一种基于大数据的时空混淆暴露度评估系统及方法与流程
本发明涉及一种基于海量大数据的时空混淆暴露度评估系统及方法,属于环境健康技术领域。
背景技术:
当前环境污染物的监测数据稀疏,早期数据缺乏。而现有的计算模型预测的时空分辨率极为有限,难以达到精细化的污染物估计。以空气污染物pm2.5为例,近年来,空气污染问题日益突出,空气污染物对人类健康的影响引起公众高度的关注。空气污染物中对人类健康危害最大的是pm2.5。目前国内外对空气污染的研究也都是以pm2.5为重点的,但是其受多种环境因素和人为因素所影响,以及受限于监测数据的时间尺度和空间尺度,使得对pm2.5浓度的预测存在一定的不确定性,很难进行高效准确的预测。而由于国内相关研究刚起步不久,对于中国广大地区而言监测数据稀疏,进而影响公共健康效应的评估准确度,因此急求一种能高效精确低误差的预测方法,从而用以公共健康研究,来保障公众的生命安全。
总之已有的环境暴露度如pm2.5估算方法,主要缺点是采用辅助数据有限,缺乏大数据的支撑;采用的模型算法缺乏空间相关性的考虑,也限制了这些方法的进一步应用。
技术实现要素:
本发明技术解决问题:克服现有技术的不足,提供一种基于大数据的时空混淆暴露度评估系统及方法,挖掘海量的时空数据,采用累加的非线性方法建立多个影响因素同污染物浓度之间的关系,通过残差变异函数拟合考虑了空间自相关性,极大提高了预测的精度及效果。本发明技术解决方案:一种基于大数据的时空混淆暴露度评估系统,包括:时空数据挖掘模块、多源异构数据融合模块、最终变量选择模块、时空广义相加模型构建模块、重采样模型模块、变异函数时空建模模块和浓度估算模块;其中:
时空数据挖掘模块:负责获取遥感卫星影像数据、pm2.5监测数据、交通路网数据、点污染源数据;遥感卫星影像数据是通过r统计软件和python编程语言实现高效的自动化算法提取而得来,pm2.5监测数据和交通路网数据通过在线数据挖掘得到,点污染源数据基于百度的api高效实现从中提取点源污染信息;最后得到多源异构数据,然后送至多源异构数据融合模块;
多源异构数据融合模块:根据时空数据挖掘模块得到的多源异构数据,实现多源异构数据的融合;基于shell脚本语言、sql语言、r语言,利用自动化的多源异构的数据融合算法,最后得到融合的多源异构数据,然后送至最终变量选择模块;
最终变量选择模块:根据多源异构数据融合模块得到的融合的多源异构数据,确定预测模型输入的最终预测自变量;在筛选自变量时,首先计算方差膨胀因子来避免多重共线性,然后通过向后逐步选择法,直到模型的aic不再变化,选择其中aic最小的预测模型中的变量作为预测模型的最终输入变量;最终得到最终输入变量,然后送至时空广义相加模型模块;
时空广义相加模型构建模块:根据最终变量选择模块得到的最终输入变量,设计包括区域时间基函数在内的混合时空的非线性时空广义相加模型;使用无参数的广义相加模型对非线性因子进行建模,同时将广义相加模型的最大自由度设为10,以避免过拟合情况的发生;区域时间基函数代表了区域的污染物浓度,采用奇异值方法分解长序列的测量浓度而获取,混合采用奇异值分解技术,其中每个站点的作为列,而行依次为时间序列,实施过程中只是设计为2维基函数,使得基函数充分包含了其时间变异的信息;最终得到时空广义相加模型,然后送至重采样模型模块;
重采样模型模块:根据时空广义相加模型构建模块中得到的时空广义相加模型,通过重采样技术获得多个模型,从而实现模型的综合解及不确定性,最终得到一个非线性累加模型。具体的实现为通过重抽样技术得到不同的训练与测试数据,分别训练得到不同的模型,通过对这些模型进行加权平均得到最终结果;最后得到一个非线性累加模型,然后送至时空变异模型构建模块;
