一种基于医学神经机器翻译的解决产生未翻译单词的方法与流程
本发明属于医学翻译技术领域,特别是涉及一种基于医学神经机器翻译的解决产生未翻译单词的方法。
背景技术:
通用机器翻译在大多数情况下不适应于医学领域,因为医学领域有很多医学专业词汇,像药物的名称,某些病毒、细菌的名称或者疾病的名称,可能是通用词而非通用含义,所以在进行翻译时,如果采用通用翻译可能会产生歧义。医学机器翻译不同于通用机器翻译,医学机器翻译有很强的专业性,所以需要使用医学语料来进行训练,这样使得翻译的结果更加专业化,使翻译医学相关的词汇的准确率更高。
医学摘要在进行翻译时要将摘要进行分句处理,模型每次调用一句话进行翻译,在翻译结果中的<unk>处理结束后,处理下一句,以此类推,直至摘要中所有的英文语句都翻译结束,将翻译结果整合成为整段英文的翻译结果并返回给用户。
医学词汇量比较大,进行机器翻译模型训练的语料中所包含的单词数有限,有时会产生未识别的单词,模型会默认返回<unk>(unknown),但是在翻译时译者不能理解<unk>是何含义,可能会误导译者从而产生歧义,因此,医学机器翻译还需要解决<unk>问题。
技术实现要素:
本发明要解决的技术问题是避免翻译结果中出现<unk>(未识别单词),本发明通过解决<unk>问题,能够帮助用户更好的理解翻译结果,使得医学词汇的中文含义更加明确。
本发明的内容为:翻译英文医学摘要并处理医学翻译得到的结果中包含<unk>的问题,包括解决单词含义歧义问题,其实施过程由输入英文语句,调用模型进行翻译,判断是否含有<unk>,处理<unk>,整合翻译结果,返回翻译结果。具体包括如下:
1).接收英文医学摘要:计算机接收译者输入的医学英文摘要;
2).文本预处理:对输入的英文医学摘要采用nltk包进行英文分句,通过nltk中的句子分割器来将英文段落分割成句子组;
3).调用医学翻译模型:翻译程序调用训练好的医学翻译模型,将输入英文语句进行翻译;
4).判断是否含有未识别单词:得到初步翻译结果后,判断翻译结果中是否含有未识别单词,如果含有,则进行未识别单词处理,否则直接返回翻译结果;
未识别单词处理的方法包括:
41).计算未识别单词位置:通过attention机制,计算未识别单词在源语言句子中的位置,返回给程序源单词;
42).处理未识别单词:根据attention机制得到未识别单词的源语言单词位置,根据返回方法,返回结果来帮助翻译提高准确率;
43).整合翻译结果:将未识别单词通过规则查找到的结果替换模型本身翻译的结果中未识别单词的位置作为最终的翻译结果;
44).返回翻译结果:将最终的翻译结果返回给用户。
进一步,方法3)中医学翻译模型的训练过程为:
31).收集训练语料:运行爬虫程序将中华医学期刊网中的所有中英文论文摘要爬取到本地,然后使用nltk包进行中英摘要分句,判断摘要是否是中英文一一对应,如果中英文句子能够对应就作为训练翻译模型的语料;
其中,爬虫程序运行过程为:
3101).先使用python编程语言中的requests包将中华医学期刊网中包含论文id的网页获取到本地;
3102).使用python编程语言中的bs4包将获取到的网页信息处理成python可处理格式,获取到每篇论文的id,将id存储到表格中以备后用;
3103).从表格中获取id,将id与网站ip结合到一起,使用requests包爬取包含每篇论文摘要的网页;
