基于记忆单元强化-时序动态学习的行为识别方法与流程
本发明涉及一种行为识别方法,特别涉及一种基于记忆单元强化-时序动态学习的行为识别方法。
背景技术:
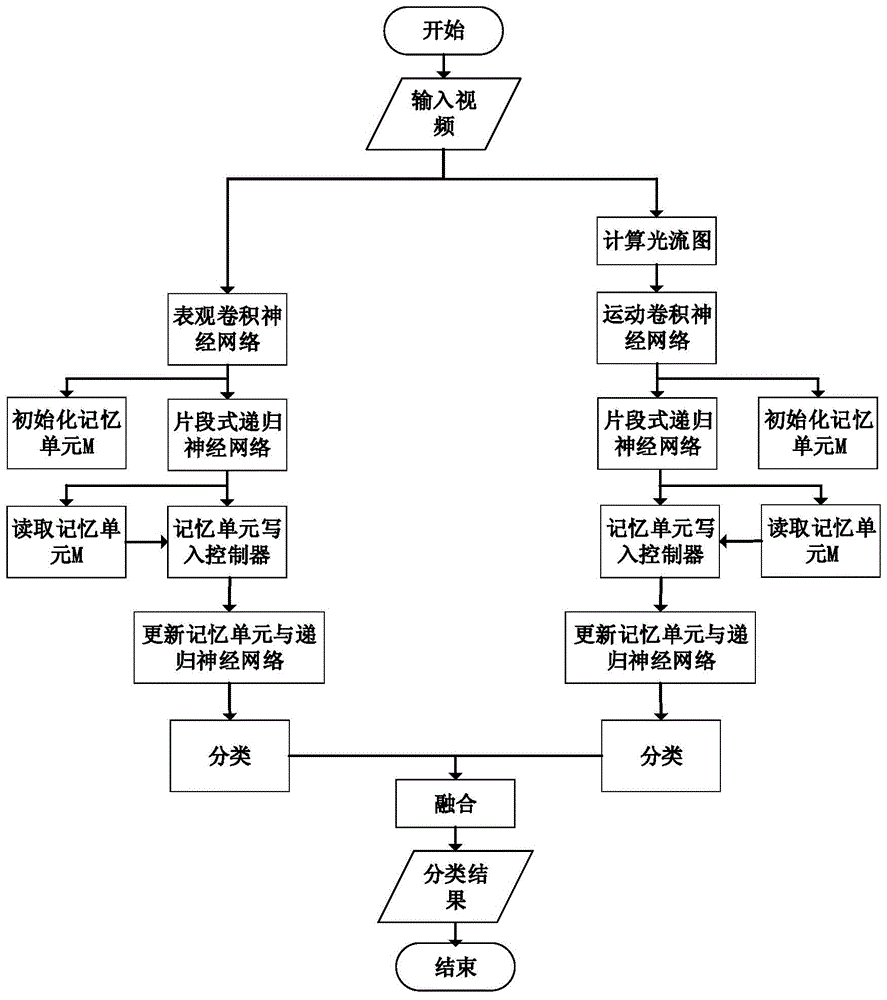
:文献“l.wang,y.xiong,z.wang,y.qiao,d.lin,x.tang,andl.v.gool.temporalsegmentnetworks:towardsgoodpracticesfordeepactionrecognition,inproceedingsofeuropeanconferenceoncomputervision,pp.20–36,2016.”公开了一种基于双流卷积神经网络与时序片段网络的人物行为识别方法。该方法利用两个独立的卷积神经网络来解决行为识别任务,其中,空间流网络从视频帧中提取目标的表观特征,而时序流网络则从对应的光流场数据中提取目标的运动特征,通过融合这两个网络输出得到行为识别结果。同时,该方法提出时序片段网络来建模视频序列的长时时序结构信息,该网络通过稀疏时序采样策略与序列尺度的监督学习,实现了整个神经网络的高效有效学习,并在大规模公开数据集上取得了较好的结果。文献所述方法对视频中的时序建模较为粗糙,使得网络在学习过程中往往会忽略特征的时序关联性;在视频序列较长及未剪辑时,该方法会将无关的噪音信息融入最终识别结果,降低人物行为识别的准确率,同时噪音信息的加入,也会使得整个神经网络的训练学习变得困难。技术实现要素:为了克服现有行为识别方法实用性差的不足,本发明提供一种基于记忆单元强化-时序动态学习的行为识别方法。该方法采用融合记忆单元的递归神经网络建模长时视频序列的时序结构信息,通过离散化记忆单元读写控制器模块将视频序列的每一视频帧分类为相关帧与噪音帧,将相关帧的信息写入记忆单元同时忽略噪音帧信息,该方法能够滤掉未剪辑视频中大量的噪音信息,提升后继行为识别的准确率。此外,融合记忆单元的递归神经网络可以实现大跨度时序结构的连接,通过数据驱动的自主训练学习,对复杂人物行为的长时时序结构模式进行建模,进而解决了现有的行为识别方法对长时、未剪辑视频的运动模式复杂,背景变化多难题,提升了人物行为识别方法的鲁棒性,并且达到平均94.8%、71.8%的识别准确率。本发明解决其技术问题所采用的技术方案:一种基于记忆单元强化-时序动态学习的行为识别方法,其特点是包括以下步骤:步骤一、计算视频帧ia的光流信息,其中每个像素的光流信息由二维向量(δx,δy)表示并保存为光流图im。利用两个独立思维卷积神经网络提取各自的高维语义特征:xa=cnna(ia;wa)(1)xm=cnnm(im;wm)(2)其中,cnna、cnnm分别代表表观卷积神经网络与运动卷积神经网络,用以提取视频帧ia与光流图im的高维特征。xa、xm分别为2048维向量,代表卷积神经网络提取出的表观与运动特征。wa、wm表示两个卷积神经网络的内部可训练参数。利用x表示卷积神经网络提取出的高维特征。步骤二、初始化记忆单元m为空,表示为m0。假设第t视频帧时,记忆单元mt不为空,其中包含nt>0个元素,分别表示为那么,对应时刻的记忆模块读取操作如下:其中,读取出的mht代表视频前t时刻的历史信息。步骤三、利用片段式递归神经网络,提取视频内容的短时上下文特征。以步骤一计算得到的高维语义特征x作为输入,对应第t视频帧时的特征记为xt。初始化长短时递归神经网络(lstm)的隐状态h0、c0为零,则t时刻的短时上下文特征计算如下:其中,emd()表示长短时递归神经网络,ht-1,ct-1表示递归神经网络前一时刻的隐状态。而作为视频内容的短时上下文特征用于后续计算。步骤四、对于每一视频帧,步骤一、二、三计算得到的高维语义特征xt,记忆单元历史信息mht以及短时上下文特征输入记忆单元控制器,计算得到二值化记忆单元写入指令st∈{0,1},具体如下:at=σ(qt)(6)st=τ(at)(7)其中,vt为可学习的行向量参数,wf、wc、wm为可学习的权重参数,bs为偏置参数。