时空变异模型构建模块:对集成学习,即上重采样模型模块得到的综合模块,最终结果得到的残差,采用日残差模型进行变异函数的时空建模;针对前面的非线性累加模型每天的输出结果的残差,采取空间建模的方式分别对每天的残差建模,时空变异模型采用了变异函数模型中的指数模型,指数模型算法拟合了每天的变异函数,将每天的变异函数结合起来,构划变异函数在1年内的变化情况,实现了采用变异函数的对残差进行预测性推理,最终的预测值由非线性累加集成模型获得的均值与残差时空变异函数模型得到的残差的估计值的和;最后得到时空变异模型,然后送至点到面浓度估算模块;
点到面浓度估算模块:利用块克里格方法进行由点到面的浓度估算;针对重采样模型模块得到的非线性累加模型每天的输出结果的残差,采取空间建模的方式分别对每天的残差建模;采用改进的块克里格方法,将待估区块为n个子块,通过已求得的整个区域的离散点的估计值,在每个子块中进行平均,求得每个子块的均值;最终得到面浓度的估算,此模块将作为最终输出结果模块,模块最后得到了面pm2.5浓度的估算。
本发明的一种基于大数据的时空混淆暴露度评估方法,包括以下步骤:
(1)时空数据挖掘:获取遥感卫星影像数据、pm2.5监测数据、交通路网数据、点污染源数据;遥感卫星影像数据是通过r统计软件和python编程语言实现高效的自动化算法提取而得来,pm2.5监测数据和交通路网数据通过在线数据挖掘得到,点污染源数据基于百度的api高效实现从中提取点源污染信息,得到多源异构数据;
(2)多源异构数据融合:根据步骤(1)得到的多源异构数据,实现多源异构数据的融合;基于shell脚本语言、sql语言、r语言,利用自动化的多源异构的数据融合算法,最后得到融合的多源异构数据;
(3)最终变量选择:根据步骤(2)得到的融合的多源异构数据,确定预测模型输入的最终预测自变量;在筛选自变量时,首先计算方差膨胀因子来避免多重共线性,然后通过向后逐步选择法,直到模型的aic不再变化,选择其中aic最小的预测模型中的变量作为预测模型的最终输入变量;
(4)时空广义相加模型构建:根据步骤(3)得到的最终输入变量,设计包括区域时间基函数在内的混合时空的非线性时空广义相加模型;使用无参数的广义相加模型对非线性因子进行建模,同时将广义相加模型的最大自由度设为10,以避免过拟合情况的发生;区域时间基函数代表了区域的污染物浓度,采用奇异值方法分解长序列的测量浓度而获取,混合采用奇异值分解技术,其中每个站点的作为列,而行依次为时间序列,实施过程中只是设计为2维基函数,使得基函数充分包含了其时间变异的信息;最终得到时空广义相加模型;
(5)重采样模型:根据步骤(4)得到的时空广义相加模型,通过重采样技术获得多个模型,从而实现模型的综合解及不确定性,最终得到一个非线性累加模型,具体的实现为通过重抽样技术得到不同的训练与测试数据,分别训练得到不同的模型,通过对这些模型进行加权平均得到一个非线性累加模型;
(6)时空变异模型构建:对集成学习,针对前面的非线性累加模型每天的输出结果的残差,采取空间建模的方式分别对每天的残差建模,时空变异模型采用了变异函数模型中的指数模型,指数模型算法拟合了每天的变异函数,将每天的变异函数结合起来,构划变异函数在1年内的变化情况,实现了采用变异函数的对残差进行预测性推理,最终的预测值由非线性累加集成模型获得的均值与残差时空变异函数模型得到的残差的估计值的和;最后得到时空变异模型;
