应用信息推送方法、装置、服务器和计算机可读存储介质与流程
本发明涉及计算机技术领域,具体而言,涉及一种应用信息推送方法、一种应用信息推送装置、一种服务器和一种计算机可读存储介质。
背景技术:
任何一个推荐场景通常都由由业务请求发起,比如网易新闻的内容推荐,阿里巴巴的商品推荐,豆瓣的电影推荐等,在商业场景中,业务人员通常根据某种商业目标来设置规则,比如新闻推荐需要考虑时效性,而算法人员则更多从人工智能的角度考虑如何让用户更快的浏览自己喜欢的内容,比如会采用各式各样的个性化算法来提升用户浏览效率。
相关技术中,如果业务策略与算法策略的开发时不在同一个方向,则会产生冲突,而这种冲突目前基本是由产品经理人工调停,最终由算法人员实现一个两者兼顾的方案,即算法人员也需要花时间去开发业务逻辑,从而增加了信息推送策略开发过程的复杂性。
技术实现要素:
本发明旨在至少解决现有技术或相关技术中存在的技术问题之一。
为此,本发明的一个目的在于提供一种应用信息推送方法。
本发明的另一个目的在于提供一种应用信息推送的装置。
本发明的又一个目的在于提供一种服务器。
本发明的又一个目的在于提供一种计算机可读存储介质。
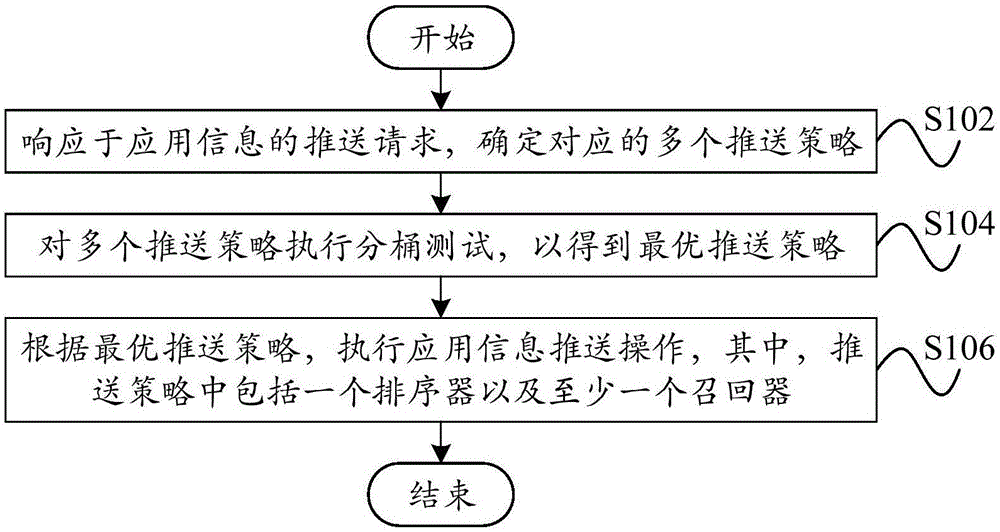
为了实现上述目的,本发明第一方面的技术方案提供了一种应用信息推送方法,包括:响应于应用信息的推送请求,确定对应的多个推送策略;对多个推送策略执行分桶测试,以得到最优推送策略;根据最优推送策略,执行应用信息推送操作,其中,推送策略中包括一个排序器以及至少一个召回器。
在该技术方案中,在接收到应用信息的推送请求时,确定策略配置模块中对应的多个推送策略,通过对多个推送策略进行相同的滚筒测试,以确定一个最优推送策略,并根据最优推送策略执行应用信息的推送操作,实现了对推送策略的优化,在满足商业需求的同时,能够提升用户的浏览效率与浏览体验。
其中,推送请求与推送策略的映射模型,可以根据推送场景建立,也可以根据推送对象建立。
在上述技术方案中,优选地,响应于应用信息推送请求,确定对应的多个推送策略,具体包括以下步骤:确定推送请求对应的应用场景;根据应用场景,确定对应的业务策略规则;将业务策略规则输入预设的算法策略模型,以生成多个推送策略。
在该技术方案中,通过确定推送请求的应用场景,以根据应用场景确定对应的业务策略规则,将业务策略规则作为一个或多个变量输入到算法策略模型中,实现算法与业务之间的组装,从而生成多个推送策略,实现了算法策略模型与业务策略规则之间的解耦,一方面,算法开发人员开发过程中能够不受业务数据的影响,降低了算法开发的复杂性,另一方面,也有利于简化业务人员的业务配置操作。
具体地,算法策略模型中包括多个召回算法模型和排序算法模型,业务策略规则中也包括多个召回规则与排序规则,根据预设条件配置推送策略,进而得到多个推送策略,其中每个推送策略可以有多个召回器但只有一个排序器,召回器之间可以取交集也可以取并集。
另外,对于算法策略模型,也可以采用机器学习算法进行分类预测,并对不同的算法模型进行打分,使算法人员能够充分享受人工智能的乐趣。
需要理解的是,算法策略模型侧重于用户体验,业务策略模型侧重于商业反馈。
在上述技术方案中,优选地,在响应于应用信息推送请求,确定对应的多个推送策略前,还包括:生成与应用场景对应的前端配置接口;接收由前端配置接口输入的业务构造参数,以根据业务构造参数生成业务策略规则,其中,业务策略规则包括召回规则与排序规则,召回规则基于逻辑构造规则生成,排序规则基于权重指标生成。
在该技术方案中,通过生成与应用场景对应的前端配置接口,以接收从前端配置接口输入的业务构造参数,并根据业务构造参数生成业务策略规则,一方面,业务策略规则配置过程简单,另一方面,业务策略规则的构建在考虑商业行为的同时,更加人性化。
具体地,在前端页面显示前端配置接口,并罗列与应用场景相关的配置指标,业务人员构造召回规则时可基于and和or逻辑构造规则,在构造排序规则时通过权重对指标进行线性相加得到最终得分。
在上述技术方案中,优选地,根据对多个推送策略执行分桶测试,以得到最优推送策略,具体包括以下步骤:在接收到应用请求时,对多个推送策略分配相同的测试权限;根据测试权限,记录每个推送策略的召回器根据应用请求召回的用户样本;根据排序器对用户样本进行排序,以根据排序结果生成对应的评价指标;根据每个评价指标,确定最优推送策略。
