用于可持续交通网络设计的多属性决策软件的制作方法
技术领域:
本发明采用r语言编写了一种用于可持续交通网络设计的多属性决策软件,属于交通工程技术领域。
背景技术:
交通系统在可持续发展中发挥着关键作用,因此,可持续城市交通最近已成为一个重要的研宄领域。可持续交通系统通常以三个方面为特征:经济、环境和社会。然而,现有的交通研究只关注一个或最多两个维度[1]。仅有少部分的研究同时考虑到所有三个维度。需要注意的是,在三个维度的每个维度下可能会有多种测量方法。例如,经济维度除了系统的总出行时间之外,还可以包括消费者剩余,网络备用能力,总投资成本,总收费收入等。此外,安全也是可持续性的重要指标。然而,它在可持续交通中被忽视了很长一段时间,这是非常奇怪的。事实上,交通安全受到交通系统各个阶段的影响,包括规划、设计、施工和运营。考虑到交通网络设计对形成交通系统的深刻影响,在网络设计阶段应充分重视交通安全。所谓主动交通安全规划就是指在网络设计阶段的交通安全审查,以提前提高交通系统的安全水平。鉴于交通安全对可持续发展的重要性,本软件将其视为可持续交通的第四个维度并纳入到综合评价中。
虽然对一个或两个维度进行了广泛的研宄,但很少有人讨论三个维度,更不用说四个维度。由于有许多关于两个可持续维度的研宄,因此这里没有对它们进行回顾,只总结了对三个维度的研究。chen和xu[2]在交通网络设计问题的双层目标规划框架中考虑了三个目标:效率、环境和公平。其中,公平是一种主要的社会维度测度方法。yin等[3]提出了一个双层目标规划模型,以解决道路收费定价和通行能力投资问题,其中考虑了以下三个维度:经济、环境和公平。feng和timmermans[4]在环境容量约束下处理了机动性和公平性之间的取舍。li和ge[5]提出了一种用于交通信号配时设计的双层规划模型,其中上层是一个具有公平约束的多目标规划问题,即最大化网络备用能力并最小化总交通排放。szeto等[1]也提出了一个多目标双层优化模型,以考虑道路网络设计中的三个维度,包括经济、环境和社会。wang等[6]提出了一个具有随机需求的可持续交通网络设计的双层规划模型,其中上层是最大化网络备用能力问题,并带有排放和公平的机会约束。sun等[7]提出一个多目标双层规划模型,以确定在效率、环境和公平方面的最佳拥堵定价。
与可持续交通的传统的三个维度相比,安全性很少被考虑进来。yang等[8]提出了一种双层规划模型,通过路段速度限制设计出有效、安全和环保的交通系统。haas和bekhor[9]构建了一个交通网络设计的双目标双层规划模型,用于最小化系统总出行时间和最大化道路安全水平。其中,安全性能表现是一个负二项式模型,其侧重于对路段上交通事故数的估计。possel等[10]定义一个用于交通网络设计问题的多目标双层优化模型,以最小化交通尾气排放、交通事故总数和总出行时间。文中对于每种类型的路段都有一定的事故率,将事故率乘以一天内路段上行驶的车辆总里程数(vmt)即可得到该路段的交通事故数。对此数值在所有路段上求和,即可确定交通网络的安全级别。
尽管已经提出了关于可持续交通系统的规划、设计、管理、操作和控制的各种措施,但交通网络设计问题(ndp)是最广泛应用的一个。它旨在有效利用有限的资源(如土地和投资)来优化交通系统的性能,同时将出行者的行为反应(例如目的地选择、交通方式选择、路线选择和出发时间选择)明确考虑到设计方案中。在现有的软件中,交通网络设计的主要目标是减轻交通拥堵,即最小化总出行时间或最大化网络备用能力,而未能充分考虑可持续性的其他维度以及它们之间的相互冲突。
参考文献:
[1]szetowy,jiangy,wangdzw,sumaleea.asustainableroadnetworkdesignproblemwithlandusetransportationinteractionovertime[j].netwspat.econ,2015,15(3):791-822
[2]chena,xux.goalprogrammingapproachtosolvingnetworkdesignproblemwithmultipleobjectivesanddemanduncertainty[j].expertsystemswithapplications,2012,39(4):4160-4170
[3]yiny,lizc,lamwhk,choik.sustainabletollpricingandcapacityinvestmentinacongestedroadnetwork:agoalprogrammingapproach[j].j.transp.eng,2014,140(12):10
[4]fengt,timmermanshjp.trade-offsbetweenmobilityandequitymaximizationunderenvironmentalcapacityconstraints:acasestudyofanintegratedmulti-objectivemodel[j].transp.res.pt.c-emerg.technol,2014,43:267-279
