简体汉语文本可读性的分级评估建模方法与流程
本发明属于汉语语言数据处理领域,具体涉及简体汉语文本可读性的分级评估建模方法。
背景技术:
在现代信息社会中,儿童读物呈指数式增长,如何在浩如烟海的书籍中挑选出合适孩子的好书成为困扰老师和家长的难题。根据最近发展区理论,儿童阅读材料的难度应该稍高于儿童目前的发展水平,但又不能过高,才能达到训练并提高儿童阅读能力的目的。若所选的阅读材料过难,会损害儿童阅读的效能感,使其逃避阅读;而太简单的材料则会让儿童感到无趣,丧失阅读兴趣,达不到培养阅读习惯和提高阅读能力的目的。目前已有的图书分级体系大多由出版商主导,既没有坚实的理论研究作为基础,也缺少实证研究验证其有效性,科学性不足、公信力不高、影响力不大,对青少年阅读的指导意义有限。为了实现儿童阅读能力与书籍难度的匹配,在准确评估儿童阅读能力的同时,研发客观、高效的汉语文本可读性公式,对文本难度进行准确评估,是目前分级阅读研究的难点和热点问题之一。
可读性公式指的是采用数学表达的方法,提取某些可量化的、影响阅读难度的文本特征,并确定这些特征和文本难度之间的函数关系。目前,英语体系中已有十几个可读性公式,例如美国的蓝思可读性公式、a-z分级法、英国的牛津阅读树系列等。这些公式的准确度高,应用范围广,以此为基础建立了庞大的分级阅读体系,在促进英语儿童阅读能力培养和习惯养成等方面发挥了巨大的作用。
由于汉语与英语存在着巨大差异,英语世界中的可读性公式并不能直接应用于汉语文本,而目前可查到数学公式的汉语可读性公式仅有7项,主要针对的是繁体字学习者或对外汉语教学,并且大部分公式并未给出明确的等级划分标准,对大陆地区小学生的读物选择指导意义有限。因此,创建一项针对小学简体汉语母语的文本可读性公式,仍是一项具有挑战性的前沿工作。
技术实现要素:
本发明的目的在于提供一种简体汉语文本可读性的分级评估建模方法。
根据本发明具体实施方式的简体汉语文本可读性的分级评估建模方法,其包括以下步骤:
选择适合的文本建立标准语料库,将文本进行等级标注;
提取文本特征,
定义字、词、句层面的文本难度特征,分别对标准语料库中的文本进行切词和字词句标注处理等,计算每篇文本的难度特征值,然后选择文本难度特征的最优特征集;
构建文本可读性分级评估公式,
将标准语料库中的文本分为训练文本集和测试文本集,
以训练文本集被标注的等级为因变量y,以最优特征集为自变量(x1,x2,x3),采用线性回归模型,得到可读性分级评估公式为:
yi=β0+β1x1i+β2x2i+β3x3i+μi,其中,yi表示文本的可读性等级(1-12),x1i,x2i和x3i分别表示这篇文本的三项最优特征集的数值,β0为常数,代表截距,β1,β2和β3是偏回归系数,代表在其他变量保持不变的情况下,变量x1,x2或x3变化一个单位后的y值变化量;
以测试文本集为参照,对所述可读性公式进行评估。
根据本发明具体实施方式的简体汉语文本可读性的分级评估建模方法,在提取文本特征步骤中,采用nlpir汉语分词系统对文本进行切词和词性标注处理。
根据本发明具体实施方式的简体汉语文本可读性的分级评估建模方法,通过以下步骤选择最优特征集:
分别计算所有文本难度特征与文本难度等级的相关,根据相关系数的绝对值从大到小将文本难度特征排序;