在该技术方案中,通过执行分桶测试,确定最优推送策略,一方面,对于多个推送策略,在测试过程中具有相同的权重值,即相同的测试权限,提升最优推送策略确定过程的稳定性,另一方面,通过对用户样本进行召回与排序,确定最优推送策略,在产生商业价值的同时,优化了用户的浏览体验。
其中,分桶测试的最简单形式为a/b测试,即设定一个基准桶,在设定一个或以上的测试桶,然后考察测试桶(即多个推送策略)与基准通之间在各项指标上的差异,最后确定测试桶的效果(确定最优推送策略)。
分桶测试的高级形式为多变量测试,在多变量测试中,每个可以改变的地方称为因素(比如应用场景),而每个可能具有的状态称为水平(比如不同的算法策略模型),多变量测试允许在同一时间测试多个要素处于不同水平时对于搜索产品的影响,通过多变量测试,能够十分清楚地看到不同的变化组合对最终效果的影响,最终得到最优推送策略。
在上述技术方案中,优选地,根据最优推送策略,执行应用信息推送操作,具体包括以下步骤:根据最优推荐策略,确定场景关键词;将场景关键词输入实时计算引擎,以获取检索到的应用信息;将应用信息推送至指定终端,其中,实时计算引擎由kafka、jstorm以及elasticsearch构造生成。
在该技术方案中,在确定最优推荐策略后,确定场景关键词,以通过实时计算引擎确定需要推送的应用信息,一方面,使用实时计算引擎能够处理复杂的查询需求,另一方面,实时计算引擎由kafka、jstorm以及elasticsearch构造生成,三者完美无缝对接且均有容错和分布式的特性。
其中,kafka指一种高吞吐量的分布式发布订阅消息系统,jstorm指参考storm的实时流式计算框架,elasticsearch指基于lucene的搜索服务器,提供了一个分布式多用户能力的全文搜索引擎。
在上述技术方案中,优选地,在响应于应用信息推送请求,确定对应的多个推送策略前,还包括:将算法策略模型代码持久化成文件,以采用动态加载以及对象反射的方式,将算法策略模型加载至内存中;以及将业务策略规则持久化在文档型数据库中,以在根据连接池技术查询到业务策略规则后缓存在内存中;以及将推送策略的配置信息持久化在管理数据库中。
在该技术方案中,对于算法策略模型,通过将算法工程师提交的代码持久化成文件,采用“动态加载”以及“对象反射”技术将算法加载到内存中,实现算法策略模型持久化;对于业务策略规则,通过将业务测量模型逻辑持久化在mongo等文档型数据库中,利用连接池技术查询到业务规则后缓存在内存中;对于配置策略,将配置策略持久化在mysql等管系统数据库中方便复杂查询,这样即使服务受到各种异常崩溃后,依然能够重启并正常恢复,采用不同模块不同的持久化策略进行容灾,提升服务稳定性和可用性。
本发明的第二方面的技术方案提供了一种应用信息推送装置,包括:确定单元,用于响应于应用信息的推送请求,确定对应的多个推送策略;测试单元,用于对多个推送策略执行分桶测试,以得到最优推送策略;执行单元,用于根据最优推送策略,执行应用信息推送操作,其中,推送策略中包括一个排序器以及至少一个召回器。
在该技术方案中,在接收到应用信息的推送请求时,确定策略配置模块中对应的多个推送策略,通过对多个推送策略进行相同的滚筒测试,以确定一个最优推送策略,并根据最优推送策略执行应用信息的推送操作,实现了对推送策略的优化,在满足商业需求的同时,能够提升用户的浏览效率与浏览体验。
其中,推送请求与推送策略的映射模型,可以根据推送场景建立,也可以根据推送对象建立。
在上述技术方案中,优选地,确定单元还用于:确定推送请求对应的应用场景;确定单元还用于:根据应用场景,确定对应的业务策略规则;应用信息推送装置还包括:输入单元,用于将业务策略规则输入预设的算法策略模型,以生成多个推送策略。
在该技术方案中,在接收到应用信息的推送请求时,确定策略配置模块中对应的多个推送策略,通过对多个推送策略进行相同的滚筒测试,以确定一个最优推送策略,并根据最优推送策略执行应用信息的推送操作,实现了对推送策略的优化,在满足商业需求的同时,能够提升用户的浏览效率与浏览体验。
其中,推送请求与推送策略的映射模型,可以根据推送场景建立,也可以根据推送对象建立。