(7)点到面浓度估算:利用块克里格方法进行由点到面的浓度估算;针对重采样模型模块得到的非线性累加模型每天的输出结果的残差,采取空间建模的方式分别对每天的残差建模;采用改进的块克里格方法,将待估区块为n个子块,通过已求得的整个区域的离散点的估计值,在每个子块中进行平均,求得每个子块的均值;最终得到面浓度的估算,作为最终输出结果,最后得到了面pm2.5浓度的估算。
本发明与现有技术相比的优点在于:
(1)本发明有效地利用了大数据带来的数据优势,研发了基于大数据的时空混淆暴露度评估模型,充分利用了空间相关性及非线性效果,在实际应用中取得了优异的预测精度效果。以山东省pm2.5预测结果为例,该方法在未使用pm10自变量的情况下,交叉验证r2为0.86,在使用pm10自变量的情况下,交叉验证r2为0.89。基于区域的pm2.5月均浓度时空预测模型是在位置时空预测模型的基础上,结合块克里格方法对山东省30个区域进行预测,在预测2014年区域pm2.5月均浓度的交叉验证r2为0.77,同时模型可生成预估结果的不确定性衡量指标。本发明采用块克里格模型外推预测2016年的多区域月平均浓度,与实际观察数据比较取得了很好的精度(r2=0.73)结果表明,提出的基于位置的预测模型以及基于区域的预测模型,均可进行外推预测,并取得良好的效果。
(2)总之,本发明将空间相关性的是时空变异及非线性融入算法中,将均值及残差结合,有效降低了估计中的精度,取得了明显的建模精度的提高。本发明可应用到空气污染物评估及其他的环境污染物暴露度的预防预报等方面,具有广泛的应用前景。
附图说明
图1为本发明系统的组成框图;
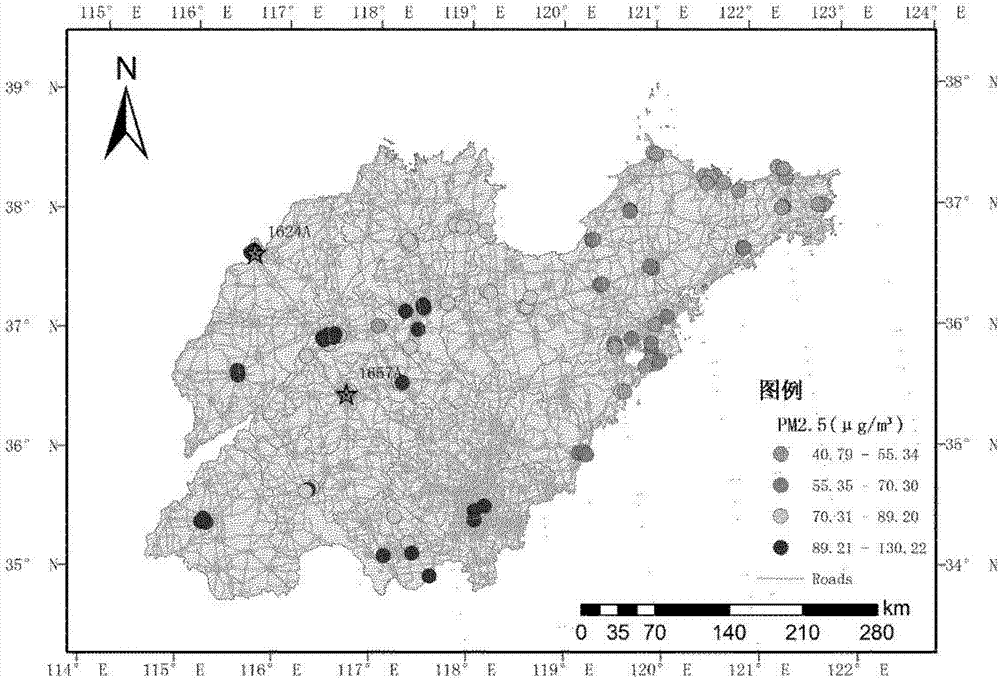
图2展示了本发明的实施例,即山东省pm2.5的90个监测站点分布图;
图3为90个根据长时间序列根据奇异值分解所提取的2014年的pm2.5的第一及第二时间基函数,反应该区域污染物难度的季节性变化;其中a为第一时间基函数,b为第二时间基函数;
图4为本发明所设计的累加模型提取的预测因子与浓度之间的非线性关系;其中a为log-pm10concentration:pm10的浓度求对数;b为aot:气溶胶光学厚度;c为numberofemissionplants监测站10km缓冲区内废弃源工厂数量;d为windvector:风速;e为precipitation:降水量;f为temperature:温度;
图5为交叉验证中pm2.5浓度预测的不确定性的时空分布(days.no(1-365):从1-365天)。
具体实施方式
下面结合附图及实施例对本发明进行详细说明。
如图1所示,本发明一种基于大数据的时空混淆暴露度评估系统,包括:时空数据挖掘模块、多源异构数据融合模块、最终变量选择模块、时空广义相加模型构建模块、重采样模型模块、变异函数时空建模模块和浓度估算模块。
1.时空数据挖掘模块具体实现过程如下:
(1)图2所示,根据域知识确定针对研究区的初步的预测因子变量,包括气象因子、气溶胶、ndvi、交通变量、土地利用变量等,设计了在线及高效的并行化数据提取技术,从在线数据、海量影像等挖掘相关的因子数据,具体包括以下几大类:
(a)监测站点数据,在线挖掘监测站点数据;
(b)通过再分析数据merra提取与pm2.5相关的气象因素,包括温度、降水量、相对湿度以及风速;
(c)交通排放对pm2.5浓度的贡献度也很大,采用了两种变量作为交通排放的代理变量,分别是监测站点10千米缓冲区内道路的长度及监测站点到道路的最短距离,道路数据源自openstreetmap;
