面向社交平台的用户情感影响力分析方法与流程
本发明涉及情感影响力分析方法技术领域,具体为面向社交平台的用户情感影响力分析方法。
背景技术:
互联网已经成为人类生活密不可分的一部分,逐渐替代了传统社交媒体的功能,在信息获取、信息传播等功能上更加强大,其快速性、实时性使其更好地为用户服务,随着互联网的发展和网络技术的提升,在线社交平台的研究开始向海量数据和复杂用户关系的这一富有挑战性的大数据命题过渡,针对在线社交网络平台用户影响力的分析可以应用到很多领域,如舆论导向领域、商业领域、公益领域,为此,我们提出了面向社交平台的用户情感影响力分析方法。
技术实现要素:
本发明的目的在于提供面向社交平台的用户情感影响力分析方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:面向社交平台的用户情感影响力分析方法,所述面向社交平台的用户情感影响力分析方法包括下述四个步骤:
第一步基于社交平台的用户网络建设:
利用网络爬虫技术从x社交平台(x表示某一个具体公知的社交平台)中收集公开的用户基本信息和用户已经上传的信息,把收集的信息存储在数据库中对应的表结构中,用于构建x社交平台的用户网络;
第二步基于社交平台内文本的高效特征抽取:
首先对x社交平台中的文本进行分词处理,去除其中的标点符号、停用词和url链接,得到纯文本的单词集合,采用文本聚类的方法,将所有训练文本的单词集合映射降维成多个话题和特征词组成特征向量矩阵,得到新的特征空间;
第三步基于深度学习算法的社交平台内文本情感分类:
利用机器学习方法对x社交平台内文本进行情感分类,机器学习方法是通过设计及其学习算法找出区分类别的特征,进而对x社交平台内文本进行情感分类;
第四步通过seinrank算法构建社交平台情感影响力计算模型:
分别基于x社交平台用户网络结构、基x社交平台用户行为和基于x社交平台文本的用户情感倾向,综合考虑上述三个方面提出本文的用户情感影响力计算模型。
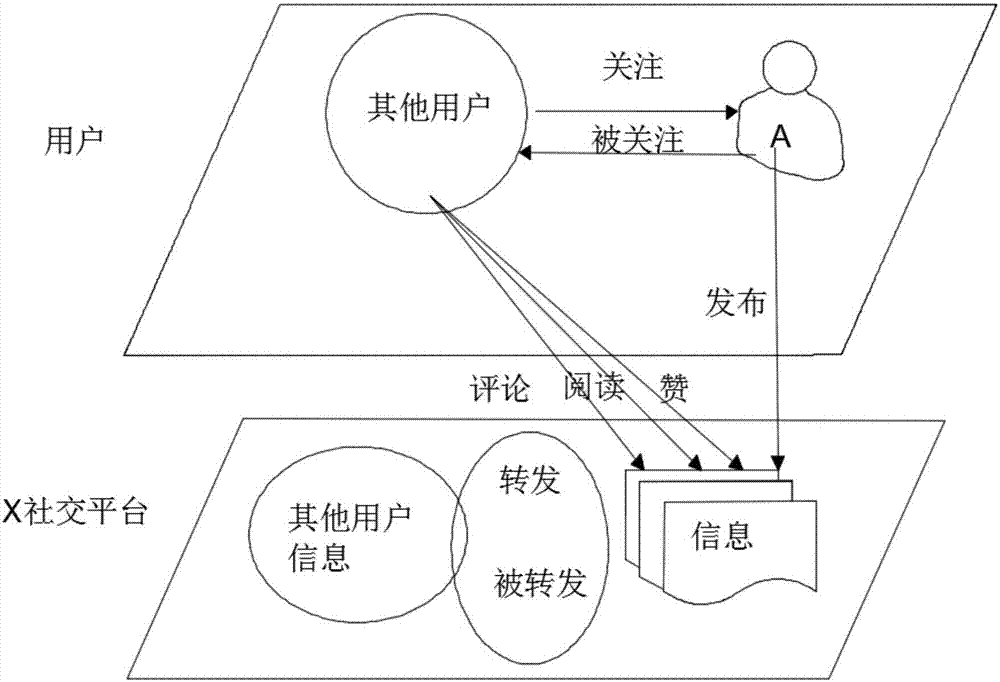
优选的,第一步基于社交平台的用户网络建设具有为:x社交平台用户之间的交互行为分为用户关注行为、用户评论行为、用户转发行为,如图2所示,设u={u1,u2,...,un}表示x社交平台用户集合,并且ui(1≤i≤n)是u中的任意一个用户,设w={w1,w2,...,wm}表示一个用户发布信息集合,并且wi(1≤i≤m)是w中的任意一条用户发布信息,针对用户ui发布的信息,设wi={wi1,wi2,...,wik}表示用户ui发布的信息集合共有k条用户信息,并且wij(1≤i≤k)是wi中的一个用户信息,x社交平台用户集合u可以构建网络拓扑结构;
定义1:关注行为链接,对于ui和uj其中(1≤i≠j≤n),分别表示互不相同的x社交平台用户,当用户ui关注了用户uj时,那么ui与uj之间存在ui指向uj的关注行为链接,即用户ui为用户uj的粉丝;
定义2:转发行为链接,对于ui和uj其中(1≤i≠j≤n),分别表示互不相同的x社交平台用户,当用户ui发布了一条信息wij时,随后用户uj转发了此条信息,那么ui与uj之间存在ui指向uj的转发行为链接;
定义3:评论行为链接,对于ui和uj其中(1≤i≠j≤n),分别表示互不相同的x社交平台用户,当用户ui发布了一条信息wij时,随后用户uj评论了此条信息,那么ui与uj之间存在uj指向ui的评论行为链接;
定义4:用户网络有向图,v是节点集合,e表示根据定义1、定义2和定义3得到的边的集合,用户集合u={u1,u2,...,un}构成x社交平台用户网络的节点,则g(v,e)可以表示一个x社交平台用户网络有向图;
