报表分解统计方法、系统、计算机设备和存储介质与流程
本发明涉及数据处理技术领域,尤其涉及一种报表分解统计方法、系统、计算机设备和存储介质。
背景技术:
客户端用户每天会产生大量的用户日志,如行为信息、异常信息等,需要存储用户产生的日志,并对日志进行统计、分析和查询,这类工作一般通过日志处理软件执行。当前的日志处理系统都有报表统计这一项功能,通过定时任务来规划周期性的查询统计,并生成查询统计结果。
但是对于查询时间范围比较大的报表,则需要消耗大量计算资源。比如,假设统计一个月的数据,数据条目数为100000,通过定时任务来直接执行查询统计需要计算100000个数据的统计函数,造成执行速度慢,且报表集中生成,系统负载压力大。而且容易造成报表查询时间有重叠,历史的查询结果没有有效利用,造成资源的浪费。
技术实现要素:
有鉴于此,有必要针对报表查询时间范围比较长、消耗系统大量对计算和存储资源以及造成资源的浪费问题,提供一种报表分解统计方法、系统、计算机设备和存储介质。
一种报表分解统计方法,包括如下步骤:
获取预设在存储介质中的日志数据报表,所述日志数据报表包括开始时间字段、结束时间字段、与所述开始时间字段和所述结束时间字段对应的业务类型字段,获取预设在所述存储介质中的查询请求,所述查询请求包括查询时间范围、一项或多项中间统计语句;
在所述日志数据报表中,查找在所述查询时间范围内的所述开始时间字段和所述结束时间字段对应的所有业务类型字段,通过所述中间统计语句对所述业务类型字段逐一进行运算,得到一项或多项运算结果,分别将所述中间统计语句、所述查询时间范围和所述运算结果保存在一项或多项子报表中;
获取目标时间范围和目标统计语句,从预设在所述存储介质中的统计列表中查找与所述目标统计语句对应的目标中间统计语句,所述统计列表中含有与所述目标统计语句对应的聚合统计语句、一项或多项目标中间统计语句,在所述子报表中查找与所述目标中间统计语句相同的所述中间统计语对应的运算结果,提取所述目标时间范围内的所述运算结果;
从所述统计列表中查找与所述目标统计语句对应的聚合统计语句,通过所述聚合统计语句对提取的所述运算结果进行聚合运算,生成查询统计结果。
在其中一个实施例中,所述获取预设在存储介质中的日志数据报表前,包括:
通过日志数据采集器采集业务系统中的日志文件;
将所述日志文件通过提取器解析成多个有效字段信息,所述有效字段信息包括开始时间字段、结束时间字段和业务类型字段;
将多个所述有效字段信息存储在所述日志数据报表中。
在其中一个实施例中,所述获取预设在所述存储介质中的查询请求,包括:
在所述存储介质中预设查询定时任务,所述查询定时任务为目多个查询请求的轮询列表,调用查询定时脚本,定时获取所述查询请求。
在其中一个实施例中,所述目标统计语句为统计函数,所述统计函数包括求最大值、求最小值、求和、求平均值、求数目、标准差或非重复结果的数目中的至少一项;
当所述目标统计语句为求最大值时,在所述子报表中查找到的所述中间统计语句为对所述查询时间范围内的所有业务类型字段求最大值,所述运算结果为最大值,所述聚合统计语句为对所述目标时间范围内的所述运算结果再求最大值;
当所述目标统计语句为求最小值时,在所述子报表中查找到的所述中间统计语句为对所述查询时间范围内的所有业务类型字段求最小值,所述运算结果为最小值,所述聚合统计语句为对所述目标时间范围内的所述运算结果再求最小值;
当所述目标统计语句为求和时,在所述子报表中查找到的所述中间统计语句为对所述查询时间范围内的所有业务类型字段求总和,所述运算结果为总和,所述聚合统计语句为对所述目标时间范围内的所述运算结果再求总和;
