一种基于监控视频的运动目标提取方法与流程
本发明属于视频监控技术领域,具体涉及一种基于监控视频的运动目标提取方法。
背景技术:
视频监控是一种直观有效的记录、观察场景情况的重要手段,其中运动目标提取是分析视频监控的关键步骤,是当前研究的重点。其主要算法有基于像素的算法:根据像素分布规律构建概率模型,从而估计运动区域。但在建模中,需提供大量像素样品,人工成本较大;基于区域的算法:根据区域纹理特征的一致性,减小了照明对运动目标和背景的影响,但面对微小变化和特征不明显的运动目标区域检测效果不佳;基于图像帧的算法:根据光线变化规律构建全局模型对运动目标进行检测,但光线变化复杂多变,难以构建统一模型。
技术实现要素:
针对现有技术中存在的不足,本发明的目的在于,提供一种基于监控视频的运动目标提取方法,解决现有技术无法满足检测精度和效率的技术问题。
为了解决上述技术问题,本申请采用如下技术方案予以实现:
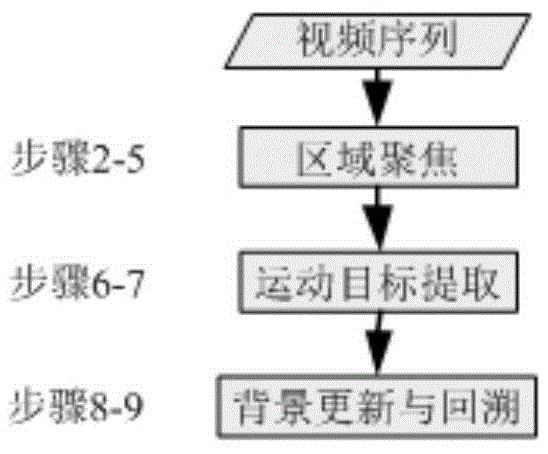
一种基于监控视频的运动目标提取方法,包括以下步骤:
步骤1,输入图像序列{a1,...,an,...,an},an表示第n帧图像,对an构建混合高斯模型,根据an的混合高斯模型得到an中的初步疑似运动区域集合arn,
步骤2,设背景帧图像序列为{b1,...,bn,...,bn},bn表示第n帧背景图像;
步骤3,令n=1,b1=a1;
步骤4,通过式(1)得到an中的疑似运动区域集合dn,
式(1)中,tn为分割阈值;
其中,agn(x,y)表示an的灰度图像,bgn(x,y)表示bn的灰度图像;
步骤5,遍历dn中每个疑似运动区域进行数学形态学操作,得到an中的初步运动区域集合drn,
步骤6,通过式(2)计算
式(2)中,
步骤7,通过式(3)得到an中的运动区域;
式(3)中,
步骤8,设当n=k时,通过式(4)更新第k帧背景图像,得到更新后的第k帧背景图像bk={bk,1,bk,2...bk,h};
式(4)中,
步骤9,根据更新后的第k帧背景图像bk,获取第k帧图像ak之前的所有帧图像{a1,...,al,...,ak-1}更新前的运动区域序列{cr1′,...,crl′,...,crk′-1},将
步骤10,n=n+1,bn=bn-1,重复步骤4至步骤9,直至n=n,即得到图像序列{a1,...,an,...,an}中的运动区域序列{cr1,...,crn,...,crn},其中
进一步地,步骤1中所述对an构建混合高斯模型,根据an的混合高斯模型得到an中的初步疑似运动区域arn,包括:
步骤11,构建式(1)所示的混合高斯模型;
式(1)中,g表示高斯模型的个数,η表示高斯概率密度函数,ωi,n表示第n帧图像对第i个高斯模型权值,ui,n表示第n帧图像对第i个高斯模型均值,∑i,n表示第n帧图像对第i个高斯模型协方差矩阵;
步骤12,根据混合高斯模型,更新第n帧图像对第i个高斯模型权值ωi,n;
ωi,n=(1-α)ωi,n-1+α(mi,n)(2)
式(2)中,α是学习因子;mi,n是第n帧图像像素与第i个高斯模型匹配程度,
步骤13,根据式(3)选取b个高斯模型构建背景模型bb;
式(3)中,t为预设阈值;
步骤14,根据背景模型bb,通过式(4)得到初步运动区域每个像素点an(x,y)的像素值arn(x,y);
将an中像素值arn(x,y)为1的像素点所组成的区域作为初步疑似运动区域集合arn。
本发明与现有技术相比,有益的技术效果是:
1.本发明将gmm与帧差法相融合,可实现目标静止、运动等不确定因数条件下,运动目标提取。
2.本发明建立重新回溯体系,可实现复杂背景下,重建纯背景。
3.本发明建立局部更新体系,平均处理速度快,达到0.35帧/s.