按照排序,顺次选择文本难度特征值进入备选特征集,建立回归方程;
通过共线性判断选择留在备选特征集中的文本难度特征,得到最优特征集。
根据本发明具体实施方式的简体汉语文本可读性的分级评估建模方法,通过共线性判断选择留在备选特征集中的文本难度特征的方法为:
如果对于备选特征集中的文本难度特征x1、x2、……xk,存在不全为0的数λ1、λ2……λk,使得λ1x1+λ2x2+……λkxk+μi=0,则备选特征集中存在共线性问题,此时需要找出存在共线性问题的两个文本难度特征,在保持其他特征不变的情况下,比较两个文本难度特征加入后的△r2,在备选特征集中保留△r2较大的特征;若备选特征集中不存在共线性问题,则计算特征加入后的△r2,若△r2>2%,则在备选特征集中保留所述特征,否则删去所述特征;
循环上述步骤,直至遍历备选特征集中的所有文本难度特征。
根据本发明具体实施方式的简体汉语文本可读性的分级评估建模方法,简体汉语文本可读性分级评估公式的构建方法如下:
以训练文本集被标注的等级为因变量y,以最优特征集为自变量(x1,x2,x3),设y随着x1,x2,x3的变化而变化,并存在线性关系:yi=β0+β1x1i+β2x2i+β3x3i+μi(i=1,2,3,…,n),假设
观测值yi与回归值
根据最小二乘法,
根据多元函数的极值原理,q分别对
因为
设
由于不存在多重共线性,x’x为4阶方阵,所以x’x满秩,x’x的逆矩阵(x’x)-1存在,因而
求得
计算根据可读性公式算出的观测值y观测和测试文本集的实际值y实际之间的相关r;
计算可读性公式对测试文本集数据的变异解释量r2,r2=r2;
计算临近准确率,临近准确率=|y观测-y实际|,若临近准确率不大于1,则视为评估正确;计算评估正确的文本总数占测试文本集总数的比例,即为临近准确率;
计算均方根误差:
当0<r<1,r接近1,且
0<r2<1,r2接近1,且
临近准确率<=1,临近准确率越接近1,且
均方根误差越小,则判断可读性分级评估公式越准确。
本发明的有益效果:
本发明基于汉语特点,提供了一种可对汉语文本进行汉字、词汇和句法三个层面的难度特征分析及自动化的分级评估建模方法,保证了文本难度评定的客观性;
本发明基于统计学原理,在全面分析44个文本特征的基础上,进行了特征优化,简化了模型,避免了多重共线性问题,在保证预测准确性的同时,提升了模型的可理解性;
本发明建构了汉语可读性公式及文本分级体系,可与汉语阅读能力测评相结合,最终建立具有汉语特色的阶梯阅读体系并进行推广,实现学生阅读能力和书本难度的有效匹配,科学推动全体青少年儿童阅读能力的发展。
附图说明
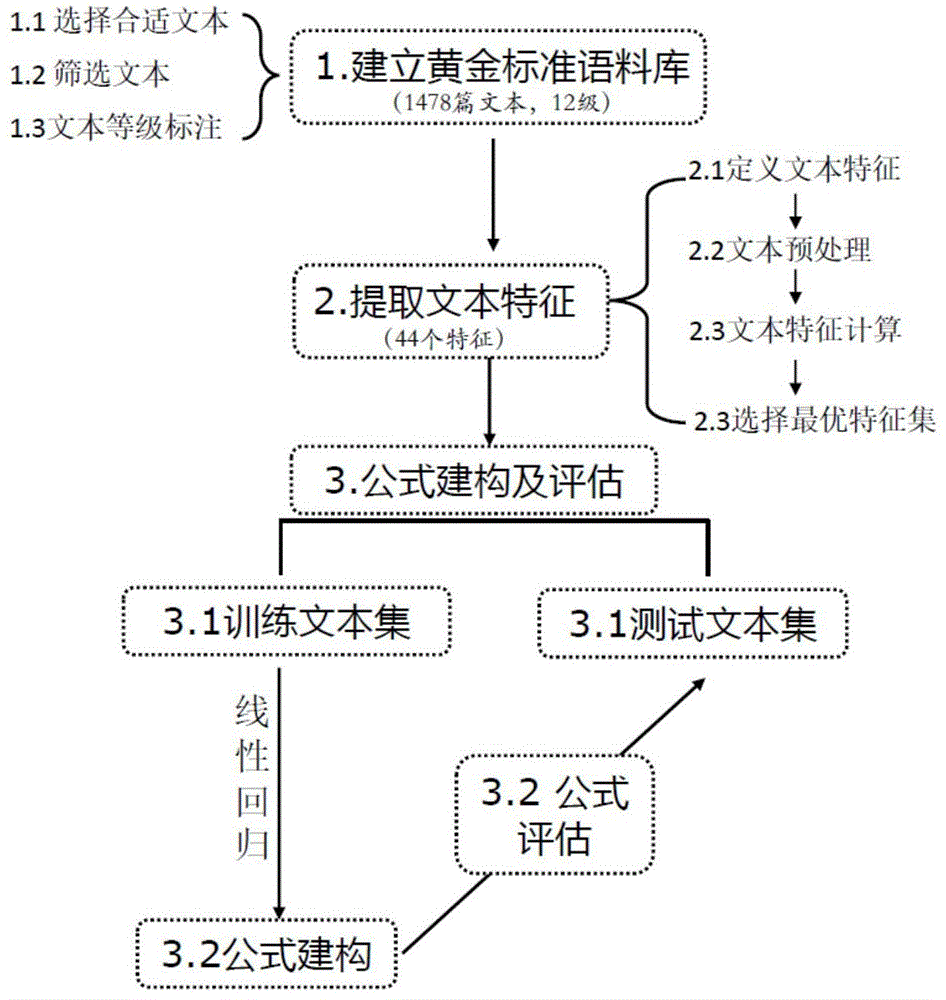
图1显示本发明的分级评估方法流程图;
图2显示最优特征集选择流程图。
具体实施方式
实施例1
如图1所示,本发明的简体汉语文本可读性的分级评估建模方法包括以下步骤:
1.建立黄金标准语料库,即定义因变量
1.1选择合适文本
标准语料库的选择需要贴合可读性公式的使用目的,本发明主要针对大陆地区小学儿童的阅读材料,故选择的文本来自于大陆地区、被广泛使用的四个版本的小学语文教材,主要包括人民教育出版社、北京师范大学出版社、江苏教育出版社和西南师范大学出版社,每一个出版社各一套(12册),共计48册,每一册均有明确的等级信息(册数),可作为文本的等级。
