一种应用于区域路网的交通事故严重度预测方法与流程
本发明涉及一种应用于区域路网的交通事故严重度预测方法,属于道路交通安全分析技术领域。
背景技术:
据全球道路安全状况报告,道路交通事故是全球第八大死亡原因,造成每年超过135万人死亡,道路交通安全逐渐成为全球都在关注的重大焦点问题。依靠交通事故数据分析来确定影响事故严重度的因素和提出降低死亡事故风险的对策,是目前最实际的交通安全改善措施之一。然而,道路交通事故是涉及各种驾驶员对外部环境反应,以及车辆、道路状况、交通因素和环境因素之间相互作用的复杂事件,可能存在未观测到的事故影响因素,这使得交通事故数据具有高度异质性,而且事故严重度可能受到各因素之间交互作用的影响。
在事故严重度(死亡和非死亡事故)分析方法方面,二元logistic回归模型应用最为广泛。然而,该方法忽略了事故数据的异质性和各自变量之间的交互作用对分析结果的影响,可能会导致不准确的参数估计或忽略重要的隐藏的关系。余荣杰等人利用潜在类别分析将事故数据划分为若干同质潜在类别降低事故数据异质性对分析结果的影响(yur,wangx,abdel-atym.ahybridlatentclassanalysismodelingapproachtoanalyzeurbanexpresswaycrashrisk[j].accidentanalysisandprevention,2017,101:37-43.)。rusli等人利用决策树筛选自变量间的高阶交互作用,并将高阶交互项和主效应相结合纳入事故严重度模型,定量分析自变量的交互作用对事故严重度的影响,而该方法仅考虑了自变量间的高阶交互作用忽略了自变量间存在的各阶交互作用(rusdirusli,md.mazharulhaque,mohammadsaifuzzaman,markking.crashseverityalongruralmountainoushighwaysinmalaysia:anapplicationofacombineddecisiontreeandlogisticregressionmodel[j].trafficinjuryprevention,2018,19(7):741-748.)。此外,传统的二元logistic回归模型仅考虑模型的整体预测精度,选取0.5作为模型分类阈值。然而,交通事故数据中死亡事故往往占比较少(即该数据为非平衡数据),采用0.5作为分类阈值虽然使模型能够获得较高的整体预测精度,但会使敏感度过低,使其失去预测意义。
技术实现要素:
本发明为克服现有技术的不足之处,提出一种应用于区域路网的交通事故严重度预测方法,以期能降低事故数据异质性对分析结果的不利影响、识别自变量的交互作用项和调整预测模型分类阈值,从而能克服传统交通事故严重度预测模型忽略交互作用项和非平衡数据综合预测效果差的问题,提高事故严重度模型的预测精度和拟合优度。
为达到上述目的,本发明采用如下技术方案:
本发明一种应用于区域路网的交通事故严重度预测方法的特点是按如下步骤进行:
步骤一、区域路网道路交通事故数据的采集与预处理;
