识别企业名称的方法及装置与流程
本发明涉及信息处理与文本挖掘技术领域,具体涉及一种识别企业名称的方法,此外还涉及一种识别企业名称的装置。
背景技术:
很多金融机构利用互联网上的海量文本来对客户做风险把控。例如,通过对互联网上的新闻进行挖掘分析,获取到金融机构的企业客户的相关信息,并提示从中发现的风险,从而对企业客户进行风险把控。例如,从某篇新闻中获取到a企业的关于产品侵权诉讼的信息,或者获取到a企业的关于拖欠供应商货款的信息,这些信息都有助于金融机构分析a企业的企业情况,从而做出减少或停止贷款等决定,把控可能产生的a企业无法如期偿还贷款的风险。
从海量文本中挖掘企业的相关信息,通常首先需要采用分词器对文本进行分词,然后一方面从文本中识别出企业名称,另一方面从文本中挖掘出对金融机构把控风险有用的相关信息,并将企业名称与相关信息关联起来,从而便于发现存在风险的企业。
发明人经过分析认为,采用常规的分词器不能从文本中把企业名称准确地切分出来,导致计算机的对企业名称的识别结果经常出现错误。这是因为,在文本中,尤其是像新闻这样的文本中,企业名称具有企业全称、企业简称等多种表现形式,而部分企业简称还存在歧义。
具体来说,常规的分词器为提高普适性,主要是按照通用日常语言的切分习惯来对文本进行切分,容易将企业全称切分成多个分词。例如,“连云港港口控股集团有限公司”经过常规的分词器的切分,得到的切分结果有可能是“连云港/港口/控股/集团/有限公司”。分词结果中,“连云港”既可以是“连云港港口控股集团有限公司”的企业简称,又可以表示一个地名,存在多种含义。因此当文本中切分出“连云港”一词时,计算机无法准确判断该分词在当前文本中是否表示企业简称。
因此,利用常规的方法识别文本中的企业名称的准确率较低,这是本领域技术人员亟待解决的问题。
技术实现要素:
第一方面,本申请提供一种识别企业名称的方法,包括以下步骤:
获取待识别文本中的歧义简称,所述歧义简称由包括歧义词典的分词器从所述待识别文本中切分出,所述歧义词典中包括至少一个存在歧义的企业简称;
从预设的企业信息库中获取与所述歧义简称匹配的企业简称,以及与所述企业简称关联的企业信息;
识别所述待识别文本中是否存在所述企业信息;
如果不存在所述企业信息,则识别所述歧义简称不是企业名称。
结合第一方面,在第一方面第一种可能的实现方式中,识别所述待识别文本中是否存在所述企业信息的步骤之后,还包括:
如果存在所述企业信息,则计算所述企业信息对应的权重值;
如果所述权重值在预设范围内,则识别所述歧义简称是企业名称;
如果所述权重值不在预设范围内,则识别所述歧义简称不是企业名称。
结合第一方面的第一种实现方式,在第一方面第二种可能的实现方式中,计算所述企业信息对应的权重值的步骤,包括:
确定所述企业信息中各条子信息对应的信息类型;
确定与各个所述信息类型分别对应的子权重值;
计算所述企业信息对应的权重值,所述权重值是所述子权重值之和。
结合第一方面及上述可能的实现方式,在第一方面第三种可能的实现方式中,所述歧义简称由包括歧义词典的分词器从所述待识别文本中切分出,具体包括以下步骤:
获取待识别文本;
将歧义词典中的企业简称以树形结构存储,生成词典树;
使用所述词典树识别所述待识别文本中的歧义简称。
结合第一方面及上述可能的实现方式,在第一方面第四种可能的实现方式中,如果未获取到待识别文本中的歧义简称,则该识别企业名称的方法还包括以下步骤:
获取待识别文本中的企业全称作为识别出的企业名称,所述企业全称由包括全称词典的分词器从所述待识别文本中切分出,所述全称词典包括至少一个企业全称;和/或,
获取待识别文本中的企业简称作为识别出的企业名称,所述企业简称由包括简称词典的分词器从所述待识别文本中切分出,所述简称词典包括至少一个没有歧义的企业简称。
第二方面,提供一种识别企业名称的装置,包括:
第一获取单元,用于获取待识别文本中的歧义简称,所述歧义简称由包括歧义词典的分词器从所述待识别文本中切分出,所述歧义词典中包括至少一个存在歧义的企业简称;
