媒体信息推荐方法、装置、存储介质和计算机设备与流程
本申请涉及互联网技术领域,特别是涉及一种媒体信息推荐方法、装置、存储介质和计算机设备。
背景技术:
随着互联网的高速发展,用户可以很方便地通过网络享受各种在线电子服务,例如在网上查看体育、科技或娱乐等方面的媒体信息。由于信息化的迅猛发展,信息量呈指数型增长,用户不得不从海量信息中查找自己所需要的信息,这将耗费用户大量的时间成本。
为了使用户可以在海量信息中快速查找到所需要的信息,在传统的信息推荐方案中通常是通过采集用户历史行为数据,然后对采集的数据进行分析得到用户所需要的信息,然后向用户推荐,用户便可快速地获得目标信息。然而,当数据分布复杂时,传统的信息推荐方案对数据的拟合差,使得无法准确地预测出用户所需的信息,从而导致信息推荐的准确性较差。
技术实现要素:
基于此,有必要针对无法准确地预测出用户所需的信息而导致信息推荐准确性差的技术问题,提供一种媒体信息推荐方法、装置、存储介质和计算机设备。
一种媒体信息推送方法,包括:
获取目标用户数据和候选媒体信息;
分别从所述目标用户数据和所述候选媒体信息提取用户特征和媒体特征;
通过机器学习模型对所提取的用户特征和媒体特征进行特征交叉处理,获得用于表示所述用户特征与所述媒体特征相关性的多阶交叉特征;
根据所述多阶交叉特征确定所述候选媒体信息的推荐系数;
从所述候选媒体信息中按照所述推荐系数选取媒体信息进行推送。
一种媒体信息推送装置,所述装置包括:
数据获取模块,用于获取目标用户数据和候选媒体信息;
特征提取模块,用于分别从所述目标用户数据和所述候选媒体信息提取用户特征和媒体特征;
特征交叉处理模块,用于通过机器学习模型对所提取的用户特征和媒体特征进行特征交叉处理,获得用于表示所述用户特征与所述媒体特征相关性的多阶交叉特征;
推荐系数确定模块,用于根据所述多阶交叉特征确定所述候选媒体信息的推荐系数;
信息推送模块,用于从所述候选媒体信息中按照所述推荐系数选取媒体信息进行推送。
一种存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行上述媒体信息推荐方法的步骤。
一种计算机设备,包括处理器和存储器,所述存储器存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行上述媒体信息推荐方法的步骤。
上述媒体信息推荐方法、装置、存储介质和计算机设备,从目标用户数据和候选媒体信息中提取用户特征和媒体特征,通过机器学习模型对用户特征和媒体特征进行交叉处理,可以很好的对用户特征和媒体特征进行拟合,得到拟合了用户特征和媒体特征的多阶交叉特征。由于多阶交叉特征拟合了用户特征和媒体特征,根据该多阶交叉特征来确定选媒体信息的推荐系数,所得的推荐系数准确性高,当从候选媒体信息中按照推荐系数选取媒体信息进行推送时,所推送的内容能够很好的满足用户需求,有效地提高了信息推荐的准确性。
附图说明
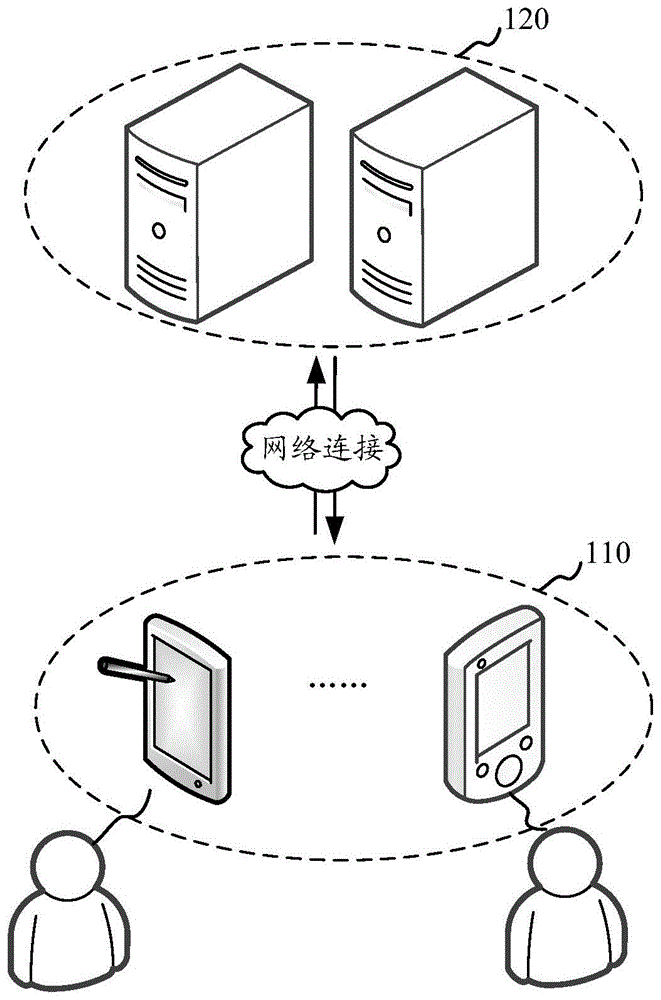
图1为一个实施例中媒体信息推送方法的应用环境图;
图2为一个实施例中媒体信息推送方法的流程示意图;
图3为一个实施例中媒体信息展示的界面示意图;
图4为一个实施例中获得二阶交叉特征和高阶交叉特征,并根据二阶交叉特征和高阶交叉特征得到多阶交叉特征步骤的流程示意图;
图5为一个实施例中因子分解机模型进行二阶特征交叉的示意图;
图6为一个实施例中深度学习模型进行高阶特征交叉的示意图;
图7为一个实施例中向用户端发送媒体信息,并在展示联系人已浏览的媒体信息是显示浏览提示符步骤的流程示意图;
图8为一个实施例中根据留存时长和媒体信息的所属领域确定候选媒体信息步骤的流程示意图;
图9为一个实施例中根据线性逻辑回归模型进行预测的流程示意图;
图10为一个实施例中媒体信息推送装置的结构框图;
图11为另一个实施例中媒体信息推送装置的结构框图;
图12为一个实施例中计算机设备的结构框图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
图1为一个实施例中媒体信息推送方法的应用环境图。参照图1,该媒体信息推送方法应用于媒体信息推送系统。该媒体信息推送系统包括终端110和服务器120。终端110和服务器120通过网络连接,其中,服务器120获取目标用户数据和候选媒体信息,分别从目标用户数据和候选媒体信息提取用户特征和媒体特征,通过机器学习模型对所提取的用户特征和媒体特征进行特征交叉处理,获得用于表示用户特征与媒体特征相关性的多阶交叉特征,根据多阶交叉特征确定候选媒体信息的推荐系数,从候选媒体信息中按照推荐系数选取媒体信息向终端110推送。终端110具体可以是台式终端或移动终端,移动终端具体可以手机、平板电脑、笔记本电脑等中的至少一种。服务器120可以用独立的服务器或者是多个服务器组成的服务器集群来实现。
如图2所示,在一个实施例中,提供了一种媒体信息推送方法。本实施例主要以该方法应用于上述图1中的服务器来举例说明。参照图2,该媒体信息推送方法具体包括如下步骤:
S202,获取目标用户数据和候选媒体信息。
其中,目标用户数据可以是目标用户的用户基本信息和行为数据。例如,基本信息可以包含有用户的年龄、性别、所在地理位置、学历和喜好等特征。行为数据可以是目标用户浏览历史媒体信息时所生成的媒体浏览记录,如用户的在社交客户端上浏览图像、视频和文章时所形成的媒体浏览记录,通过该浏览记录可以获得用户对某中类型的图文、视频和文章等的点击率、浏览时长和来源。对于文章的来源,如图3所示,标题为“第五届世界互联网大会取得圆满成功”的文章来源于新华社。媒体信息可以对应有多种领域,如体育、娱乐、美食、科技和建筑等,具体可以是文字、图像和视频及结合等资讯,如图3中所展示的内容,用户在社交客户端浏览时,这些媒体信息可以被选择出来推送给用户进行浏览。候选媒体信息是所有媒体信息中可能被推送给用户的媒体信息。