从道路交通事故数据库中获取n起事故数据作为事故数据集d,并从任意第i起事故数据中选取k个分类变量组成集合x={x1,x2,…,xk,…,xk}来表征第i起事故,其中,xk表示第k个分类变量,且第k个分类变量xk包含ck种类别,第k个分类变量xk在ck种类别中的取值记为sk,令sik表示第i起事故的第k个分类变量的取值,则第i起事故中所有k个分类变量的取值所组成的分类变量取值集合记为si={si1,si2,...,sik,...,sik};令
将第i起事故的严重度作为预测变量,记为yi,且yi的取值为“0”或“1”分别表示非死亡事故和死亡事故;
步骤二、根据区域路网道路交通事故数据,建立潜在类别分析模型;
步骤2.1、定义所述潜在类别分析模型中存在一个潜在类别变量v,v包含t种类别,且任意一种类别记为t,t=1,2,...,t;令第i起事故中潜在类别变量v的取值记为vi;
步骤2.1.1、定义外循环次数为τ、最大外循环迭代次数为τmax;令第τ次所设置的类别数目为tτ;初始化τ=1;
步骤2.1.2、初始化t=1;
步骤2.1.3、初利用式(1)得到第i起事故vi取值为t,即属于第t种潜在类别时,第i起事故在k个分类变量上的取值集合为
式(1)中,p(sik=sk|vi=t)表示第i起事故属于第t个潜在类别时,第k个分类变量上取值为sk的条件概率;
步骤2.1.4、利用式(2)得到第i起事故中k个分类变量取值集合为
式(2)中,p(vi=t)是第i起事故属于第t个潜在类别的概率,潜在类别t占总体的比率;
步骤2.2、采用极大似然法进行模型参数估计,得到潜在类别概率和分类变量条件概率的估计值
步骤2.3、利用式(3)计算第i起事故被分类到第t个潜在类别的后验概率
步骤2.4、令t+1赋值给t,并判断t>tτ是否成立,若成立,则执行步骤2.5;否则,返回步骤2.1.3执行;
步骤2.5、利用式(4)、式(5)、式(6)和式(7)得到模型拟合评价指标,包括:第τ次信息评价指标aicτ、第τ次贝叶斯信息准则bicτ、第τ次样本校正的贝叶斯信息准则abicτ、第τ次熵值
aicτ=-2ln(lτ)+2m(4)
bicτ=-2ln(lτ)+ln(n)×m(5)
abicτ=-2ln(lτ)+ln(n*)×m(6)
式(4)、式(5)、式(6)和式(7)中,m为潜在类别分析模型中未知参数的个数;n*是调整后的样本量,且n*=(n+2)/24;
步骤2.6、将τ+1赋值给后τ,判断τ>τmax是否成立,若成立,则返回步骤2.7;否则,执行步骤2.1.3;
步骤2.7、从τmax次信息评价指标aic、贝叶斯信息准则bic、样本校正的贝叶斯信息准则abic和熵值r2中选出各个模型拟合评价指标均取到最优值时所对应的潜在类别个数,记为t*;将所述事故数据集d划分为t*个事故子类别,记为
步骤三、根据潜在类别分析模型结果,对t*个子类别分别建立cart决策树模型;
步骤3.1、令所述第t*个事故子类别中的事故数据
步骤3.2、初始化t*=1;
步骤3.3、将所述训练样本集
步骤3.4、令t*+1赋值给t*,并判断t*>t*是否成立,若成立,则表示得到t*个决策树,并执行步骤3.5;否则,返回步骤3.3执行;
步骤3.5、根据所述t*个二叉决策树的树形图,确定分类变量间的交互作用项,其中,第t*个事故子类别对应的二叉决策树所确定的交互作用项;
步骤四、对t*个子类别分别建立基于二元logistic回归的事故严重度模型;