1.2筛选文本
由于古汉语和现代汉语在句法、字词含义上均有较大差异,现代诗没有标点符号,难以统计句子层面的文本特征,故通过人工检查删去了古诗、古文、现代诗歌等文本。最终黄金标准语料库共有1478篇文本,总计801550字,具体信息见表1。
表1标准语料库
1.3文本等级标注
根据文本在教材中的出现册数(每个年级分上、下学期,六个年级共计12册),对每一篇文本进行1~12的等级标注。
2.提取文本特征,即定义自变量
2.1定义文本特征
本发明共定义了字、词、句三个层面的文本难度特征共计44个,具体文本特征名称及定义见表2:
表2文本特征汇总
2.2文本预处理
采用nlpir汉语分词系统(源自nlpir.org(自然语言处理与信息检索共享平台))对文本进行切词和词性标注处理,该系统切词标注准确性达到98.45%。
2.3文本特征计算
2.3.1统计文章中的字数、词数、字种、词种以及标点符号的数量;
2.3.2将字、词与汉字笔画数表、字词难度等级表等进行比对,得到每个字词的相关信息;
2.3.3统计词汇的词性分布情况;
2.3.4根据表2中44个特征的操作性定义,以及2.3.1至2.3.3的结果,获得每篇文本对应的44个特征值。
2.4选择最优特征集
2.4.1分别计算44个特征(x1,x2,x3,……x44)和文本难度等级(y)的相关系数(r),具体为
其中,j=1,2,3,……,44;n=1478;σxj,σy表示xj,y的标准差;xji表示第i篇文本在第j项文本特征上的分数;yi表示第i篇文本的文本难度等级;
2.4.2根据相关系数(r)的绝对值,从大到小对44个特征进行排序,按照顺序依次选择一项特征进入备选特征集,建立回归方程yi=β0+β1x1i+β2x2i+……+βkxki+μi;
其中,yi表示第i篇文本的难度等级,x1i,x2i,……,xki分别表示这篇文本的k项备选特征集分数,β0为常数,代表截距,β1,β2……,βk是偏回归系数,代表在其他变量保持不变的情况下,变量x1,x2,……,xk变化一个单位后的y值变化量。
2.4.3进行共线性判定
若对于此时备选特征集中的特征x1,x2,……xk,存在不全为0的常数λ1,λ2……λk,μ,使得λ1x1+λ2x2+……λkxk+μ=0,即判定备选特征集中存在共线性问题。反之,若这个式子无解,即找不到不全为0的常数λ1,λ2……λk,μ使该等式成立,那么就不存在共线性问题。
当备选特征集中存在共线性问题时,计算备选特征集中的k个特征x1,x2,……xk两两之间的相关系数(计算方法同2.4.1),若某两个特征间的相关系数大于0.75,即能确定是这两个特征存在共线性问题。
假设特征xk-1和xk存在共线性问题,则首先建立不加入这两项特征的回归方程模型m0:yi=β0+β1x1i+……+βk-2xk-2i+μi(参数含义同2.4.2),并计算模型的多重决
其中,
