一种授信方法、系统、计算机设备及介质与流程
本发明涉及信用管理技术领域。更具体地,涉及一种授信方法、系统、计算机设备及介质。
背景技术:
目前授信模型的建立需要从合作方获得用户信用卡账单的明细数据,利用此数据和我方的用户表现数据建立预授信模型,将明细数据转化为一个表示风险排序的分数。但是出于对用户隐私数据的保护,合作方的数据一般不能以明细数据的模式提供,并且合作方提供的数据覆盖广度不足,影响授信模型的精度。
因此,亟需提供一种新的授信模型的建立方式。
技术实现要素:
为了解决上述技术问题中的至少一个,本发明提供一种授信方法、系统、计算机设备及介质,该授信方法及系统首先建立预授信模型,再通过预授信模型和新增的用户信用数据建立授信模型,提高了模型的精度以及稳定性。
在某些实施例中,一种授信模型的建立方法,包括:
基于预设的数据库中的用户数据,建立预授信模型;
根据所述预授信模型,筛选出符合要求的用户;
获取符合要求的用户的信用数据,并根据所述信用数据和所述预授信模型建立授信模型。
在某些实施例中,所述基于预设的数据库中的用户数据,建立预授信模型,包括:
获取预设的数据库中每个用户的用户数据;
将每个用户的用户数据按照预设的用户数据与用户风险程度的对应关系转化为分值数据;
对每个用户的分值数据按照数值大小进行排序,获得所述预授信模型;
其中,所述根据所述预授信模型,筛选出符合要求的用户,包括:
根据每个用户分值数据的排序,筛选出排序名次处于预设范围的用户。
在某些实施例中,将每个用户的用户数据按照预设的用户数据与用户风险程度的对应关系转化为分值数据,包括:
根据建立的评分卡模型,确定每个用户的分值数据,其中,所述预设的评分卡模型根据预设的用户数据与用户风险程度的对应关系建立。
在某些实施例中,所述获取符合要求的用户的信用数据,并根据所述信用数据和所述预授信模型建立授信模型,包括:
获取符合要求的用户的信用数据,利用所述预授信模型输出的每个用户分值数据,通过嵌套的方式建立所述授信模型。
在某些实施例中,所述获取符合要求的用户的信用数据,利用所述预授信模型输出的每个用户分值数据,通过嵌套的方式建立所述授信模型,包括:
对预授信模型输出的每个用户分值数据和用户的信用数据进行分箱处理;
对分箱数据进行逻辑回归,将分箱数据转换为标准评分卡格式的授信模型。
在某些实施例中,所述对预授信模型输出的每个用户分值数据和用户的信用数据进行分箱处理,包括:
对预授信模型输出的每个用户分值数据和用户的信用数据的信息增益率进行分箱处理,获得增益率分箱数据;
选取样本比例过大的分箱进行等距或等分位数分箱,获得分位数分箱数据,并将选取的分箱的增益率分箱数据替换为分位数分箱数据。
在某些实施例中,所述对分箱数据进行逻辑回归,将分箱数据转换为标准评分卡格式的授信模型,包括:
对分箱数据进行lasso回归;
对经过lasso回归后的分箱数据进行stepwise逐步回归,获得标准评分卡格式的授信模型。
在某些实施例中,一种授信模型的建立系统,包括:
预授信模型模块,基于预设的数据库中的用户数据,建立预授信模型;
筛选模块,根据所述预授信模型,筛选出符合要求的用户;
授信模型模块,获取符合要求的用户的信用数据,并根据所述信用数据和所述预授信模型建立授信模型。
在某些实施例中,所述预授信模型模块包括:
用户数据获取单元,获取预设的数据库中每个用户的用户数据;
分值数据转化单元,将每个用户的用户数据按照预设的用户数据与用户风险程度的对应关系转化为分值数据;
排序单元,对每个用户的分值数据按照数值大小进行排序,获得所述预授信模型;
其中,所述筛选模块包根据每个用户分值数据的排序,筛选出排序名次处于预设范围的用户。
在某些实施例中,所述分值数据转化单元根据建立的评分卡模型,确定每个用户的分值数据,其中,所述预设的评分卡模型根据预设的用户数据与用户风险程度的对应关系建立。
在某些实施例中,所述授信模型模块包括:
授信模型建立单元,获取符合要求的用户的信用数据,利用所述预授信模型输出的每个用户分值数据,通过嵌套的方式建立所述授信模型。
在某些实施例中,所述授信模型建立单元包括:
分箱单元,对预授信模型输出的每个用户分值数据和用户的信用数据进行分箱处理;
逻辑回归单元,对分箱数据进行逻辑回归,将分箱数据转换为标准评分卡格式的授信模型。
在某些实施例中,所述分箱单元包括:
第一分箱单元,对预授信模型输出的每个用户分值数据和用户的信用数据的信息增益率进行分箱处理,获得增益率分箱数据;
第二分箱单元,选取样本比例过大的分箱进行等距或等分位数分箱,获得分位数分箱数据,并将选取的分箱的增益率分箱数据替换为分位数分箱数据。
在某些实施例中,所述逻辑回归单元包括:
第一回归单元,对分箱数据进行lasso回归;
第二回归单元,对经过lasso回归后的分箱数据进行stepwise逐步回归,获得标准评分卡格式的授信模型。
本发明第三方面提供一种计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上所述的方法。
本发明第四方面提供一种计算机可读介质,其上存储有计算机程序,该程序被处理器执行时实现如上所述的方法。
本发明的有益效果如下:
本发明提供一种授信方法、系统、计算机设备及介质,通过首先建立预授信模型,再通过预授信模型和新增的用户信用数据建立授信模型,一方面不需要合作方提供明细数据,保护了用户隐私,另一方面增加了用户信用数据,提高了数据的覆盖度,降低了模型的风险,提高了模型的精度以及稳定性,并且由于对用户进行了筛选,简化了授信操作,降低了模型计算的时间成本和计算设备的负担。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细的说明。
图1示出本发明实施例中授信模型的建立方法流程示意图。
图2示出图1中步骤s1的具体流程示意图。
图3示出图1中步骤s3的具体流程示意图。
图4示出图3中步骤s31的具体流程示意图。
图5示出图3中步骤s32的具体流程示意图。
图6示出本发明实施例中的授信模型的建立系统的结构示意图。
图7示出图6中预授信模块的具体结构示意图。
图8示出图6中授信模块的具体结构示意图。
图9示出适用于用来实现本发明实施例的终端设备或服务器的计算机设备的结构示意图。
具体实施方式
为了更清楚地说明本发明,下面结合优选实施例和附图对本发明做进一步的说明。附图中相似的部件以相同的附图标记进行表示。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。
在附图中示出了根据本发明公开实施例的各种截面图。这些图并非是按比例绘制的,其中为了清楚表达的目的,放大了某些细节,并且可能省略了某些细节。图中所示出的各种区域、层的形状以及他们之间的相对大小、位置关系仅是示例性的,实际中可能由于制造公差或技术限制而有所偏差,并且本领域人员根据实际所需可以另外设计具有不同形状、大小、相对位置的区域/层。
目前授信模型的建立依赖性严重,需要合作方提供明细数据,但是出于对用户隐私数据的保护,合作方的数据一般不能以明细数据的模式提供,并且合作方提供的数据覆盖广度不足,影响授信模型的精度。
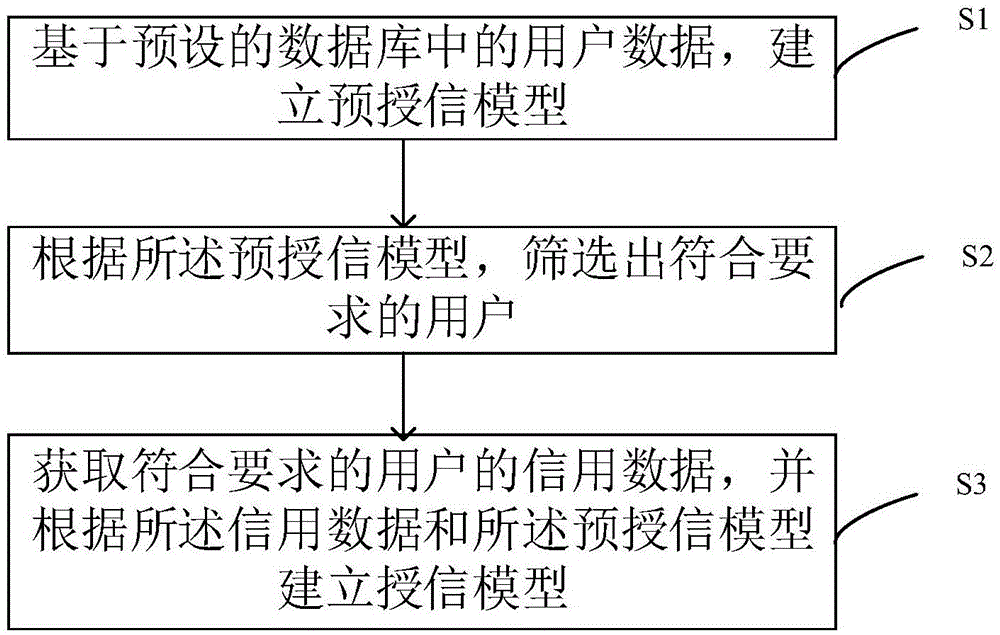
有鉴于此,本发明第一方面提供一种授信方法,请结合图1所示,该方法包括:
s1:基于预设的数据库中的用户数据,建立预授信模型;
s2:根据所述预授信模型,筛选出符合要求的用户;
s3:获取符合要求的用户的信用数据,并根据所述信用数据和所述预授信模型建立授信模型。
本发明提供的授信模型的建立方法,通过首先建立预授信模型,再通过预授信模型和新增的用户信用数据建立授信模型,一方面不需要合作方提供明细数据,保护了用户隐私,另一方面增加了用户信用数据,提高了数据的覆盖度,降低了模型的风险,提高了模型的精度以及稳定性,并且由于对用户进行了筛选,简化了授信操作,降低了模型计算的时间成本和计算设备的负担。
下面结合图2-5对本发明的授信模型的建立方法进行详细说明。
结合图2所示,步骤s1包括:
s11:获取预设的数据库中每个用户的用户数据。
