一种深度神经网络的计算执行方法和系统与流程
本发明属于神经网络技术领域,特别是涉及一种深度神经网络的计算执行方法和系统。
背景技术:
近年来,依托于深度学习技术的进步,越来越多的图像处理难题,能通过深度学习很好的解决,例如:图像识别、分类和描述,精确到像素的图像内容分割(俗称抠图),图像的风格转移等等。但深度神经网络模型在执行时的计算量与内存开销非常巨大,通常只能运行于配备了高性能gpu的服务器之上。为了能让深度学习技术更广泛的应用和落地,让其能在计算资源有限的设备上使用,包括低端计算机,智能手机、智能手表等移动设备。
要达到上述目的,通常要结合两种方法实现,一是精简深度神经网络模型,二是提高深度神经网络模型的执行效率。第一个方向已经有非常多的研究者提出了很多行之有效的解决办法,而第二个方向上,由于各种具体应用场景的复杂性,开发难度等原因,并没有一个高效而通用的解决方案。
技术实现要素:
为了解决上述问题,本发明提出了一种深度神经网络的计算执行方法和系统,提高对深度神经网络模型的执行效率,能极大限度和有效的利用包括gpu与cpu等计算资源。
为达到上述目的,本发明采用的技术方案是:
一种深度神经网络的计算执行方法,包括步骤:
s100构建深度神经网络;
s200初始化深度神经网络;
s300通过计算后端模块执行提交的神经层算法,逐一执行深度神经网络中各神经层模块;
s400通过运行计算后端模块,获取深度神经网络的运算输出结果。
进一步的是,所述构建深度神经网络,包括步骤:
s101通过神经层模块定义出深度神经网络中的所有隐藏层;
s102根据所要实现的内存管理对象,定义各神经层模块所的输入及输出。
进一步的是,所述初始化深度神经网络,包括步骤:
s201把预先训练好的深度神经网络,加载到深度神经网络的模型对象中;
s202初始化计算后端模块;
s203加载算法库:将预先编写的算法库分别加载到计算后端模块中;
s204逐一初始化深度神经网络中所有的神经层:选取所需的计算后端模块初始化神经层;
s205逐一初始化深度神经网络中的缓冲区。
进一步的是,所述神经层模块的运行,包括步骤:
s301参数设置:设置神经层模块的必需参数,加载计算后端模块执行提交的神经层算法,神经层算法所产生的中间结果分配到神经层模块中的中间结果缓冲区;
s302提交:指定神经层模块的输入位置和输出位置,提交到计算后端模块;计算后端模块在适时执行算法,计算输出结果。
进一步的是,所述计算后端模块的运行,包括步骤:
s401初始化:初始化当前系统平台中的所有可用计算资源信息,根据计算资源信息初始化所有运行于该平台的计算后端实现;
s402计算设备选择:向神经层模块提供当前平台上的计算资源信息,并执行相应算法;
s403计算队列创建:在指定的计算设备上创建执行队列;
s404内存分配:在指定的计算设备上创建缓冲区,以及在不同的设备间同步缓冲区内容;
s405算法提取:向神经层模块提供指定设备上的算法实现。
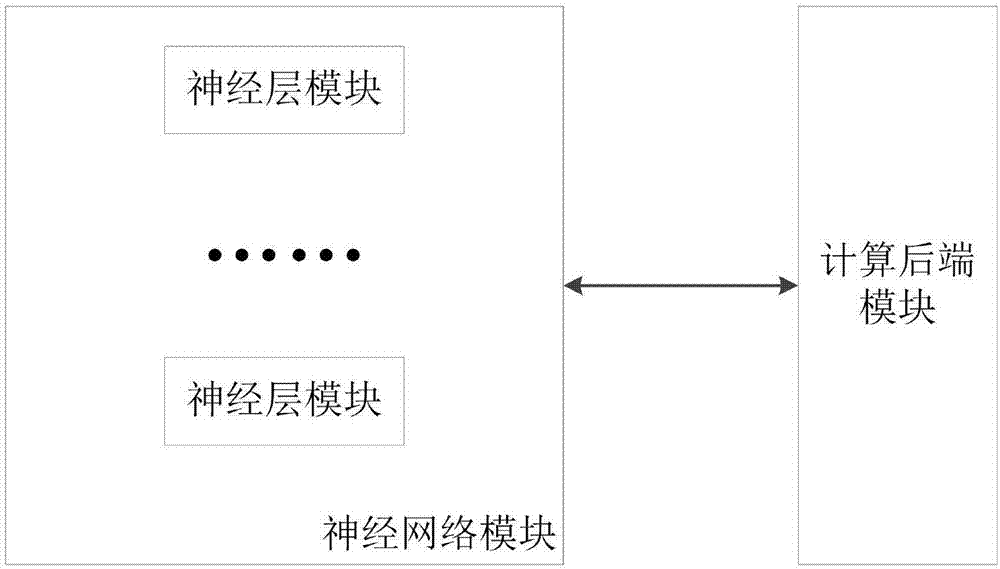
另一方面,本发明还提供了一种深度神经网络的计算执行系统,包括神经网络模块、神经层模块和计算后端模块;
所述神经网络模块,包括各种类型的神经层模块,用于描述和执行深度神经网络;
所述神经层模块,对应深度神经网络中的隐藏层概念,按不同的功能与实现算法,分为多种不同类型的神经层模块;由计算后端模块中的算法实现,为计算后端模块提供参数,供计算后端模块生成中间结果;
所述计算后端模块,包括后端上下文、计算设备描述、执行队列、后端内存管理器和后端算法管理器,用于执行神经层算法并输出结果。
采用本技术方案的有益效果:
1.通过计算后端模块的设置,提供统一而简洁的计算资源管理功能,让神经层的具体实现简洁且统一;
2.能够在不同的平台上使用不同的计算后端,达到优秀的跨平台(跨操作系统,跨gpu/cpu,兼容各种通用计算接口)能力;
