图像识别方法及装置与流程
本发明涉及图像处理领域,尤其涉及一种图像识别方法及装置。
背景技术:
随着电子设备的迅速发展,其所具备的计算能力、存储能力、待机能力等也随之增强。由此,基于卷积神经网络模型的图像识别智能服务已开始部署在各类型电子设备上,例如,由移动终端提供人脸识别、由嵌入式设备提供的手势识别、障碍回避、智能导航等等。
目前,卷积神经网络模型中卷积层所涉及的计算量很大,极易耗尽电子设备的计算资源、存储资源等,而影响电子设备响应其他服务的效率。为此,针对卷积神经网络模型广泛使用的3×3卷积核,提出了一种winograd F(2x2,3x3)算法,该算法的理论加速比是2.25X。
然而,在实际应用时,该算法的计算效率并不高,尚无法达到理论加速比,进而导致现有的图像识别方法仍存在电子设备所部署的卷积神经网络模型计算效率低下的缺陷。
技术实现要素:
为了解决上述技术问题,本发明的一个目的在于提供一种图像识别方法及装置。
其中,本发明所采用的技术方案为:
一种图像识别方法,包括:为图像识别所部署的卷积神经网络模型中,通过卷积层输入通道从目标图像中提取得到多个输入矩阵;遍历多个所述输入矩阵,通过行变换重构对遍历到的所述输入矩阵执行输入变换及对应的卷积核变换,分别得到第一结果矩阵和第二结果矩阵;对所述第一结果矩阵与所述第二结果矩阵进行矩阵乘法重构得到待变换矩阵;通过行变换重构对所述待变换矩阵执行输出变换,直至所有输入矩阵遍历完毕,由所述卷积层输出通道输出得到多个输出矩阵;进行多个所述输出矩阵的拼接,根据拼接得到的卷积结果对所述目标图像进行深度学习。
一种图像识别装置,其特征在于,包括:输入矩阵提取模块,用于为图像识别所部署的卷积神经网络模型中,通过卷积层输入通道从目标图像中提取得到多个输入矩阵;结果矩阵获取模块,用于遍历多个所述输入矩阵,通过行变换重构对遍历到的所述输入矩阵执行输入变换及对应的卷积核变换,分别得到第一结果矩阵和第二结果矩阵;待变换矩阵获取模块,用于对所述第一结果矩阵与所述第二结果矩阵进行矩阵乘法重构得到待变换矩阵;输出矩阵获取模块,用于通过行变换重构对所述待变换矩阵执行输出变换,直至所有输入矩阵遍历完毕,由所述卷积层输出通道输出得到多个输出矩阵;卷积结果获取模块,用于进行多个所述输出矩阵的拼接,根据拼接得到的卷积结果对所述目标图像进行深度学习。
一种图像识别装置,包括处理器及存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时实现如上所述的图像识别方法。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的图像识别方法。
在上述技术方案中,为图像识别所部署的卷积神经网络模型中,通过卷积层输入通道从目标图像中提取得到多个输入矩阵,遍历多个输入矩阵,以通过行变换重构对遍历到的输入矩阵执行输入变换及对应的卷积核变换,分别得到第一结果矩阵和第二结果矩阵,并对第一结果矩阵和第二结果矩阵进行矩阵乘法重构得到待变换矩阵,进而通过行变换重构对待变换矩阵执行输出变换,直至所有输入矩阵遍历完毕,由卷积层输出通道输出得到多个输出矩阵,最终通过拼接多个输出矩阵所得到的卷积结果对目标图像进行深度学习。
由此,通过卷积层中的多次行变换重构和一次矩阵乘法重构,避免卷积层中执行多次矩阵乘法和一次逐元素乘法,以此大幅度降低了卷积层的计算量,且有效地提高了卷积神经网络模型的计算效率,进而有利于提高图像识别的效率。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并于说明书一起用于解释本发明的原理。
图1是现有技术所涉及的卷积神经网络模型不同算法阶段的示意图。
图2是根据本发明所涉及的实施环境的示意图。
图3是根据一示例性实施例示出的一种图像识别装置的硬件结构框图。
图4是根据一示例性实施例示出的一种图像识别方法的流程图。
图5是图4对应实施例中步骤310在一个实施例的流程图。
图6是根据本发明所涉及的滑动窗口的滑动示意图。
图7是图4对应实施例中步骤330在一个实施例的流程图。
图8是图4对应实施例中步骤370在一个实施例的流程图。
图9是根据一示例性实施例示出的行变换重构过程的方法流程图。
图10是图4对应实施例中步骤350在一个实施例的流程图。
图11是一应用场景中一种图像识别方法的具体实现示意图。
图12是根据本发明所涉及的图像识别方法的图像识别性能与其他算法的比较示意图。
图13是根据一示例性实施例示出的一种图像识别装置的框图。