当所述目标统计语句为求数目时,在所述子报表中查找到的所述中间统计语句为对所述查询时间范围内的所有业务类型字段求数目,所述运算结果为数目,所述聚合统计语句为对所述目标时间范围内的所述运算结果进行累加;
当所述目标统计语句为求平均值时,在所述子报表中查找到的所述中间统计语句为对所述查询时间范围内的所有业务类型字段求总和和数目,所述运算结果为总和和数目,所述聚合统计语句为对所述目标时间范围内的总和再求和得a1,对所述目标时间范围内的数目求和得b1,最后求平均值为a1/b1;
当所述目标统计语句为求标准差时,在所述子报表中查找到的所述中间统计语句为对所述查询时间范围内的所有业务类型字段求平方和、数目和求总和,所述运算结果为平方和、数目和总和,所述聚合统计语句为对所述目标时间范围内的总和累加得a2,对平方和累加得b2,对数目累加得c2,最后求标准差为sqrt(b2/c2-(a2/c2)^2);
当所述目标统计语句为求非重复结果的数目时,在所述子报表中查找到的所述中间统计语句为对所述查询时间范围内的所有业务类型字段求字段值和数目,所述运算结果为字段值和数目,所述聚合统计语句为对所述目标时间范围内的字段值进行合并,合并规则为相同字段值的数目进行相加,生成结果为非重复结果的数目。
在其中一个实施例中,所述获取目标时间范围和目标统计语句,包括:
在存储介质中预设统计定时任务,所述统计定时任务为目标时间范围和对应的目标统计语句的轮询列表,调用统计定时脚本,定时获取所述目标时间范围和目标统计语句。
在其中一个实施例中,所述获取目标时间范围和目标统计语句,包括:
设置用户输入界面,所述用户输入界面设有时间范围字段和目标统计语句字段,通过所述时间范围字段获取所述目标时间范围,通过所述目标统计语句字段获取所述目标统计语句。
一种报表分解统计系统,包括如下单元:
获取信息单元,用于获取预设在存储介质中的日志数据报表,所述日志数据报表包括开始时间字段、结束时间字段、与所述开始时间字段和所述结束时间字段对应的业务类型字段,获取预设在所述存储介质中的查询请求,所述查询请求包括查询时间范围、一项或多项中间统计语句;
生成运算结果单元,用于在所述日志数据报表中,查找在所述查询时间范围内的所述开始时间字段和所述结束时间字段对应的所有业务类型字段,通过所述中间统计语句对所述业务类型字段逐一进行运算,得到一项或多项运算结果,分别将所述中间统计语句、所述查询时间范围和所述运算结果保存在一项或多项子报表中;
提取运算结果单元,用于获取目标时间范围和目标统计语句,从预设在所述存储介质中的统计列表中查找与所述目标统计语句对应的目标中间统计语句,所述统计列表中含有与所述目标统计语句对应的聚合统计语句、一项或多项目标中间统计语句,在所述子报表中查找与所述目标中间统计语句相同的所述中间统计语对应的运算结果,提取所述目标时间范围内的所述运算结果;
生成查询统计结果单元,用于从所述统计列表中查找与所述目标统计语句对应的聚合统计语句,通过所述聚合统计语句对提取的所述运算结果进行聚合运算,生成查询统计结果。
在其中一个实施例中,还包括采集单元,用于通过日志数据采集器采集业务系统中的日志文件,将所述日志文件通过提取器解析成多个有效字段信息,所述有效字段信息包括开始时间字段、结束时间字段和业务类型字段,将多个所述有效字段信息存储在所述日志数据报表中。
一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,使得所述处理器执行上述报表分解统计方法的步骤。
一种存储有计算机可读指令的存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述报表分解统计方法的步骤。
