基于双重自动编码器的半监督跨领域文本分类方法与流程
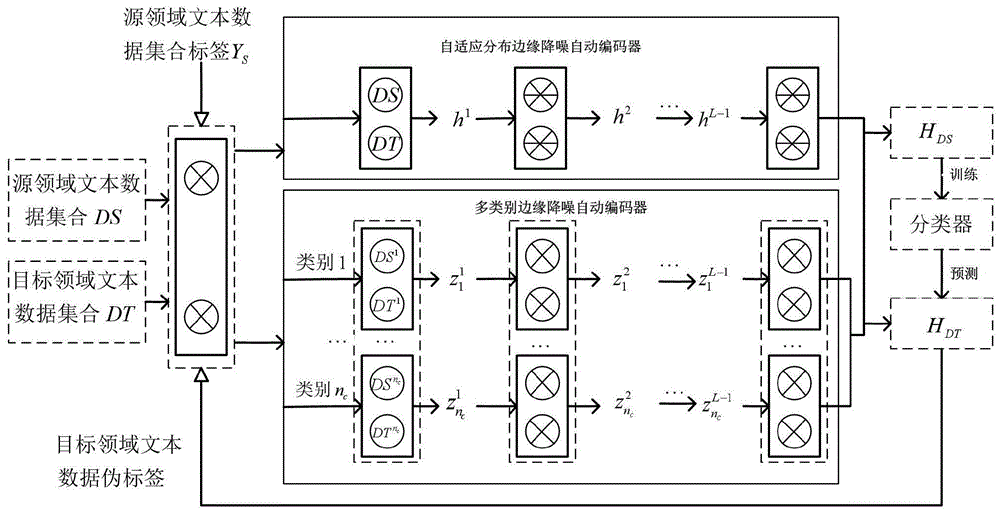
本发明涉及机器学习领域,具体的说是一种基于双重自动编码器的半监督跨领域分类方法,并对文本数据信息进行分类,更具体地说是利用某个领域的文本数据信息对另一个具有不同数据分布的文本数据信息进行分类。
背景技术:
近年来,随着信息化、网络化快速发展,人们的生活与工作也越来越依赖网络信息;现如今,网络信息几乎涉及了人类生活的全部领域;然而,网络技术的发展,网络数据也在逐年增长;一些具有重要价值的信息一般都隐藏在这些数据中,如何对这些海量数据进行高效、准确的分类,使之更好地服务于人们的日常生活与工作日益重要;例如:在京东、淘宝等购物平台,商家可以通过分析消费者评论信息,有针对地进行产品改进或升级,从而提高产品质量;对消费者而言,商品的评论信息在一定程度上左右了消费者的购买意愿,消费者偏向购买口碑较好的商品;一些个性化新闻推荐网站,后台技术人员通过对用户的阅览记录进行分析,对用户的喜好进行分类,然后根据用户的兴趣,给不同用户推荐不同领域的文章;鉴于此,文本分类等相关领域的研究具有极其重要的价值和意义;
现如今,不仅人类社会生活中数据的类型越来越多样化,而且对海量数据进行标记需要大量的人力和财力,传统的机器学习方法因而面临着艰难的挑战;传统机器学习方法通常基于两个基本假设:不仅训练数据和测试数据独立并且服从同一数据分布,而且需要大量的标记样本用于训练分类模型;然而,由于网络中数据受用户,时间等多因素的影响,其数据分布在不断发生变化,因此,较难收集到满足同一分布的充足的有效训练数据,从而传统的文本分类方法面临巨大的挑战;为了解决这个问题,国内外学者提出了大量跨领域文本学习算法;
深度学习在自然处理领域研究成果显著,多种神经网络模型被用于文本分类,如卷积神经网络(cnn)、循环神经网络(rnn)、对抗神经网络(gan)以及自动编码器(ae);其中,降噪自动编码器通过堆叠多层能获取高层、鲁棒的特征表示,在跨领域文本分类任务上取得令人满意的分类正确率,然而其计算成本很高且缺乏对高维特征的可扩展性;目前,已有的降噪自动编码器多为无监督模型,在训练分类器时容易产生过拟合问题;此外,基于自动编码器的跨领域文本分类方法一般是基于自动编码器学习同时适用于源领域和目标领域深层特征表示,而忽略领域内的一些固有信息对跨领域文本分类的影响;已有的自动编码器模型不具有普适性,从而限制了在应用中的使用;
综上,现有技术中基于降噪自动编码器的跨领域文本分类面临着以下的挑战:
一是降噪编码器一般多为无监督模型,利用源领域中文本数据训练分类器时,没有利用源领域中文本数据的标签信息,容易产生过拟合问题;
二是已有的降噪自动编码器一般仅仅使用一种自动编码器模型学习可迁移的特征表示用于跨领域文本分类,通常一种自动编码器仅可以学习源领域和目标领域中文本数据的一种数据特征表示,不能从多个角度(全局、局部)学习丰富的数据表示用于跨领域文本分类;
技术实现要素:
本发明是为避免上述现有技术所存在的不足,提供一种基于双重自动编码器的半监督跨领域文本分类方法,以期能获取源领域中文本数据和目标领域中文本数据的更丰富的特征表示,从而能进一步提高跨领域文本分类的准确率。
本发明为实现发明目的采用如下技术方案:
本发明一种基于双重自动编码器的半监督跨领域文本分类方法的特点是按如下步骤进行:
步骤1:初始化
步骤1.1:获取源领域的文本数据集合
步骤1.2:获取目标领域的文本数据集合
步骤1.3:基于所述源领域的文本数据集合ds利用支持向量机进行训练,得到源领域的分类器;利用所述源领域的分类器对所述目标领域的文本数据集合dt进行分类,得到目标领域的文本数据的伪标签集合