对于x社交平台用户集合u={u1,u2,...,un},根据定义1、定义2和定义3得到的链接关系构建一个x社交平台用户关系网络g(v,e),节点集合u的数目为x社交平台用户数目n,边集合e包含上述三种链接,因此构建x社交平台用户网络模型g(v,e)的算法如图3所示。
优选的,第二步基于社交平台内文本的高效特征抽取:用户层中x社交平台用户之间存在关注关系,若用户ui关注了用户uj,则用户uj发布的全部信息对用户ui可见,并且用户ui可以针对自身喜好对用户uj的信息进行转发和评论,其中转发的信息属于用户ui;信息文本层与用户层之间存在发布、转发和评论关系;话题层表示用户所发一条信息可以对应多个话题,同时每一个话题可以涉及到多个特征词,本文通过特征抽取可以得到对应话题的特征词,基于上述描述x社交平台环境存在多层结构,分为话题层、信息文本层和用户层;
定义5:x社交平台中用户信息文本特征,设w={w1,w2,...,wm}表示一个用户信息集合,并且wi(1≤i≤m)是w中的一个用户信息,假设用户ui发布信息,设wi={wi1,wi2,...,wik}表示用户ui的用户信息集合,并且wij(1≤j≤k)是wi中的一个信息,针对用户ui的用户信息集合,通过特征提取可以获得t={t1,t2,...,tn}表示一个信息话题集合,其中ti(1≤i≤n)是对应wi中的一个话题,每一个话题下对应一个特征词集合vi={vi1,vi2,...,vim},其中vim(1≤j≤m)是vi中一个对应话题ti的一个特征词,如果可以用特征词集合vi={vi1,vi2,...,vim}表示用户所发的信息wij,那么称特征词集合vi={vi1,vi2,...,vim}为信息wij的信息文本特征;
利用潜在狄利克雷分配(lda)算法来计算一篇文档的话题概率分布,lda算法的核心公式如下:(1)p(vj|wi)表示词语vj在给定x社交平台用户信息wi中出现的概率,(2)p(tk|wi)表示主题tk在给定x社交平台用户信息wi中出现的概率,(3)p(vj|tk)表示词语vj在给定主题tk中出现的概率,由上面三个公式可以推导出:
描述lda算法的实现过程的算法如图4所示,算法包含三层结构,分别是特征词、话题和x社交平台中文本,具体操作是将词频数据缓存到rdd中,进行map操作将数据转换成向量格式,设置lda模型的话题个数,得到一个distributedldamodel的模型,调用topicdistributions方法可以得到x社交平台中话题分布,topicsmatrix方法可以得到话题单词分布矩阵,经过描述lda算法的实现过程的算法的处理,根据公式1的原理,可以得到两个概率分布矩阵,话题|x社交平台中文本矩阵,特征词|话题矩阵,如公式2和公式3所示,
公式2中,矩阵t|w的行数为m表示一共有m条x社交平台文本,列数为k,表示将每一条x社交平台用户信息划分成k个话题,tij:wgtij表示第i条用户信息的第j个话题的序号和该话题在此用户信息下的概率分布权重;
公式3中,矩阵v|t的行数为k表示一共存在k个话题,列数为n,表示将每个话题可以包含n个特征词,vij:wgtij表示第i话题的第j个特征词的序号和该特征词在此话题下的概率分布权重;
根据公式2和公式3,一条x社交平台的用户信息通过lda模型可以得到对应的话题和关键词,假设用户信息集合w={w1,w2,...,wm}的任意一条用户信息wi均可以表示为:
优选的,第三步基于深度学习算法的社交平台内文本情感分类:
定义6:x社交平台中用户信息情感倾向,设wi={wi1,wi2,...,wim}表示x社交平台用户ui的信息文本集合,并且wij(1≤j≤m)是wi中的一个信息文本,信息文本经分词处理之后可以得到单词集合wordij={wordij1,wordij2,...,wordijn},对任意wordijk(x社交平台用户i发布的第j条信息经分词处理后的第k个单词)判断情感倾向,若wordijk的情感倾向sk为正向则sk=1,若wordijk的情感倾向sk为负向则sk=-1,否则sk=0,计算单词集合wordij中否定词的数目count,综上用户信息的情感倾向可表示为:sw=∑sk,如果count为奇数,sw=-sw,若sw>0,则设定wlable=1,即这个用户信息为正向情感,反之设定wlable=-1,即这个用户信息为负向情感;
根据定义6,可以计算x社交平台的情感倾向wlabel,伪代码如图5所示,在图5的算法中,算法第2行首先进行分词处理,3~10行对分词之后的单词集合初始化wlabel=0,将单词进行positive和negative情感分类,并统计集合中的否定词,第12行量化计算用户信息情感倾向,如否定词为奇数个,那么用户信息的情感标签为原来的负向,最后得到wlabel∈{1,0,-1};
如图6为x社交平台用户情感分类流程图,用户的信息情感表示用户对于日常生活的真实态度,是研究x社交平台用户情感影响力的一个主要的衡量因素,本文对用户信息进行情感倾向的划分,可划分为正向情感、负向情感和中立情感,用1、-1和0分别表示,作为每条用户信息的情感标签;
根据图5的算法,可以得到每条x社交平台用户的信息的情感标签wlabel,当wlabel=1时表示此用户信息为正向情感;当wlabel=-1时表示此用户信息为负向情感;当wlabel=0时表示此用户信息为中立情感,根据已分类的用户信息文本进行深度学习分类模型的训练,其中训练数据集可以表示为
如图7的算法所示,本文提出的基于x社交平台中用户信息特征词向量的信息情感的分类算法,算法第2行首先将训练集数据通过map算子转换成densematrix数据形式,作为分类模型的输入rdd,之后设置分类器的属性值,其中包括分类器各层节点数、输入层和隐藏层激活函数、学习因子以及惩罚因子等,并设置训练的迭代次数,算法5~12行描述训练分类器的迭代过程,算法第6行随机设置可见层到隐藏层的权重,算法6~8先通过前向传播从可见层通过激活函数得到隐藏层结果,之后从隐藏层到可见层进行输入重构,采用反向传播的方法,进行局部收敛,随着迭代次数的增加,更新上述权重参数,得到训练好的分类器,并对测试数据进行测试得到其用户信息情感标签;
通过上述研究将原始x社交平台用户信息文本转化成特征词向量输入到深度学习的分类器中,训练分类器,已达到大面积标记信息文本情感的目的,x社交平台用户的情感倾向是通过其用户信息文本表达的情感累积得到的,分类器会将用户的情感分为正向情感和负向情感,根据相应情感信息的条数,计算出x社交平台用户的情感值,作为衡量x社交平台用户影响力的情感因素。
优选的,第四步通过seinrank算法构建社交平台情感影响力计算模型:社交平台情感影响力的度量从三方面入手,分别是基于x社交平台用户网络结构、基于x社交平台用户行为和基于x社交平台用户信息文本的用户情感倾向,综合考虑上述三个方面提出本文的用户情感影响力计算模型:
(1)影响自发度ins,针对x社交平台用户自身,用户影响力的直观体现在用户发布信息的数量和用户拥有粉丝的数量,这两方面为自身影响力被其他用户接受提供条件,其中衡量的指标是粉丝数和用户信息总数;
(2)影响参与度inp,用户的信息可以被其他用户评论和转发,能触发这些用户行为,表明此用户对其他用户存在影响力,其中衡量的指标是转发数和评论数;
(3)影响传播度ind,用户转发一条信息,则此条信息保存在用户的信息列表中,对此用户的所有粉丝可见,这样一条信息的影响被转发行为扩散出去,而影响力的传播范围体现在转发信息的用户拥有的粉丝数;