第二获取单元,用于从预设的企业信息库中获取与所述歧义简称匹配的企业简称,以及与所述企业简称关联的企业信息;
第一识别单元,用于识别待识别文本中是否存在所述企业信息;
第二识别单元,用于在所述待识别文本中不存在所述企业信息的情况下,识别所述歧义简称不是企业名称。
结合第二方面,在第二方面第一种可能的实现方式中,所述第二识别单元还用于在所述待识别文本中存在所述企业信息的情况下,计算所述企业信息对应的权重值;如果所述权重值在预设范围内,则识别所述歧义简称是企业名称;以及,如果所述权重值不在预设范围内,则识别所述歧义简称不是企业名称。
结合第二方面的第一种实现方式,在第二方面第二种可能的实现方式中,所述第二识别单元还用于确定所述企业信息中各条子信息对应的信息类型;确定与各个所述信息类型分别对应的子权重值;以及,计算所述企业信息对应的权重值,所述权重值是所述子权重值之和。
结合第二方面及上述可能的实现方式,在第二方面第三种可能的实现方式中,该识别企业名称的装置还包括:
分词器,用于获取待识别文本;将歧义词典中的企业简称以树形结构存储,生成词典树;以及,使用所述词典树识别所述待识别文本中的歧义简称。
结合第二方面及上述可能的实现方式,在第二方面第四种可能的实现方式中,该识别企业名称的装置还包括:
全称识别单元,用于在所述第一获取单元未获取到待识别文本中的歧义简称的情况下,获取待识别文本中的企业全称作为识别出的企业名称,所述企业全称由包括全称词典的分词器从所述待识别文本中切分出,所述全称词典包括至少一个企业全称;和/或,
简称识别单元,用于在所述第一获取单元未获取到待识别文本中的歧义简称的情况下,获取待识别文本中的企业简称作为识别出的企业名称,所述企业简称由包括简称词典的分词器从所述待识别文本中切分出,所述简称词典包括至少一个没有歧义的企业简称。
上述技术方案提供识别企业名称的方法及装置中,首先获取由分词器根据歧义词典切分出的待识别文本中的歧义简称,这里的歧义简称在待识别文本中有可能表示企业名称,也有可能表示其他的含义。然后根据歧义简称从企业信息库中获取与歧义简称匹配企业简称,并获取企业信息库中与该企业简称关联的企业信息。再利用企业信息去识别待识别文本中是否存在该企业信息,如果不存在,则可以确认在待识别文本中该歧义简称不是企业名称,而是表示其他的含义。通过这样的方法,首先获取到可能表示企业名称也可能表示其他含义的歧义简称,然后通过验证识别出在文本中所表示的含义不是企业名称的歧义简称,从而提高计算机识别文本中企业名称的准确率。
附图说明
为了更清楚地说明本申请的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本申请识别企业名称的方法的具体实施方式之一的流程图;
图2为本申请识别企业名称的方法的具体实施方式之一中,分词器切分出歧义简称的其中一种实现方式的流程图;
图3为本申请识别企业名称的方法的具体实施方式之一中s330步骤其中一种实现方式的流程图;
图4为本申请识别企业名称的方法的具体实施方式之二的流程图;
图5为本申请识别企业名称的方法的具体实施方式之三的流程图;
图6为本申请识别企业名称的方法的具体实施方式之四的流程图;
图7为本申请识别企业名称的装置的具体实施方式之一的结构示意图;
图8为本申请识别企业名称的装置的具体实施方式之二的结构示意图。
具体实施方式
下面对本申请的实施例作详细说明。
请参考图1,在本发明的第一个实施例中,提供一种识别企业名称的方法,包括以下步骤:
s100获取待识别文本中的歧义简称,所述歧义简称由包括歧义词典的分词器从所述待识别文本中切分出,所述歧义词典中包括至少一个存在歧义的企业简称;
s200从预设的企业信息库中获取与所述歧义简称匹配的企业简称,以及与所述企业简称关联的企业信息;
s310识别所述待识别文本中是否存在所述企业信息;