图14是图13对应实施例中输入矩阵提取模块在一个实施例的框图。
图15是图13对应实施例中结果矩阵获取模块在一个实施例的框图。
图16是图13对应实施例中输出矩阵获取模块在一个实施例的框图。
图17是根据一示例性实施例示出的重构单元的框图。
图18是图13对应实施例中待变换矩阵获取模块在一个实施例的框图。
通过上述附图,已示出本发明明确的实施例,后文中将有更详细的描述,这些附图和文字描述并不是为了通过任何方式限制本发明构思的范围,而是通过参考特定实施例为本领域技术人员说明本发明的概念。
具体实施方式
这里将详细地对示例性实施例执行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
如前所述,针对卷积神经网络模型广泛使用的3×3卷积核,所提出的一种winograd F(2x2,3x3)算法,在实际应用中计算效率并不高,尚无法达到理论加速比2.25X。
其中,F(2x2,3x3)表示winograd算法中输出矩阵为2x2矩阵,而卷积核矩阵为3x3矩阵。
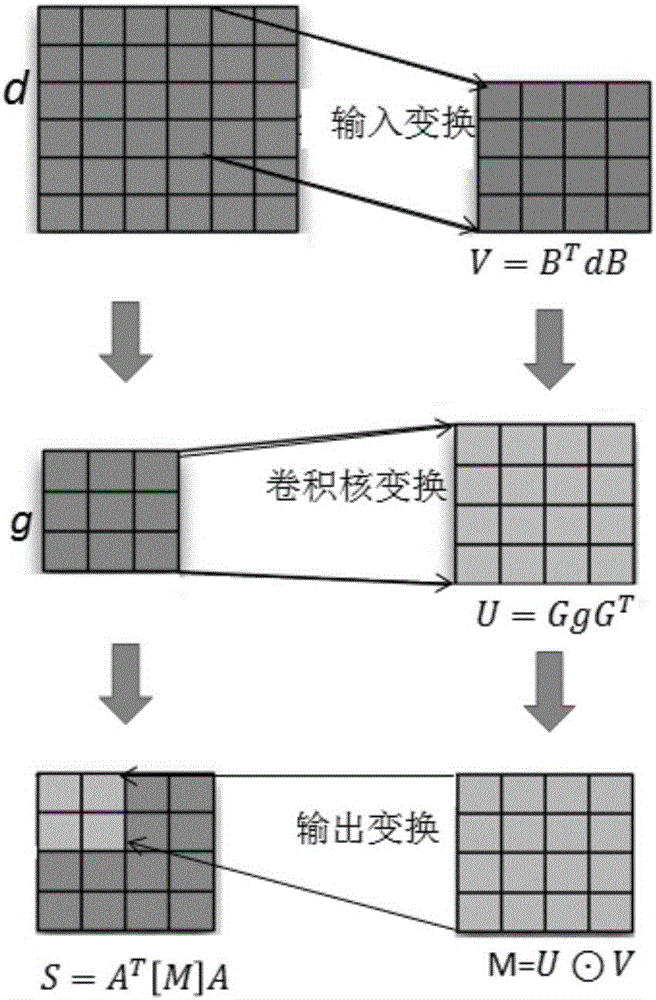
具体地,如图1所示,该算法包括四个关键阶段:
1)、输入变换:V=BTdB(1)
2)、卷积核变换:U=GgGT(2)
3)、乘法:M=U⊙V(3)
4)、输出变换:S=ATMA(4)。
其中,对于图像识别所部署的卷积神经网络模型而言,d为输入矩阵,g为对应于输入矩阵d的卷积核矩阵,B\G\A以及BT\GT\AT为已知参数矩阵,V为输入变换结果矩阵,U为卷积核变换结果矩阵,M为待输出变换矩阵,S为输出矩阵。
由上可知,上述三个变换中需要执行6次矩阵乘法,计算指令开销大,极容易耗尽电子设备的计算资源、存储资源等。
此外,对于输入变换结果矩阵V和卷积核变换结果矩阵U所执行的乘法而言,其定义为逐元素乘法,该逐元素乘法操作属于BLAS-1级的矩阵操作,实质上并不适合具备冯诺依曼体系结构的电子设备,因此相较于直接计算方式虽然计算量大幅减少,但是计算效率低下而导致计算量大幅减少的优势被抵消,反而使得加速比相对于直接计算方式的加速比并未改善多少。
由此,现有的图像识别方法仍存在电子设备所部署的卷积神经网络模型计算效率低下的缺陷。
而对于通过专用硬件加速,不仅实现成本过高,而且不具备兼容性;对于模型压缩而言,在保证计算精度的前提下虽然具有非常高的压缩率,但是仍然无法保证加速比能够有效地被改善。
为此,本发明特提出了一种高效的图像识别方法,相应地,该种图像识别方法所对应的图像识别装置适用于具备冯诺依曼体系结构的电子设备,例如,智能手机、平板电脑等等。
图2为一种图像识别方法所涉及的实施环境的示意图。该实施环境包括图像识别装置100和服务端200。
其中,图像识别装置100可以是平板电脑、掌上电脑、智能手机、无人机、机器人、智能便携设备(例如智能眼镜、智能相机等)或者其他部署了卷积神经网络模型的电子设备,在此不进行限定。
服务端200通过无线网络或者有线网络与图像识别装置100之间建立通信连接,以通过该通信连接与图像识别装置100实现数据传输。例如,所传输数据包括存储为文件形式的卷积神经网络模型。其中,该服务端200可以是一台服务器,也可以是由多台服务器构成的服务器集群,在此也不进行限定。
对于服务端200而言,通过大量的训练样本进行卷积神经网络模型的模型训练,并将训练得到的卷积神经网络模型存储为文件形式,下发至图像识别装置100。
通过图像识别装置100与服务端200的交互,图像识别装置100将接收到服务端200下发的卷积神经网络模型,进而通过卷积神经网络模型进行图像识别,以为用户提供图像识别智能服务,例如,人脸识别、手势识别、文本识别等等。
请参阅图3,图3是根据一示例性实施例示出的一种图像识别装置的框图。
需要说明的是,该图像识别装置只是一个适配于本发明的示例,不能认为是提供了对本发明的使用范围的任何限制。该图像识别装置也不能解释为需要依赖于或者必须具有图3中示出的示例性的图像识别装置100中的一个或者多个组件。
如图3所示,图像识别装置100包括存储器101、存储控制器103、一个或多个(图3中仅示出一个)处理器105、外设接口107、射频模块109、定位模块111、摄像模块113、音频模块115、触控屏幕117以及按键模块119。这些组件通过一条或多条通讯总线/信号线121相互通讯。
其中,存储器101可用于存储计算机程序以及模块,如本发明示例性实施例中的图像识别方法及装置对应的计算机可读指令及模块,处理器105通过运行存储在存储器101内的计算机可读指令,从而执行各种功能以及数据处理,即完成图像识别方法。
