一种基于声音视觉联合特征的视频内表情识别方法与流程
本发明涉及一种视频内表情识别方法,尤其涉及一种基于声音视觉联合特征的视频内表情识别方法。
背景技术:
视频内的表情识别是依据视频中出现的人物特征来判断其表情的技术。视频中常见且重要的表情类别包括开心、愤怒、厌恶、恐惧、悲伤、惊讶等。表情是视频内容的重要组成部分,通过识别表情,可对视频片段所表达和对应的情感情绪进行分析,从而衍生出与情感相关的视频应用。
现有的视频中表情识别技术大多聚焦在基于人脸视觉特征的方式,即通过人脸检测定位,分析和识别人脸区域图像,根据人脸区域图像的视觉特征对其进行表情分类。人脸区域图像视觉特征确实是最能反映人脸表情的视觉特征,但由于人脸图像存在模糊、光照条件、角度偏向等因素的干扰,仅基于视觉单一模态特征的人脸表情识别存在一定的局限性。但是视频中能反映表情的信息并不仅局限于视觉特征,声音特征也是一类能反映视频情感的重要特征,通过声音特征可对视频片段的情感属性进行分析,从而帮助视频内表情识别提高准确率。如何将视觉特征和声音特征有效融合,是有待解决的问题。
技术实现要素:
本发明的目的在于利用声音特征模型对视频情感进行分析,将声音特征与视觉特征联合建模,对视频中出现的多种表情类别进行检测识别。其核心是设计一种声音视觉多模态特征联合框架,使各模态特征之间互为补充,弥补单一特征模态的不足。
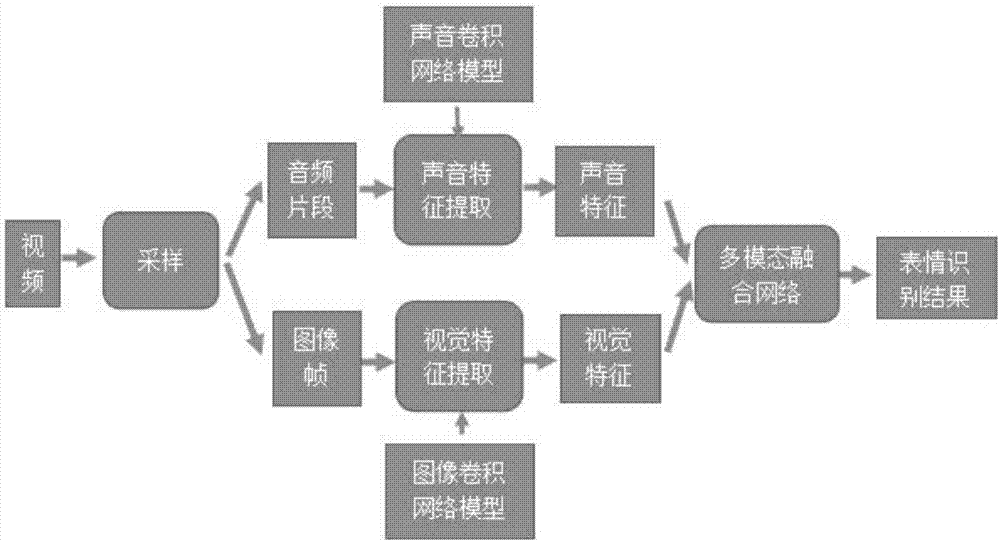
为了实现以上目的,本发明提供的一种基于声音视觉联合特征的视频内表情识别方法,分为以下步骤:
步骤s1:对输入视频在视觉和声音两个维度上进行采样,得到采样图像帧和采样音频片段;
步骤s2:在采样图像帧上进行视觉特征提取,获得视觉特征向量,在采样声音片段上进行声音特征提取,获得声音特征向量;
步骤s3:融合视觉和声音特征向量,设计联合分类器对视觉声音联合特征进行分类,得到表情检测分类结果。
其中,输入视频视觉和声音两个维度上均采用等间隔采样。
其中,采样图像帧上视觉特征采用经训练的卷积神经网络获得,该网络训练数据为经标注表情类别的人脸图像数据。
其中,采用声音片段上的声音特征采用经训练的卷积神经网络获得,该网络训练数据为经标注情感类别的包含情感语音的声音片段。
其中,融合视觉和声音特征向量,采用了单层神经网络的方式进行,通过学习视觉特征和声音特征到各表情类别间映射权重来得到最终映射函数和分类结果。
本发明的优点和技术效果:从具体实施例可以看出本发明的优点和技术效果,充分利用视频中包含的声音和视觉信息,通过神经网络将其有效地组合,建立联合特征和模型,弥补单一模态特征各自的不足,达到提升视频中表情识别准确率的效果。
附图说明
图1本发明基于声音视觉联合特征的视频内表情识别的基本流程。
具体实施方式
