一种面向大规模数据的自适应最近邻查询方法与流程
本发明涉及信息检索技术领域,尤其是一种面向大规模数据的自适应最近邻查询方法。
背景技术:
目前,哈希技术是大规模数据检索的一种有效解决方案。相关技术中,对整个数据集,采用统一的哈希编码方式,得到的哈希编码的长度也是一致的。但实际大规模数据中,数据集的分布没有规律性。相关哈希技术没有充分地利用数据集的分布信息,有待改进。
技术实现要素:
本发明所要解决的技术问题是提供一种面向大规模数据的自适应最近邻查询方法,该方法能够根据数据集分布的密度大小将其量化为不同长度的哈希编码,有效减少数据集的编码冗余,提高检索准确性。
本发明解决上述技术问题所采用的技术方案为:一种面向大规模数据的自适应最近邻查询方法,包括以下步骤:
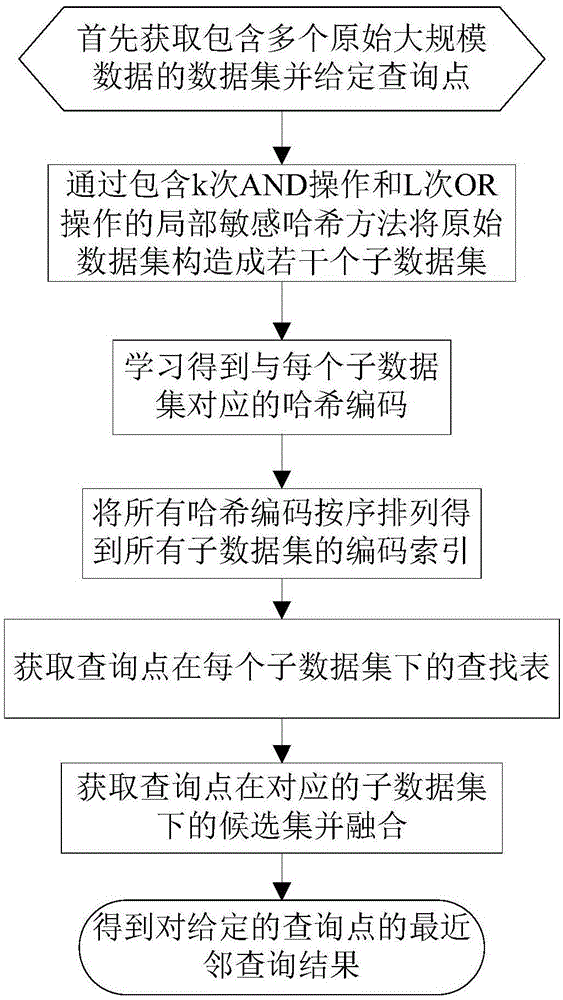
①获取包含多个原始大规模数据的原始大规模数据集并给定查询点,通过包含k次and操作和l次or操作的局部敏感哈希方法将原始大规模数据集构造成2k个子数据集,通过k次and操作和l次or操作将查询点映射到2k个子数据集中,得到查询点在每个子数据集中对应的映射数据;
②根据每个子数据集的大小从大到小对所有子数据集进行排序得到排序后的数据集,并对排序后的数据集中的每个子数据集设置一个与该子数据集的大小呈线性相关的编码长度;
③将每个子数据集分别映射到乘积空间,通过最小化哈希编码和原始数据的误差的方法学习得到与每个子数据集对应的哈希编码,然后将所有哈希编码按照对应的子数据集在排序后的数据集中的顺序对应排列得到所有子数据集的编码索引;
④根据所有子数据集的编码索引,在每个子数据集中对查询点在每个子数据集中对应的映射数据按最近距离量化映射,得到查询点在每个子数据集下的查找表;
⑤根据子数据集的编码索引和查询点在每个子数据集下的查找表,分别获取在子数据集的编码索引中离每个子数据集下的查找表的海明距离最近的与该查找表对应的最近邻点集,并将每个最近邻点集作为查询点在对应的子数据集下的候选集;
①将查询点对应的所有子数据集空间下的候选集进行融合,将融合后的数据集作为对给定的查询点的最近邻查询结果,完成对给定的查询点的最近邻查询过程。
所述的k次and操作的具体过程为:根据原始大规模数据集特征及查询精度的需求确定局部敏感哈希函数个数k,并根据局部敏感哈希函数族构建k个哈希函数,对所有原始大规模数据集中的每个原始大规模数据分别通过k个哈希函数进行映射,将原始大规模数据集划分至2k个子空间,然后按每个子空间中存在的数据数量对子空间降序排序,得到与原始大规模数据集对应的2k个经过降序排序后的子数据集;l次or操作的具体过程为:将上述k次and操作执行l次,每次取k个不同的局部敏感哈希函数,最终得到l组不同的2k个经过降序排序后的子数据集,然后将l组不同的2k个经过降序排序后的子数据集按融合因子β进行融合得到最终的2k个子数据集,其中,