存储器101作为资源存储的载体,可以是随机存储器、例如高速随机存储器、非易失性存储器,如一个或多个磁性存储装置、闪存、或者其它固态存储器。存储方式可以是短暂存储或者永久存储。
外设接口107可以包括至少一有线或无线网络接口、至少一串并联转换接口、至少一输入输出接口以及至少一USB接口等,用于将外部各种输入/输出装置耦合至存储器101以及处理器105,以实现与外部各种输入/输出装置的通信。
射频模块109用于收发电磁波,实现电磁波与电信号的相互转换,从而通过通讯网络与其他设备进行通讯。通信网络包括蜂窝式电话网、无线局域网或者城域网,上述通信网络可以使用各种通信标准、协议及技术。
定位模块111用于获取图像识别装置100的当前所在的地理位置。定位模块111的实例包括但不限于全球卫星定位系统(GPS)、基于无线局域网或者移动通信网的定位技术。
摄像模块113隶属于摄像头,用于拍摄图片或者视频。拍摄的图片或者视频可以存储至存储器101内,还可以通过射频模块109发送至上位机。
音频模块115向用户提供音频接口,其可包括一个或多个麦克风接口、一个或多个扬声器接口以及一个或多个耳机接口。通过音频接口与其它设备进行音频数据的交互。音频数据可以存储至存储器101内,还可以通过射频模块109发送。
触控屏幕117在图像识别装置100与用户之间提供一个输入输出界面。具体地,用户可通过触控屏幕117进行输入操作,例如点击、触摸、滑动等手势操作,以使图像识别装置100对该输入操作进行响应。图像识别装置100则将文字、图片或者视频任意一种形式或者组合所形成的输出内容通过触控屏幕117向用户显示输出。
按键模块119包括至少一个按键,用以提供用户向图像识别装置100进行输入的接口,用户可以通过按下不同的按键使图像识别装置100执行不同的功能。例如,声音调节按键可供用户实现对图像识别装置100播放的声音音量的调节。
可以理解,图3所示的结构仅为示意,图像识别装置还可包括比图3中所示更多或更少的组件,或者具有与图3所示不同的组件。图3中所示的各组件可以采用硬件、软件或者其组合来实现。
请参阅图4,在一示例性实施例中,一种图像识别方法适用于图1所示实施环境的图像识别装置,该图像识别装置的结构可以如图3所示。
该种图像识别方法可以由图像识别装置执行,可以包括以下步骤:
步骤310,为图像识别所部署的卷积神经网络模型中,通过卷积层输入通道从目标图像中提取得到多个输入矩阵。
首先说明的是,卷积神经网络模型,为图像识别而部署,包括卷积层、池化层、全连接层、损失层。
由此,对于图像识别而言,即是将目标图像输入至卷积层进行特征提取,并进一步经过池化层的特征压缩、全连接层对池化层输出的特征进行连接,进而输入至损失层,最终通过计算损失层的损失得到图像识别结果。
其中,目标图像,可以为人脸图片、手势图片、文本图片等等,本实施例不对目标图像的类型作具体限定。相应地,由于目标图像的不同类型可对应于不同的应用场景,例如,人脸图片可对应人脸识别场景,手势图片可对应手势识别场景,文本图片可对应文本识别场景,因此,本实施例所提供的图像识别方法可根据目标图像的不同类型而适用于不同的应用场景,本实施例也并未对此进行限定。
如前所述,由于卷积神经网络模型中卷积层计算量很大,而针对3×3卷积核提出的winograd F(2x2,3x3)算法中涉及的三个变换和一个乘法,使得单卷积层中就需要执行6次矩阵乘法和1次逐元素乘法,进而导致卷积神经网络模型计算效率低下。
为此,本实施例中,通过卷积层中的多次行变换重构和一次矩阵乘法重构,避免卷积层中执行多次矩阵乘法和一次逐元素乘法,以此大幅度降低卷积层的计算量,进而提高卷积神经网络模型的计算效率。首先,如图1所示,获取输入矩阵d。
卷积神经网络模型中,一个卷积层可接收N个携带C个输入通道,且尺寸为H×W的图像,因此,输入矩阵d的获取,具体而言就是,通过卷积层的C个输入通道从N个尺寸为H×W目标图像中提取得到的。
在此补充说明的是,图像本质上是一个包含了多个像素的二维矩阵,由此,图像尺寸是基于图像中的像素而言的,例如,尺寸为H×W的目标图像,即是指目标图像的每行包含H个像素,而目标图像的每列包含W个像素。
在一实施例的具体实现中,输入矩阵d的获取,包括:先对目标图像中的像素进行图像分割,进而将分割图像由卷积层的多个输入通道输出得到。
步骤330,遍历多个输入矩阵,通过行变换重构对遍历到的输入矩阵执行输入变换及对应的卷积核变换分别得到第一结果矩阵和第二结果矩阵。
