恶意代码壳识别与静态脱壳方法和系统与流程
本发明涉及互联网信息安全技术领域,具体地,涉及一种恶意代码壳识别与静态脱壳方法和系统。
背景技术:
当今社会,计算机网络与人类生活的各方面息息相关。计算机技术的飞速发展在带来便利的同时,也带来了诸多的安全隐患。随着计算机技术的发展,出现了一类软件代码,他们被附加在可执行程序中,将程序中的原始代码进行保护,同时将可执行程序的执行顺序进行修改。攻击者们正是利用这一点,将恶意代码进行加壳操作,利用壳代码来逃避诸多的检测分析,从而躲避安全软件的扫描与查杀。
面对这一严峻的挑战,如何准确地识别出加壳代码种类,如何完整的还原出原始程序的数据和代码,成为了影响恶意代码分析检测的主要问题所在,针对爆发式增长的恶意代码,安全研究人员对恶意代码分析技术做出深入研究。结果发现,很多新型的恶意代码壳代码都是来自于已有的壳代码的变种,这些代码往往具有高度相似的结构、雷同的函数调用顺序与代码编写习惯等。对未知恶意代码壳代码进行识别并找出与其具有相似特征的、已记录在库的同源恶意代码壳代码,从而做出快速响应与处理就显得十分重要。针对识别出的加壳算法,本发明也设计了一种能够快速对其进行脱壳处理的方法。
恶意代码壳代码的识别已有学者进行一定研究,但采用特征码匹配的算法无法识别新型壳代码的变种,极大影响了其的适用性。而对壳代码进行可视化的思想最早是由加利福尼亚大学的nataraj和karthikeyan在2011年提出的。而近年来,伴随着深度神经网络的迅猛发展,lenet网络在图像分类领域展现出卓越性能,为壳代码图像的识别提供了合适的模型选择。目前没有发现同本发明类似技术的说明或报道,也尚未收集到国内外类似的资料。
与本申请相关的现有技术是专利文献cn104850786a,公开了一种基于环境重构的恶意代码完整性分析方法,通过使用合理的分析策略提取恶意代码执行过程中所需的环境数据,以此为基础进行恶意代码执行环境的动态构建,将恶意代码置入动态构建的环境中进行分析,从而获得较为完整的行为信息。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种恶意代码壳识别和静态脱壳方法和系统。
根据本发明提供的一种恶意代码壳识别和静态脱壳方法,包括:
壳代码预处理步骤:对待判定恶意代码进行反汇编,提取反汇编中的特征信息;
可代码可视化步骤:接收特征信息,利用特征信息对待判定恶意代码进行可视化,生成壳代码图像;
深度学习步骤:将壳代码图像与待判定恶意代码的标签值组成样本集,对深度学习模型进行训练,得到成熟识别模型,将待判定恶意代码作为成熟识别模型的输入,进行壳代码识别,得到加壳代码;
脱壳步骤:将加壳代码进行脱壳处理。
优选地,所述脱壳处理是对加壳代码进行文件校验、加壳算法校验、pe文件加载、数据解压、导入函数表iat修复、创建pe文件镜像。
优选地,使用ida工具对待判定恶意代码进行反汇编,得到附加信息、反汇编指令信息,令附加信息去除,将反汇编指令信息作为特征信息。
优选地,所述对待判定恶意代码进行可视化是对特征信息按字节分割,映射为像素点的灰度值数组,并对所述灰度值数组进行可视化。
优选地,对特征信息按字节分割,每个字节所对应的十六进制的范围为[00,ff],将[00,ff]对应到十进制数值为0-255,覆盖整个灰度值的范围,其中0代表黑色,255代表白色。
优选地所述深度学习模型使用深度学习lenet-5网络模型。所述深度学习lenet-5网络模型的参数包括:
输入:像素大小为128*128的壳代码图像;
输出:待判定恶意代码的标签值的加壳编号;
卷积层数:3;
池化层数:2;
激活函数:relu;
训练参数总数:49836。
优选地,所述文件校验是判定加壳代码的程序完整性;所述加壳算法校验是判定加壳代码的程序类型;所述pe文件加载是判定pe文件类型;所述导入函数表iat修复是将被加壳代码修改的指向加壳代码自身函数地址表的导入表进行修复。
