一种图书馆图书自动分类方法与流程
本发明涉及信息管理领域,具体涉及一种图书馆图书自动分类方法。
背景技术:
基于电子科技技术的发展和推广,数字化办公已越来越受到用户的青睐,相对于传统的纸质化办公,数字化办公具有效率高、易管理和环保等优势。而基于长久的数字化办公,在阅读方面,人们也越来越倾向于网络的推荐和检索。
在大众阅读的良好环境下,各地区也相应建设了如图书馆等供公众借阅图书的场所,而在建设该类场所的同时,因考虑到需要存入大量的图书,这就需要大量的工作量以对图书进行相应的归类和存放,即同种类别的图书需要放入相应的书柜中,以便查阅。
而对于如何将图书进行分类,在传统方式中,为人工分类,或者人工借助扫码设备对图书进行分类。在一方面,条形码也仅能显示图书在专业上的分类,对于其他分类信息是无法得知的。因此,通过扫描也仅能实现在专业上的分类。该种分类方式下,需要该图书的信息已写入扫码数据库,进一步的,还需要该图书已登记有条形码。因此,该种分类方式存在效率不高和分类信息不丰富的缺陷,对于受众在选择上,无法提供相应的参考信息。
技术实现要素:
为了解决上述问题,本发明提供了一种图书馆图书自动分类方法。
本发明的具体技术方案为:一种图书馆图书自动分类方法,包括:
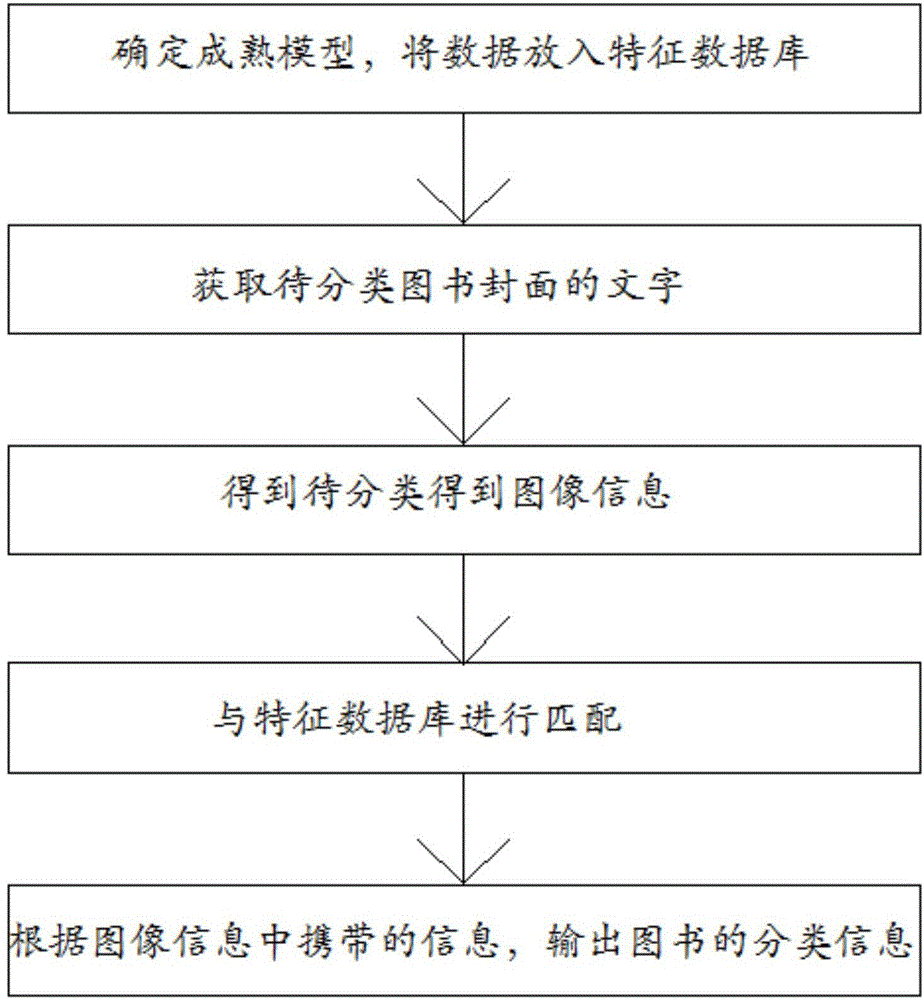
步骤一、确定成熟模型,将数据放入特征数据库;
步骤二:获取待分类图书封面的文字;
步骤三:得到待分类得到图像信息;
步骤四:与特征数据库进行匹配;
步骤五:根据图像信息中携带的信息,输出图书的分类信息。
优选的,所述步骤一具体为:读取所有图书的名称及对应书架并将图书名称转化为汉字,通过汉语语言模型结合用来产生词向量的相关模型或信息检索数据挖掘的常用加权技术进行分词形成特征向量,其中,n为大于等于1的正整数,根据书架所属的图书种类个数确定分类个数;
将已有图书的特征向量及对应的书架号分为3块,比例分别为7∶1.5∶1.5,其中70%用于训练模型15%用于测试训练精度并不断调整模型已使测试精度达到最高,剩余的15%用于实际测量精度;此时,通过模型库中的模型对70%的图书数据图书特征向量进行分类,得出训练模型并使用15%的数据作为测试数据对模型进行评测,得到精度最高的模型,并用剩余15%的数据进行实测,选择此时精度最高的模型作为成熟模型,放入特征数据库。
优选的,所述步骤二具体为:通过拍摄方式获取待分类图书封面的文字。
优选的,所述步骤二具体为:通过扫描方式获取待分类图书封面的文字。
优选的,所述封面文字按照行划分,具体为:将图书封面的文字按照在图书封面上文字排版划分为多行。
优选的,所述步骤三具体为:利用训练好的成熟模型检测拍摄到的待分类图书封面的文字,若未检测到拍摄到的待分类图书封面的文字,则系统处于等待状态,若检测到拍摄到的待分类图书封面的文字,系对图书进行匹配。
优选的,所述步骤三具体为:利用训练好的成熟模型检测扫描到的待分类图书封面的文字,若未检测到扫描到的待分类图书封面的文字,则系统处于等待状态,若检测到扫描到的待分类图书封面的文字,系对图书进行匹配。
优选的,所述步骤四具体为:将图书封面的文字逐行与特征数据库进行匹配,识别出待测图书的具体信息。
优选的,所述步骤四具体为:将图书封面的文字逐行与特征数据库进行匹配,若未匹配到待测图书的文字信息,则依次识别下一行的文字,直到匹配到待测图书的文字信息,则停止匹配。
优选的,所述步骤五具体为:识别出具体信息的图书,使用成熟模型对图书进行分类,输出图书的分类信息。
本发明的有益效果为:本发明所述的图书分类方法,首先得到成熟模型,将数据放入特征数据库,为图书分类提供了数据的支撑;然后将获取的待分类图书封面文字逐行与特征数据库中的数据进行匹配,实现了快速自动对待测图书进行相应分类的效果,同时该方法操作方便,有效的节省成本和人力物力。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
