一种深度神经网络运算系统及方法与流程
本发明涉及深度神经网络加速计算领域,特别涉及一种深度神经网络运算系统及方法。
背景技术:
gpu通用计算技术发展已经引起业界不少的关注,事实也证明在浮点运算、并行计算等部分计算方面,gpu可以提供数十倍乃至于上百倍于cpu的性能。gpu通用计算方面的标准目前有opencl(opencomputinglanguage,开放运算语言)、cuda(computeunifieddevicearchitecture)、atistream。其中,opencl是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(cpu)、图形处理器(gpu)、cell类型架构以及数字信号处理器(dsp)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。
目前对深度神经网络的加速方法通常采用gpu加速方法,其高度优化的计算库cudnn及高性能的gpu并行处理架构,使得深度神经网络在gpu平台上的加速性能十分优越,但其高耗电量造成能耗比很低,也是极大的弊端。
技术实现要素:
有鉴于此,本发明的目的在于提供一种深度神经网络运算系统及方法,以降低耗电量,提高能耗比,降低运行成本。其具体方案如下:
一种深度神经网络运算系统,包括:
cpu,用于接收目标数据,利用深度神经网络进行处理,得到深度神经网络的输入层数据;
fpga,用于利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节,计算所述输入层数据,得到计算结果。
可选的,所述fpga,包括:
gemm计算单元,用于利用激活函数所述输入层数据,得到所述计算结果;其中,
所述激活函数为:
式中,wij表示第一隐含层节点i和第二隐含层节点j之间的权值,bj表示第二隐含层节点j的阀值,xj表示第二隐含层节点j的输出值。
可选的,所述fpga,包括:
并行运算单元,用于通过#pragaunrollx展开计算所述推算环节,其中,x表示利用pcie带宽数确定的展开层数。
本发明还公开了一种深度神经网络运算方法,包括:
接收目标数据,利用深度神经网络进行处理,得到深度神经网络的输入层数据;
利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节,计算所述输入层数据,得到计算结果。
可选的,所述利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节,计算所述输入层数据,得到计算结果的过程,包括:
利用激活函数所述输入层数据和并行运算程序执行推算环节,得到所述计算结果;其中,
所述激活函数为:
式中,wij表示第一隐含层节点i和第二隐含层节点j之间的权值,bj表示第二隐含层节点j的阀值,xj表示第二隐含层节点j的输出值。
可选的,所述利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节的过程,包括:
通过#pragaunrollx展开并行计算所述gemm计算节点,执行所述推算环节,其中,x表示利用pcie带宽数确定的展开层数。
本发明中,深度神经网络运算系统,包括:cpu,用于接收目标数据,利用深度神经网络进行处理,得到深度神经网络的输入层数据;fpga,用于利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节,计算输入层数据,得到计算结果。本发明通过将深度神经网络的gemm计算节点移植到fpga中,由cpu接收用户输入的目标数据,基于深度神经网络将目标数据转化为深度神经网络输入层数据,并发送至fpga,fpga利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节,计算输入层数据,得到计算结果,完成运算,基于fpga的硬件特性,由fpga完成推算环节,极大地降低了运算能耗,降低了运行成本。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明实施例公开的一种深度神经网络运算系统结构示意图;
图2为本发明实施例公开的一种深度神经网络运算方法流程示意图;
图3为本发明实施例公开的一种深度神经网络gemm节点结构示意图;
图4为本发明实施例公开的一种深度神经网络gemm节点输出层结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种深度神经网络运算系统,参见图1所示,该系统包括:
cpu11,用于接收目标数据,利用深度神经网络进行处理,得到深度神经网络的输入层数据。
具体的,cpu11接收用户输入的目标数据,目标数据的形式可以为一段代码,或一个计算任务,cpu11将目标数据转化为满足深度神经网络输入层的格式,并且输入到输入层,从而得到深度神经网络的输入层数据,以便于后续深度神经网络的隐含层和输出层对目标数据进行处理,得到计算结果。