优选地,创建pe文件镜像是将对加壳代码进行文件校验、加壳算法校验、pe文件加载、数据解压、导入函数表iat修复各个环节得到的原始程序数据、原始导入表信息进行整合和转存,生成新pe文件头,完成脱壳处理。
根据本发明提供的一种恶意代码壳识别和静态脱壳系统,包括:
壳代码预处理模块:对待判定恶意代码进行反汇编,提取反汇编中的特征信息;
可代码可视化模块:接收特征信息,利用特征信息对待判定恶意代码进行可视化,生成壳代码图像;
深度学习模块:将壳代码图像与待判定恶意代码的标签值组成样本集,对深度学习模型进行训练,得到成熟识别模型,将待判定恶意代码作为成熟识别模型的输入,进行壳代码识别,得到加壳代码;
脱壳模块:将加壳代码进行脱壳处理。
与现有技术相比,本发明具有如下的有益效果:
1、本发明将特征选择着眼于更抽象的恶意代码壳代码图像,舍弃常用的静态分析所得到的静态特征信息,无需对恶意代码壳代码做人工处理与分析,实现系统自动化,可高效便捷地对恶意代码壳代码做识别分析。
2、本发明的判定系统具备可学习性,深度学习技术的特性支持系统获取新恶意代码样本时可进行追加训练,及时适应新型恶意代码壳代码的出现,进一步提高准确率。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
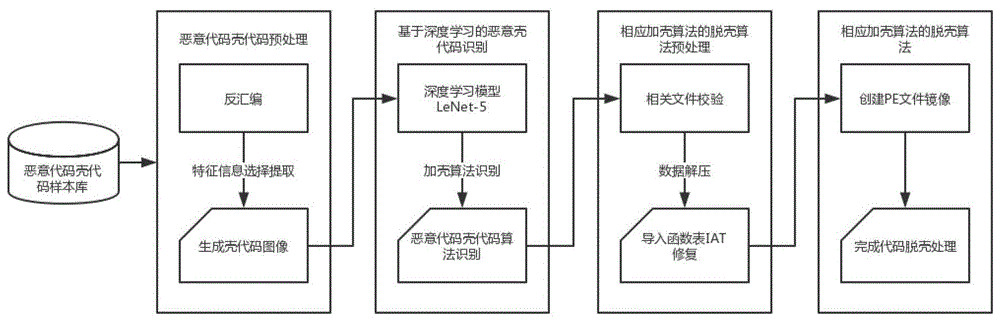
图1为本发明一实施例的系统总体架构图。
图2为本发明的恶意代码壳代码可视化算法示意图。
图3为本发明的lenet-5模型示意图。
图4为本发明的脱壳算法示意图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
本发明针对现有技术存在的上述不足,提供了一种恶意代码壳代码识别方法和静态脱壳方法,该方法使用已经较为成熟的深度神经网络,完成一个可用的高效准确的恶意代码壳代码识别和修复系统。该系统利用一种恶意代码壳代码可视化算法将壳代码映射为灰度图像,将加壳算法识别问题转化为图像分类问题,结合深度学习的lenet模型,实现比现有系统更高判定准确率的壳代码识别技术,并针对已被识别出的加壳算法进行脱壳处理,实现更加高效的脱壳方法。
根据本发明提供的一种恶意代码壳识别和静态脱壳方法,包括:
壳代码预处理步骤:对待判定恶意代码进行反汇编,使用ida工具提取反汇编中的特征信息;
可代码可视化步骤:接收特征信息,利用特征信息对待判定恶意代码进行可视化,生成壳代码图像;
深度学习步骤:将壳代码图像与待判定恶意代码的标签值组成样本集,对深度学习模型进行训练,得到成熟识别模型,将待判定恶意代码作为成熟识别模型的输入,进行壳代码识别,得到加壳代码;
脱壳步骤:将加壳代码进行脱壳处理。
具体地,所述脱壳处理是对加壳代码进行文件校验、加壳算法校验、pe文件加载、数据解压、导入函数表iat修复、创建pe文件镜像。
具体地,使用ida工具对待判定恶意代码进行反汇编,得到附加信息、反汇编指令信息,令附加信息去除,将反汇编指令信息作为特征信息。
具体地,所述对待判定恶意代码进行可视化是对特征信息按字节分割,映射为像素点的灰度值数组,并对所述灰度值数组进行可视化。
具体地,对特征信息按字节分割,每个字节所对应的十六进制的范围为[00,ff],将[00,ff]对应到十进制数值为0-255,覆盖整个灰度值的范围,其中0代表黑色,255代表白色。
具体地所述深度学习模型使用深度学习lenet-5网络模型。所述深度学习lenet-5网络模型的参数包括:
输入:像素大小为128*128的壳代码图像;
输出:待判定恶意代码的标签值的加壳编号;
卷积层数:3;
池化层数:2;
激活函数:relu;
训练参数总数:49836。
