基于上下文向量图核的生物医学实体关系分类方法与流程
本发明涉及生物医学文本挖掘和数据挖掘技术领域,尤其是基于上下文向量图核的生物医学实体关系分类方法。
背景技术:
生物医学实体间关系抽取是生物医学领域最基本最核心的任务。它不仅有助于构建生物医学相关数据库,而且对知识图谱的构建来说,也是最基本最关键的环节之一。海量的生物医学文献中蕴含着丰富的以及前沿的生物医学知识,是生物医学领域相关研究者重要的知识宝库,实践表明,应用文本挖掘技术可以从这座知识宝库中自动高效的提取有用的知识,但现存方法的性能和应用还存在着诸多不足。
由于很多生物医学领域实体关系分类都是新兴的关系提取任务,只在句子上进行了相关标注,而且标注语料相对较少,不像通用领域存在大量人工标注过的数据。传统的机器学习方法如svm等对数据规模要求不高,并且分类速度快,尤其图核在基于svm的关系提取任务里显示了极大的优势性。因此,在规模有限的生物医学语料上往往更具优越的性能。针对科学文献中长文本上关系提取性能低下问题,本方法从句子的图表示出发,以充分利用上下文信息为目的,提出了基于上下文向量图核的方法,用于生物医学实体关系分类。
技术实现要素:
本发明的目的是提供基于上下文向量图核的生物医学实体关系分类方法,基于句子文本和句子的依存解析,自动学习医学文本中蕴含的实体间关系特征,从而对生物医学文献中已标注生物医学实体间关系进行更为准确且有效地分类。
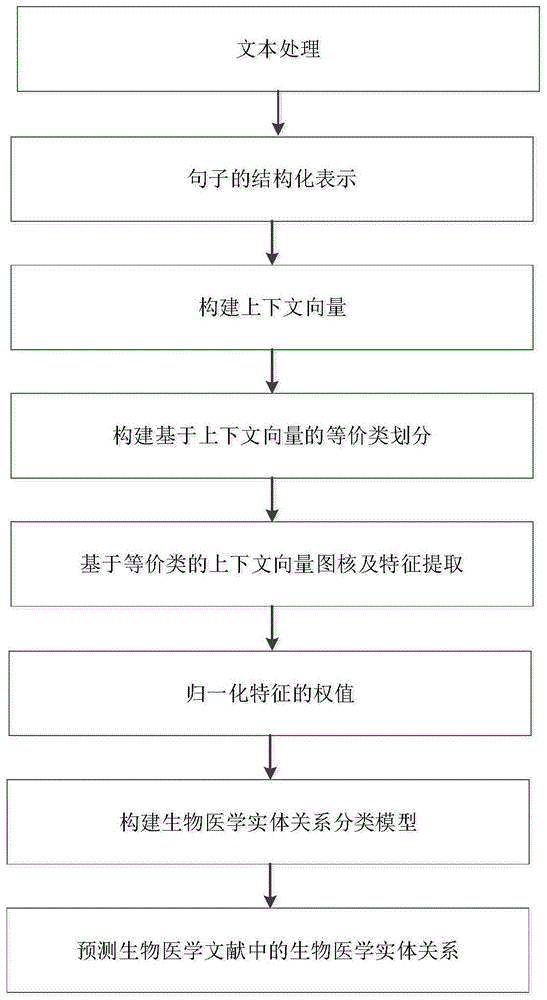
本发明解决现有技术问题所采用的技术方案:基于上下文向量图核的生物医学实体关系分类方法,包括以下步骤:
s1、对生物医学文献进行文本处理:利用文本处理技术对句子进行基本文本处理,其处理方法为:
a1、过滤带有一个生物医学实体或两个实体具有同样符号表示的句子;
a2、为了减少特征空间的稀疏性,用特殊符号“zhnum”代替不是生物医学实体子串的数字串;
a3、为了突出句子中实体周围的句法和依存关系,对包括共享前缀或者后缀的由多个单词组成的实体,用“#”连接它们形成一个不带空格的字符串代替相应的实体出现;
a4、所有的生物医学实体用bioenti*代替,*表示0,1,2,其中bioenti1和bioenti2表示欲分析关系的实体,bioenti0表示其它生物医学实体;
a5、利用斯坦福依存解析器stanfordparser在预处理后的句子上进行依存解析,从而得到了句子的依存解析结果,即获得了句子中符号的文本、pos标记以及符号间的依存关系;
s2、句子的结构化表示:对于每一包含候选生物医学实体对的句子实例,可以表示成一个有向的结点带标签的带权图,如图2所示,其中包括依存子图和线性子图两个子图;对于依存分析结果中的每一个符号和依存关系,分别创建对应的结点和相关联的标签集;在依存子图中,每个符号结点用单词的文本和词性pos作为标签,每个依存结点用依存类型作标签;例如,标签“effects/nns”表示符号结点的文本是“effects”,词性是“nns”,标签“amod”表示符号结点“additive”和“effects”间的依存类型;此外,候选实体间最短路径上的点和边相较于图中其他点和边更能体现实体间的语义关系,于是,利用迪杰斯特拉(dijkstra)算法求出候选实体间的最短依存路径,在图中最短路径上的点和边用黑体表示,而且,最短依存路径上所有点的词性pos标签或者依存类型被特殊标记上前缀“sp_”;在线性子图中,对于句中的每个符号创建了带有标签的第二个结点;结点标签除了包括符号的文本text和词性pos标记,每个单词特殊地用位置前缀“b_”、“m_”或者“a_”标记,表示其出现在两个候选实体的前中后的哪一个位置;此外,为了显示不同类型边对于候选实体间关系的重要程度,每条边可以被赋予不同的权值;最后,一个符号字典保存了图中的所有标签;
