一种改进PBFT的以太坊共识机制应用于联盟链的方法与流程
本发明涉及区块链技术领域,具体涉及一种改进pbft(practicalbyzantinefaulttolerancepracticalbyzantinefaulttolerance,实用拜占庭容错算法)的以太坊共识机制应用于联盟链的方法。
背景技术:
在区块链系统中,共识算法作为保证分布式节点间数据一致性的算法,可以被分为两大类,即概率一致性算法和绝对一致性算法。
概率一致性算法指在不同分布式节点之间,有较大概率保证节点间数据达到一致,但仍存在一定概率使得某些节点间数据不一致。对于某一个数据节点而言,数据在节点间不一致的概率会随时间的推移逐渐降低至趋近于零,从而最终达到一致性。例如工作量证明算法(proofofwork,pow)、股份证明算法(proofofstake,pos)和委托股权证明算法(delegatedproofofstake,dpos)都属于概率一致性算法。
绝对一致性算法则指在任意时间点,不同分布式节点之间的数据都会保持绝对一致,不存在不同节点间数据不一致的情况。例如分布式系统中常用的paxos算法及其衍生出的raft算法等,以及拜占庭容错类算法(类bft算法)。
根据cap原理可知,概率一致性算法保证了系统的可用性而牺牲了系统的一致性,绝对一致性算法则与之相反,保证了系统的一致性而牺牲了系统的可用性。
目前根据区块链应用对象不同,可将区块链分成三类,即是公有链、私有链和联盟链。公有链是完全去中心化的,任何人既可以进行交易也可以读取信息。任何人都可以参与链上的交易确认和共识机制,各个节点可以随时加入,也可以随时退出;私有链是对单独的个人或实体进行开放的区块链系统,系统内的每个节点的权限都需要组织来分配,对每个节点开放的数据量要视情况由组织来决定;然而联盟链是由多个中心控制,系统由几个权威的机构共同分布式记账,这些节点再根据共识机制协调工作。这是部分去中心化的区块链,民众可以进行查阅和交易,不过验证交易的话就需要联盟内部决定。根据前面描述,将区块链应用在食品供应链中时,食品供应链可归为联盟链。因为食品供应链的记账权力控制在供应链各节点中,包括供应商、制造商、零售商和监管机构等,而消费者可以查看食品处于供应链各环节中的信息,同时保证信息的安全可追溯。
目前以太坊采用的共识机制是工作量证明机制,虽然pow可以实现去中心化,将记账权分派到其他节点,且很好的实现了供应链节点间的相互信任,但是该共识机制应用于联盟链有很多缺点,主要缺点有以下几点:
(1)pow中的挖矿机制对计算资源要求很高,易造成大量电力资源浪费和硬件设备浪费。
(2)采用pow共识机制,会造成区块同步时间长,可扩展性很弱,最致命的是tps低且响应速度慢,这是现在商业联盟链所不能接受的。
(3)由于联盟链的计算能力比公有链低,容易被其他节点通过算力堆积(包括恶意联盟等)破坏整条链的可信度,造成不可估量的损失。
技术实现要素:
本发明首先进行pbft共识机制的改进,解决网络拥挤问题,然后提出了基于dpoa+pbft的共识机制作为以太坊共识机制的基础,不仅能提升系统处理交易数量,而且还能实现快速可靠的秒级确认。
为了实现上述任务,本发明采用以下技术方案:
一种改进pbft的以太坊共识机制应用于联盟链的方法,包括以下步骤:
在区块链系统中,对于联盟链中的节点,使用dpoa共识机制筛选出参与共识节点,将这些节点构成联盟链的计费网络;
