一种用于预测葡萄酒饮酒量的方法与流程
本发明涉及中国葡萄酒产业发展研究,尤其涉及一种用于预测葡萄酒饮酒量的方法。
背景技术:
近年来,亚洲葡萄酒产业的发展再次振兴世界葡萄酒产业。中国和日本的葡萄酒消费量占据亚洲市场的近百分之九十。过去十年里,中国葡萄酒市场逐步开阔,得益于中国经济的迅猛发展和人民生活水平的大幅提升,中国葡萄酒产量快速增长。根据国际葡萄与葡萄酒组织的最新数据,2014年,中国已成为世界第八大葡萄酒生产国。
但是,作为世界重要的葡萄酒生产国,中国葡萄酒人均饮酒量较欧洲发达国家依然微乎其微,人均葡萄酒消费量仅占所有酒类的百分之五。中国葡萄酒产业有待发展,存在巨大潜力。
当前,国内外学者纷纷聚焦中国葡萄酒市场,面向中国葡萄酒消费者购买行为及品质偏好的研究成果颇丰。近十年,国内外学者针对中国葡萄酒消费者的感官特征偏好进行了广泛的调研,并有学者围绕中国消费者的购买特征与传统习俗相结合进行剖析,探究中国传统文化对葡萄酒市场发展带来的影响。但现有研究成果大多通过消费者对葡萄酒价格的接受程度来研究其消费行为,关注中国消费者饮酒量的研究成果较少;并且,除葡萄酒价格的影响外,多种因素都会导致饮酒量的大幅波动,缺乏对其系统性的研究。关注中国消费者饮酒量,探究影响饮酒量的关键因素才能从根本上挖掘促进中国葡萄酒市场发展与成长的关键。
技术实现要素:
本发明提供一种克服上述问题或者至少部分地解决上述问题的一种用于预测葡萄酒饮酒量的方法,以解决现有技术中研究饮酒量的变化时的影响因素单一、缺乏系统性研究的技术问题。
根据本发明的一个方面,提供一种用于预测葡萄酒饮酒量的方法,包括:将影响饮酒量的多个因素作为原始变量,并对所述原始变量与所述饮酒量进行相关性分析得到与所述饮酒量相关性大的特征变量,建立有关所述特征变量与所述饮酒量的线性回归模型,对所述饮酒量的变化进行预测。
本发明实施例提供的一种用于预测葡萄酒饮酒量的方法,通过对所选择的多个原始变量进行赋值,并采用相关性分析方法分析,以筛选去除对葡萄酒饮酒量影响较小的变量而得到特征变量,其能够精简数据分析过程,提取对饮酒量变化较大的因素;通过对多个原始变量与饮酒量的关联分析,以对饮酒量变化系统性研究;
在此基础上,再通过多元线性回归,逐步引入和移除特征变量,建立线性回归模型,通过系数检验得到模型中包含的各个变量对应的系数以及常量,从而可以得到预测公式;
线性回归模型中所包含的变量可以看出对我国葡萄酒消费者饮酒量变化趋势、造成主要影响的变量以及他们之间的关系。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
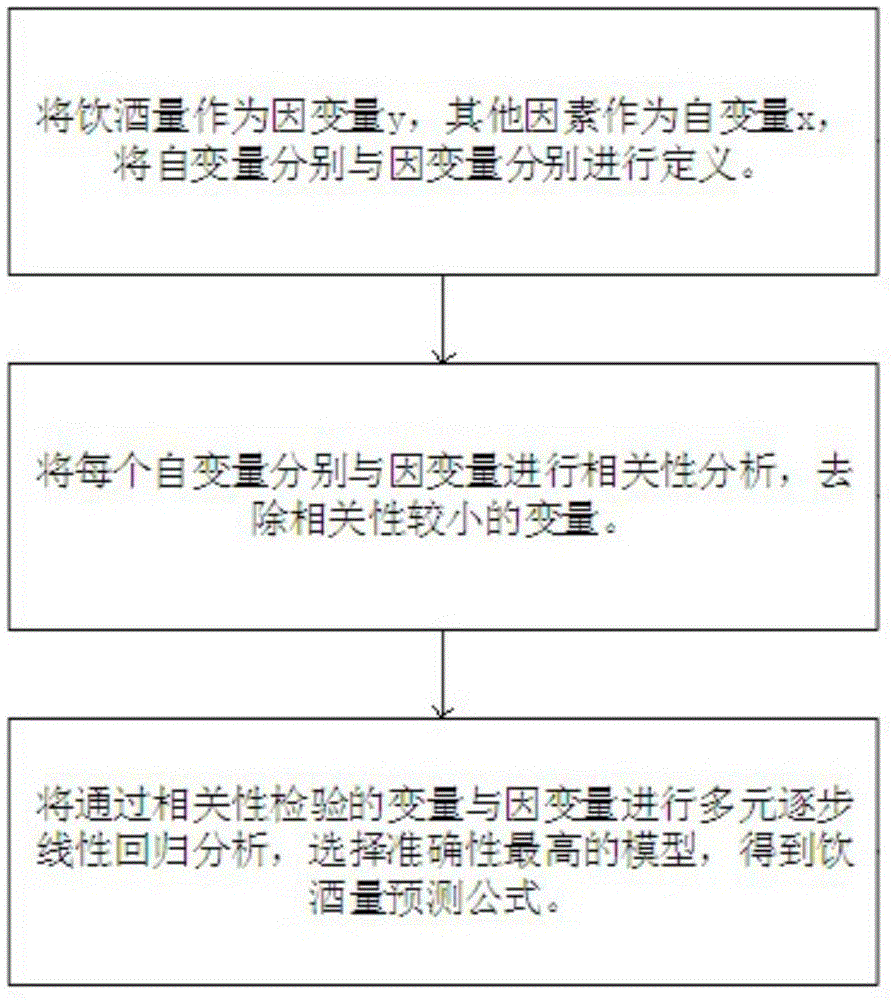
图1为根据本发明实施例中一种用于预测葡萄酒饮酒量的方法的流程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见图1所示,一种用于预测葡萄酒饮酒量的方法,包括:将影响饮酒量的多个因素作为原始变量,并对所述原始变量与所述饮酒量进行相关性分析得到与所述饮酒量相关性大的特征变量,建立有关所述特征变量与所述饮酒量的线性回归模型,对实际饮酒量进行预测。
