一种发布数据的生成方法、装置和服务器与流程
本发明涉及大数据平台的数据发布,尤其涉及一种发布数据的生成方法、装置和服务器。
背景技术:
近年来,大数据的蓬勃发展孕育了新业态,激发了新活力,创造了新价值,为了加快建成统一运营、统一管控的企业级大数据平台和运营体系,实现大数据变现,以此支撑开拓市场,需要着力集中资源搭建统一的大数据分析平台,然而,大数据的运营存在着安全风险,例如,对于运营商而言,大数据平台中的数据会涉及客户、业务使用、财政收入、资源等企业运营中的各个方面,同时也含有大量客户信息、话单账单等涉及客户隐私的敏感数据,如果这些敏感数据一旦遭到泄露,一方面会对客户的人身安全、经济安全产生巨大的威胁,另一方面也会引起大规模的客户投诉,这样,会导致巨大的经济损失及名誉损失。
大数据平台的数据服务层主要负责对平台中的数据进行统一封装和对外发布,但是容易遭到黑客的攻击,敏感数据泄露的风险更大,为了降低大数据平台中敏感数据泄露的风险,在数据服务层对信息的共享和发布中,强调要最大化平衡敏感数据的保密性和可用性,为了提高敏感数据的保密性和可用性,现有的是对数据服务层的元数据进行数据匿名化处理,采用基于限制发布的技术来保护敏感数据的隐私性,其中,最核心的算法为k匿名(k-anonymity)算法,通过限制发布对大数据进行脱敏处理,k-anonymity算法要求发布数据中存在至少为k个在准标识符上不可区分的记录,使攻击者不能判别出隐私信息所属的具体个体,从而保护了个人隐私。
k-anonymity算法通过参数k指定用户可承受的最大信息泄露风险,k-anonymity算法简单易懂,便于实现,能够在一定程度上保护用户隐私信息,虽然现有的k-anonymity算法有以上的优点,但当攻击者拥有一定的背景知识,用户信息容易遭受背景知识的攻击,k-anonymity算法无法有效保证用户信息的隐私性;当共享的数据为统计数据时,统计数据本身为敏感数据,采用k-anonymity算法并不能保证统计数据的隐私性,采用k-anonymity算法对统计数据进行过度泛化处理,会带来许多不必要的信息损失,降低统计数据的可用性;可见,现有的采用k-anonymity算法确定出的发布数据存在隐私泄露风险较高且可用性较低的技术问题。
技术实现要素:
有鉴于此,本发明实施例期望提供一种发布数据的生成方法、装置和服务器,以解决现有的采用k-anonymity算法确定出的发布数据存在隐私泄露的风险较高的技术问题,降低了发布数据的隐私泄露风险,同时增强了发布数据的可用性。
为达到上述目的,本发明的技术方案是这样实现的:
第一方面,本发明实施例提供一种发布数据的生成方法,包括:按照预设的统计类别对原始数据进行分类统计,用分类统计得到的每个统计类别对应的统计数值形成统计数据;为所述统计数据选定差分隐私算法;根据选定的差分隐私算法的隐私预算,对所述统计数据进行排序,对排序后的统计数据进行合并,对合并后的统计数据进行加噪,生成发布数据。
进一步地,所述根据选定的差分隐私算法的隐私预算,对所述统计数据进行排序,对排序后的统计数据进行合并,对合并后的统计数据进行加噪,生成发布数据,包括:将选定的差分隐私算法的隐私预算进行拆分,得到第一部分差分隐私预算和第二部分差分隐私预算;根据选定的差分隐私算法的隐私预算,对所述统计数据进行排序,得到所述排序后的统计数据;根据所述第一部分差分隐私预算,对所述排序后的统计数据进行合并,得到所述合并后的统计数据;根据所述第二部分差分隐私预算,对所述合并后的统计数据进行加噪,生成所述发布数据。
进一步地,所述根据选定的差分隐私算法的隐私预算,对所述统计数据进行排序,得到所述排序后的统计数据,包括:根据选定的差分隐私算法的隐私预算,确定出所述统计数据中各统计数值的噪声;根据所述各统计数值的噪声,对所述统计数据中各统计数值进行排序,得到所述排序后的统计数据。
进一步地,所述根据所述各统计数值的噪声,对所述统计数据中各统计数值进行排序,得到所述排序后的统计数据,包括:以i=1为初始值;当第i个统计数值与所述第i个统计数值的噪声之和大于第i+1个统计数值与所述第i+1个统计数值的噪声之和时,交换所述第i个统计数值与所述第i+1个统计数值,将i更新为i+1,直至更新后的i等于所述统计数据中统计数值的总数,得到所述排序后的统计数据;其中,i为整数。
进一步地,所述根据所述第一部分差分隐私预算,对所述排序后的统计数据进行合并,得到所述合并后的统计数据,包括:获取所述排序后的统计数据的发布误差阈值和隐私预算阈值;判断所述第一部分隐私预算是否大于等于所述隐私预算阈值;当所述第一部分隐私预算大于等于所述隐私预算阈值时,从所述排序后的统计数据中,选取出相邻统计数值之差最小的两个统计数值,合并所述两个统计数值为一个统计数值,用合并后的一个统计数值和剩余统计数值形成单次合并后的统计数据;确定所述单次合并后的统计数据的发布误差;当所述单次合并后的统计数据的发布误差小于所述发布误差阈值时,将所述发布误差阈值更新为所述单次合并后的统计数据的发布误差,将所述第一部分隐私预算更新为所述第一部分隐私预算减去所述隐私预算阈值,重新判断所述第一部分隐私预算是否大于等于所述隐私预算阈值,直至合并完成;当所述单次合并后的统计数据的发布误差大于等于所述发布误差阈值时,合并完成;用合并完成后的统计数据形成所述合并后的统计数据;其中,所述剩余统计数值为所述排序后的统计数据中除所述两个统计数值以外的其他统计数值。