将pbft算法应用于联盟链中,以保证联盟链中节点的交易信息达成共识的一致性;若联盟链中某节点的区块链数据信息与其他节点的信息不同时,则该节点向联盟链中的其他2f+1个节点请求联盟链缺失的区块的hash,其中f为联盟链中拜占庭节点数量;若该节点收到大于f个节点返回的区块的hash一致,则认为需要同步的区块是可信任的;若该节点在本地有此区块的hash,则不向其他节点同步此区块,直接将本地区块添加到联盟链;否则,就选择任意一个收到此区块hash的节点,并同步此区块;当该节点完成联盟链的同步之后,自动更新该节点内存所存储的交易列表;根据联盟链中最新区块产生的时间,清除已被打包成区块并上链的交易信息。
进一步地,所述的方法还包括:
通过以下方法判断联盟链中的主节点是否出现错误,在出现错误时进行主节点的重新选择:
当主节点交易列表为空时,若联盟链最新添加的区块数据不为空,且当前时间与最新上链区块的时间之差大于t,则判定主节点出现错误,需要切换视图重新选择主节点;其中,t为从最新上链的区块产生并达成共识的最长时间;
若联盟链最新区块为空,且当前需要共识的区块也为空,则需要等待时间t后查看当前需要共识的区块能否达成共识,如不能达成共识就切换视图;若主节点交易列表不为空且当前时间与最新上链区块的时间之差大于t,则判定主节点出现错误,需重新选择主节点来提交区块信息。
进一步地,所述的使用dpoa共识机制筛选出参与共识节点,包括:
从联盟链的各个节点中筛选出具有稳定在线、平滑传输和良好性能的高质量节点并集中在一个候选池中,然后使用dpoa共识机制从候选池中选择一定数量的节点作为参与共识节点。
进一步地,所述的计费网络,是进行共识计算的节点在参与共识的时候所需要的激励费用。
本发明具有以下技术特点:
1构建基于以太坊的联盟链,但是以太坊共识机制pow会造成系统算力浪费,还会因为网络延迟致使区块链产生支链。采用基于pbft共识机制的以太坊能够降低算力损耗,而且能够实现交易秒级确认。
2对pbft共识机制中的检查点协议进行改进,当区块达成共识后,内存将该区块之前的交易全部删除,减少内存空间损耗,删除区块交易数据不需要达成共识,减少了网络资源的消耗。
3对pbft共识机制中的视图切换机制进行改进,本方案采用超时触发机制来重新选择系统主节点,减少节点间通信,使得系统网络资源损耗减少。
附图说明
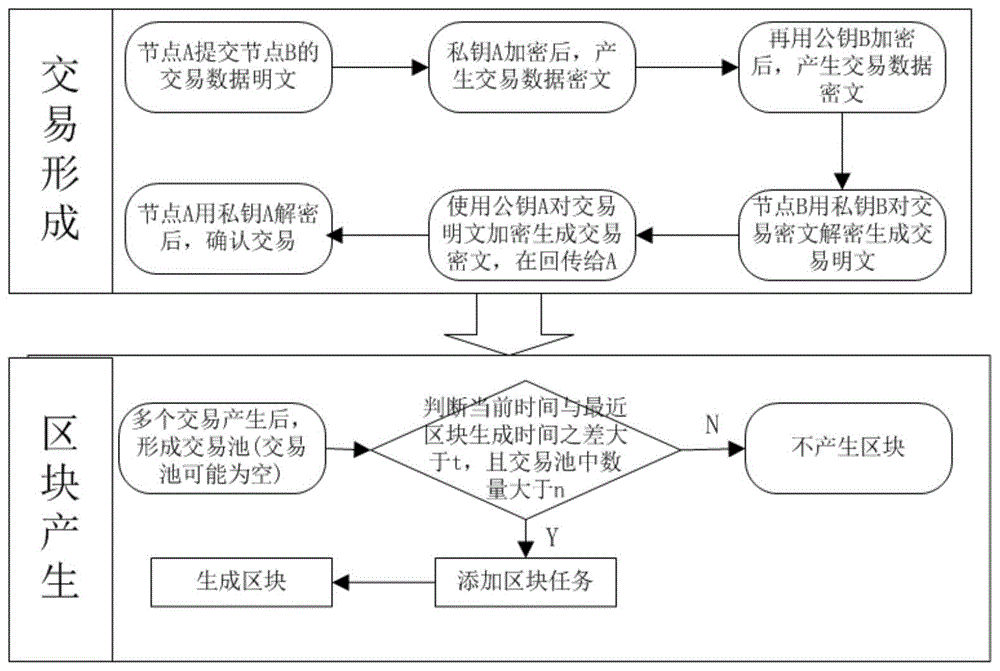
图1为区块产生流程图;
图2为判断联盟链中有多少个拜占庭节点的算法图;
图3为请求消息达成共识一致性协议过程图;
图4为本方案中提出的视图切换机制的示意图;
图5的(a)、(b)分别为本方案实验平台的核心、线程查看界面以及配置查看界面;
图6为拜占庭节点测试的结果示意图;
图7为cpu损耗率对比图;
图8为清除区块传输消耗对比图;
图9为系统视图切换网络消耗对比图。
具体实施方式
一、区块产生机制
联盟链(例如食品供应链)的成员进行交易时,进行交易的节点先对交易进行校验以保证交易的有效性,然后交易按序(包括从网络其他节点传过来的交易)写入区块中。当区块按照标准(区块大小和区块生成时间标准)生成后,则广播至网络其他节点,其他节点则解析区块,对区块中的交易进行校验,校验通过后各节点将区块异步添加到区块链中。区块链在系统中数据一致性的保持是通过区块头中的父哈希来保持的,区块头通过父哈希将所有区块连成一条链。
当联盟链某节点的某个时间段内没有发生交易时,即该节点交易列表为空(可能出现网络延迟或该节点网络出现中断等情况),该节点会计算系统时间与区块链最近添加上区块时间之差,我们计为t。节点从产生区块到全网达成共识所需时间计为δt。当t>δt时,则表明此时产生了一个空的区块,并在共识网络中达成一致,然后将空区块添加到区块链中,最后该节点停止生产区块,全网会重新选择主节点负责区块的产生。如果主节点交易列表不为空,但在指定时间内全网不能达成共识,则重新选择主节点。对于节点出现恶意更改交易信息,则会取消其作为主节点的资格。