3104).使用bs4包处理含有论文摘要的网页,将中英文摘要分别存储到本地txt中以备后用;
32).训练翻译模型:借助训练程序在收集到的医学语料的基础上进行翻译模型的训练;
具体的训练过程为:
3201).将语料分为训练集、测试集、验证集;
3202).预先定义训练参数,包括学习率为0.1、梯度裁剪为0.1、随机失活为0.2、句子最大词数量为100,然后使用训练集进行训练;
3203).一个阶段的训练结束后训练程序自动调用验证集来进行优化训练参数,使其更符合医学翻译模型的训练;
3204).按照先验经验,步骤3202)、3203)迭代20次训练参数达到最优、得到的训练模型为最优训练模型;
3205).训练程序自动调用测试集进行验证医学翻译模型的泛化能力;
3206).训练结束,得到最终的医学翻译模型。
进一步,方法42)中的返回方法包括方法一:如果单词为大写字母单词,则直接返回原单词。
进一步,方法42)中的返回方法包括方法二:如果不满足方法一,则先进行meddra疾病词典的查询,后续还有加入更多医学专业词典,如果查找得到中文含义,则返回含义替换未识别的单词,meddra词典是自行整理的医学词汇词典,每个英文词汇只有一个中文含义,因为是医学专业词典,所以不需要进行语义消歧。
进一步,方法42)中的返回方法包括方法三:如果不满足方法二,则将未识别单词进行通用词典查询,如果查询到结果而且结果只有一个,则返回中文含义,替换未识别单词;如果查询到的结果有多个中文含义,我们将进行语义消歧,通过整句话的语义来判断该单词在该环境下的含义,根据每个中文含义的概率来决定该未识别单词的含义,如果有多个中文含义的概率相同,则默认选择第一个中文含义为最佳含义;得到中文含义后返回结果。
进一步,方法42)中的返回方法包括方法四:如果方法二和方法三均未查询到中文含义,判断是否含有连词符“-”,如果不含有连词符,则返回源单词作为翻译结果;如果含有连词符,去掉连词符将分开的单词单独进行方法二和方法三的查找,如果找到中文含义,则使用“-”拼接作为源单词的中文含义;如果未找到,则返回源单词作为翻译结果。
附图说明
图1是本发明的模型翻译过程流程图;
图2是本发明的结构图。
具体实施方式
下面结合具体实施例和附图对本发明作进一步的说明。
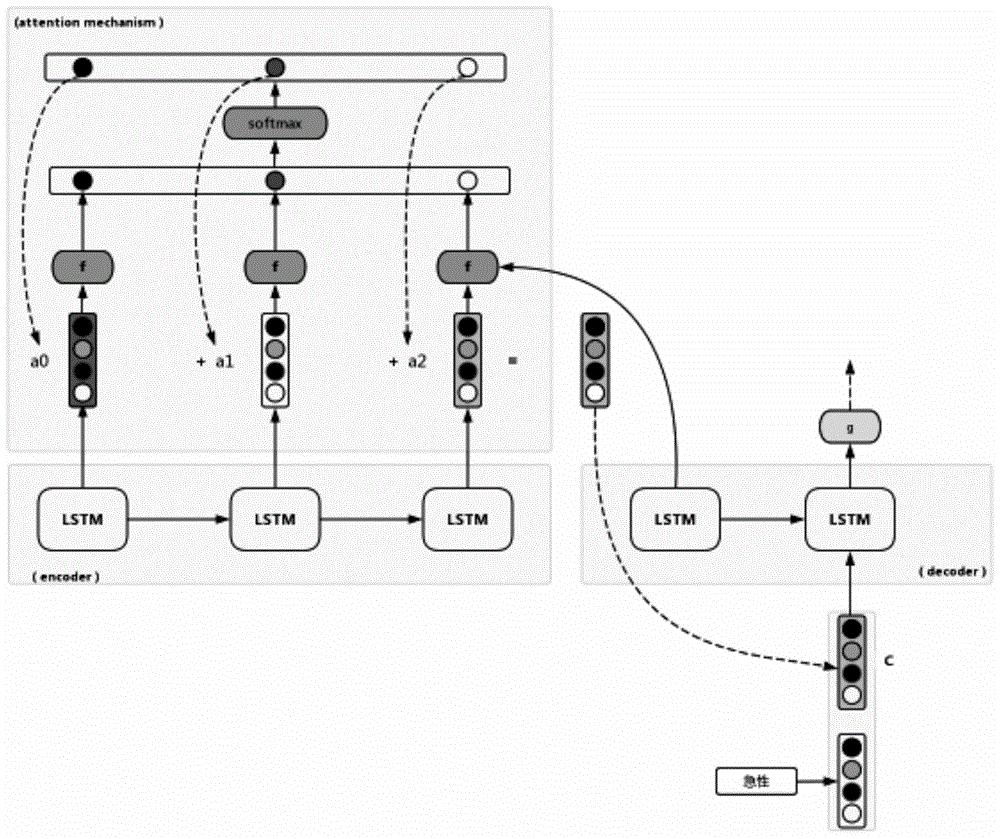
如图1至图2所示,一种基于医学神经机器翻译的解决产生未翻译单词(unk)的方法,其方法包含了最新的神经机器翻译训练方法,以及处理模型翻译所产生未翻译单词而采用的组合方法。所述的基于医学神经机器翻译模型采用医学语料进行训练,其翻译的结果更加偏向于医学领域。所述使用医学语料进行神经机器翻译的方法,再使用多规则的未翻译单词(unk)处理方法,提高了翻译的准确率,在翻译效果方面,更加贴近于医学专业人员翻译。
其中,翻译模型的训练,采用lstm+attention架构,附图中的每个原点代表一个单词,attention机制计算每个源语言单词的权重,权重最大的词的下标作为<unk>所指的源语言单词的位置,在得到翻译结果后,通过判断<unk>的位置得到<unk>在待翻译句子中的源语言单词,我们根据处理<unk>的规则将<unk>进行处理,最大程度的保证了<unk>也能翻译为中文,仅由大写字母组合的单词默认返回原单词,不进行翻译。