3.在同一个神经网络中,不同的神经层可以工作在不同的计算后端中,达到计算资源的最大化利用,即cpu与gpu的混合计算;
4.提供高效的任务执行管理系统,神经层提交到计算后端的执行队列中的各个任务,可以得到最适当规模的并发执行;
5.灵活的神经层模块实现,可以让一种神经层算法有多种实现,达到高效的计算资源利用;例如卷积层,可以按卷积公式来实现,也可以基于im2col+sgemm来实现,或基于快速傅里叶变换实现等;系统可根据当前卷积层参数及计算资源情况,选择最优的算法实现;
6.在使用时,将编写的算法再编译和转换成具体的平台实现,不必为每个计算平台或计算接口分别开发,极大节省开发和维护成本。
附图说明
图1为本发明的一种深度神经网络的计算执行方法的流程示意图;
图2为本发明的一种深度神经网络的计算执行系统的结构示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步阐述。
在本实施例中,参见图1所示,本发明提出了一种深度神经网络的计算执行方法,包括步骤:
s100构建深度神经网络结构;
s200初始化深度神经网络;
s300通过计算后端模块执行提交的神经层算法,逐一执行深度神经网络中各神经层模块;
s400通过运行计算后端模块,获取深度神经网络的运算输出结果。
其中,所述构建深度神经网络结构,包括步骤:
s101通过神经层模块定义出深度神经网络中的所有隐藏层。
定义网络中的卷积层conv1_1_,使用本系统中提供的基于快速傅里叶变换的卷积实现;
定义网络中的卷积层conv2_1_,使用本系统中提供的基于im2col+sgemm的卷积实现;
定义网络中的池化层average_pool1_;
其它的若干层网络;
定义网络中的featuremap相加操作层score_pool3_add_;
其它的若干层网络;
定义网络中的反卷积层deconv8_1_,使用本系统中提供的基于原始公式的反卷积实现;
定义网络中的seg_softmax_层,使用本系统中提供的为分割网络定制的softmax实现。
s102根据所要实现的内存管理对象,定义各神经层模块所的输入及输出。
定义卷积层conv1_1_的输入,使用本系统提供的compute_image来管理;
定义卷积层conv1_1_的输出,使用本系统提供的compute_buffer来管理;
定义卷积层conv2_1_的输出,使用本系统提供的compute_buffer来管理;
其它的若干层的输出;
定义最后一层seg_softmax_的输出,也就是整个网络的最终输出。
其中,初始化神经网络模块,包括步骤:
s201把训练好的深度神经网络,加载到模型对象中;
s202初始化计算后端模块;
计算后端初始化时,主要包含以下步骤和逻辑:
s2021根据当前的操作系统及版本判断需要初始化哪些计算后端的实现:
(1)初始化cpu实现的计算后端;
(2)若系统为macos或ios,则尝试初始化metal实现的计算后端;
(3)若系统为linux/windows,则尝试初始化cuda实现的计算后端;
(4)若系统为android,则尝试初始化renderscript或opengles3.1或vulkan实现的计算后端;
(5)最终所有可用的计算后端实现均被保存在backends_impl_中,以备后续调用。
由于后端实现过多,此处仅以cpu后端和metal为代码的gpu后端为例,结合代码分别阐释计算后端初始化时的工作和逻辑:
a.cpu计算后端的初始化步骤:
获取cpu名称,方便调试;获取cpu频率,决定计算任务粒度的划分;获取cpu各级缓存大小,决定各种算法实现时一个批次处理的数据量;如卷积运算时的通道数量,尺寸合适时,利用cpu缓存可加快运算速度;获取系统内存大小;将获取到的信息保存于计算设备描述中。
b.metal为例的gpu计算后端的初始化步骤:
获取metal设备对象;获取gpu名称,方便调试;获取gpu频率,在某些后端实现中,部分信息无法获取,直接使用优选值;获取gpu缓存大小,此处按最大缓存使用;获取系统内存大小;将获取到的信息保存于计算设备描述中。