根据媒体信息推送的时机,数据获取的触发条件也可能不同,可以将S202 划分以下三种场景进行阐述:
场景1,用户在点击媒体信息浏览工具栏时进行数据的获取。
在一个实施例中,由于目标用户数据包括用户基本信息和媒体浏览记录, S202具体可以包括:当接收到社交客户端发送的携带有目标用户标识的浏览指令时,服务器在用户数据库中获取用户在注册社交账号时所提供的用户基本信息和媒体浏览记录;然后,从媒体库获取留存时长未超出时效阈值的媒体信息作为候选媒体信息。
其中,留存时长可以是媒体信息从产生到当前时间戳之间的时间段,留存时长越短表示媒体信息的时效性越高,留存时长越长表示媒体信息的时效性低。对于留存时长超过所设置的时效阈值时,表示该媒体信息推送的价值较低,可以不用向用户进行推荐。对于留存时长未超过所设置的时效阈值时,表示该媒体信息推送的价值较高,可以用向用户进行推荐。
例如,用户在网页或社交客户端注册社交账号时,会提供自己的基本信息进行注册和验证。当用户打开社交客户端上的媒体信息浏览页面时,社交客户端会生成一个携带目标用户标识的浏览指令发送给服务器,表示用户准备浏览媒体信息,指示服务器从媒体库中预测用户所喜爱的媒体信息推送过来以便用户进行浏览。服务器在接收到社交客户端发送的携带有目标用户标识的浏览指令时,从用户数据库中获取用户基本信息和历史的媒体浏览记录,以便根据用户基本信息和历史的媒体浏览记录结合媒体库中所保存的媒体信息来确定哪一些媒体信息是用户所喜爱的,然后进行推送。
场景2,用户启动社交客户端时进行数据的获取。
在一个实施例中,由于目标用户数据包括用户基本信息和媒体浏览记录, S202具体可以包括:当接收到社交客户端发出的启动指令时,服务器则从与社交客户端对应的用户数据库获取用户基本信息和媒体浏览记录;从媒体库获取留存时长未超出时效阈值的媒体信息作为候选媒体信息。
例如,用户在启动社交客户端时,表示用户可能有浏览媒体信息的需求,此时社交客户端会生成一个携带有目标用户标识的启动指令并向服务器进行发送。服务器在接收到社交客户端发送的启动指令时,从用户数据库中获取用户基本信息和历史的媒体浏览记录,以便根据用户基本信息和历史的媒体浏览记录结合媒体库中所存在的媒体信息来确定哪一些媒体信息是用户所喜爱的,然后进行推送。
场景3,终端的位置信息发生变化时进行数据的获取。
在一个实施例中,由于目标用户数据包括用户基本信息和媒体浏览记录, S202具体可以包括:当检测到与社交客户端对应终端的位置信息发生变化时,服务器则从与社交客户端对应的用户数据库获取用户基本信息和媒体浏览记录;从媒体库获取留存时长未超出时效阈值的媒体信息作为候选媒体信息。
例如,用户对地方特色的美食、手工艺品或建筑比较感兴趣,当用户从A 地区到达B地区时,服务器可以从用户数据库中获取历史的媒体浏览记录,以及获取与目标用户标识对应包含有B地区位置信息的用户基本信息,以便根据 B地区位置信息、媒体浏览记录结合媒体库中的候选媒体信息来选取B地区的用户所喜爱的媒体信息,如B地区的美食信息、手工艺品信息或建筑信息等。
在一个实施例中,服务器可以在与社交客户端对应的用户数据库中获取用户基本信息和历史的媒体浏览记录,或者也可以从第三方平台获取用户的媒体浏览记录。
S204,分别从目标用户数据和候选媒体信息提取用户特征和媒体特征。
在一个实施例中,S204具体可以包括:服务器从用户基本信息中提取用户基本特征;从媒体浏览记录中提取媒体点击率、媒体浏览时长和第一媒体来源信息中的至少一种;将用户基本特征,以及媒体点击率、媒体浏览时长和第一媒体来源信息中的至少一种组合成用户特征;在候选媒体信息的内容和/或第二媒体来源信息中提取媒体特征。
其中,媒体点击率可以是用户点击服务器推送给用户的不同类型媒体信息的点击概率。例如,服务器向用户推送了球类比赛、美食类、娱乐类和汽车类等资讯,若每种类型的资讯数量有5条,用户分别点击美食类和娱乐类中的2 条和3条资讯,那么,对于球类比赛的点击率为0,美食类的点击率为40%,娱乐类的点击率为60%,而汽车类的点击率为0。媒体来源信息可以是媒体信息原始产生的地方信息,如图3所示的标题为“第五届世界互联网大会取得圆满成功”的文章来源于新华社,这里的新华社即为媒体来源信息中的一部分。
在一个实施例中,服务器在获取到目标用户数据和候选媒体信息之后,对目标用户数据进行解析,得到用户基本信息和用户历史浏览媒体信息的媒体浏览信息。服务器按照预设的字段从用户基本信息中提取用户年龄、性别、所在地理位置、学历和喜好等用户基本特征;然后,按照预设的字段从媒体浏览记录中提取媒体点击率、媒体浏览时长和第一媒体来源信息中的至少一种。
在一个实施例中,服务器历史每次向社交客户端推送媒体信息时,可以按历史推送媒体信息的所属领域或目标关键字统计用户对所推荐媒体信息的点击率,并保存在对应的用户数据库。其中,所属领域可以是按照体育、美食(如各地特色小吃或美食)、娱乐(如影视歌等)和汽车等,实际应用过程中,也可以对所属领域进行细分,如体育可以细分为球类比赛、田径比赛、赛车比赛和游泳比赛,而球类比赛也可以分为篮球比赛、足球比赛和乒乓球比赛等。目标关键字可以是媒体信息中具有代表性的词或短语,如姚明、周杰伦或火锅等关键字。
S206,通过机器学习模型对所提取的用户特征和媒体特征进行特征交叉处理,获得用于表示用户特征与媒体特征相关性的多阶交叉特征。
其中,相关性可以是用户特征与媒体特征之间的关联关系。例如,若用户喜欢漫画,而候选媒体信息中正好有漫画,那么表示用户特征与对应的媒体特征之间存在较强的相关性。若用户只喜欢漫画,而候选媒体信息中却没有漫画,那么用户特征与媒体特征之间不具有相关性,或相关性弱。多阶交叉特征可以是1阶、2阶、3阶、…、n阶的交叉特征,这里的n为正整数。需要说明的是, 1阶交叉特征指的是未交叉的用户特征和媒体特征。
