一种与银屑病相关的分类模型的构建方法与流程
本发明涉及医学检测技术领域,具体涉及一种与银屑病相关的分类模型的构建方法。
背景技术:
银屑病又称牛皮癣是一种常见的复杂疾病,有报道银屑病的发生与遗传因素相关,尤其是人类白细胞抗原区域(hla),但真正相关的位点并未可知。
随着测序技术的发展和基因组研究的深入,在去年《自然遗传》上就有报道中国人mhc区域的高深度测序和精准变异检测,在其基因组关联分析中定位了数个银屑病的易感位点。但是目前尚缺乏基于hla区域的易感位点的分类和预测模型。所以急需开发相关的分类预测工具利用hla区域易感位点对数据进行分类预测。
银屑病与hla最显著相关,但目前的技术缺乏对hla区域针对性的运用。近期hla区域进行精准变异检测得到突破,精准的定位了hla上与银屑病相关的易感位点。本发明针对这些易感位点对其进行编码和再用机器学习模型adaboost进行分类,可以整合利用hla区域找到的易感位点信息。利用机器学习模型对数据进行综合分析,提高分类准确性,为银屑病的预防筛查提供依据。
技术实现要素:
本发明的目的是解决上述现有技术的不足,基于对mhc区域的全覆盖找到与银屑病相关的生物标记,基于hla区域独立相关的易感位点,利用svm-adaboost构建银屑病的分类模型,提供一种与银屑病相关的分类模型的构建方法,为银屑病的预防筛查提供依据。
本发明是通过以下技术方案实现的:
1数据处理和转换
将各个样本的变异进行编码。通过高通量测序数据获得变异信息,包括hla型别(c*06:02、c*07:04、dpb1*05:01),单核苷酸多态性位点(snp位点)和氨基酸(snp31443520、b:y33y、b:y91c、b:y140s、snp32472030)。
然后对每样本,根据易感位点,转化为本发明所需要的输入数据。针对hla型别采用编辑距离打分,snp和氨基酸采用0/1打分。具体方法如下:①针对易感hla型别,计算每个个体该型别与易感型别的编辑距离并打分;②针对snp位点,如果突变存在记为1,不存在记为0;③针对氨基酸突变,如果突变存在记为1,不存在记为0。
打分完成后,将数据随机拆分,拆分为测试集和训练集,注意测试集和训练集数据没有重叠。样本数少的时候,可以按照5折交叉法(或10折交叉法)将数据分成5份(10份),每次取出1作为测试集,其余的作为训练集。
2利用adaboost-svm模型进行数据的分类
本发明利用adaboost方法来集成支持向量机(svm)分类器,整合利用所有的易感位点信息,提高数据的分类的正确率。
2.1关于分类模型的构建
2.1.1子分类模型svm
支持向量机模型svm是经典的机器学习分类软件,属于有监督式学习。本发明首先利用的高斯核函数(公式1)将数据投射到高维度空间。
其中,x为空间中任意一点,y为所选空间中心,σ为宽度参数,k(x,y)为x到y的空间距离。
之后高维度空间中用svm模型构建分隔平面。分隔平面构建主要是通过距离分隔平面最近的数个点来确定(如图1所示a点就是最近的点之一),并且将最近的点到分隔平面的连线称为支持向量,当支持向量达到最大化时候的平面就设为分隔平面,也即是通过分隔平面将数据最大地分开。本发明采用基于python2的svm模型(参考网站https://www.manning.com/books/machine-learning-in-action)。
2.1.2分类模型集成算法adaboost
adaboost是一种基于错误提升分类器性能的集成方法,通过每一个样本多次训练,通过错误率反复修正分类器最后整合得到集成后的结果。具体方法:首先对样本赋予一样同等的权重。然后在训练数集数据上训练svm并计算该分类器的错误率(ε,公式2)。