(4)影响力动能ine,综合考虑影响力自发度、影响力参与度、影响力传播度以及用户情感倾向这四个方面,计算影响力的度量参数;
如图8所示表示seinrank算法的计算原理,基于上述三个量化指标结合用户的信息情感倾向得到用户的影响动能,之后迭代计算用户的seinrank值,设x社交平台用户u的粉丝集合为ufollow,x社交平台用户u发布的具有情感倾向的信息集合为w={w1,w2,...,wn},wi(1≤i≤n)是w中的一个信息,转发wi的用户集合表示为urepost,评论wi的用户集合表示为ucomment,基于上述三个量化指标,设计如下计算公式:
公式4计算影响自发度,|ufollow|表示用户u的粉丝数目,|wall|表示用户的信息总数,用户的信息数和粉丝数作为自身属性计算用户自身影响力,
公式5计算影响传播度,表示情感用户信息wi的传播程度,用户uk是urepost中任意一个用户,对urepost中的用户粉丝数求和,用户转发信息使用户信息影响力得到传播,
公式6计算影响参与度,|ucomment|表示情感用户信息wi的评论数,情感信息的转发和评论体现用户对情感影响力传播的参与程度,
公式7计算用户u的正向情感的影响力动能,其中wpos是用户u的正向情感的信息集合,|wpos|表示正向情感信息的个数,其中参数α、β、λ、μ为影响力计算因素的权重,
公式8计算用户u的负向情感的影响力动能,其中wneg是用户u的负向情感的信息集合,|wneg|表示负向情感信息的个数,公式7和公式8中参数α、β、λ、μ为影响力计算因素的权重,参数的确定方法是层次分析法,
公式9计算用户u的所有粉丝用户的正向情感影响力动能的总和,
公式10计算用户的所有粉丝用户的负向情感影响力动能的总和,
公式11计算x社交平台网络中用户节点的正向情感影响力,n为x社交平台网络中的用户节点个数,seinrank(u)为节点u的情感影响力值,用户v是用户u的粉丝,d/n为随机游走的概率,称为阻尼系数,表示用户节点随机节点到其他用户节点的概率,
公式12计算x社交平台网络中用户节点的负向情感影响力;
基于上述计算原理,x社交平台用户情感影响力计算模型算法的伪代码如图9算法所示,这个算法是本文提出的x社交平台用户情感影响力计算的seinrank算法,是x社交平台用户情感影响力排序模型,算法2~4行首先对网络关系图中每一条链接根据公式7和8计算权重值,算法5~7行将用户关系网络图g(v,e)对应成一个邻接关系表,并将关系表缓存到linkrdd中,其中rdd中的数据元素为一个三元组(u,v,weight),并对其进行groupbykey操作获得(u,list(node,weight))数据格式,生成一个rankrdd并设置初始rank值,数据格式为(u,rank),初始的rank值为1/n,其中n为网络关系图中的节点总数,算法11~17行linksrdd与rankrdd进行join操作,并转换rdd映射成为node,weight*rank),并其进行reducebykey操作,通过公式11和12迭代计算seinrank值,生成新的rankrdd。
与现有技术相比,本发明的有益效果是:本发明通过利用面向社交平台的用户情感影响力分析方法,找出在线社交平台用户情感影响力大的用户,用户的影响力越大,其权威值越大,得到的用户关注越多,这样的用户在社交平台环境中具有导向能力,此研究可以用于舆论导向领域、商业领域、公益领域和公共健康领域。
附图说明
图1为本专利的用户情感影响力分析算法总体流程图;
图2为本专利的x社交平台用户网络结构图;
图3为本专利的x社交平台用户网络构建算法程序图;
图4为本专利的x社交平台文本特征抽取算法程序图;
图5为本专利的x社交平台情感倾向分类算法程序图;
图6为本专利的x社交平台情感分类流程图;