s203加载算法库:将预先编写的算法库,分别加载到计算后端模块中。
s2031列出算法库中所有的算法实现的相关信息,即各种神经层实现时所必需的函数,相关信息包括了算法名,算法参数个数、类型、绑定索引等信息;在算法执行时,计算后端即可根据这些信息,找到对应的函数,并将传入的参数对应到适当位置,然后进行计算;
例如:按公式实现的通用卷积运算;
输入参数,类型为image2d,绑定到image索引0;
输出参数,类型为buffer,绑定到buffer索引0;
卷积kernel参数,类型为buffer,绑定到buffer索引1;
卷积bias参数,类型为buffer,绑定到buffer索引2;
其它卷积参数,包含通道数量,kernelsize,stride等等必要信息的结构体,类型为buffer,绑定到buffer索引3;
获取算法执行时的grid位置信息。
softmax算法:
输入参数,类型为buffer,绑定到buffer索引0;
输出参数,类型为buffer,绑定到buffer索引1;
其它必要的参数,如输入数据的shape信息等,类型为buffer,绑定到buffer索引2;
获取算法执行时的grid位置信息。
s2032算法的预处理、编译和加载:虽然计算后端多样,每种计算后端在算法加载时也稍有差异,但总体可划分为预编译和运行时编译两种情况,同样以cpu后端和metal后端为例来阐释这两种情况:
(1)cpu计算后端的算法库加载逻辑(使用预编译的形式加载):
a.在系统编译时,将自定义的通用计算语言编写的代码,转换为通用的c++代码;
b.在系统编译时,若目标平台支持动态库,则将转换出的c++代码编译为动态库,则运行时的lib_source为动态库路径;
c.在系统编译时,若目标平台不支持动态库,则将转换出的c++代码编译直接编译到系统中,则运行时的lib_source为函数指针列表;
d.在系统运行时,根据b和c两种情况,分别找到函数的实现,并生成algorithm_lib,供神经层后续提取使用;
(2)metal计算后端的算法库加载逻辑(使用运行时编译的形式加载):
a.在系统运行时,将自定义的通用计算语言编写的代码,转换为metalshader代码;
b.在系统运行时,将转换得到的metalshader代码,作为lib_source传入;
c.在计算设备上编译metalshader代码;
d.从最终编译出的库中获取各个算法的实现,并生成algorithm_lib,供神经层后续提取使用;
e.后端中是否还有其它计算设备(比如macos上的metal可以分别工作在intel集成显卡与nvidia独立显卡上),如果没有则完成加载;
f.如果有其它计算设备,重复c到e,直到算法库加载到该计算后端中的所有计算设备上。
(3)实现:
a.cpu计算后端中代码的转换为常用的编译器技术,加载动态库与函数指针的操作是通用技术,此处不再赘述;
b.metal计算后端中代码转换同样是常用的编译器技术,编译shader原码为库可直接使用metaldevice提供的newlibrarywithsource等接口。
s204逐一初始化深度神经网络中所有的神经层:选取所需的计算后端模块初始化神经层;
由于神经层的种类和数量较多,此处选用基于傅里叶变换实现的卷积层来阐释神经层的实现,因为这是本系统中最为复杂的神经层,且包含了参数计算,内部子算法选择,有中间结果生成等所有情况,其它神经层在创建和使用上的步骤可视为其子集。
具体包括步骤:
(1)根据padding的类型、输入数据宽高、卷积核宽高计算输入数据padding后的宽高;
(2)根据padding后的输入宽高,卷积核宽高,stride信息,计算输出数据的宽高;
(3)校验所有卷积参数是否合法,包含batchsize、输入数据宽高、卷积核等不能为0,stride不能大于1等校验条件;