如果不存在,则执行s320识别所述歧义简称不是企业名称。
进一步地,该方法还可以包括:
如果待识别文本中存在企业信息,则执行s330计算所述企业信息对应的权重值;
s410判断所述企业信息对应的权重值是否在预设范围内;
如果在预设范围内,则执行s420识别所述歧义简称是企业名称;
如果不在预设范围内,则执行s320识别所述歧义简称不是企业名称。
上述识别企业名称的方法中,首先获取由分词器根据歧义词典切分出的待识别文本中的歧义简称,这里的歧义简称在待识别文本中有可能表示企业名称,也有可能表示其他的含义。然后根据歧义简称从企业信息库中获取与歧义简称匹配企业简称,并获取企业信息库中与该企业简称关联的企业信息。再利用企业信息去识别待识别文本中是否存在该企业信息,如果不存在,则可以确认在待识别文本中该歧义简称不是企业名称,而是表示其他的含义。
通过这样的方法,首先获取到可能表示企业名称也可能表示其他含义的歧义简称,然后通过验证识别出在文本中所表示的含义不是企业名称的歧义简称,从而提高计算机识别文本中企业名称的准确率。
而对于待识别文本中存在企业信息的情况,则可以直接确认在待识别文本中该歧义简称是企业名称,或者可以经过进一步的验证步骤再来识别该歧义简称是或不是企业名称,从而从整体上进一步提高计算机识别文本中企业名称的准确率。
在s100的步骤中,歧义词典作为分词器的其中一个词典,其中包括至少一个存在歧义的企业简称。例如,“连云港港口控股集团有限公司”的企业简称是“连云港”,同时“连云港”又是一个地名,存在超过一种含义,故而将“连云港”作为存在歧义的企业简称,添加到歧义词典中。又例如,“上海新文化传媒集团股份有限公司”的企业简称是“新文化”,同时,“新文化”还是一本杂志期刊的名称,存在超过一种含义,故而将“新文化”添加到歧义词典中。
本申请具体实施方式中的歧义词典,以及后面会涉及的全称词典、简称词典可以通过多种方式来构建。例如,从互联网上的数据中获取企业名称,爬取搜狗词库中的公司机构名称等,再通过crf(conditionalrandomfield,条件随机场)批量训练自动识别未知企业名称,然后把这些企业名称汇总,整理成歧义词典、全程词典和/或简称词典,并通过人工验证,使最终词条数量可以达到百万级别。
待识别文本中的歧义简称可以由外部的分词器切分出来,然后本地直接接收获取切分出的歧义简称,也可以由本地的分词器从待识别文本中切分出来,本申请对此不做限制。
这里的分词器具体可以采用ik分词器(ikanalyzer),现有的ik分词器无法准确地从待识别文本中将企业名称切分出来。通过对ik分词器进行改造,使其具有歧义词典,并利用歧义词典将待识别文本中的存在歧义的企业简称准确地切分出来,也就是切分出歧义简称,用于后续进一步判断歧义简称是不是企业名称的步骤,从而能够准确地识别出待识别文本中的企业名称。
具体地,对现有的ik分词器的改造包括添加歧义词典,以及添加:
第一词典管理模块,用于将分词器中歧义词典中的企业简称加载到内存中;
第一词典片段模块,用于将加载到内存中的企业简称以树形结构存储,生成第一词典树;
歧义简称子分词器,用于使用词典树切分出待识别文本中的歧义简称。
此外,还可以添加第一存储模块,用于存储识别出的歧义简称及相关信息。这里的相关信息可以是指歧义简称的词性等。
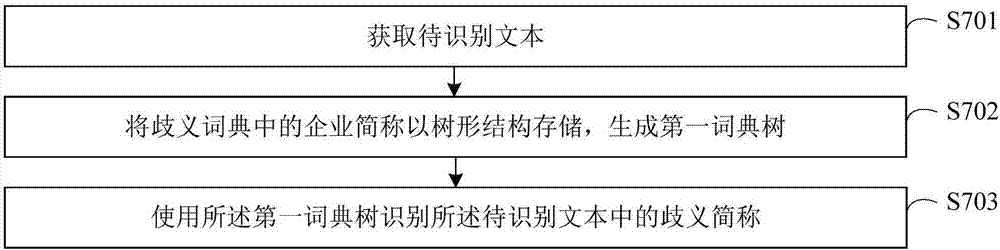
采用改造后的ik分词器从所述待识别文本中切分出歧义简称的步骤,请参考图2,可以包括:
s701获取待识别文本;
s702将歧义词典中的企业简称以树形结构存储,生成第一词典树;
s703使用所述第一词典树切分出所述待识别文本中的歧义简称。
当分词器切分出多个不同的歧义简称时,可以将多个歧义简称先存储起来,然后依次识别其是不是企业名称。
在s200的步骤中,预设的企业信息库包括企业简称,以及与企业简称关联的企业信息,例如股票代码、企业地址、企业法人等,企业信息库中还可以包括与企业简称关联的企业全称。