在得到多个输入矩阵之后,便需要对该多个输入矩阵执行输入变换及对应卷积核变换的遍历,以相应得到第一结果矩阵和第二结果矩阵。
应当说明的是,卷积核变换,是通过输入矩阵对应的卷积核矩阵实现的,该卷积核矩阵是在对卷积神经网络模型进行模型训练时生成的。也就是说,模型训练时,通过大量的训练样本,为输入矩阵训练出对应的卷积核矩阵,并以此建立输入矩阵与卷积核矩阵之间的对应关系,以便于后续图像识别时使用。
本实施例中,对输入矩阵执行输入变换及对应的卷积核变换是通过行变换重构实现的,以此减少上述变换中的计算指令开销。
具体而言,通过输入参数矩阵对输入矩阵进行行变换得到第一结果矩阵,并通过卷积参数矩阵对卷积核矩阵进行行变换得到第二结果矩阵。
其中,输入参数矩阵和卷积参数矩阵是由已知参数矩阵B\G\BT\GT得到的,亦视为已知参数矩阵。第一结果矩阵是由输入变换结果矩阵转换得到的,第二结果矩阵是由卷积核变换结果矩阵转换得到的。
进一步地,输入参数矩阵为BT,卷积参数矩阵为G,第一结果矩阵为VT,即输入变换结果矩阵的转置,第二结果矩阵为UT,即卷积核变换结果矩阵的转置。
由此,将输入变换以及卷积核变换中的多次矩阵乘法转换为对输入矩阵和卷积核矩阵所进行的行变换,避免输入变换以及卷积核变换中较大的计算指令开销,从而有利于卷积神经网络模型的计算效率。
步骤350,对第一结果矩阵与第二结果矩阵进行矩阵乘法重构得到待变换矩阵。
如前所述,输入变换结果矩阵和卷积核变换结果矩阵所执行的逐元素乘法属于BLAS-1级的矩阵操作,并不适用于具备冯诺依曼体系结构的电子设备,而导致计算效率低下。
为此,本实施例中,针对与输入变换结果矩阵相关的第一结果矩阵和与卷积核变换结果矩阵相关的第二结果矩阵,将逐元素乘法重构为矩阵乘法,使得BLAS-1级的矩阵操作被转化为BLAS-3级的矩阵操作,将大幅度提升计算效率,同时有利于提高图像识别方法的兼容性。
步骤370,通过行变换重构对待变换矩阵执行输出变换,直至所有输入矩阵遍历完毕,由卷积层输出通道输出得到多个输出矩阵。
如前所述,输出变换中的多次矩阵乘法,使得计算指令开销大,极容易耗尽电子设备的计算资源、存储资源等。
因此,本实施例中,将待变换矩阵执行的输出变换通过行变换重构实现。
具体地,通过输出参数矩阵对待变换矩阵进行行变换得到输出矩阵。
其中,输出参数矩阵是由已知参数矩阵A\AT得到的,亦视为已知参数矩阵。待变换矩阵是由待输出变换矩阵转换得到的。
进一步地,输出参数矩阵为AT,待变换矩阵为MT,即待输出变换矩阵的转置。
由此,将输出变换中的多次矩阵乘法转换为对输出矩阵所进行的行变换,避免输出变换中较大的计算指令开销,进一步有利于卷积神经网络模型的计算效率。
进一步地,对于输入矩阵,在经过输入变换、卷积核变换、输出变换之后,便由卷积层的输出通道输出为输出矩阵。为此,待所有输入矩阵完成遍历,即可通过卷积层的多个输出通道相应得到多个输出矩阵。
步骤390,进行多个输出矩阵的拼接,根据拼接得到的卷积结果对目标图像进行深度学习。
如前所述,输入矩阵是通过目标图像进行图像分割相应得到的,为此,卷积结果将根据多个输出矩阵进行拼接得到。
在得到卷积结果之后,便对目标图像执行后续的深度学习。
具体地,卷积结果即视为目标图像输入至卷积层所提取出的特征,将进一步经过池化层的特征压缩、全连接层对池化层输出的特征进行连接,进而输入至损失层,最终通过计算损失层的损失得到图像识别结果。
也可以理解为,卷积结果仅描述了目标图像的局部特征,后续全连接层的输出则用于描述目标图像的全局特征,并基于该全局特征得到最终的图形识别结果,进而完成了对目标图像的深度学习。
通过如上所述的过程,使得卷积层中不必执行多次矩阵乘法和一次逐元素乘法,而是被多次行变换和一次矩阵乘法替代,以此大幅度降低了卷积层的计算量,且有效地提高了卷积神经网络模型的计算效率,进而充分地保证了图像识别的效率。
请参阅图5,在一示例性实施例中,步骤310可以包括以下步骤:
步骤311,控制滑动窗口在目标图像中滑动,对目标图像中的像素进行图像分隔,得到分割图像。
步骤313,将分割图像由卷积层的输入通道输出得到滑动窗口指定大小的多个输入矩阵。
本实施例中,图像分割依赖于滑动窗口实现,滑动窗口的指定大小和指定滑动距离均可以根据应用场景的不同需求而灵活地设定,在此不加以限定。
较优地,滑动窗口的指定大小4×4,以适用于winograd F(2x2,3x3)算法。
进一步地,滑动窗口的指定滑动距离为2,是指每一次滑动窗口所滑动的距离是按行排列的2个元素。