用户特征、媒体特征和多阶交叉特征可以用矩阵或向量表示,如用户特征向量、媒体特征向量和交叉特征向量。其中,交叉特征向量(或矩阵)中零的数量远大于非零的数量,可以表示用户特征与媒体特征之间的相关性较弱;交叉特征向量中非零的数量远大于零的数量,可以表示用户特征与媒体特征之间的相关性很强。
在一个实施例中,服务器将所提取的用户特征向量和媒体特征向量输入机器学习模型,通过机器学习模型中的隐藏层对用户特征向量和媒体特征向量进行内积处理,获得用于表示用户特征与媒体特征相关性的多阶交叉特征向量。
在一个实施例中,机器学习模型可以是包括有因子分解机模型和深度学习模型的深度因子分解模型。S206具体可以包括:服务器可以将用户特征向量和媒体特征向量输入因子分解机模型,通过因子分解机模型对用户特征向量和媒体特征向量进行二阶交叉处理,获得用于表示用户特征与媒体特征相关性的多个二阶交叉特征向量;通过深度学习模型对因子分解机模型所获得的二阶交叉特征向量之间进行交叉处理,获得用于表示用户特征与媒体特征相关性的高阶交叉特征向量;将高阶交叉特征向量和因子分解机模型所获得的二阶交叉特征向量进行组合得到多阶交叉特征向量,或者,将用户特征向量、媒体特征向量、高阶交叉特征向量和因子分解机模型所获得的二阶交叉特征向量进行组合得到多阶交叉特征向量。
在一个实施例中,服务器可以将用户特征向量和媒体特征向量输入因子分解机模型之前,可以对用户特征向量和媒体特征向量进行降维,用低维度的向量来表示用户特征向量和媒体特征向量,然后将低维度的用户特征向量和媒体特征向量输入因子分解机模型进行特征交叉处理,从而可以有效地降低计算量。
S208,根据多阶交叉特征确定候选媒体信息的推荐系数。
其中,推荐系数可以是对候选媒体信息的预测点击率。推荐系数越大表示在推荐时推荐顺序越靠前,即对应的媒体信息具有较大概率被推送到用户。推荐系数越小表示在推荐时推荐顺序越靠后,即对应的媒体信息被推送的的概率较低,可能在用户阅读完推荐概率较大的媒体信息之后才可能被推送到用户。
在一个实施例中,服务器通过预测函数根据多阶交叉特征确定候选媒体信息的推荐系数。其中,预测函数可以是sigmoid函数、Tanh函数、ReLu函数或 Softmax函数。例如,假设多阶交叉特征为y1+y2,则利用预测函数sigmoid来确定候选媒体信息的推荐系数
S210,从候选媒体信息中按照推荐系数选取媒体信息进行推送。
在一个实施例中,服务器按照推荐系数的大小对候选媒体信息进行排列,可以是降序排列或升序排列,若为降序排列,那么排列靠前的推荐系数大于排列靠后的推荐系数,在排列后的候选媒体信息中选取从第一位媒体信息进行选取,选取预设数量的媒体信息作为推荐的媒体信息向社交客户端进行推送。若为升序排列,则在排列后的候选媒体信息中从最后一位开始选取媒体信息,选取预设数量的媒体信息作为推荐的媒体信息向社交客户端进行推送。
在一个实施例中,对媒体信息进行降序排列,具体可以包括:服务器根据推荐系数的大小对候选媒体信息进行降序排列;在排列后的候选媒体信息中按照排列顺序选取待推荐的多个媒体信息;获取目标用户标识,将所选取的媒体信息按照目标用户标识进行推送,以便在社交客户端上显示所选取的媒体信息。
例如,如图3所示,用户在打开媒体信息浏览页面时,服务器将所选取出来的媒体信息推送到社交客户端,社交客户端在“全部”工具栏对应的媒体信息展示区展示所接收到的媒体信息,例如以标题的形式展示“第五届世界互联网大会取得圆满成功”这条媒体信息。此外,除了展示媒体信息,还会展示媒体信息的来源,如“第五届世界互联网大会取得圆满成功”这条媒体信息的来源为新华社,在这条媒体信息的下方展示“新华社”。
在一个实施例中,当用户浏览完所推送的媒体信息时,社交客户端根据输入操作生成用户更新当前所展示媒体信息的媒体信息更新指令。服务器接收社交客户端发送的媒体信息更新浏览指令,从排列后的候选媒体信息中从上一次选取媒体指令的截至位置开始选取未向该社交客户端推送的媒体信息,并向社交客户端进行推送。
在一个实施例中,候选媒体信息可以是经过初步排列的信息。服务器获取到目标用户信息和经过初步排列的候选媒体信息时,分别从目标用户数据和候选媒体信息中提取用户特征和媒体特征,通过机器学习模型对所提取的用户特征和媒体特征进行特征交叉处理,获得用于表示用户特征与媒体特征相关性的多阶交叉特征。服务器根据机器学习模型中的全连接层对多维的多阶交叉特征进行加权求和,然后得到低维(如一维)的输出特征,根据预测函数对输出特征进行处理得到推荐系数,然后按照推荐系数对经过初步排列的候选媒体信息进行进一步地排序,实现了候选媒体信息从粗排到精确排序的过程。服务器从精确排序后的候选媒体信息中按照排序序号选取用于向用户推送的媒体信息,从而可以有效地提高媒体信息推送的准确性。
上述实施例中,从目标用户数据和候选媒体信息中提取用户特征和媒体特征,通过机器学习模型对用户特征和媒体特征进行交叉处理,可以很好的对用户特征和媒体特征进行拟合,得到拟合了用户特征和媒体特征的多阶交叉特征。由于多阶交叉特征拟合了用户特征和媒体特征,根据该多阶交叉特征来确定选媒体信息的推荐系数,所得的推荐系数准确性高,当从候选媒体信息中按照推荐系数选取媒体信息进行推送时,所推送的内容能够很好的满足用户需求,有效地提高了信息推荐的准确性。
在一个实施例中,如图4所示,S206具体可以包括:
S402,通过因子分解机模型对用户特征中的用户子特征和媒体特征中的媒体子特征进行二阶交叉处理,获得用于表示用户子特征与媒体子特征相关性的多个二阶交叉特征。
其中,机器学习模型也可称为深度因子分解模型,集成了因子分解机模型和深度学习模型,通过因子分解机模型可以得到低阶特征(低阶特征可以包含有一阶特征和二阶交叉特征),通过深度学习模型可以得到高阶特征,根据这两部分特征共同进行预测。此外,深度因子分解模型中具有全连接层,当因子分解机模型和深度学习模型输出作为全连接层的输入,然后通过预测函数对全连接层的输出进行预测。
