一种自由定制的中文预处理方法及其系统与流程
本发明属于自然语言处理
技术领域:
,具体涉及一种自由定制的中文预处理方法及其系统。
背景技术:
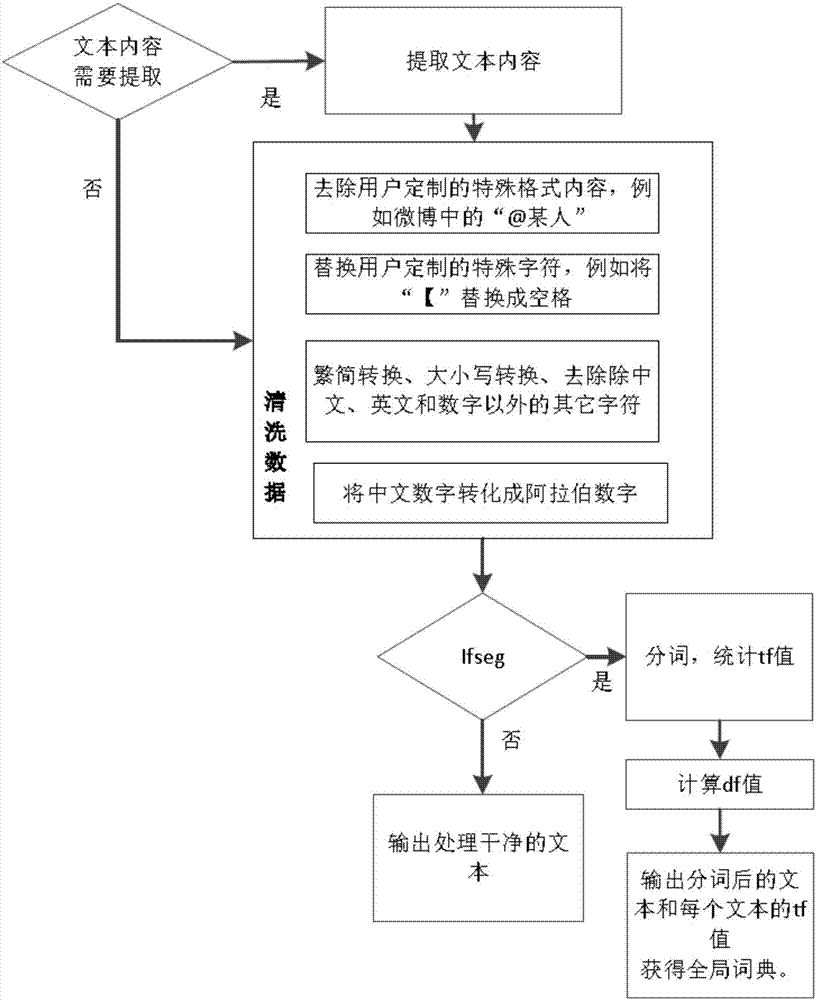
:随着自然语言处理技术在现实生活中得到越来越广泛的应用,如词性标注、句法分析、文本分类、情感分析、客服机器人等,我们需要使用更多的语料并从中进行学习。文本预处理作为自然语言处理的第一步,是后续处理的基础,至关重要。如果语料处理不当,例如有大量噪声、分词错误等,会严重影响后面的词性标注等操作,以及模型的训练。目前,在英文预处理上,有nltk以及stanford工具包。但是,在中文预处理上,并没有一个可用的工具。另外,不同来源的中文元数据有各自的特殊字符,在提取和清理方式上大相径庭,通常要编写不同的程序来处理,耗费人力,处理速度慢,不方便使用。因此,一个可自由配置的中文预处理工具的需求巨大。如今是信息时代,网络和社交媒体上有着丰富的语料资源。为了更好地利用这些语料数据进行后续自然语言的相关研究,如文本分类、问答、对话、机器阅读以及实体抽取等,我们需要对不同来源、不同形式的文本数据进行预处理,得到干净的语料。通常我们每次对不同的语料都编写不同的预处理程序,可重复利用率低,无法找到开源的或者可用的中文预处理工具包。技术实现要素:本发明的目的在于,为解决现有的中文预处理方法存在上述问题,本发明提供了一种自由定制的中文预处理方法,语料指大规模的语言实例,也就是现实生活中的文本。通常我们把一个文本集合称为语料库。该方法可处理来源于微博、网络新闻元数据、维基百科以及其他来源的语料。该方法只需要在配置文件中修改对应参数,无需更改程序,记为可将输入文件进行清洗数据、分词、移除停用词等相应处理。另外,为了更快速地处理大语料,该方法支持多进程,无论是单文件还是多文件输入。经过检验,该方法能达到期望的结果。为了实现上述目的,本发明提供了一种自由定制的中文预处理方法。在该方法中,对涉及到相关的技术术语进行逐一解释,具体内容如下:文档:一个文档为一个文本内容,是计算词频(tf)和文档频率(df)时的单位。一个文本文件可以是一个文档,也可以包含多个文档。在本方法中,每个文件一个文档还是一行一个文档,由documentunit参数决定。词频tf:由公式(1)计算得到,与当前所在文档有关,同一个词在不同文档中的tf值不同。文档频率df:由公式(2)计算得到,与整个语料有关,每个词的df值是全局的。阈值:又叫临界值,超过或低于这个值会进行某些处理或产生效应。在本方法中tf阈值,dftheshold阈值和tfidf阈值均为设定的参数。进程:计算机中的程序关于某数据集合上的一次运行活动,是方法进行资源分配和调度的基本单位。进程与进程之间相互独立。本发明提供了一种自由定制的中文预处理方法,具体步骤如下:步骤1)从配置文件中读取由若干参数组成的参数列表并记录;步骤2)根据参数列表中的inputform,判断输入是否为一个文件夹,其中,默认所述文件夹包括多个文件,每个所述文件包括一个或多个文档。若输入为文件夹,则开辟进程池,进程数目为设定的参数threads,后续进行多进程操作,读取所述文件夹中的所述每个文件,对每个文件进行处理,生成词典,然后合并词典;若输入不是一个文件夹,而是单个文件,再判断进程数threads是否大于1,如果进程数threads大于1,则将该单个文件分割成threads个子文件,然后开辟进程池,进程数目为设定的参数threads,后续进行多进程操作,读取并处理所述每个子文件,生成词典,然后合并词典;如果进程数等于1,则进行单进程操作,读取并处理单个文件,生成词典;步骤3)根据步骤2)处理得到的词典,进一步生成一个全局词典,保存在outputdir文件夹下的df文件夹中;对步骤2)输入的每一个文件(无论是文件夹中的还是分割单文件得到的子文件),生成分词后的结果和带词频的结果,并分别保存在用户指定的outputdir文件夹下的seg文件夹、tf文件夹;步骤4)根据df文件夹中的全局词典和参数列表中的dftheshold阈值,计算全局的停用词,再结合用户指定的停用词典userstopwords,生成一个全局停用词词典,并将其保存在outputdir文件夹下的df文件夹中。