图7为本专利的x社交平台情感分类算法程序图;
图8为本专利的seinrank算法的计算原理图;
图9为本专利的x社交平台用户情感影响力计算模型算法程序图。
具体实施方式
下面将结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不限于此。
实验环境:
本文实验环境是运行在hadoop集群的spark平台,spark是一个实现快速而通用的集群计算平台;
本实验spark和hadoop集群共有3个节点,每个节点详细配置如下:
cpu:2*xeone5-2620cpu(每个有6核心*2线程);
内存:32gbytes;
硬盘:5tbytes,10000rpm,raid5;
操作系统:centos6.4;
开发环境:jdk1.7.0_45;
实验所用开发语言为标准java,scala语言。
面向社交平台的用户情感影响力分析方法,所述面向社交平台的用户情感影响力分析方法包括下述四个步骤:
第一步基于社交平台的用户网络建设:
利用网络爬虫技术从x社交平台(x表示某一个具体公知的社交平台)中收集公开的用户基本信息和用户已经上传的信息,把收集的信息存储在数据库中对应的表结构中,用于构建x社交平台的用户网络;
第二步基于社交平台内文本的高效特征抽取:
首先对x社交平台中的文本进行分词处理,去除其中的标点符号、停用词和url链接,得到纯文本的单词集合,采用文本聚类的方法,将所有训练文本的单词集合映射降维成多个话题和特征词组成特征向量矩阵,得到新的特征空间;
第三步基于深度学习算法的社交平台内文本情感分类:
利用机器学习方法对x社交平台内文本进行情感分类,机器学习方法是通过设计及其学习算法找出区分类别的特征,进而对x社交平台内文本进行情感分类;
第四步通过seinrank算法构建社交平台情感影响力计算模型:
分别基于x社交平台用户网络结构、基x社交平台用户行为和基于x社交平台文本的用户情感倾向,综合考虑上述三个方面提出本文的用户情感影响力计算模型。
具体而言,第一步基于社交平台的用户网络建设具有为:x社交平台用户之间的交互行为分为用户关注行为、用户评论行为、用户转发行为,如图2所示,设u={u1,u2,...,un}表示x社交平台用户集合,并且ui(1≤i≤n)是u中的任意一个用户,设w={w1,w2,...,wm}表示一个用户发布信息集合,并且wi(1≤i≤m)是w中的任意一条用户发布信息,针对用户ui发布的信息,设wi={wi1,wi2,...,wik}表示用户ui发布的信息集合共有k条用户信息,并且wij(1≤i≤k)是wi中的一个用户信息,x社交平台用户集合u可以构建网络拓扑结构;
定义1:关注行为链接,对于ui和uj其中(1≤i≠j≤n),分别表示互不相同的x社交平台用户,当用户ui关注了用户uj时,那么ui与uj之间存在ui指向uj的关注行为链接,即用户ui为用户uj的粉丝;
定义2:转发行为链接,对于ui和uj其中(1≤i≠j≤n),分别表示互不相同的x社交平台用户,当用户ui发布了一条信息wij时,随后用户uj转发了此条信息,那么ui与uj之间存在ui指向uj的转发行为链接;
定义3:评论行为链接,对于ui和uj其中(1≤i≠j≤n),分别表示互不相同的x社交平台用户,当用户ui发布了一条信息wij时,随后用户uj评论了此条信息,那么ui与uj之间存在uj指向ui的评论行为链接;
定义4:用户网络有向图,v是节点集合,e表示根据定义1、定义2和定义3得到的边的集合,用户集合u={u1,u2,...,un}构成x社交平台用户网络的节点,则g(v,e)可以表示一个x社交平台用户网络有向图;