在上述技术方案中,优选地,还包括:生成单元,用于生成与应用场景对应的前端配置接口;接收单元,用于接收由前端配置接口输入的业务构造参数,以根据业务构造参数生成业务策略规则,其中,业务策略规则包括召回规则与排序规则,召回规则基于逻辑构造规则生成,排序规则基于权重指标生成。
在该技术方案中,通过生成与应用场景对应的前端配置接口,以接收从前端配置接口输入的业务构造参数,并根据业务构造参数生成业务策略规则,一方面,业务策略规则配置过程简单,另一方面,业务策略规则的构建在考虑商业行为的同时,更加人性化。
具体地,在前端页面显示前端配置接口,并罗列与应用场景相关的配置指标,业务人员构造召回规则时可基于and和or逻辑构造规则,在构造排序规则时通过权重对指标进行线性相加得到最终得分。
在上述技术方案中,优选地,还包括:分配单元,用于在接收到应用请求时,对多个推送策略分配相同的测试权限;记录单元,用于根据测试权限,记录每个推送策略的召回器根据应用请求召回的用户样本;排序单元,用于根据排序器对用户样本进行排序,以根据排序结果生成对应的评价指标;确定单元还用于:根据每个评价指标,确定最优推送策略。
在该技术方案中,通过执行分桶测试,确定最优推送策略,一方面,对于多个推送策略,在测试过程中具有相同的权重值,即相同的测试权限,提升最优推送策略确定过程的稳定性,另一方面,通过对用户样本进行召回与排序,确定最优推送策略,在产生商业价值的同时,优化了用户的浏览体验。
其中,分桶测试的最简单形式为a/b测试,即设定一个基准桶,在设定一个或以上的测试桶,然后考察测试桶(即多个推送策略)与基准通之间在各项指标上的差异,最后确定测试桶的效果(确定最优推送策略)。
分桶测试的高级形式为多变量测试,在多变量测试中,每个可以改变的地方称为因素(比如应用场景),而每个可能具有的状态称为水平(比如不同的算法策略模型),多变量测试允许在同一时间测试多个要素处于不同水平时对于搜索产品的影响,通过多变量测试,能够十分清楚地看到不同的变化组合对最终效果的影响,最终得到最优推送策略。
在上述技术方案中,优选地,确定单元还用于:根据最优推荐策略,确定场景关键词;输入单元还用于:将场景关键词输入实时计算引擎,以获取检索到的应用信息;应用信息推送装置还包括:推送单元,用于将应用信息推送至指定终端,其中,实时计算引擎由kafka、jstorm以及elasticsearch构造生成。
在该技术方案中,在确定最优推荐策略后,确定场景关键词,以通过实时计算引擎确定需要推送的应用信息,一方面,使用实时计算引擎能够处理复杂的查询需求,另一方面,实时计算引擎由kafka、jstorm以及elasticsearch构造生成,三者完美无缝对接且均有容错和分布式的特性。
其中,kafka指一种高吞吐量的分布式发布订阅消息系统,jstorm指参考storm的实时流式计算框架,elasticsearch指基于lucene的搜索服务器,提供了一个分布式多用户能力的全文搜索引擎。
在上述技术方案中,优选地,还包括:第一持久化单元,用于将算法策略模型代码持久化成文件,以采用动态加载以及对象反射的方式,将算法策略模型加载至内存中;第二持久化单元,用于将业务策略规则持久化在文档型数据库中,以在根据连接池技术查询到业务策略规则后缓存在内存中;第三持久化单元,用于将推送策略的配置信息持久化在管理数据库中。
在该技术方案中,对于算法策略模型,通过将算法工程师提交的代码持久化成文件,采用“动态加载”以及“对象反射”技术将算法加载到内存中,实现算法策略模型持久化;对于业务策略规则,通过将业务测量模型逻辑持久化在mongo等文档型数据库中,利用连接池技术查询到业务规则后缓存在内存中;对于配置策略,将配置策略持久化在mysql等管系统数据库中方便复杂查询,这样即使服务受到各种异常崩溃后,依然能够重启并正常恢复,采用不同模块不同的持久化策略进行容灾,提升服务稳定性和可用性。
本发明的第三方面的技术方案提供了一种服务器,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述任一项应用信息推送方法限定的步骤,和/或包括上述任一项的应用信息推送装置。