[5]lizc,gexy.trafficsignaltimingproblemswithenvironmentalandequityconsiderations[j].j.adv.transp,2014,48(8):1066-1086
[6]wangh,lamwhk,zhangxn,shnoh.sustainabletransportationnetworkdesignwithstochasticdemandsandchanceconstraints[j].internationaljournalofsustainabletransportation,2015,9(2):126-144
[7]sunx,liuzy,thompsonrg,bieym,wengjx,chensy.amulti-objectivemodelforcordon-basedcongestionpricingschemeswithnonlineardistancetolls[j].journalofcentralsouthuniversity,2016,23(5),1273-1282
[8]yangyn,luhp,yinyf,yangh.optimizationofvariablespeedlimitsforefficient,safe,andsustainablemobility[j].transportationresearchrecord,2013(2333):37-45
[9]haasi,bekhors.networkdesignproblemconsideringsystemtimeminimizationandroadsafetymaximization:formulationandsolutionapproaches[j].transportmetricaa,2017,13(9):829-851
[10]posselb,wismansljj,vanberkumec,bliemermcj.themulti-objectivenetworkdesignproblemusingminimizingexternalitiesasobjectives:comparisonofageneticalgorithmandsimulatedannealingframework[j].transportation,2018,45(2):545-572
技术实现要素:
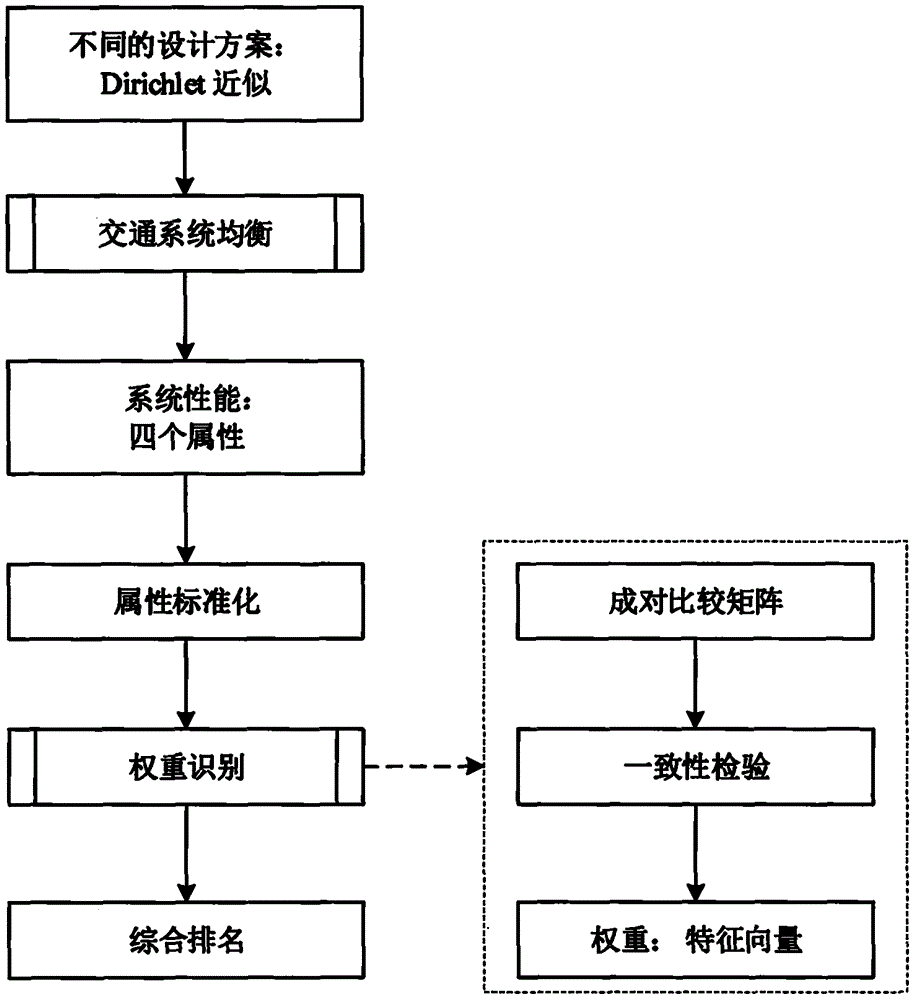
技术问题:当前的交通网络设计软件至少存在三个问题。首先,在可持续交通中安全维度很少被考虑到。在本软件中,使用公路安全手册(hsm)的安全性能函数来测量路段和路网的安全性能。其次,下层的模型通常是用于交通流分配的用户均衡模型,这是相当局限的,因为出行者的决策行为包括交通发生、交通分布、交通方式划分和交通流分配。因此,本软件采用了一种带反馈的四阶段模型,以实现下层的交通系统均衡,从而充分表现出行者的决策行为。最后,多目标双层模型的复杂性是众所周知的。为了解决所提出的双层模型,本软件在dirichlet分布,权重递减的连续平均法(msa),frank-wolfe算法和dijkstra算法的基础上,设计了多属性决策(madm)方法。
技术方案:本发明使用r语言编写了一种用于可持续交通网络设计的多属性决策软件,该软件具体包括以下步骤:
(一)总体算法设计
步骤一:上层政策制定者使用dirichlet分布生成一个随机的交通网络通行能力提升方案δc,方案编号m=0,下层出行者作出一系列行为反应;
步骤二:下层模型是交通产生、交通分布、交通方式划分和交通流分配的顺序模型,通过反馈迭代达到交通系统平衡,可以计算出平衡状态时的路段交通流量和通行时间;
步骤三:计算交通系统平衡时可持续交通的四个属性值:
经济属性
环境属性
社会属性
安全属性;
步骤四:返回步骤一,使用dirichlet分成另外一个随机的交通网络通行能力提升方案δc,方案编号m=m+1,当方案数目达到预先定义的m(m≥200)时,即m=m时,停止循环,转到步骤五;
步骤五:使用多属性决策方法找出最优的交通网络设计方案。
(二)步骤二的具体计算过程
步骤二是交通系统平衡,也是双层模型中的下层模型。对于上层的每个设计方案,都有一个对应的下层平衡状态。算法流程图如图2所示,详细的计算过程如下:
步骤1:从dirichlet分布dir(α)得到通行能力提升模式δc;
步骤2:通过均匀分布初始化交通分布矩阵
步骤3:通过frank-wolfe算法基于用户均衡将交通分布矩阵分配给交通网络,以计算每个路段a上的交通流量和出行时间,之后,起点i和目的地j之间的最短出行时间,即
步骤4:基于