进一步地,所述根据所述第二部分差分隐私预算,对所述合并后的统计数据进行加噪,生成所述发布数据,包括:根据所述第二部分隐私预算和所述合并后的统计数据中每个统计数值中已经合并的统计数值个数,分别对所述合并后的统计数据中每个统计数值进行加噪,生成所述发布数据。
第二方面,本发明实施例提供一种发布数据的生成装置,包括:形成模块,用于按照预设的统计类别对原始数据进行分类统计,用分类统计得到的每个统计类别对应的统计数值形成统计数据;选定模块,用于为所述统计数据选定差分隐私算法;生成模块,用于根据选定的差分隐私算法的隐私预算,对所述统计数据进行排序,对排序后的统计数据进行合并,对合并后的统计数据进行加噪,生成发布数据。
进一步地,所述生成模块,具体用于:将选定的差分隐私算法的隐私预算进行拆分,得到第一部分差分隐私预算和第二部分差分隐私预算;根据选定的差分隐私算法的隐私预算,对所述统计数据进行排序,得到所述排序后的统计数据;根据所述第一部分差分隐私预算,对所述排序后的统计数据进行合并,得到所述合并后的统计数据;根据所述第二部分差分隐私预算,对所述合并后的统计数据进行加噪,生成所述发布数据。
进一步地,所述生成模块根据选定的差分隐私算法的隐私预算,对所述统计数据进行排序,得到所述排序后的统计数据,包括:根据选定的差分隐私算法的隐私预算,确定出所述统计数据中各统计数值的噪声;根据所述各统计数值的噪声,对所述统计数据中各统计数值进行排序,得到所述排序后的统计数据。
进一步地,所述生成模块根据所述各统计数值的噪声,对所述统计数据中各统计数值进行排序,得到所述排序后的统计数据,包括:以i=1为初始值;当第i个统计数值与所述第i个统计数值的噪声之和大于第i+1个统计数值与所述第i+1个统计数值的噪声之和时,交换所述第i个统计数值与所述第i+1个统计数值,将i更新为i+1,直至更新后的i等于所述统计数据中统计数值的总数,得到所述排序后的统计数据;其中,i为整数。
进一步地,所述生成模块根据所述第一部分差分隐私预算,对所述排序后的统计数据进行合并,得到所述合并后的统计数据,包括:获取所述排序后的统计数据的发布误差阈值和隐私预算阈值;判断所述第一部分隐私预算是否大于等于所述隐私预算阈值;当所述第一部分隐私预算大于等于所述隐私预算阈值时,从所述排序后的统计数据中,选取出相邻统计数值之差最小的两个统计数值,合并所述两个统计数值为一个统计数值,用合并后的一个统计数值和剩余统计数值形成单次合并后的统计数据;确定所述单次合并后的统计数据的发布误差;当所述单次合并后的统计数据的发布误差小于所述发布误差阈值时,将所述发布误差阈值更新为所述单次合并后的统计数据的发布误差,将所述第一部分隐私预算更新为所述第一部分隐私预算减去所述隐私预算阈值,重新判断所述第一部分隐私预算是否大于等于所述隐私预算阈值,直至合并完成;当所述单次合并后的统计数据的发布误差大于等于所述发布误差阈值时,合并完成;用合并完成后的统计数据形成所述合并后的统计数据;其中,所述剩余统计数值为所述排序后的统计数据中除所述两个统计数值以外的其他统计数值。
进一步地,所述生成模块根据所述第二部分差分隐私预算,对所述合并后的统计数据进行加噪,生成所述发布数据,包括:根据所述第二部分隐私预算和所述合并后的统计数据中每个统计数值中已经合并的统计数值个数,分别对所述合并后的统计数据中每个统计数值进行加噪,生成所述发布数据。
第三方面,本发明实施例提供一种服务器,所述服务器至少包括处理器和配置为存储可执行指令的存储介质,其中:处理器配置为执行存储的可执行指令,所述可执行指令包括:按照预设的统计类别对原始数据进行分类统计,用分类统计得到的每个统计类别对应的统计数值形成统计数据;为所述统计数据选定差分隐私算法;根据选定的差分隐私算法的隐私预算,对所述统计数据进行排序,对排序后的统计数据进行合并,对合并后的统计数据进行加噪,生成发布数据。
第四方面,本发明实施例提供一种计算机存储介质,所述计算机存储介质中存储有计算机可执行指令,该计算机可执行指令配置为执行上述一个或多个实施例中提供的发布数据的生成方法。
本发明实施例所提供的一种发布数据的生成方法、装置和服务器,该方法包括:首先,按照预设的统计类别对原始数据进行分类统计,用分类统计得到的每个统计类别对应的统计数值形成统计数据,然后,为统计数据选定差分隐私算法,并根据选定的差分隐私算法的隐私预算,对统计数据进行排序,对排序后的统计数据进行合并,对合并后的统计数据进行加噪,生成发布数据,也就是说,通过本发明实施例中,根据选定的差分隐私算法的隐私预算对统计数据进行排序,可以降低统计数据的隐私敏感度,实现对统计数据的隐私保护,通过对排序后的统计数据进行合并,可以保证统计数据的准确性,从而降低了注入至统计数据的噪声,使得得到的发布数据降低了隐私泄露风险,同时增强了发布数据的可用性。
