融合深度神经网络模型和二进制哈希的人体动作识别方法与流程
本发明属于图像视频处理技术领域,特别涉及一种基于深度神经网络模型结合二进制哈希的人体动作识别方法。
背景技术:
近年来,人体动作识别在模式识别,图像处理与分析等领域的研究取得了很大的进步,目前已有部分人体动作识别系统投入实际使用。人体动作识别算法主要包括动作表示和动作分类两个步骤,如何编码人体动作信息对后续的动作分类是十分关键的一步。理想情况下的动作表示算法不仅要对人体外观、尺度、复杂背景及动作速度的变化,而且包含足够的信息提供给分类器用于动作类型划分。但复杂背景和人体本身的多变性问题给人体动作识别带来极大的挑战。
深度学习方法将短视频看做一系列输入的帧进行处理。很明显,使用单独的帧不足以有效的捕捉动作的动态,而大量帧又需要大量的参数,从而导致模型过拟合,需要更大的训练集,计算复杂度也更高。这个问题也存在于其他流行的CNN架构中,比如Tran.D等人提出的3D卷积网络。因此,最先进的深度动作识别模型通常被训练成从短的视频剪辑生成有用的特征,然后汇集产生整体的序列级别描述符,然后用来训练带有特定动作标签的线性分类器。在Cheron等人提出的PCNN模型中,通过提取视频RGB流的FC层的输出特性并结合使用min或max池化方法来获得视频的特征表示。但是min或max池化方法只捕获了特征之间的一级关联,聚集操作可以更恰当地捕捉到CNN功能之间的高阶关联。
虽然CNN在框架级的功能上可能非常复杂,但我们考虑利用视频帧变化之间的关联性可以捕捉视频的独特性特征这可能有助于提高视频的识别的性能。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种具有更好的识别效果的融合深度神经网络模型和二进制哈希的人体动作识别方法。本发明的技术方案如下:
一种融合深度神经网络模型和二进制哈希的人体动作识别方法,其包括以下步骤:
101、获取包含有人体动作的短视频,并将该短视频切分成视频帧序列;
102、使用光流算法计算步骤101视频帧序列中相邻视频帧的光流图;
103、对101视频帧序列使用姿态估计算法得到人体关节点的坐标;
104、使用步骤103得到的关节点坐标截取不同人体部位的RGB与光流区域图,得到视频的RGB帧序列与光流帧序列;
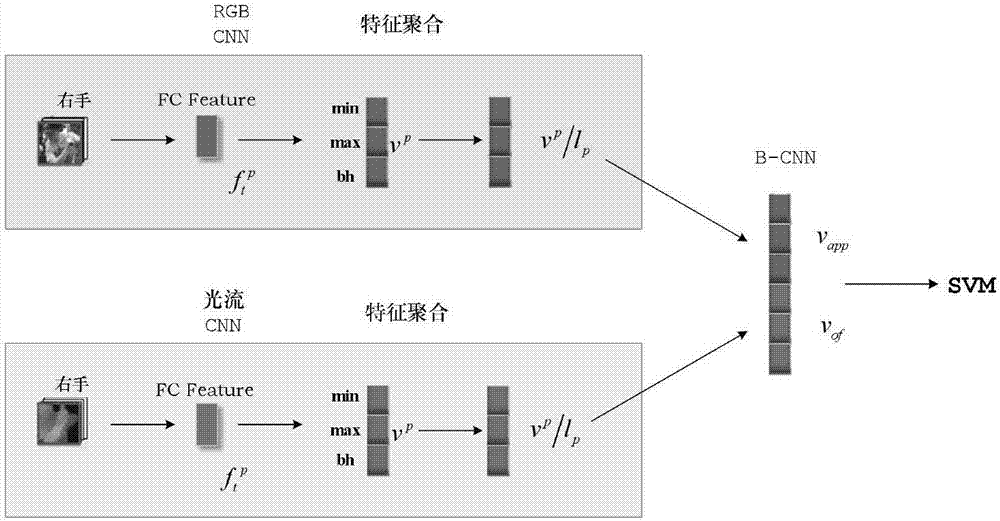
105、使用牛津大学视觉几何组(Visual Geometry Group)的VGG-16模型与光流网络(FlowNet)模型对步骤104得到的RGB帧序列与光流帧序列中的每一帧提取的全连接(Full Connected)层特征,本层特征维度为4096维;
106、使用步骤105得到的FC特征进行池化操作进行聚集,得到n×4096维的视频特征表示;
107、将步骤106得到的视频特征进行l2归一化后送入线性SVM分类器进行分类。
进一步的,所述步骤102使用光流算法计算步骤101相邻视频帧序列的光流图,具体包括步骤:
201.提取两个相邻视频帧之间的光流矢量;
202.对生成的光流矢量的所有像素点处水平方向和垂直方向的绝对值分别求和,得到帧的水平方向和垂直方向的两个光流绝对值的和;
203.将所有帧的光流绝对值和按时间排序生成整个视频水平方向和垂直方向的光流序列。
进一步的,所述步骤104选取视频的RGB帧序列与光流帧序列关的步骤包括:
选取不同的尺寸的滑动窗口尺寸h,并动态的根据视频帧数|F|采集S数目的样本帧并提取特征。fT表示原始视频帧序列中的一帧,其中原始视频共有T帧;表示所选关键帧序列中的一帧,关键帧选取使用公式(2)所示方法,每间隔S帧选取一帧,共选取h帧。