s3、构建上下文向量:根据句子的图表示构建上下文向量,其处理方法如下:
对于顶点带标签的图g=(v,ε,l),v表示顶点的有限集,
定义1上下文向量:给定一个点vx∈v和它的邻接点adj(vx)={vadj_1,vadj_2,k,vadj_m},在对点vx的邻接点标签第i次迭代后,它的标签可以用一个有序的向量lvi(vx)表示,如公式(1)所示:
上式中l(vx)表示点vx的标签;当i=0时,lv0(vx)的元素由点vx自身标签里的元素组成;然后,当i=1时,公式(1)被用来迭代的计算lvi(vx),它的元素由vx的所有邻接点的上下文向量lvi-1(vadj_k)里的元素组成,其中vadj_k∈adj(vx)表示vx的第k个邻接点,m是vx邻接点的个数;lvi(vx)里的所有元素按字典序排序;图3显示了在顶点带标签的图中上下文向量计算的一个例子,其中图3(a)是图2的一部分;为了随后计算过程描述的方便,图3(b)中的别名将代替每个顶点的标签;每个顶点上下文向量的计算显示在图3(c)中;最后,计算出的每个上下文向量将加到特征字典里;以顶点d为例,它的标签“drug2/nns”用别名l3代替,开始时即i=0时它的上下文向量为lv0(d)=[l3];第一次迭代时,它的上下文向量lv1(d)由它所有的邻接点(b,h)的第0次上下文向量(lv0(b),lv0(h))组成,即lv1(d)=[l4,l6];按照同样的方式可以完成依存子图和线性子图上其他点的迭代;
点的上下文向量lvi(vx)是它所有邻域顶点的迭代序列,它不仅隐含了顶点周围的拓扑结构信息并且传递了非邻接点信息;就上下文向量在两个子图中的含义来看,它体现的是依存子图中的功能子团或结构子团,线性子图中一个单词前后的符号对;通过迭代地应用公式(1),点vx(vx∈v)的标签形成了一个向量序列lv(vx)=[lv0(vx)),lv1(vx),lv2(vx),k];由此,一个点被细分成多个向量,从而使每个点的上下文信息得以充分利用;
s4、构建基于上下文向量的等价类:对于步骤s3中得到的每一轮迭代上下文向量,进行等价类的划分;
定义2基于上下文向量的等价类划分:如果v是顶点带标签图中所有点的集合,“有同样的上下文向量”是v上的一个等价关系~。元素
其中,x表示图中与元素
lh(gh)={lvh(v1),lvh(v2),k,lvh(vi),k,lvh(vn)}vi∈v(3)
由于迭代的进行,向量表示由近及远地精确地捕获了点周围直接和间接的上下文信息;从而,一个图形成了层次图序列g=(g0,g1,...)。迭代过程可以由两个条件中断:一个条件是当gh的组数等于gh-1的组数时,向量的迭代结束;另一种情况是可以设置迭代次数的上限h*;
s5、基于等价类的上下文向量图核及特征提取:图核即基于建立在顶点带标签图上的核函数计算两个图的相似性进而实现分类的目的;本发明中,两个图g和g'的相似度依赖于所有层中上下文向量对间任意长度的带权路径之和;本部分包括上下文向量对特征提取以及上下文向量图核的定义,其处理如下:
b1、上下文向量对特征提取:划分出等价类后,在同一层gh里的任意两个向量lvh(vi)和lvh(vj)的并集如果非空的话,就形成上下文向量对vph(vi,vj),其权值为gh层中上下文向量对间任意长度的带权路径之和;例如,在图3(c)里,g0层的两个向量lv0(a)和lv0(d)组成了上下文向量对vp0(a,d)=[l1,l3];从图3(a)里可以看出,向量对vp0(a,d)中a和d的路径长度为2时,带权路径长度之和为1.8;向量对vp0(a,d)对应的a和d两点间的所有长度的带权路径之和是3.0,其路径分别为a-b-d和a-f-g-h-d;