错误率ε=正确分类数目/总样本数目(公式2)
然后调整高斯核函数σ,之后在同一数据集上再次svm。在分类器的第二次训练当中,将会重新调整每个样本的权重(这里的权重是一个多维度的向量),其中分类正确样本的下次分类权重将会降低,分类错误的样本的下次权重将会提高。也就是说,最终达到分类正确时候的权重会比分类错误的权重占比要大。具体方法是根据错误率计算每个分类器的权重α。
计算出α之后可以对权重进行更新。
分类正确:
分类错误:
α为基本分类器在最终分类器中的权重,ε为分类器的错误率;(t)代表顺序,t代表本次,t+1代表下一次;di为第i个训练样本权值。
计算权值d之后,开始进入下一轮迭代。不断地重复训练和调整权重的过程,直到训练错误率为0或者弱分类器的数目达到指定值。本发明采用基于python2的adaboost集成框架(参考网站https://www.manning.com/books/machine-learning-in-action)
3对数据进行分类和评估
构建好输入训练集和测试集之后,代入构建的adaboost-svm模型中进行分类。通过分类模型的结果与实际患病与否的情况进行比较。通过计算准确率和绘制roc曲线来对结果进行评估。
roc曲线是用于选择最佳的信号模型的方法。通常可计算roc曲线下方面积(auc)来判断分类模型好坏,具体参考表1。
表1
本发明的有益效果在于:
目前缺乏相关的技术来对银屑病数据进行分类和预测,只停留在判断位点有无来推断患病情况。本发明利用有效的机器学习分类器svm进行分类,并通过了adaboost框架来集成svm,提高分类器的准确性。该模型可以整合snp、氨基酸和型别数据进行分类,综合考虑各个维度的信息,提高了数据了分类结果的准确性。
附图说明
图1为高维度空间中用svm模型构建分隔平面的示意图;
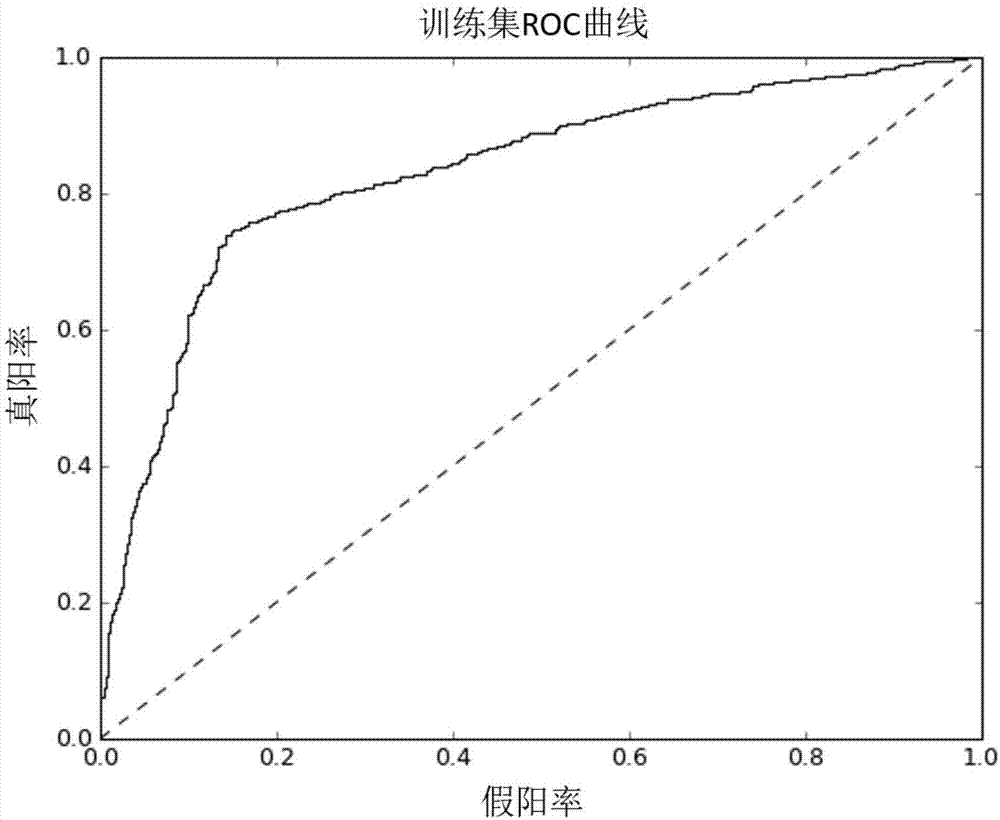
图2为本发明训练集分类结果的roc曲线;
图3为本发明测试集分类结果的roc曲线。
具体实施方式
为更好理解本发明,下面结合实施例及附图对本发明作进一步描述,以下实施例仅是对本发明进行说明而非对其加以限定。
实施例1
选择了银屑病30岁以下样本进行研究共计5168例。利用基于python2语言的adaboost-svm模型针对易感位点构建模型进行分类。
1数据的处理和转换
本实施案例中,首先通过变异检测获得样本的变异信息ped和map文件。之后根据易感位点(表2)提取出hla区域变异信息。其中型别(1、2、7)的打分按照编辑距离进行打分(打分矩阵见表3),氨基酸位点和snp位点(3、4、5、6、8)按照存在与否进行打分,存在打分为1,不存在打分为0。
表2易感位点
表3编辑距离打分矩阵
得到数据列表,由于数据量5168例,所以本案选择2000例作为训练集,余下样本作为测试集。
2代入模型
将处理好的数据代入本发明构建的adaboost-svm模型中进行计算,本案设置9个svm分类器,σ取值从30到3,从大到小逐次递减。
3得到结果
如图2和3所示,本案分类错误率为23.9%,训练集auc(roc曲线下面积)为0.833,测试集auc为0.868,说明本发明在本实施例中达到良好效果。
以上所述实施方式仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明的权利要求书确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!