(d)除了交通排放污染外,工业污染在pm2.5形成过程中起了很大的作用,从山东省环保厅得到2014年废气国控源企业信息,并通过poi技术在百度地图中得到废气国控源企业信息的地理位置信息,在模型中同样采用了两种变量作为工业排放的代理变量,分别为在监测站点10千米缓冲区内排放废气的企业个数以及监测站点到最近排放废气企业的距离;
(e)同时于遥感数据中的研究区的空间分辨率为1km的2014年土地利用数据提取监测站点的10km缓冲区中林地及建筑用地像元个数,以及由modis计算得到的空间分辨率为1km日气溶胶产品和月ndvi产品,分别提取监测站点的气溶胶值和ndvi值。
2.多源异构数据融合模块具体实现过程如下:
(1)根据时空数据挖掘模块得到的多源异构数据,实现过程如下:
a.从国家环保部网站数据中心(http://datacenter.mep.gov.cn),由于该网站不提供历史数据,设计了实时的网络挖掘软件,可获取覆盖全国的pm2.5的实时数据。该挖掘软件采用了python的urllib及bs等库进行网页解析及分析,并从结果中提取相关的数据,自2014年上线一直运行挖掘得到了多年的空气污染物数据;
b.采用类似的方式批量及高效地挖掘各种遥感影像数据,包括merra、ndvi、maiac等海量遥感数据。仍然采用python结合scrapy、beautifulsoup、urlib及re正则化模式匹配库等实现网络挖掘。具体流程:输入各数据来源的网页url地址→解析网页→搜索关键字→网页跳转→找到目标网页→获得数据下载链接→下载数据。其他海量遥感数据的挖掘采用类似的方式获取。
poi数据的挖掘:根据百度提供的接口(http://api.map.baidu.com/place/v2/search)链接获取地区数据,提取其中的相关数据。首先获取山东省2014年废气国控源企业信息(企业列表来源:http://xxgk.sdein.gov.cn),根据信息提取这些潜在污染企业的位置,计算其与监测站点的距离或者一定缓冲(如5km)范围类的个数获取其信息。我们采用了python的urllib等实现了相应功能。
(2)基于shell脚本语言、sql语言、r语言,利用自动化的多源异构的数据融合算法,最后得到融合的多源异构数据;
由于数据来源不一样,针对不同的数据源设计了不同的挖掘及提取程序,最后通过脚本语言shellscript将各种信息融合在一起,实现一定程度的自动化,提高生产效率。如前所述,分别设计了pm2.5测量在线挖掘程序、各种影像数据提取程序、poi挖掘程序等,获得不同的数据。最后通过脚本将各种分异的数据融合在一起。主要的融合过程包括以下几步:
a.sql查询语言输入数据库导库中,检查数据的一致性、正确性等,根据id提取相应的pm2.5测量样本或因子的值,本发明采用了postgis实现了相应的空间数据库功能;
b.各种影像数据的处理,主要采用了r的rgdal及raster库,便于将各种影像进行预处理,如各种去噪、缺失值处理、投影转换、图像淹没及叠加获取值;
c.poi数据的提取及与测量位置匹配。
d.最后将各种生成的数据采用bash脚本融合打包,形成训练用的统一数据集。
3.最终变量选择模块具体实现过程如下:
(1)在筛选自变量时,首先计算方差膨胀因子(varianceinflationfactor,vif)来避免多重共线性;vif计算过程公式:vif=(1-r^2)-1,式中,r^2是以将一自变量为因变量时对其它自变量回归的复测定系数。得到各个预测变量的vif之后,限定vif>10为不合格,移除预测因子集,所有保留的预测因子都需满足其vif<10时条件。