对于x社交平台用户集合u={u1,u2,...,un},根据定义1、定义2和定义3得到的链接关系构建一个x社交平台用户关系网络g(v,e),节点集合u的数目为x社交平台用户数目n,边集合e包含上述三种链接,因此构建x社交平台用户网络模型g(v,e)的算法如图3所示。
具体而言,第二步基于社交平台内文本的高效特征抽取:用户层中x社交平台用户之间存在关注关系,若用户ui关注了用户uj,则用户uj发布的全部信息对用户ui可见,并且用户ui可以针对自身喜好对用户uj的信息进行转发和评论,其中转发的信息属于用户ui;信息文本层与用户层之间存在发布、转发和评论关系;话题层表示用户所发一条信息可以对应多个话题,同时每一个话题可以涉及到多个特征词,本文通过特征抽取可以得到对应话题的特征词,基于上述描述x社交平台环境存在多层结构,分为话题层、信息文本层和用户层;
定义5:x社交平台中用户信息文本特征,设w={w1,w2,...,wm}表示一个用户信息集合,并且wi(1≤i≤m)是w中的一个用户信息,假设用户ui发布信息,设wi={wi1,wi2,...,wik}表示用户ui的用户信息集合,并且wij(1≤j≤k)是wi中的一个信息,针对用户ui的用户信息集合,通过特征提取可以获得t={t1,t2,...,tn}表示一个信息话题集合,其中ti(1≤i≤n)是对应wi中的一个话题,每一个话题下对应一个特征词集合vi={vi1,vi2,...,vim},其中vim(1≤j≤m)是vi中一个对应话题ti的一个特征词,如果可以用特征词集合vi={vi1,vi2,...,vim}表示用户所发的信息wij,那么称特征词集合vi={vi1,vi2,...,vim}为信息wij的信息文本特征;
利用潜在狄利克雷分配(lda)算法来计算一篇文档的话题概率分布,lda算法的核心公式如下:(1)p(vj|wi)表示词语vj在给定x社交平台用户信息wi中出现的概率,(2)p(tk|wi)表示主题tk在给定x社交平台用户信息wi中出现的概率,(3)p(vj|tk)表示词语vj在给定主题tk中出现的概率,由上面三个公式可以推导出:
描述lda算法的实现过程的算法如图4所示,算法包含三层结构,分别是特征词、话题和x社交平台中文本,具体操作是将词频数据缓存到rdd中,进行map操作将数据转换成向量格式,设置lda模型的话题个数,得到一个distributedldamodel的模型,调用topicdistributions方法可以得到x社交平台中话题分布,topicsmatrix方法可以得到话题单词分布矩阵,经过描述lda算法的实现过程的算法的处理,根据公式1的原理,可以得到两个概率分布矩阵,话题|x社交平台中文本矩阵,特征词|话题矩阵,如公式2和公式3所示,
公式2中,矩阵t|w的行数为m表示一共有m条x社交平台文本,列数为k,表示将每一条x社交平台用户信息划分成k个话题,tij:wgtij表示第i条用户信息的第j个话题的序号和该话题在此用户信息下的概率分布权重;
公式3中,矩阵v|t的行数为k表示一共存在k个话题,列数为n,表示将每个话题可以包含n个特征词,vij:wgtij表示第i话题的第j个特征词的序号和该特征词在此话题下的概率分布权重;
根据公式2和公式3,一条x社交平台的用户信息通过lda模型可以得到对应的话题和关键词,假设用户信息集合w={w1,w2,...,wm}的任意一条用户信息wi均可以表示为:
具体而言,第三步基于深度学习算法的社交平台内文本情感分类:
定义6:x社交平台中用户信息情感倾向,设wi={wi1,wi2,...,wim}表示x社交平台用户ui的信息文本集合,并且wij(1≤j≤m)是wi中的一个信息文本,信息文本经分词处理之后可以得到单词集合wordij={wordij1,wordij2,...,wordijn},对任意wordijk(x社交平台用户i发布的第j条信息经分词处理后的第k个单词)判断情感倾向,若wordijk的情感倾向sk为正向则sk=1,若wordijk的情感倾向sk为负向则sk=-1,否则sk=0,计算单词集合wordij中否定词的数目count,综上用户信息的情感倾向可表示为:sw=∑sk,如果count为奇数,sw=-sw,若sw>0,则设定wlable=1,即这个用户信息为正向情感,反之设定wlable=-1,即这个用户信息为负向情感;
根据定义6,可以计算x社交平台的情感倾向wlabel,伪代码如图5所示,在图5的算法中,算法第2行首先进行分词处理,3~10行对分词之后的单词集合初始化wlabel=0,将单词进行positive和negative情感分类,并统计集合中的否定词,第12行量化计算用户信息情感倾向,如否定词为奇数个,那么用户信息的情感标签为原来的负向,最后得到wlabel∈{1,0,-1};
如图6为x社交平台用户情感分类流程图,用户的信息情感表示用户对于日常生活的真实态度,是研究x社交平台用户情感影响力的一个主要的衡量因素,本文对用户信息进行情感倾向的划分,可划分为正向情感、负向情感和中立情感,用1、-1和0分别表示,作为每条用户信息的情感标签;
根据图5的算法,可以得到每条x社交平台用户的信息的情感标签wlabel,当wlabel=1时表示此用户信息为正向情感;当wlabel=-1时表示此用户信息为负向情感;当wlabel=0时表示此用户信息为中立情感,根据已分类的用户信息文本进行深度学习分类模型的训练,其中训练数据集可以表示为
如图7的算法所示,本文提出的基于x社交平台中用户信息特征词向量的信息情感的分类算法,算法第2行首先将训练集数据通过map算子转换成densematrix数据形式,作为分类模型的输入rdd,之后设置分类器的属性值,其中包括分类器各层节点数、输入层和隐藏层激活函数、学习因子以及惩罚因子等,并设置训练的迭代次数,算法5~12行描述训练分类器的迭代过程,算法第6行随机设置可见层到隐藏层的权重,算法6~8先通过前向传播从可见层通过激活函数得到隐藏层结果,之后从隐藏层到可见层进行输入重构,采用反向传播的方法,进行局部收敛,随着迭代次数的增加,更新上述权重参数,得到训练好的分类器,并对测试数据进行测试得到其用户信息情感标签;
通过上述研究将原始x社交平台用户信息文本转化成特征词向量输入到深度学习的分类器中,训练分类器,已达到大面积标记信息文本情感的目的,x社交平台用户的情感倾向是通过其用户信息文本表达的情感累积得到的,分类器会将用户的情感分为正向情感和负向情感,根据相应情感信息的条数,计算出x社交平台用户的情感值,作为衡量x社交平台用户影响力的情感因素。
具体而言,第四步通过seinrank算法构建社交平台情感影响力计算模型:社交平台情感影响力的度量从三方面入手,分别是基于x社交平台用户网络结构、基于x社交平台用户行为和基于x社交平台用户信息文本的用户情感倾向,综合考虑上述三个方面提出本文的用户情感影响力计算模型:
(1)影响自发度ins,针对x社交平台用户自身,用户影响力的直观体现在用户发布信息的数量和用户拥有粉丝的数量,这两方面为自身影响力被其他用户接受提供条件,其中衡量的指标是粉丝数和用户信息总数;
(2)影响参与度inp,用户的信息可以被其他用户评论和转发,能触发这些用户行为,表明此用户对其他用户存在影响力,其中衡量的指标是转发数和评论数;
(3)影响传播度ind,用户转发一条信息,则此条信息保存在用户的信息列表中,对此用户的所有粉丝可见,这样一条信息的影响被转发行为扩散出去,而影响力的传播范围体现在转发信息的用户拥有的粉丝数;
(4)影响力动能ine,综合考虑影响力自发度、影响力参与度、影响力传播度以及用户情感倾向这四个方面,计算影响力的度量参数;