作为影响饮酒量的因素,可结合中国市场现状、文献以及相关专家意见等,设计中国葡萄酒消费者决策行为调查问卷,并根据调查问卷对消费者进行面对面调研以获取调研数据。获取调研数据的样本遍布中国各大省份,并综合考虑人口年龄、性别分布等因素。
获取影响葡萄酒饮酒量的调研数据后,将其作为原始变量。可以理解的是,由于影响饮酒量的因素较多,该原始变量可以有多个。并且,以各原始变量为自变量,采用相关性分析方法,确定原始变量与饮酒量的相关性。采用相关性分析方法对原始变量进行筛选,筛除跟饮酒量相关性小的原始变量,将与饮酒量相关性大的原始变量作为特征变量以进行后续分析。即筛除对饮酒量变化影响较小的原始变量,可以确保分析准确性的同时精简数据分析量。可以理解的是,经过相关性分析后所获取的特征变量依然可以是多个。
获取对饮酒量变化影响较大的特征变量后,建立特征变量与饮酒量的线性回归模型,该线性回归模型能够很好的反映特征变量与饮酒量之间的关系。利用该线性回归模型对实际饮酒量进行准确预测,进而获取对饮酒量变化影响较大的原始变量,以利于探究影响饮酒量的关键因素。
在一个具体的实施例中,原始变量包括葡萄酒消费者购买行为特征、消费者对葡萄酒产地的偏好、消费者对葡萄酒口味的偏好以及消费者个人信息。通过对消费者的个人信息、购买行为、产地偏好、口味偏好等因素综合考虑,能够提高消费者对葡萄酒饮酒量预测的准确性。
具体地,上述影响消费者葡萄酒饮酒量的原始变量可进一步细分为如下58个原始变量,见表1。该58个原始变量x可表述为:x={x1,x2,x3……xi}(i=58)。
表1:原始变量名称及定义
具体地,根据各原始变量的特性对上述各原始变量进行赋值。例如,可根据消费者对某种口味的偏好进行赋值;当倾向于购买该种口味的葡萄酒时,可赋值为1,不喜欢该口味的葡萄酒时,可赋值为0。对各原始变量进行赋值,以便于后续对各原始变量与饮酒量的相关性进行量化分析。涉及购买行为或个人信息的变量根据调研问卷中选项设置的顺序进行赋值(如学历一项中,问题设置中从“小学”至“研究生及以上”共设置4个选项,分别赋值为1/2/3/4)。
在一个具体的实施例中,根据葡萄酒消费者每年饮酒量的多少划分饮酒量等级,并对各饮酒量等级赋值。具体地,按照葡萄酒消费者每年饮酒量(以瓶/年计)的多少将饮酒量有少到多划分为多个等级。例如,可按照消费者每年饮酒量的多少将饮酒量划分为三个等级;并分别赋值为1、2和3。根据对各原始变量和饮酒量进行赋值后,将各原始变量作为自变量,将饮酒量作为因变量,以进行相应分析。
在一个具体的实施例中,所述相关性分析采用斯皮尔曼等级相关系数,利用双变量的秩次大小进行相关性分析。具体地,对各原始变量均进行赋值后,以各原始变量为自变量、以饮酒量为因变量,进行相关性分析。在对各原始变量与饮酒量进行相关性分析时,利用双变量的秩次大小作为分析对象,可以不关注各原始变量的分析类型,从而增强了饮酒量影响因素量化分析的便捷性。
具体地,当选用上述58个原始变量并相应赋值后,同时,采用斯皮尔曼等级相关系数、利用双变量秩次大小进行相关性分析时,其相关性结果参见表2所示。
表2:相关性分析结果