对于步骤3)中的tf文件夹中的每一个文件,进行滤除停用词;计算tfidf值,再根据tfidf阈值,再计算每个文档的停用词,得到当前文档特有的停用词词典,当前文档特有的停用词词典则只存储在程序中;根据停用词词典,判断每个所述文件或子文件中的每个词是否在停用词词典中,若该词在停用词词典中,则滤除该词,若该停用词不在停用词词典中,则将该词保留。将滤除后的文件或子文件保存到outputdir文件夹下的remove_words文件夹中,每个文档特有的停用词词典在下一个文档进行停用词滤除前将被更新,程序结束后文档特有的停用词词典即被删除;步骤5)判断步骤2)的输入是否为单文件且多进程;如果步骤2)的输入为单个文件且多进程,将remove_words文件夹中被分割的处理后的多个子文件进行合并,得到一个大文件,并且将所述多个子文件删除;否则,再继续判断是否为文件夹;如果是文件夹,则程序结束;如果是单进程,则程序结束。其中,所述停用词词典包括:全局停用词词典和当前文档特有的停用词词典。所述配置文件采用yaml的格式,所述参数有数值和类型警报机制。步骤1)中,所述参数列表包括:要删除的字符,记为delete,采用列表的数据结构存储;要替换的字符,记为punchdic,采用字典数据结构存储;需要提取内容的标签,extractbetween,采用字典数据结构存储;文档单元,表示每行一个文档还是整个文件一个文档,记为documentunit;是否去除第一行,记为deletefirstline;是否转换成简体中文,记为if2simplified;是否分词,记为ifseg;分词粒度,记为seglevel;用于分词的自定义词典,记为userdic;词频-逆文档频率阈值,记为tfidfthreshold;文档频率阈值,记为dfthreshold;进程数,记为threads;是否删除出现一次的词,记为deletesingle;输入形式,记为inputform;语料路径,记为corpuspath;用户已经处理好的文件夹,记为userprocessdir;用户自定义停用词文件,记为userstopwords;输出文件夹,记为outputdir。步骤2)中进行多进程操作的具体步骤如下:如果输入是一个文件夹,则获取所述文件夹中的所有文档的路径,并将其放入到进程共享的列表中,每个进程从中取出一个路径,删除列表中该路径,然后读取文档并进行相应的文本处理,直到该路径列表为空,返回各个线程的词典和总文档数。然后合并词典和文档数;如果输入为单个文件,且进程数大于1,则将所述单个文件均匀分割成threads个子文件,每个子文件的字节数相同,每个进程处理一个子文件,最后合并词典和文档数。如果进程数为1,就直接处理并返回词典和文档数。步骤2)中处理所述文件夹中的所述每个文件处理的具体步骤为:a)判断所述文件中的文本内容是否要进行提取,若需要提取所述文本内容,则提取文本内容中extractbetween之间的文字,去除delete中的字符,替换punchdic中的字符,然后进行清洗数据;b)判断参数ifseg是否为真;如果ifseg参数为真,则进行分词,采用seglevel参数作为分词粒度,若为1,则获取所有的分词结果;若为0,则进行精确分词;根据公式(1),计算所述文件夹中的每个文档中的每个词的词频tf,输出分词后的文档和每个文档的tf值。公式如下:其中,tfi,j为词ti在文档dj中的词频。ni,j表示词ti在文档dj中出现的次数,nk,j为任一词tk在同一文档dj中出现的次数;根据公式(2),统计语料中的每个词的文档频率值df,其中,|{j:ti∈dj}|为包含词ti的文档数目,|d|为语料中总文档数;获得全局的df词典,并生成词典;如果参数ifseg为假,则直接输出经过步骤a)处理后的干净的文本内容。