一种热门话题活跃用户定位方法与流程
本发明涉及计算机领域,尤其涉及一种热门话题活跃用户定位方法。
背景技术:
在数据分析领域,经常需要对数据进行分析。在常见互动性网站中,比如知乎,百度贴吧存在大量的用户互评类数据,这类数据能够反应用户的个人偏好,也能够用于研究时事热点和社会现象,存在较多的社会信息,能够被广泛的应用于广告目标用户研究,热点问题研究,舆情监督等各个领域。但是现有技术中缺乏对于这类数据的数据处理方法,也难以从这类数据中提取出有效的数据源和活跃用户以用作后续的数据分析之用。
技术实现要素:
为了解决上述技术问题,本发明提出了一种热门话题活跃用户定位方法。本发明具体是以如下技术方案实现的:
一种热门话题活跃用户定位方法,包括:
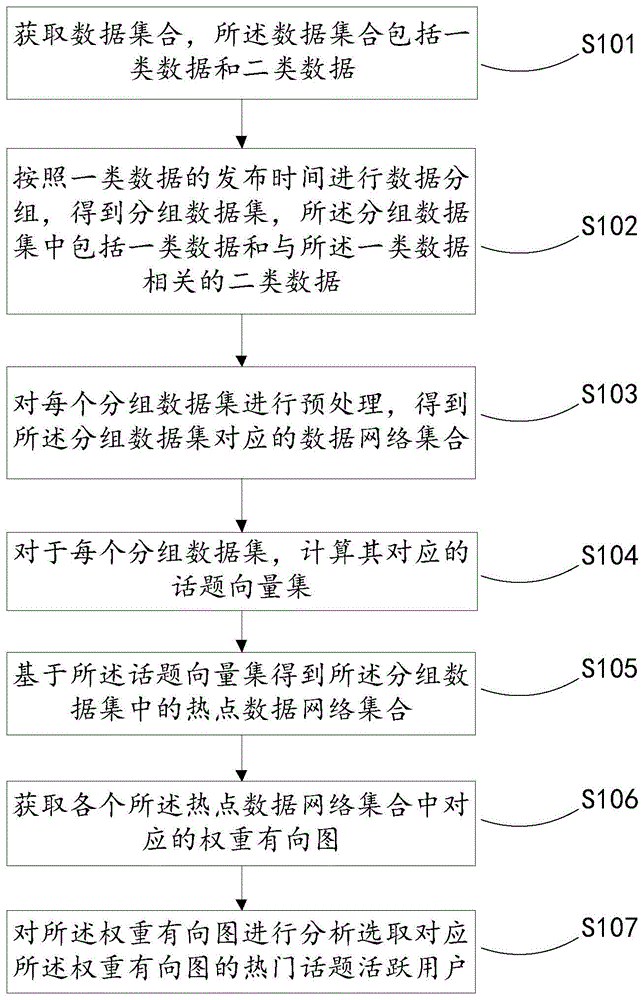
获取数据集合,所述数据集合包括一类数据和二类数据;所述一类数据为直接发布的数据,所述二类数据为针对一类数据的评论数据;
按照一类数据的发布时间进行数据分组,得到分组数据集,所述分组数据集中包括一类数据和与所述一类数据相关的二类数据;
对每个分组数据集进行预处理,得到所述分组数据集对应的数据网络集合;
对于每个分组数据集,计算其对应的话题向量集;
基于所述话题向量集得到所述分组数据集中的热点数据网络集合;
获取各个所述热点数据网络中对应的权重有向图;
对所述权重有向图进行分析,选取对应所述权重有向图的热门话题活跃用户。
进一步地,所述基于所述话题向量集得到所述分组数据集中的热点数据网络集合包括:
获取每个数据网络的热度属性;
根据所述热度属性提取疑似热点数据网络;
获取疑似热点数据网络的相关度矩阵;
获取所述相关度矩阵中数值大于预设相关度阈值的元素;
若所述元素总数大于预设的热度阈值,则所述疑似热点数据网络被判定为热点数据网络,从而得到热点数据网络集合。
进一步地,权重有向图的构建方法包括:
获取热点数据网络每条边的诚恳度权重和支持度权重;
根据所述诚恳度权重和所述支持度权重计算所述边的综合权重。
进一步地,还包括量化诚恳度权重的方法:
构建诚恳度量化表,所述诚恳度量化表包括字数区间和所述字数区间对应的诚恳度权重;
得到每条边中起点用户对终点用户的回复的字数;
根据所述诚恳度量化表查询所述字数所在的字数区间,并得到其对应的诚恳度权重。
进一步地,还包括量化支持度权重的方法:
根据预设的感情词语表提取每条边中起点用户对终点用户的回复中的目标感情词语;
获取目标感情词语对应的权重;
取全部目标感情词语对应的权重的总和值作为支持度权重。
进一步地,热门话题活跃用户的选取方法包括:
简化权重有向图得到目标有向图;
初始化目标有向图中各个顶点的热度值;
任意选择一个顶点,根据所述顶点和指向所述顶点的各个相关顶点的当前热度计算所述顶点的迭代后热度,并将所述迭代后热度作为所述顶点的当前热度;
按照步骤上述方法继续计算其它顶点的当前热度,直至所述目标有向图中各个顶点的当前热度趋于稳定;
选取当前热度最大的n个用户作为热门话题活跃用户。
本发明通过合理的数据处理步骤得到了热点数据网络集合,而热点数据网络集合的获取是研究热门话题的合理数据源,其具备广阔的应用空间。进一步地,本发明还从热点数据网络集合中得到了热门话题活跃用户,所述热门话题活跃用户可以作为很多场景的目标用户,比如发放调研报告,问卷调查,广告定向投放等等。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
图1是本发明实施例提供的一种热门话题活跃用户定位方法流程图;
图2是本发明实施例提供的基于所述话题向量集得到所述分组数据集中的热点数据网络集合的方法流程图;
图3是本发明实施例提供的权重有向图的构建方法流程图;
图4是本发明实施例提供的量化诚恳度权重的方法流程图;
图5是本发明实施例提供的量化支持度权重的方法流程图;
图6是本发明实施例提供的热门话题活跃用户的选取方法流程图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