进一步的,所述步骤105为了区分RGB序列与光流序列,使用两种不同架构的卷积网络模型,每个网络均包含了五层的卷积层和三层的全连接层,使用第二个全连接层的输出作为FC特征即视频帧特征,将输入图像统一调整为224×224的大小,这样可以得到一致的FC层特征,我们使用min和max池化操作对一个视频的所有帧特征进行聚合后就得到了视频的特征表示。
进一步的,对选取的关键帧以及对应的4096维的FC特征进行相邻差值计算,使用0,1表示特征的变化趋势,这样就得到一个4096×h大小的矩阵,矩阵中每个元素为0或为1,提取每一行的二进制序列作为输入,使用公式(3)计算输出,这样就得到了视频对应的4096维的二进制哈希特征。
进一步的,所述步骤106计算视频特征值具体包括:比较两个相邻关键帧和特征值变化,对应于视频帧对应的特征向量ftp,比较相邻两帧同一维度上特征值的变化,增加用1表示,减小用0表示,这样可以得到一个4096*h的特征值矩阵M,矩阵元素仅包含0或1,对于矩阵的每一行特征向量[xh-1,xh-2,...,x0]使用以下公式(3)计算其二进制哈希映射,公式(3)将由0和1组成的数字串转化为一个无符号的整数;
最终得到了人体不同部位的RGB流与光流帧特征变化的二进制哈希特征。
进一步的,步骤107除了使用l2归一化以外,还使用了融合l1+β·l2的特征归一化方式,l2表示对特征的二阶归一化,l1表示对特征的一阶归一化,β表示融合归一化系数。当最终把通过深度神经网络提取的特征与二进制哈希得到的特征融合后得到视频的特征表示p,由于不同来源的特征值尺度存在差异,归一化所有特征值到一个尺度再使用分类器分类。
进一步的,所述使用了l1+β·l2融合的归一化方式,即
p=p/(||p||1+β·||p||2) (4)
本发明的优点及有益效果如下:
本发明的创新之处在于:将深度网络模型与二进制哈希方法相融合。考虑到近年来深度卷积神经网络对图像中物体表征问题上的有效性与准确性,所以选择使用涵盖了2万多种物体的Imagenet数据集上预训练的VGG-16网络模型对RGB帧序列提取特征,使用包含了101种动作的UCF101数据集上预训练的深度模型对光流帧序列提取特征。使用二进制哈希方法的简单操作性以及高效性对提取的静态视频帧以及光流帧特征作进一步高阶处理。结合多种特征后使用不同的归一化方法进行训练识别。因而相对于传统的人体动作识别方法,具有更好的识别效果。
附图说明
图1是本发明提供优选实施例姿态估计方法的输出结果图;
图2是本发明提供优选实施例方法的流程图;
图3是二进制哈希算法流程;
图4是:不同归一化方法的比较图。
图5是不同大小的哈希窗口比较图;
图6是不同大小的融合系数比较图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
下面结合附图1-2所示,一种基于深度网络模型和二进制哈希方法的人体动作识别方法包括以下步骤:
1.提取视频的深度特征
将实验的视频库中的样本分为训练集和测试集,并对所有样本提取FC层特征,该提取方法详细步骤如下:
1)对输入视频切分成帧
为了提取视频的局部特征信息,将输入的包含有人体动作的视频切分成帧序列。
2)使用光流算法对RGB帧序列计算光流帧。
3)使用姿态估计算法定位人体的关节点的坐标。
4)根据以上关节点坐标提取RGB帧序列与光流帧序列中人体关节点所在的区域。包括头部、肩部、腰部、肘部。