上述报表分解统计方法、装置、计算机设备和存储介质,包括获取预设在存储介质中的日志数据报表,日志数据报表包括开始时间字段、结束时间字段、与开始时间字段和结束时间字段对应的业务类型字段,获取预设在存储介质中的查询请求,查询请求包括查询时间范围、一项或多项中间统计语句;在日志数据报表中,查找在查询时间范围内的开始时间字段和结束时间字段对应的所有业务类型字段,通过中间统计语句对业务类型字段逐一进行运算,得到一项或多项运算结果,分别将中间统计语句、查询时间范围和运算结果保存在一项或多项子报表中;获取目标时间范围和目标统计语句,从预设在存储介质中的统计列表中查找与目标统计语句对应的目标中间统计语句,统计列表中含有与目标统计语句对应的聚合统计语句、一项或多项目标中间统计语句,在子报表中查找与目标中间统计语句相同的中间统计语对应的运算结果,提取目标时间范围内的运算结果;从统计列表中查找与目标统计语句对应的聚合统计语句,通过聚合统计语句对提取的运算结果进行聚合运算,生成查询统计结果。本发明通过对日志数据报表的数据统计的功能集中某一时刻进行查询计算,在查询计算时,通过把原有查询用的统计语句分解为中间统计语句,在需要最终结果时,对中间统计语句计算得到的子报表中的运算结果进行聚合,大大提升了查询效率,把繁重的查询计算负担均匀分散到定时完成的子报表中进行。同时,由于每个子报表只保存相同中间统计语句及对应的运算结果,不同的目标统计语句聚合时,只要具有相同的中间统计语句,可直接重复利用中间统计语句对应的运算结果,达到运算结果复用、降低系统负荷的目的。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。
图1为本发明一个实施例中的报表分解统计方法的流程图;
图2为本发明一个实施例中的报表分解统计系统的结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。
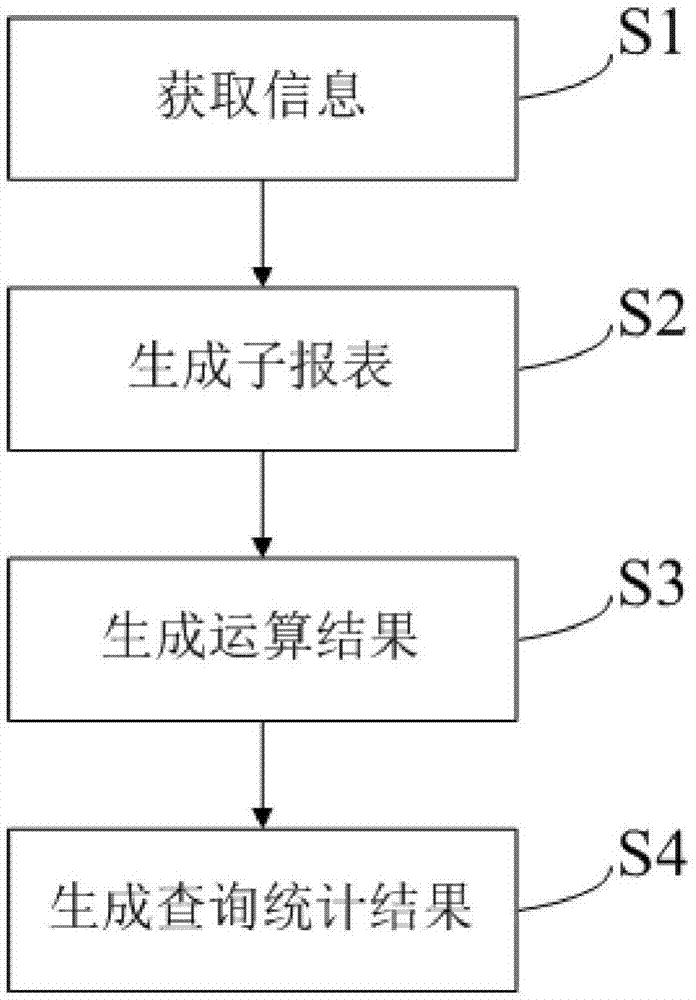
图1为本发明一个实施例中的报表分解统计方法的流程图,如图1所示,报表分解统计方法包括如下步骤:
步骤s1,获取信息:获取预设在存储介质中的日志数据报表,日志数据报表包括开始时间字段、结束时间字段、与开始时间字段和结束时间字段对应的业务类型字段,获取预设在存储介质中的查询请求,查询请求包括查询时间范围、一项或多项中间统计语句。
在一个实施例中,本步骤中的日志数据报表通过如下方法获取:通过日志数据采集器采集业务系统中的日志文件;将日志文件通过提取器解析成多个有效字段信息,有效字段信息包括开始时间字段、结束时间字段和业务类型字段;将多个有效字段信息存储在日志数据报表中。
业务系统如基金交易网站等均会产生日志文件,本步骤通过日志数据采集器采集日志文件,日志文件中通常包括日期、时间及对应的很多业务类型,如访问量、按钮点击量、用户停留平均时长等信息,通过提取器解析日志文件,将这些业务类型字段解析并进行存储后,得到本步骤需要的日志数据报表。在采集日志文件时,可以定时或定期的通过日志数据采集器采集日志文件,可以通过filebeat采集器到业务系统中获取日志。filebeat是一个开源的文件采集器,采用go语言开发,将filebeat采集器安装在业务系统上作为代理来监视业务系统中的日志目录或特定的日志文件,并可以把日志文件发送到日志处理平台中,对日志文件进一步处理。在对日志文件进行解析时,可以根据日志文件的格式选择json提取器、gork提取器或正则解析,如日志文件中的内容是特定结构化类型的日志,则采用正则解析,如日志文件中的内容是json类型的日志,则采用json提取器,如日志文件中的内容是非结构化复杂类型的日志,则采用gork提取器。