本发明的第四方面的技术方案提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述任一项应用信息推送方法限定的步骤。
本发明的优点将在下面的描述部分中给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1示出了根据本发明的实施例的应用信息推送方法的示意流程图;
图2示出了根据本发明的实施例的应用信息推送装置的示意框图;
图3示出了根据本发明的实施例的服务器的示意框图;
图4示出了根据本发明的实施例的运营推送过程的示意流程图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
图1示出了根据本发明的一个实施例的应用信息推送方法的示意流程图。
如图1所示,根据本发明的实施例的无线局域网的通信方法,包括:步骤102,响应于应用信息的推送请求,确定对应的多个推送策略;步骤104,对多个推送策略执行分桶测试,以得到最优推送策略;步骤106,根据最优推送策略,执行应用信息推送操作,其中,推送策略中包括一个排序器以及至少一个召回器。
在该技术方案中,在接收到应用信息的推送请求时,确定策略配置模块中对应的多个推送策略,通过对多个推送策略进行相同的滚筒测试,以确定一个最优推送策略,并根据最优推送策略执行应用信息的推送操作,实现了对推送策略的优化,在满足商业需求的同时,能够提升用户的浏览效率与浏览体验。
其中,推送请求与推送策略的映射模型,可以根据推送场景建立,也可以根据推送对象建立。
在上述技术方案中,优选地,响应于应用信息推送请求,确定对应的多个推送策略,具体包括以下步骤:确定推送请求对应的应用场景;根据应用场景,确定对应的业务策略规则;将业务策略规则输入预设的算法策略模型,以生成多个推送策略。
在该技术方案中,通过确定推送请求的应用场景,以根据应用场景确定对应的业务策略规则,将业务策略规则作为一个或多个变量输入到算法策略模型中,实现算法与业务之间的组装,从而生成多个推送策略,实现了算法策略模型与业务策略规则之间的解耦,一方面,算法开发人员开发过程中能够不受业务数据的影响,降低了算法开发的复杂性,另一方面,也有利于简化业务人员的业务配置操作。
具体地,算法策略模型中包括多个召回算法模型和排序算法模型,业务策略规则中也包括多个召回规则与排序规则,根据预设条件配置推送策略,进而得到多个推送策略,其中每个推送策略可以有多个召回器但只有一个排序器,召回器之间可以取交集也可以取并集。
另外,对于算法策略模型,也可以采用机器学习算法进行分类预测,并对不同的算法模型进行打分,使算法人员能够充分享受人工智能的乐趣。
需要理解的是,算法策略模型侧重于用户体验,业务策略模型侧重于商业反馈。
在上述技术方案中,优选地,在响应于应用信息推送请求,确定对应的多个推送策略前,还包括:生成与应用场景对应的前端配置接口;接收由前端配置接口输入的业务构造参数,以根据业务构造参数生成业务策略规则,其中,业务策略规则包括召回规则与排序规则,召回规则基于逻辑构造规则生成,排序规则基于权重指标生成。
在该技术方案中,通过生成与应用场景对应的前端配置接口,以接收从前端配置接口输入的业务构造参数,并根据业务构造参数生成业务策略规则,一方面,业务策略规则配置过程简单,另一方面,业务策略规则的构建在考虑商业行为的同时,更加人性化。
具体地,在前端页面显示前端配置接口,并罗列与应用场景相关的配置指标,业务人员构造召回规则时可基于and和or逻辑构造规则,在构造排序规则时通过权重对指标进行线性相加得到最终得分。
在上述技术方案中,优选地,根据对多个推送策略执行分桶测试,以得到最优推送策略,具体包括以下步骤:在接收到应用请求时,对多个推送策略分配相同的测试权限;根据测试权限,记录每个推送策略的召回器根据应用请求召回的用户样本;根据排序器对用户样本进行排序,以根据排序结果生成对应的评价指标;根据每个评价指标,确定最优推送策略。
在该技术方案中,通过执行分桶测试,确定最优推送策略,一方面,对于多个推送策略,在测试过程中具有相同的权重值,即相同的测试权限,提升最优推送策略确定过程的稳定性,另一方面,通过对用户样本进行召回与排序,确定最优推送策略,在产生商业价值的同时,优化了用户的浏览体验。