步骤4.1、将所述第t*个子类别中的事故数据
步骤4.2、初始化t*=1;
步骤4.3、利用式(11)得到基于二元logistic回归在自变量x*条件下死亡事故即yj=1的发生概率p(y=1|x*):
式(11)中,w*为自变量x*的回归系数;
步骤4.4、利用极大似然法估计所述二元logistic回归的事故严重度模型的参数w*:
对于第j起事故,
利用极大似然估计,求出使得l(w*)取得最大值时的估计参数w′;
根据估计参数w′得到第j起事故在自变量
步骤4.5、调整事故严重度模型的预测分类阈值;
步骤4.6、令t*+1赋值给t*,并判断t*>t*是否成立,若成立,则表示获得t*个事故严重度预测模型,否则,返回步骤4.3执行。
本发明所述的交通事故严重度预测方法的特点也在于,所述步骤3.3是按如下过程进行:
步骤3.3.1、cart决策树使用gini系数作为判定决策树是否进行分支的依据,建立二叉决策树模型,根据特征值切分点α,将所述训练样本集
式(8)中,
gini(dα1)表示第一子集dα1的gini指数,并有:
式(9)中,
式(8)中,gini(dα2)表示第二子集dα2的gini指数,并有:
式(10)中,
步骤3.3.2、遍历所述特征集x中每个特征值的切分点,并计算每个特征值的切分点的gini指数;若特征集x中每个特征值的切分点的gini指数小于阈值ε,则表示所述cart决策树模型是一棵单结点的树,并输出所述单结点的树;否则执行步骤3.3.3;
步骤3.3.3、选择特征集x中最小切分点的gini指数所对应的特征值xmin及其相应的切分点αmin,并根据所述切分点αmin将训练样本集
若子集dmin1和子集dmin2的样本数均小于给定的结点样本阈值σ,则表示两个子集dmin1和dmin2所在的子结点均是叶子结点,输出二叉决策树;若子集dmin1和/或子集dmin2的样本数大于所述结点样本阈值σ,则表示子集dmin1或子集dmin2所在的子结点是非叶子结点可进一步进行划分,并执行步骤3.3.4;
步骤3.3.4、对于非叶子结点,令训练样本集
所述步骤4.5是按如下过程进行:
步骤4.5.1、定义θ为模型的预测分类阈值,且0<θ<1;
步骤4.5.2、初始化j=1;
步骤4.5.3、令模型的第j个分类阈值θj等于p′j,利用式(13)得到事故严重度模型预测的第j个敏感度se(θj),即事故数据集中死亡事故预测为死亡事故的概率:
式(13)中,
利用式(14)得到事故严重度模型预测的第j个特异性sp(θj),即事故数据集中非死亡事故预测为非死亡事故的概率:
式(14)中,
步骤4.5.4、令j+1赋值给j,并判断j>j是否成立,若成立,则表示得到j对敏感度和特异性取值,并执行步骤4.5.5;否则,返回步骤4.5.3执行;
步骤4.5.5、以第j个分类阈值θj为横坐标,分别以第j个分类阈值θj所对应的敏感度se(θj)和特异性sp(θj)值为纵坐标,绘制敏感度与特异性的曲线,以两曲线的交点对应的阈值作为最佳模型预测分类阈值θ′。
与现有技术相比,本发明的有益效果在于:
1、本发明方法基于区域路网交通事故数据,建立潜在类别分析模型,将事故数据划分为若干同质子类别;其次,对各子类别分别建立cart决策树模型,识别自变量间交互作用项;然后,基于二元logistic回归对各子类别分别建立考虑交互作用项事故严重度模型,并设置敏感度与特异性曲线交点作为事故严重度模型的预测分类阈值。该方法降低了事故数据异质性对分析结果的不利影响,克服了传统交通事故严重度预测模型忽略交互作用项和非平衡数据综合预测效果差的问题,提高了事故严重度模型的预测精度和拟合优度。
2、本发明方法通过潜在类别分析将交通事故数据划分为若干同质子类别,既能够反映事故数据异质性,又能精准识别、分析潜在的道路交通事故发生模式和机理;
3、本发明方法通过cart决策树模型识别自变量间的各阶交互作用项,并纳入二元logistic回归模型,提高了模型的拟合优度,并识别出影响区域路网交通事故严重度的重要自变量和交互作用项,有助于提高区域路网道路交通安全水平;
4、本发明方法使用敏感度和特异性曲线交点对应阈值作为二元logistic回归模型的分类阈值解决了非平衡数据分类问题,提高了事故严重度模型的预测准确度。
附图说明
图1为本发明类别1cart决策树图;
图2为本发明类别1的灵敏度与特异度曲线图;
图3为本发明类别1的roc曲线图;
图4为本发明方法流程图。
具体实施方式
本实施例中,如图4所示,一种应用于区域路网的交通事故严重度预测方法是按如下步骤进行:
步骤一、区域路网道路交通事故数据的采集与预处理;
步骤1.1、从道路交通事故平台中采集某区域路网的交通事故数据,删除交通事故数据库中记录不全(具有空白项)或记录不合理的事故数据,共获取2595(n=2595)起事故数据作为分析事故数据集d,从人、车、事故特征、路和环境五个方面选取26个分类变量组成集合x={x1,x2,...,x26}来表征第i起事故,并将他们作为预测模型的自变量,自变量具体取值见表1;其中,xk表示第k个分类变量,且第k个分类变量xk包含ck种类别,xk在ck种类别中的取值记为sk(例如:x1表示第一个分类变量包括两种类别即c1的值为2,则s1为1女性或2男性),每起事故都可以表示为26个分类变量取值的集合si={si1,si2,...,sik,...,si26};令
每一起事故的事故严重度作为预测变量,记为yi,yi的取值为“0”或“1”分别表示非死亡事故和死亡事故;
步骤1.2、利用spss软件进行多重共线性检验,删除具有共线性的分类变量,通过共线性检验发现方差膨胀因子(vif)均小于5,对应容差(tol)均大于0.1(如表1所示),证明26分类变量之间无共线性关系,均可纳入模型分析。
表1自变量定义与赋值及共线性检验
步骤二、根据区域路网道路交通事故数据,建立潜在类别分析模型;
步骤2.1、定义潜在类别分析模型中存在一个潜在类别变量v,v包含t种类别,且任意一种类别记为t,t=1,2,...,t;令第i起事故中潜在类别变量v的取值记为vi;
步骤2.1.1、定义外循环次数为τ、最大外循环迭代次数为5;令第τ次所设置的类别数目为tτ且tτ=τ;初始化τ=1;
步骤2.1.2、初始化t=1;
步骤2.1.3、初利用式(1)得到第i起事故vi取值为t,即属于第t种潜在类别时,第i起事故在k个分类变量上的取值集合为
式(1)中,p(sik=sk|vi=t)表示第i起事故属于第t个潜在类别时,第k个分类变量上取值为sk的条件概率;
步骤2.1.4、利用式(2)得到第i起事故中k个分类变量取值集合为