本实施例通过日志数据采集器采集日志文件,通过提取器解析日志文件,采用本实施例的方式得到日志数据报表,能根据业务系统,自动实时的得到最新的日志数据报表。
在一个实施例中,获取预设在存储介质中的查询请求,包括:在存储介质中预设查询定时任务,查询定时任务为目多个查询请求的轮询列表,调用查询定时脚本,定时获取查询请求。
本实施例中的存储介质可以是数据库。数据库是按照数据结构来组织、存储和管理数据的仓库,用户可以对数据库中的数据进行新增、截取、更新、删除等操作。数据库中的数据是从全局观点出发建立的,按一定的数据模型进行组织、描述和存储。其结构基于数据间的自然联系,从而可提供一切必要的存取路径,且数据不再针对某一应用,而是面向全组织,具有整体的结构化特征。基于此,子查询结果信息存储在数据库中,保证数据存储稳定。
本实施例中的存储介质也可以是文本文件。文本文件是一种计算机文件,它是一种典型的顺序文件,其文件的逻辑结构属于流式文件。文本文件中除了存储文件有效字符信息(包括能用ascii码字符表示的回车、换行等信息)外,不能存储其他任何信息。由于结构简单,文本文件被广泛用于记录信息,它能够避免其它文件格式遇到的一些问题。此外,当文本文件中的部分信息出现错误时,往往能够比较容易的从错误中恢复出来,并继续处理其余的内容。虽然文本文件存储空间较小,但是由于本步骤的存储内容小,因此本步骤的存储介质优选采用文本文件,子查询结果信息存储在文本文件中,便于快速读取。
本实施例中的查询定时脚本可以采用oracle的job定时执行脚本,它是一种基于存储过程的定时任务,使用oracle的存储过程,可以大大减少java程序代码的编写工作量,而且存储过程执行在数据库或文本文件上,这样可以利用oracle的良好性能支持,极大地提高程序执行效率和稳定性。定时执行存储过程,使用oracle的job定时执行任务。在设定好轮询参数和定时任务后,job定时执行脚本及本实施例中的查询定时脚本,可以在指定的时间点或每天的某个时间点自行执行定时任务。比如,夜间、周末或月末,日志处理平台负载较小,此时定时获取查询请求,降低白天工作时间的日志处理平台压力,增强日志处理平台的稳定性。
步骤s2,生成子报表:在日志数据报表中,查找在查询时间范围内的开始时间字段和结束时间字段对应的所有业务类型字段,通过中间统计语句对业务类型字段逐一进行运算,得到一项或多项运算结果,分别将中间统计语句、查询时间范围和运算结果保存在一项或多项子报表中。
在对业务类型字段进行统计时,本发明将传统的查询用的统计语句拆分了至少一项中间统计语句,因此需要逐一对业务类型字段利用至少一项中间统计语句分别进行运算,得到至少一项运算结果,有几项运算结果则就有几项子报表。例如,查询请求中包括查询时间范围为小时为单位一天的时间范围、中间统计语句为对业务类型字段求数目、对业务类型字段求总和,本步骤为了查询数据的准确性,整点时间不覆盖查询,例如查询时间范围为7:00-8:00时,对业务类型字段查询的是07:00.000-07:59:59.999的时间范围。通过中间统计语句对业务类型字段求数目得到一项运算结果保存在子报表1中,通过中间统计语句对对业务类型字段求总和得到另一项运算结果保存在子报表2中,选取两个时间段的运算结果,具体如下表1所示:
表1
步骤s3,生成运算结果:获取目标时间范围和目标统计语句,从预设在存储介质中的统计列表中查找与目标统计语句对应的目标中间统计语句,统计列表中含有与目标统计语句对应的聚合统计语句、一项或多项目标中间统计语句,在子报表中查找与目标中间统计语句相同的中间统计语对应的运算结果,提取目标时间范围内的运算结果。