其中,分桶测试的最简单形式为a/b测试,即设定一个基准桶,在设定一个或以上的测试桶,然后考察测试桶(即多个推送策略)与基准通之间在各项指标上的差异,最后确定测试桶的效果(确定最优推送策略)。
分桶测试的高级形式为多变量测试,在多变量测试中,每个可以改变的地方称为因素(比如应用场景),而每个可能具有的状态称为水平(比如不同的算法策略模型),多变量测试允许在同一时间测试多个要素处于不同水平时对于搜索产品的影响,通过多变量测试,能够十分清楚地看到不同的变化组合对最终效果的影响,最终得到最优推送策略。
在上述技术方案中,优选地,根据最优推送策略,执行应用信息推送操作,具体包括以下步骤:根据最优推荐策略,确定场景关键词;将场景关键词输入实时计算引擎,以获取检索到的应用信息;将应用信息推送至指定终端,其中,实时计算引擎由kafka、jstorm以及elasticsearch构造生成。
在该技术方案中,在确定最优推荐策略后,确定场景关键词,以通过实时计算引擎确定需要推送的应用信息,一方面,使用实时计算引擎能够处理复杂的查询需求,另一方面,实时计算引擎由kafka、jstorm以及elasticsearch构造生成,三者完美无缝对接且均有容错和分布式的特性。
其中,kafka指一种高吞吐量的分布式发布订阅消息系统,jstorm指参考storm的实时流式计算框架,elasticsearch指基于lucene的搜索服务器,提供了一个分布式多用户能力的全文搜索引擎。
在上述技术方案中,优选地,在响应于应用信息推送请求,确定对应的多个推送策略前,还包括:将算法策略模型代码持久化成文件,以采用动态加载以及对象反射的方式,将算法策略模型加载至内存中;以及将业务策略规则持久化在文档型数据库中,以在根据连接池技术查询到业务策略规则后缓存在内存中;以及将推送策略的配置信息持久化在管理数据库中。
在该技术方案中,对于算法策略模型,通过将算法工程师提交的代码持久化成文件,采用“动态加载”以及“对象反射”技术将算法加载到内存中,实现算法策略模型持久化;对于业务策略规则,通过将业务测量模型逻辑持久化在mongo等文档型数据库中,利用连接池技术查询到业务规则后缓存在内存中;对于配置策略,将配置策略持久化在mysql等管系统数据库中方便复杂查询,这样即使服务受到各种异常崩溃后,依然能够重启并正常恢复,采用不同模块不同的持久化策略进行容灾,提升服务稳定性和可用性。
图2示出了根据本发明的实施例的应用信息推送装置的示意框图。
如图2所示,根据本发明的实施例的应用信息推送装置200,包括:确定单元202,用于响应于应用信息的推送请求,确定对应的多个推送策略;测试单元204,用于对多个推送策略执行分桶测试,以得到最优推送策略;执行单元206,用于根据最优推送策略,执行应用信息推送操作,其中,推送策略中包括一个排序器以及至少一个召回器。
在该技术方案中,在接收到应用信息的推送请求时,确定策略配置模块中对应的多个推送策略,通过对多个推送策略进行相同的滚筒测试,以确定一个最优推送策略,并根据最优推送策略执行应用信息的推送操作,实现了对推送策略的优化,在满足商业需求的同时,能够提升用户的浏览效率与浏览体验。
其中,推送请求与推送策略的映射模型,可以根据推送场景建立,也可以根据推送对象建立。
在上述技术方案中,优选地,确定单元202还用于:确定推送请求对应的应用场景;确定单元202还用于:根据应用场景,确定对应的业务策略规则;应用信息推送装置200还包括:输入单元208,用于将业务策略规则输入预设的算法策略模型,以生成多个推送策略。
在该技术方案中,在接收到应用信息的推送请求时,确定策略配置模块中对应的多个推送策略,通过对多个推送策略进行相同的滚筒测试,以确定一个最优推送策略,并根据最优推送策略执行应用信息的推送操作,实现了对推送策略的优化,在满足商业需求的同时,能够提升用户的浏览效率与浏览体验。
其中,推送请求与推送策略的映射模型,可以根据推送场景建立,也可以根据推送对象建立。
在上述技术方案中,优选地,还包括:生成单元210,用于生成与应用场景对应的前端配置接口;接收单元212,用于接收由前端配置接口输入的业务构造参数,以根据业务构造参数生成业务策略规则,其中,业务策略规则包括召回规则与排序规则,召回规则基于逻辑构造规则生成,排序规则基于权重指标生成。