具体地,所述文件校验是判定加壳代码的程序完整性;所述加壳算法校验是判定加壳代码的程序类型;所述pe文件加载是判定pe文件类型;所述导入函数表iat修复是将被加壳代码修改的指向加壳代码自身函数地址表的导入表进行修复。
具体地,创建pe文件镜像是将对加壳代码进行文件校验、加壳算法校验、pe文件加载、数据解压、导入函数表iat修复各个环节得到的原始程序数据、原始导入表信息进行整合和转存,生成新pe文件头,完成脱壳处理。
根据本发明提供的一种恶意代码壳识别和静态脱壳系统,包括:
壳代码预处理模块:对待判定恶意代码进行反汇编,使用ida工具提取反汇编中的特征信息;
可代码可视化模块:接收特征信息,利用特征信息对待判定恶意代码进行可视化,生成壳代码图像;
深度学习模块:将壳代码图像与待判定恶意代码的标签值组成样本集,对深度学习模型进行训练,得到成熟识别模型,将待判定恶意代码作为成熟识别模型的输入,进行壳代码识别,得到加壳代码;
脱壳模块:将加壳代码进行脱壳处理。
本发明提供的恶意代码壳识别和静态脱壳系统,可以通过恶意代码壳识别和静态脱壳方法的步骤流程实现。本领域技术人员可以将恶意代码壳识别和静态脱壳方法理解为所述恶意代码壳识别和静态脱壳系统的优选例。
在具体实施中,通过恶意代码可视化算法,将壳代码识别任务转化为图像分类任务,结合深度学习判定模型,实现了一个可用的恶意代码壳代码识别系统并对识别出的加壳算法进行脱壳处理。本发明通过以下步骤实施:
第一步:恶意代码壳代码预处理:对于待判定的恶意代码进行反汇编,选择反汇编指令信息作为特征信息,去除附加信息。
所述特征信息,具体为,恶意代码经过反汇编后,ida工具得到的附加信息和反汇编指令信息中的反汇编信息。
所述去除附加信息,具体为,由反汇编器进行添加的,帮助总结了pe文件中包括入口点、基址、导入表等的信息,但是随着应用的扩展,使用的反汇编器种类可能会对后续的训练造成影响,故将其忽略。
第二步:恶意代码壳代码可视化:接收步骤s1中得到的特征信息内容作为输入,利用恶意代码壳代码可视化算法,将特征信息内容映射为恶意代码壳代码图像。
所述恶意代码壳代码可视化,具体为,对特征信息按字节进行分割,每个字节所对应的十六进制的范围为[00,ff],将其对应到十进制数值为0-255,刚好覆盖了整个灰度值的范围,0代表黑色,255代表白色。对恶意代码文件进行反汇编操作得到其特征信息,按字节分割得到像素值存入数组,将二进制串映射为像素点灰度值数组,再将数组可视化为恶意代码壳代码图像。
第三步:基于深度学习的壳代码识别:利用步骤s2中得到的恶意代码壳代码图像与标签值组成的样本集,对深度学习模型lenet-5进行训练,得到成熟的识别模型;接收待判定的恶意代码作为输入,完成壳代码识别。
所述lenet-5模型,具体为,一种深度学习模型,一种前馈神经网络,由卷积层和池化层堆叠而成,因其局部连接、权重共享、多卷积核的特点被广泛应用于图像处理与识别领域,性能优异。
进一步地,所述卷积神经网络模型的参数为:
输入:像素大小为128*128的恶意代码壳代码图像;
输出:经识别所属加壳算法编号;
卷积层数:3;
池化层数:2;
激活函数:relu;
训练参数总数:49836;
第四步:将样本中的壳代码进行文件校验、加壳算法校验、pe文件加载、数据解压、导入函数表iat修复、创建pe文件镜像操作完成脱壳处理。
所述文件验证,即判断脱壳程序能否正常打开,待检测程序是否完整。
所述加壳算法校验,即判断待检测文件为何种加壳程序。
所述pe文件验证,即验证待脱壳文件是否为pe文件类型。
所述导入函数表修复,即将被壳代码修改的指向壳代码自身函数地址表的导入表进行修复。
所述创建pe文件镜像,即将之前的各项操作得到的原始程序数据、原始导入表等信息进行整合和转存,从而生成一个新的pe文件头,结束脱壳处理。
下面结合附图对本实施例的技术方案进一步详细描述。