附图说明
图1为大数据平台的逻辑架构示意图;
图2为本发明实施例中的发布数据的生成方法的一种可选的流程示意图;
图3为拉普拉斯机制的分布示意图;
图4为本发明实施例中的发布数据的生成方法的另一种可选的流程示意图;
图5为本发明实施例中的统计数据的一种可选的直方图结构示意图;
图6为本发明实施例中的基于差分隐私算法的大数据平台数据发布装置的结构示意图;
图7为本发明实施例中的发布数据的生成装置的结构示意图;
图8为本发明实施例中的服务器的结构示意图;
图9为本发明实施例中的计算机存储介质的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
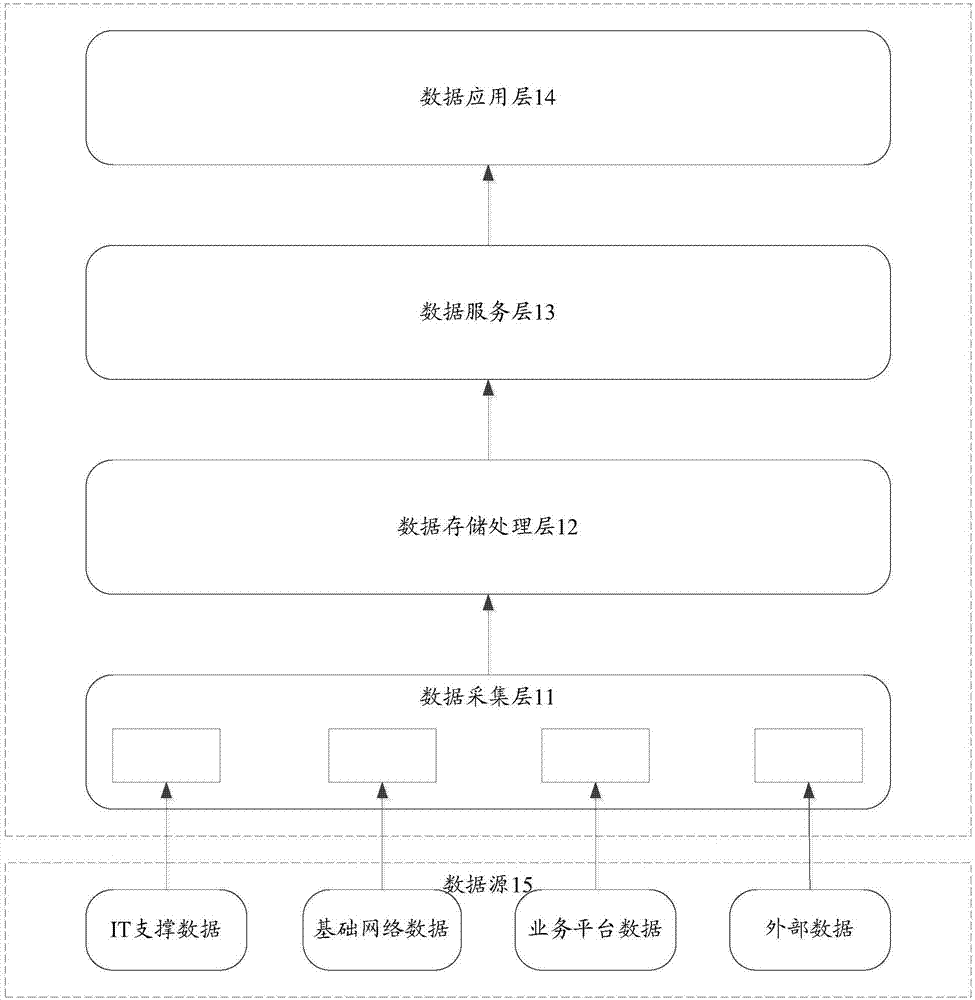
本发明实施例提供一种发布数据的生成方法,该方法可以应用于大数据平台中的数据服务层中,图1为大数据平台的逻辑架构示意图,如图1所示,大数据平台的逻辑架构可以包括:数据采集层11、数据存储处理层12、数据服务层13和数据应用层14。
其中,数据服务层13主要负责提供大数据平台服务的数据封装和统一接口,通过数据封装,建立统一的标准化输出接口,开放数据服务,促进信息共享和应用重用;数据采集层11主要采集数据源15的数据,采集到的数据可以包括:it支撑数据、基础网络数据、业务平台数据和外部数据。其中,对数据服务层13发布的敏感信息数据项,一般采用k-anonymity算法做数据匿名化处理。
图2为本发明实施例中的发布数据的生成方法的一种可选的流程示意图,如图2所示,该发布数据的生成方法可以包括:
s201:按照预设的统计类别对原始数据进行分类统计,用分类统计得到的每个统计类别对应的统计数值形成统计数据;
在大数据平台中的服务器中存储有很多原始数据,例如,电信运营商的大数据平台中存储的原始数据可以包括:用户的个人信息、用户的话费信息和用户的使用信息等等,医院的大数据平台中存储的原始数据可以包括:病人的个人信息、病人的家庭信息和病人的患病类别等等,为了在共享这些大数据时防止一些敏感数据泄露,需要对原始数据进行统计。
具体来说,当需要共享医院的大数据平台中的数据时,需要对病人的患病类别做进一步的处理,以防止泄露病人的患病类别,首先,按照预设的疾病种类对病人的患病类别进行分类统计,例如,原始数据中,病人的总数为124个,预设的患病类别包括骨癌、膀胱癌、肺癌、食道癌、血癌、肝癌和乳腺癌,按照上述预设的患病类别对原始数据进行分类统计,得到骨癌的人数为2,膀胱癌的人数为12,肺癌的人数为15,食道癌的人数为14,血癌的人数为16,肝癌的人数为30,乳腺癌的人数为35;所以形成的统计数据为{2,12,15,14,16,30,35}。
至此,便可以得到统计数据。
s202:为统计数据选定差分隐私算法;
为了对统计数据进行处理以得到发布数据,需要为统计数据选定差分隐私算法,之所以采用差分隐私算法,是因为通过差分隐私算法可以来打乱个体用户数据,目的是让任何人都不能凭此追踪到具体的某一名用户,但又可以在获得发布数据后成批分析数据以获得大规模的整体趋势,可见,差分隐私算法的目标在保护用户身份和数据详情的同时,仍能提炼出一些基本信息用于机器学习,这正适合大数据平台数据服务层的应用场景。
上述为统计数据选定的差分隐私算法,下面以差分隐私算法保护下基于直方图结构的数据发布为例进行说明。
目前,基于直方图结构的数据发布方法是目前最常用的一种数据发布方法,由于它形象地显示了数据分布形式,其统计结果可以为实现计数范围查询提供理论依据;直方图主要是根据一个或多个属性拥有不同的属性值把数据表拆分成多个不相交的子集,类似于形成若干个独立的单元桶,并且,分别用统计数值来标识每个子集(或单元桶)的划分意义,其中,每个单元桶的宽度代表了一个查询范围,从而实现了范围计数查询。
例如,包含n个单元桶的直方图实际上就是n个独立的范围计数查询,假设其中一个单元桶的频数值为x,从数据集中删除一条记录后该单元桶的频数值为x′,由于||x-x′||1=1,则直方图每个单元桶的计数查询敏感度δf=1,因此通过向直方图代表每个单元桶的统计频数中注入少量服从拉普拉斯分布的独立噪音就可以满足差分隐私的要求。
直方图采用一系列高度不等的单元桶来表示相应查询范围内的统计信息情况。令a表示数据表d中的某一个属性,a∈a为属性a中的任一属性值,count(a)代表数据表中属性值为a的记录个数,则直方图为一系列统计属性值个数的计数序列,每个计数值代表直方图相应单元桶的频数,即h={h1,h2,…,hn},其中hi=count(ai),