预设的数据库为合作方提供的数据库,合作方一般不会将用户数据以明细的方式提供,因此,在一些具体实施例中,用户数据可以为用户总的欠款数额,用户月消费、月收入等较为笼统的数据。
在一个实施例中,设置模型关联用户的变量,例如关联用户的变量变量为姓名、身份证以及手机号,与合作方的数据库进行连通,将合作方数据库中的用户数据作为解释变量。
s12:将每个用户的用户数据按照预设的用户数据与用户风险程度的对应关系转化为分值数据。
具体的,在一个实施例中,预设的用户数据与用户风险程度的对应关系通过预设的评分卡模型或者评分表格呈现,即所述预设的评分卡模型或者评分表格根据预设的用户数据与用户风险程度的对应关系建立。
通过建立评分卡模型或者评分表格可以知晓每个用户数据对应的用户风险程度,将用户数据转化为分值数据,分值数据的大小可以直接反映用户的信用,例如,在一个具体实施例中,用户的分值数据越小,用户的信用越低,当用户的信用低于预定的阈值时,判定为危险客户。
s13:对每个用户的分值数据按照数值大小进行排序,获得所述预授信模型。
在一个实施例中,可以按照从大到小或者从小到大的顺序排列,预授信模型即为按照分值数据大小的排序,该实施例中,步骤s2为根据每个用户分值数据的排序,筛选出排序名次处于预设范围的用户。
在一些具体实施例中,在进行步骤s3之前,还需要进行数据的预处理,主要工作包括数据清洗、缺失值处理、异常值处理,主要是为了将获取的原始数据转化为可用作模型开发的格式化数据。
在一些具体实施例中,数据属于个人消费类贷款,只考虑信用评分最终实施时能够使用到的数据应从如下一些方面获取数据:
–基本属性:包括了借款人当时的年龄。
–偿债能力:包括了借款人的月收入、负债比率。
–信用往来:两年内35-59天逾期次数、两年内60-89天逾期次数、两年内90天或高于90天逾期的次数。
–财产状况:包括了开放式信贷和贷款数量、不动产贷款或额度数量。
–贷款属性:暂无。
–其他因素:包括了借款人的家属数量(不包括本人在内)。
–时间窗口:自变量的观察窗口为过去两年,因变量表现窗口为未来两年。
一般地,缺失值处理包括如下几种:
(1)直接删除含有缺失值的样本。
(2)根据样本之间的相似性填补缺失值。
(3)根据变量之间的相关关系填补缺失值。
需要说明的是,本实施例中的用户数据为从预设数据库获取的数据,用户的信用数据为经过用户授权的授权项数据,以上述为例,合作方提供的预设数据库往往没有借款人当时的年龄、月收入、负债比、以及周期时间内的预期次数等详细信息。
步骤s3中,用户的信用数据的获取需要经过用户的准许,例如,用户可以授权发送用户的具体职业、收入来源、人际关系等信用数据,通过获取符合要求的用户的信用数据,利用所述预授信模型输出的每个用户分值数据,通过嵌套的方式建立所述授信模型。即将用户分值数据作为授信模型的输入数据的其中一个,从而通过嵌套建模的技巧,将预授信模型和授信模型形成嵌套关联。
请结合图3所示,步骤s3包括:
s31:对预授信模型输出的每个用户分值数据和用户的信用数据进行分箱处理。
变量分箱(binning)是对连续变量离散化(discretization)的一种称呼。通常对数据进行分箱时,一般进行等距分割、分位数分割,或是使用chi_square值、gini值或是信息增益率等统计指标来进行分割。使用等距分割或是分位数分割时,通常不能得到最优分割结果,但会使得每个分箱的样本量相对比较接近。而使用chi_square值、gini值或是信息增益率来进行分箱,虽然可以得到最优分割结果,但是对于每个分箱而言,样本量差别通常会很大。
在一个优选的实施例中,如图4所示,步骤s31具体包括:
s311:对预授信模型输出的每个用户分值数据和用户的信用数据的信息增益率进行分箱处理,获得增益率分箱数据;
s312:选取样本比例过大的分箱进行等距或等分位数分箱,获得分位数分箱数据,并将选取的分箱的增益率分箱数据替换为分位数分箱数据。
本实施例综合了这两种分箱的优点,先使用信息增益率来得到最优分箱,然后对样本比例过大的分箱进行分位数分箱,这样可以使得在保证每个分箱样本量差距不大的条件下,得到最优的分箱结果。