本实施例使用已经较为成熟的lenet-5模型,完成一个高效的普适性广的恶意代码壳代码识别和对应加壳算法脱壳处理系统。该系统利用一种恶意代码可视化算法将恶意代码壳代码映射为灰度图像,将加壳算法识别问题转化为图像分类问题,结合深度学习的lenet-5模型,实现比现有系统更高判定准确率的壳代码识别技术和脱壳算法。如图1所示,描述本实施例的系统总体架构图。
根据本实施例所提供方法的具体实施过程,分为以下4个步骤。
第一步:恶意代码壳代码预处理:对于待判定的恶意代码进行反汇编,得到包括指令地址、指令码和汇编指令的指令代码列表即反汇编指令信息和附加信息,选择反汇编指令信息作为特征信息,去除附加信息。
附加信息是由反汇编器进行添加的,帮助总结了pe文件中包括入口点、基址、导入表等的信息,但是随着应用的扩展,使用的反汇编器种类可能会对后续的训练造成影响,故将其忽略。
第二步,恶意代码可视化。对特征信息按字节进行分割,每个字节所对应的十六进制的范围为[00,ff],将其对应到十进制数值为0-255,刚好覆盖了整个灰度值的范围,0代表黑色,255代表白色。接收第一步所述的特征信息作为输入,按字节分割得到像素值存入数组,将二进制串映射为像素点灰度值数组,再将数组可视化为恶意代码图像。
如图2所示,描述该算法伪代码。具体算法如下:
(1)读取长度为m的恶意代码特征信息字符串str;
(2)截取str下一个字节,将其转化为十进制值dec,存入像素值数组img_array;
(3)判断str是否截取至最后一个字节,如果是,则退出程序返回img_array,否则跳转至(2)。
第三步,基于深度学习的加壳算法识别。利用所述恶意代码壳代码图像与标签值组成的样本集,对深度学习模型lenet-5进行训练,得到成熟的识别模型。接收待判定的恶意代码作为输入,完成加壳算法识别。
lenet-5是深度神经网络的一种。它属于卷积神经网络cnn的一种,cnn近年来发展迅速,已经在图像领域中大放异彩。在cnn模型中,图像中的局部感知区域作为模型底层的输入数据,经过网络中各个层由过滤器进行处理,逐层抽象,最终获得输入图像的高抽象的显著特征。
图3示出了图1所示的基于深度学习的恶意代码壳代码识别的深度学习模型部分,该lenet模型的最终参数为:
输入:像素大小为128*128的恶意代码壳代码图像;
输出:经识别所属加壳算法编号;
卷积层数:3;
池化层数:2;
激活函数:relu;
训练参数总数:49836;
在本实施中,恶意代码预处理是指:利用ida工具,对于待判定的恶意代码进行反汇编,得到附加信息和反汇编指令信息,忽略附加信息,将反汇编指令信息作为处理对象。恶意代码可视化是指:对特征信息按字节分割,映射为像素点灰度值数组,再将数组可视化为恶意代码壳代码图像。基于深度学习的壳代码识别是指:利用恶意代码图像与标签值组成的样本集,对深度学习模型lenet-5进行训练,得到成熟的识别模型。接收待判定的恶意代码作为输入,输出加壳算法,完成壳代码识别。
第四步,选择nspack加壳算法的脱壳处理。如图4出示了对于nspack加壳算法的脱壳处理部分。对识别出的nspack壳代码进行文件校验、加壳算法校验、pe文件加载、数据解压、导入函数表iat修复、创建pe文件镜像操作完成脱壳处理。
在本实施中文件验证是指:判断脱壳程序能否正常打开,待检测程序是否完整。pe文件验证是指:验证待脱壳文件是否为pe文件类型。加壳算法校验是指:判断待检测文件是否为nspack加壳程序。导入函数表修复是指:将被壳代码修改的指向壳代码自身函数地址表的导入表进行修复。创建pe文件镜像是指:将之前的各项操作得到的原始程序数据、原始导入表等信息进行整合和转存,从而生成一个新的pe文件头,结束脱壳处理。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!