与现有技术相比,本发明的优点在于首先获取包含多个原始大规模数据的数据集并给定查询点,通过包含k次and操作和l次or操作的局部敏感哈希方法将原始数据集构造成若干个子数据集,然后根据每个子数据集的大小对所有子数据集进行排序,再通过最小化哈希编码和原始数据的误差的方法学习得到与每个子数据集对应的哈希编码,然后将所有哈希编码按照对应的子数据集在排序后的数据集中的顺序对应排列得到所有子数据集的编码索引,再根据所有子数据集的编码索引获取查询点在每个子数据集下的查找表,接下来获取在子数据集的编码索引中离每个子数据集下的查找表的海明距离最近的最近邻点集并融合,得到对给定的查询点的最近邻查询结果;这种子数据集的构造方式旨在模拟数据分布的密度信息,通过数据集的密度大小自适应数据的编码长度,使用较短的编码表示密度较小的数据,使用较长的编码表示密度较大的数据,这样能更好地挖掘数据集分布的信息,最大限度地降低了编码的冗余,提升了对给定的查询点的最近邻查询过程的查询精度和查询效率。
附图说明
图1为本发明的步骤流程图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
一种面向大规模数据的自适应最近邻查询方法,包括以下步骤:
①获取包含多个原始大规模数据的原始大规模数据集并给定查询点,通过包含k次and操作和l次or操作的局部敏感哈希方法将原始大规模数据集构造成2k个子数据集,通过k次and操作和l次or操作将查询点映射到2k个子数据集中,得到查询点在每个子数据集中对应的映射数据。
其中,k次and操作的具体过程为:根据原始大规模数据集特征及查询精度的需求确定局部敏感哈希函数个数k,并根据局部敏感哈希函数族构建k个哈希函数,对所有原始大规模数据集中的每个原始大规模数据分别通过k个哈希函数进行映射,将原始大规模数据集划分至2k个子空间,然后按每个子空间中存在的数据数量对子空间降序排序,得到与原始大规模数据集对应的2k个经过降序排序后的子数据集;l次or操作的具体过程为:将上述k次and操作执行l次,每次取k个不同的局部敏感哈希函数,最终得到l组不同的2k个经过降序排序后的子数据集,然后将l组不同的2k个经过降序排序后的子数据集按融合因子β进行融合得到最终的2k个子数据集,其中,
②根据每个子数据集的大小从大到小对所有子数据集进行排序得到排序后的数据集,并对排序后的数据集中的每个子数据集设置一个与该子数据集的大小呈线性相关的编码长度。
③将每个子数据集分别映射到乘积空间,通过最小化哈希编码和原始数据的误差的方法学习得到与每个子数据集对应的哈希编码,然后将所有哈希编码按照对应的子数据集在排序后的数据集中的顺序对应排列得到所有子数据集的编码索引。
④根据所有子数据集的编码索引,在每个子数据集中对查询点在每个子数据集中对应的映射数据按最近距离量化映射,得到查询点在每个子数据集下的查找表。
⑤根据子数据集的编码索引和查询点在每个子数据集下的查找表,分别获取在子数据集的编码索引中离每个子数据集下的查找表的海明距离最近的与该查找表对应的最近邻点集,并将每个最近邻点集作为查询点在对应的子数据集下的候选集。
⑥将查询点对应的所有子数据集空间下的候选集进行融合,将融合后的数据集作为对给定的查询点的最近邻查询结果。
- 还没有人留言评论。精彩留言会获得点赞!