所述清洗数据的具体内容包括:繁简转换、英文大小写转换、去除除中文、英文和数字以外的其他字符和将中文数字转阿拉伯数字;步骤4)中,所述全局停用词词典,设立了三个规则来增加全局停用词词典,所述三个规则在整个停用词词典的构建过程中只判断一次,所述三个规则包括:第一规则,是否导入用户自定义停用词词典,对应的是参数列表中的userstopwords。若为真,则将用户设定的userstopwords也加入停用词词典;若为假,则不扩充停用词词典;第二规则,是否删除df值为1的词,对应的是参数列表中的deletesingle。若为真,则将df值为1的词加入到停用词词典;若为假,则不扩充停用词词典;第三规则,df阈值是否大于0,对应的是参数列表中的dfthreshold。若为真,则将词典中的所有词按照df值降序排列,若某个词在df词典中排在df阈值之前,则将该词加入到停用词词典中,例如df阈值为1.5,则将df词典中排在前1.5%的词加入到停用词词典;若为假,则不扩充停用词词典;依次判断上述三个规则,若所述第一规则、所述第二规则、所述第三规则的判断均为真,则根据所述三个规则扩充停用词词典,生成一个全局的停用词词典;若所述第一规则判断为假,则判断所述第二规则,若所述第二规则判断为假,则判断所述第三规则,若所述第三规则判断为假,则结束,且全局词典为空。步骤4)中,在所述当前文档特有的停用词词典中,若tfidf的阈值大于0,则需要根据每一个文档中每一个词的tfidf值生成当前文档特有的停用词词典。根据每个词的词频tf和文档频率df,依据公示(3),计算每个词的tfidf值,将当前文档的停用词按照tfidf值升序排列,若某个词排在tfidf阈值之前,则将该词放入当前文档特有的停用词词典中。其中,tfidfi,j为词ti在文档dj中的词频-逆文档频率;tfi,j为上面计算所得词ti在文档dj中的词频,dfi为上面计算得到的词ti的文档频率。对于文档中的每个词,若该词在全局停用词词典或文档特有的停用词词典中,则所述该词被滤除,每个滤除停用词后的文档都保存在outputdir下的remove_word文件夹中。每个文件一个文档还是一行一个文档,由documentunit参数决定。步骤1)中的配置文件中的参数和需要处理的特殊字符,均可由用户根据实际情况来自由配置,不需要进行程序上的更改,自由配置是本发明的方法本身的特性,基本上所有的应用场景和需求都可以通过对参数值的设定,来完成预处理。所述步骤1)中的配置文件,通过用户自由设定,可以决定是否要进行多进程的预处理,并且本方法通过步骤2)多进程的操作和判断,可以进一步加快处理速度。本发明还提供了一种中文预处理系统,包括存储器、处理器和存储在存储器上的并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述方法的步骤。本发明的优点在于:1.可自由配置,无需更改程序2.速度快,多进程。3.语料清理干净,可自定义去除的字符和替换的格式,且不限个数。4.参数多样可调节,参数多达19个。去除停用词的df阈值、tfidf阈值等均可根据需要进行调节。附图说明图1是本发明的一种自由定制的中文预处理方法的流程图,图2是图1的一种自由定制的中文预处理方法中的处理文件的流程图,图3是图1的一种自由定制的中文预处理方法中的生成停用词词典和移除停用词的流程图。具体实施方式如图1所示,本发明提供了一种自由定制的中文预处理方法,具体步骤如下:步骤1)从配置文件中读取由若干参数组成的参数列表并记录;步骤2)根据参数列表中的inputform,判断输入是否为一个文件夹,其中,默认所述文件夹包括多个文件,每个所述文件包括一个或多个文档。