之后,在模型m0的特征基础上分别加入特征xk-1和xk,建立模型m1:yi=β0+β1x1i+……+βk-2xk-2i+βk-1xk-1i+μi(参数含义同2.4.2)和m2:yi=β0+β1x1i+……+βk-2xk-2i+βkxki+μi(参数含义同2.4.2),同样得到模型m1和m2的多重决定系数rm12和rm12。最终,计算相较于模型m0而言,模型m1和模型m2的所增加的r2变化量:△rm12=rm12-rm02;△rm22=rm22-rm02,保留△r2较大的模型中所有的特征进入备选特征集。
若备选特征集不存在共线性问题,则计算该特征加入后的△r2,若△r2>2%,则在备选特征集中保留该特征,否则删去该特征。
2.4.4循环2.4.2~2.4.3各步骤,直至遍历所有特征,流程图参见图2。
2.4.5最终得到最优特征集,在本发明中,最终共包含三项特征:字种、识字表字种平均难度和虚词比例。
3.构建可读性公式并对公式效果进行评估
3.1确定训练和测试文本集
将每一册语文教材中的文本随机分成训练文本集和测试文本集,保证每一版本、每一册中,训练文本集和测试文本集的文本数量比为1:1。
3.2建立可读性公式
以训练文本集的等级标定为因变量y,以上述2.4步骤中确定的最优特征集(字种、识字表字种平均难度和虚词比例)为自变量(x1,x2,x3),采用线性回归模型,构建可读性公式,具体如下:
设y随着x1,x2,x3的变化而变化,并存在线性关系,用公式表示如下:
yi=β0+β1x1i+β2x2i+β3x3i+μi,
其中,yi表示文本的可读性等级,x1i,x2i,x3i分别表示这篇文本的字种、识字表字种平均难度和虚词比例的分值,β0为常数,代表截距,β1,β2,β3是偏回归系数,代表在其他变量保持不变的情况下,变量x1,x2或x3变化一个单位后的y值变化量。
假设
观测值yi与回归值
根据最小二乘法,
根据多元函数的极值原理,q分别对
因为
设
由于不存在多重共线性,x’x为4阶方阵,所以x’x满秩,x’x的逆矩阵(x’x)-1存在,因而
最终求得
最终得到的可读性公式为:
分级数=-4.84+0.01*字种+3.34*识字表字种平均难度+7.83*虚词比例。
3.3可读性公式评估
以测试文本集为参照,对上述可读性公式进行评估,具体步骤为:
3.3.1计算r值:计算根据可读性公式算出的观测值(y观测)和测试文本集的实际值(y实际)之间的相关系数(计算公式同2.4.1,具体为
其中,n=1478;σy观测,σy实际分别表示y观测和y实际的标准差;y观测i表示第i篇文本根据可读性公式算出的文本难度等级;y实际i表示第i篇文本实际的文本难度等级;
3.3.2计算r2:r2是衡量回归结果的重要指标,表示可读性公式对测试文本集难度值的变异解释量,r2=r2。
r2取值范围在0到1之间,越接近1,可读性公式效果越好。
3.3.3计算临近准确率:临近准确是指将观测值与实际值相差一个级别的情况也视为预测正确。例如,若文本实际值为3,则观测值为2或3或4均标记为正确,临近准确率即|y观测-y实际|<=1的文本所占的比例,其取值范围在0到1之间,越接近1,可读性公式效果越好。
3.3.4均方根误差:均方根误差是指观测值与实际值之间的平方根偏差大小,具体计算公式为:
本发明所构建的可读性公式的各项指标如表3所示:
表3可读性公式各项指标
由结果可知,本发明所建构的汉语可读性公式,可用于预测小学阶段汉语文本的难度,进行1~12等级的难度标定。
- 还没有人留言评论。精彩留言会获得点赞!