper对应数据块的最值;map端本地最大值、最小值组合成key-value对形式<key,maxl>、<key,minl>(line9ˉ12),其中key设置为固定值,算法描述中用τ表示固定值,以便于所有map节点的最值信息能够发送到同一reducer节点进行处理;集群中包含多个mapper,设定第i个mapper对应的最大值和最小值用maxli、minli进行表示。
上述的等宽直方图并行构建方法,其中:所述步骤1中第一轮mapreduce任务reduce阶段获取全局最值的算法:reduce端初始化全局最值为0(line1),迭代读取map端发送的最值信息构成的链表数据,与全局最值进行比较以更新全局最值信息(line2ˉ10),将最终得到的全局最大值、最小值maxg、ming组合成<key-value>对形式进行输出(line11ˉ12),其中key用常数τ表示。
上述的等宽直方图并行构建方法,其中:所述步骤2中的第二轮mapreduce依据文件全局最值信息在map阶段分布式构建具有相同边界值的本地等宽子直方图的算法:首先依据第一轮mapreduce得到的全局数据范围[maxg、ming]与直方图包含的桶数初始化b个桶(line1ˉ7),这里的数据范围是hdfs上整个数据文件的数据范围;每个map逐条读取inputsplit内信息,并对字符串信息进行分割得到对应数据(line8),判断数据落入在子直方图hl哪个桶内,对应子直方图桶内频率加1(line9ˉ12);inputsplit中所有记录读取完毕之后,hl本地子直方图构建完毕,依次将hl中b个桶以<key-value>对形式进行封装(13ˉ18),key为等宽直方图中的桶的序列,value为复合值,包含桶的左边界值、右边界值、频率值;包含b个桶的第i个mapper节点构建的本地子直方图hli可用集合表示为:
hli={<1,<bil,bir,f(bi1)>>,<2,<bil,bir,f(bi2)>>…,<b,<bil,bir,f(bib)>>}。
上述的等宽直方图并行构建方法,其中:所述步骤2中的第二轮mapreduce任务实现对多个子直方图进行合并的reduce端功能算法:全局直方图第i个桶bgi的左边界和右边界值与m个mapper产生的子直方图的第i个桶的左边界值、右边界值相等(line2ˉ3),频率值为m个mapper节点的第i个桶内频率值的和(line4ˉ6),将得到的全局直方图的b个桶信息以字符串形式输出至hdfs(line9ˉ14);
其中reduce端对m个map端构建的直方图hl进行合并的公式为:
hg.bi.bl=hl.bi.bl
hg.bi.br=hl.bi.br
hg.bi.f(bi)=h1l.bi.f(bi)+…+hkl.bi.f(bi)
+…+hml.bi.f(bi);
公式中bi为直方图中第i个桶,bl为第i个桶的左边界值,br为第i个桶的右边界值,hkl为第k个map节点构建的子直方图,f(bi)为第i个桶内数据的频率值。
本发明与现有技术的相比,具有明显的有益效果,由以上方案可知,所述的使用两轮的所述mapreduce数据处理任务完成等宽直方图的构建。在map程序执行前,原始数据文件被分割成多个inputsplit,一个maptask读取一个inputsplit作为输入,每个map只拥有对应分片的数据信息。为了使各map节点构建具有相同边界值的等宽直方图,首先应获取文件全局最值。所有map节点通过比较输出inputsplit内最大值、最小值至同一个reduce节点再次进行比较可以获得文件在所有分片范围的全局最值maxg、ming,然后依据全局最值在各map节点构建具有相同边界值和桶个数的等宽直方图。同时,map端至reduce端仅涉及到inputsplit最值的传输和直方图桶信息的传输,与文件内数据记录数量无关,且直方图的构建提前至map阶段,reduce阶段通过对具有相同边界值的等宽直方图桶内频率信息的累加直接实现对map端构建直方图的合并,无需传输文件数据的机制可以大幅降低算法运行过程中网络传输量。总之,本发明具有能降低网络传输量、直方图构建效率高的特点。
以下通过具体实施方式,进一步说明本发明的有益效果。
附图说明
图1为本发明的第一轮mapreduce任务流程图;
图2为本发明的第二轮mapreduce任务流程图;
图3为实施例中的高斯分布数据集直方图;
图4为实施例中的评分数据集直方图;
图5为现有技术的mapreduce框架执行流程。
具体实施方式
以下结合附图及较佳实施例,对依据本发明提出的一种等宽直方图并行构建方法具体实施方式、特征及其功效,详细说明如后。