若输入为文件夹,则开辟进程池,进程数目为设定的参数threads,后续进行多进程操作,读取所述文件夹中的所述每个文件,对每个文件进行处理,生成词典,然后合并词典;若输入不是一个文件夹,而是单个文件,再判断进程数threads是否大于1,如果进程数threads大于1,则将该单个文件分割成threads个子文件,然后开辟进程池,进程数目为设定的参数threads,后续进行多进程操作,读取并处理所述每个子文件,生成词典,然后合并词典;如果进程数等于1,则进行单进程操作,读取并处理单个文件,生成词典;步骤3)根据步骤2)处理得到的词典,进一步生成一个全局词典,保存在outputdir文件夹下的df文件夹中;对步骤2)输入的每一个文件(无论是文件夹中的还是分割单文件得到的子文件),生成分词后的结果和带词频的结果,并分别保存在用户指定的outputdir文件夹下的seg文件夹、tf文件夹;步骤4)根据df文件夹中的全局词典和参数列表中的dftheshold阈值,计算全局的停用词,再结合用户指定的停用词典userstopwords,生成一个全局停用词词典,并将其保存在outputdir文件夹下的df文件夹中。对于步骤3)中的tf文件夹中的每一个文件,进行滤除停用词;计算tfidf值,再根据tfidf阈值,再计算每个文档的停用词,得到当前文档特有的停用词词典,当前文档特有的停用词词典则只存储在程序中;根据停用词词典,判断每个所述文件或子文件中的每个词是否在停用词词典中,若该词在停用词词典中,则滤除该词,若该停用词不在停用词词典中,则将该词保留。将滤除后的文件或子文件保存到outputdir文件夹下的remove_words文件夹中,每个文档特有的停用词词典在下一个文档进行停用词滤除前将被更新,程序结束时被删除;步骤5)步骤5)判断步骤2)的输入是否为单文件且多进程;如果步骤2)的输入为单个文件且多进程,将remove_words文件夹中被分割的处理后的多个子文件进行合并,得到一个大文件,并且将所述多个子文件删除;否则,再继续判断是否为文件夹;如果是文件夹,则程序结束;如果是单进程,则程序结束。。其中,所述停用词词典包括:全局停用词词典和当前文档特有的停用词词典。所述配置文件采用yaml的格式,所述参数有数值和类型警报机制。步骤1)中,所述参数列表包括:要删除的字符,记为delete,采用列表的数据结构存储;要替换的字符,记为punchdic,采用字典数据结构存储;需要提取内容的标签,extractbetween,采用字典数据结构存储;文档单元,表示每行一个文档还是整个文件一个文档,记为documentunit;是否去除第一行,记为deletefirstline;是否转换成简体中文,记为if2simplified;是否分词,记为ifseg;分词粒度,记为seglevel;用于分词的自定义词典,记为userdic;词频-逆文档频率阈值,记为tfidfthreshold;文档频率阈值,记为dfthreshold;进程数,记为threads;是否删除出现一次的词,记为deletesingle;输入形式,记为inputform;语料路径,记为corpuspath;用户已经处理好的文件夹,记为userprocessdir;用户自定义停用词文件,记为userstopwords;输出文件夹,记为outputdir。步骤2)中进行多进程操作的具体步骤如下:如果输入是一个文件夹,则获取所述文件夹中的所有文档的路径,并将其放入到进程共享的列表中,每个进程从中取出一个路径,删除列表中该路径,然后读取文档并进行相应的文本处理,直到该路径列表为空,返回各个线程的词典和总文档数。然后合并词典和文档数;如果输入为单个文件,且进程数大于1,则将所述单个文件均匀分割成threads个子文件,每个子文件的字节数相同,每个进程处理一个子文件,最后合并词典和文档数。如果进程数为1,就直接处理并返回词典和文档数。