在一个实施例中,目标统计语句为统计函数,统计函数包括求最大值、求最小值、求和、求平均值、求数目、标准差或非重复结果的数目中的至少一项。目标统计语句与中间统计语句、聚合统计语句的对应关系如下表2所示:
表2
具体的,当目标统计语句为求最大值时,在子报表中查找到的中间统计语句为对查询时间范围内的所有业务类型字段求最大值,运算结果为最大值,聚合统计语句为对目标时间范围内的运算结果再求最大值;
当目标统计语句为求最小值时,在子报表中查找到的中间统计语句为对查询时间范围内的所有业务类型字段求最小值,运算结果为最小值,聚合统计语句为对目标时间范围内的运算结果再求最小值;
当目标统计语句为求和时,在子报表中查找到的中间统计语句为对查询时间范围内的所有业务类型字段求总和,运算结果为总和,聚合统计语句为对目标时间范围内的运算结果再求总和;
当目标统计语句为求数目时,在子报表中查找到的中间统计语句为对查询时间范围内的所有业务类型字段求数目,运算结果为数目,聚合统计语句为对目标时间范围内的运算结果进行累加;
当目标统计语句为求平均值时,在子报表中查找到的中间统计语句为对查询时间范围内的所有业务类型字段求总和和数目,运算结果为总和和数目,聚合统计语句为对目标时间范围内的总和再求和得a1,对目标时间范围内的数目求和得b1,最后求平均值为a1/b1;
当目标统计语句为求标准差时,在子报表中查找到的中间统计语句为对查询时间范围内的所有业务类型字段求平方和、数目和求总和,运算结果为平方和、数目和总和,聚合统计语句为对目标时间范围内的总和累加得a2,对平方和累加得b2,对数目累加得c2,最后求标准差为sqrt(b2/c2-(a2/c2)^2);
当目标统计语句为求非重复结果的数目时,在子报表中查找到的中间统计语句为对查询时间范围内的所有业务类型字段求字段值和数目,运算结果为字段值和数目,聚合统计语句为对目标时间范围内的字段值进行合并,合并规则为相同字段值的数目进行相加,生成结果为非重复结果的数目。
本实施例通过目标统计语句、聚合统计语句和中间统计语句的对应关系,对分解后得到的运算结果根据目标时间范围进行提取,当目标统计语句而具有相同中间统计语句时,可以重复利用中间统计语句得到的运算结果,大大减少了统计时带来的系统负载压力。
在一个实施例中,获取目标时间范围和目标统计语句,包括:在存储介质中预设统计定时任务,统计定时任务为目标时间范围和对应的目标统计语句的轮询列表,调用统计定时脚本,定时获取目标时间范围和目标统计语句。
本实施例中的统计定时任务和统计定时脚本可以采用与查询定时任务和查询定时脚本相同的方法。通过设定定时任务来对运算结果进行提取,大大降低了白天工作时间的日志处理平台压力,增强日志处理平台的稳定性。
在一个实施例中,获取目标时间范围和目标统计语句,包括:设置用户输入界面,用户输入界面设有时间范围字段和目标统计语句字段,通过时间范围字段获取目标时间范围,通过目标统计语句字段获取目标统计语句。
在无需定时聚合生成查询统计结果时,可以预先设置好用户输入界面,用户输入界面除了设置时间范围字段和目标统计语句字段外,还可设有触发按钮,用户点击触发按钮用于统计时间范围字段内与目标统计语句字段对应的查询统计结果。本步骤的用户输入界面可以设置在日志处理平台中,本发明的主体即为日志处理平台,日志处理平台接收到触发按钮的触发信号后,获取目标时间范围和目标统计语句后,通过聚合运算,生成查询统计结果。
步骤s4,生成查询统计结果:从统计列表中查找与目标统计语句对应的聚合统计语句,通过聚合统计语句对提取的运算结果进行聚合运算,生成查询统计结果。