(2)然后通过向后逐步选择法,直到模型的aic不再变化,选择其中aic最小的模型中的变量作为预测模型的最终输入变量。aic信息准则即akaikeinformationcriterion,是衡量模型性能的主要标准,越小表明模型越理想。实施采用以下步骤进行:
a.将现有的所有因子作为预测变量集输入模型,获取模型的性能指标aic;
b.分别移除一个变量重新拟合模型,计算新的aic值,如aic变小,表明移除的变量是在现有预测因子集下会带来噪声,可作为候选移除因集。将现有的所有预测因子变量对应的aic计算出来,看那个aic减少得最多,将减少最多的因子移除;
c.如aic没有减少,说明模型最优,停止迭代,得到新预测因子变量集;
d.如有因子需要删除,则删除导致aic减少最多的因子,重新返回a步循环,直至得到理想的模型。
4.时空广义相加模型构建模块具体实现过程如下:
(1)实施非线性累加模型,采用r统计软件中的generalizedadditivemodel(gam)实施该模型;设计包括区域时间基函数的非线性时空广义相加模型:
y(s,t)=μ(s,t)+ε(s,t),y(s,t)~n(μ,σ)(1)
上式,s,t分别代表监测数据的监测站点位置和监测时间,y(s,t)为对数变换的pm2.5浓度,之所以对其进行对数变换是由于pm2.5的监测值为偏态分布而非正态分布(见图3);μ(s,t)是y(s,t)的均值,且时空残差ε(s,t)服从n(0,σ2)分布。在公式(2)中,μ(s,t)由三部分建模组成,f1(t),f2(t)为时间变量,分别为第一、第二时间基函数,xi(s,t)为时空变量,包括气象因子、气溶胶、ndvi,pk(s)为空间变量,包括交通变量,土地利用变量等,s(...)代表广义相加模型中的平滑函数。
(2)使用无参数的广义相加模型对非线性因子进行建模,同时将广义相加模型的最大自由度设为10,以避免过拟合情况的发生。区域时间基函数代表了区域的污染物浓度,采用奇异值方法分解长序列的测量浓度而获取。
5.重采样模型模块具体实现过程如下:
(1)通过重采样bootstrap技术,针对大小为n数据,重采样生成同样大小的数据,但实际抽样只具有66%左右;
(2)通过重抽样技术得到不同的训练与测试数据,分别训练得到不同的模型(本实验中得到1000个模型),最终结果得到加权平均值及不确定性;集成学习方法bagging,非线性广义相加模型可能对新的数据敏感,因此算法采用集成学习的bagging算法提高预测结果的稳定度,并估算具体的不确定性(标准误差)。在本发明中,采用重采样得到不同的数据集,分别训练模型得到不同的非线性广义累加模型,最后的结果是这些模型的加权求和。
yf(s,t)=∑iyi(s,t)wi(3)
式中yf(s,t)是最终预测值(加权求和值),由多个模型得到,wi是其权重值,由rmse派生得到:
wi=rmsei/∑irmsei(4)
不确定性计算公式(标准变差):
m为非0权重个数。
6.变异函数时空建模模块具体实现过程如下:
(1)对集成学习最终结果得到的残差,采用日残差进行变异函数的建模,求取得到的2014年内每日的残差的变异函数参数;针对前面的非线性累加模型每天的输出结果的残差,采取空间建模的方式分别对每天的残差建模。