如图2所示,步骤2)中处理所述文件夹中的所述每个文件处理的具体步骤为:a)判断所述文件中的文本内容是否要进行提取,若需要提取所述文本内容,则提取文本内容中extractbetween之间的文字,去除delete中的字符,替换punchdic中的字符,然后进行清洗数据;b)判断参数ifseg是否为真;如果ifseg参数为真,则进行分词,采用seglevel参数作为分词粒度,若为1,则获取所有的分词结果;若为0,则进行精确分词;根据公式(1),计算所述文件夹中的每个文档中的每个词的词频tf,输出分词后的文档和每个文档的tf值。公式如下:其中,tfi,j为词ti在文档dj中的词频。ni,j表示词ti在文档dj中出现的次数,nk,j为任一词tk在同一文档dj中出现的次数;根据公式(2),统计语料中的每个词的文档频率值df,其中,|{j:ti∈dj}|为包含词ti的文档数目,|d|为语料中总文档数;获得全局的df词典,并生成词典;如果参数ifseg为假,则直接输出经过步骤a)处理后的干净的文本内容。所述清洗数据的具体内容包括:繁简转换、英文大小写转换、去除除中文、英文和数字以外的其他字符和将中文数字转阿拉伯数字。这些步骤涵盖了几乎所有的可能的处理情况,可以将语料清洗干净并将字符规范化,以方便后续操作。其中提取所需文本、删除指定字符、对指定字符进行替换均由用户通过配置文件指定,以满足用户的不同需求。这些特征保证了语料清理的效果。如图3所示,步骤4)中,所述全局停用词词典,设立了三个规则来增加全局停用词词典,所述三个规则在整个停用词词典的构建过程中只判断一次,所述三个规则包括:第一规则,是否导入用户自定义停用词词典,对应的是参数列表中的userstopwords。若为真,则将用户设定的userstopwords也加入停用词词典;若为假,则不扩充停用词词典;第二规则,是否删除df值为1的词,对应的是参数列表中的deletesingle。若为真,则将df值为1的词加入到停用词词典;若为假,则不扩充停用词词典;第三规则,df阈值是否大于0,对应的是参数列表中的dfthreshold。若为真,则将词典中的所有词按照df值降序排列,若某个词在df词典中排在df阈值之前,则将该词加入到停用词词典中,例如df阈值为1.5,则将df词典中排在前1.5%的词加入到停用词词典;若为假,则不扩充停用词词典;依次判断上述三个规则,若所述第一规则、所述第二规则、所述第三规则的判断均为真,则根据所述三个规则扩充停用词词典,生成一个全局的停用词词典;若所述第一规则判断为假,则判断所述第二规则,若所述第二规则判断为假,则判断所述第三规则,若所述第三规则判断为假,则结束,且全局词典为空。如图3所示,步骤4)中,在所述当前文档特有的停用词词典中,若tfidf的阈值大于0,则需要根据每一个文档中每一个词的tfidf值生成当前文档特有的停用词词典。根据每个词的词频tf和文档频率df,依据公示(3),计算每个词的tfidf值,将当前文档的停用词按照tfidf值升序排列,若某个词排在tfidf阈值之前,则将该词放入当前文档特有的停用词词典中。其中,tfidfi,j为词ti在文档dj中的词频-逆文档频率;tfi,j为上面计算所得词ti在文档dj中的词频,dfi为上面计算得到的词ti的文档频率。对于文档中的每个词,若该词在全局停用词词典或文档特有的停用词词典中,则所述该词被滤除,每个滤除停用词后的文档都保存在outputdir下的remove_word文件夹中。每个文件一个文档还是一行一个文档,由documentunit参数决定。其中,根据配置文件得到的参数,进行文本预处理。1.文本预处理在清理文本数据时,可以根据需要提取文本内容,例如下面这种新闻语料结构:<doc><url>http://auto.sina.com.cn/photo1/08wmlxc4xct/250228.shtml</url><docno>bdb300e1e392c845-e3207783d4cca6e0</docno><contenttitle>东风雪铁龙世嘉发布现场图</contenttitle><content>在酝酿了多时之后,东风雪铁龙终于决定把c4引进国内市场。