一种抽取式与生成式相结合的公文摘要生成模型的制作方法
本发明涉及一种抽取式与生成式相结合的公文摘要生成模型,属于自然语言处理技术领域。
背景技术:
大量的政府公文文本数据的存在使得人们针对性的检索和查阅变得十分困难,庞大的信息使得人们在浏览阅读时花费大量时间。因此,如何通过自动化的方法快速从大量公文信息中提取关键内容,解决信息过载的问题,成为了一个迫切的需求,自动公文摘要技术是其中一个可行有效的解决方案。
文本摘要技术按照生成摘要类型可分为抽取式摘要和生成式摘要。前者是将原文中的句子按照一定的方法来进行重要性排序,将重要性最高的前n个句子作为摘要;后者是通过挖掘更深层次的语义信息,对原文中心思想进行转述、概括而生成摘要。然而生成式算法模型的训练需要大量的人工标注数据,在人力、财力和时间有限的情况下,生成式算法的应用收到了一定的限制,本发明提出了一种将抽取式和生成式摘要相结合的公文摘要生成方法有效的解决了这个问题。
技术实现要素:
为解决上述技术问题,本发明提供了一种抽取式与生成式相结合的公文摘要生成模型,该抽取式与生成式相结合的公文摘要生成模型对公文数据进行预先处理,使用抽取式摘要模型产生弱标签摘要数据a,并对弱标签摘要数据a进行语义增强,利用基于seq2seq+attention机制的生成式摘要模型进行训练,使所生成的公文摘要更准确的表征文本的语义含义。
本发明通过以下技术方案得以实现。
本发明提供的一种抽取式与生成式相结合的公文摘要生成模型;首先筛选公文内容,去除公文摘要噪声数据,并对处理后的数据进行清洗、预处理,然后采用抽取式摘要模型生成弱标签数据集a,其次通过摘要连贯性和增加高置信度样本数的方式增强弱标签数据集a的质量,最后采用弱标签数据集a训练生成式摘要模型,获取公文摘要生成模型。
具体包括以下步骤:
①公文内容筛选:从公文数据语料中,对公文内容进行筛选,去除公文中的公文摘要噪声数据;
②数据清洗、预处理:对筛选后的公文进行文本预处理和清洗,获取文本数据,将文本数据进行预处理分词,再利用训练好的政务领域专用word2vec模型将分词后的词语表示成词向量;
③抽取式摘要模型:将词向量融合表示成句子向量,并将句子向量输入抽取式摘要模型,获取每个句子在公文中的重要性,选取重要性最大的句子作为抽取式摘要模型生成的弱标签摘要数据a;
④弱标签摘要数据a语义增强:对弱标签摘要数据a进行数据增强,增强摘要句子之间的语义连贯性,筛选去除抽取式摘要模型中置信度较小的样本;
⑤生成式摘要模型:将弱标签摘要数据a以及公文数据语料输入生成式摘要模型,并采用步骤①及步骤②的方法对公文数据语料进行处理;
⑥公文摘要:训练步骤⑤中的生成式摘要模型,获取公文摘要生成模型。
所述步骤①中,公文摘要噪声数据包括表格、具体叙述条文、名单列表,并采用正则匹配的方式去除公文中的表格、名单列表、具体叙述条文与公文正文之间的空白行。
所述步骤②中,文本预处理和清洗为:去除筛选后的公文中的数字、网络字符以及特殊字符。
所述步骤⑤中,生成式摘要模型采用基于seq2seq+attention机制的方法生成公文摘要序列。
所述seq2seq由基于lstm的编码器和解码器组成,并采用attention机制来增大重要信息权重。
所述步骤②分为以下步骤:
(2.1)采用正则匹配的方式去除筛选后的公文中的数字、网络字符以及特殊字符;
(2.2)根据政务领域的特征构建政务领域停用词表及分词表,并采用jieba分词对公文数据进行分词;