步骤5:利用权重递减的msa对交通分布矩阵
步骤6:使用相对根平方误差(rrse)检查交通分布矩阵的收敛性
如果满足收敛条件,则转步骤8,否则转步骤7;
步骤7:令n=n+1,然后通过frank-wolfe算法基于用户均衡将交通分布矩阵
步骤8:输出交通分布矩阵
(三)步骤三的具体计算过程
步骤1:经济属性,以总出行时间(ttt)计算
其中a是网络上的路段集合;ta是路段a上的出行时间,以分钟为单位;va是路段a上的流量,以pcu/h为单位。
步骤2;环境属性,以车辆总co排放(tco)计算
其中ea(va)表示路段a中标准车当量(pcu)的co污染量。下面的宏观函数是具有代表性的一个函数,常用于估算基于路段的车辆co排放:
其中la,ta和ea分别以千米,分钟和克每小时为单位。
步骤3:公平属性,以道路通行能力增强之前和之后o-d出行时间的最大比率来定义空间公平:
其中πw(δc)和πw(0)是在实施网络设计方案δc之后和之前o-d对w的最小出行时间;w是o-d对的集合。
步骤4:安全属性,根据公路安全手册(hsm)中建议的安全性能函数得到路段交通事故数:
spfa=[β1×(va/ca)2+β2×(va/ca)+β3]×va×la×365×10-8
其中,spfa表示每年路段a的平均每小时事故数(acc);va是路段a的平均每小时交通量(pcu/h);la是路段a的长度(km);ca是路段a上的实际路段通行能力(pcu/h);并且β1,β2和β3是可以使用交通调查数据校准的参数。因此,所有路段交通事故的总和可用作网络安全的度量如下:
(四)步骤五的具体计算过程
步骤1:计算每个方案下交通系统均衡的四个属性,即经济,环境,社会和安全;
步骤2:由于属性的量纲不同,它们必须在整合之前进行标准,对于数值越大越好的属性,标准化公式是
其中yij是模式i的属性j的值;
步骤3:采用特征向量法确定属性的权重wj;
步骤4:网络设计方案i的综合得分是
步骤5:在计算出所有的m个得分之后,可以对网络设计方案进行排序,并且可以选择得分最高的网络设计,这就是最佳设计。
(五)程序设计
#用于可持续交通网络设计的多属性决策软件:双层模型与算法
#步骤1:初始化,按格式输入数据和必要的包;
#1.1加载计算最短路径的包,准备调用dijkstra最短路径算法,注意igraph包首次使用需要安装,然后才能调用;
#install.packages(″igraph″)#安装igraph包
library(igraph)
options(digits=3)
#1.2创建图的距离矩阵,包含所有的候选路段,第一列为路段标号(road),第二列为路段起点标号(roadorigin),第三列为路段终点标号(roaddestination),第四列为该路段自由流时间(freeflowtime),第五列为道路通行能力(capacity),第六列为道路长度(length),此处以交通配流中常用的nguyen-dupuis网络为例,详细的参数设置可参考程序文档;
#也可以在excel中复制,然后执行
#e=read.delim(″clipboard″,header=f)
e=matrix(c(1,1,5,7.0,900,4.00,2,1,12,9.0,700,4.00,3,4,5,9.0,700,4.00,4,4,9,12.0,900,7.00,5,5,6,3.0,800,2.00,6,5,9,9.0,600,4.00,7,6,7,5.0,900,4.00,8,6,10,13.0,500,8.00,9,7,8,5.0,300,4.00,10,7,11,9.0,400,5.00,11,8,2,9.0,700,5.00,12,9,10,10.0,700,6.00,13,9,13,9.0,600,5.00,14,10,11,6.0,700,4.00,15,11,2,9.0,700,5.00,16,11,3,8.0,700,4.00,17,12,6,7.0,300,4.00,18,12,8,14.0,700,9.00,19,13,3,11.0,700,6.00),ncol=6,byrow=t)
colnames(e)=c(″road″,″roadorigin″,″roaddestination″,″freetime″,″roadcapacity″,″roadlength″)
#e#用于检查程序的断点
#1.3输入初始交通需求矩阵d0,第一列为起讫点对的标号(odpair),第二列为起点标号(origin),第三列为终点标号(destination),第四列为交通需求(demand);
tge=3000#总的现状交通需求
d0=matrix(c(1,1,2,0.2*tge,2,1,3,0.4*tge,3,4,2,0.3*tge,4,4,3,0.1*tge),ncol=4,byrow=t)#初始分配方案
colnames(d0)=c(″odpair″,″origin″,″destination″,″demand″)