如图6所示,滑动窗口的指定大小401为4×4,指定滑动距离402为2个元素,随着滑动窗口在目标图像input中的滑动,目标图像input中的像素被分割为若干分割图像(例如401、403、404),且每个分割图像所包含的像素为4×4。
在此补充说明的是,如果滑动窗口移动至目标图像的边缘位置处时,目标图像边缘位置处所包含的像素不足以填充滑动窗口时,则以空白图像填充,即通过像素值为0的像素进行填充。
由此,对于尺寸为H×W目标图像而言,输入变换的次数将由H×W减少为(H-2)(W-2)/2×2,以此减少计算量,进而有利于提高计算效率。
相应地,在一示例性实施例中,步骤390可以包括以下步骤:
按照滑动窗口在目标图像中的滑动位置对多个输出矩阵进行拼接,得到卷积结果。
也就是说,卷积结果的拼接,是与滑动窗口所执行的图像分割相对应的,即,对于在输入矩阵经历输入变换、卷积核变换、输出变换之后,由卷积层输出通道输出所得到的输出矩阵而言,该输出矩阵在卷积结果中的拼接位置,即是通过卷积层输入通道输出得到该输入矩阵的分割图像在目标图像中的滑动位置。
如图6所示,对于分割图像401、403、404在目标图像中的滑动位置来说,输出矩阵在卷积结果output中的拼接位置分别为405、406、407。
在上述实施例的作用下,实现了目标图像的图像分割和卷积结果的拼接,进而充分地保障了卷积层对目标图像的局部特征学习。
请参阅图7,在一示例性实施例中,步骤330可以包括以下步骤:
步骤331,通过输入参数矩阵对遍历到的输入矩阵进行行变换得到第一结果矩阵。
如前所述,输入变换如以下计算公式所示:
V=BTdB (1)
其中,d为输入矩阵,B及BT为已知参数矩阵。
步骤333,获取输入矩阵对应的卷积核矩阵,并通过卷积参数矩阵对卷积核矩阵进行行变换得到第二结果矩阵。
如前所述,卷积核变换如以下计算公式所示:
U=GgGT (2)
其中,g为对应于输入矩阵d的卷积核矩阵,G及GT为已知参数矩阵。
由上可知,无论是输入变换还是卷积核变换,已知参数矩阵均包含数值为0的元素,如果按照通用的矩阵乘法进行计算将导致上述变换的计算指令开销很大,不利于提高卷积神经网络模型的计算效率。
因此,通过行变换重构仅执行上述变换中的必要计算,即仅计算其中数值不为0的元素,以此减少计算指令开销。
以输入变换为例进行说明,将公式(1)重构为公式(5):
VT=BT(BTd)T (5)。
其中,VT为第一结果矩阵,BT为输入参数矩阵,d为输入矩阵。
由此,输入变换中,从原先的输入矩阵d分别左乘一个已知参数矩阵BT和右乘一个已知参数矩阵B,重构为通过输入参数矩阵BT对输入矩阵d执行两次左乘,进而使得输入参数矩阵BT中仅有数值不为0的元素才会参与输入矩阵d的行变换得以实现。
同理,卷积核变换,将公式(2)重构为公式(6):
UT=G(Gg)T (6)
其中,UT为第二结果矩阵,G为卷积参数矩阵,g为卷积核矩阵。
由此,卷积核变换中,从原先的卷积核矩阵g分别左乘一个已知参数矩阵G和右乘一个已知参数矩阵GT,重构为通过卷积参数矩阵G对卷积核矩阵g执行两次左乘,进而使得卷积参数矩阵G中仅有数值不为0的元素才会参与卷积核矩阵g的行变换得以实现。
相应地,请参阅图8,在一示例性实施例中,步骤370可以包括以下步骤:
步骤371,通过输出参数矩阵对待变换矩阵进行行变换。
步骤373,待所有输入矩阵遍历完毕,由卷积层输出通道输出得到多个输出矩阵。
如前所述,输出变换如以下计算公式所示:
S=ATMA (4)
其中,S为输出矩阵,A及AT为已知参数矩阵。
由上可知,对于输出变换而言,已知参数矩阵也包含数值为0的元素,如果按照通用的矩阵乘法进行计算仍然会导致输出变换的计算指令开销很大,不利于提高卷积神经网络模型的计算效率。
因此,通过行变换重构仅执行输出变换中的必要计算,即仅计算其中数值不为0的元素,以此减少计算指令开销。
具体地,将公式(4)重构为公式(7):
S=AT(ATMT)T (7)。
其中,MT为待变换矩阵,AT为输出参数矩阵,S为输出矩阵。
由此,输出变换中,从原先的待输出变换矩阵M分别左乘一个已知参数矩阵AT和右乘一个已知参数矩阵A,重构为通过输出参数矩阵AT对待变换矩阵MT执行两次左乘,进而使得输出参数矩阵AT中仅有数值不为0的元素才会参与待变换矩阵MT的行变换得以实现。
值得一提的是,在上述行变换重构过程中,第一结果矩阵VT是对输入变换结果矩阵V的转置,第二结果矩阵UT是对卷积核变换结果矩阵U的转置,而在进行输出变换之后,输出结果仍然是输出矩阵S,而并非输出矩阵S的转置ST。