式(2)中,p(vi=t)是第i起事故属于第t个潜在类别的概率,潜在类别t占总体的比率;
此外,潜在类别分析模型的基本限定条件为各潜在类别概率以及每个分类变量的条件概率总和均为1,如式(3)、式(4)所示:
步骤2.2、采用极大似然法进行模型参数估计,得到潜在类别概率和分类变量条件概率的估计值
步骤2.3、根据贝叶斯理论,利用式(5)计算第i起事故被分类到第t个潜在类别的后验概率
其中,
第i起事故归属于某一类别的后验概率最大,则第i起事故被划分到该子类别,对所有n起事故数据进行后验概率的计算与比较,从而实现聚类的目的;
步骤2.4、令t+1赋值给t,并判断t>tτ是否成立,若成立,则执行步骤2.5;否则,返回步骤2.1.3执行;
步骤2.5、利用式(7)、式(8)、式(9)和式(10)得到模型拟合评价指标,包括:第τ次信息评价指标aicτ、第τ次贝叶斯信息准则bicτ、第τ次样本校正的贝叶斯信息准则abicτ、第τ次熵值
aicτ=-2ln(lτ)+2m(7)
bicτ=-2ln(lτ)+ln(n)×m(8)
abicτ=-2ln(lτ)+ln(n*)×m(9)
利用式(7)、式(8)、式(9)和式(10)中,m为潜在类别分析模型中未知参数的个数;n*是调整后的样本量,且n*=(n+2)/24;
步骤2.6、将τ+1赋值给后τ,判断τ>5是否成立,若成立,则返回步骤2.7;否则,执行步骤2.1.3;
步骤2.7、潜在类别分析模型的建模和参数估计采用mplusvision7.4软件进行,通过限定潜在类别数目t。从t=1开始逐渐增大潜在类别数目到t=5,得到5个不同的潜在类别分析模型估计参数ln(l),即τ的值为5。分别计算5个模型的拟合评价指标,包括:第τ次信息评价指标aicτ、第τ次贝叶斯信息准则bicτ、第τ次样本校正的贝叶斯信息准则abicτ、第τ次熵值
表2模型拟合指标汇总
表2中,aic、bic、abic的值越小模型的拟合程度越高,熵值大于0.8表明有90%以上分类正确率,lmr和blrt是相对拟合指标,p值显著表示t个类别优于t-1个类别显著。因此,考虑将事故数据划分为3个类别进行分析即t*=3。t*=3时潜在类别分析模型估计结果如表3所示,由条件概率分布识别出各子类别的事故特点,将类别1命名为县道上的乘用车事故,类别2乡村道路上的机动车事故,类别3老年人非机动车事故,识别出潜在的道路交通事故发生模式。
根据贝叶斯理论,利用式(5)计算第i起观测事故数据被分类到第3个潜在类别的后验概率
表3t*=3时潜在类别概率和自变量条件概率(部分)
步骤三、根据潜在类别分析模型结果,对3个子类别分别建立cart决策树模型;
步骤3.1、令第t*个事故子类别中的事故数据
步骤3.2、初始化t*=1;
步骤3.3、利用spss软件,构建cart决策树模型,输入事故数据集
步骤3.3.1、cart决策树使用gini系数作为判定决策树是否进行分支的依据,建立二叉决策树模型,根据特征值切分点α,将训练样本集
式(11)中,
gini(dα1)表示第一子集dα1的gini指数,并有:
式(12)中,
式(11)中,gini(dα2)表示第二子集dα2的gini指数,并有:
式(13)中,