在该技术方案中,通过生成与应用场景对应的前端配置接口,以接收从前端配置接口输入的业务构造参数,并根据业务构造参数生成业务策略规则,一方面,业务策略规则配置过程简单,另一方面,业务策略规则的构建在考虑商业行为的同时,更加人性化。
具体地,在前端页面显示前端配置接口,并罗列与应用场景相关的配置指标,业务人员构造召回规则时可基于and和or逻辑构造规则,在构造排序规则时通过权重对指标进行线性相加得到最终得分。
在上述技术方案中,优选地,还包括:分配单元214,用于在接收到应用请求时,对多个推送策略分配相同的测试权限;记录单元216,用于根据测试权限,记录每个推送策略的召回器根据应用请求召回的用户样本;排序单元218,用于根据排序器对用户样本进行排序,以根据排序结果生成对应的评价指标;确定单元202还用于:根据每个评价指标,确定最优推送策略。
在该技术方案中,通过执行分桶测试,确定最优推送策略,一方面,对于多个推送策略,在测试过程中具有相同的权重值,即相同的测试权限,提升最优推送策略确定过程的稳定性,另一方面,通过对用户样本进行召回与排序,确定最优推送策略,在产生商业价值的同时,优化了用户的浏览体验。
其中,分桶测试的最简单形式为a/b测试,即设定一个基准桶,在设定一个或以上的测试桶,然后考察测试桶(即多个推送策略)与基准通之间在各项指标上的差异,最后确定测试桶的效果(确定最优推送策略)。
分桶测试的高级形式为多变量测试,在多变量测试中,每个可以改变的地方称为因素(比如应用场景),而每个可能具有的状态称为水平(比如不同的算法策略模型),多变量测试允许在同一时间测试多个要素处于不同水平时对于搜索产品的影响,通过多变量测试,能够十分清楚地看到不同的变化组合对最终效果的影响,最终得到最优推送策略。
在上述技术方案中,优选地,确定单元202还用于:根据最优推荐策略,确定场景关键词;输入单元208还用于:将场景关键词输入实时计算引擎,以获取检索到的应用信息;应用信息推送装置200还包括:推送单元220,用于将应用信息推送至指定终端,其中,实时计算引擎由kafka、jstorm以及elasticsearch构造生成。
在该技术方案中,在确定最优推荐策略后,确定场景关键词,以通过实时计算引擎确定需要推送的应用信息,一方面,使用实时计算引擎能够处理复杂的查询需求,另一方面,实时计算引擎由kafka、jstorm以及elasticsearch构造生成,三者完美无缝对接且均有容错和分布式的特性。
其中,kafka指一种高吞吐量的分布式发布订阅消息系统,jstorm指参考storm的实时流式计算框架,elasticsearch指基于lucene的搜索服务器,提供了一个分布式多用户能力的全文搜索引擎。
在上述技术方案中,优选地,还包括:第一持久化单元222,用于将算法策略模型代码持久化成文件,以采用动态加载以及对象反射的方式,将算法策略模型加载至内存中;第二持久化单元224,用于将业务策略规则持久化在文档型数据库中,以在根据连接池技术查询到业务策略规则后缓存在内存中;第三持久化单元226,用于将推送策略的配置信息持久化在管理数据库中。
在该技术方案中,对于算法策略模型,通过将算法工程师提交的代码持久化成文件,采用“动态加载”以及“对象反射”技术将算法加载到内存中,实现算法策略模型持久化;对于业务策略规则,通过将业务测量模型逻辑持久化在mongo等文档型数据库中,利用连接池技术查询到业务规则后缓存在内存中;对于配置策略,将配置策略持久化在mysql等管系统数据库中方便复杂查询,这样即使服务受到各种异常崩溃后,依然能够重启并正常恢复,采用不同模块不同的持久化策略进行容灾,提升服务稳定性和可用性。
图3示出了根据本发明的实施例的服务器的示意框图。
如图3所示,根据本发明的实施例的服务器300,包括:存储器302、处理器304及存储在存储器302上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述任一项应用信息推送方法限定的步骤,和/或包括上述任一项的应用信息推送装置200。
根据本发明的实施例,还提出了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现:响应于应用信息的推送请求,确定对应的多个推送策略;对多个推送策略执行分桶测试,以得到最优推送策略;根据最优推送策略,执行应用信息推送操作,其中,推送策略中包括一个排序器以及至少一个召回器。