在一个实施例中,用户特征中可以包含有多个子特征,媒体特征中也可以包含有多个子特征。服务器将用户特征和媒体特征输入训练后所得的因子分解机模型中,通过因子分解机模型来对用户特征中的各用户子特征和媒体特征中的各媒体子特征进行交叉处理,经过交叉处理后便可得到多个可以表示用户子特征与媒体子特征之间相关性的二阶交叉特征。
在一个实施例中,服务器通过因子分解机模型对用户特征和媒体特征进行二阶交叉处理时,使用对应的权重对输入的用户特征和媒体特征分别进行加权处理,然后将加权后的用户特征、媒体特征与二阶交叉特征进行组合,得到包含有一阶特征和二阶交叉特征的低阶特征。
例如,假设用户特征中的用户子特征和媒体特征中的媒体子特征用向量xt(t 为大于或等于0的整数)表示,用户特征中包括有是否喜欢球类比赛、是否喜欢美食、是否喜欢娱乐和是否喜欢汽车等方面的媒体信息。对于用户是否喜欢球类比赛,还可以细分为是否喜欢篮球比赛、是否喜欢足球比赛和是否喜欢乒乓球比赛等赛事的媒体信息。假设用户是否喜欢球类比赛的这一用户子特征用向量xi表示,候选媒体信息中是否包含有球类比赛的媒体子特征用向量xm表示,则二阶交叉特征xixm。因此,用户对球类比赛的爱好与候选媒体信息中是否存在有球类比赛的媒体信息,通过这个二阶交叉特征可以建立两者之间的关联,以实现更加精准的推荐媒体信息。
在一个实施例中,S402具体可以包括:服务器通过因子分解机模型,对用户特征和媒体特征进行去稀疏处理得到稠密化的用户特征和媒体特征;对稠密化的用户特征中的用户子特征与稠密化的媒体特征中的媒体子特征之间进行二阶交叉处理。
在一个实施例中,服务器通过因子分解机模型,对用户特征和媒体特征进行去稀疏处理得到稠密化的用户特征和媒体特征,具体可以包括:通过因子分解机模型,将用户特征中的用户子特征分别映射到预设维度的用户特征向量;以及,将媒体特征中的媒体子特征分别映射到预设维度的媒体特征向量;预设维度小于用户特征的维度、且小于媒体特征的维度;对稠密化的用户特征中的用户子特征与稠密化的媒体特征中的媒体子特征之间进行二阶交叉处理包括:根据映射所得到的用户特征向量和媒体特征向量,对稠密化的用户特征中的用户子特征与稠密化的媒体特征中的媒体子特征之间进行二阶交叉处理。
例如,在社交客户端上的媒体信息推荐系统中所涉及的用户数据和媒体信息的维度通常很高,如媒体信息的维度可以包括媒体标题、媒体信息字数、内容中的各关键字(如影视歌、体育、科技和金融等领域的名人,以及各种关于美食、建筑和风景的词语等)等。用户数据和媒体信息内容的具体取值都是不一样的,因此不同的特征甚至同一个特征均对应很多维度的取值,维度通常在十亿以上,可以看出用户数据和媒体信息的特征表达是非常稀疏的。因此,可以通过因子分解机模型对从用户数据和媒体信息中提取的用户特征和媒体特征进行稠密表达。对于两个不同特征xixj之间的相关性,服务器可以使用一个固定的低维向量Vi作为特征xi的表示,因此通过计算<Vi,Vj>可以学习到用户特征和媒体特征之间的二阶交叉特征,因子分解机模型中关于二阶交叉特征的计算方式为:对该计算方式进行优化,优化后的计算方式如下所示:
其中,为按照权重wi对用户特征和媒体特征进行加权后所得的一阶特征,为二阶交叉特征的部分。
作为一个示例,如图5所示,因子分解机模型首先对稀疏的用户特征和媒体特征进行去稀疏化处理,得到稠密化的用户特征和媒体特征,然后将稠密话的用户特征和媒体特征输入因子分解机层进行二阶交叉处理,此外,因子分解机模型还会将原始的用户特征和媒体特征输入因子分解机层与交叉的特征进行相加,得到最终的二阶交叉特征。
S404,通过深度学习模型对因子分解机模型所获得的二阶交叉特征之间进行交叉处理,获得用于表示用户子特征与媒体子特征相关性的高阶交叉特征;高阶交叉特征的阶数大于二阶交叉特征的阶数。
其中,深度学习模型是可以学习低阶特征的组合来形成高阶特征的神经网络结构。在深度学习模型中具有多个网络层(即隐藏层)可以学习低阶特征之间的相关性,得到用于表示多个用户子特征与多个媒体子特征之间相关性的高阶交叉特征。例如,若用户子特征为喜欢体育比赛,媒体子特征有球类比赛、赛车比赛、田径比赛和游泳比赛等,那么可将一个用户子特征与多个媒体子特征进行交叉得到高阶交叉特征。
在一个实施例中,服务器将因子分解机模型所获得的二阶交叉特征输入深度学习模型,通过深度学习模型中的各网络层对输入的多个二阶交叉特征之间进行交叉处理,低层网络层将处理得到的交叉特征作为高层网络层的输入,由高层网络层继续进行交叉处理,通过各网络层进行交叉处理后得到表示多个用户子特征与多个媒体子特征相关性的高阶交叉特征。
例如,若用户子特征为喜欢体育比赛xm,媒体子特征有球类比赛xn、赛车比赛xs、田径比赛xt和游泳比赛xu等。在通过因子分解机模型的特征交叉处理得到用户子特征xm与xn、xs、xt和xu四个媒体子特征之间的二阶交叉特征,然后将所得到的二阶交叉特征通过深度学习模型的各网络层进行进一步地特征交叉,得到用户子特征xm与xn、xs、xt和xu四个媒体子特征之间的高阶交叉特征,如三阶交叉特征和三阶以上的交叉特征。
作为一个示例,如图6所示,因子分解机模型输出稠密的二阶交叉特征,然后将二阶交叉特征作为深度学习模型的输入,通过深度学习模型的隐藏层对二阶交叉特征进行进一步的特征交叉,得到高阶交叉特征。当隐藏层为一层网络层时可以得到三阶交叉特征,当隐藏层为多层网络层时可以得到三阶以上的交叉特征。
S406,将高阶交叉特征和因子分解机模型所获得的二阶交叉特征进行组合得到多阶交叉特征。