本发明实施例提供一种热门话题活跃用户定位方法。所述方法如图1所示,包括:
s101.获取数据集合,所述数据集合包括一类数据和二类数据。
所述数据包括一类数据和二类数据,所述一类数据为直接发布的数据,所述二类数据为针对一类数据的评论数据。
s102.按照一类数据的发布时间进行数据分组,得到分组数据集,所述分组数据集中包括一类数据和与所述一类数据相关的二类数据。
具体地,数据分组的时间维度可以根据具体需求进行设置,比如同一天、同一个星期、同一个月等等。
s103.对每个分组数据集进行预处理,得到所述分组数据集对应的数据网络集合。
所述数据网络集合以有向图di={v,e}的形式记录,其中v为顶点,对应用户标识,e为有向边,代表一个用户标识发布的二类数据对另一个用户标识发布的一类数据的评论关系,每个顶点均包括用户标识、标题和内容三部分数据。
举例而言,若用户spark发布了一个一类数据,用户tony,samby和dazzi对其进行了评论,则得到了包括四个顶点,三条有向边的数据网络,有向边为从tony指向spark,samby指向spark和dazzi指向spark的三条边。有向边的方向由发布二类数据的用户指向所述二类数据对应的一类数据的用户。
具体地,数据网络中可以包括多个发布一类数据的用户和多个发布二类数据的用户,而发布一类数据的用户也可以同时作为发布二类数据的用户,本发明实施例并不限定数据网络的具体生成方法。
s104.对于每个分组数据集,计算其对应的话题向量集。
具体地,所述话题向量集可以被标识为{topi}i,c其中topici={(ti1,pi1)......(tin,pin)},其中为tij话题topici中可能出现的关键词,pij为所述关键词在该话题中出现的概率。事实上数据网络中的各个顶点的标题和内容都可以看做是一系列关键词的概率分布,因此,通过对于各个顶点的标题进行分析结合先验知识即可得到与顶点相关的话题,由此得到数据网络对应的话题向量集,对于每个分组数据集中的各个数据网络对应的话题向量集取并集,得到每个分组数据集对应的话题向量集。而对于得到话题向量集的具体方法本发明实施例并不做出具体限定,可以参考现有技术。
s105.基于所述话题向量集得到所述分组数据集中的热点数据网络集合。
具体地,热点数据网络集合对应了在某个时间段内的热门话题,热点数据网络集合的获取是研究热门话题的合理数据源,基于这一数据源可以进行数据分析、话题热度分析、与话题相关的行业热度分析,相关广告目标群体的定位等多种后续操作,因此,热点数据网络集合的获取具备较大的实际价值。
s106.获取各个所述热点数据网络中对应的权重有向图。
s107.对所述权重有向图进行分析,选取对应所述权重有向图的热门话题活跃用户。
进一步地,如图2所示,所述基于所述话题向量集得到所述分组数据集中的热点数据网络集合包括:
s1051.获取每个数据网络的热度属性。
具体地,所述热度属性可以根据实际情况进行获取,比如,本发明实施例中使用的热度属性为数据网络顶点数重要度、数据网络参与重要度和数据网络的阅读重要度。
具体地,所述数据网络顶点重要度为所述数据网络顶点的个数与所述数据网络所在分组数据集对应的时间段内的活跃用户总数的比值。所述活跃用户可以根据用户上线浏览数据的次数定义。
所述数据网络参与重要度为所述数据网络顶点个数与所述数据网络中各个数据被浏览的总数的比值。
所述数据网络的阅读重要度为所述数据网络中各个数据被浏览的总数与所述数据网络所在分组数据集对应的时间段内的活跃用户总数的比值。
s1052.根据所述热度属性提取疑似热点数据网络。
具体地,只有当数据网络顶点数重要度大于预设第一阈值,并且数据网络参与重要度大于预设第二阈值和数据网络的阅读重要度大于预设第三阈值的数据网络,才是疑似热点数据网络。
具体地,本发明实施例中第一阈值为0.1,第二阈值为0.15,第三阈值为0.3。
s1053.获取疑似热点数据网络的相关度矩阵。