本方法具体包括:
输入英文医学摘要:译者将医学英文摘要输入到翻译程序中。
文本预处理:将输入的英文医学摘要进行分句处理。采用的是斯坦福大学推出的nltk包来进行英文分句,使用nltk中的句子分割器来将英文段落分割成句子组。
调用医学翻译模型:翻译程序调用使用自己爬取的医学语料、基于开源fairseq代码进行训练的新的医学领域的专业翻译模型,将输入英文语句进行翻译。
lstm+attention的模型翻译过程简介:
lstm计算隐层状态h的公式为:
ht=lstm(ht-1,[wt-1,ct])
其中,ht代表第t个输出的隐层状态,
计算第t个输入的分数αt′
其中,ht-1代表第t-1个输出的隐层状态,et′代表第t个输入的编码(encoder),
通过softmax函数计算得到平均α:
通过第t个输入的分数αt′的平均值和第t个输入的编码求和计算第t个attention向量
判断是否含有<unk>:得到初步翻译结果后,判断翻译结果中是否含有<unk>单词,如果含有<unk>,则进行<unk>处理,否则直接返回翻译结果。
计算<unk>位置:通过attention机制,计算<unk>在源语言句子中的位置,返回给程序源单词。
处理<unk>:根据attention机制得到<unk>的源语言单词位置,根据返回方法,返回合适的结果来帮助翻译提高准确率。
返回方法包括:
方法一:如果单词为大写字母单词,则直接返回原单词。
方法二:如果不满足方法一,则先进行meddra疾病词典的查询,后续还有加入更多医学专业词典,如果查找得到中文含义,则返回含义替换<unk>,meddra词典是自行整理的医学词汇词典,每个英文词汇只有一个中文含义,因为是医学专业词典,所以不需要进行语义消歧。
方法三:如果不满足方法二,则将<unk>单词进行通用词典查询,如果查询到结果而且结果只有一个,则返回中文含义,替换<unk>;如果查询到的结果有多个中文含义,我们将进行语义消歧,通过整句话的语义来判断该单词在该环境下的含义,根据每个中文含义的概率来决定该<unk>的含义,如果有多个中文含义的概率相同,则默认选择第一个中文含义为最佳含义;得到中文含义后返回结果。
方法四:如果两个词典均未查询到中文含义,判断是否含有连词符“-”,如果不含有连词符,则返回源单词作为翻译结果;如果含有连词符,去掉连词符将分开的单词单独进行方法二,方法三的查找,如果找到中文含义,则使用“-”拼接作为源单词的中文含义;如果未找到,则返回源单词作为翻译结果。
整合翻译结果:将<unk>通过规则查找到的结果替换模型本身翻译的结果中<unk>的位置作为最终的翻译结果;
返回翻译结果:将最终的翻译结果返回给用户。
其中,上述调用医学翻译模型,使用python编程语言编写基于django框架的翻译程序,将调用模型的命令写进程序,每次运行翻译程序时自动进行医学翻译模型的调用;
基于django框架的翻译程序的编写及运行过程为:
a.编写manage.py来进行整个程序的启动控制,程序运行时由manage.py来进行整个翻译程序的运行控制,运行manage.py即可将整个翻译程序运行;
b.将医学神经机器翻译训练得到的模型、django框架调用的通用字典、生物医学字典等翻译程序要用到的数据的路径存储到settings.py中;