s32:对分箱数据进行逻辑回归,将分箱数据转换为标准评分卡格式的授信模型。
一个优选的实施例中,如图5所示,步骤s32包括:
s321:对分箱数据进行lasso回归;
s322:对经过lasso回归后的分箱数据进行stepwise逐步回归,获得标准评分卡格式的授信模型。
本实施例中,一般逻辑回归筛选变量,使用stepwise逐步回归法,效率较低。本案例采用lasso回归,即用l1正则化去筛选变量,之后再使用stepwise逐步回归法,效率大幅提升。
在一些具体实施例中,还可以在分箱处理后,对分箱数据进行相关性分析和iv筛选,本发明不限于此。
基于与上述授信模型的建立方法相同的发明构思,本发明还提供一种授信模型的建立系统,结合图6,包括:
预授信模型模块100,基于预设的数据库中的用户数据,建立预授信模型;
筛选模块200,根据所述预授信模型,筛选出符合要求的用户;
授信模型模块300,获取符合要求的用户的信用数据,并根据所述信用数据和所述预授信模型建立授信模型。
本发明提供的授信模型的建立系统,通过首先建立预授信模型,再通过预授信模型和新增的用户信用数据建立授信模型,一方面不需要合作方提供明细数据,保护了用户隐私,另一方面增加了用户信用数据,提高了数据的覆盖度,降低了模型的风险,提高了模型的精度以及稳定性,并且由于对用户进行了筛选,简化了授信操作,降低了模型计算的时间成本和计算设备的负担。
结合图7所示,所述预授信模型模块100包括:
用户数据获取单元101,获取预设的数据库中每个用户的用户数据。
预设的数据库为合作方提供的数据库,合作方一般不会将用户数据以明细的方式提供,因此,在一些具体实施例中,用户数据可以为用户总的欠款数额,用户月消费、月收入等较为笼统的数据。
在一个实施例中,设置模型的关联用户变量,例如模型的关联用户变量为姓名、身份证以及手机号,与合作方的数据库进行连通,将合作方数据库中的用户数据作为解释变量。
分值数据转化单元102,将每个用户的用户数据按照预设的用户数据与用户风险程度的对应关系转化为分值数据。
具体的,在一个实施例中,预设的用户数据与用户风险程度的对应关系通过预设的评分卡模型或者评分表格呈现,即所述预设的评分卡模型或者评分表格根据预设的用户数据与用户风险程度的对应关系建立。
通过建立评分卡模型或者评分表格可以知晓每个用户数据对应的用户风险程度,将用户数据转化为分值数据,分值数据的大小可以直接反映用户的信用,例如,在一个具体实施例中,用户的分值数据越小,用户的信用越低,当用户的信用低于预定的阈值时,判定为危险客户。
排序单元103,对每个用户的分值数据按照数值大小进行排序,获得所述预授信模型。
在一个实施例中,可以按照从大到小或者从小到大的顺序排列,预授信模型即为按照分值数据大小的排序,该实施例中,所述筛选模块200根据每个用户分值数据的排序,筛选出排序名次处于预设范围的用户。
授信模型模块中,用户的信用数据的获取需要经过用户的准许,例如,用户可以授权发送用户的具体职业、收入来源、人际关系等信用数据,通过获取符合要求的用户的信用数据,利用所述预授信模型输出的每个用户分值数据,通过嵌套的方式建立所述授信模型。即将用户分值数据作为授信模型的输入数据的其中一个,从而通过嵌套建模的技巧,将预授信模型和授信模型形成嵌套关联。
在一些具体实施例中,还需要进行数据的预处理,主要工作包括数据清洗、缺失值处理、异常值处理,主要是为了将获取的原始数据转化为可用作模型开发的格式化数据。
在一些具体实施例中,数据属于个人消费类贷款,只考虑信用评分最终实施时能够使用到的数据应从如下一些方面获取数据:基本属性、偿债能力、信用往来、财产状况、其他因素以及时间窗口等。
需要说明的是,本实施例中的用户数据为从预设数据库获取的数据,用户的信用数据为经过用户授权的授权项数据,以上述为例,合作方提供的预设数据库往往没有借款人当时的年龄、月收入、负债比、以及周期时间内的预期次数等详细信息。
在一个优选实施例中,结合图8所示,所述授信模型模块300包括:
分箱单元,对预授信模型输出的每个用户分值数据和用户的信用数据进行分箱处理;