在s310的步骤中,企业信息可以仅有一个类型,也可以有多个子信息类型。当企业信息具有多个子信息类型时,只要待识别文本中存在至少一条具体的子信息,就认为待识别文本中存在企业信息。只有当所有类型的子信息都不存在时,才认为待识别文本中不存在企业信息。
在s330的步骤中,企业信息可以预设有对应的权重值。请参考图3,在一种实现方式中,计算所述企业信息对应的权重值的步骤,可以包括:
s331确定所述企业信息中各条子信息对应的信息类型;
s332确定与各个所述信息类型分别对应的子权重值;
s333计算所述企业信息对应的权重值,所述权重值是所述子权重值之和。
在s331至s333的步骤中,企业信息中所有的子信息的信息类型都可以预设相应的子权重值,不同的信息类型的子权重值可以相同,也可以不同。例如,企业信息包括股票代码、企业地址、企业法人三个信息类型,其中,股票代码对应的子权重值可以预设为10,企业地址对应的子权重值可以预设为15,企业法人对应的子权重值可以预设为10。如果待识别文本中识别出了股票代码和企业法人两个信息类型,则可以计算企业信息对应的权重值为20。当待识别文本中多次识别出同一个信息类型的子信息时,由于信息类型相同,因此在计算权重值时该信息类型对应的子权重值只会加一次,而不会多次重复相加。
将企业信息中所有的子信息一一与待识别文本进行比对,当待识别文本中存在至少一条子信息时,先确定各条存在的子信息分别对应的信息类型。然后确定与前述各个信息类型对应的子权重值,计算各个子权重值之和作为企业信息对应的权重值。再通过权重值与预设范围的比较,来确定待识别文本中的歧义简称是不是企业名称。通过对多个信息类型的企业信息分别进行识别和计算权重,能够进一步提高识别歧义简称的准确率。
以下通过具体实例来进一步说明本实施例。
在具体实例中,分词器的歧义词典中包括“新文化”、“连云港”这两个词。企业信息库中包括如表一所示的信息:
表1
信息类型与对应的子权重值如表二所示,权重值的预设范围为大于等于10。
表2
以下对于待识别文本1进行企业名称识别。
待识别文本1:
在杭州文博会的开幕首日,头头是道创始合伙人曹国熊、著名财经作家吴晓波、国家博物馆副馆长李六三等多位文化产业界人士齐聚一堂,探讨“新文化消费的流量阵地之争”核心话题。
首先获取待识别文本1中由分词器切分出的歧义简称“新文化”,然后从企业信息库中获取与歧义简称“新文化”匹配的如下信息:
企业简称新文化
企业信息股票代码300336
企业地址上海市虹口区东江湾路aaa号
企业法人杨震华。
将股票代码“300336”与待识别文本1进行比对,以便识别待识别文本1中是否存在“300336”,发现待识别文本1中不存在“300336”。
将企业地址“上海市虹口区东江湾路aaa号”与待识别文本1进行比对,发现待识别文本1中也不存在“上海市虹口区东江湾路aaa号”。
将企业法人“杨震华”与待识别文本1进行比对,发现待识别文本1中也不存在“杨震华”。
所有的企业信息都一一与待识别文本1比对后,结果待识别文本1中不存在与歧义简称“新文化”匹配的企业信息,则识别待识别文本1中的歧义简称“新文化”不是企业名称。
以下对于待识别文本2进行企业名称识别。
待识别文本2:
3月30日,新文化(300336)董事长杨震华在首届中国(上海)上市公司企业社会责任峰会上谈到公司主营业务布局时表示,新文化上市初以电视剧为主,现在增加了产品线,电视剧、电影、综艺栏目、网络剧。杨震华还表示,从整个市场角度看,电影和综艺慢慢已经超过了电视剧的影响力和规模,未来互联网的网络剧也会上升。
首先获取待识别文本2中由分词器切分出的歧义简称“新文化”,然后从企业信息库中获取与歧义简称“新文化”匹配的如下信息:
企业简称新文化
企业信息股票代码300336
企业地址上海市虹口区东江湾路aaa号
企业法人杨震华。
将“300336”与待识别文本2进行比对,发现待识别文本2中存在“300336”。