5)为了区分RGB序列与光流序列,我们使用两种不同架构的卷积网络模型,每个网络均包含了五层的卷积层和三层的全连接层。我们使用第二个全连接层的输出作为FC特征即视频帧特征。我们将输入图像统一调整为224×224的大小,这样我们可以得到一致的FC层特征。我们使用min和max池化操作对一个视频的所有帧特征进行聚合后就得到了视频的特征表示。
2.计算视频的二进制哈希特征
观察可以发现视频的运动特性有时是由部分关键的短时动作区别的。为了进一步捕捉视频的运动特性,我们使用以下步骤计算视频的二进制哈希特征:
1)与提取视频深度特征类似。首先对视频切分成帧,计算光流帧,提取人体关节点坐标,计算不同节点部位的帧序列对应的FC特征。
2)不同的视频有不同的帧数|F|,我们定义滑动窗口大小为h,步长S为|F|/h。每隔相应步长选取关键帧。如图3所示。
3)对选取的关键帧以及对应的4096维的FC特征。我们进行相邻差值计算,使用0,1表示特征的变化趋势。这样我们就得到一个4096×h大小的矩阵,矩阵中每个元素为0或为1.我们提取每一行的二进制序列作为输入,使用公式(3)计算输出。这样我们就得到了视频对应的4096维的二进制哈希特征。
3.融合深度特征与哈希特征
对于以上步骤1,2得到的深度特征与二进制哈希特征我们首先要进行特征融合,再使用SVM分类器进行分类。主要包含以下详细步骤:
1)保存深度特征与哈希特征拼接后的融合特征。
2)使用所有动作视频的融合特征计算特征矩阵的范式与L2范式。
3)对特征矩阵中的所有元素除以l1范式、l2范式进行归一化后得到两种不同的归一化特征。
4)定义融合因子β、l1+β·l2作为融合后的归一化范式得到另一种归一化特征。
5)将以上归一化特征,以及对应动作类别标签送入SVM分类器,选择线性核进行训练。
6)对每一种视频训练一个分类器。标记当前类别为正样本,其他所有类别为负样本。训练多个分类器。
7)对于测试集的视频,使用每一个分类器计算得分,选择得分最高的作为相应动作类别。
本发明的一个实施例如下:
采用JHMDB及MPII-Cooking人体动作库作为实验数据库。
JHMDB动作数据集包含21类人体动作,包括梳头、坐、站、跑步、挥手等。每个视频仅包含了很短的一段视频,包含15-40帧。共有928个视频以及标注好的31838帧。
MPII-Cooking动作数据集包含一系列高分辨率人在厨房中烹饪的动作视频。包含洗盘子、切水果、洗手等动作。每个视频包含一种烹饪活动。共包含了64种类别的烹饪动作,涉及3748个视频片段以及同一个背景。
(1)JHDMB数据集有三种不同的训练集/测试集划分,比例为80/20分。保证可以覆盖到所有动作种类。每个测试划分上计算分类的准确率,使用三种划分的平均成绩作为评价标准。具体测试结果如附图4、附图5所示。使用归一化方法的效果要明显好于使用原始特征进行分类的结果。选取不同大小的哈希窗口,大多数情况下l1归一化优于l2归一化。
我们同样比较了在不同哈希窗口下不同融合系数β对l1+β·l2归一化的影响。实验结果如附图6所示。
(2)我们使用相同的方法在JHMDB数据集与MPII-Cooking数据集上测试了分类效果。如表1所示,分类效果表明融合了深度网络特征与二进制哈希特征的方法要优于之前基于PCNN模型的方法。
表1:在JHDMB数据集与MPII-Cooking数据集上不同归一化方法结合哈希特征对分类结果的影响
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!