在一个实施例中,服务器获取与用户特征和媒体特征对应的权重,按照所获取的权重对用户特征和媒体特征进行加权处理。服务器将加权处理后的用户特征和媒体特征,以及深度学习模型所得的高阶交叉特征和因子分解机模型所获得的二阶交叉特征进行组合得到组合特征。服务器将组合特征作为机器学习模型中全连接层的输入,通过全连接层对输入的多维度的组合特征进行加权求和,得到一维的特征值。服务器将所得到一维的特征值作为预测函数的输入值,通过预测函数对所得到一维的特征值进行处理得到推荐系数。服务器根据推荐系数从候选媒体信息中选取用于向用户推送的媒体信息进行推送。
例如,将加权处理后的用户特征和媒体特征作为wide部分特征,假设该wide 部分特征为因子分解机模型所获得的二阶交叉特征为深度学习模型所获得的高阶交叉特征为y3=yDNN,将y1、 y2和y3进行组合作为全连接层的输入,通过全连接层对多维的y1、y2和y3组合特征进行加权求和,得到一维的特征值youtput,然后利用sigmoid函数对一维的特征值youtput进行处理,得到推荐系数
在一个实施例中,候选媒体信息可以是经过初步排列的信息。当从目标用户数据和经过初步排列的候选媒体信息中提取到用户特征和媒体特征时,服务器获取与用户特征和媒体特征对应的权重,按照所获取的权重对用户特征和媒体特征进行加权处理。服务器将加权处理后的用户特征和媒体特征,以及深度学习模型所得的高阶交叉特征和因子分解机模型所获得的二阶交叉特征进行组合得到组合特征。服务器将组合特征作为机器学习模型中全连接层的输入,通过全连接层对输入的多维度的组合特征进行加权求和,得到一维的特征值。服务器将所得到一维的特征值作为预测函数的输入值,通过预测函数对所得到一维的特征值进行处理,得到推荐系数。服务器根据推荐系数对经过初步排列的候选媒体信息进行进一步地排序,实现了候选媒体信息从粗排到精确排序的过程。服务器从精确排序后的候选媒体信息中按照排序序号选取用于向用户推送的媒体信息,从而可以有效地提高媒体信息推送的准确性。
上述实施例中,通过因子分解机模型对用户特征中和媒体特征进行二阶交叉处理,然后将因子分解机模型输出的二阶交叉特征作为深度学习模型的输入,通过深度学习模型对二阶交叉特征进行进一步地交叉出的,得到高阶交叉特征,从而可以避免因人工难以手动设计高阶特征的问题,从而即便是当数据特征分布复杂时,也可以很容易地对数据特征进行拟合,得到二阶甚至高于二阶的交叉特征,以便通过二阶以及更高阶的交叉特征来实现媒体信息的推荐,提高推荐的准确性。
在一个实施例中,如图7所示,S210具体可以包括:
S702,获取目标用户标识以及与目标用户标识对应的联系人标识。
其中,目标用户可以指正在打开社交客户端进行媒体信息阅读的用户,服务器在选取到媒体信息后向该目标用户进行推送。目标用户标识指的是目标用户的标识,如目标用户通过社交客户端注册的社交账号。而联系人指的是目标用户的好友。联系人标识指的是目标用户在社交客户端所添加的联系人的标识,如目标用户使用社交客户端所添加的联系人的账号。
在一个实施例中,服务器在接收到社交客户端发送携带有目标用户标识的媒体信息浏览指令,或接收到社交客户端发出携带有目标用户标识的启动指令时,从媒体信息浏览指令或启动指令提取目标用户标识,然后在与目标用户标识对应的联系人列表中获取联系人标识。或者,服务器在检测到与社交客户端对应终端的位置信息发生变化时,获取该终端所对应的目标用户标识,通过该目标用户标识来获取对应的保存至联系人列表中的联系人标识。
S704,从候选媒体信息中选取推荐系数达到推荐阈值的媒体信息。
其中,推荐系数可以是对候选媒体信息的预测点击率。推荐系数越大表示在推荐时推荐顺序越靠前,即对应的媒体信息具有大概率推送到用户。推荐系数越小表示在推荐时推荐顺序越靠后,即对应的媒体信息被推送到用户的概率较小,可能在用户阅读完推荐概率较大的媒体信息之后才可能被推送到用户。而推荐系数小于一定值时,表示对应的候选媒体信息不是用户所想看的媒体信息,即时推送给用户了可能也不会被点击浏览,那么该候选媒体信息将不会被选取出来向用户推送。
在一个实施例中,可以设置有多个推荐阈值,当用户在历史浏览媒体信息时,由于浏览的媒体信息较少使得媒体浏览记录较少,在使用样本集较小的媒体浏览记录结合用户基本信息和候选媒体信息预测用户所需求的媒体信息时,可以使用值较小的推荐阈值与推荐系数进行比较,从而避免了虽然用户历史未浏览某种类型的媒体信息,但却是用户想要看而服务器没有推荐给用户的尴尬。
在一个实施例中,S704具体可以包括:确定候选媒体信息中包含有向联系人标识历史推送、且标记为联系人已浏览的媒体信息;获取已浏览的媒体信息的浏览数量;按照浏览数量获取与已浏览的媒体信息对应的权值;根据权值对与已浏览的媒体信息对应的推荐系数进行加权处理,得到加权后的推荐系数。其中,权值为大于1的数。
例如,对于某一条媒体信息,目标用户的许多好友都看过,表示该媒体信息比较受人喜欢,目标用户可能也会喜欢这条媒体信息,那么可以对这条媒体信息所对应的推荐系数进行加权处理,使加权后的推荐系数比加权之前要大,以增大该媒体信息被推送给目标用户的概率。
S706,当所选取的媒体信息中包含有向联系人标识历史推送、且标记为联系人已浏览的媒体信息时,则根据目标用户标识推送所选取的媒体信息;推送的媒体信息用于在展示媒体信息时对应显示表示联系人已浏览的浏览提示符。
在一个实施例中,服务器在获取到联系人标识之后,获取向联系人标识推送的媒体信息,判断推送给联系人标识的媒体信息与或选取的媒体信息是否有相同的,若有相同的,则表示所选取的媒体信息中包含有向联系人标识历史推送、且标记为联系人已浏览的媒体信息;若没有相同的,则表示所选取的媒体信息中不包含向联系人标识历史推送、且标记为联系人已浏览的媒体信息。
在一个实施例中,当所选取的媒体信息中包含有向联系人标识历史推送、且标记为联系人已浏览的媒体信息时,则服务器生成浏览提示符展示指令,向目标用户标识对应的社交客户端推送所选取的媒体信息,并发送浏览提示符展示指令。社交客户端在接收到媒体信息和浏览提示符展示指令时,根据浏览提示符展示指令将媒体信息进行展示,并在联系人已浏览的媒体信息的展示位置下方显示表示联系人已浏览的浏览提示符。