(2.3)将步骤(2.1)中的公文进行政务领域词向量模型训练,获取政务领域专用word2vec模型;
(2.4)利用训练好的政务领域专用word2vec模型将分词后的词语表示成词向量。
所述步骤③分为以下步骤:
(3.1)将每个句子中的词向量相加取平均,得到句子向量,采用余弦相似度的方法,获取公文中句子与句子之间的相似度;
(3.2)输入句子相似度矩阵,使用抽取式摘要模型,采用textrank算法,获取到每个句子在公文中的重要度,选取重要度高的句子作为抽取式摘要模型的弱标签摘要数据a。
所述步骤④中,对弱标签摘要数据a采用正则匹配的方式去除弱标签摘要数据a中的数字、网络字符以及特殊字符,并利用连接词词典,增加句子的语义连贯性,对弱标签摘要数据a进行增强。
所述步骤⑤分为以下步骤:
(5.1)采用步骤①及步骤②的方法对公文数据进行处理;
(5.2)编码器对于输入的公文正文句子,用一个双向lstm网络进行编码,其中在embedding部分使用政务领域专用word2vec词向量模型进行向量化表示;
(5.3)解码器采用单向lstm网络模型,在每个时刻输入的公文数据语料由前一时刻的输出、前一时刻隐藏状态以及编码器产生的语义向量组成,输出为公文摘要序列;
(5.4)将步骤(5.1)~(5.3)中的数据输入生成式摘要模型。
本发明的有益效果在于:通过将抽取式摘要和生成式摘要相结合,对公文数据进行筛选与预处理,同时增强了抽取式摘要生成的弱标签数据的语义含义,学习了一个公文文本摘要自动生成模型来实现公文摘要的自动生成,相对于传统的基于端到端并加入注意力机制的摘要生成方法,本方法解决了缺少训练数据的问题,并针对公文数据的特征进行了数据筛选与语义增强,从而能够更准确的表征公文文本的语义含义。
附图说明
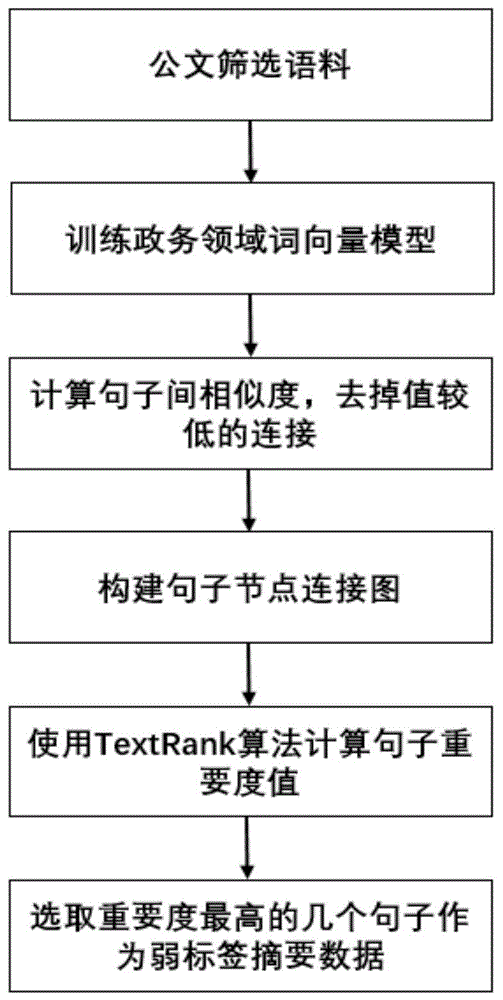
图1是本发明分析抽取式摘要模型的流程图;
图2是本发明基于编码器、解码器结构以及引入注意力机制的生成式摘要模型结构示意图;
图3是本发明的流程图。
具体实施方式
下面进一步描述本发明的技术方案,但要求保护的范围并不局限于所述。
如图3所示,一种抽取式与生成式相结合的公文摘要生成模型;首先筛选公文内容,去除公文摘要噪声数据,并对处理后的数据进行清洗、预处理,然后采用抽取式摘要模型生成弱标签数据集a,其次通过摘要连贯性和增加高置信度样本数的方式增强弱标签数据集a的质量,最后采用弱标签数据集a训练生成式摘要模型,获取公文摘要生成模型。
具体包括以下步骤:
①公文内容筛选:从公文数据语料中,对公文内容进行筛选,去除公文中的公文摘要噪声数据;
②数据清洗、预处理:对筛选后的公文进行文本预处理和清洗,获取文本数据,将文本数据进行预处理分词,再利用训练好的政务领域专用word2vec模型将分词后的词语表示成词向量;
③抽取式摘要模型:将词向量融合表示成句子向量,并将句子向量输入抽取式摘要模型,获取每个句子在公文中的重要性,选取重要性最大的句子作为抽取式摘要模型生成的弱标签摘要数据a,如图1所示;
④弱标签摘要数据a语义增强:对弱标签摘要数据a进行数据增强,增强摘要句子之间的语义连贯性,筛选去除抽取式摘要模型中置信度较小的样本;
⑤生成式摘要模型:将弱标签摘要数据a以及公文数据语料输入生成式摘要模型,并采用步骤①及步骤②的方法对公文数据语料进行处理;
⑥公文摘要:训练步骤⑤中的生成式摘要模型,获取公文摘要生成模型。