任何一个数据表都可以根据某个属性映射成相应的直方图,假设h、h′分别为仅相差一条记录的相邻数据表d、d′映射成的直方图,那么称h、h′为相邻直方图,则h、h′的结构除了一个单元桶的计数频数相差1,其余单元桶的频数都相同。下面给出差分隐私的数学定义:
差分隐私:给定相邻直方图h和h′,二者仅在一个单元桶的计数频数之间相差1,给定一个隐私算法a,range(a)为a的取值范围,若算法a在直方图h和h′上任意输出结果o(o∈range(a))满足下列不等式:
pr[a(h)=o]≤eε×pr[a(h')=o](1)
则算法a满足ε-差分隐私。
其中,pr为概率运算符,参数ε(ε>0)表示隐私预算,ε越小,隐私保护的程度越高;实现差分隐私有两种经典的生成噪声机制:拉普拉斯(laplace)机制和指数机制,这两种机制基于查询函数的敏感性,对于相邻直方图h和h′以及查询函数f:h→rd,其全局敏感性为δf=max∥f(h)-f(h′)∥1。
拉普laplace定义如下:
laplace机制:给定原始直方图h,设有查询函数f:h→rd,其敏感度为δf,那么随机算法m(h)=f(h)+y提供ε-差分隐私保护,其中y~lap(δf/ε)为随机噪声,服从尺度参数为δf/ε的laplace分布,图3为拉普拉斯机制的分布示意图,如图3所示,分别为b=1,b=2,b=4的laplace分布图。
指数机制定义如下:
指数机制:给定一个随机算法a以及数据集d,用q(d,r)表示一个打分函数,δq为函数q(d,r)的敏感度,其中r为从输出结果集中所选择的输出结果。若算法a满足公式(2),且
a(d,q)={r:|pr[r∈o]∞exp(ε·q(d,r)/2δq)}(2)
则算法a提供ε-差分隐私保护,其中,∞为正比于符号,在这里,如果一个对象的打分越高,则其被选择并输出的概率也就越大。
由于laplace机制仅适用于数值型查询结果,而在许多实际应用中,查询结果为实体对象(例如一种方案或一种选择),因此指数机制被提出。设查询函数的输出域为range,域中的每个值r∈range为一实体对象,在指数机制下,函数q(d,r)→r称为输出值r的可用性函数,用来评估输出值r的优劣程度。
指数机制的另一种定义:设随机算法a输入为数据集d,输出为一实体对象r∈range,q(d,r)为可用性函数,δq为函数q(d,r)的敏感度。若算法a以正比于exp(ε·q(d,r)/2δq)的概率从range中选择并输出r,那么算法a提供ε-差分隐私保护。
举例来说,假如拟举办一场体育比赛,可供选择的项目来自集合{足球,排球,篮球,网球},参与者们为此进行了投票,现要从中确定一个项目,并保证整个决策过程满足ε-差分隐私保护要求。以得票数量为可用性函数,显然δq=1。那么按照指数机制,在给定的隐私保护预算ε下,可以计算出各种项目的输出概率,如下表1所示:
表1
由上述表1可以看出,在ε较大时(如ε=1),可用性最好的选项被输出的概率被放大,当ε较小时,各选项在可用性上的差异则被平抑,其被输出的概率也随着ε的减小而趋于相等。
另外,差分隐私还有两个重要的性质,即序列组合性和并行组合性。
其中,序列组合性:设a1,a2,…,an为n个随机性算法,假设ai满足εi-差分隐私(0<i≤n),那么针对于同一个数据集d,组合算法{a1(d),a2(d),…,an(d)}满足ε-差分隐私,其中
并行组合性:设a1,a2,…,an为n个随机性算法,假设ai满足εi-差分隐私(0<i≤n),那么对于相互没有交集的数据集d1,d2,…,dn,由这些算法构成的组合算法{a1(d1),a2(d2),…,an(dn)}满足ε-差分隐私,其中ε=max(εi)。这两个性质为本发明实施例中为统计数据所选定的差分隐私算法是否提供差分隐私保护奠定了理论基础。
需要说明的是,这里,基于差分隐私算法的直方图结构的发布形式仅仅为举例说明,本发明实施例对差分隐私算法的数据发布形式不限于此。
另外,本发明实施例中,采用均方误差(mse)来衡量数据发布的可用性。给定一个原始直方h={h1,h2,…,hn},以及一范围计数查询q={q1,q2,…,qn},分别查询原始直方图h和发布后的直方图
假设向直方图单元桶的频数中注入的噪音为y,其中,y~lap(δf/ε),则根据计算噪音量y如下:
y=-(δf/ε)sgn(p-0.5)ln(1-2|p-0.5|)(4)
其中,sgn为阶跃函数,p为随机数。且δf=1,公式(4)可以简化如下:
y=-(1/ε)sgn(p-0.5)ln(1-2|p-0.5|)(5)
如果一个重构算法将m个单元桶合并一个新桶,那么敏感性由1变为1/m,即δf=1/m,因此向新桶中注入的单元噪音量如下:
而新桶中总共注入的噪音量仍然为公式(5),那么如果将一个具有n个单元桶的原始直方图重构成k个新桶的直方图,添加的噪音由原来的ny减少到ky(n>k)。
根据以上分析,本发明量化的差分隐私保为护下直方图发布过程中的误差如下所示:
其中
s203:根据选定的差分隐私算法的隐私预算,对统计数据进行排序,对排序后的统计数据进行合并,对合并后的统计数据进行加噪,生成发布数据。
为了得到保证发布数据的隐私性和可用性,s203中采用差分隐私算法,对外发布有价值的统计数据,首先在发布数据之前,对统计数据进行满足差分隐私的排序预处理,以满足各类数据特征的发布要求;然后对排序后的统计数据进行重组,以此降低数据敏感性,从而达到降低注入噪声的目的;最后对数据服务层需要发布的敏感统计数据中注入适量的噪声,对其进行随机化处理。
s203中在对原始数据进行预处理的过程中,每一步都需小心谨慎,如何采用差分隐私算法以防止每一步产生隐私泄露的风险,是数据预处理的关键,为了尽可能地在满足差分隐私的条件下,提高数据的可用性,唯一地做法就是尽可能减小注入的随机噪声,仍然以直方图结构的发布形式举例来说,本发明实施例中对原始直方图的单元桶频数做一个满足差分隐私的排序预处理,然后合并直方图中相邻单元桶的频数,降低全局敏感性,以降低注入的随机噪声。
在一种具体实施过程中,图4为本发明实施例中的发布数据的生成方法的另一种可选的流程示意图,如图4所示,s203可以包括:
s401:将选定的差分隐私算法的隐私预算进行拆分,得到第一部分差分隐私预算和第二部分差分隐私预算;
s402:根据选定的差分隐私算法的隐私预算,对统计数据进行排序,得到排序后的统计数据;
s403:根据第一部分差分隐私预算,对排序后的统计数据进行合并,得到合并后的统计数据;
s404:根据第二部分差分隐私预算,对合并后的统计数据进行加噪,生成发布数据。
具体来说,选定的差分隐私算法的隐私预算用ε来表示,那么,首先对ε进行拆分,得到第一部分差分隐私预算ε1和第二部分差分隐私预算ε2。
其中,ε=ε1+ε2;ε用来对统计数据进行排序,ε1用来对排序后的统计数据进行合并,ε2用来对合并后的统计数据进行加噪,在实际应用中,当ε=0.1时,ε1=0.01,ε2=0.09。
为了降低发布数据的隐私泄露风险,需要对统计数据进行排序,在具体实施过程中,s402可以包括:根据选定的差分隐私算法的隐私预算,确定出统计数据中各统计数值的噪声;根据各统计数值的噪声,对统计数据中各统计数值进行排序,得到排序后的统计数据。
具体来说,按照上述公式(4)计算统计数据中每个统计数值的噪声,得到各统计数值的噪声,然后根据各统计数值的噪声来对各统计数值进行排序;在具体实施过程中,根据各统计数值的噪声,对统计数据中各统计数值进行排序,得到排序后的统计数据,可以包括:
以i=1为初始值;当第i个统计数值与第i个统计数值的噪声之和大于第i+1个统计数值与第i+1个统计数值的噪声之和时,交换第i个统计数值与所述第i+1个统计数值,将i更新为i+1,直至更新后的i等于统计数据中统计数值的总数,得到排序后的统计数据;其中,i为整数。
具体来说,以统计数据为{2,12,15,14,16,30,35}为例来说,当i=1时,h1=2,h2=12,当(h1+y1)>(h2+y2)时,交换h1和h2,则统计数据变为{12,2,15,14,16,30,35},这样,以此类推,得到排序后的统计数据。
为了提高发布数据的可用性,在具体实施过程中,s403可以包括:
获取排序后的统计数据的发布误差阈值和隐私预算阈值;
判断第一部分隐私预算是否大于等于隐私预算阈值;
当第一部分隐私预算大于等于隐私预算阈值时,从排序后的统计数据中,选取出相邻统计数值之差最小的两个统计数值,合并两个统计数值为一个统计数值,用合并后的一个统计数值和剩余统计数值形成单次合并后的统计数据;
确定单次合并后的统计数据的发布误差;
当单次合并后的统计数据的发布误差小于发布误差阈值时,将发布误差阈值更新为单次合并后的统计数据的发布误差,将第一部分隐私预算更新为第一部分隐私预算减去隐私预算阈值,重新判断第一部分隐私预算是否大于等于隐私预算阈值,直至合并完成;
当单次合并后的统计数据的发布误差大于等于发布误差阈值时,合并完成;
用合并完成后的统计数据形成合并后的统计数据;
其中,剩余统计数值为排序后的统计数据中除两个统计数值以外的其他统计数值。
具体来说,获取排序后的统计数据的发布误差阈值ε1′,隐私预算阈值errmin;当ε1≥ε1′时,选取出两个统计数值之差最小的两个统计数值,合并两个统计数值,以排序后的统计数据为{2,12,15,14,16,30,35}的直方图结构为例来说,选取出两个统计数值之差最小的两个统计数值为15和14,按照以下公式来合并:
其中,bi表示第i个新桶,bi表示第i个新桶的频数,|bi|表示第i个新桶内单元桶的个数;可以得到bi=14.5,然后按照公式(7)计算发布误差,发布误差小于发布误差阈值时,将发布误差阈值更新为单次合并后的统计数据的发布误差,将第一部分隐私预算更新为第一部分隐私预算减去隐私预算阈值,重新判断第一部分隐私预算是否大于等于隐私预算阈值,直至合并完成;或者,发布误差大于等于发布误差阈值时,合并完成。