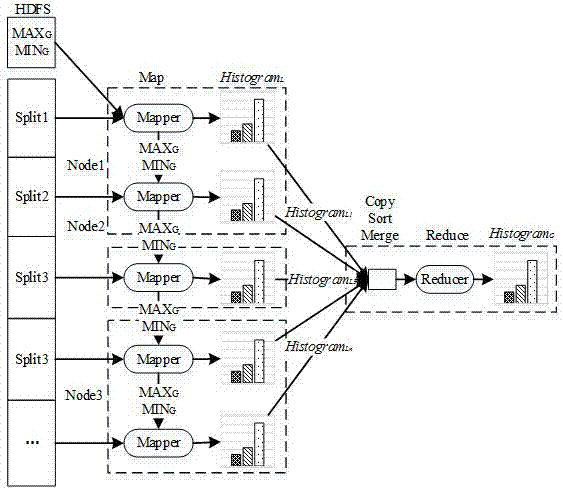
如图1和2所示,本发明的等宽直方图并行构建方法,使用两轮mapreduce任务完成等宽直方图的构建,包括以下步骤:
步骤1:第一轮mapreduce的任务
1.1map阶段
第一轮mapreduce任务的map阶段分别对读取数据块中数据值的比较得到本地最大值、最小值maxl、minl,此阶段功能伪代码描述如算法:map端读取数据文件file,每个map对应文件的一个inputsplit,为每个map设定一个本地最大值、最小值(line1),map逐条读取inputsplit中每行信息,并对字符串信息进行分割得到对应数据(line2),本文数据文件中每行第三列为数据值信息,本地最值与map分割得到的数据进行比较更新最值信息(line3ˉ8),与inputsplit中所有数据比较后得到此mapper对应数据块的最值。map端本地最大值、最小值组合成key-value对形式<key,maxl>、<key,minl>(line9ˉ12),其中key设置为固定值,算法描述中用τ表示固定值,以便于所有map节点的最值信息能够发送到同一reducer节点进行处理。集群中包含多个mapper,设定第i个mapper对应的最大值和最小值用maxli、minli进行表示。
1.2reduce阶段
m个mapper节点比较后得到的最值集合为{<τ,maxl1><τ,minl1>,<τ,maxl2><τ,minl2>,…,<τ,maxlm><τ,minlm>}。reduce端通过对m个map节点的2m个最值数据的比较得到整个数据文件的全局最大值、最小值maxg、ming。第一轮mapreduce任务reduce阶段获取全局最值的伪代码实现可用下列算法进行描述:reduce端初始化全局最值为0(line1),迭代读取map端发送的最值信息构成的链表数据,与全局最值进行比较以更新全局最值信息(line2ˉ10),将最终得到的全局最大值、最小值maxg、ming组合成<key-value>对形式进行输出(line11ˉ12),其中key用常数τ表示。
将上述map与reduce阶段合并,得如图1所示的第一轮mapreduce任务流程。
步骤2:第二轮mapreduce任务
2.1map阶段
map端读取全局最大值、最小值maxg、ming,通过mapreduce架构的distributedcache(分布式缓存机制)将全局最大值、最小值maxg、ming广播发送至集群中所有map节点。
各map节点依据全局最大值、最小值maxg、ming及直方图桶数b构建本地等宽直方图hl,计算等宽直方图桶边界值bl、br,初始化桶内频率为0。等宽直方图的边界值计算比较简单,计算公式如公式(1)所示,其中i为直方图hl中第i个桶,bil为直方图hl中第i个桶的左边界值,bir为直方图hl中第i个桶的右边界值。
第二轮mapreduce依据文件全局最值信息在map阶段分布式构建具有相同边界值的子直方图,map阶段功能实现的伪代码描述算法:首先依据第一轮mapreduce得到的全局数据范围[maxg、ming]与直方图包含的桶数初始化b个桶(line1ˉ7),注意这里的数据范围不是map所读取数据块的数据范围,而是hdfs上整个数据文件的数据范围。每个map逐条读取inputsplit内信息,并对字符串信息进行分割得到对应数据(line8),判断数据落入在直方图hl哪个桶内,对应直方图桶内频率加1(line9ˉ12)。inputsplit中所有记录读取完毕之后,hl本地直方图构建完毕,依次将hl中b个桶以<key-value>对形式进行封装(13ˉ18),key为等宽直方图中的桶的序列,value为复合值,包含桶的左边界值、右边界值、频率值。包含b个桶的第i个mapper节点构建的本地直方图hli可用集合表示为:hli={<1,<bil,bir,f(bi1)>>,<2,<bil,bir,f(bi2)>>…,<b,<bil,bir,f(bib)>>}。
2.2reduce阶段
reducer从m个mapper节点复制m个子直方图hl可用集合表示为:d={{<1,<b1l,b1r,f(b11)>>,<2,<b1l,b1r,f(b12)>>…,<b,<b1l,b1r,f(b1b)>>},{<1,<b2l,b2r,f(b21)>>,<2,<b2l,b2r,f(b22)>>…,<b,<b2l,b2r,f(b2b)>>},…,{<1,<bml,bmr,f(bm1)>>,<2,<bml,bmr,f(bm2)>>…,<b,<bml,bmr,f(bmb)>>}}。依据<key-value>对中的key值对记录进行sort(排序)、group(分组)操作,key值相同的<key-value>对被分到同一分组,则集合d中数据被分为b个分组,每个分组中valuelist包含m条记录,其中第i个分组可表示为:
di=<i,{<b1l,b1r,f(b1i)>,<b2l,b2r,f(b2i)>,…,<1,<bml,bmr,f(bmi)>}>。依次将同一分组内m条记录的数据频率值从value中取出进行累加即得到数据文件在对应直方图桶内的总频率值,最后将桶对应左边界值、右边界值、总频率值直接输出至hdfs得到直方图hg。第二轮mapreduce任务实现对多个子直方图进行合并的reduce端功能伪代码算法:全局直方图第i个桶bgi的左边界和右边界值与m个mapper产生的子直方图的第i个桶的左边界值、右边界值相等(line2ˉ3),频率值为m个mapper节点的第i个桶内频率值的和(line4ˉ6),将得到的全局直方图的b个桶信息以字符串形式输出至hdfs(line9ˉ14)。
其中reduce端对m个map端构建的直方图hl进行合并的公式(2)为:
公式中bi为直方图中第i个桶,bl为第i个桶的左边界值,br为第i个桶的右边界值,hkl为第k个map节点构建的子直方图,f(bi)为第i个桶内数据的频率值。
将上述的map与reduce阶段合并,第二轮mapreduce任务的数据流转示意图如图2所示。
有益效果分析如下:
1等宽直方图网络传输量分析
基于mapreduce的精确等宽直方图构建过程使用两轮mapreduce任务实现,其中第一轮mapreduce任务只涉及map读取inputsplit的最大值、最小值的传输。假设map端输出一个<key-value>对的大小占a个字节,每个map传输<key,maxl>,<key,minl>至reduce端的大小为2a,包括m个map节点的第一轮mapreduce任务网络传输量大小为2am。
第二轮mapreduce任务中每个map传输本地构建直方图hl,包含b个桶的第i个直方图hli用集合表示为:
hli={<1,<bil,bir,f(bi1)>>,<2,<bil,bir,f(bi2)>>…,<b,<bil,bir,f(bib)>>}
其中value为复合值,设添加了桶信息的<key,<bil,bir,f(bi)>>对较原始<key-value>对增加了p个字节大小。则包含b个桶的直方图hl所占字节大小为b*(a+p)。包括m个map节点的第二轮mapreduce任务的网络传输量大小为mb*(a+p)。
第一轮mapreduce任务结束后得到的全局最大值、最小值在第二轮mapreduce任务开始时经distributedcache广播传输至集群中另外m-1个map节点的网络传输量为2a*(m-1)。
依据以上分析,等宽直方图的分布式并行构造方法map-reduce过程的数据传输量q为:
q=2am+mb*(a+p)+2a*(m-1)(3)
由网络传输量计算公式可以看出,在数据类型已定的条件下,<key-value>对大小a与增加了桶信息的<key,<bl,br,f(b)>>对大小p为固定值,网络传输量的大小主要受集群中map个数m和构建直方图桶数b影响,与文件数据量大小无关。
本发明提出方法与mapreduce环境下直方图构建方法相比,将直方图的构建提前至map阶段,map至reduce之间不需要传输具体数据,只传输少量直方图桶信息,可大幅降低直方图构建过程中网络传输量。假设待处理数据文件大小用filesize表示,hdfs文件系统的分片大小用splitsize表示,map读取inputsplit数据分成n个分区,近似直方图构造方法中数据的抽样概率为p,现有方法中等宽直方图并行构建方法与本发明方法在mapreduce架构运行的相关参数与网络传输量的对比如表1所示。从表中可知:现有方法中基于mapreduce的精确与近似等宽直方图的构建都需要多个reduce节点,相比本发明方法的两轮任务都只需要一个reduce处理节点。hadoop集群中map节点和reduce节点可以在同一节点上,基于数据的本地性感知locality=reducepartitiondata/reducedata,reduce分配的分区数据中来自本地节点数据量的比例,当所有map读取inputsplit数据形成的<key-value>对经哈希分区后都刚好发送至mapper所在节点的reducer处理时,不需要将数据传输至集群中其他节点,因此网络传输量为0,本发明方法在同一个节点上运行多个map和一个reduce的时候,网络传输量达到最优0,然而这在实际运行过程中几乎是不可能发生的。现有方法中的hedc++算法构建精确的等宽直方图需将数据文件中所有的数据从map端传输至reduce端,尽管基于元组、块抽样的近似直方图构建能够有效降低处理数据量,但抽样后传输数据量依赖于文件数据量t和抽样概率p,本文提出的算法与文件内数据量t无关,在网络传输量最差和平均情况下都远远低于hedc++算法。