下面结合附图详细说明技术方案中所涉及的各个细节问题。应该指出的是,所描述的实施例旨在便于对本发明的理解,而对其不起任何限定作用。
本发明的实施流程如图1所示:
本发明实施例首先对视频进行采样,采样分为图像和声音两个模态。
图像采样采用2.56秒等间隔采样,获得采样帧。
声音采样以20毫秒为间隔对音频进行等间隔采样,获得20毫秒长度的音频片段。
采样图像经过以下预处理步骤:利用参考文献[1](zhang,k.,zhang,z.,li,z.,andqiao,y.(2016).jointfacedetectionandalignmentusingmultitaskcascadedconvolutionalnetworks.ieeesignalprocessingletters,23(10):1499–1503)的方法检测图像中的人脸框和特征点并进行姿态对齐,获得对齐后的人脸图像。
采样音频片段经过以下预处理步骤:对每个采样音频片段进行频谱分析,频谱量化为128个频段,每128个采样点为一采样组,每个采样片段时长为0.02秒*128=2.56秒,构成128*128维的频谱响应图。
图像卷积神经网络采用经标注的人脸表情图像数据集进行训练,网络结构为50层resnet。
声音卷积神经网络采样经标注的情感音频数据集进行训练,其标注类别标签与图像数据中的人脸表情一一对应,网络结构也采用50层resnet。
采样图像帧经预处理后输入到图像卷积神经网络,提取1000维pool5层输出作为采样图像对应的视觉特征向量。
采样音频片段经预处理后输入到声音卷积神经网络,提取1000维pool5层输出作为采样音频片段对应的声音特征向量。
连接合并视觉特征向量和声音特征向量,经pca主元分析法降维到512维并归一化后,作为该采样的声音视觉联合特征向量。
用监督学习方法训练基于声音视觉联合特征向量的表情分类器,训练样本为同时包含人脸表情和声音的视频片段及标注的表情类别标签,分类器样式可选svm、xgboost、单层全连接神经网络等常见的监督学习分类器或其组合,推理时将采样的声音视觉联合特征向量输入分类器即可获得采样对应的表情分类。
技术特征:
技术总结
本发明公开一种基于声音视觉联合特征的视频内表情识别方法,该方法包括以下步骤:步骤S1:对输入视频在视觉和声音两个维度上进行采样,得到采样图像帧和采样音频片段;步骤S2:在采样图像帧上进行视觉特征提取,获得视觉特征向量,在采样声音片段上进行声音特征提取,获得声音特征向量;步骤S3:融合视觉和声音特征向量,设计联合分类器对视觉声音联合特征进行分类,得到表情检测分类结果。
技术研发人员:张奕;谢锦滨;顾寅铮
受保护的技术使用者:上海极链网络科技有限公司
技术研发日:2018.10.11
技术公布日:2019.02.15
- 还没有人留言评论。精彩留言会获得点赞!