如图1所示,联盟链节点a向节点b发起交易,自己先用私钥a和公钥b对交易信息加密,然后将交易数据发送给节点b。节点b收到加密交易数据后,然后用自己的私钥b对其解密,确认交易后,再用私钥b和公钥a对确认交易信息加密回传给节点a。节点a再用自己的私钥对加密交易信息进行解密,确认b对交易信息已确认,然后交易完成,将交易放入交易池中,并广播至供应链其他节点。供应链主节点先判断当前时间与区块链最近添加的区块时间戳之差是否大于δt,若不大于则不产生区块。若大于δt,则添加一个区块任务,并采用锁机制,防止多线程造成验证区块数据不一致。然后开始执行区块任务直到区块通过验证添加到区块链中。
二、区块达成共识的协议
1.拜占庭节点数量计算
所谓拜占庭节点即是一个可能呈现任意行为的节点,比如,该节点不能发送任何消息,向不同临近节点发送不同且错误的消息,以及谎报自己的输入值等。判断联盟链中有多少个拜占庭节点,由图2中所给出的算法可知。
2.参与共识节点的选择
dpoa(delegatedproof-of-ability)共识机制是根据dpos的思想,提出了一种选择参与共识的节点的机制。与传统的dpos不同之处在于,dpoa共识机制并不是根据矿工持有的代币数量或币龄作为选举标准投票权重,而是按参与供应链各节点的设备存储容量、网络稳定性、带宽、时延、cpu使用率等指标作为衡量标准,以获得更好的公平性和网络效率。
dpoa共识机制的具体处理机制如下:对于存储空间不足的设备,则不再参与记账;对于网络不稳定的节点,则减小其权重,则由它提议(propose)区块的机率降低,这样就能让网络状况好的节点多提议区块;对于带宽大的节点,则增加其权重,以提高它提议区块的机率;对于时延低的节点,则增加其权重,以提高它提议区块的机率;对于cpu使用率高的节点,则减小其权重,以降低它提议区块的机率。
dpoa共识机制能有效保证参与记账节点总是有足够存储空间、系统状态较好、网络环境较好的节点,保证了区块链系统的稳定运行,解决了供应链各节点网络环境差异大的问题。由于dpoa每轮动态选择部分满足条件的节点作为投票节点,使共识机制更加安全、稳定和高效。
首先监控系统从联盟链的各节点中选择具有稳定在线、平滑传输和良好性能的n个高质量节点,并集中到一个候选池中。然后使用dpoa共识机制从候选池中选择一定数量的节点,以形成整个联盟链的计费网络;该计费网络,是进行共识计算的节点在参与共识的时候所需要的激励费用。这些节点定期轮换并重新选举,以防止计算节点被外界暴露和攻击。
3.pbft共识的一致性协议
假设系统中节点数量为r>=3f+1,其中f为系统中拜占庭节点数量。在发送消息的时候通过环境状态、时间戳、请求、回复信息,客户端同样等待2f+1个回复,同时保证签名、时间戳、回复信息来保证一致性。这里存在两种情况,一种是客户端请求超时,那就再发送一次,如果是主节点p出故障,那就改变环境状态,新选一个主节点p,以保证第二次的执行过程(视图切换机制)。
在实际的算法流程中,pbft算法定义三个任务阶段:预准备(pre-prepare)、准备(prepare)、确认(commit)。
1)预准备:主节点p分配一个系统序列号id,发送区块给所有其他节点b。发送格式(环境状态、id、信息摘要、客户端请求)。b节点验证信息摘要和客户端请求一致,验证当前环境状态编号。