在对统计数数进行排序和合并之后,需要对合并后的统计数据注入噪声,在具体实施过程中,s404可以包括:根据第二部分隐私预算和合并后的统计数据中每个统计数值中已经合并的统计数值个数,分别对合并后的统计数据中每个统计数值进行加噪,生成发布数据。
具体来说,根据第二部分隐私预算和合并后的统计数据中每个统计数值中已经合并的统计数值个数,按照lapace机制计算出合并后的统计数据中各统计数值的噪声:
lap(1/|bi|ε2)(9)
然后,根据上述噪声分别对合并后的统计数据中每个统计数值进行加噪,生成发布数据。
本发明实施例中,从经营分析统计数据的角度出发,结合当前流行的差分隐私保护方法—差分隐私算法,并对差分隐私直方图数据发布算法进行改进:首先,对直方图结构下的统计数据做满足差分隐私的排序预处理,使得统计数据可以在数据发布过程中,实现对各类特征统计数据的隐私保护;其次,合并直方图结构下临近的相似统计数据,以此减少注入的噪音量,在保证对敏感信息隐私保护的前提下,提高统计数据的经营分析可用性;本发明实施例所采用的差分隐私算法有效地保护了发布数据的敏感信息,使得分析人员可以放心挖掘大数据的潜在价值,减小对泄露客户隐私的担忧,对现有数据做经营分析,为市场部门营销人员提供营销导向,满足未来发展的需要。
下面举实例来对本发明实施例中发布数据的生成方法进行说明。
本实例中采用基于差分隐私模型的大数据直方图发布算法(bigdatahistogrampublishedalgorithmbasedondifferentialprivacy,bdhpbdp)算法中的pre_bdhpbdp算法及merge-bins算法,其中,pre_bdhpbdp算法用于对统计数据进行排序,merge-bins算法用于对排序后的统计数据进行合并,pre_bdhpbdp算法及merge-bins算法具体实现方式如下:
算法1:pre_bdhpbdp(h,ε):
在具体实施过程中,输入原始直方图h={h1,h2,…,hn},ε;根据算法1进行处理,得到满足均匀分布的原始直方图h′={h′1,h′2,…,h′n};具体算法1如下步骤所示:
s11、从原始直方图的第一个频数h1开始一直到hn-1,逐个检查,若(hi+lapi(1/ε))-(hi+1+lapi+1(1/ε))>0,则交换hi+1与hi的位置;
s12、重复步骤s11,直到再也不能交换;
s13、返回满足均匀分布的原始直方图h′={h′1,h′2,…,h′n};
s14、否则直接返回原始直方图h={h1,h2,…,hn}。
算法2:merge-bins(h′,ε1)
在具体实施过程中,输入满足均匀分布的原始直方图h′={h′1,h′2,…,h′i,…,h′n},ε1;根据算法2进行处理,得到输出
s21、初始化:
其中
s22、while(ε1≥ε1′)
s23、ε1′=ε1/2;
s24、根据指数机制的定义,算法2以正比于
s25、根据公式(7)计算err;
s26、if(err<errmin)errmin=err;
s27、elsebreak;
s28、k--;ε1=ε1-ε1′;
s29、endwhile;
s210、return
算法3:bdhpbdp(h,ε)
在具体实施过程中,输入原始直方图h={h1,h2,…,hn},ε;根据算法3进行处理,输出满足差分隐私的直方图
s31、ε=ε1+ε2;
s32、调用排序预处理算法pre_bdhpbdp(h,ε);
s33、调用合并桶算法merge-bins(h′,ε1);
s34、分别向合并后的新桶中添加lap(1/|bi|ε2);//其中|bi|表示第i个新桶中含有单元桶的个数。
s35、返回
下面对本发明实施例中的bdhpbdp算法的隐私性进行分析,主要分析bdhpbdp算法中pre_bdhpbdp算法及merge-bins算法的关键步骤是否有泄露隐私的可能。
假如该算法中可能泄漏隐私的步骤均满足差分隐私要求,则本发明实施例提出的bdhpbdp算法满足ε-差分隐私,输出的直方图中新桶的频数不会暴露原始数据集中的个人敏感属性信息。算法2的s24、算法3的s34及算法1的s11均有泄露隐私的可能,为了说明bdhpbdp算法满足ε-差分隐私,分析过程如下:
(1)假设算法2的s24执行合并桶的操作执行了(n-k)次,那么每次分得的隐私预算为
(2)根据差分隐私的定义,算法3的s34中,对于直方图
(3)在算法1的s11中,假设hi与hi+1为原始直方图h的第i个、第i+1个单元桶的桶频数,h′i与h′i+1+1为h′的第i个、第i+1个单元桶的桶频数,那么根据以上分析,将第i个、第i+1个单元桶的桶频数加入参数为ε拉普拉斯噪声后,h与h′输出相同桶的桶频数的概率比值小于或等于eε,则比较h与h′第i个单元桶与第i+1个单元桶注入噪声后的桶频数大小,概率比值小于或等于eε;虽然算法1最后输出了真实的桶频数排序结果,最终并未消耗隐私预算,但是根据以上分析,算法1仍然满足差分隐私要求。