c.编写views.py,在django框架的基础上编写程序的运行过程,将调用api的过程、接收用户待翻译的英文摘要、将英文摘要分句、调用医学神经机器翻译模型、查询词典的过程、通过attention查找<unk>单词的位置的过程、以及判断<unk>替换方法、返回给用户翻译结果的过程均以python程序的函数的形式写到views.py中。
d.在程序运行时由manage.py激活views.py的运行,views.py负责在翻译的主要过程以及返回给用户结果的过程。即运行manage.py使整个翻译程序自动运行,以api调用的方法供译者使用。
上述方法中的医学翻译模型的训练过程为:
首先,收集训练语料:使用自己编写的运行爬虫程序将中华医学期刊网中的118个期刊中2005年-2018年的所有中英文论文摘要爬取到本地,然后使用nltk包进行中英摘要分句,判断摘要是否是中英文一一对应,如果中英文句子能够对应就作为训练翻译模型的语料;
其中,爬虫程序运行过程为:
a.先使用python编程语言中的requests包将中华医学期刊网中包含论文id的网页获取到本地;
b.使用python编程语言中的bs4包将获取到的网页信息处理成python可处理格式,获取到每篇论文的id,将id存储到表格中以备后用;
c.从表格中获取id,将id与网站ip结合到一起,使用requests包爬取包含每篇论文摘要的网页;
d.使用bs4包处理含有论文摘要的网页,将中英文摘要分别存储到本地txt中以备后用;
然后,训练翻译模型:借助训练程序(fairseq开源神经机器翻译代码)在收集到的医学语料的基础上进行翻译模型的训练;
具体的训练过程为:
(1).将语料分为训练集、测试集、验证集;
(2).预先定义训练参数,使用训练集进行训练;
参数初步设置值:
根据开源神经机器翻译代码以及监督机器学习算法的定义,我们预先定义神经机器翻译程序的训练参数:
学习率(lr)为0.1、梯度裁剪(clip-norm)为0.1、随机失活(dropout)0.2、句子最大词数量(max-tokens)100;
参数介绍:
学习率(lr):控制着训练程序的收敛速度。
梯度裁剪(clip-norm):为了防止lstm模型在训练的过程中出现梯度爆炸,设置梯度裁剪来进行训练过程的控制。
随机失活(dropout):为了缓解参数过多导致的过拟合现象的发生,在一定程度上起到正则化的作用。
句子最大词数量(max-tokens):进行训练时规定每个句子的长度,如果单词的数量超过100,则将后边的单词忽略。
(3).一个阶段的训练结束后训练程序自动调用验证集来进行优化训练参数,使其更符合医学翻译模型的训练;
(4).按照先验经验,步骤(2)、(3)迭代20次训练参数达到最优、得到的训练模型为最优训练模型;
(5).训练程序自动调用测试集进行验证医学翻译模型的泛化能力;
(6).训练结束,得到最终的医学翻译模型。
本发明的优点为,在现有开源神经机器翻译代码的基础上完成了翻译模型利用医学中英文语料的训练,利用开源词典、专业医学词典查询得到未翻译单词的中文含义同时如果查询词典产生了一词多义的现象,使用语义消歧的方法来选择最适合待翻译语句语境的未翻译单词含义。通过本发明的设计,提高了医学神经机器翻译的准确性,提高了医学语句翻译的专业性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!