各原始变量的相关性分析参数,可以筛选于因变量相关性弱的变量,即可以去除对饮酒量变化影响较小的原始变量,从而精简数据处理复杂程度,同时,能够提高预估饮酒量变化的准确性,避免相关性弱的因素的不利影响。由表2中的数据可以看出,x1,x2,x3,x6,x7,x12,x13,x21,x22,x23,x24,x25,x27,x29,x31,x35,x37,x38,x39,x42,x43,x44,x45,x46,x48,x49,x50,x51,x53,x54,x55,x57,x58等对饮酒量变化的影响较大,可以将上述33个原始变量作为特征变量,以进一步分析影响饮酒量变化的趋势或条件。
在一个具体的实施例中,所述原始变量进行相关性分析的相关性系数大于0.5时,将所述原始变量作为特征变量。在对原始变量进行相关性分析时,通过设置相关性系数阈值,对各原始变量的相关性进行筛选。具体地,在采用双变量的秩次大小进行相关性分析时,将相关性系数阈值设置为0.5,能够有效去除冗余变量。
在一个具体的实施例中,以特征变量为自变量、以饮酒量为因变量,采用逐步回归法建立线性回归模型。例如,以所选择的58个原始变量与饮酒量进行相关性分析后,将筛选所得的33个特征变量作为因变量,其与饮酒量采用逐步回归法建立线性回归模型。
采用逐步回归的方法,在每引入一个特征变量后都进行相应的检测,能够增强所构建模型对饮酒量变化进行预测的准确性,以利于获取对饮酒量影响较大的因素。以下列11个特征变量为例,其逐步回归的过程参数参见表3。
表3:特征变量进入/移除情况
对每个特征变量与饮酒量均采用简单回归,确定对饮酒量变化影响最大的特征变量所对应的回归方程为基础,对其他各特征变量进行检验。由表3可以看出,由于所选择的回归方程的拟合度较好,因此,从表3中看到只有变量进入,没有变量被移除。
在不断引入特征变量的过程中,其进行检验的过程参数可参见表4。
表4:模型汇总
在引入的各特征变量并进行检验的过程中,可以选择最优的模型,由其检验过程中的对应参数,即可得到最终的线性回归模型。以上述11个特征变量为例,第11个模型的效果最好,对应给出其偏回归系数和标准偏回归系数,参见表5。
表5:系数
由表5中的参数,即可得到线性回归模型的具体表达式为:
y=2.439-0.362x1+2.439x2+0.034x57-0.189x37+0.042x6+0.08x53+0.178x21+0.134x7+0.123x31-0.173x3+0.155x50。
其中,x1、x2、x3、x6、x7、x21、x31、x37、x50、x53、x57所对应的特征变量名称分别为购买频率、购买葡萄酒的价位、送礼、自饮、国产/进口、德国、酒类专卖店、干红、橡木味浓郁型、年龄和职业。
通过该公式可以对中国葡萄酒消费者的实际饮酒量进行预测。由上述公式中也可以看出对葡萄酒饮酒量影响较大的因素。
本发明的用于预测葡萄酒饮酒量的方法,通过对所选择的原始变量进行赋值,并采用相关性分析方法分析,以筛选去除对葡萄酒饮酒量影响较小的变量以获取对饮酒量变化影响较大的特征变量,简化数据分析过程;再采用逐步回归分析方法进一步对特征变量进行筛选和建模,以建立线性回归模型,即能够对葡萄酒饮酒量进行预测,还能够获取对显著影响饮酒量变化的因素以进行进一步分析。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!