基于汉字结构的文字点选验证码识别与填入方法与流程
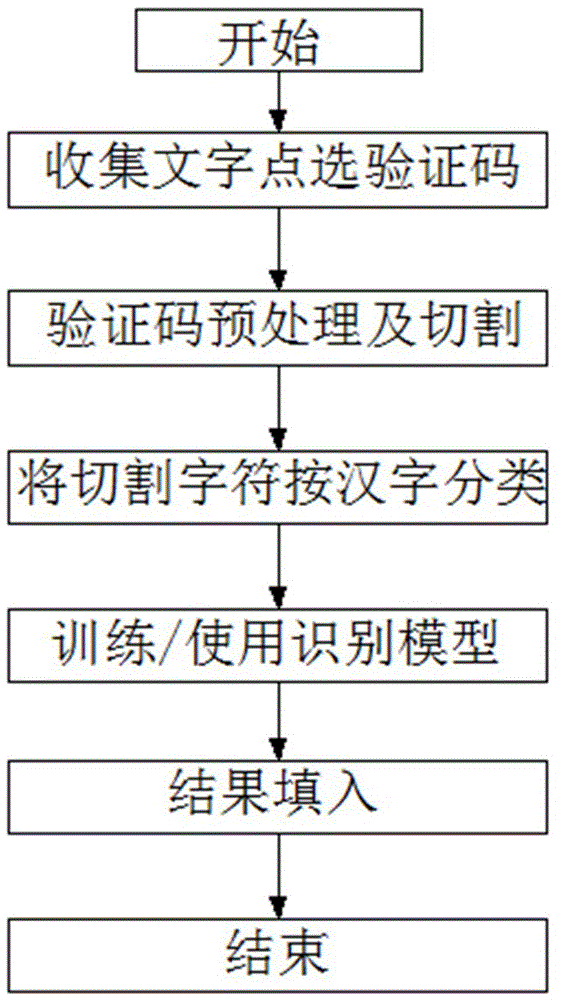
本发明涉及一种基于汉字结构的文字点选验证码识别与填入方法,属于验证码识别技术领域。
背景技术:
文字点选验证码目前常见的一般为两类,一类在验证码图片之外提示需要点选的文字及顺序,称为非语义类点选;另一类则未提示,需要根据语义顺序进行点选,通常为成语、美食、风景等中文词组,称为语义类点选。
传统的文字点选验证码识别过程,一般基于每个汉字整理并训练分类模型。具体操作过程如图1所示,首先将收集到的文字点选验证码进行去噪、二值化等预处理,并进行切割;在切割成单个汉字后,会给每个汉字一个唯一数值标签以标识类别,相同的汉字具有相同的标签,达到将汉字分类目的;在样本按标签分类整理好后,利用深度学习cnn等算法进行训练得到模型,从而可以应用于新样本预测;对于未能正确预测部分在结果填入时采用随机方式返回结果。
但由于汉字数量很大,据不完全统计信息,目前汉字的总数已经超过了8万,常用的约有3500字。因此,如果按一个类别大概需要50张样本,按常见汉字则需要人工收集近20万张样本,如果有更多汉字需要收集样本则数量更多,可谓极为耗费人力及时间成本;且可能由于背景复杂,单纯识别模型结合随机算法较容易导致识别准确率低。
技术实现要素:
为了解决上述现有技术中存在的问题,本发明提供一种基于汉字结构的文字点选验证码识别与填入方法,利用汉字结构特征,采用结合识别模型及形体结构及偏旁部首的汉字检索匹配算法,极大降低所需样本,从而大幅节省人力时间成本。
本发明的技术方案如下:
技术方案一
基于汉字结构的文字点选验证码识别与填入方法,包括以下步骤:
配置语义类词组库,收集语义类中文词组加入语义类文字库中,供检索使用;
配置结构化汉字库,收集汉字添加至所述结构化汉字库,并对单个汉字添加结构标签,供检索使用;
获取点选填入值,采集包含文字点选的验证码图片,通过目标检测算法检测所述验证码图片中的存在汉字的区域,并返回存在汉字的区域坐标,通过每个汉字的区域坐标对所述验证码图片进行切割,生成单个汉字图片,记录各所述汉字图片的区域坐标作为文字点选的填入值;
创建识别模型,将每个汉字分类并采用深度学习算法进行调优训练得到识别模型,用于预测汉字;
预测汉字,调用识别模型,输入各所述汉字图片至识别模型内进行识别预测,得到各所述汉字图片中的预测汉字;
将得到的各所述预测汉字,输入所述语义类词组库和结构化汉字库进行检索匹配,并进行加权综合评定,得到目标汉字填入顺序;
根据得到的目标汉字填入顺序及各所述汉字图片的区域坐标,在验证码验证窗口中自动点选验证码并提交。
进一步的,所述对单个汉字添加结构标签具体为:
对单个汉字添加形体结构标签以及偏旁部首标签,其中所述形体结构标签包括左右结构、上下结构、左中右结构、上中下结构、半包围结构、全包围结构以及镶嵌结构。
进一步的,所述将各所述预测汉字,输入所述语义类词组库和结构化汉字库进行检索匹配,并进行加权综合评定,得到目标汉字填入顺序,包括对语义类验证码的加权综合评定以及对非语义类验证码的加权综合评定;
所述对语义类验证码的加权综合评定具体为:
将各所述预测汉字,输入所述语义类词组库中进行检索,得到与各所述预测汉字相关的词组,舍弃字数与所述文字点选验证码图片中汉字字数不同的词组,等到一个或一个以上的备选结果;
将各所述预测汉字以及所述备选结果,输入所述结构化汉字库进行检索,得到各所述预测汉字的形体结构和偏旁部首以及备选结果中汉字的形体结构和偏旁部首;
根据各所述预测汉字的形体结构和偏旁部首以及各所述备选结果中汉字的形体结构和偏旁部首的匹配关系,加权综合评定得到目标汉字词组,从而得到目标汉字的填入顺序;
所述对非语义类验证码的加权综合评定具体为:
将各所述预测汉字以及非语义类验证码提示的目标结果汉字,输入所述结构化汉字库进行检索,得到各所述预测汉字的形体结构和偏旁部首以及非语义类验证码提示的目标结果汉字的形体结构和偏旁部首;
根据各所述预测汉字的形体结构和偏旁部首以及非语义类验证码提示的目标结果汉字的形体结构和偏旁部首的匹配关系,修正各所述预测文字,得到目标汉字的填入顺序。
进一步的,所述目标检测算法采用fasterr-cnn或yolo算法;所述深度学习算法采用cnn算法。
技术方案二
基于汉字结构的文字点选验证码识别与填入设备,包括存储器和处理器,所述存储器存储有指令,所述指令适于由处理器加载并执行以下步骤:
配置语义类词组库,收集语义类中文词组加入语义类文字库中,供检索使用;
配置结构化汉字库,收集汉字添加至所述结构化汉字库,并对单个汉字添加结构标签,供检索使用;
获取点选填入值,采集包含文字点选的验证码图片,通过目标检测算法检测所述验证码图片中的存在汉字的区域,并返回存在汉字的区域坐标,通过每个汉字的区域坐标对所述验证码图片进行切割,生成单个汉字图片,记录各所述汉字图片的区域坐标作为文字点选的填入值;
创建识别模型,将每个汉字分类并采用深度学习算法进行调优训练得到识别模型,用于预测汉字;
预测汉字,调用识别模型,输入各所述汉字图片至识别模型内进行识别预测,得到各所述汉字图片中的预测汉字;
将得到的各所述预测汉字,输入所述语义类词组库和结构化汉字库进行检索匹配,并进行加权综合评定,得到目标汉字填入顺序;
根据得到的目标汉字填入顺序及各所述汉字图片的区域坐标,在验证码验证窗口中自动点选验证码并提交。
进一步的,所述对单个汉字添加结构标签具体为:
对单个汉字添加形体结构标签以及偏旁部首标签,其中所述形体结构标签包括左右结构、上下结构、左中右结构、上中下结构、半包围结构、全包围结构以及镶嵌结构。
进一步的,所述将各所述预测汉字,输入所述语义类词组库和结构化汉字库进行检索匹配,并进行加权综合评定,得到目标汉字填入顺序,包括对语义类验证码的加权综合评定以及对非语义类验证码的加权综合评定;
所述对语义类验证码的加权综合评定具体为:
将各所述预测汉字,输入所述语义类词组库中进行检索,得到与各所述预测汉字相关的词组,舍弃字数与所述文字点选验证码图片中汉字字数不同的词组,等到一个或一个以上的备选结果;
将各所述预测汉字以及所述备选结果,输入所述结构化汉字库进行检索,得到各所述预测汉字的形体结构和偏旁部首以及备选结果中汉字的形体结构和偏旁部首;
根据各所述预测汉字的形体结构和偏旁部首以及各所述备选结果中汉字的形体结构和偏旁部首的匹配关系,加权综合评定得到目标汉字词组,从而得到目标汉字的填入顺序;