在该技术方案中,在接收到应用信息的推送请求时,确定策略配置模块中对应的多个推送策略,通过对多个推送策略进行相同的滚筒测试,以确定一个最优推送策略,并根据最优推送策略执行应用信息的推送操作,实现了对推送策略的优化,在满足商业需求的同时,能够提升用户的浏览效率与浏览体验。
其中,推送请求与推送策略的映射模型,可以根据推送场景建立,也可以根据推送对象建立。
在上述技术方案中,优选地,响应于应用信息推送请求,确定对应的多个推送策略,具体包括以下步骤:确定推送请求对应的应用场景;根据应用场景,确定对应的业务策略规则;将业务策略规则输入预设的算法策略模型,以生成多个推送策略。
在该技术方案中,通过确定推送请求的应用场景,以根据应用场景确定对应的业务策略规则,将业务策略规则作为一个或多个变量输入到算法策略模型中,实现算法与业务之间的组装,从而生成多个推送策略,实现了算法策略模型与业务策略规则之间的解耦,一方面,算法开发人员开发过程中能够不受业务数据的影响,降低了算法开发的复杂性,另一方面,也有利于简化业务人员的业务配置操作。
具体地,算法策略模型中包括多个召回算法模型和排序算法模型,业务策略规则中也包括多个召回规则与排序规则,根据预设条件配置推送策略,进而得到多个推送策略,其中每个推送策略可以有多个召回器但只有一个排序器,召回器之间可以取交集也可以取并集。
另外,对于算法策略模型,也可以采用机器学习算法进行分类预测,并对不同的算法模型进行打分,使算法人员能够充分享受人工智能的乐趣。
需要理解的是,算法策略模型侧重于用户体验,业务策略模型侧重于商业反馈。
在上述技术方案中,优选地,在响应于应用信息推送请求,确定对应的多个推送策略前,还包括:生成与应用场景对应的前端配置接口;接收由前端配置接口输入的业务构造参数,以根据业务构造参数生成业务策略规则,其中,业务策略规则包括召回规则与排序规则,召回规则基于逻辑构造规则生成,排序规则基于权重指标生成。
在该技术方案中,通过生成与应用场景对应的前端配置接口,以接收从前端配置接口输入的业务构造参数,并根据业务构造参数生成业务策略规则,一方面,业务策略规则配置过程简单,另一方面,业务策略规则的构建在考虑商业行为的同时,更加人性化。
具体地,在前端页面显示前端配置接口,并罗列与应用场景相关的配置指标,业务人员构造召回规则时可基于and和or逻辑构造规则,在构造排序规则时通过权重对指标进行线性相加得到最终得分。
在上述技术方案中,优选地,根据对多个推送策略执行分桶测试,以得到最优推送策略,具体包括以下步骤:在接收到应用请求时,对多个推送策略分配相同的测试权限;根据测试权限,记录每个推送策略的召回器根据应用请求召回的用户样本;根据排序器对用户样本进行排序,以根据排序结果生成对应的评价指标;根据每个评价指标,确定最优推送策略。
在该技术方案中,通过执行分桶测试,确定最优推送策略,一方面,对于多个推送策略,在测试过程中具有相同的权重值,即相同的测试权限,提升最优推送策略确定过程的稳定性,另一方面,通过对用户样本进行召回与排序,确定最优推送策略,在产生商业价值的同时,优化了用户的浏览体验。
其中,分桶测试的最简单形式为a/b测试,即设定一个基准桶,在设定一个或以上的测试桶,然后考察测试桶(即多个推送策略)与基准通之间在各项指标上的差异,最后确定测试桶的效果(确定最优推送策略)。
分桶测试的高级形式为多变量测试,在多变量测试中,每个可以改变的地方称为因素(比如应用场景),而每个可能具有的状态称为水平(比如不同的算法策略模型),多变量测试允许在同一时间测试多个要素处于不同水平时对于搜索产品的影响,通过多变量测试,能够十分清楚地看到不同的变化组合对最终效果的影响,最终得到最优推送策略。
在上述技术方案中,优选地,根据最优推送策略,执行应用信息推送操作,具体包括以下步骤:根据最优推荐策略,确定场景关键词;将场景关键词输入实时计算引擎,以获取检索到的应用信息;将应用信息推送至指定终端,其中,实时计算引擎由kafka、jstorm以及elasticsearch构造生成。