对于图g,第h次迭代后产生的图为gh,其任意向量对间所有长度的带权路径长度之和可通过公式
其中,h表示迭代次数,h*表示迭代次数的上限,用来调整窗口大小。此外,公式中的e'为图g'的邻接矩阵,l'h为g'h的所有上下文向量形成的标签分配矩阵,
s6、归一化特征的权值:对于每一对候选生物医学实体实例,利用步骤s5中方法获得的所有上下文向量对和权值,所述的上下文向量对称为特征,其权值利用公式
s7、构建生物医学实体关系分类模型:使用最小平方支持向量机中的svm程序进行有监督学习建模,建模过程中核函数采用步骤s5中自定义的上下文向量图核函数,同时设置惩罚参数c为1.5;
s8、预测生物医学文献中的生物医学实体关系:利用步骤s1中的方法对待预测语料中的句子文本进行基本处理和依存解析,步骤s2中的方法获得句子的图表示;然后利用步骤s3中的方法获得结点的上下文向量表示,进而利用步骤s4中的方法对上下文向量划分等价类;利用步骤s5中的方法得到上下文向量对的权值,然后利用步骤s6中的方法对特征权值进行归一化处理;通过步骤s7构建分类模型,从而对生物医学实体关系类型进行分类。
本发明的有益效果在于:对于长复杂句上生物医学实体关系检测和分类,提出了有足够表达力的上下文向量图核。提出的方法聚焦在不同种类型上下文的有效使用,不同距离单词符号间的关系的有效提取。利用句子的图表示构建了近距离和远距离单词间的关系。迭代地从带标签的邻域顶点计算而来的上下文向量,获得了句中符号丰富而有表达力的周围特征。每个符号根据子图类型、邻域、不同大小的窗口、边权表示成了多个向量,细化了符号的上下文特征表示。基于相同上下文向量的等价类的划分最小化了一个图的表示。进一步,利用同一层中不同距离的上下文信息来体现结点间的连接强度。本方法没有多核和外部资源使用,有助于改善从包含长复杂句的科学文献中进行关系提取系统的性能,并且具有高精度特性。此外,基于svm的特性,本方法也适用于要求响应速度或者语料规模相对较小的关系提取系统。对于实施例ddiextraction2013挑战提出的的三个药物药物交互(ddi)语料,相对于其上现有的先进系统,本发明在主要评价指标f-score上有明显的提高,验证了本发明方法对生物医学文献中生物医学实体关系分类的有效性。
附图说明
图1为本发明关系分类方法的流程示意图;
图2为本发明中候选实体对所在句子的图表示,(a)依存子图,(b)线性子图。
图3为本发明中上下文向量的计算过程,(a)图例g,(b)标签对应的别名,(c)上下文向量的计算和等价类划分。
具体实施方式
以下结合附图及具体实施方式对本发明进行说明:
实施例:
根据上述针对于本发明所涉及方法和系统具体实施方式的描述,结合具体实施例进行说明。
本实施例使用ddiextraction2013挑战赛中的两个数据集,即medline以及all-2013,all-2013是medline和drugbank两个数据集的并集。这两个数据集又分为训练集和测试集。medline来源于medline数据库中生物医学摘要中的文本,其训练集和测试集分别包含1787和496个关系实例。medline数据集不仅具有更少的样本数,而且复合的长复杂句居多。all-2013的训练集和测试集分别包含27792和5761个关系实例。drugbank中的句子来源于生物医学数据库drugbank中的文本。基于上下文向量图核的生物医学实体关系分类方法具体步骤如下:
1、对生物医学文献进行文本处理:利用文本处理技术对句子进行基本文本处理,过滤带有一个生物医学实体或两个实体具有同样符号表示的句子。用特殊符号“zhnum”代替不是生物医学实体子串的数字串。对共享前缀或者后缀的由多个单词组成的实体,用“#”连接它们形成一个不带空格的字符串代替相应的实体出现。所有的生物医学实体用bioenti*代替,*表示0,1,2。利用斯坦福依存解析器stanfordparser在预处理后的句子上进行依存解析,从而得到了句子的依存解析结果,获得了句子的文本、pos标记以及符号间的依存关系。
2、句子的结构化表示:对于每一包含候选生物医学实体对的句子实例,构建有向的结点带标签的带权图,其中包括依存子图和线性子图两个子图;对于两个子图中的结点按步骤s2附加上标签;利用迪杰斯特拉(dijkstra)算法求出候选实体间的最短依存路径,并且在最短依存路径上所有点的词性pos标签或者依存类型被特殊标记上前缀“sp_”;在线性子图中,每个单词特殊地用位置前缀“b_”、“m_”或者“a_”标记,表示其出现在两个候选实体的前中后的哪一个位置;此外,每条边被赋予不同的权值;在依存子图中,最短依存路径上的边赋权值为0.9,其他边赋权值为0.3;在线性子图中,bioenti1前的三个单词和bioenti2后的三个单词间所有边赋权值为0.9,其他边赋权值为0.3。
3、构建上下文向量和对上下文向量进行等价类划分:根据步骤s3的方法对句子图中的结点构建上下文向量;根据步骤s4的方法对获得的每一层上下文向量进行等价类划分,其结束条件是迭代次数h*=2。
4、基于等价类的上下文向量图核及特征提取:划分出等价类后,对同一层gh里的任意两个向量形成上下文向量对vph(vi,vj),按步骤s5中的方法计算其权值。其中公式5中的衰退因子βh设置方式如下:为了简化参数的选择过程,设置一个初始的值β,然后分配β的h次幂给βh。在每个数据集上按步长0.1递增方式在[0.1,0.9]区间内选择β。当h*=2时,在ml-2013及all-2013三个数据集上其值分别为0.3和0.4。
5、归一化特征的权值:对于每一对候选生物医学实体实例,利用步骤s5中方法获得的所有上下文向量对和权值,其权值利用公式
6、构建生物医学实体关系分类模型:使用最小平方支持向量机svm对所存特征文件进行有监督学习建模从而得到模型文件;svm的核函数选择步骤s5中自定义的上下文向量图核函数,设置惩罚参数c为1.5;
7、预测生物医学文献中的生物医学实体关系:利用步骤s1中的方法对待预测语料中的句子文本进行基本处理和依存解析,步骤s2中的方法获得句子的图表示;然后利用步骤s3中的方法获得结点的上下文向量表示,进而利用步骤s4中的方法对上下文向量划分等价类;利用步骤s5中的方法得到上下文向量对的权值,然后利用步骤s6中的方法对特征权值进行归一化处理,得到待预测语料的特征文件;把特征文件及步骤s7中得到的模型文件同时传给最小平方支持向量机svm程序,模型会输出每对候选实例在各个类别上的概率值,其中概率值最大的那一类即为候选实例对应的类别标签,从而得到生物医学实体关系类型。
为了验证方法的有效性,实验选择了两类五种对比方法:
(1)基于svm的方法:biosem[1]把跨越一个以上子句的ddi对划分为多个子句,然后设计了大量的特征。fbk-irst[2]使用了三个核的混合系统,是ddi测评的第一名。系统raihani[3]除了使用了biosem系统的思想,还设计了很多的规则和特征,如chunk,触发词,否定句过滤和same_blok等等。