所述对非语义类验证码的加权综合评定具体为:
将各所述预测汉字以及非语义类验证码提示的目标结果汉字,输入所述结构化汉字库进行检索,得到各所述预测汉字的形体结构和偏旁部首以及非语义类验证码提示的目标结果汉字的形体结构和偏旁部首;
根据各所述预测汉字的形体结构和偏旁部首以及非语义类验证码提示的目标结果汉字的形体结构和偏旁部首的匹配关系,修正各所述预测文字,得到目标汉字的填入顺序。
进一步的,所述目标检测算法采用fasterr-cnn或yolo算法;所述深度学习算法采用cnn算法。
本发明具有如下有益效果:
1、本发明通过配置语义类词组库和结构化汉字库,利用语义类词组的固有语序以及汉字形体结构及偏旁部首的特征,对识别模型识别出的预测汉字进行加权综合评定,极大降低所需样本,从而大幅节省人力时间成本。
2、本发明将形体结构标签划分为汉字形体结构的七大类,能够更细致的划分汉字的结构。
3、本发明在识别语义类点选验证码时,得到预测汉字后,先输入至语义类词组库中进行检索匹配,得到一个或多个备选结果,再输入至结构化汉字库进行检索匹配,得到预测汉字的形体结构,通过预测汉字的形体结构与备选结果的形体结构进行匹配对比,从而精确得到实际目标结果。在识别非语义类点选验证码时,能够直接解析目标结果的形体结构,从而能够将预测汉字的形体结构与目标结果的形体结构直接进行匹配对比,较于随机返回的准确率得到较大程度提升。
附图说明
图1为现有技术的文字点选验证码识别过程;
图2为本发明实施例的文字点选验证码识别过程;
图3为一文字点选验证码的示例图;
图4为本发明实施例中备选结果的形体结构和偏旁部首表;
图5为本发明实施例中预测汉字的形体结构和偏颇部首表;
图6为本发明实施例中预测汉字的语义类词组检索表。
具体实施方式
下面结合附图和具体实施例来对本发明进行详细的说明。
实施例一
参见图2,基于汉字结构的文字点选验证码识别与填入方法,包括以下步骤:
配置语义类词组库,收集语义类中文词组(如:庖丁解牛、胆固醇、非物质文化遗产等)加入语义类文字库中,供检索使用。
配置结构化汉字库,收集汉字添加至所述结构化汉字库,并对单个汉字添加结构标签,供检索使用。
获取点选填入值,采集包含文字点选的验证码图片,通过目标检测算法检测所述验证码图片中的存在汉字的区域,并返回存在汉字的区域坐标,通过每个汉字的区域坐标对所述验证码图片进行切割,生成单个汉字图片,记录各所述汉字图片的区域坐标作为文字点选的填入值;如图3所示,图3为一语义类点选验证码的图片,图片中的语义类词组为庖丁解牛,通过目标检测算法,得到庖、丁、解、牛四个字的图片和区域坐标,各汉字的区域坐标作为最终点选时的填入值。
创建识别模型,将每个汉字分类并采用深度学习算法进行调优训练得到识别模型,用于预测汉字。
预测汉字,调用识别模型,输入各所述汉字图片至识别模型内进行识别预测,得到各所述汉字图片中的预测汉字;如图3所示,通过识别模型,分别识别庖、丁、解、牛四个字的图片,得到预测汉字。
将得到的各所述预测汉字,输入所述语义类词组库和结构化汉字库进行检索匹配,并进行加权综合评定,得到目标汉字填入顺序。
根据得到的目标汉字填入顺序及各所述汉字图片的区域坐标,在验证码验证窗口中自动点选验证码并提交。
