一种基于卷积神经网络的脱机手写汉字识别方法与流程
本发明属于图像分类领域,具体为基于卷积神经网络的脱机手写汉字识别方法。
背景技术:
汉字是重要的信息载体,利用计算机识别手写汉字,在大量手写材料录入、单据识别、教学辅助等领域具有重要的作用。
汉字识别可以分为联机汉字识别与脱机汉字识别,脱机汉字识别又分为脱机手写汉字识别与脱机印刷汉字识别。联机汉字识别指的是对在电子屏上书写的汉字进行识别,例如手机上手写输入功能,银行电子签名功能。脱机汉字识别,指的是对传统的在纸张等介质上书写的汉字进行识别,相比较联机汉字识别,丢失了书写时的笔画信息。脱机手写汉字识别与脱机印刷汉字识别区分在于手写汉字比印刷体汉字更加多变。目前联机汉字识别与脱机印刷汉字识别,效果较好,已基本商用,而脱机手写汉字识别效果还不尽人意,亟需解决。
脱机手写汉字识别效果不佳,难度较大,主要体现在三个方面。一、汉字种类繁多,国标gb2312-80规定的常用汉字字符集为6763个,其中一类汉字3755个,二类汉字3008个,相比于英文字母只有52个大小写字符,汉字识别是一个大类别分类任务,汉字种类越多,分类准确率就越难提高;二、汉字书写风格差异巨大,不同人的笔迹差异明显,即使同一人在不同状态下写出来的字也不尽相同,而且汉字的书写还分为楷书、行书、隶书、草书等字体,这无疑增加了识别的难度;三、汉字结构复杂,如“撇”、“罐”、“蘸”等,形近字多,如“我”、“找”、“伐”、“代”等,汉字书写时笔划不规范,笔划的角度、相对大小和粗细千变万化,都影响着汉字的最终识别效果。
技术实现要素:
本发明的内容为实现了一种基于卷积神经网络的脱机手写汉字识别方法,实现了对gb2312-80规定的一类3755类汉字的识别,具体技术方案包括以下4个部分。
(1)图像预处理:使用hwdb-1.1作为样本集,对hwdb-1.1样本集中所提供图片进行缩放、对比度增强。
(2)构建卷积神经网络模型,本发明所设计的卷积神经网络模型包括输入层,5个卷积层,3个全连接层,4个最大值池化层,softmax层及输出层。
(3)模型训练:利用keras深度学习框架搭建卷积神经网络,对模型进行训练。
(4)分类预测:利用构建好的卷积神经网络,对输入的汉字图片进行预测,系统将给出预测结果。
与现有脱机手写汉字识别方法相比,本发明的优点体现在以下几点:1、设计方法简单,本发明单纯利用卷积神经网络来对脱机手写汉字图像进行分类,避免了传统图像分类方法中复杂的图像特征提取、分类器设计等步骤。2、正确率高,本方法在验证集和测试集上的正确率均达到了94.5%。
附图说明
图1为本发明所涉一种基于卷积神经网络的脱机手写汉字识别方法整体流程图
图2为casia-hwdb1.1数据集样本图像
图3为样本图像预处理前后效果对比图
图4为卷积神经网络模型结构图
图5为网络在训练集上正确率曲线图
图6为网络在验证集上正确率曲线图
具体实施方式
本发明用于提供一种基于卷积神经网络的脱机手写汉字识别方法,为了使本发明的技术方案及效果更加清晰、明确,下面结合附图,对本发明的具体实施方式进行详细描述。
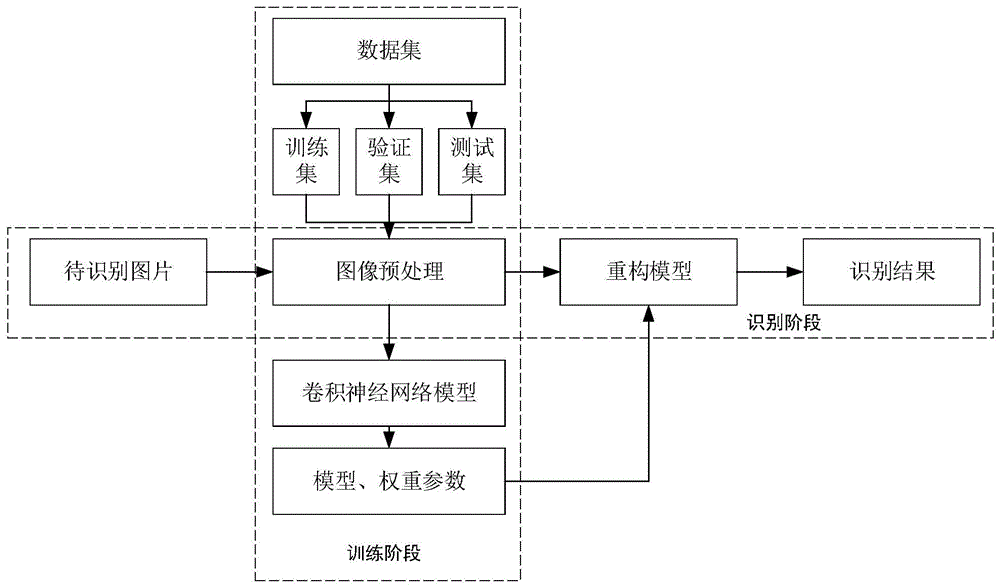
如图1所示,本发明设计的一种基于卷积神经网络的脱机手写汉字识别方法包括训练和识别两个阶段,训练阶段主要包括数据集获取,数据集划分,图像预处理,卷积神经网络模型构建与训练,模型及权重参数的保存;识别阶段主要包括图像预处理,重构模型,识别结果输出等过程。
1.模型训练