在步骤s3得到目标时间范围内的运算结果后,由于提取的运算结果是分解后的结果,因此本步骤通过聚合统计语句对分解的运算结果重新进行聚合才能得到最终的查询统计结果。本步骤得到的查询统计结果可以存储在存储介质中。例如,目标统计语句为求平均值,目标时间范围是xxxx年xx月xx日7点到9点,通过步骤s3提取得到的运算结果为子报表1中的数目1、数目2,子报表2中的总和1、总和2。则此时聚合统计语句为对总和1和总和2求和得a1,对数目1和数目2求和得到b1,查询统计结果为平均值a1/b1。
本发明的报表分解统计方法,通过查询请求将传统的查询用的统计语句分解为中间统计语句,定时生成多项子报表,通过保存子报表作为中间结果,在需要对数据进行聚合时,再多中间结果聚合,可以降低后续聚合的计算成本,而且还可以实现计算结果重复使用,降低日志处理平台的负荷。
例如统计一个月的数据,且条目数为100000,通过定时任务来直接执行查询用的统计语句需要计算100000个数据的统计函数,而使用本步骤的聚合运算,假设中间统计语句一小时执行一次,得到24*30=720个数据的运算结果,并将运算结果保存在子报表中,本发明只需要根据聚合需求,执行720个数据的统计计算即可,大大加快了时间范围较大的报表的生成。
在一个实施例中,提出了一种报表分解统计系统,如图2所示,包括如下单元:
获取信息单元,用于获取预设在存储介质中的日志数据报表,日志数据报表包括开始时间字段、结束时间字段、与开始时间字段和结束时间字段对应的业务类型字段,获取预设在存储介质中的查询请求,查询请求包括查询时间范围、一项或多项中间统计语句;
生成运算结果单元,用于在日志数据报表中,查找在查询时间范围内的开始时间字段和结束时间字段对应的所有业务类型字段,通过中间统计语句对业务类型字段逐一进行运算,得到一项或多项运算结果,分别将中间统计语句、查询时间范围和运算结果保存在一项或多项子报表中;
提取运算结果单元,用于获取目标时间范围和目标统计语句,从预设在存储介质中的统计列表中查找与目标统计语句对应的目标中间统计语句,统计列表中含有与目标统计语句对应的聚合统计语句、一项或多项目标中间统计语句,在子报表中查找与目标中间统计语句相同的中间统计语对应的运算结果,提取目标时间范围内的运算结果;
生成查询统计结果单元,用于从统计列表中查找与目标统计语句对应的聚合统计语句,通过聚合统计语句对提取的运算结果进行聚合运算,生成查询统计结果。
在一个实施例中,还包括采集单元,用于通过日志数据采集器采集业务系统中的日志文件,将日志文件通过提取器解析成多个有效字段信息,有效字段信息包括开始时间字段、结束时间字段和业务类型字段,将多个有效字段信息存储在日志数据报表中。
在一个实施例中,提出了一种计算机设备,包括存储器和处理器,存储器中存储有计算机可读指令,计算机可读指令被处理器执行时,使得处理器执行上述各实施例的报表分解统计方法中的步骤。
在一个实施例中,提出了一种存储有计算机可读指令的存储介质,计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述各实施例的报表分解统计方法中的步骤。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,randomaccessmemory)、磁盘或光盘等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明一些示例性实施例,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!