#d0#用于检查程序的断点
#自定义的frank-wolfe算法函数,注意输入的需求矩阵d形式如d0,交通网络e的形式如上面的e,相对误差0.001;
fw=function(e,d)
{
#1.4根据路径自由流时间计算各个od对的最短路径和路径流量
g=add.edges(graph.empty(13),t(e[,2:3]),weight=e[,4])#创建图,13为节点的个数,以时间为权重而非路径的长度
b12=get.shortest.paths(g,from=″1″,to=″2″,mode=″out″,output=″epath″)$epath[[1]]#从起点1到终点2的最短路径
b13=get.shortest.paths(g,from=″]″,to=″3″,mode=″out″,output=″epath″)$epath[[1]]#从起点1到终点3的最短路径
b42=get.shortest.paths(g,from=″4″,to=″2″,mode=″out″,output=″epath″)$epath[[1]]#从起点4到终点2的最短路径
b43=get.shortest.paths(g,from=″4″,to=″3″,mode=″out″,output=″epath″)$epath[[1]]#从起点4到终点3的最短路径
#创建一个矩阵,用于保存各个od对的最短路径和流量
v=cbind(e[,1])
st0=numeric(4)#存放初始的各od对最短行驶时间
colnames(v)=″road″
v
#od对12的最短路径和流量
sp12=as.vector(b12)#转化为路段标号(road)
st0[1]=sum(e[sp12,4])#各路段时间求和
x12=cbind(e[sp12,1],rep(d[1,4],length(sp12)))#路段标号和流量,算法中的迭代起点
colnames(x12)=c(″road″,″v12″)
x12
v=merge(v,x12,by=″road″,all=true)#定义v为专门保存迭代起点的矩阵
v[is.na(v)]=0
v
#od对13的最短路径和流量
sp13=as.vector(b13)#转化为路段标号(road)
st0[2]=sum(e[sp13,4])#各路段时间求和
x13=cbind(e[sp13,1],rep(d[2,4],length(sp13)))#路段标号和流量,算法中的迭代起点
colnames(x13)=c(″road″,″v13″)
x13
v=merge(v,x13,by=″road″,all=true)#定义v为专门保存迭代起点的矩阵
v[is.na(v)]=0
v
#od对42的最短路径和流量
sp42=as.vector(b42)#转化为路段标号(road)
st0[3]=sum(e[sp42,4])#各路段时间求和
x42=cbind(e[sp42,1],rep(d[3,4],length(sp42)))#路段标号和流量,算法中的迭代起点
colnames(x42)=c(″road″,″v42″)
x42
v=merge(v,x42,by=″road″,all=true)#定义v为专门保存迭代起点的矩阵
v[is.na(v)]=0
v
#od对43的最短路径和流量
sp43=as.vectot(043)#转化为路段标号(road)
st0[4]=sum(e[sp43,4])#各路段时间求和
x43=cbind(e[sp43,1],rep(d[4,4],length(sp43)))#路段标号和流量,算法中的迭代起点
colnames(x43)=c(″road″,″v43″)
x43
v=merge(v,x43,by=″road″,all=true)#定义v为专门保存迭代起点的矩阵
v[is.na(v)]=0
v
#当所有最短路径上的流量求和,得到初始流量
vs=rowsums(v[,seq(ncol(v)-3,ncol(v))])
vs
#步骤2:更新各路段的阻抗
t0=e[,4]#自由流时间
c=e[,5]#道路通行能力
a=0.15
b=4
tp=function(v){
t0*(1+a*(v/c)^b)
}
repeat{
#步骤3:寻找下一个迭代方向
g2=add.edges(graph.empty(13),t(e[,2:3]),weight=tp(vs))#构造图,13为节点的个数,更新路段阻抗
b12=get.shortest.paths(g2,from=″1″,to=″2″,mode=″out″,output=″epath″)$epath[[1]]#从起点1到终点2的最短路径
b13=get.shortest.paths(g2,from=″1″,to=″3″,mode=″out″,output=″epath″)$epath[[1]]#从起点1到终点3的最短路径