fpga12(fieldprogrammablegatearray,现场可编程门阵列),用于利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节,计算输入层数据,得到计算结果。
具体的,fpga12是在pal、gal、cpld等可编程器件的基础上进一步发展的产物,它是作为专用集成电路领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点,可以实现对深度神经网络快速的并行计算。
具体的,利用opencl语言将gemm算法移植到fpga12的kernel端,利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节,计算输入层数据,得到计算结果。
本发明实施例中,fpga12,具体可以包括gemm计算单元和并行运算单元;其中,
gemm计算单元,用于利用激活函数输入层数据,得到计算结果;其中,
激活函数为:
式中,wij表示第一隐含层节点i和第二隐含层节点j之间的权值,bj表示第二隐含层节点j的阀值,xj表示第二隐含层节点j的输出值。
其中,隐含层中各节点计算相对独立,且均与上一层节点有关,计算方法相同,均为gemm算法,每个节点的输出值是根据上层所有节点的输出值、当前节点与上一层所有节点的权值和当前节点的阀值还有激活函数计算得到的。
需要说明的是,隐含层可以根据用户的计算要求进行设定,而不仅只局限于两层。
并行运算单元,用于通过#pragaunrollx展开计算推算环节,其中,x表示利用pcie带宽数确定的展开层数。
具体的,fpga12接收cpu11处理得到的输入层数据,基于pcie带宽数,通过#pragaunrollx程序可以生成与pcie带宽数相对应的深度神经网络中的gemm计算节点数,每个gemm计算节点利用激活函数输入层数据,并行运算,执行推算环节,得到计算结果。
其中,展开层数,也可以在满足pcie带宽数最大限定范围内,根据用户实际应用需求进行设定,例如,根据pcie带宽数展开层数最多为20层,用户可以设定展开层数为10层。
需要说明的是,由于fpga12硬件特性,fpga12的能耗量远低于gpu,因此,将深度神经网络的gemm计算节点移植到fpga12中,通过fpga12执行深度神经网络的计算环节,能够极大地降低能耗,从而降低运行成本。
可见,本发明实施例通过将深度神经网络的gemm计算节点移植到fpga12中,由cpu11接收用户输入的目标数据,基于深度神经网络将目标数据转化为深度神经网络输入层数据,并发送至fpga12,fpga12利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节,计算输入层数据,得到计算结果,完成运算,基于fpga12的硬件特性,由fpga12完成推算环节,极大地降低了运算能耗,降低了运行成本。
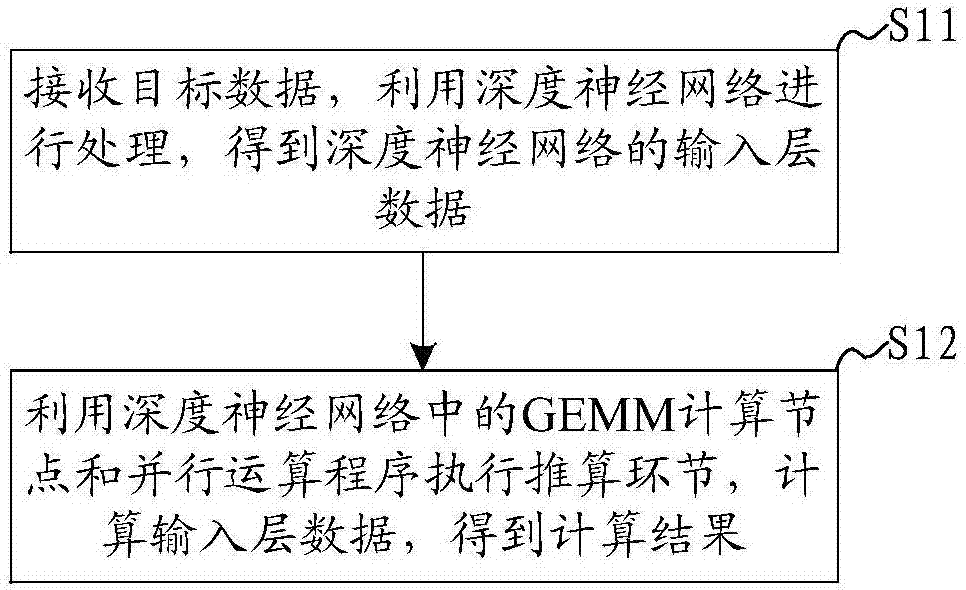
本发明实施例还公开了一种深度神经网络运算方法,参见图2所示,该方法包括:
步骤s11:接收目标数据,利用深度神经网络进行处理,得到深度神经网络的输入层数据;
步骤s12:利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节,计算输入层数据,得到计算结果。
具体的,可以利用激活函数输入层数据和并行运算程序执行推算环节,得到计算结果;其中,
激活函数为:
式中,wij表示第一隐含层节点i和第二隐含层节点j之间的权值,bj表示第二隐含层节点j的阀值,xj表示第二隐含层节点j的输出值。
具体的,可以通过#pragaunrollx展开并行计算gemm计算节点,执行推算环节,其中,x表示利用pcie带宽数确定的展开层数。
其中,在深度神经网络中,全连接层主要由gemm节点计算及分类器输出计算。gemm节点计算由于深度神经网络的网络特性,其隐含层的同层节点间计算是相对独立的,参见图3所示,且在推算阶段均且只与上层节点相关,参见图4所示。fpga在处理并行计算时优势明显,其通过硬件特性实现数据并行处理能力。
可见,本发明实施例通过将深度神经网络的gemm计算节点移植到fpga中,由cpu接收用户输入的目标数据,基于深度神经网络将目标数据转化为深度神经网络输入层数据,并发送至fpga,fpga利用深度神经网络中的gemm计算节点和并行运算程序执行推算环节,计算输入层数据,得到计算结果,完成运算,基于fpga的硬件特性,由fpga完成推算环节,极大地降低了运算能耗,降低了运行成本。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上对本发明所提供的一种深度神经网络运算系统及方法进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!