2)准备:b节点在接收信息后加上自己的消息日志,发送至其余节点。p和b节点同时验证消息签名,如果一致,那么就把验证通过写入消息日志。每个节点在准备阶段对每个副本节点验证预准备的消息和准备消息一致性检查完毕。
3)确认:在前面预准备和准备阶段正常情况下,在同一系统环境中,所有请求序号一致,验证消息一致,也即是确认2f+1个节点发送了之前发送的序号和消息。
每个节点接受确认消息,签名正确;消息的系统环境编号v与节点的环境编号v一致;消息的序号id满足序列要求。节点通过确认至少2f+1个副本信息,保证了交易信息达成共识的一致性。
如图3所示,client是客户端,主节点p、节点1、节点2和节点3是分布式系统中的节点成员,其中由主节点p提议区块,节点1、2、3节点对提议出来的区块进行投票,其中节点3已发生故障。我们默认节点3发送信息为无效。那么pbft算法执行的流程如下:
1)client发起一个请求到主节点p。(该请求会广播到各个节点)
2)节点p开始对请求排序编号,并把请求序号发送到节点1、2、3。
3)节点2、3互相之间和节点1之间发送消息。
4)节点1、2、3之间确认节点p的分配序号,互相确认。
5)节点1、2、3确认信息回复client。
6)客户端client判断收到确认是否在2f+1内,确认结果。
4.改进的检查点协议
本方案将pbft算法应用于联盟链中,以保证联盟链中节点的交易信息达成共识的一致性;而当联盟链中有些节点可能因网络故障或网络延迟等原因,导致节点信息更新程度落后其他节点。所以,节点需要周期性地同步其他节点数据,保持数据与其他节点的一致性。以太坊采用的同步方式是直接向他自认为可信任的节点同步区块,并添加到区块链中,然而联盟链中可能存在不可信节点,因此不能采用以太坊中同步可信任节点区块的方法。
本方案提出,若联盟链中某节点a的区块链数据信息与其他节点的信息不同时,则该节点a向联盟链中的其他2f+1个节点请求联盟链缺失的区块的hash,其中f为联盟链中拜占庭节点数量;若该节点a收到大于f个节点返回的区块的hash一致,则认为需要同步的区块是可信任的;若该节点a在本地有此区块的hash,则不向其他节点同步此区块;直接将本地区块添加到联盟链;否则,就选择任意一个收到此区块hash的节点(所述的大于f个节点中的任一节点),并同步此区块。
联盟链的节点在完成区块链同步后,需要对证书信息回收,降低节点设备的内存开销。节点a在定期同步其他节点区块链信息后,会自动更新节点a内存所存储的交易列表。根据联盟链中最新区块产生的时间,清除已被打包成区块并上链的交易信息,这样就不需要采用以前的检查点协议即是通过三阶段协议来清理已上链的交易,这样避免了大量的网络开销。
5.改进的视图切换机制
该机制能够快速解决主节点不能在规定时间内出块的问题,保证系统即使主节点出错也能保证系统正常运行,避免了客户端确认长时等待。当主节点发生异常不能出块,则需要重新选择主节点。pbft在视图切换过程中,可能会因为视图切换不当导致系统没能选出提议区块的主节点,同时视图切换也会进行节点间的通信来选出主节点。本方案不采用通信的方式来选取主节点,而是采用超时机制来选举。通过以下方法判断联盟链中的主节点是否出现错误,在出现错误时进行主节点的重新选择:
当主节点交易列表为空时,若联盟链最新添加的区块数据不为空,且当前时间与最新上链区块的时间之差大于t,则判定主节点出现错误,需要切换视图重新选择主节点;其中,t为从最新上链的区块产生并达成共识的最长时间,t可根据系统测试得到。切换视图过程中将上个节点在共识过程中传播的信息进行清除释放内存空间,并由新的主节点提议需要达成共识的区块信息,使系统正常运行。