b42=get.shortest.paths(g2,from=″4″,to=″2″,mode=″out″,output=″epath″)$epath[[1]]#从起点4到终点2的最短路径
b43=get.shortest.paths(g2,from=″4″,to=″3″,mode=″out″,output=″epath″)$epath[[1]]#从起点4到终点3的最短路径
#创建一个临时矩阵,用于保存各个od对的最短路径和流量
v=cbind(e[,1])
colnames(v)=″road″
v
#od对12的最短路径和流量
sp12=as.vector(b12)#转化为路段标号(road)
x12=cbind(e[sp12,1],rep(d[1,4],length(sp12)))#路段标号和流量,算法中的迭代起点
colnames(x12)=c(″road″,″v12″)
x12
v=merge(v,x12,by=″road″,all=true)#定义v为专门保存迭代起点的矩阵
v[is.na(v)]=0
v
#od对13的最短路径和流量
sp13=as.vector(b13)#转化为路段标号(road)
x13=cbind(e[sp13,1],rep(d[2,4],length(sp13)))#路段标号和流量,算法中的迭代起点
colnames(x13)=c(″road″,″v13″)
x13
v=merge(v,x13,by=″road″,all=true)#定义v为专门保存迭代起点的矩阵
v[is.na(v)]=0
v
#od对42的最短路径和流量
sp42=as.vector(b42)#转化为路段标号(road)
x42=cbind(e[sp42,1],rep(d[3,4],length(sp42)))#路段标号和流量,算法中的迭代起点
colnames(x42)=c(″road″,″v42″)
x42
v=merge(v,x42,by=″road″,all=true)#定义v为专门保存迭代起点的矩阵
v[is.na(v)]=0
v
#od对43的最短路径和流量
sp43=as.vector(b43)#转化为路段标号(road)
x43=cbind(e[sp43,1],rep(d[4,4],length(sp43)))#路段标号和流量,算法中的迭代起点
colnames(x43)=c(″road″,″v43″)
x43
v=merge(v,x43,by=″road″,all=true)#定义v为专门保存迭代起点的矩阵
v[is.na(v)]=0
v
#当所有最短路径上的流量求和,得到迭代方向
vs2=rowsums(v[,seq(ncol(v)-3,ncol(v))])
vs2
#步骤4:计算迭代步长
step=function(lamda){
x2=vs2
x1=vs
q=x1+lamda*(x2-x1)
sum((x2-x1)*tp(q))
}
#lamda=uniroot(step,c(0,1))$root#注意lamda的取值范围,步长不能太长,uniroot要求两端的函数值符号相反,有的函数不一定满足,采用optimize函数可以确保找到一元函数的最优值;
g=function(lamda){step(lamda)^2}
lamda=optimize(g,c(0,1))$minimum
lamda
#步骤5:确定新的迭代起点
vs3=vs+lamda*(vs2-vs)
vs3
#步骤6:收敛性检验
if((sqrt(sum((vs3-vs)^2))/sum(vs))<0.001)break
vs=vs3#如果不满足收敛条件则用新点vs3替代原点vs,如此循环直到收敛
}
#步骤7:输出平衡状态的特征矩阵result和od行驶时间矩阵u;
#步骤7.1:输出平衡状态各路径的流量、通行时间和速度;
result=cbind(e[,1],round(vs,0),tp(vs),e[,6]/(tp(vs)/60),e[,5],round(vs,0)/e[,5])
colnames(result)=c(″road″,″volume″,″time″,″speed″,″roadcapacity″,″levelofservice″)
#步骤7.2:输出各od行驶时间矩阵u;
g=add.edges(graph.empty(13),t(e[,2:3]),weight=result[,3])#创建图,13为节点的个数,result为步骤7生成的矩阵
b12=get.shortest.paths(g,from=″1″,to=″2″,mode=″out″,output=″epath″)$epath[[1]]#从起点1到终点2的最短路径
b13=get.shortest.paths(g,from=″1″,to=″3″,mode=″out″,output=″epath″)$epath[[1]]#从起点1到终点3的最短路径