式中,ε(s0,t)为目标位置的s0及对应时间点t的残差,si(i=0,1,…)为空间位置点,s0为待估计的点,λi为周围点si(s,t)对应的权重,由变异函数建模得到。采用了变异函数模型(球状、指数、椭圆及高斯模型),最后选中了指数模型:
模型对应的几个关键的残差变异参数:t时间(分辨率:天),c0(t)为块金常数,c(t)为拱高,a0为变程。每个参数随时间t而不同。
拟合每天的变异函数,将每天的变异函数结合起来,构划变异函数在1年内的变化情况,并由此作为每年的残差函数计算的依据,实现了采用变异函数的对残差进行预测性推理。
(2)并根据此参数拟合累加了非线性拟合曲线,从而将该变异函数的非线性年纪变异规律应用到预测之中去,从而达到提高估计结果的精度。
7.浓度估算模块具体实现过程如下:
(1)针对重采样模型模块得到的非线性累加模型每天的输出结果的残差,采取空间建模的分别对每天的残差建模;具体实现方式如下:
a.对2014年模型,以每天样本数据分别建立的模型,计算bootstrapaggregation预测得到各个样本的残差(=观察值-预测值);
b.对每天的残差采用指数变异函数进行拟合,计算拟合的参数:变程(range)、块金效应(nugget)及基台(sill)值,作为计算各点之间的空间关联性依据,并探索这些参数一年内的趋势;
c.根据拟合的变异函数,计算交叉验证结果作为衡量模型标志;此外参数可以直接用以普通克里格模型预测各点的残差结果。
(2)采用改进的块克里格方法,将待估区块为n个子块,通过已求得的整个区域的离散点的估计值,在每个子块中进行平均,求得每个子块的均值;得到面浓度的估算。
块克里格的公式如下:
其中v(s,t)为通过s及t模拟的目标区域,通过均匀布点而拟合目标区域v的均值,a为样本点的数目,其中权重参数λαv(s,t)通过以下的克里格系统拟合:
其中λβv(s,t)为待求的权重系数,c(sα-sβ)为空间点α及β的协方差值(通过变异函数求解),
具体的过程:
a.根据前一阶段得到的模型估算一定数量的每天点浓度值;
b.计算每天的变异函数参数;
c.根据精度要求在空间均匀布点,获取分到每个区内的样本点;
d.根据以上公式计算各区域对应样本的权重;
e.加权求和得到区域平均值。
下面以典型的空气污染物pm2.5为例,对本发明再作进一步说明其具体实施方式:
(1)时空数据挖掘模块:考虑到环境污染物如pm2.5浓度的影响因素的复杂性,采用了多源数据对pm2.5浓度进行预测以减少预测偏差,首先是根据域知识确定针对研究区(图1)的初步的预测因子变量,包括遥感数据(气溶胶、土地利用、ndvi)以及地面监测站的监测数据;时间、空间分辨率更高的再分析数据用以提取气象因子;道路数据及来自研究区政府公布的空气污染企业数据;社会经济等数据,这些数据来自不同领域,大部分采用在线挖掘的技术获取;而海量数据的使用使模型预测结果更加能贴近真实,精度准确定大幅提高。具体包括以下几大类:
(11)通过再分析数据merra提取与pm2.5相关的气象因素,包括温度、降水量、相对湿度以及风速;
(12)交通排放对pm2.5浓度的贡献度也很大,采用了两种变量来作为交通排放的代理变量,分别是监测站点10千米缓冲区内道路的长度及监测站点到道路的最短距离,道路数据源自openstreetmap;
(13)除了交通排放污染外,工业污染在pm2.5形成过程中起了很大的作用,从山东省环保厅得到2014年废气国控源企业信息,并通过poi技术在百度地图中得到废气国控源企业信息的地理位置信息,在模型中同样采用了两种变量作为工业排放的代理变量,分别为在监测站点10千米缓冲区内排放废气的企业个数以及监测站点到最近排放废气企业的距离;