具体地,某个顶点与某个话题向量的相关度的获取方法包括:
基于公式
进一步地,在得到某个顶点与某个话题向量的相关度的基础上,可以得到该顶点所述话题向量集中各个话题的相关度,从而得到顶点相关度向量,所述相关度向量表示所述顶点与各个话题的相关度。
以某个顶点的顶点相关度向量为列,得到疑似热点数据网络对应的相关度矩阵。
s1054.获取所述相关度矩阵中数值大于预设相关度阈值的元素。
s1055.若所述元素总数大于预设的热度阈值,则所述疑似热点数据网络被判定为热点数据网络,从而得到热点数据网络集合。
进一步地,所述权重有向图的构建方法如图3所示,包括:
s1061.获取热点数据网络每条边的诚恳度权重和支持度权重。
具体地,本发明实施例中从诚恳度和支持度两个方面评价每条边的权重。诚恳度通过每条边起点用户对终点用户的回复的字数来衡量,本发明实施例认为回复的字数越多,表示起点用户的回答越具有诚意。支持度通过每条边起点用户对终点用户的回复的内容的情感分析结果来衡量,若起点用户的回复的内容具备较多的正面色彩,则支持度较高,反之,支持度角度。
s1062.根据所述诚恳度权重和所述支持度权重计算所述边的综合权重。
具体地,所述综合权重=α诚恳度权重+β支持度权重。α和β为调节参数,可以根据实际情况进行调节,但是其总和值为1。
具体地,本发明实施例进一步提供了量化诚恳度权重的方法,如图4所示,包括:
s1.构建诚恳度量化表,所述诚恳度量化表包括字数区间和所述字数区间对应的诚恳度权重。
比如,字数在1-50,则诚恳度权重为0.2,若字数在50-100,则诚恳度权重为0.5,若字数大于100,则诚恳度权重为1.
s2.得到每条边中起点用户对终点用户的回复的字数。
s3.根据所述诚恳度量化表查询所述字数所在的字数区间,并得到其对应的诚恳度权重。
具体地,本发明实施例进一步提供了量化支持度权重的方法,如图5所示,包括:
s10.根据预设的感情词语表提取每条边中起点用户对终点用户的回复中的目标感情词语。
具体地,所述感情词语表可以预先根据大数据统计结果进行设置,所述感情词语表记录了感情词语以及感情词语对应的权重,所述感情词语包括肯定词语、否定词语和中立词语,其中中立词语的权重为0.5,肯定词语的权重小于0.5,否定词语的权重大于0.5。
比如否定词语“白痴”对应权重0.9,否定词语“小傻瓜”对应权重0.6。权重越重,则否定词语的否定语气越激烈。比如肯定词语“绝对正确”对应权重0.4,肯定词语“应该对”对应权重0.3。权重越重,则肯定词语的肯定语气越激烈。
s20.获取目标感情词语对应的权重。
s30.取全部目标感情词语对应的权重的总和值作为支持度权重。
进一步地,本发明实施例里提供了热门话题活跃用户的选取方法,如图6所示,包括:
s1071.简化权重有向图得到目标有向图。
若起点用户对终点用户进行了多次回复,则在有向图g中会产生起点用户指向终点用户的多条有向线段,为了便于后期热门话题活跃用户的筛选,先对权重有向图进行简化,使得起点用户与终点用户之间的多条有向线段合并为一条有向线段,所述合并后的有向线段的综合权重为合并前的多条有向线段的权重的总和值。
s1072.初始化目标有向图中各个顶点的热度值。
本发明实施例中初始的热度值均为1.
s1073.任意选择一个顶点,根据所述顶点和指向所述顶点的各个相关顶点的当前热度计算所述顶点的迭代后热度,并将所述迭代后热度作为所述顶点的当前热度。
具体地,迭代后热度热度值根据公式
在一个可行的实施方式中
s1074.按照步骤s1073的方法继续计算其它顶点的当前热度,直至所述目标有向图中各个顶点的当前热度趋于稳定。
具体地,各个顶点计算迭代后热度的先后顺序可以根据实际情况有所不同,本发明实施例并不对其进行明确限定。趋于稳定即为迭代前后的当前热度值的差值小于预设阈值。
s1075.选取当前热度最大的n个用户作为热门话题活跃用户。
应当理解的是,在本文中提及的“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!