逻辑回归单元,对分箱数据进行逻辑回归,将分箱数据转换为标准评分卡格式的授信模型。
变量分箱(binning)是对连续变量离散化(discretization)的一种称呼。通常对数据进行分箱时,一般进行等距分割、分位数分割,或是使用chi_square值、gini值或是信息增益率等统计指标来进行分割。使用等距分割或是分位数分割时,通常不能得到最优分割结果,但会使得每个分箱的样本量相对比较接近。而使用chi_square值、gini值或是信息增益率来进行分箱,虽然可以得到最优分割结果,但是对于每个分箱而言,样本量差别通常会很大。
在一个优选的实施例中,所述分箱单元包括:
第一分箱单元,对预授信模型输出的每个用户分值数据和用户的信用数据的信息增益率进行分箱处理,获得增益率分箱数据;
第二分箱单元,选取样本比例过大的分箱进行等距或等分位数分箱,获得分位数分箱数据,并将选取的分箱的增益率分箱数据替换为分位数分箱数据。
本实施例综合了这两种分箱的优点,先使用信息增益率来得到最优分箱,然后对样本比例过大的分箱进行分位数分箱,这样可以使得在保证每个分箱样本量差距不大的条件下,得到最优的分箱结果。
一个优选的实施例中,所述逻辑回归单元包括:
第一回归单元,对分箱数据进行lasso回归;
第二回归单元,对经过lasso回归后的分箱数据进行stepwise逐步回归,获得标准评分卡格式的授信模型。
本实施例中,一般逻辑回归筛选变量,使用stepwise逐步回归法,效率较低。本案例采用lasso回归,即用l1正则化去筛选变量,之后再使用stepwise逐步回归法,效率大幅提升。
在一些具体实施例中,还可以在分箱处理后,对分箱数据进行相关性分析和iv筛选,本发明不限于此。
下面参考图9,其示出了适于用来实现本申请实施例的终端设备或服务器的计算机设备800的结构示意图。
如图9所示,计算机设备800包括中央处理单元(cpu)801,其可以根据存储在只读存储器(rom)802中的程序或者从存储部分808加载到随机访问存储器(ram))803中的程序而执行各种适当的工作和处理。在ram803中,还存储有系统800操作所需的各种程序和数据。cpu801、rom802、以及ram803通过总线804彼此相连。输入/输出(i/o)接口805也连接至总线804。
以下部件连接至i/o接口805:包括键盘、鼠标等的输入部分806;包括诸如阴极射线管(crt)、液晶显示器(lcd)等以及扬声器等的输出部分807;包括硬盘等的存储部分808;以及包括诸如lan卡,调制解调器等的网络接口卡的通信部分809。通信部分809经由诸如因特网的网络执行通信处理。驱动器810也根据需要连接至i/o接口806。可拆卸介质811,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器810上,以便于从其上读出的计算机程序根据需要被安装如存储部分808。
特别地,根据本发明的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本发明的实施例包括一种计算机程序产品,其包括有形地包含在机器可读介质上的计算机程序,所述计算机程序包括用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分809从网络上被下载和安装,和/或从可拆卸介质811被安装。
附图中的流程图和框图,图示了按照本发明各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,所述模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发送。例如两个接连地表示的方框实际上可以基本并行地执行,他们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定,对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 还没有人留言评论。精彩留言会获得点赞!