也就是说,虽然第一结果矩阵和第二结果矩阵分别是输入变换结果矩阵和卷积核变换结果的转置,然而在进行输出变换之前,并不需要对第一结果矩阵和第二结果矩阵实施逆转置,仍然输出得到了原来的输出结果,即输出矩阵S。
在此,对于上述行变换重构过程中,在进行输出变换之前,不需要对第一结果矩阵和第二结果矩阵实施逆转置,进行如下证明:
首先,将公式(3)引入公式(7),即得到如下恒成立公式(8):
S=AT(ATMT)T=AT(AT(U⊙V)T)T (8)。
应当理解,逐元素乘法中,(U⊙V)T=(UT⊙VT),为此,将公式(8)进一步地转换为公式(9):
S=AT(AT(UT⊙VT)) (9)。
其中,UT为第一结果矩阵,VT为第二结果矩阵,UT⊙VT则为待变换矩阵MT。
由上可知,输出矩阵即是由待变换矩阵MT进行行变换重构得到的,因此,第一结果矩阵VT和第二结果矩阵UT不必在输出变换之前执行逆转置。
上述过程中,使得卷积层中的右乘矩阵转换为左乘矩阵,进而使得已知参数矩阵中仅有数值不为0的元素才会参与行变换重构过程得以实现。
应当理解,上述行变换重构过程中,行变换重构原理是相同的,区别仅在于输入对象、输出对象的不同,以及所使用已知参数矩阵的不同,为此,在对行变换重构过程作进一步地详细说明之前,将针对上述各类变换中的差异进行如下定义说明,以便于后续更好地描述行变换重构过程中存在于各类变换中的共性。
其中,重构参数矩阵包括输入参数矩阵、卷积参数矩阵或者输出参数矩阵。
重构输入矩阵包括输入矩阵、对应于输入矩阵的卷积核矩阵或者待变换矩阵。
重构输出矩阵包括第一结果矩阵、第二结果矩阵或者输出矩阵。
进一步地,在一示例性实施例中,如图9所示,行变换重构过程,即通过重构参数矩阵对重构输入矩阵进行行变换得到重构输出矩阵,可以包括以下步骤:
步骤511,将重构输入矩阵中各行的元素分别拼接存储为对应于行的行向量,由重构输入矩阵各行所对应的行向量构成行向量矩阵。
步骤513,将重构参数矩阵左乘行向量矩阵,得到中间矩阵。
步骤515,进行中间矩阵的转置,并将重构参数矩阵左乘转置后的中间矩阵,得到重构输出矩阵。
举例来说,假设重构输入矩阵为X,重构参数矩阵为Y,重构输出矩阵为Z,中间矩阵为W,则Z=Y(YX)T=YWT。
其中,
为重构输入矩阵X各行配置对应于行的行向量vD0、vD1、vD2、vD3。
由此,便可以将重构输入矩阵X中各行存储至对应的行向量,进而构成行向量矩阵。
例如,vD0={x0,x1x2,x3},vD1={x4,x5,x6,x7},以此类推。
在此说明的是,将重构输入矩阵X中各行的元素拼接存储的方式可以从高到低,如本实施例中,也可以从低到高,还可以按照指定规则进行,本实施例并非对此加以限定。
在此,即实现了对重构输入矩阵X的行向量表示,也可以理解为,行向量是对重构输入矩阵X中对应行的准确表示,如果重构输入矩阵中某一行的某个元素不同,则对应的行向量将有所区别,由此构成的行向量矩阵也各不相同。
在得到重构输入矩阵X的行向量矩阵之后,便可以基于该行向量矩阵对重构输入矩阵X进行行变换。
具体地,
通过上述过程,使得消耗较多计算指令的多次矩阵乘法被高效紧凑的行变换指令替代,大幅度减少了计算量,有效地提高了卷积神经网络模型的计算效率。
请参阅图10,在一示例性实施例中,步骤350可以包括以下步骤:
步骤351,按照输出通道、滑动窗口、输入通道逐个遍历,确定遍历到输入通道所对应的第一结果矩阵和第二结果矩阵。
步骤353,分别提取第一结果矩阵和第二结果矩阵同一位置的元素进行乘法运算,直至所有输出通道遍历完毕,得到多个乘积结果。
步骤355,进行多个乘积结果的累加运算,得到对应于同一位置的累加结果。
步骤357,对第一结果矩阵和第二结果矩阵中元素所在位置进行遍历,将对应于不同位置的累加结果按照所对应位置进行拼接,得到待变换矩阵。
根据输出通道、滑动窗口、输入通道,将公式(9)进一步地详细描述为公式(10):
其中,k表示输出通道,e表示滑动窗口,c表示输入通道。
进一步地,待变换矩阵,即
由公式(11)可知,对于待变换矩阵而言,实质上是基于不同输出通道、不同滑动窗口、不同输入通道,分别对第一结果矩阵与第二结果矩阵中同一位置的元素执行逐元素乘法和逐元素加法,而乘法和加法的操作本质上恰好满足了矩阵乘法的定义,也就是说,待变换矩阵中元素可以定义为公式(12):
其中,k表示输出通道,e表示滑动窗口,c表示输入通道,相应地,K表示输出通道个数,E表示滑动窗口个数,C表示输入通道个数。
由此,便能够按照公式(12)计算得到待变换矩阵中的元素并通过元素遍历,得到构成待变换矩阵MT各行中的各元素,进而按照元素所在位置拼接得到待变换矩阵MT。