如图8所示表示seinrank算法的计算原理,基于上述三个量化指标结合用户的信息情感倾向得到用户的影响动能,之后迭代计算用户的seinrank值,设x社交平台用户u的粉丝集合为ufollow,x社交平台用户u发布的具有情感倾向的信息集合为w={w1,w2,...,wn},wi(1≤i≤n)是w中的一个信息,转发wi的用户集合表示为urepost,评论wi的用户集合表示为ucomment,基于上述三个量化指标,设计如下计算公式:
公式4计算影响自发度,|ufollow|表示用户u的粉丝数目,|wall|表示用户的信息总数,用户的信息数和粉丝数作为自身属性计算用户自身影响力,
公式5计算影响传播度,表示情感用户信息wi的传播程度,用户uk是urepost中任意一个用户,对urepost中的用户粉丝数求和,用户转发信息使用户信息影响力得到传播,
公式6计算影响参与度,|ucomment|表示情感用户信息wi的评论数,情感信息的转发和评论体现用户对情感影响力传播的参与程度,
公式7计算用户u的正向情感的影响力动能,其中wpos是用户u的正向情感的信息集合,|wpos|表示正向情感信息的个数,其中参数α、β、λ、μ为影响力计算因素的权重,
公式8计算用户u的负向情感的影响力动能,其中wneg是用户u的负向情感的信息集合,|wneg|表示负向情感信息的个数,公式7和公式8中参数α、β、λ、μ为影响力计算因素的权重,参数的确定方法是层次分析法,
公式9计算用户u的所有粉丝用户的正向情感影响力动能的总和,
公式10计算用户的所有粉丝用户的负向情感影响力动能的总和,
公式11计算x社交平台网络中用户节点的正向情感影响力,n为x社交平台网络中的用户节点个数,seinrank(u)为节点u的情感影响力值,用户v是用户u的粉丝,d/n为随机游走的概率,称为阻尼系数,表示用户节点随机节点到其他用户节点的概率,
公式12计算x社交平台网络中用户节点的负向情感影响力;
基于上述计算原理,x社交平台用户情感影响力计算模型算法的伪代码如图9算法所示,这个算法是本文提出的x社交平台用户情感影响力计算的seinrank算法,是x社交平台用户情感影响力排序模型,算法2~4行首先对网络关系图中每一条链接根据公式7和8计算权重值,算法5~7行将用户关系网络图g(v,e)对应成一个邻接关系表,并将关系表缓存到linkrdd中,其中rdd中的数据元素为一个三元组(u,v,weight),并对其进行groupbykey操作获得(u,list(node,weight))数据格式,生成一个rankrdd并设置初始rank值,数据格式为(u,rank),初始的rank值为1/n,其中n为网络关系图中的节点总数,算法11~17行linksrdd与rankrdd进行join操作,并转换rdd映射成为node,weight*rank),并其进行reducebykey操作,通过公式11和12迭代计算seinrank值,生成新的rankrdd。
工作原理:首先需要构建x社交平台用户网络模型,用来表示x社交平台用户之间的关注关系,之后针对x社交平台用户信息文本进行情感特征抽取,将原始信息文本映射成一个由特征词组成的词向量,有效地进行数据降维,之后训练深度学习的用户信息情感分类器,将用户信息文本数据分成正向情感数据、负向情感数据和中立情感数据,在衡量用户情感影响力上添加情感因素,最后设计用户情感影响力计算的seinrank模型,通过从影响自发度、影响参与度和影响传播度三个方面结合用户信息文本的情感因素计算情感影响力动能,迭代计算用户情感影响力并进行影响力排序。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!