步骤1.4:将所述源领域的文本数据集合ds和目标领域的文本数据集合dt中所有文本数据进行合并,得到合并集合x,x=[x1,x2,…,xa,…,xa],xa为合并集合x中第a个文本数据,a=1,2,…,a,且a=ns+nt;
步骤1.5:根据源领域的文本数据的样本标签集合ys和目标领域的文本数据的伪标签集合yt,将所述源领域的文本数据集合ds和目标领域的文本数据集合dt中的属于同一类别的文本数据划分为一类,从而得到包含nc个类的数据集,其中第d个类别cd的数据集,记为ed=[dsd,dtd];dsd为所述源领域的文本数据集合ds中,样本标签属于第d个类别cd的所有文本数据;dtd为目标领域的文本数据集合dt中,伪标签属于第d个类别cd的所有文本数据;
步骤2:利用基于自适应分布的边缘降噪自动编码方法对所述合并集合x进行lmax层堆叠学习,获得源领域的文本数据集合ds和目标领域的文本数据集合dt的全局特征表示:
步骤2.1:定义当前堆叠学习的层数为l;并初始化l=1;定义最大堆叠学习的层数为lmax;
步骤2.2:将所述合并集合x的第l层的输入记为hl-1,当l=1,令hl-1=x;
步骤2.3:以噪音干扰系数p对所述第l层的输入hl-1进行随机损坏,得到损坏数据
步骤2.4:利用式(1)表征第l层的重构误差θ(wl):
式(1)中,λ,β为常数,||·||2表示矩阵的frobenius范数的平方,
式(2)中,tr(·)为矩阵的迹,(·)t为矩阵(·)的转置,
式(3)中,(·)αδ表示矩阵的第α行第δ列元素;xα和xδ分别表示所述合并集合x中第α个文本数据和第δ个文本数据;
式(4)中,
式(5)中,(·)ηκ表示矩阵的第η行第κ列元素,xη和xκ分别表示所述合并集合x中第η个文本数据和第κ个文本数据;
步骤2.5:利用最小二乘法对所述重构误差θ(wl)进行求解,得到
式(6)中,(·)mu表示矩阵的第m行第u列元素;
式(7)中,(·)μν表示矩阵的第μ行第ν列元素;
步骤2.6:获得第l层的输出特征空间hl=tanh(hl-1wl),其中,tanh()为双曲正切函数;
步骤2.7:将l+1赋值给l,并判断l>lmax是否成立,若成立,则表示得到获得源领域的文本数据集合ds和目标领域的文本数据集合dt的全局特征表示
步骤3:利用基于多类别的边缘降噪自动编码方法学习对第d个类别cd的数据集ed进行lmax层堆叠学习,获得源领域的文本数据集合ds和和目标领域的文本数据集合dt的局部特征表示:
步骤3.1:初始化l=1;
步骤3.2:将第d个类别cd的数据集ed的第l层的输入记为
步骤3.3:以噪音干扰系数p对所述第l层的输入
步骤3.4:利用式(8)表征第d个类别cd的数据集ed的第l层的重构误差
式(8)中,
式(9)中,
式(10)中,
步骤3.5:利用最小二乘法对所述重构误差
式(11)中,(·)θρ表示矩阵的第θ行第ρ列元素;
式(12)中,(·)υψ表示矩阵的第υ行第ψ列元素;
步骤3.6:获得所述第d个类别cd的数据集ed第l层的输出特征空间
步骤3.7:将l+1赋值给l,并判断l>lmax是否成立,若成立,则表示得到获得源领域的文本数据集合ds和目标领域的文本数据集合dt的局部特征表示
步骤4:获取双重特征表示并构建分类器:
步骤4.1:将所述源领域和目标领域文本数据的全局特征表示hglobal和局部特征表示hlocal进行合并,形成双重特征表示h=[hglobal;hlocal];
将所述双重特征表示h划分为源领域的文本数据集合ds的特征表示hds和目标领域的文本数据集合dt的特征表示hdt;
步骤4.2:基于所述源领域的文本数据集合ds的特征表示hds利用支持向量机进行训练,得到源领域的特征表示的分类器;利用所述源领域的特征表示的分类器对所述目标领域的文本数据集合dt的特征表示hdt进行分类,得到目标领域的文本数据的新伪标签集合yt′;