b42=get.shortest.paths(g,from=″4″,to=″2″,mode=″out″,output=″epath″)$epath[[1]]#从起点4到终点2的最短路径
b43=get.shortest.paths(g,from=″4″,t0=″3″,mode=″out″,output=″epath″)$epath[[1]]#从起点4到终点3的最短路径
#创建一个行驶时间矩阵,用于保存各个od对的行程时间,初始假设各od行程时间为0
u=matrix(c(1,1,2,0,2,1,3,0,3,4,2,0,4,4,3,0),ncol=4,byrow=t)
#od对12的行程时间
sp12=as.vector(b12)#转化为路段标号(road)
u[1,4]=sum(result[sp12,3])#各路段时间求和
#od对13的行程时间
sp13=as.vector(b13)#转化为路段标号(road)
u[2,4]=sum(result[sp13,3])#各路段时间求和
#od对42的行程时间
sp42=as.vector(b42)#转化为路段标号(road)
u[3,4]=sum(result[sp42,3])#各路段时间求和
#od对43的行程时间
sp43=as.vector(b43)#转化为路段标号(road)
u[4,4]=sum(result[sp43,3])#各路段时间求和
u=cbind(u,st0)#od对间无障碍行驶时间st0
#以列表的形式输出result矩阵和od行驶时间矩阵
list(result,u)
}
#fw(e,d0)#用于检查程序的断点
#步骤8:定义目的地选择的多项式logit函数mlogit,输入为各od行驶时间时间矩阵u和各地交通需求sg,输出为新的交通分布矩阵;
mlogit=function(u,sg)
{
d=nuneric(4)
d[1]=sg[1]*exp(-0.1*u[1,4])/(exp(-0.1*u[1,4])+exp(1-0.1*u[2,4]))
d[2]=sg[1]*exp(1-0.1*u[2,4])/(exp(-0.1*u[1,4])+exp(1-0.1*u[2,4]))
d[3]=sg[2]*exp(-0.1*u[3,4])/(exp(-0.1*u[3,4])+exp(1-0.1*u[4,4]))
d[4]=sg[2]*exp(1-0.1*u[4,4])/(exp(-0.1*u[3,4])+exp(1-0.1*u[4,4]))
cbind(u[,1:3],d)
}
#步骤9:定义一个给定交通需求d0和sg及交通网络e下综合的交通分布与交通分配交替迭代平衡函数,对于初始交通分布可以求得用户平衡状态时各od的行驶时间矩阵,用户根据该矩阵重新选择目的地,对于新的交通分布又可以生成新的行驶时间矩阵,该过程一直循环进行,一直到交通分布矩阵不再变化为止;
cda=function(e,d0,sg){
k=3
repeat{
d1=mlogit(fw(e,d0)[[2]],sg)
k=k+1
if(sqrt(sum((d1[,4]-d0[,4])^2))/sum(d0[,4])<0.01)break#满足一定的精度要求就停止
d0[,4]=d0[,4]+(1/k)*(d1[,4]-d0[,4])#这里采用迭代加权法(methodofsuccessiveaverage,msa),此处采用循环次数的倒数作为权重,随着循环次数的增加而减少;
#print(d1)#用于检查程序的断点
#print(k)#用于检查程序
if(k==100)break#如果循环次数达到100次但还没有满足精度要求也跳出循环
}
#print(d1)
d2=fw(e,d1)
#print(d2)
list(d1,d2)
}
#现状交通系统表现,用于政策的before-after比较
ge1=c(sum(d0[1:2,4]),sum(d0[3:4,4]))#用于检查程序的断点
before=cda(e,d0,ge1)[[2]][[2]]#用于检查程序的断点
#步骤10:dirichlet分配法主程序;
#install.packages(″direct″)#安装生成dirichlet的包,首次需要安装,再次不需要
library(direct)#加载包
set.seed(100)#设定随机种子,这样每次生成的同样的随机数
nsd=500#表示dirichilet样本的个数,对于每个进行比较,找出最优的一个
candicate=7#候选路段的数目
rd=rdirichlet(nsd,rep(1,candicate))#生成dirichlet随机分布
inv=2000#投资预算
len=inv*rd/(0.3*c(5,8,2,3,5,5,7))#备选路段通行能力的增加值
st=matrix(numeric(nsd*4),nc=4)#用于存放每个dirichlet方案的4个属性