本实施例通过配置语义类词组库和结构化汉字库,利用语义类词组的固有语序以及汉字形体结构及偏旁部首的特征,对识别模型识别出的预测汉字进行加权综合评定,极大降低所需样本,从而大幅节省人力时间成本。
实施例二
进一步的,所述对单个汉字添加结构标签具体为:
对单个汉字添加形体结构标签以及偏旁部首标签,其中所述形体结构标签包括左右结构(如:指、细、汉)、上下结构(如:要、志、苗)、左中右结构(如:谢,树,御)、上中下结构(如:高、黄、萤)、半包围结构(如:句、庙、建)、全包围结构(如:围、团、圆)以及镶嵌结构(如:坐、爽、夹)。
进一步的,所述将各所述预测汉字,输入所述语义类词组库和结构化汉字库进行检索匹配,并进行加权综合评定,得到目标汉字填入顺序,包括对语义类验证码的加权综合评定以及对非语义类验证码的加权综合评定。
所述对语义类验证码的加权综合评定具体为:
将各所述预测汉字,输入所述语义类词组库中进行检索,得到与各所述预测汉字相关的词组,舍弃字数与所述文字点选验证码图片中汉字字数不同的词组,等到一个或一个以上的备选结果。
将各所述预测汉字以及所述备选结果,输入所述结构化汉字库进行检索,得到各所述预测汉字的形体结构和偏旁部首以及备选结果中汉字的形体结构和偏旁部首。
根据各所述预测汉字的形体结构和偏旁部首以及各所述备选结果中汉字的形体结构和偏旁部首的匹配关系,加权综合评定得到目标汉字词组,从而得到目标汉字的填入顺序。
参见图3至图6,假设图3中的庖、丁、解、牛四个汉字图片经识别模型识别后得到病、丁、触、牛四个预测汉字;具体参见图6,,先将病、丁、触、牛四个汉字输入到语义类词组库进行检索匹配,得到四个汉字相关的词组,并排除字数不为四的词组,经检索可以得出庖丁解牛出现了两次,所以庖丁解牛为备选结果。具体参见图4和图5,再将病、丁、触、牛四个预测汉字以及庖、丁、解、牛四个备选结果中的汉字,输入到结构化汉字库进行检索,得到四个预测汉字和四个备选结果中的汉字的形体结构和偏旁部首,如(病-左上包围-疒、触-左右-角)。进行加权综合评定,预测汉字与实际目标汉字不同的两个字为“触”和“病”,由于“解”和“触”的结构和偏旁都一致,匹配度很高;“庖”和“病”结构一致但偏旁部首不一致,也具有一定的匹配度,且庖丁解牛在语义类词组库检索时出现了两次,因此针对此例可以判定识别模型得到的预测汉字“触”实际为“解”,预测汉字“病”实际为“庖”;另假设“庖”识别为“包”,即结构和偏旁部首都不一致,但由于“解”和“触”具有较高的匹配关系,因此仍能得到正确的结果。
所述对非语义类验证码的加权综合评定具体为:
将各所述预测汉字以及非语义类验证码提示的目标结果汉字,输入所述结构化汉字库进行检索,得到各所述预测汉字的形体结构和偏旁部首以及非语义类验证码提示的目标结果汉字的形体结构和偏旁部首。
根据各所述预测汉字的形体结构和偏旁部首以及非语义类验证码提示的目标结果汉字的形体结构和偏旁部首的匹配关系,修正各所述预测文字,得到目标汉字的填入顺序。
因为在非语义类点选验证码会提示的一个目标结果,结合结构和偏旁能从结构化汉字库中检索出的一个或多个备选结果,从而进行加权综合评定得到修正的结果,相较于随机返回的准确率得到较大程度提升;且在样本相对较少时,识别错误(往往识别为形近字)也能通过此方法进一步提升少样本时的准确率。