附图说明
图1是本发明方法的流程图;
图2是类型1的处理效果图;
图3是类型2的处理效果图;
图4是类型3的处理效果图;
图5是roi分析图;
以下结合附图和实施例对本发明的具体内容作进一步详细解释说明。
具体实施方式
以下给出本发明的具体实施例,需要说明的是本发明并不局限于以下具体实施例,凡在本申请技术方案基础上做的等同变换均落入本发明的保护范围。
实施例:
本实施例给出一种基于监控视频的运动目标提取方法,包括以下步骤:
步骤1,输入图像序列{a1,...,an,...,an},an表示第n帧图像,对an构建混合高斯模型,根据an的混合高斯模型得到an中的初步疑似运动区域集合arn,将arn中的一个连通区域作为一个初步运动区域
包括:
步骤11,构建式(1)所示的混合高斯模型;
式(1)中,k表示高斯模型的个数,η表示高斯概率密度函数,ωi,n表示第n帧图像对第i个高斯模型权值,ui,n表示第n帧图像对第i个高斯模型均值,∑i,n表示第n帧图像对第i个高斯模型协方差矩阵;
步骤12,根据混合高斯模型,更新第n帧图像对第i个高斯模型权值ωi,n;
ωi,n=(1-α)ωi,n-1+α(mi,n)(2)
式(2)中,α是学习因子;
mi,n是第n帧图像像素与第i个高斯模型匹配程度,
步骤13,根据式(3)选取b个高斯模型构建背景模型bb;
式(3)中,t为预设阈值;
步骤14,根据背景模型bb,通过式(4)得到初步运动区域每个像素点an(x,y)的像素值arn(x,y);
将an中像素值arn(x,y)为1的像素点所组成的区域作为初步疑似运动区域arn。
通过式(4)可得,像素值为1的区域为初步运动区域集合,像素值为1的区域中的连通区域即为一个初步运动区域。
步骤2,设背景帧图像序列为{b1,...,bn,...,bn},bn表示第n帧背景图像;
步骤3,令n=1,b1=a1;
步骤4,通过式(1)得到an中的疑似运动区域集合dn,
式(5)中,tn为分割阈值;
其中,agn(x,y)表示an的灰度图像,bgn(x,y)表示bn的灰度图像;
通过式(1)中可得像素值为1的区域即为疑似运动区域集合,将像素值为1的区域中的连通区域作为疑似运动区域。
步骤5,遍历dn中每个疑似运动区域进行数学形态学操作,得到an中的初步运动区域集合drn,
步骤6,通过式(2)计算
式(2)中,
步骤7,通过式(3)得到an中的运动区域;
式(3)中,
步骤8,设当n=k时,通过式(4)更新第k帧背景图像,得到更新后的第k帧背景图像bk={bk,1,bk,2...bk,h};
式(4)中,
步骤9,根据更新后的第k帧背景图像bk,获取第k帧图像ak之前的所有帧图像{a1,...,al,...,ak-1}更新前的运动区域序列{cr1′,...,crl′,...,cr′k-1}。将
步骤10,n=n+1,bn=bn-1,重复步骤4至步骤9,直至n=n,即得到图像序列{a1,...,an,...,an}中的运动区域序列{cr1,...,crn,...,crn},其中
实验验证:
类型1:开始没有运动目标,然后目标一直运动。
类型2:开始目标运动,然后目标停留很长时间。
类型3:开始目标静止,然后目标运动。由于高斯混合模型为渐进学习过程,所以实验中选取视频前10帧图像予以学习。
本发明对类型1的处理效果如图2所示,通过高斯混合模型聚焦至运动区域,得到运动目标大致区域,但是不能有效提取局部变化不大的点,需要修补,然后将帧差法提取结果与高斯混合模型提取结果相融合精确的提取出运动目标{cr50}1,重建背景b50。
本发明对类型2的处理效果如图3所示,通过高斯混合模型聚焦至运动区域,随着时间的推移,前景像素点会逐步转化为背景像素点。通过本方案的算法精确提取运动目标{cr100}1,重建背景b100。随着时间进一步推移,最终前景运动区域全部湮没在背景中,但计算机无法确定该区域为目标长时间停留所致,还是停留在背景图像中,需要背景更新。通过本方案的算法精确提取运动目标{cr1000}1,重建背景b1000。
本发明对类型3的处理效果如图4所示,由于高斯混合模型的算法,前景背景转化是一个渐进学习过程,会出现拖尾现象。计算机无法确定该区域为目标长时间停留所致,还是停留在背景图像中,需要背景更新。通过本方案的算法精确提取运动目标{cr1000}1,重建背景b1000。在此基础上,通过背景回溯去除拖尾现象,得到运动目标{cr100}1,重建背景b100。
统计roi分布情况如图5所示。可知a816出现大量roi,对比a815与a816,可知a816出现虚化,从侧面证明该算法可以有效检测细微的变化。
综上所述本发明可以在目标长时间滞留、小幅度运动等诸多复杂条件下,对运动目标提取和背景重建。
依据分割精度和处理时间对本发明提出方法与主流算法对比。采用面积交迭度(areaoverlapmeasure,aom)作为分割效果的评价指标。其定义为:
其中,aom为面积交迭度,υ为人工标记的运动区域,ν为算法分割出的运动区域,s(·)表示对应区域的像素点数,aom取值越大表明分割效果越好。检测结果如表1所示。
表1aom和平均时间统计
根据上表可知,对于目标一直运动的情况,基于像素的低秩的算法,判断背景与运动目标,分割精度高,但该算法需对所有像素点进行计算,平均处理时间长。而基于帧的算法,仅考虑整体信息,处理时间快,但精度不高。而本文提出的基于格式塔原理的运动目标提取与背景重建算法,虽然在平均处理时间上略逊与帧的算法,在目标一直运动的情况下分割精度略逊于像素的算法,但从总体效果和在目标运动后,长时间停止和目标起始停止,后运动的情况,精度对比主流算法均有大幅度提高。
- 还没有人留言评论。精彩留言会获得点赞!