#下面是用来测量安全性的参数
b1=358.6
b2=-407.7
b3=175.3
#计算程序的开始运行时间!!前面都是在定义函数,并不占用计算时间;
timestart<-sys.time()
for(iin(1:nsd))
{
#i=2#用于检查程序的
#下面是对每一个分配模型构建一个新的网络图e
ren=cbind(c(3,4,5,9,13,16,19),len[i,])#一个更新方案
colnames(ren)=c(″road″,″enhancement″)#和路段编号结合起来
ren2=merge(e,ren,by=″road″,all=true)#合并
ren2[,7][is.na(ren2[,7])]=0#把na用0替换下来,因为na参与计算的结果还是na
ren2[,5]=ren2[,5]+ren2[,7]#与原来的通行能力相加,变成改进后的通行能力
e1=ren2[,1:6]#一个新的网络e1
d3=cda(e1,d0,ge1)#对固定交通需求(1200,800)和交通分布d0调用前面定义的cda函数
#下面求4个属性的值,并存放在st矩阵中
#1.经济属性:出行总时间(分钟)
st[i,1]=d3[[2]][[1]][,2]%*%d3[[2]][[1]][,3]
#2.环境属性:co的排放量
st[i,2]=(0.2038*d3[[2]][[1]][,3]*exp(0.7962*e[,6]/d3[[2]][[1]][,3]))%*%d3[[2]][[1]][,2]
#3.社会属性:政策前后的变化
st[i,3]=max(d3[[2]][[2]][,4]/before[,4])
#4.安全属性:事故个数
st[i,4]=sum((b1*d3[[2]][[1]][,6]^2+b2*d3[[2]][[1]][,6]+b3)*d3[[2]][[1]][,2]*e1[,6]*365*10^(-8))
print(paste(″第″,i,″个方案的4个属性分别是″,round(st[i,],2)))
}
#步骤11:将各属性标准化,这4个属性都是越小越好
zst=st
zst[,1]=(max(st[,1])-st[,1])/(max(st[,1])-min(st[,1]))
zst[,2]=(max(st[,2])-st[,2])/(max(st[,2])-min(st[,2]))
zst[,3]=(max(st[,3])-st[,3])/(max(st[,3])-min(st[,3]))
zst[,4]=(max(st[,4])-st[,4])/(max(st[,4])-min(st[,4]))
#步骤12:计算各属性的权重
a=c(1,1/3,1/2,1/4,3,1,2,1,2,1/2,1,1/2,4,1,2,1)
a=matrix(a,nc=4,byrow=t)
a
a=apply(a,1,prod)
ai=a^(1/4)
w=ai/sum(ai)
w#权重向量
lamda=sum((a%*%w)/w)/4
ci=(lamda-4)/3
cr=ci/0.89
cr#一致性检验
#步骤13:输出各个方案的最终得分
zst%*%w
si=zst%*%w
which.max(zst%*%w)
si[which.max(zst%*%w),]
#步骤14:输出最终需要的结果
ren=cbind(c(3,4,5,9,13,16,19),len[which.max(zst%*%w),])#最优更新方案
colnames(ren)=c(″road″,″enhancement″)#和路段编号结合起来
ren2=merge(e,ren,by=″road″,all=true)#合并
ren2[,7][is.na(ren2[,7])]=0#把na用0替换下来,因为na参与计算的结果还是na
ren2[,5]=ren2[,5]+ren2[,7]#与原来的通行能力相加,变成改进后的通行能力
e1=ren2[,1:6]#最优的网络e
d3=cda(e1,d0,ge1)#对交通需求ge1和交通分布d01调用前面定义的cda函数
#print(st[which.max(zst%*%w),],digits=7)#输出此时网络的4个属性,保留7位小数;
formatc(st[which.max(zst%*%w),],format=′f′,digits=3)
#在formatc()函数中可以用format=参数指定c格式类型,如″d″(整数),″f″′(定点实数),″e″(科学记数法),″e″,″g″(选择位数较少的输出格式),″g″,″fg″(定点实数但用digits指定有效位数),″s″(字符串),可以用width指定输出宽度,用digits指定有效位数(格式为e,e,g,g,fg时)或小数点后位数(格式为f)
write.csv(d3[[1]],file=″交通分布矩阵.csv″)#以csv格式保持到当前工作目录