(2)基于神经网络:mccnn[4]使用了多通道词嵌入向量,是ddiextraction2013语料上基于网络架构方法中现有最好的cnn方法之一。
表1给出了包括本发明方法和4个对比方法在内的5种方法在前文所述ddi实验语料测试集上关系分类的f-score评价指标测试结果。f-score是文本领域关系提取经常采用的标准的评价指标,它的定义如下:
其中p表示精度,r表示召回率,tp(truepositives,真正正例)代表分类器预测为正例实例中实际也为正例的个数,fp(falsepositives,虚假正例)代表分类器预测为正例实例中实际为负例的个数,fn(falsenegatives,虚假负例)代表分类器预测为负例的实例中实际为正例的个数。精度p和召回率r分别考虑了算法的查准性和查全性。但这两个指标不能较全面地体现一个分类系统的性能,因此,通常用在精度p和召回率r间起到一个平衡作用的f-score(f)值来评价一个算法的整体性能。
表1不同系统在三个数据集上的f性能比较
除本发明的方法外,表中各比较组的具体实施方法,请参见如下文献记载:
[1]buiq-c,slootpm,vanmulligenem,etal.anovelfeature-basedapproachtoextractdrug–druginteractionsfrombiomedicaltext[j].bioinformatics,2014,btu557.
[2]chowdhurymfm,lavellia.fbk-irst:amulti-phasekernelbasedapproachfordrug-druginteractiondetectionandclassificationthatexploitslinguisticinformation[c].secondjointconferenceonlexicalandcomputationalsemantics(*sem),volume2:proceedingsoftheseventhinternationalworkshoponsemanticevaluation(semeval2013),2013,2:351-355.
[3]raihania,laachfoubin.extractingdrug-druginteractionsfrombiomedicaltextusingafeature-basedkernelapproach[j].journaloftheoreticalandappliedinformationtechnology,2016,92(1):109.
[4]quanc,hual,sunx,etal.multichannelconvolutionalneuralnetworkforbiologicalrelationextraction[j].biomedresearchinternational,2016,2016(2-1):1-10.
从表1所列的实验结果可以看出本发明所提出的方法在medline和all-2013两个实验数据集上获得了好的综合性能,其主要评价指标f-score相对于其他方法有明显提高,本发明方法验证了对包含长复杂句的生物医学文献中生物医学实体关系分类的有效性。本发明方法虽然使没有多核和外部资源使用,同样有助于改善从包含长复杂句的科学文献中进行关系提取系统的性能,并且具有高精度特性。此外,基于svm的特性,本方法也适用于要求响应速度或者语料规模相对较小的关系提取系统。
以上内容是结合具体的优选技术方案对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!