(14)同时于遥感数据中的研究区的空间分辨率为1km的2014年土地利用数据提取监测站点的10km缓冲区中林地及建筑用地像元个数,以及由modis计算得到的空间分辨率为1km日气溶胶产品和月ndvi产品,分别提取监测站点的气溶胶值和ndvi值。
(2)多源异构数据融合模块:将(1)中得到的多源异构数据进行融合;基于shell脚本语言、sql语言、r语言,利用自动化的多源异构的数据融合算法,最后得到融合的多源异构数据。
(3)最终变量选择模块:在筛选自变量时,首先计算方差膨胀因子(varianceinflationfactor,vif)来避免多重共线性,然后通过向后逐步选择法,直到模型的aic不再变化,选择其中aic最小的模型中的变量作为预测模型的最终输入变量。
(4)时空广义相加模型构建模块:实施非线性累加模型,采用r统计软件中的generalizedadditivemodel(gam)实施该模型,其中加入了季节性变化趋势曲线,控制累加模型的自由度为10以下,以减少拟合数据中的过拟合,提高预测精度,图3展示了所涉及的模型提取得到的非线性关系。传统的预测方法大多使用多元线性方法(如土地利用回归等)来预测pm2.5,而pm2.5浓度与影响其的多种因素之间并不是呈线性关系,本发明提出了结合空间相关性的非线性预测方法,该方法考虑了pm2.5与多种影响因素之间的非线性关系,使用非线性模型—广义相加模型进行建模,并通过基于时间序列的空间残差建模大幅提高预测精度,特别是提高了对未采用pm10作为自变量的模型预测效果。
(5)重采样模型模块:通过重采样bootstrap技术,针对大小为n数据,重采样生成同样大小的数据,但实际抽样只具有66%左右。通过重抽样技术得到不同的训练与测试数据,分别训练得到不同的模型(本实验中得到1000个模型),最终结果得到加权平均值及不确定性。图4展示了本发明所提取的不确定性(标准变差)的时空分布。采用计算机领域中的集成学习方法bagging,可对目标变量pm2.5进行多次有放回的抽样以作为模型的多个训练集,并根据每个训练集的建模结果可以得到每个站点每天的不确定性,将为传统方法中预测的单一值增加了预测的不确定性,提高了模型预测的可信度。
(6)变异函数时空建模模块:对集成学习最终结果得到的残差,采用日残差进行变异函数的建模,求取得到的2014年内每日的残差的变异函数参数,并根据此参数拟合累加了非线性拟合曲线,从而将该变异函数的非线性年纪变异规律应用到预测之中去,从而达到提高估计结果的精度。图5展示了本发明所拟合得到的时间变化曲线。
(7)面浓度估算模块:采用改进的块克里格方法,将待估区块为n个子块,通过已求得的整个区域的离散点的估计值,在每个子块中进行平均,求得每个子块的均值;得到面浓度的估算。
针对以前pm2.5估算方法的不足,本发明有以下技术上几方面的突破:提出了挖掘相关大数据获取适当预测因子的方法及实施方式,如污染源数据、气溶胶及土地利用等海量数据,这些要素的使用可使模型有效地捕捉污染物浓度时空变化的影响因子,有助于模型精度的提高;非线性累加建模方法,可有效建立影响因素同污染物浓度之间的复杂关系,相比线性模型建立关系更符合实际;采用残差克里格时空建模方法,有效补充了残差之中的时空变异,加入到非线性模型均值输出极大提高了预测精度,非常适合当其他协污染物(如pm10)缺乏的情况。本发明还对其污染物浓度在不同时间尺度、空间尺度上进行预测,结果的输出对相关环境健康研究具有重大意义。
- 还没有人留言评论。精彩留言会获得点赞!