步骤4.3:判断||yt-yt′||2≤1是否成立,若成立,则所得到的新伪标签集合yt′即为所述目标领域的文本数据的分类结果;否则,将yt′赋值给yt后,返回步骤1.3顺序执行。
与已有技术相比,本发明有益效果体现在:
1、本发明有效减少了训练分类器时出现过拟合的风险,同时提高了跨领域文本分类的正确性;本发明充分利用了源领域中文本数据的标签信息,并利用步骤1.3获取目标领域中文本数据的伪标签信息,然后利用这两个领域中的文本数据的标签信息最小化了领域间的文本数据分布差异,从而避免了训练分类器时出现过拟合问题又进一步提高了跨领域文本分类的分类精度;
2、本发明充分挖掘了源领域中文本数据和目标领域中文本数据的特征之间的潜在关系,从而提高了跨领域文本分类的分类性能;本发明在步骤2对源领域和目标领域中文本数据的全局特征表示进行了学习,同时挖掘了具有同一类别中文本数据间的信息,具体实施过程如步骤3所示,从而获得了更多的特征信息,有利于跨领域文本分类;
3、本发明采用两种类型的堆叠自动编码器学习源领域中文本数据和目标领域中文本数据的深层特征表示,获取了更高质量的特征表示,提高了跨领域文本分类的准确率;而且,本发明使用的两种类型的堆叠自动编码器运行速度更快,具有较高的实用价值;
4、本发明面向实际应用领域,如:用户在社交网络发表对不同事件看法的分类,可用于政府部门及时发现并掌握舆论走向;购物网站根据用户对某一商品的评论对另一种商品进行分析、分类,可为商家、消费者提供预测、预警工作,为商家的销售、服务质量调整策略提供建议以及为消费者的购物行为进行推荐,具有非常好的实用性;
附图说明
图1是本发明流程图。
具体实施方式
参见图1,本实施例中,一种基于双重自动编码器的半监督跨领域文本分类方法是按如下步骤进行:
步骤1:初始化
步骤1.1:获取源领域的文本数据集合
步骤1.2:获取目标领域的文本数据集合
在学习特征表示时,需要利用源领域中文本数据的标签信息来获取更高质量的特征表示。具体实施时,同时也需要目标领域中文本数据的标签信息,由于源领域中文本数据标签已知而目标领域中文本数据的标签是未知,需要利用支持向量机在源领域文本数据上训练分类器并对目标领域中文本数据进行分类;具体实施过程如步骤1.3所示;
步骤1.3:基于源领域的文本数据集合ds利用支持向量机进行训练,得到源领域的分类器;利用源领域的分类器对目标领域的文本数据集合dt进行分类,得到目标领域的文本数据的伪标签集合
步骤1.4:将源领域的文本数据集合ds和目标领域的文本数据集合dt中所有文本数据进行合并,得到合并集合x,x=[x1,x2,…,xa,…,xa],xa为合并集合x中第a个文本数据,a=1,2,…,a,且a=ns+nt;
步骤1.5:根据源领域的文本数据的样本标签集合ys和目标领域的文本数据的伪标签集合yt,将源领域的文本数据集合ds和目标领域的文本数据集合dt中的属于同一类别的文本数据划分为一类,从而得到包含nc个类的数据集,其中第d个类别cd的数据集,记为ed=[dsd,dtd];dsd为源领域的文本数据集合ds中,样本标签属于第d个类别cd的所有文本数据;dtd为目标领域的文本数据集合dt中,伪标签属于第d个类别cd的所有文本数据;
步骤2:利用基于自适应分布的边缘降噪自动编码方法对合并集合x进行lmax层堆叠学习,获得源领域的文本数据集合ds和目标领域的文本数据集合dt的全局特征表示:
在学习两个领域中文本数据的全局特征表示时,直接将源领域数据集合ds和目标领域数据集合dt中的样本数据放在一起训练,充分挖掘两个领域间所有特征之间的潜在关系。为了进一步获取高质量的全局特征表示,利用了源领域文本数据的标签信息和目标领域文本数据的伪标签信息来最小化领域间的边缘分布和条件分布。具体实施时,在目标函数中添加了边缘分布和条件分布这两个约束项来学习映射矩阵。