以计算待变换矩阵MT中第一行第一列的元素m11为例进行说明。
1),确定输出通道k=0,滑动窗口e=0,输入通道c=0所对应的第一结果矩阵和第二结果矩阵
2),提取第一结果矩阵和第二结果矩阵中第一行第一列的元素进行乘法运算,得到对应于输出通道k=0,滑动窗口e=0,输入通道c=0的乘积结果。
3),对输入通道由c=0->C进行遍历,便可得到对应于输出通道k=0,滑动窗口e=0,输入通道c=1->C的乘积结果。
以此类推,待所有输入通道遍历完毕,则对滑动窗口由e=0->E进行遍历,待所有滑动窗口遍历完毕,再对输出通道由k=0->K进行遍历,直至所有输出通道遍历完毕,即得到对应于不同输出通道(k=0->K)、不同滑动窗口(e=0->E)、不同输入通道(c=0->C)的多个乘积结果。
4),将多个乘积结果进行累加运算,便得到对应于第一行第一列位置的累加结果,即视为待变换矩阵MT中第一行第一列的元素m11。
由此,在得到待变换矩阵MT中第一行第一列的元素m11之后,便进行元素遍历,即计算待变换矩阵MT中第一行第二列的元素m12,以此类推,直至所有元素计算完毕,便可按照元素所在位置拼接得到待变换矩阵MT。
在上述过程中,使得独立的两次计算操作,即逐元素乘法和逐元素加法,变换成对应于不同元素的独立矩阵乘法,有效地降低了计算量,降低幅度接近于2.25,进而使得就乘法计算而言,winograd F(2x2,3x3)算法能够最高达到理论加速比2.25X,大幅度提升了卷积神经网络模型的计算效率。
在此补充说明的是,对于硬件资源而言,可以分别为多个乘积结果配置寄存器,以此来存储乘积结果,进而通过读取寄存器中的数值进行多个乘积结果的累加运算,如本实施例中,而在其他实施例中,还可以仅设置两个寄存器,以降低硬件资源的消耗,一个寄存器用于存储当前乘积结果,另一个寄存器用于存储前一个乘积结果,进而通过读取寄存器中的数值将该两个乘积结果相加,当计算得到后一个乘积结果时,则对该两个寄存器中的数值进行更新,即将当前乘积结果更新至存储前一个乘积结果的寄存器中,而后一个乘积结果则更新至存储当前乘积结果的寄存器中,再基于数值更新的寄存器中数值进行累加运算,由此实现多个乘积结果的累加,本实施例并非对此加以限定,可以根据应用场景中对硬件资源的实际要求灵活地设置。
图11是一应用场景中一种图像识别方法的场景示意图。如图11所示,该应用场景包括用户610、智能手机630和支付服务器650。其中,智能手机630中部署了卷积神经网络模型,以为用户610提供人脸识别智能服务。
例如,针对某个待支付订单,用户610通过智能手机630所配置的摄像头进行刷脸,使得智能手机630获得用户610相应的目标图像,进而利用部署的卷积神经网络模型对该目标图像进行人脸识别。
具体地,在卷积神经网络模型中,通过卷积层输入通道从目标图像中提取得到多个输入矩阵,遍历多个输入矩阵,通过行变换重构对遍历到的输入矩阵执行输入变换及对应的卷积核变换,分别得到第一结果矩阵和第二结果矩阵,进而对第一结果矩阵和第二结果矩阵进行矩阵乘法重构得到待变换矩阵,再次通过行变换重构对待变换矩阵执行输出变换,直至所有输入矩阵遍历完毕,则由卷积层输出通道输出得到多个输出矩阵,并根据由多个输出矩阵拼接得到的卷积结果对目标图像进行深度学习,从而得到图像识别结果。
如果图像识别结果指示用户610通过身份验证,则智能手机630为待支付订单向支付服务器650发起订单支付请求,以此完成待支付订单的支付流程。
上述过程中,通过卷积层中的多次行变换重构和一次矩阵乘法重构,避免卷积层中执行多次矩阵乘法和一次逐元素乘法,大幅度降低了卷积层的计算量,进而有效地提高了卷积神经网络模型的计算效率。
如图12所示,在峰值性能方面,本发明所提供的行变换重构和矩阵乘法重构方法相较于其他算法要快8.67~35.4倍。
此外,表1是本发明针对不同型号智能手机在不同线程数量下的图像识别性能。如表1所示,本发明所提供的图像识别方法不仅具备良好的兼容性,而且峰值性能可达到在357.75ms之内即完成一次图像识别。
表1不同型号智能手机在不同线程数量下的图像识别性能
下述为本发明装置实施例,可以用于执行本发明所涉及的图像识别方法。对于本发明装置实施例中未披露的细节,请参照本发明所涉及的图像识别方法的方法实施例。
请参阅图13,在一示例性实施例中,一种图像识别装置900包括但不限于:输入矩阵提取模块910、结果矩阵获取模块930、待变换矩阵获取模块950、输出矩阵获取模块970和卷积结果获取模块990。
其中,输入矩阵提取模块910用于为图像识别所部署的卷积神经网络模型中,由输入卷积层输入通道的目标图像中提取得到多个输入矩阵。