若联盟链最新区块为空,且当前需要共识的区块也为空,则需要等待时间t后查看当前需要共识的区块能否达成共识,如不能达成共识就切换视图;若主节点交易列表不为空且当前时间与最新上链区块的时间之差大于t,则判定主节点出现错误,需重新选择主节点来提交区块信息。
pbft中的视图切换需要共识节点间的相互通信。当主节点出现故障后,选出新的主节点并将视图切换信息发送给其他节点,其他节点收到包括自己的2f+1个切换信息时,则需要向新的主节点发送确认信息。主节点收到确认消息后,在重新开始执行区块共识协议。本方案提出的视图切换机制采用超时触发重新选举主节点的方法,按照最新区块添加到区块链的时间以及在区块产生到达成共识所需的最长时间t来判断是否进行视图切换,这样便可以减少节点间的相互通信,减少了流量损耗。
实验部分:
如图5所示,可以看到本方案实验平台的处理器是intel(r)core(tm)i5-6300hqcpu@2.3ghz,内存16g,通过命令可以查看到实验机器是四核四线程的。我们在windows10操作系统上安装vmware虚拟机并在虚拟技上安装4台ubuntu虚拟机作为4个模拟节点,他们共享实验机器的cpu。
本方案的实验机器配置了4个模拟节点,四个节点拥有等同的配置参数和计算能力,每个节点都部署了pow共识机制代码和改进pbft共识机制代码。然后,人为实验两个共识机制能够容忍的拜占庭错误,实验结果如图6所示,表明了供应链在能够容忍节点错误数量的情况下是可以达成共识实现去中心化的。从图6可以看出,pow共识机制可以容忍2个拜占庭节点,而pbft共识机制最多只能容忍1个拜占庭节点。从拜占庭错误节点容忍数量来说,pow共识机制比pbft共识机制要多。
接下来开始单节点测试pow共识机制与pbft共识机制的算力消耗,因为实验机器是四核四线程的,pow可以用四核同时计算(四线程挖矿),最终计算出符合要求的随机值,而pbft只需单线程即可用三阶段达成共识。其结果如图7所示,横坐标代表测试进行的时间,纵坐标代表cpu损耗率。改进的pbft共识机制在实验机器上的损耗率大致在20%左右,而pow共识机制的损耗率接近100%,相当于满负荷运行,因此改进的pbft共识机制损耗率比pow共识机制要小很多,减小了很多算力消耗,同时也能达成供应链区块的共识。
接下来在比较现有的pbft共识机制和改进pbft共识机制的通信消耗。节点在删除已达成共识的区块交易数据时,网络传输区块数据所耗费的网络资源的对比,如图8所示,横坐标代表在执行检查点协议时清除内存中区块交易的数量,纵坐标代表在执行检查点协议时网络传输区块哈希数量。pbft共识机制中已达成共识的区块在内存清楚是采用三阶段验证的方法,也即是在清除已共识的区块需要与其他节点达成共识才能清楚,这造成了网络消耗,而改进的pbft则不需要损耗。从图中可以看出,pbft共识机制中网络传输区块数量随着以达成共识区块数量的增加而成正比增加,而改进pbft共识机制中网络传输区块数量和已达成共识区块数量没有关系且传输量为0。
最后我们看一下当主节点发生错误时,对比下pbft共识机制和改进的pbft共识机制在系统进行视图切换所产生的网络消耗。图9展示了系统主节点产生故障后,系统进行视图切换所产生的网络消耗,图中横坐标代表系统总节点数量,纵坐标代表系统进行视图切换时对区块达成共识所需的节点数量。根据图中曲线可知:pbft共识机制中,网络消耗会随着系统中拜占庭节点数量增加而增加,而改进pbft共识机制中,网络消耗与系统中拜占庭节点数量没有关系且网络消耗为0。
- 还没有人留言评论。精彩留言会获得点赞!