表1现有方法与本发明方法在mapreduce架构运行的相关参数与网络传输量的对比情况表
值得指出的是:本发明方法两轮mapreduce任务都只使用一个reducer进行处理,因为不需要传输文件具体数据,单个reducer足以处理最值信息与直方图信息。实际运行过程中文件数据分布经常会存在数据倾斜问题,这会导致集群中部分reducer的负载失衡,影响整个算法的运行效率。本发明方法由于不传输文件中数据,可以避免此问题的产生。由map端至reduce端数据量公式可知,本发明方法网络传输量与文件中数据量大小无关,在大数据环境下,文件中数据记录数上百万、千万已是常态,与数据量t相比,计算集群中节点数m、直方图内桶个数b的几乎可以忽略不计。
2性能测试实验与分析
2.1实验环境及数据
1)实验平台
实验环境采用包含3个虚拟机节点的hadoop计算集群,集群中包含一个master节点和2个slave节点,每个计算节点配置单核cpu、2g内存、40g硬盘,hadoop2.6.0版本运行于64位centos7系统。算法实现采用java语言编写,通过myeclipse连接hadoop调试mapredcue程序。
2)测试数据集
分别是一组人工合成的符合gauss分布的数据集和一组真实数据集。符合高斯分布数据集包含1000000条数据,其最大值4.6419,最小值为-5.0530,真实数据是美国minnesota大学计算机科学与工程学院的grouplens项目组搜集的用于推荐系统的24,000,000万条评分数据集[21]。
2.2实验设置
为了验证算法所构建直方图在数据分布评估中预测精度和本发明方法与相似算法相比性能的提升,设计了两组实验:
1)数据分布评估精度与直方图桶数关系。针对100万条人工合成数据集,使用本发明方法分别建立包含不同桶个数的直方图。限于篇幅和评分取值范围,对于2400万条评分数据集,只建立包含5个桶的直方图,每个桶内为1类评分所包含评分的次数。
2)与相似算法性能比较。比较本发明方法与现有方法中提出的hedc++方法运行过程中的关键参数,对比相同条件下两种算法构建不同桶个数的等宽直方图使用时间。
2.3实验结果与分析
1)人工合成数据直方图
实验将数据集上传至hdfs文件系统,使用本发明方法并行构建包含10个桶、20个桶和50个桶的等宽直方图如图3所示。
图3中同一数据集构造的3种等宽直方图可以看出,直方图桶数越多,数据分布的描述就越精细,依据直方图中桶的左右边界信息和频率值可以估计数据在更精确范围内频率分布情况,图3(a)中一个桶在3(b)中用两个桶进行表示,图3(b)能够评估数据在更精确范围的数据频率值。但直方图桶的增加必然导致构建代价的增加,如图3(c)数据分布评估范围比图3(a)精确了10倍,数据集大小确定的条件下桶数的增加对数据评估优化的提高是有限的,实际应用中需根据数据集大小、数据特征、应用请求精度等实际情况确定直方图应包含的桶数。
2)真实数据直方图
实验使用的真实数据集为包含260,000个用户对40,000部电影的24,000,000条评分数据,评分范围为0-5的浮点数,该评分数据集大小为632.69m,最后一次更新时间为2016年10月。经本发明方法对评分数据构建等宽直方图结果如图4所示。
由图4直方图结果可以明显看出,24404096条评分数据中评分在(3,4]之间的数据最多,达到38.77%,评分为(2,3]之间和(4,5]分的数据在25%左右,评分在(0,1]和(1,2]之间的数据最少。直方图的数据分布对推荐系统缺失值的评分预测、用户行为分析等提供了重要依据。
总之,本发明方法通过对直方图特点的分析,将直方图的构建任务提前至map阶段,reduce阶段对map阶段并行构建子直方图进行合并规约构建全局直方图。算法运行过程中数据传输量与数据文件内数据量无关,大幅减少了直方图构建过程中网络传输量。实验结果表明,与已有基于mapreduce架构的直方图构建方法相比,本发明方法运行过程中mapreduce架构的网络传输量与磁盘i/o等参数指标都得到了优化。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,任何未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!