步骤2.1:定义当前堆叠学习的层数为l;并初始化l=1;定义最大堆叠学习的层数为lmax;
步骤2.2:将合并集合x的第l层的输入记为hl-1,当l=1,令hl-1=x;
步骤2.3:以噪音干扰系数p对第l层的输入hl-1进行随机损坏,得到损坏数据
步骤2.4:利用式(1)表征第l层的重构误差θ(wl):
式(1)中,λ,β为常数,||·||2表示矩阵的frobenius范数的平方,
式(2)中,tr(·)为矩阵的迹,(·)t为矩阵(·)的转置,
式(3)中,(·)αδ表示矩阵的第α行第δ列元素;xα和xδ分别表示合并集合x中第α个文本数据和第δ个文本数据;
式(4)中,
式(5)中,(·)ηκ表示矩阵的第η行第κ列元素,xη和xκ分别表示合并集合x中第η个文本数据和第κ个文本数据;
步骤2.5:利用最小二乘法对重构误差θ(wl)进行求解,得到
式(6)中,(·)mu表示矩阵的第m行第u列元素;
式(7)中,(·)μν表示矩阵的第μ行第ν列元素;
步骤2.6:获得第l层的输出特征空间hl=tanh(hl-1wl),其中,tanh()为双曲正切函数;
步骤2.7:将l+1赋值给l,并判断l>lmax是否成立,若成立,则表示得到获得源领域的文本数据集合ds和目标领域的文本数据集合dt的全局特征表示
步骤3:利用基于多类别的边缘降噪自动编码方法学习对第d个类别cd的数据集ed进行lmax层堆叠学习,获得源领域的文本数据集合ds和和目标领域的文本数据集合dt的局部特征表示:
在学习局部特征表示时,利用源领域中文本数据的标签信息和目标领域中文本数据的伪标签信息,将属于同一类别的源领域中样本和目标领域中样本单独放在一起训练,以减少其它类别的数据对这个类别的影响。同时在学习局部特征表示时,在目标函数中添加了最大均值差异(mmd)约束项来进一步减小源领域和目标领域中文本数据的分布差异。
步骤3.1:初始化l=1;
步骤3.2:将数据集ed的第l层的输入记为
步骤3.3:以噪音干扰系数p对第l层的输入
步骤3.4:利用式(8)表征第d个类别cd的数据集ed的第l层的重构误差
式(8)中,
式(9)中,
式(10)中,
步骤3.5:利用最小二乘法对重构误差
式(11)中,(·)θρ表示矩阵的第θ行第ρ列元素;
式(12)中,(·)υψ表示矩阵的第υ行第ψ列元素;
步骤3.6:获得第d个类别cd的数据集ed第l层的输出特征空间
步骤3.7:将l+1赋值给l,并判断l>lmax是否成立,若成立,则表示得到获得源领域的文本数据集合ds和目标领域的文本数据集合dt的局部特征表示
步骤4:获取双重特征表示并构建分类器:
步骤4.1:将源领域和目标领域文本数据的全局特征表示hglobal和局部特征表示hlocal进行合并,形成双重特征表示h=[hglobal;hlocal];
将双重特征表示h划分为源领域的文本数据集合ds的特征表示hds和目标领域的文本数据集合dt的特征表示hdt;
步骤4.2:基于源领域的文本数据集合ds的特征表示hds利用支持向量机进行训练,得到源领域的特征表示的分类器;利用源领域的特征表示的分类器对目标领域的文本数据集合dt的特征表示hdt进行分类,得到目标领域的文本数据的新伪标签集合yt′;
步骤4.3:判断||yt-yt′||2≤1是否成立,若成立,则所得到的新伪标签集合yt′即为目标领域的文本数据的分类结果;否则,将yt′赋值给yt后,返回步骤1.3顺序执行;
本发明使用两种不同类型的自动编码器用于学习源领域中文本数据和目标领域中文本数据的全局特征表示和局部特征表示,并引入源领域中文本数据的标签信息来优化特征表示,以此来进一步缩小源领域和目标领域中文本数据的分布差异,能更好的捕捉源领域和目标领域中文本数据中特征之间的关系,从而能够提高文本分类的正确性。
- 还没有人留言评论。精彩留言会获得点赞!