进一步的,所述目标检测算法采用fasterr-cnn或yolo算法;所述深度学习算法采用cnn算法。
本实施例不仅具备实施例一的有益效果,进一步的,提出了具体的实施方法;形体结构标签划分为汉字形体结构的七大类,能够更细致的划分汉字的结构。在识别语义类点选验证码时,得到预测汉字后,先输入至语义类词组库中进行检索匹配,得到一个或多个备选结果,再输入至结构化汉字库进行检索匹配,得到预测汉字的形体结构,通过预测汉字的形体结构与备选结果的形体结构进行匹配对比,从而精确得到实际目标。在识别非语义类点选验证码时,能够直接解析目标结果的形体结构,从而能够将预测汉字的形体结构与目标结果的形体结构直接进行匹配对比,较于随机返回的准确率得到较大程度提升。
实施例三
参见图2,基于汉字结构的文字点选验证码识别与填入方法,包括以下步骤:
配置语义类词组库,收集语义类中文词组(如:庖丁解牛、胆固醇、非物质文化遗产等)加入语义类文字库中,供检索使用。
配置结构化汉字库,收集汉字添加至所述结构化汉字库,并对单个汉字添加结构标签,供检索使用。
获取点选填入值,采集包含文字点选的验证码图片,通过目标检测算法检测所述验证码图片中的存在汉字的区域,并返回存在汉字的区域坐标,通过每个汉字的区域坐标对所述验证码图片进行切割,生成单个汉字图片,记录各所述汉字图片的区域坐标作为文字点选的填入值;如图3所示,图3为一语义类点选验证码的图片,图片中的语义类词组为庖丁解牛,通过目标检测算法,得到庖、丁、解、牛四个字的图片和区域坐标,各汉字的区域坐标作为最终点选时的填入值。
创建识别模型,将每个汉字分类并采用深度学习算法进行调优训练得到识别模型,用于预测汉字。
预测汉字,调用识别模型,输入各所述汉字图片至识别模型内进行识别预测,得到各所述汉字图片中的预测汉字;如图3所示,通过识别模型,分别识别庖、丁、解、牛四个字的图片,得到预测汉字。
将得到的各所述预测汉字,输入所述语义类词组库和结构化汉字库进行检索匹配,并进行加权综合评定,得到目标汉字填入顺序。
根据得到的目标汉字填入顺序及各所述汉字图片的区域坐标,在验证码验证窗口中自动点选验证码并提交。
本实施例通过配置语义类词组库和结构化汉字库,利用语义类词组的固有语序以及汉字形体结构及偏旁部首的特征,对识别模型识别出的预测汉字进行加权综合评定,极大降低所需样本,从而大幅节省人力时间成本。
实施例四
进一步的,所述对单个汉字添加结构标签具体为:
对单个汉字添加形体结构标签以及偏旁部首标签,其中所述形体结构标签包括左右结构(如:指、细、汉)、上下结构(如:要、志、苗)、左中右结构(如:谢,树,御)、上中下结构(如:高、黄、萤)、半包围结构(如:句、庙、建)、全包围结构(如:围、团、圆)以及镶嵌结构(如:坐、爽、夹)。
进一步的,所述将各所述预测汉字,输入所述语义类词组库和结构化汉字库进行检索匹配,并进行加权综合评定,得到目标汉字填入顺序,包括对语义类验证码的加权综合评定以及对非语义类验证码的加权综合评定。
所述对语义类验证码的加权综合评定具体为:
将各所述预测汉字,输入所述语义类词组库中进行检索,得到与各所述预测汉字相关的词组,舍弃字数与所述文字点选验证码图片中汉字字数不同的词组,等到一个或一个以上的备选结果。
将各所述预测汉字以及所述备选结果,输入所述结构化汉字库进行检索,得到各所述预测汉字的形体结构和偏旁部首以及备选结果中汉字的形体结构和偏旁部首。
根据各所述预测汉字的形体结构和偏旁部首以及各所述备选结果中汉字的形体结构和偏旁部首的匹配关系,加权综合评定得到目标汉字词组,从而得到目标汉字的填入顺序。
参见图3至图6,假设图3中的庖、丁、解、牛四个汉字图片经识别模型识别后得到病、丁、触、牛四个预测汉字;具体参见图6,先将病、丁、触、牛四个汉字输入到语义类词组库进行检索匹配,得到四个汉字相关的词组,并排除字数不为四的词组,经检索可以得出庖丁解牛出现了两次,所以庖丁解牛为备选结果。具体参见图5,再将病、丁、触、牛四个预测汉字以及庖、丁、解、牛四个备选结果中的汉字,输入到结构化汉字库进行检索,得到四个预测汉字和四个备选结果中的汉字的形体结构和偏旁部首,如(病-左上包围-疒、触-左右-角)。进行加权综合评定,预测汉字与实际目标汉字不同的两个字为“触”和“病”,由于“解”和“触”的结构和偏旁都一致,匹配度很高;“庖”和“病”结构一致但偏旁部首不一致,也具有一定的匹配度,且庖丁解牛在语义类词组库检索时出现了两次,因此针对此例可以判定识别模型得到的预测汉字“触”实际为“解”,预测汉字“病”实际为“庖”;另假设“庖”识别为“包”,即结构和偏旁部首都不一致,但由于“解”和“触”具有较高的匹配关系,因此仍能得到正确的结果。
所述对非语义类验证码的加权综合评定具体为:
将各所述预测汉字以及非语义类验证码提示的目标结果汉字,输入所述结构化汉字库进行检索,得到各所述预测汉字的形体结构和偏旁部首以及非语义类验证码提示的目标结果汉字的形体结构和偏旁部首。
根据各所述预测汉字的形体结构和偏旁部首以及非语义类验证码提示的目标结果汉字的形体结构和偏旁部首的匹配关系,修正各所述预测文字,得到目标汉字的填入顺序。
因为在非语义类点选验证码会提示的一个目标结果,结合结构和偏旁能从结构化汉字库中检索出的一个或多个备选结果,从而进行加权综合评定得到修正的结果,相较于随机返回的准确率得到较大程度提升;且在样本相对较少时,识别错误(往往识别为形近字)也能通过此方法进一步提升少样本时的准确率。
进一步的,所述目标检测算法采用fasterr-cnn或yolo算法;所述深度学习算法采用cnn算法。
本实施例不仅具备实施例三的有益效果,进一步的,提出了具体的实施方法;形体结构标签划分为汉字形体结构的七大类,能够更细致的划分汉字的结构。在识别语义类点选验证码时,得到预测汉字后,先输入至语义类词组库中进行检索匹配,得到一个或多个备选结果,再输入至结构化汉字库进行检索匹配,得到预测汉字的形体结构,通过预测汉字的形体结构与备选结果的形体结构进行匹配对比,从而精确得到实际目标。在识别非语义类点选验证码时,能够直接解析目标结果的形体结构,从而能够将预测汉字的形体结构与目标结果的形体结构直接进行匹配对比,较于随机返回的准确率得到较大程度提升。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!