对于钟情于法国两厢车的消费者来说,漂亮的外观,法式的独到设计,优秀的底盘调校,都有着不小的吸引力。图为东风雪铁龙世嘉发布现场图。</content></doc><doc>提取其中的文本内容:在酝酿了多时之后,东风雪铁龙终于决定把c4引进国内市场。对于钟情于法国两厢车的消费者来说,漂亮的外观,法式的独到设计,优秀的底盘调校,都有着不小的吸引力。图为东风雪铁龙世嘉发布现场图。通过提取文本,直接获得有用信息。2.可以将文本中的繁体字转换成简体字,中文的数字转换成阿拉伯数字,例如文本中有这种:一零零八六,可以转换成10086,这种转换一方面更加方便分词(阿拉伯数字在分词时不会被切开),另一方面更加便于语义的表达。3.将一些符号替换掉,例如在微博语料中会用“//”来表示转发,将“//”替换成“\n”,即将转发内容当做两条内容进行处理。例:支持王xx,马xx不要脸//@:小朋友这次王xx真是跌了大跟头啊!。经过处理后,变成两条语料,分别是:支持王xx,马xx不要脸;@:小朋友这次王xx真是跌了大跟头啊!这种处理是根据语料本身的特性定制的,以微博语料为例,当分析大家对某一事件的态度时,转发这种特征并不重要,而分成多条语料之后增加了更多人对事件的看法语料。4.将某些语料中的特殊表达去掉,仍以上面的微博语料为例,第二句语料:“@:小朋友这次王xx真是跌了大跟头啊!”,前面的@:小朋友这种表示方式是微博中特有的提醒某人关注的表达方式,但对分析语料是没有帮助的,并且会给分词造成一定的困扰,因此在处理时,@:小朋友这种格式也是可以选择性去除的。5.去除文本中一些不可识别的字符和乱码。如果不分词的话,可以直接输出经过上述清洗步骤,如果分词的话,分词粒度(即将一个语料切多碎,例如我爱家乡蓝天,可以切成:“我/爱/家乡/蓝天”,也可以切成:“我/爱/家乡蓝天”)可以选择。另外,如果没有分词这个步骤,就不会生成停用词,生成停用词的步骤时在分词的前提下进行的。对于每一个文本分词之后,每一个词都会统计词频,这里有两个词频,一个是每一条语料中每个词的词频,例如分词后的语料:“我/爱/家乡/蓝天,北京/是/我们/的/首都”,这里北京的词频就是tf值,为2。而统计所有某一类别的文件,例如“国庆阅兵”这一话题的微博语料,其中假设有1000条微博提到了北京这个词,则这个类别的文件中北京的df值就是1000。停用词词典有哪些部分组成是可以通过配置文件配置的,其中有固有的停用词词典,这是在网上可得的词典。根据df值生成的词典,这个词典考量的就是一个词对文档的贡献率,例如“的”这个字在没有篇文档中都出现,那么它的df值就会很高,我们设定合适的df阈值就可以将它加入到停用词词典中去。另外,根据tf-idf值生成的词典以及是否删除只出现一次的词,也可以将这些冗余的词加入停用词词典。生成停用词词典之后,将语料中含有的停用词去掉,例如“的”。去除停用词一方面可以增加之后利用语料进行分析的速度,另一方面去掉了冗余信息使对语料的分析更加精确。本发明的配置方式可处理干净绝大多数的语料,并且速度相当快。在4核cpu,8g内存机器上,从sogouca新闻语料中的提取内容的运行速度如下:(共一个文件,3996条新闻,处理前大小为9.1m)单进程(所有处理)4进程(所有处理)单文件15.656s6.483s在32核cpu,16g内存机器上,从新闻文件夹中提取内容并处理的运行速度如下:(共375个文件,处理前大小为3.0g)单进程(所有处理)20进程(所有处理)多文件8284.162s625.373s选取了一个客服对话文本处理前处理后的效果对比:处理前:1你好高兴您服务2喂你好2嗯,我家的宽带,昨天晚上,就掉线了2这这边是我这边什么都收不到,电视也看不到,无线网也不能用1请问您的宽带账号是本手机吗2嗯,对,是这个本2就这个本手机吗1后有没有提示错误代码2这个好像他说什么,2我网络,网络