上述实施例中,在推送媒体信息之前,判断推送的媒体信息中是否包含有联系人已浏览的媒体信息,若包含了,则在向目标用户标识所对应的社交客户端推送媒体信息时,指示社交客户端在展示联系人已浏览的媒体信息时展示忒硬的浏览提示标识,用于提示用户该媒体信息好友都在阅读,可以有效地提高媒体信息的点击率。此外,联系人已浏览的媒体信息表示许多好友都在阅读,目标用户可能也会有兴趣点击浏览,因此可以对联系人已浏览的媒体信息所对应的推荐系数进行加权处理,是该推荐系数增大,提高该媒体信息被推送的概率,从而提高媒体信息的点击率。
在一个实施例中,如图8所示,从媒体库获取留存时长未超出时效阈值的媒体信息作为候选媒体信息的步骤,具体可以包括:
S802,确定媒体库中各媒体信息的产生时间和所属领域。
其中,产生时间指的是媒体信息形成时候的时间点。例如,新闻媒体编辑人员在编辑完一篇体育新闻时,体育新闻的完成时间可以确定为产生时间;或者,新闻媒体编辑人员将该体育新闻上传到服务器,上传到服务器的时间可以确定为媒体信息的产生时间。
每个媒体信息都有对应的领域,可以对应一个或多个领域。在一个实施例中,服务器根据媒体库中的各媒体信息的关键字确定媒体信息的所属领域。或者,媒体数据库中除了保存有媒体信息之外,还可以保存有对应的所属领域,服务器从媒体库中获取媒体信息所对应的所属领域。
在一个实施例中,当确定用户为首次浏览媒体信息时,服务器可以向目标用户标识的社交客户端发送领域关注指令,用于在社交客户端上显示关于各媒体信息的领域,如体育、科技、娱乐、休闲、美食和汽车等领域,用户可以选择对应的领域进行关注。用户关注对应的领域表示对该领域比较感兴趣,推送这个领域的媒体信息用户点击浏览的概率较大。
S804,根据产生时间和当前时间戳确定相应媒体信息的留存时长。
其中,留存时长指的是媒体信息从形成到当前时刻的时间长度值。新闻资讯一般都具有时效性,在一定时间范围内具有时效,表示该媒体信息具有阅读意义;超出该时间范围可能不具有时效,表示该媒体信息失去了阅读的意义。留存时长可以表示媒体信息的时效性,留存时长越小则表示媒体信息越具有时效,具有较强的推送意义。留存时长越大则表示媒体信息时效越差,可能会失去新闻时效,不具有向用户推送的意义。
S806,获取目标用户标识,并根据目标用户标识确定对应的关注领域。
在一个实施例中,社交客户端在接收到输入的关注领域后,向服务器进行发送,以便服务器对接收的关注领域按照目标用户标识进行保存。
在一个实施例中,当社交客户端向服务器发送媒体信息浏览指令后,根据媒体信息浏览指令获取目标用户标识,并按照模板用户标识从保存关注领域的数据库中获取目标用户的关注领域。
S808,从媒体库中筛选留存时长未超出时效阈值、且所属领域属于关注领域的媒体信息作为候选媒体信息。
其中,留存时长未超出时效阈值可以表示对应的媒体信息具有新闻时效性。若留存时长超出时效阈值则表示对应的媒体信息不具有新闻时效性,此时将不选取留存时长超出时效阈值的媒体信息。
上述实施例中,从媒体库中筛选留存时长未超出时效阈值、且所属领域属于关注领域的媒体信息作为候选媒体信息,一方面可以确保所筛选的媒体信息具有新闻时效性,可以有效地刺激用户去点击浏览,提高媒体信息的浏览率;另一方面,可以确保所筛选的媒体信息属于用户所喜欢的领域,也可以进一步地提高媒体信息的浏览率。
作为一个示例,对于传统的信息推荐方案中,许多都采用线性逻辑回归模型进行信息预测与推荐,这种方法的特点在于传统的算法模型原理比较简单,通常使用随机梯度下降等方法可以得到效果不错的局部最优解,对输入特征只能做线性的加权求和运算,在应用场景较为简单地时候,使用简单特征也能有效的对样本数据进行刻画,从而得到有效的预测结果,使用该技术时预测流程图如图9所示:
S902,推荐系统获取数据样本。
S904,从数据样本中提取样本特征。
S906,利用排序模型进行预测。
S908,判断预测效果是否符合预期效果。
S910,若否,则重新设计特征,重新执行S904。
S912,若是,则模型上线。
传统的推荐算法模型虽然具有可解释性强、原理简单等优点,但是这种线性模型因不具备刻画高阶特征的能力,当数据分布复杂时,对数据特征的拟合很差,不能准确的根据特征进行预测。
此外,在模型预测效果较差时,由于模型本身的简单可解释性,并不具有自主学习有效特征的能力,因此只能基于工作人员在本领域的先验知识去重新刻画特征。而且,由于线性逻辑回归模型是线性模型,在引入特征之间的高阶信息时,只能通过工作人员对特征进行乘、除、取幂、分段等非线性手段进行处理来引入模型的非线性,对工作人员的要求较高;而且,相同模型应用在不同场景时,特征都需要在相应场景下重新进行设计,对软件开发和程序上线带来额外的工作量。
基于上述问题,本实施例中提出了一种媒体信息推送方法,该推送方法基于深度因子分解模型,该深度因子分解模型集成了深度学习模型和因子分解机模型,通过深度学习模型能够学习到特征的高阶交叉信息,同时通过因子分解机模型也能够提供足够的低阶特征供预测函数预测。
但是使用上述方法进行计算时不能有效的考虑到特征之间的相关性,而实际的应用场景中,在进行预测时用户特征与媒体特征(即资讯内容相关的特征) 之间存在很强的相关性,例如用户喜欢漫画,而媒体信息(即如漫画文章)正好是与漫画相关的内容,因此用户特征与媒体特征之间存在较强的相关性,若向用户推送漫画相关的媒体信息,将会是一次成功的推荐。
因此在因子分解机模型中,对不同特征xixj之间的关系做一种表示,通常使用固定长度的低维向量Vi作为特征xi的表示,因此通过计算<Vi,Vj>可以学习到用户特征和媒体特征之间的关系,因此可以根据因子分解机模型中的计算方式计算用户特征和媒体特征之间的关系得到二阶交叉特征,其中因子分解机模型中的计算方式为:对该计算方式进行优化,可得:
通过因子分解机模型可以得到用户特征与媒体特征之间的二阶交叉特征,可以通过深度学习模型与因子分解机模型结合的方式,来自动的提取高阶和低阶相结合的特征。
对于深度学习模型,可以对稀疏的用户特征和媒体特征做一个embedding 的嵌入表示,然后所得到的特征输入多层的深度学习模型中去学习高阶特征。
最后,深度因子分解机基于媒体信息推荐系统所使用的用户特征和候选媒体信息来预测出推荐系数,该推荐系数为:
在向用户推送对应的媒体信息时,可以按照推荐系数的大小对媒体信息进行排序,将排列靠前的媒体信息推送给用户,从而提高用户对内容的点击概率,优化用户阅读体验。
本实施例中提出的媒体信息推送方法可应用在媒体信息推荐系统的feeds流推荐场景下,能够有效地挖掘用户特征和媒体特征,并且基于深度因子分解模型自动地学习用户特征和媒体特征之间的相关性。能够有效地提高媒体信息推荐的准确性,并且降低工作人员在特征工程方面花费的时间成本。本方案在媒体信息推荐系统feeds流推荐场景下,可以有效从多方面改进现有方法的不足,上线后可以对媒体信息浏览页面上所曝光内容点击率提高4%,对人均停留时长提升0.9%,阅读时间超过3分钟的比例提高3%,阅读多样性提高8%。
图2、4、7-8为一个实施例中媒体信息推送方法的流程示意图。应该理解的是,虽然图2、4、7-8的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图2、4、7-8中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
如图10所示,在一个实施例中,提供了一种媒体信息推送装置,该媒体信息推送装置具体包括:数据获取模块1002、特征提取模块1004、特征交叉处理模块1006、推荐系数确定模块1008和信息推送模块1010;其中:
数据获取模块1002,用于获取目标用户数据和候选媒体信息;
特征提取模块1004,用于分别从目标用户数据和候选媒体信息提取用户特征和媒体特征;
特征交叉处理模块1006,用于通过机器学习模型对所提取的用户特征和媒体特征进行特征交叉处理,获得用于表示用户特征与媒体特征相关性的多阶交叉特征;
推荐系数确定模块1008,用于根据多阶交叉特征确定候选媒体信息的推荐系数;
信息推送模块1010,用于从候选媒体信息中按照推荐系数选取媒体信息进行推送。
在一个实施例中,目标用户数据包括用户基本信息和媒体浏览记录;特征提取模块1004还用于:从用户基本信息中提取用户基本特征;从媒体浏览记录中提取媒体点击率、媒体浏览时长和第一媒体来源信息中的至少一种;将用户基本特征,以及媒体点击率、媒体浏览时长和第一媒体来源信息中的至少一种组合成用户特征;在候选媒体信息的内容和/或第二媒体来源信息中提取媒体特征。
在一个实施例中,信息推送模块1010还用于:根据推荐系数的大小对候选媒体信息进行降序排列;在排列后的候选媒体信息中按照排列顺序选取待推荐的多个媒体信息;获取目标用户标识,将所选取的媒体信息按照目标用户标识进行推送。
上述实施例中,从目标用户数据和候选媒体信息中提取用户特征和媒体特征,通过机器学习模型对用户特征和媒体特征进行交叉处理,可以很好的对用户特征和媒体特征进行拟合,得到拟合了用户特征和媒体特征的多阶交叉特征。由于多阶交叉特征拟合了用户特征和媒体特征,根据该多阶交叉特征来确定选媒体信息的推荐系数,所得的推荐系数准确性高,当从候选媒体信息中按照推荐系数选取媒体信息进行推送时,所推送的内容能够很好的满足用户需求,有效地提高了信息推荐的准确性。
在一个实施例中,机器学习模型包括因子分解机模型和深度学习模型;特征交叉处理模块1006还用于:通过因子分解机模型对用户特征中的用户子特征和媒体特征中的媒体子特征进行二阶交叉处理,获得用于表示用户子特征与媒体子特征相关性的多个二阶交叉特征;通过深度学习模型对因子分解机模型所获得的二阶交叉特征之间进行交叉处理,获得用于表示用户子特征与媒体子特征相关性的高阶交叉特征;高阶交叉特征的阶数大于二阶交叉特征的阶数;将高阶交叉特征和因子分解机模型所获得的二阶交叉特征进行组合得到多阶交叉特征。
在一个实施例中,特征交叉处理模块1006还用于:通过因子分解机模型,对用户特征和媒体特征进行去稀疏处理得到稠密化的用户特征和媒体特征;对稠密化的用户特征中的用户子特征与稠密化的媒体特征中的媒体子特征之间进行二阶交叉处理。
在一个实施例中,特征交叉处理模块1006还用于:通过因子分解机模型,将用户特征中的用户子特征分别映射到预设维度的用户特征向量;以及,将媒体特征中的媒体子特征分别映射到预设维度的媒体特征向量;预设维度小于用户特征的维度、且小于媒体特征的维度;特征交叉处理模块1006还用于:根据映射所得到的用户特征向量和媒体特征向量,对稠密化的用户子特征与稠密化的媒体子特征之间进行二阶交叉处理。
在一个实施例中,特征交叉处理模块1006还用于:通过因子分解机模型,对用户特征和媒体特征进行去稀疏处理得到稠密化的用户特征和媒体特征;对稠密化的用户特征中的用户子特征与稠密化的媒体特征中的媒体子特征之间进行二阶交叉处理。
上述实施例中,通过因子分解机模型对用户特征中和媒体特征进行二阶交叉处理,然后将因子分解机模型输出的二阶交叉特征作为深度学习模型的输入,通过深度学习模型对二阶交叉特征进行进一步地交叉出的,得到高阶交叉特征,从而可以避免因人工难以手动设计高阶特征的问题,从而即便是当数据特征分布复杂时,也可以很容易地对数据特征进行拟合,得到二阶甚至高于二阶的交叉特征,以便通过二阶以及更高阶的交叉特征来实现媒体信息的推荐,提高推荐的准确性。
在一个实施例中,信息推送模块1010还用于:获取目标用户标识以及与目标用户标识对应的联系人标识;
从候选媒体信息中选取推荐系数达到推荐阈值的媒体信息;