将“上海市虹口区东江湾路aaa号”与待识别文本2进行比对,发现待识别文本2中不存在“上海市虹口区东江湾路aaa号”。
将“杨震华”与待识别文本2进行比对,发现待识别文本2中存在“杨震华”。
获取到的企业信息中所有子信息都一一与待识别文本2比对后,结果待识别文本2中存在企业信息。故需要计算企业信息对应的权重值。
具体地,待识别文本2中存在子信息“300336”,确定该子信息的信息类别为“股票代码”,对应的子权重值为10。
待识别文本2中存在子信息“杨震华”,确定该子信息的信息类别为“企业法人”,对应的子权重值为10。
待识别文本2中不存在子信息“上海市虹口区东江湾路aaa号”,故而无需考虑该子信息对应的信息类型的子权重值。
则计算得到企业信息的权重值为20,预设范围为大于等于10,因此权重值在预设范围内,故而识别在待识别文本2中的歧义简称“新文化”是企业名称。
在本发明的第二个实施例中,提供一种识别企业名称的方法,请参考图4和图5,包括以下步骤:
s510判断由分词器切分出的待识别文本中的歧义简称是否为空。
如果不为空,说明从待识别文本中切分出了至少一个歧义简称,则
s100获取待识别文本中的歧义简称,所述歧义简称由包括歧义词典的分词器从所述待识别文本中切分出,所述歧义词典中包括至少一个存在歧义的企业简称;
s200从预设的企业信息库中获取与所述歧义简称匹配的企业简称,以及与所述企业简称关联的企业信息;
s310识别所述待识别文本中是否存在所述企业信息;
如果不存在,则执行s320识别所述歧义简称不是企业名称;
如果存在,则执行s330计算所述企业信息对应的权重值;
s410判断所述企业信息对应的权重值是否在预设范围内;
如果在预设范围内,则执行s420识别所述歧义简称是企业名称;
如果不在预设范围内,则执行s320识别所述歧义简称不是企业名称。
如果为空,说明未获取到待识别文本中的歧义简称,则
s520获取待识别文本中的企业全称作为识别出的企业名称,所述企业全称由包括全称词典的分词器从所述待识别文本中切分出,所述全称词典包括至少一个企业全称;或者
s530获取待识别文本中的企业简称作为识别出的企业名称,所述企业简称由包括简称词典的分词器从所述待识别文本中切分出,所述简称词典包括至少一个没有歧义的企业简称。
s510的步骤判断结果如果不为空,则执行s100至s410的步骤,直到识别得到结果,即歧义简称是或不是企业名称。这个过程的步骤可以参考第一个实施例的相关说明,此处不再赘述。
在s520的步骤中,全称词典包括至少一个企业全称,例如“上海新文化传媒集团股份有限公司”、“连云港港口控股集团有限公司”等。
待识别文本中的企业全称由包括全称词典的分词器从待识别文本中切分出来。与第一个实施例中的类似的,这里所说的分词器具体也可以采用ik分词器,现有的ik分词器无法准确地从待识别文本中将企业全称切分出来。通过对ik分词器进行改造,使其具有全称词典,并利用全称词典将待识别文本中的企业全称准确地切分出来,并以此作为识别出的企业名称。
这里,ik分词器可以与第一个实施例中的ik分词器彼此独立的分词器,也可以直接对第一个实施例中的ik分词器进行改造,使ik分词器同时具有全称词典和歧义词典。
具体地,对现有的ik分词器的改造包括添加全称词典,以及添加:
第二词典管理模块,用于将分词器中全称词典中的企业全称加载到内存中;
第二词典片段模块,用于将加载到内存中的企业全称以树形结构存储,生成第二词典树;
企业全称子分词器,用于使用第二词典树切分出待识别文本中的企业全称。
此外,还可以添加第二存储模块,用于存储识别出的企业全称及相关信息。这里的相关信息可以是指企业全称的词性等。
采用改造后的ik分词器从所述待识别文本中切分出企业全称的步骤,可以包括:
获取待识别文本;
将全称词典中的企业全称以树形结构存储,生成第二词典树;
使用所述第二词典树识别所述待识别文本中的企业全称。
具体地,s520的步骤可以包括:
s521判断是否获取到待识别文本中的企业全称;