所述步骤①中,公文摘要噪声数据包括表格、具体叙述条文、名单列表,并采用正则匹配的方式去除公文中的表格、名单列表、具体叙述条文与公文正文之间的空白行。
所述步骤②中,文本预处理和清洗为:去除筛选后的公文中的数字、网络字符以及特殊字符。
所述步骤⑤中,生成式摘要模型采用基于seq2seq+attention机制的方法生成公文摘要序列,如图2所示,其中x为输入序列,h为编码隐状态,h为解码隐状态,c为语义编码向量,y为输出序列,eos为标识符。
所述seq2seq由基于lstm的编码器和解码器组成,并采用attention机制来增大重要信息权重。
进一步地,关于attention机制在生成式摘要模型中的作用;在编码阶段,编码器将输入编码成一个向量序列,在解码阶段,每一时刻都选择性的从向量序列中挑选一个子集进行处理,因此在产生输出时能充分利用输入序列携带的信息。
所述步骤②分为以下步骤:
(2.1)采用正则匹配的方式去除筛选后的公文中的数字、网络字符以及特殊字符;
(2.2)根据政务领域的特征构建政务领域停用词表及分词表,并采用jieba分词对公文数据进行分词;
(2.3)将步骤(2.1)中的公文进行政务领域词向量模型训练,获取政务领域专用word2vec模型;
(2.4)利用训练好的政务领域专用word2vec模型将分词后的词语表示成词向量。
所述步骤③分为以下步骤:
(3.1)将每个句子中的词向量相加取平均,得到句子向量,采用余弦相似度的方法,获取公文中句子与句子之间的相似度;
(3.2)输入句子相似度矩阵,使用抽取式摘要模型,采用textrank算法,获取到每个句子在公文中的重要度,选取重要度高的句子作为抽取式摘要模型的弱标签摘要数据a。
所述步骤④中,对弱标签摘要数据a采用正则匹配的方式去除弱标签摘要数据a中的数字、网络字符以及特殊字符,并利用连接词词典,增加句子的语义连贯性,对弱标签摘要数据a进行增强。
所述步骤⑤分为以下步骤:
(5.1)采用步骤①及步骤②的方法对公文数据进行处理;
(5.2)编码器对于输入的公文正文句子,用一个双向lstm网络进行编码,其中在embedding部分使用政务领域专用word2vec词向量模型进行向量化表示;
(5.3)解码器采用单向lstm网络模型,在每个时刻输入的公文数据语料由前一时刻的输出、前一时刻隐藏状态以及编码器产生的语义向量组成,输出为公文摘要序列;
(5.4)将步骤(5.1)~(5.3)中的数据输入生成式摘要模型。
进一步地,本发明首先对公文进行筛选处理,并进行文本预处理,再使用抽取式摘要方法生成弱标签摘要数据a,将弱标签摘要数据a进行语义增强,最后利用基于生成式摘要模型进行训练,对于新公文文本,利用训练后获取的公文摘要生成模型生成摘要。
具体的,本发明针对基于深度学习的文本摘要生成方法需要大量人工标注数据而带来的巨大人力物力和时间成本问题,通过数据增强的方式作为弱标签摘要数据a,以辅助基于深度学习端到端文本摘要生成模型的参数微调训练。
综上所述,本发明通过训练一个公文摘要,自动生成公文摘要生成模型,其生成的公文摘要不局限于公文文本中的词,能生成语义更通顺的公文摘要;在实际应用中,可以简略清晰地描述公文的主要内容,达到提高工作效率的目的,有效解决了生成式公文摘要和生成算法中缺少标注数据训练的问题,同时又避免了抽取式方法导致的摘要信息片段化、歧义化的问题。
- 还没有人留言评论。精彩留言会获得点赞!