不能用,什么的1嗯,那请问一下,家里面使用的有没有光猫还有路由器2那都有啊1您看一下光猫上的指示灯有没有亮红灯2他那个光猫上好像,好像他他启动了以后,我看就没有没有红灯,全是全是绿灯啊1是三盏灯吗2他就是全是绿的,我没有看到他亮的,亮的有红灯啊1您看一下是不是亮了三盏灯2啊,我我我看一下啊1好的2他他就是就是那个,那个上面你说红灯,我没我没看到有,红灯啊1您看1几盏灯好吗2嗯,我给你看一下啊2嗯,是2一盏两盏三盏2盏灯吗2四盏灯1是不灯长亮的2嗯,长亮的1家里面使用的有没有路由器2有1您看一下路由器上有一个sys的指示灯,有没有闪烁2他这个好像好像是亮着了,没闪1这个指示灯代表路由器的工作状态,正常情况下,应该闪烁的1如果现在长亮的话,可能是路由器有问题1请问您刚才有没有把路由器还有光猫重启试过2这个这个没有1那您稍候先把光猫还有路由器关了,过五到十分钟重新再启动1看看能不能正常的使用1如果那个指示灯还是不闪烁的话,那建议您换一个路由器1可能是路由器坏了2嗯2嗯,好的,好的,好的谢谢啊1不客气,还有什么需要补充的吗2嗯2接,就是这个,电视,他,他是2嗯,我我我现在看看我可,你说我这那个路由器有问题呀,我先看一下1好2如果不行的话我再我再打电话吧1嗯1好的2嗯,好好1感谢您来电再见2嗯,再见使用的参数:delete:#reexpressions,要删除的字符列表,用正则表达式表示,每一行是一种,理论上可以无限多种-'e:.*'-'(/.*?pcm)'#punchdic:要替换的字符,本例没有使用documentunit:0#文档单元是一个文件一个文档deletefirstline:false#是否删除第一行,本例为否if2simplified:true#是否繁简转换,本例为是ifseg:true#是否分词,本例是seglevel:0#1meanscut_all=true,0meansfalse#分词粒度为精确切分tfidfthreshold:0.0#文档停用词的tfidf阈值dfthreshold:0.5#全局停用词的df阈值,本例为0.5,表示df值排序前0.5%的词加入到停用词词典threads:10#multithreads多进程数目为10deletesingle:false#是否删除只出现一次的词,否inputform:dir#输入的是文件夹还是文件,本例为文件夹处理后的结果:12喂你好2我家宽带昨天晚上掉线2这这边这边什么都收不到电视也看不到无线网也不能用1请问宽带账号本手机2本2本手机1后有没有提示错误代码2好像他说什么2网络网络不能用什么1请问家里面使用有没有光猫路由器2都1看光猫上指示灯有没有亮红灯2他光猫上好像好像他他启动以后看红灯全是全是绿灯1三盏灯2他就是全是绿看到他亮亮红灯1看是不是亮三盏灯2看12他他就是就是上面你说红灯没没看到红灯1看1几盏灯好2给你看22一盏两盏三盏2盏灯2四盏灯1不灯长亮2长亮1家里面使用有没有路由器21看路由器上一个sys指示灯有没有闪烁2他好像好像亮着没闪1指示灯代表路由器工作状态正常情况下应该闪烁1如果现在长亮的话可能路由器问题1请问刚才有没有把路由器光猫重启试过21稍候先把光猫路由器关过五到十分钟重新再启动1看看能不能正常使用1如果指示灯还是闪烁的话建议您换一个路由器1可能路由器坏22谢谢1客气什么需要补充22接就是电视他他2现在看看可你说这路由器问题呀先看12如果不行的话再再打电话112好好1感谢您来电采用本方法后,肉眼可见的文本内容变少了,这必将会提高分析文本的速度。另外,根据设置的参数,文档进行了分词,文本将一些例如“嗯”、“好的”之类没有什么实际意义的词去掉,减少了文本的冗余信息,标点符号被去掉,英文大写转成小写。基本上每句话只剩下了关键词。并且从上面的结果看,分词的效果也不错,分词效果好有利于之后对文本进行向量表示。最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1