sigmoid函数σ()将线性加权的结果qt归一化到0,1之间,即at∈(0,1)。at输入到阈值限制的二值化函数τ()得到二值化记忆单元写入指令st。步骤五、基于二值化记忆单元写入指令st,更新记忆单元与片段式递归神经网络。对于每一视频帧,记忆单元mt的更新策略如下:其中,ww为可学习权重矩阵,该矩阵通过乘法运算将高维语义特征xt转换为记忆单元元素表示将写入记忆单元mt-1,形成新的记忆单元mt。此外,片段式递归神经网络的隐状态ht,ct更新如下:其中,为式(4)计算得到的结果。步骤六、利用记忆单元进行行为分类。假设视频总长为t,整个视频处理结束时记忆单元为mt,其中有nt个元素,则整个视频的特征表示f为:其中,f为d维向量,代表视频中行为类别的信息。该特征输入全连接分类层得到行为类别得分y,具体如下:y=softmax(w·f)(12)其中,w∈rc×d,c表示可识别的行为类别总数。计算得到的y表示系统对各个类别的分类得分,得分越高表示越有可能是该类行为。假设ya、ym分别表示表观与运动神经网络得到的得分,则最终得分yf如下:yf=ya+ym(13)其中,yf表示最终人物行为识别结果。本发明的有益效果是:该方法采用融合记忆单元的递归神经网络建模长时视频序列的时序结构信息,通过离散化记忆单元读写控制器模块将视频序列的每一视频帧分类为相关帧与噪音帧,将相关帧的信息写入记忆单元同时忽略噪音帧信息,该方法能够滤掉未剪辑视频中大量的噪音信息,提升后继行为识别的准确率。此外,融合记忆单元的递归神经网络可以实现大跨度时序结构的连接,通过数据驱动的自主训练学习,对复杂人物行为的长时时序结构模式进行建模,进而解决了现有的行为识别方法对长时、未剪辑视频的运动模式复杂,背景变化多难题,提升了人物行为识别方法的鲁棒性,并且达到平均94.8%、71.8%的识别准确率。下面结合附图和具体实施方式对本发明作详细说明。附图说明图1是本发明基于记忆单元强化-时序动态学习的行为识别方法的流程图。具体实施方式参照图1。本发明基于记忆单元强化-时序动态学习的行为识别方法具体步骤如下:步骤一、提取蕴含语义信息的高维表观与运动特征。首先,计算视频帧ia的光流信息,其中每个像素的光流信息由二维向量(δx,δy)表示并保存为光流图im。然后,利用两个独立思维卷积神经网络提取各自的高维语义特征:xa=cnna(ia;wa)(1)xm=cnnm(im;wm)(2)其中cnna、cnnm分别代表表观卷积神经网络与运动卷积神经网络,用以提取视频帧ia与光流图im的高维特征。xa、xm分别为2048维向量,代表卷积神经网络提取出的表观与运动特征。wa、wm表示两个卷积神经网络的内部可训练参数。由于表观神经网络与运动神经网络的后续操作完全一致,为使得标号简单清晰,利用x表示卷积神经网络提取出的高维特征。步骤二、初始化记忆单元m为空,表示为m0。假设第t视频帧时,记忆单元mt不为空,其中包含nt>0个元素,分别表示为那么,对应时刻的记忆模块读取操作如下:其中读取出的mht代表了视频前t时刻的历史信息,同时该历史信息影响了此时刻视频内容的分析与理解。步骤三、利用片段式递归神经网络,提取视频内容的短时上下文特征。以步骤一计算得到的高维语义特征x作为输入,对应第t视频帧时的特征记为xt。首先,初始化长短时递归神经网络(lstm)的隐状态h0、c0为零,则t时刻的短时上下文特征计算如下:其中emd()表示长短时递归神经网络,ht-1,ct-1表示递归神经网络前一时刻的隐状态。而作为视频内容的短时上下文特征用于后续计算。步骤四、离散化记忆单元写入控制器。对于每一视频帧,步骤1,2,3计算得到的高维语义特征xt,记忆单元历史信息mht以及短时上下文特征输入记忆单元控制器,计算得到二值化记忆单元写入指令st∈{0,1},具体如下:at=σ(qt)(6)st=τ(at)(7)其中vt为可学习的行向量参数,wf、wc、wm为可学习的权重参数,bs为偏置参数。由上可看出,sigmoid函数σ()将线性加权的结果qt归一化到0,1之间,即at∈(0,1)。