如图1:一种图书馆图书自动分类方法,包括:
步骤一、确定成熟模型,将数据放入特征数据库;
具体为:读取所有图书的名称及对应书架并将图书名称转化为汉字,通过汉语语言模型结合用来产生词向量的相关模型或信息检索数据挖掘的常用加权技术进行分词形成特征向量,其中,n为大于等于1的正整数,根据书架所属的图书种类个数确定分类个数;
将已有图书的特征向量及对应的书架号分为3块,比例分别为7∶1.5∶1.5,其中70%用于训练模型,15%用于测试训练精度并不断调整模型已使测试精度达到最高,剩余的15%用于实际测量精度;此时,通过模型库中的模型对70%的图书数据图书特征向量进行分类,得出训练模型并使用15%的数据作为测试数据对模型进行评测,得到精度最高的模型,并用剩余15%的数据进行实测,选择此时精度最高的模型作为成熟模型,放入特征数据库。
步骤二:获取待分类图书封面的文字;
具体为:将图书封面的文字按照在图书封面上文字排版划分为多行,通过逐行拍摄方式获取待分类图书封面的文字。
步骤三:得到待分类得到图像信息;
利用训练好的成熟模型检测拍摄到的待分类图书封面的文字,若未检测到拍摄到的待分类图书封面的文字,则系统处于等待状态,若检测到拍摄到的待分类图书封面的文字,系对图书进行匹配。
步骤四:与特征数据库进行匹配;
将图书封面的文字逐行与特征数据库进行匹配,识别出待测图书的具体信息。具体为:
将图书封面的文字逐行与特征数据库进行匹配,若未匹配到待测图书的文字信息,则依次识别下一行的文字,直到匹配到待测图书的文字信息,则停止匹配。
步骤五:根据图像信息中携带的信息,输出图书的分类信息。
识别出具体信息的图书,使用成熟模型对图书进行分类,输出图书的分类信息。
实施例2
如图1:一种图书馆图书自动分类方法,包括:
步骤一、确定成熟模型,将数据放入特征数据库;
具体为:读取所有图书的名称及对应书架并将图书名称转化为汉字,通过汉语语言模型结合用来产生词向量的相关模型或信息检索数据挖掘的常用加权技术进行分词形成特征向量,其中,n为大于等于1的正整数,根据书架所属的图书种类个数确定分类个数;
将已有图书的特征向量及对应的书架号分为3块,比例分别为7∶1.5∶1.5,其中70%用于训练模型15%用于测试训练精度并不断调整模型已使测试精度达到最高,剩余的15%用于实际测量精度;此时,通过模型库中的模型对70%的图书数据图书特征向量进行分类,得出训练模型并使用15%的数据作为测试数据对模型进行评测,得到精度最高的模型,并用剩余15%的数据进行实测,选择此时精度最高的模型作为成熟模型,放入特征数据库。
步骤二:获取待分类图书封面的文字;
具体为:将图书封面的文字按照在图书封面上文字排版划分为多行,通过逐行扫描方式获取待分类图书封面的文字。
步骤三:得到待分类得到图像信息;
利用训练好的成熟模型检测扫描到的待分类图书封面的文字,若未检测到扫描到的待分类图书封面的文字,则系统处于等待状态,若检测到扫描到的待分类图书封面的文字,系对图书进行匹配。
步骤四:与特征数据库进行匹配;
将图书封面的文字逐行与特征数据库进行匹配,识别出待测图书的具体信息。具体为:
将图书封面的文字逐行与特征数据库进行匹配,若未匹配到待测图书的文字信息,则依次识别下一行的文字,直到匹配到待测图书的文字信息,则停止匹配。
步骤五:根据图像信息中携带的信息,输出图书的分类信息。
识别出具体信息的图书,使用成熟模型对图书进行分类,输出图书的分类信息。
本发明的有益效果为:本发明所述的图书分类方法,首先训练图书模型,形成特征向量,得到成熟模型,将数据放入特征数据库,为图书分类提供了数据的支撑;然后将获取的待分类图书封面文字逐行与特征数据库中的数据进行匹配,实现了快速自动对待测图书进行相应分类的效果,同时该方法操作方便,有效的节省成本和人力物力。
- 还没有人留言评论。精彩留言会获得点赞!