write.csv(d3[[2]][[1]],file=″路段平衡结果.csv″)
write.csv(d3[[2]][[2]],file=″od出行时间.csv″)
write.csv(ren2,file=″交通网络设计方案.csv″)
getwd()#查看输出文件的保存地址
###计算程序的运行时间
timeend<-sys.time()
runningtime<-timeend-timestart
print(runningtime)#输出运行时间。
有益效果:当前的交通网络设计软件仅包含一个或两个可持续发展的维度,未能全面测度可持续发展。本软件将社会、经济、环境、安全等可持续交通的四个重要维度结合起来,进行交通网络设计。本软件具有较好的有效性和可操作性,对于充分利用有限的交通基础设施投资,设计可持续的交通网络,具有显著的效果。此外,本软件具有以下技术特点:1)开源免费:r语言是开源软件,而交通规划与管理软件多是国外软件,价格昂贵;2)易于操作:国外商业软件普遍界面复杂、应用繁琐,难以为一般的工程师和规划师掌握,而本软件易于操作;3)矩阵算法快捷高效:国外商业软件多采用c语言开发,在进行算法实现时比较低效,采用矩阵语言大大加快了计算过程。
附图说明:
图1是摘要附图。
图2是下层模型的算法流程图
图3是nguyen-dupuis测试网络。
具体实施方式:
本软件使用的硬件环境为inter2.60ghzcpu/4g内存、软件环境为windows8.1/r3.3.3/rstudio,软件使用r3.3.3进行编程。使用如图3所示的nguyen-dupuis交通网络说明具体的实施方式。路段参数包括自由流动出行时间,路段通行能力和路段长度,如表1所示
表1.nguyen-dupuis网络的路段参数
nguyen-dupuis网络中有两个起点区域1和4以及两个目的地区域2和3。假设在峰值时间内起点1和4的交通发生分别为1800pcu/h和1200pcu/h。也就是说,o1=1800pcu/h,o4=1200pcu/h。提升通行能力的候选路段是3、4、5、9、13、16、19。问题是根据四个属性确定最佳的路段通行能力提升模式,以便最好地利用投资预算。利用来自α=(1,1,1,1,1,1,1)的dirichlet分布dir(α)随机生成m=500个投资分配模式,其中它的维度是候选路段的数量。使用预先确定的方程和参数为每个分配模式计算四个可持续属性。
假设路段投资函数是
ga(δca)=0.3×δca×la,a∈a
其中la为以千米为单位的路段长度。因此,对于dirichlet分布的每个实现,将会有
其中,投资预算设定为b=2000。
在下层模型的交通分布中,众所周知,传统的重力模型中不包括许多具有显著解释力的关键变量。其中,最有影响力的是出行者目的地偏好。例如,出行者通常喜欢传统的目的地而不是新开发的地区。因此,本文中目的地选择采用具有出行者偏好的多项式logit模型。为简便起见,反馈过程中的目的地选择模型被简化为
其中βj是出行者对目的地j的偏好,βt是o-d对ij之间的路径出行时间系数。可以使用实证数据校准βj和βt的值。在这里我们设置β2=0、β3=1和βt=-0.1。也就是说,目的地区域2上的出行者偏好是0,而目的地区域3的出行者偏好是1,这意味着出行者通常更喜欢目的地3。出行时间系数是-0.1,这意味着出行时间是负效用。
在下层模型的交通流分配中,本文采用传统的用户均衡方法,该方法将路段性能函数应用于均衡状态中。由美国公路局(bpr)开发的常用路段性能函数如下:
其中ta(va,ca+δca)是具有交通流量va,现有通行能力ca和通行能力提升δca的给定路段a的阻抗函数;
收敛标准相对根平方误差(rrse)设定为0.01,即ε=0.01。通过对每个dirichlet分配模式使用上述参数,可以收敛得到一个稳定的解,这个解具有一致的出行时间/成本和交通分布矩阵。此外,可以使用dijkstra算法计算i和j之间的最短路径出行时间。最终,可以计算出四个可持续属性的值。注意安全属性的计算中使用了参数β1=358.6,β2=-407.7和β3=175.3。
在列出所有m=500个模式的性能表现之后,对其进行标准化。为了确定权重向量,邀请决策者按照表1所示的9级量表完成成对比较矩阵。假设比较矩阵为
其中行名称依次为“经济属性”、“环境属性”、“社会属性”和“安全属性”。比较矩阵的一致性比率(cr)为0.004,小于阈值0.1,因此比较矩阵满足一致性检验并且可以用于确定权重。权重向量是w=(0.10,0.34,0.19,0.37),这意味着政策制定者更注重环境属性和安全属性。每个模式的综合得分可以计算出来。最高得分的就是最佳的路段通行能力提升模式,如表2所示。在此模式中,ttt=116056min、tco=34873g、equity=0.94、safety=28.16acc。
表2.最佳交通网络设计和路段性能
- 还没有人留言评论。精彩留言会获得点赞!