综合以上分析,再根据序列组合性,本发明实施例采用的bdhpbdp算法满足(ε1+ε2)-差分隐私,即ε-差分隐私。
在合并两个统计数值的过程中,以直方图结构为发布形式为例,在合并相邻单元桶的过程中,由于对于相邻直方图,会产生不同的选择结果;例如,对于输入直方图为{2,12,15,15,16,30,35},首次选择的相邻单元桶是15与15,然而对于其相邻直方图为{2,12,15,16,16,30,35},首次选择的相邻单元桶则变为16与16;为了满足差分隐私,该过程采用指数机制来实现,其中,以频数距离作为指数机制的打分函数,频数距离越小,打分越高,则该合并方案被输出的概率越大。并且由于原始数据集中无论增加或删除一条记录,对形成直方图后的频数距离最大影响为1,则该打分函数的全局敏感性为1,即δq=1,ε2为合并相邻单元桶的过程中分得的隐私预算。
例如,输入直方图为h′={2,12,15,14,16,30,35},初始化每一个单元桶作为一个独立的桶,并且此时重构误差为0,假设每一个独立的噪声为1,即y=1,则此时发布的直方图误差err=7,将7作为最小误差errmin,即errmin=7。根据算法2,通过指数机制选择差值最小的相邻单元桶为15和14进行合并,并且计算当前误差err=re+ne=0.5+6=6.5。由于err=6<errmin=7,则将6.5作为最小误差errmin,即errmin=6.5,并且继续执行合并操作;以此类推,当合并单元桶15,14,16后,计算发布误差为err=2+5=7>errmin=6.5,则终止合并操作。输出结果为
图5为本发明实施例中的统计数据的一种可选的直方图结构示意图,如图5所示,输入h={30,15,14,35,12,2,16},输出后h={30,14.5,14.5,35,12,2,16}。
上述发布数据的生成方法可以应用于基于差分隐私模型的大数据平台数据发布装置中,图6为本发明实施例中的基于差分隐私算法的大数据平台数据发布装置的结构示意图,如图6所示,基于差分隐私模型的大数据平台数据发布装置可以包括:隐私数据库、基于差分隐私的发布算法、对外发布数据库等。在发布数据之前,用户查询数据的主要过程如下:首先,数据管理者利用差分隐私随机性发布算法将数据库的统计信息存储在发布数据库中,实现数据发布。其中,基于差分隐私的发布算法主要通过直接加噪或转换的方法实现,即本发明实施例中提出的bdhpbdp算法实现,其次,用户(或潜在的攻击者)向发布数据库提交查询任务q,最后,用户得到发布数据库返回的带噪音的查询结果q′;另外,提交查询任务q与返回的查询结果q′具有相同的统计趋势,该查询结果既满足了数据发布的隐私保护要求,又可以保证其潜在的挖掘价值不被破坏。
本发明实施例所提供的一种发布数据的生成方法,该方法包括:首先,按照预设的统计类别对原始数据进行分类统计,用分类统计得到的每个统计类别对应的统计数值形成统计数据,然后,为统计数据选定差分隐私算法,并根据选定的差分隐私算法的隐私预算,对统计数据进行排序,对排序后的统计数据进行合并,对合并后的统计数据进行加噪,生成发布数据,也就是说,通过本发明实施例中,根据选定的差分隐私算法的隐私预算对统计数据进行排序,可以降低统计数据的隐私敏感度,实现对统计数据的隐私保护,通过对排序后的统计数据进行合并,可以保证统计数据的准确性,从而降低了所需注入至统计数据的噪声,使得得到的发布数据降低了隐私泄露风险,同时增强了发布数据的可用性。
基于同一发明构思,本实施例提供一种发布数据的生成装置,图7为本发明实施例中的发布数据的生成装置的结构示意图,如图7所示,该发布数据的生成装置包括:形成模块71、选定模块72和生成模块73;
其中,形成模块71,用于按照预设的统计类别对原始数据进行分类统计,用分类统计得到的每个统计类别对应的统计数值形成统计数据;选定模块72,用于为统计数据选定差分隐私算法;生成模块73,用于根据选定的差分隐私算法的隐私预算,对统计数据进行排序,对排序后的统计数据进行合并,对合并后的统计数据进行加噪,生成发布数据。
在一种可选的实施例中,上述生成模块73,具体用于:将选定的差分隐私算法的隐私预算进行拆分,得到第一部分差分隐私预算和第二部分差分隐私预算;根据选定的差分隐私算法的隐私预算,对统计数据进行排序,得到排序后的统计数据;根据第一部分差分隐私预算,对排序后的统计数据进行合并,得到合并后的统计数据;根据第二部分差分隐私预算,对合并后的统计数据进行加噪,生成发布数据、
在一种可选的实施例中,生成模块73根据选定的差分隐私算法的隐私预算,对统计数据进行排序,得到排序后的统计数据,包括:根据选定的差分隐私算法的隐私预算,确定出统计数据中各统计数值的噪声;根据各统计数值的噪声,对统计数据中各统计数值进行排序,得到排序后的统计数据。