在该技术方案中,在确定最优推荐策略后,确定场景关键词,以通过实时计算引擎确定需要推送的应用信息,一方面,使用实时计算引擎能够处理复杂的查询需求,另一方面,实时计算引擎由kafka、jstorm以及elasticsearch构造生成,三者完美无缝对接且均有容错和分布式的特性。
其中,kafka指一种高吞吐量的分布式发布订阅消息系统,jstorm指参考storm的实时流式计算框架,elasticsearch指基于lucene的搜索服务器,提供了一个分布式多用户能力的全文搜索引擎。
在上述技术方案中,优选地,在响应于应用信息推送请求,确定对应的多个推送策略前,还包括:将算法策略模型代码持久化成文件,以采用动态加载以及对象反射的方式,将算法策略模型加载至内存中;以及将业务策略规则持久化在文档型数据库中,以在根据连接池技术查询到业务策略规则后缓存在内存中;以及将推送策略的配置信息持久化在管理数据库中。
在该技术方案中,对于算法策略模型,通过将算法工程师提交的代码持久化成文件,采用“动态加载”以及“对象反射”技术将算法加载到内存中,实现算法策略模型持久化;对于业务策略规则,通过将业务测量模型逻辑持久化在mongo等文档型数据库中,利用连接池技术查询到业务规则后缓存在内存中;对于配置策略,将配置策略持久化在mysql等管系统数据库中方便复杂查询,这样即使服务受到各种异常崩溃后,依然能够重启并正常恢复,采用不同模块不同的持久化策略进行容灾,提升服务稳定性和可用性。
图4示出了根据本发明的实施例的应用信息推送过程的示意流程图。
如图4所示,对于算法策略模型,基于算法sdk402进行算法开发,sdk(软件开发工具包)会严格定义算法的输入和输出,比如使用java开发时得到包括召回和排序两个抽象类的算法策略404,重载抽象类中的方法后打包成jar文件,上传到推送系统中的算法管理模块406。
对于业务策略规则,在前端页面显示前端配置接口408,并罗列与应用场景相关的配置指标,业务人员构造召回规则时可基于and和or逻辑构造规则,在构造排序规则时通过权重对指标进行线性相加得到业务策略410,保存完毕后这些配置同样会上传到推送系统中的业务管理模块412。
当算法策略模型和业务策略规则均完成配置后,算法管理模块406里面会有若干召回和排序算法,业务管理模块412中也会具有若干召回和排序规则,这时可以共同在策略管理池414中组装最后的投放策略。
其中任何推荐策略可以分解为召回和排序两部分,召回部分可以有多个召回器,但排序部分只能有一个排序器。因此在策略管理中,双方可以按照需求配置策略,每个策略可以有多个召回器但只有一个排序器,召回器之间可以取交集也可以取并集。
策略管理池414最终输出是若干个最终需要进行实验的推送策略,当应用请求发送过来后,策略管理池414能够将流量均匀分配到每个推送策略上,从而进行分桶测试,已得到最优推送策略。
采用实时计算引擎416作为存储工具以处理复杂的查询需求,在建立一个新场景时,算法人员需要配置相关数据源来进行投放,实时计算引擎由kafka、jstorm以及elasticsearch构造生成,三者完美无缝对接且均有容错和分布式的特性,最终得到应用推送信息,并推送至指定终端。
另外,对于算法策略模型,也可以采用机器学习算法进行分类预测,并对不同的算法模型进行打分,使算法人员能够充分享受人工智能的乐趣。
对于算法策略模型,通过将算法工程师提交的代码持久化成文件,采用“动态加载”以及“对象反射”技术将算法加载到内存中,实现算法策略模型持久化;对于业务策略规则,通过将业务测量模型逻辑持久化在mongo等文档型数据库中,利用连接池技术查询到业务规则后缓存在内存中;对于配置策略,将配置策略持久化在mysql等管系统数据库中方便复杂查询,这样即使服务受到各种异常崩溃后,依然能够重启并正常恢复,采用不同模块不同的持久化策略进行容灾,提升服务稳定性和可用性。
以上结合附图详细说明了本发明的技术方案,考虑到相关技术提出的信息推送策略开发过程的复杂性高等技术问题,本发明提出了一种应用信息推送方法,通过对多个推送策略进行相同的滚筒测试,以确定一个最优推送策略,并根据最优推送策略执行应用信息的推送操作,实现了对推送策略的优化,在满足商业需求的同时,能够提升用户的浏览效率与浏览体验。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!