其次,at输入到阈值限制的二值化函数τ()得到二值化记忆单元写入指令st。步骤五、基于二值化记忆单元写入指令st,更新记忆单元与片段式递归神经网络。对于每一视频帧,记忆单元mt的更新策略如下:其中ww为可学习权重矩阵,该矩阵通过乘法运算将高维语义特征xt转换为记忆单元元素表示将写入记忆单元mt-1,形成新的记忆单元mt。此外,片段式递归神经网络的隐状态ht,ct更新如下:其中为式(4)计算得到的结果。步骤六、利用记忆单元进行行为分类。假设视频总长为t,整个视频处理结束时记忆单元为mt,其中有nt个元素,则整个视频的特征表示f为:其中f为d维向量,代表了视频中行为类别的信息。然后,该特征输入全连接分类层得到行为类别得分y,具体如下:y=softmax(w·f)(12)其中w∈rc×d,c表示可识别的行为类别总数。计算得到的y表示系统对各个类别的分类得分,得分越高表示越有可能是该类行为。假设ya、ym分别表示表观与运动神经网络得到的得分,则最终得分yf如下:yf=ya+ym(13)其中yf表示最终人物行为识别结果。本发明的效果通过以下仿真实验做进一步的说明。1.仿真条件。本发明是在中央处理器为xeone5-2697a2.6ghzcpu、显卡nvidiak80、内存16g、centos7操作系统上,运用pytorch软件进行的仿真。仿真中使用的数据为两个公开测试数据集ucf101/hmdb51中的数据,其中摄像机移动变化较大,背景较为复杂。实验数据共包括13320/6766段视频,按照行为类别可分为101/51类。其中hmdb51数据集中的视频数据大多未剪辑,包含较多噪音。2.仿真内容。为了证明本发明的有效性,仿真实验对本发明提出的记忆单元强化和时序动态学习方法进行了对比实验。具体地,作为本发明的对比算法,仿真实验选择了准确率最高的双流网络架构(tsn)和l.sun等人在文献“l.sun,k.jia,k.chen,d.yeung,b.shiands.savarese.latticelongshort-termmemoryforhumanactionrecognition,inproceedingsofieeeconferenceoncomputervisionandpatternrecognition,pp.2166–2175,2011.”中提出晶格长短时递归神经网络的方法(lattice-lstm)。三个算法设置同样的参数,计算其在ucf101/hmdb51数据集上的平均auc数值。对比结果如表1所示。表1methodtsnlattice-lstmourauc(ucf101)93.6%94.0%94.8%auc(hmdb51)66.2%68.5%71.8%从表1可见,本发明的识别准确率显著地高于已有行为识别方法。具体地,算法tsn的准确率低于算法lattice-lstm和our,原因在于tsn算法没有考虑视频内容的时序变化模式,而lattice-lstm和our都采用了递归神经网络对视频的时序变化模式进行了建模,从而证明了本发明提出的基于递归神经网络的时序动态学习方法的有效性。另外,在hmdb51数据集上,算法our明显优于lattice-lstm,这是由于本发明提出的记忆单元能够有效强化递归神经网络对长时、未剪辑视频的处理能力。因此,为了记忆单元对递归神经网络强化的有效性,仿真实验在ucf101数据集上将各类递归神经网络lstm、alstm以及videolstm与本发明的算法进行了对比实验,结果如表2所示。表2methodlstmalstmvideolstmoursauc88.3%77.0%89.2%91.03%从表2可见,本发明融合得到的结果比各类递归神经网络结果准确率高,原因在于,本发明的记忆单元强化方法能够有效提取视频中的有效信息,进而建模视频中的时序变化模式。相比之下,简单的递归神经网络方法易受噪音的影响,因此反而降低了准确率。因此,通过以上仿真实验可以验证本发明的有效性。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1