数据集获取:使用casia-hwdb1.1数据集作为本设计训练集,casia-hwdb1.1数据集涵盖了3755类一类汉字,总计1,121,749个汉字,分为训练集和测试集两部分,训练集包含每类汉字约240个,包含测试集每类汉字约60个。为了验证模型的泛化能力,本发明将训练集又分为了训练集和验证集两部分,最终训练集包括每类汉字200个,验证集包含每类汉字约40个。casia-hwdb1.1数据集原始格式为.gnt格式文件,无法直接打开,根据.gnt文件格式各个字段含义,通过编程将其转换为.hdf5文件,作为卷积神经网络的输入。想比于将.gnt文件转换为常规的.jpg或者.png格式文件,使用.hdf5可以大大节省图片读取时间,减少大量的磁盘寻址操作。casia-hwdb1.1数据集样本图像如图2所示。
图像预处理:casia-hwdb1.1数据集中图像为灰度图像,但图像的大小并不统一,对图像进行尺寸归一化操作,来满足卷积神经网络图像输入的要求。归一化后图像的尺寸为64*64,采用最近邻插值法进行归一化操作。设原图像的大小为(s_height,s_weight),目标图像大小为(d_height,d_width),图像的高度和宽度缩放比例为h_ratio=s_height/d_height,w_ratio=s_width/d_width,则目标图像(x,y)处的像素值等于原图像(x*w_ration,y*h_ration)处的值。归一化后,对图像进行对比度增强操作,设原图像的像素值范围为[a,b],将像素范围[a,b]缩放到[0,255],具体公式为:
x表示原图像的像素值,g(x)表示对比度增强后图像像素值。以手写汉字“似”为例,图像尺寸归一化及对比度增强前后示意图如图3所示。
卷积神经网络模型构建:图3为本发明卷积神经网络模型结构图,包括输入层,5个卷积层,3个全连接层,4个最大值池化层,softmax层及输出层。输入层图像的维度为64*64*1,64*64表示图像的尺寸,1代表图像的通道数;图中c开头的代表卷积层,以c1-64,3*3+2(s)为例,1代表是第一个卷积层,64代表卷积核个数,3*3代表卷积核尺寸,2(s)表示卷积步长为2*2;maxpool,2*2+2(s)表示池化层,并且采用最大值池化的方法,2*2表示池化尺寸,2(s)表示池化步长为2*2;fc表示全连接层,以fc1-512为例,1代表第一个全连阶层,512表示全连接层神经元个数;最后softmax层用于判决识别为每种汉字的概率。在本模型中,每一个卷积层和全连接层后都紧接着一个relu激活层,每一个卷积层的卷积核的尺寸和步长设置都相同,卷积时为保证图像大小一致,均采用了0填充策略。为方便理解,在图右边给出了模型每一层输出图像的信息,数字含义同输入层图像维度。
模型训练:本发明使用keras框架搭建模型并进行训练,keras后端基于tensorflow。训练时,使用交叉熵损失函数作为代价函数,采用随机梯度下降算法进行权重更新,来最小化代价函数。训练时,批尺寸设置为128,初始学习率为0.01,每2个迭代周期学习率减半一次。在全连阶层fc1和fc2层后,均设置了dropout来减小模型过拟合,dropout均设置为0.5。模型在casia-hwdb1.1训练集上进行训练,训练迭代次数设置为20次,每次迭代结束时,在验证集上进行验证,训练中,通过tensorboard实时观测代价函数及正确率数据。模型在训练集上的正确率变化曲线如图4所示,模型在验证集上的正确率变换曲线如图5所示。可以看到,模型在训练集上的准确率在94%左右,在验证集上的准确率在95%左右。最终将训练好的模型在测试集上进行测试,dropout均设置为1,达到了94.22%的正确率。可以看到模型的泛化能力较好。
模型及权重参数的保存:在模型训练过程及结束时,保存模型的结构到.json格式文件,保存模型的权重到.hdf5文件。
2.分类识别
训练好卷积神经网络模型后,就可以利用该模型进行脱机手写汉字识别。从casia-hwdb1.1数据集中随便获取一张图片,采用与模型训练时相同的图像预处理方法进行预处理操作,然后利用模型训练时保存的.json模型文件及.hdf5权重文件,重构训练好的卷积神经网络模型,利用该模型进行分类识别,输出最终识别结果。
- 还没有人留言评论。精彩留言会获得点赞!