(4)选择fft的分块大小与算法,本系统中实现了16x16与8x8两种分块尺寸的分块2dfft,根据卷积核宽高与运算量选择合适的实现;
(5)根据fft分块大小,卷积核宽高,计算输出数据的分片尺寸;
(6)从计算后端中分配中间结果缓冲区,用于存放傅里叶变换后的输入数据、傅里叶变换后的卷积核数据、变换后输入与变换后卷积核相乘的数据;
(7)从计算后端中加载算法实现,包括对卷积核数据进行fft的实现,对输入数据进行fft的实现,对变换后数据进行复数乘法的实现,对相乘结果进行ifft的实现;
(8)构造卷积核的fft参数,构造输入数据的fft参数,构造复数乘法参数,构造输出结果的ifft参数;
(9)对卷积核数据执行fft变换,因为卷积核数据在当前层中是不会变化的,所以在初始化时即可进行fft,而不用在每次执行此神经层时都对卷积核进行fft,以节省运算量;
将输出数据的shape(featuremap的width,height,depth等信息)保存为成员变量,备后续使用。至些神经层构造步骤全部完成。
s205逐一初始化深度神经网络中的缓冲区。
其中,所述神经层模块的运行,包括步骤:
s301参数设置:设置神经层模块的必需参数,加载计算后端模块执行提交的神经层算法,神经层算法所产生的中间结果分配到神经层模块中的中间结果缓冲区;
s302提交:指定神经层模块的输入位置和输出位置,提交到计算后端模块;计算后端模块在适时执行算法,计算出输出结果。
其中,所述计算后端模块的运行,包括步骤:
s401初始化:初始化当前系统平台中的所有可用计算资源信息,根据计算资源信息初始化所有运行于该平台的计算后端实现;
s402计算设备选择:向神经层模块提供当前平台上的计算资源信息,并执行算法;
s403计算队列创建:在指定的计算设备上创建执行队列;
s404内存分配:在指定的计算设备上创建缓冲区,以及在不同的设备间同步缓冲区内容;
s405算法提取:向神经层模块提供指定设备上的算法实现。
为配合本发明方法的实现,基于相同的发明构思,如图2所示,本发明还提供了一种深度神经网络的计算执行系统,包括神经网络模块、神经层模块和计算后端模块。
所述神经网络模块,包括各种类型的神经层模块,用于描述和执行深度神经网络;
通常包含初始化,执行和输出三个关键步骤。
初始化:加载训练好的深度神经网络模型文件,初始化包含的神经层,以及神经层的输入与输出缓冲区;
执行:按所设计的执行顺序,逐一执行各神经层模块,直至最后一层神经层执行完毕;
输出:将最后一层神经层的输出结果返回,作为整个神经网络的输出。
所述神经层模块,对应神经网络中的隐藏层概念,按不同的功能与实现算法,分为多种不同类型的神经层模块;由计算后端模块中的算法实现,为计算后端模块提供参数,供计算后端模块生成中间结果。
通常包含参数设置和提交两个步骤:
参数设置:设置神经层的必需参数,加载计算后端中的算法实现,如果算法会产生中间结果则分配中间结果缓冲区;
提交:指定好神经层的输入位置及输出位置,提交到计算后端,计算后端会在适时时执行算法,计算出输出结果。
所述计算后端模块,包括后端上下文、计算设备描述、执行队列、后端内存管理器和后端算法管理器,用于执行神经层算法并输出结果。
执行过程包括步骤:
初始化:初始化步骤中会获取当前平台中的所有可用计算资源的信息,包括cpu核心数,缓存大小,频率,gpu个数和支持的通用计算接口等,然后根据这些信息初始化所有能运行于该平台的计算后端实现;
计算设备选择:向上层提供当前平台上的计算资源信息,方便上层决定使用哪种实现,以及在cpu还是gpu中执行算法;
计算队列创建:在指定的计算设备上创建执行队列;按照执行列队执行算法,提高效率。
后端内存管理器:在指定的计算设备上创建缓冲区,以及在不同的设备间同步缓冲区内容;在缓冲区缓冲计算过程,加快计算速度。
后端算法管理器:向上层提供指定设备上的算法实现。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!