如果获取到企业全称,则s522以企业全称作为识别出的企业名称。
在s530的步骤中,简称词典包括至少一个没有歧义的企业简称,例如“株洲千金药业”、“乐通股份”等。
待识别文本中的企业简称由包括简称词典的分词器从待识别文本中切分出来。与第一个实施例中的类似的,这里所说的分词器具体也可以采用ik分词器,现有的ik分词器无法准确地从待识别文本中将企业简称切分出来。通过对ik分词器进行改造,使其具有简称词典,并利用简称词典将待识别文本中的企业简称准确地切分出来,并以此作为识别出的企业名称。
这里,ik分词器可以与第一个实施例中的ik分词器彼此独立的分词器,也可以直接对第一个实施例中的ik分词器进行改造,使ik分词器同时具有简称词典和歧义词典。
具体地,对现有的ik分词器的改造包括添加简称词典,以及添加:
第三词典管理模块,用于将分词器中简称词典中的企业简称加载到内存中;
第三词典片段模块,用于将加载到内存中的企业简称以树形结构存储,生成第三词典树;
企业简称子分词器,用于使用第三词典树切分出待识别文本中的企业简称。
此外,还可以添加第三存储模块,用于存储识别出的企业简称及相关信息。这里的相关信息可以是指企业简称的词性等。
采用改造后的ik分词器从所述待识别文本中切分出没有歧义的企业简称的步骤,可以包括:获取待识别文本;
将简称词典中的企业简称以树形结构存储,生成第三词典树;
使用所述第三词典树识别所述待识别文本中的企业简称。
s530的步骤具体可以包括:
s531判断是否获取到待识别文本中的企业简称;
如果获取到企业简称,则s532以企业简称作为识别出的企业名称。
可选地,请参考图6,本实施例中的识别企业名称的方法可以包括s520的步骤和s530的步骤。此时,需要对ik分词器进行改造使其同时具有简称词典和全称词典。可选地,还可以对ik分词器进行改造使其同时具有歧义词典、简称词典和全称词典。具体的改造方式可以参考第一个实施例以及本实施例前述的相关内容,此处不再赘述。现有的ik分词器尽管具有多个自带的词典,例如主词词典、量词词典、停用词词典等,但是对于分词结果中的分词,后续的步骤无法知晓该分词来源于那个词典。而采用本实施例中的方法对ik分词器进行改造,则对于分词结果中的分词,可以知道分词相应地是利用哪个词典所切分出来的,通过对其标注词性,从而可以将分词结果中的歧义简称、企业全称和企业简称区分开来,并利用其执行相应的后续步骤。
识别企业名称的方法包括s520的步骤和s530的步骤的情况,具体可以包括:在本实施例中s510的步骤之后,如果判断切分出的歧义简称为空,则
s521判断是否获取到待识别文本中的企业全称;
如果获取到企业全称,则s522以企业全称作为识别出的企业名称。
如果未获取到企业全称,则s531判断是否获取到待识别文本中的企业简称。
如果获取到企业简称,则s532以企业简称作为识别出的企业名称。
如果未获取到企业简称,则结束,说明该待识别文本中没有企业名称。
发明人采用该方法对3000篇新闻文献进行识别,发现识别文本中的企业名称的准确率可以达到95%以上。
以下通过具体实例来进一步说明本实施例。
在具体实例中,分词器的歧义词典中包括“连云港”。全称词典包括“连云港港口控股集团有限公司”。简称词典包括“乐通股份”。
企业信息库中包括如表三所示的信息:
表3
信息类型与对应的子权重值如表四所示,权重值的预设范围为大于等于15。
表4
以下对于待识别文本3进行企业名称识别。
待识别文本3:
过去10年,作为中国沿海开放港口之一,连云港也受益于金砖国家机制,获得了开放发展新机遇。连云港同金砖国家合作起始于港口物流合作。作为世界新兴经济体,金砖国家同连云港合作最初是以港口物流合作为基础。随着这种合作深入,连云港进一步彰显了开放优势,为未来连云港申报自贸港区提供更多的筹码。
首先判断分词器从待识别文本3中切分出的歧义简称是否为空。结果不为空,然后获取待识别文本3中由分词器切分出的歧义简称“连云港”,然后从企业信息库中获取与歧义简称“连云港”匹配的如下信息:
企业简称连云港
企业信息股票代码601008
企业地址连云港市连云区中华西路bb号
企业法人丁锐
业务或产品名称港口物流。
将股票代码“601008”与待识别文本3进行比对,发现待识别文本3中不存在“601008”。
将企业地址“连云港市连云区中华西路bb号”与待识别文本3进行比对,发现待识别文本3中不存在“连云港市连云区中华西路bb号”。
将企业法人“丁锐”与待识别文本3进行比对,发现待识别文本3中不存在“丁锐”。
将业务或产品名称“港口物流”与待识别文本3进行比对,发现待识别文本3中存在“丁锐”。
获取到的企业信息中所有子信息都一一与待识别文本3比对后,结果待识别文本3中存在企业信息。故需要计算企业信息对应的权重值。待识别文本3中只存在子信息“港口物流”,确定该子信息的信息类别为“业务或产品名称”,对应的子权重值为5。因此计算得到企业信息的权重值为5,预设范围为大于等于10,因此权重值不在预设范围内,故而识别在待识别文本3中的歧义简称“连云港”不是企业名称。
以下对于待识别文本4进行企业名称识别。
待识别文本4:
8月28日,乐通股份发布的中报显示,上半年公司实现营收2.48亿元,同比下滑7.59%;营业利润为207.0万元,同比减少89.2%。公司解释称,这主要是因为油墨行业竞争激烈,公司原材料价格上涨,导致营业成本增加。
首先判断分词器从待识别文本4中切分出的歧义简称是否为空。结果为空,判断是否获取到待识别文本4中的企业全称。结果未获取到企业全称,判断是否获取到待识别文本4中的企业简称。结果获取到企业简称“乐通股份”,则以“乐通股份”作为从待识别文本4中识别出的企业名称。
请参考图7和图8,在本发明的第三个实施例中,提供一种识别企业名称的装置,包括:
第一获取单元1,用于获取待识别文本中的歧义简称,所述歧义简称由包括歧义词典的分词器7从所述待识别文本中切分出,所述歧义词典中包括至少一个存在歧义的企业简称;
第二获取单元2,用于从预设的企业信息库8中获取与所述歧义简称匹配的企业简称,以及与所述企业简称关联的企业信息;
第一识别单元3,用于识别待识别文本中是否存在所述企业信息;
第二识别单元4,用于在所述待识别文本中不存在所述企业信息的情况下,识别所述歧义简称不是企业名称。
该识别企业名称的装置为前述识别企业名称的方法一一对应的装置,其有益效果与前述方法类似,此处不再赘述。
可选地,所述第二识别单元4还用于在所述待识别文本中存在所述企业信息的情况下,计算所述企业信息对应的权重值;如果所述权重值在预设范围内,则识别所述歧义简称是企业名称;以及,如果所述权重值不在预设范围内,则识别所述歧义简称不是企业名称。
可选地,所述第二识别单元4还用于确定所述企业信息中各条子信息对应的信息类型;确定与各个所述信息类型分别对应的子权重值;以及,计算所述企业信息对应的权重值,所述权重值是所述子权重值之和。
可选地,该识别企业名称的装置还包括:
分词器7,用于获取待识别文本;将歧义词典中的企业简称以树形结构存储,生成词典树;以及,使用所述词典树识别所述待识别文本中的歧义简称。
请参考图8,可选地,该是识别企业名称的装置还包括:
全称识别单元5,用于在所述第一获取单元未获取到待识别文本中的歧义简称的情况下,获取待识别文本中的企业全称作为识别出的企业名称,所述企业全称由包括全称词典的分词器从所述待识别文本中切分出,所述全称词典包括至少一个企业全称;和/或,
简称识别单元6,用于在所述第一获取单元未获取到待识别文本中的歧义简称的情况下,获取待识别文本中的企业简称作为识别出的企业名称,所述企业简称由包括简称词典的分词器从所述待识别文本中切分出,所述简称词典包括至少一个没有歧义的企业简称。
本说明书中各个实施例之间相同相似的部分互相参见即可。以上所述的本发明实施方式并不构成对本发明保护范围的限定。
- 还没有人留言评论。精彩留言会获得点赞!