步骤3.3.2、遍历特征集x中每个特征值的切分点,并计算每个特征值的切分点的gini指数;若特征集x中每个特征值的切分点的gini指数小于阈值0.001,则表示cart决策树模型是一棵单结点的树,并输出单结点的树,此时无交互作用项;否则执行步骤3.3.3;
步骤3.3.3、选择特征集x中最小切分点的gini指数所对应的特征值xmin及其相应的切分点αmin,并根据切分点αmin将训练样本集
若子集dmin1和子集dmin2的样本数均小于给定的结点样本阈值50,则表示两个子集dmin1和dmin2所在的子结点均是叶子结点,输出二叉决策树,此时仅存在二阶交互作用项;若子集dmin1和/或子集dmin2的样本数大于结点样本阈值50,则表示子集dmin1或子集dmin2所在的子结点是非叶子结点可进一步进行划分,并执行步骤3.3.4;
步骤3.3.4、对于非叶子结点,令训练样本集
步骤3.4、令t*+1赋值给t*,并判断t*>3是否成立,若成立,则表示得到3个决策树模型,并执行步骤3.5;否则,返回步骤3.3执行;
步骤3.5、根据3个二叉决策树的树形图,确定分类变量间的交互作用项,其中,第t*个事故子类别对应的二叉决策树所确定的交互作用项;
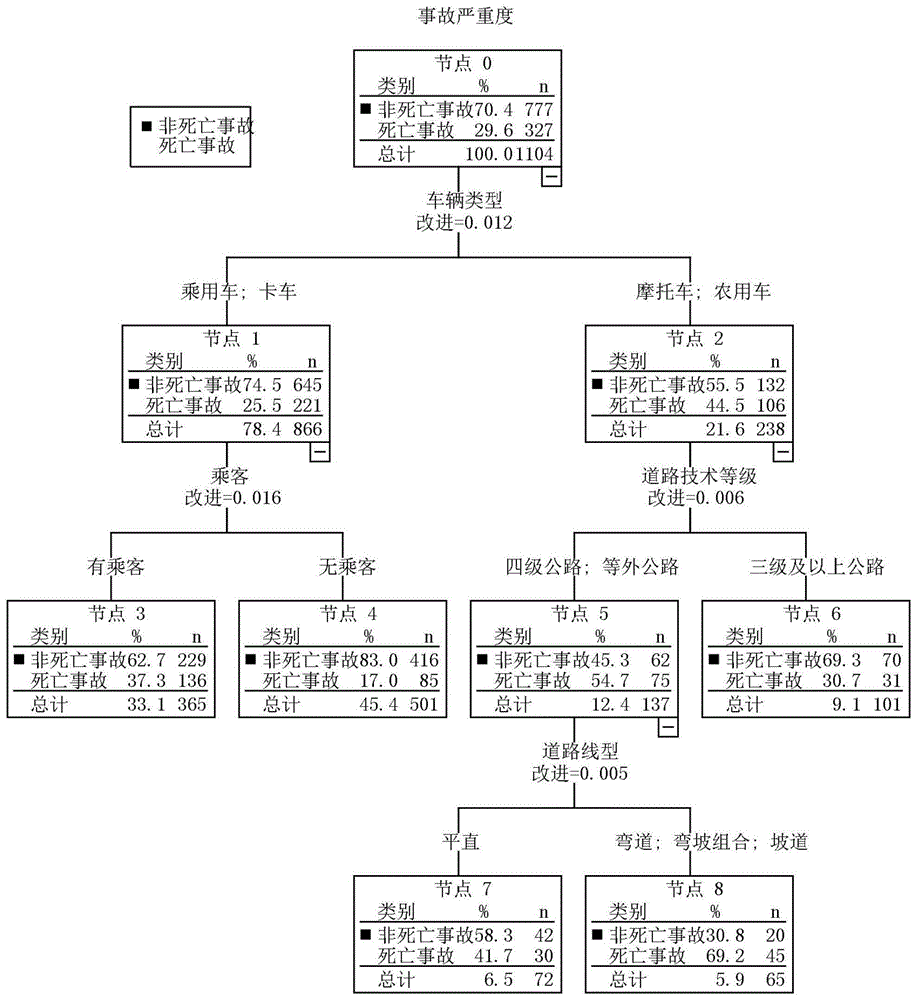
图1所示是类别1的二叉决策树树形图,该图以类别1中所有数据为根结点,包含4层树高,5个叶子结点。图中每个结点矩形框都标明了该结点包含的事故总数、死亡事故和非死亡事故数及二者比例。从树形图(图1)可知车辆类型与乘客、车辆类型与道路技术等级、道路技术等级与道路线型之间存在二阶交互作用,车辆类型、道路技术等级和道路线型之间存在三阶交互作用;
同理,确定类别2中存在二阶交互项分别是事故形态和照明条件、事故形态和车辆类型,类别3中存在二阶交互作用项是车辆类型和驾驶员年龄。
步骤四、对3个子类别分别建立基于二元logistic回归的事故严重度模型;
步骤4.1、将第t*个事故子类别中的事故数据
利用spss对各子类别进行单因素卡方检验,其中p值小于0.05表示自变量与因变量显著相关。单因素卡方检验结果见表4,类别1中16个变量与事故严重度显著相关。
表4各子类别单因素卡方检验结果
步骤4.2、初始化t*=1;
步骤4.3、利用式(14)得到基于二元logistic回归在自变量x*条件下死亡事故即yj=1的发生概率p(y=1|x*):
式(13)中,w*为自变量x*的回归系数;
步骤4.4、利用极大似然法估计二元logistic回归的事故严重度模型的参数w*:
对于第j起事故,
利用极大似然估计,求出使得l(w*)取得最大值时的估计参数w′;利用spss软件进行事故严重度模型的参数估计,其中分类变量的交互作用项以分类变量乘积的形式作为模型分析的自变量,为方便模型结果解释并对各自变量设置哑变量;自变量进入或剔除模型采用wald检验,进入或剔除标准分别为p<0.05和p>0.1,设置迭代次数为20次;
根据估计参数w′得到第j起事故在自变量
步骤4.5、调整事故严重度模型的预测分类阈值;
步骤4.5.1、定义θ为模型预测的分类阈值,且0<θ<1;
步骤4.5.2、初始化j=1;
步骤4.5.3、令模型的第j个分类阈值θj等于p′j,利用式(15)得到事故严重度模型预测的第j个敏感度se(θj),即事故数据集中死亡事故预测为死亡事故的概率:
式(15)中,
利用式(16)得到事故严重度模型预测的第j个特异性sp(θj),即事故数据集中非死亡事故预测为非死亡事故的概率:
式(16)中,
步骤4.5.4、令j+1赋值给j,并判断j>j是否成立,若成立,则表示得到j对敏感度和特异性取值,并执行步骤4.5.5;否则,返回步骤4.5.3执行;
步骤4.5.5、以第j个分类阈值θj为横坐标,分别以第j个分类阈值θj所对应的敏感度se(θj)和特异性sp(θj)值为纵坐标,绘制敏感度与特异性的曲线,以两曲线的交点对应的阈值作为最佳模型预测分类阈值θ′;
步骤4.6、令t*+1赋值给t*,并判断t*>3是否成立,若成立,则表示获得3个事故严重度预测模型,否则,返回步骤4.3执行。
得到3个二元logistic回归模型得到事故严重度模型参数估计结果
表6事故严重度模型估计结果
注:b为模型回归系数;or为优势比,or=exp(b);
同时,根据估计参数w′得到第j起事故在自变量
步骤4.6.1、事故严重度模型结果分析:
由表6可知,各子类别中影响事故严重度的因素之间存在显著差异,其中,无证驾驶、酒驾、超速、中央隔离设施、地形,摩托车与乘客的二阶交互作用,以及货车与四级公路、道路线形的三阶交互作用仅在类别1中显著;农用车、撞击固定物、非高峰时段、道路线型、能见度仅在类别2中显著;坠车、等外公路、交通控制设施、年龄与非机动车的交互作用仅在类别3中显著。
以类别1为例,无证驾驶、超速和酒驾的回归系数均为正,三种情况下死亡事故发生概率分别增加约132%、140%和124%。在事故形态方面,撞击非固定物使死亡事故的发生概率增加96%;有乘客状态下死亡事故发生概率增加165%,缺少道路中央隔离设施使死亡事故发生的概率增加120%;夜晚时死亡事故的发生概率上升约44%。
变量交互作用方面,摩托车搭载乘客驾驶时死亡事故发生概率降低约60%;货车在四级公路上行驶时,事故严重度易受道路线型影响,其中弯坡组合路段影响最大(or值为12.036),其次是弯道路段(or值为5.57)。
步骤4.6.2、模型比较:
为比较本发明方法与传统二元logistic回归模型在事故严重度分析方面的优劣性,采用模型预测准确度和roc曲线两个指标衡量模型预测精度,采用hosmer-lemeshow(hl)统计量衡量模型的拟合优度。
以敏感度和特异性曲线交点为分类阈值得到模型预测准确度,其值越高表明模型性能越好;以1-特异性为横坐标、敏感度为纵坐标绘制roc曲线,roc曲线下的面积即auc来评价模型的分类效能,auc值大于0.5表示优于随机猜测具有预测价值,auc值越接近于1表示模型的预测分类能力越好;以类别1为例,以敏感度和特异性曲线交点对应的阈值作为模型预测分类阈值如图2所示,以1-特异性为横坐标、敏感度为纵坐标绘制roc曲线如图3所示;此外,模型拟合优度采用hosmer-lemeshow(hl)统计量,其服从卡方分布,p值不显著(>0.05)表示模型拟合数据较好。
表7模型检验指标汇总表
由表7可知,本发明提出的一种应用于区域路网的交通事故严重度预测方法在模型预测准确度和拟合优度方面优于传统的二元logistic回归模型。
- 还没有人留言评论。精彩留言会获得点赞!