在一种可选的实施例中,生成模块73根据各统计数值的噪声,对统计数据中各统计数值进行排序,得到排序后的统计数据,包括:以i=1为初始值;当第i个统计数值与第i个统计数值的噪声之和大于第i+1个统计数值与第i+1个统计数值的噪声之和时,交换第i个统计数值与第i+1个统计数值,将i更新为i+1,直至更新后的i等于统计数据中统计数值的总数,得到排序后的统计数据;其中,i为整数。
在一种可选的实施例中,生成模块73根据第一部分差分隐私预算,对排序后的统计数据进行合并,得到合并后的统计数据,包括:获取排序后的统计数据的发布误差阈值和隐私预算阈值;判断第一部分隐私预算是否大于等于隐私预算阈值;当第一部分隐私预算大于等于隐私预算阈值时,从排序后的统计数据中,选取出相邻统计数值之差最小的两个统计数值,合并两个统计数值为一个统计数值,用合并后的一个统计数值和剩余统计数值形成单次合并后的统计数据;确定单次合并后的统计数据的发布误差;当单次合并后的统计数据的发布误差小于发布误差阈值时,将发布误差阈值更新为单次合并后的统计数据的发布误差,将第一部分隐私预算更新为第一部分隐私预算减去隐私预算阈值,重新判断第一部分隐私预算是否大于等于隐私预算阈值,直至合并完成;当单次合并后的统计数据的发布误差大于等于发布误差阈值时,合并完成;用合并完成后的统计数据形成合并后的统计数据;其中,剩余统计数值为排序后的统计数据中除两个统计数值以外的其他统计数值。
在一种可选的实施例中,生成模块73根据第二部分差分隐私预算,对合并后的统计数据进行加噪,生成发布数据,包括:根据第二部分隐私预算和合并后的统计数据中每个统计数值中已经合并的统计数值个数,分别对合并后的统计数据中每个统计数值进行加噪,生成发布数据。
基于同一发明构思,本实施例提供一种服务器,图8为本发明实施例中的服务器的结构示意图,如图8所示,上述服务器80至少包括处理器81和配置为存储可执行指令的存储介质82,其中:
处理器81配置为执行存储的可执行指令,所述可执行指令包括:
按照预设的统计类别对原始数据进行分类统计,用分类统计得到的每个统计类别对应的统计数值形成统计数据;为统计数据选定差分隐私算法;根据选定的差分隐私算法的隐私预算,对统计数据进行排序,对排序后的统计数据进行合并,对合并后的统计数据进行加噪,生成发布数据。
在本发明其他实施例中,处理器81配置为执行存储的可执行指令,所述可执行指令还包括:将选定的差分隐私算法的隐私预算进行拆分,得到第一部分差分隐私预算和第二部分差分隐私预算;根据选定的差分隐私算法的隐私预算,对统计数据进行排序,得到排序后的统计数据;根据第一部分差分隐私预算,对排序后的统计数据进行合并,得到合并后的统计数据;根据第二部分差分隐私预算,对合并后的统计数据进行加噪,生成发布数据、
在本发明其他实施例中,处理器81配置为执行存储的可执行指令,所述可执行指令还包括:根据选定的差分隐私算法的隐私预算,确定出统计数据中各统计数值的噪声;根据各统计数值的噪声,对统计数据中各统计数值进行排序,得到排序后的统计数据。
在本发明其他实施例中,处理器81配置为执行存储的可执行指令,所述可执行指令还包括:以i=1为初始值;当第i个统计数值与第i个统计数值的噪声之和大于第i+1个统计数值与第i+1个统计数值的噪声之和时,交换第i个统计数值与第i+1个统计数值,将i更新为i+1,直至更新后的i等于统计数据中统计数值的总数,得到排序后的统计数据;其中,i为整数。
在本发明其他实施例中,处理器81配置为执行存储的可执行指令,所述可执行指令还包括:获取排序后的统计数据的发布误差阈值和隐私预算阈值;判断第一部分隐私预算是否大于等于隐私预算阈值;当第一部分隐私预算大于等于隐私预算阈值时,从排序后的统计数据中,选取出相邻统计数值之差最小的两个统计数值,合并两个统计数值为一个统计数值,用合并后的一个统计数值和剩余统计数值形成单次合并后的统计数据;确定单次合并后的统计数据的发布误差;当单次合并后的统计数据的发布误差小于发布误差阈值时,将发布误差阈值更新为单次合并后的统计数据的发布误差,将第一部分隐私预算更新为第一部分隐私预算减去隐私预算阈值,重新判断第一部分隐私预算是否大于等于隐私预算阈值,直至合并完成;当单次合并后的统计数据的发布误差大于等于发布误差阈值时,合并完成;用合并完成后的统计数据形成合并后的统计数据;其中,剩余统计数值为排序后的统计数据中除两个统计数值以外的其他统计数值。
在本发明其他实施例中,处理器81配置为执行存储的可执行指令,所述可执行指令还包括:根据第二部分隐私预算和合并后的统计数据中每个统计数值中合并统计数值的个数,分别对合并后的统计数据中每个统计数值进行加噪,生成发布数据。
本发明实施例提供一种计算机存储介质,图9为本发明实施例中的计算机存储介质的结构示意图,如图9所示,所述计算机存储介质90中存储有计算机可执行指令,该计算机可执行指令配置为执行本发明其他实施例提供的发布数据的生成方法。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!