结果矩阵获取模块930用于遍历多个输入矩阵,通过行变换重构对遍历到的输入矩阵执行输入变换及对应的卷积核变换分别得到第一结果矩阵和第二结果矩阵。
待变换矩阵获取模块950用于对第一结果矩阵与第二结果矩阵进行矩阵乘法重构得到待变换矩阵。
输出矩阵获取模块970用于通过行变换重构对待变换矩阵执行输出变换,直至所有输入矩阵遍历完毕,得到多个输出矩阵。
卷积结果获取模块990用于进行多个输出矩阵的拼接,根据拼接得到的卷积结果对目标图像进行深度学习。
请参阅图14,在一示例性实施例中,输入矩阵提取模块910包括但不限于:滑动控制单元911和输出单元913。
其中,滑动控制单元911用于控制滑动窗口在目标图像中滑动,对目标图像中的像素进行图像分隔,得到分割图像;
输出单元913用于将分割图像由卷积层的输入通道输出得到滑动窗口指定大小的多个输入矩阵。
在一示例性实施例中,卷积结果获取模块990包括但不限于:滑动拼接单元。
其中,滑动拼接单元用于按照滑动窗口在目标图像中的滑动位置对多个输出矩阵进行拼接,得到卷积结果。
请参阅图15,在一示例性实施例中,结果矩阵获取模块930包括但不限于:第一重构单元931和第二重构单元933。
其中,第一重构单元931用于通过输入参数矩阵对遍历到的输入矩阵进行行变换得到第一结果矩阵。
第二重构单元933用于获取输入矩阵对应的卷积核矩阵,并通过卷积参数矩阵对卷积核矩阵进行行变换得到第二结果矩阵。
请参阅图16,在一示例性实施例中,输出矩阵获取模块970包括但不限于:第三重构单元971和遍历单元973。
其中,第三重构单元971用于通过输出参数矩阵对待变换矩阵进行行变换得到输出矩阵。
遍历单元973用于待所有输入矩阵遍历完毕,由卷积层输出通道输出得到多个输出矩阵。
请参阅图17,在一示例性实施例中,重构参数矩阵包括输入参数矩阵、卷积参数矩阵或者输出参数矩阵。
重构输入矩阵包括输入矩阵、对应于输入矩阵的卷积核矩阵或者待变换矩阵。
重构输出矩阵包括第一结果矩阵、第二结果矩阵或者输出矩阵。
相应地,重构单元1010包括但不限于:行向量获取子单元1011、中间矩阵获取子单元1013和左乘子单元1015。
其中,行向量获取子单元1011用于将重构输入矩阵中各行的元素分别拼接存储为对应于行的行向量,由重构输入矩阵各行所对应的行向量构成行向量矩阵。
中间矩阵获取子单元1013用于将重构参数矩阵左乘行向量矩阵,得到中间矩阵。
左乘子单元1015用于进行中间矩阵的转置,并将重构参数矩阵左乘转置后的中间矩阵,得到重构输出矩阵。
请参阅图18,在一示例性实施例中,待变换矩阵获取模块950包括但不限于:矩阵确定单元951、乘法运算单元953、累加运算单元955和累加结果拼接单元957。
其中,矩阵确定单元951用于按照输出通道、滑动窗口、输入通道逐个遍历,确定遍历到输入通道所对应的第一结果矩阵和第二结果矩阵。
乘法运算单元953用于提取第一结果矩阵和第二结果矩阵同一位置的元素进行乘法运算,直至所有输出通道遍历完毕,得到多个乘积结果。
累加运算单元955用于进行多个乘积结果的累加运算,得到对应于同一位置的累加结果。
累加结果拼接单元957用于对第一结果矩阵和第二结果矩阵中元素所在位置进行遍历,将对应于不同位置的累加结果按照所对应位置进行拼接,得到待变换矩阵。
需要说明的是,上述实施例所提供的图像识别装置在进行图像识别处理时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即图像识别装置的内部结构将划分为不同的功能模块,以完成以上描述的全部或者部分功能。
另外,上述实施例所提供的图像识别装置与图像识别方法的实施例属于同一构思,其中各个模块执行操作的具体方式已经在方法实施例中进行了详细描述,此处不再赘述。
在一示例性实施例中,一种图像识别装置,包括处理器及存储器。
其中,存储器上存储有计算机可读指令,该计算机可读指令被处理器执行时实现上述各实施例中的图像识别方法。
在一示例性实施例中,一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述各实施例中的图像识别方法。
上述内容,仅为本发明的较佳示例性实施例,并非用于限制本发明的实施方案,本领域普通技术人员根据本发明的主要构思和精神,可以十分方便地进行相应的变通或修改,故本发明的保护范围应以权利要求书所要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!