当所选取的媒体信息中包含有向联系人标识历史推送、且标记为联系人已浏览的媒体信息时,则根据目标用户标识推送所选取的媒体信息;推送的媒体信息用于在展示媒体信息时对应显示表示联系人已浏览的浏览提示符。
在一个实施例中,如图11所示,该装置还可以包括:已浏览媒体信息确定模块1012、浏览数据获取模块1014、权值获取模块1016和加权处理模块1018;其中:
已浏览媒体信息确定模块1012,用于在从候选媒体信息中选取推荐系数达到推荐阈值的媒体信息之前,确定候选媒体信息中包含有向联系人标识历史推送、且标记为联系人已浏览的媒体信息;
浏览数据获取模块1014,用于获取已浏览的媒体信息的浏览数量;
权值获取模块1016,用于按照浏览数量获取与已浏览的媒体信息对应的权值;
加权处理模块1018,用于根据权值对与已浏览的媒体信息对应的推荐系数进行加权处理,得到加权后的推荐系数。
在一个实施例中,目标用户数据包括用户基本信息和媒体浏览记录;数据获取模块1002还用于:
当接收到社交客户端发送的媒体信息浏览指令,或接收到社交客户端发出的启动指令,或检测到与社交客户端对应终端的位置信息发生变化时,则
从与社交客户端对应的用户数据库获取用户基本信息和媒体浏览记录;
从媒体库获取留存时长未超出时效阈值的媒体信息作为候选媒体信息。
上述实施例中,在推送媒体信息之前,判断推送的媒体信息中是否包含有联系人已浏览的媒体信息,若包含了,则在向目标用户标识所对应的终端推送媒体信息时,指示终端在展示联系人已浏览的媒体信息时展示忒硬的浏览提示标识,用于提示用户该媒体信息好友都在阅读,可以有效地提高媒体信息的点击率。此外,联系人已浏览的媒体信息表示许多好友都在阅读,目标用户可能也会有兴趣点击浏览,因此可以对联系人已浏览的媒体信息所对应的推荐系数进行加权处理,是该推荐系数增大,提高该媒体信息被推送的概率,从而提高媒体信息的点击率。
在一个实施例中,数据获取模块1002还用于:确定媒体库中各媒体信息的产生时间和所属领域;
根据产生时间和当前时间戳确定相应媒体信息的留存时长;
获取目标用户标识,并根据目标用户标识确定对应的关注领域;
从媒体库中筛选留存时长未超出时效阈值、且所属领域属于关注领域的媒体信息作为候选媒体信息。
上述实施例中,从媒体库中筛选留存时长未超出时效阈值、且所属领域属于关注领域的媒体信息作为候选媒体信息,一方面可以确保所筛选的媒体信息具有新闻时效性,可以有效地刺激用户去点击浏览,提高媒体信息的浏览率;另一方面,可以确保所筛选的媒体信息属于用户所喜欢的领域,也可以进一步地提高媒体信息的浏览率。
图12示出了一个实施例中计算机设备的内部结构图。该计算机设备具体可以是图1中的服务器120。如图12所示,该计算机设备包括该计算机设备包括通过系统总线连接的处理器、存储器、网络接口、输入装置和显示屏。其中,存储器包括非易失性存储介质和内存储器。该计算机设备的非易失性存储介质存储有操作系统,还可存储有计算机程序,该计算机程序被处理器执行时,可使得处理器实现媒体信息推送方法。该内存储器中也可储存有计算机程序,该计算机程序被处理器执行时,可使得处理器执行媒体信息推送方法。计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
本领域技术人员可以理解,图12中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
在一个实施例中,本申请提供的媒体信息推送装置可以实现为一种计算机程序的形式,计算机程序可在如图12所示的计算机设备上运行。计算机设备的存储器中可存储组成该媒体信息推送装置的各个程序模块,比如,图10所示的数据获取模块1002、特征提取模块1004、特征交叉处理模块1006、推荐系数确定模块1008和信息推送模块1010。各个程序模块构成的计算机程序使得处理器执行本说明书中描述的本申请各个实施例的媒体信息推送方法中的步骤。
例如,图12所示的计算机设备可以通过如图10所示的媒体信息推送装置中的数据获取模块1002执行S202。计算机设备可通过特征提取模块1004执行 S204。计算机设备可通过特征交叉处理模块1006执行S206。计算机设备可通过推荐系数确定模块1008执行S208。计算机设备可通过信息推送模块1010执行 S210。
在一个实施例中,提供了一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,计算机程序被处理器执行时,使得处理器执行上述媒体信息推送方法的步骤。此处媒体信息推送方法的步骤可以是上述各个实施例的媒体信息推送方法中的步骤。
在一个实施例中,提供了一种存储介质,存储有计算机程序,计算机程序被处理器执行时,使得处理器执行上述媒体信息推送方法的步骤。此处媒体信息推送方法的步骤可以是上述各个实施例的媒体信息推送方法中的步骤。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一非易失性计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM (EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM 以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM (SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM (RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态 RAM(RDRAM)等。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!