基于数据融合的油井含水率在线测量装置及提高精度方法与流程
本发明涉及采油装置技术领域,尤其涉及一种同轴相位法含水仪的现场标定方法。
背景技术:
油井是油田开发最重要的基本生产单元。油井含水率的在线准确计量对于确定油井出水、出油层位、估计原油产量、预测油井的开发寿命、油井的产量质量控制、油井状态检测、数字化油田建设等具有重要意义。目前,原油含水率检测有x射线、γ射线、α射线、超声波、微波、电容、射频等各种不同的测量原理和方法,但是由于现场环境复杂以及井口油气水多相流的复杂性,这些测量方法受流体温度、流态、原油物性、传感器特性等多种因素影响,能够运用到油井的原油含水率的测量方法还是不多,在性价比、全程测量、安全环保、稳定性、测量精度等方面存在着诸多问题。
技术实现要素:
本发明的目的在于克服上述技术的不足,而提供一种基于数据融合的油井含水率在线测量装置及提高精度方法。
本发明为实现上述目的,采用以下技术方案:一种基于数据融合的油井含水率在线测量装置,其特征在于:包括第一法兰、测试管、底部射频传感器、顶部射频传感器、左部射频传感器、右部射频传感器以及第二法兰,所述第一法兰位于测试管左端,所述第二法兰位于测试管右端,所述底部射频传感器、顶部射频传感器、左部射频传感器、右部射频传感器位于测试管内部并沿测试管的轴向上下左右方向延伸设置,通过上下左右方向射频传感器获得管线内流体的4个方向的射频信号。
一种基于数据融合的油井含水率在线测量装置的提高精度方法,其特征在于:包括以下步骤:
步骤一、对上下层含水率信号进行emd分解
1)利用采集到的数据建立油井含水率数据集为射频信号数据,
利用带通滤波器,采用经验模态方法对油井采出液含水率数据集
步骤二、定义射频信号的8个特征量
其中:xf表示射频信号的波动成分,即各个本证模态imf的和,r(j)表示射频信号的残差,cx-j(j)表示所有虚假模态分量的和,二者代表射频信号的平稳成分;m为数据点数。特征量d,波动成分均方根的值;特征量r,平稳成分的均值。上下左右方向射频信号各有自己的两个特征量,
即dup,dlow,dlt,drt,rup,rlow,rlt,rrt;
步骤三、基于emd分解的油井含水率的遗传算法优化支持向量机ga-svm回归模型。
在步骤一中,所述采用经验模态方法对油井采出液含水率数据集中的数据进行预处理的步骤如下:
(a)找
(b)、求取上下包络线的平均值,作为原始含水率信号的平均包络线m1(t),定义新数据序列h1(t)=x(t)--m1(t);由于h1(t)一般不满足作为imf分量的条件,一般需要经过重复不走一来找到符合条件的h1(t),本发明根据不同位置含水量数据的噪声特征分析和emd伪成分分析,上层含水率数据序列采用h2(t)作为下面计算要用的第一个imf分量c1(t),下层含水率数据序列采用h1(t)为c1(t);
(c)、从原始含水率信号x(t)分解出第一个imf后,r1(t)=x(t)-c1(t);
(d)、把滤除高频组分的差值信号r1(t)作为原始信号数据重复循环步骤1至3,求出r1、r2、r3、…,rn,直到rn成为一个单调函数(或rn很小)时结束循环;
(e)、通过上述过程,原始某层含水率信号x(t)被分解成若干个imf和一个余项rn,即
在步骤三中,具体步骤如下:
1)确定网络结构。把射频信号的8个特征量、气液比、温度、矿化度共11个特征量作为模型输入,输出为含水率。选择径向基核函数为svm的核函数。
2)初始种群的产生。群体规模n一般根据所求问题的非线性程度选取,非线性程度越大,n越大。初始种群由随机产生的n个染色体串构成,每个染色体由n个基因(即核参数σ和惩罚因子c)组成;
3)编码方案
传统二进制编码不便于遗传运算算子操作,影响学习精度。本发明采用实数编码,不存在编码和解码过程,可以提高解的精度和运算速度。实数编码形式如下所示;
其中k表示进化代数,kmax表示终止代数,
n=(4+2)*4+1=25
4)适应度函数设计与计算。本发明选择系统实际标定值和学习输出的误差平方和的倒数作为适应度函数。但是遗传算法是对适应度函数的最大化寻优,而支持向量机模型参数选择是最小化优化问题,因此作如下转换:
将染色体上各个基因分配到支持向量机结构中,以训练样本正向运行支持向量机,如下计算个体适应度f;
其中函数为支持向量机内部复杂计算函数,此处予以忽略;σ为核参数和c为惩罚因子;o为预测输出;t为期望输出;n为输出单元数;n为样本数。m是为保证适应度函数值不至于太小而引入的一个系数;
5)遗传算子设计选择、交叉、变异是遗传算法的三个基本算子。选择操作采用轮盘赌选择方式计算适应度fi的权值个体对应的选择概率为:
交叉操作采用非一致交叉算子,以一定的交叉概率随机选择一对父代个体
α∈(0,1)为均匀分布随机变量。
变异操作采用非一致变异,其算子定义为:
其中c′i为
6)存优策略
计算当前群体的适应度,并保留最优个体,再按照交叉概率和变异概率,选择不同的个体对其进行不同的交叉和变异操作,产生下一代个体,并对新生个体进行评价,直到达到终止代数100次结束,否则转第4)步,将全局最优结果映射为svm的参数;
7)用训练样本训练模型,获得相应的支持向量,从而确定该回归模型的结构。
本发明的有益效果是:与现有技术相比,该模型在计算时,运用多传感器数据融合考虑、重力和浮力对水平管道中油气水三相分布的影响即流态的影响,即运用管道内部上下左右的射频信号数据更加全面、准确的反映管道中流体的含水率情况;然后考虑了温度、矿化度、气液比对射频法测量含水率的影响,提高精度。其次采用支持向量机建立回归模型,从理论上解决神经网络方法无法避免的局部最优问题,将低维非线性的输入映射到高维线性的输出,模型简单。模型采用遗传算法对svm的参数进行优化,降低射频信号非平稳性对精度的影响。
附图说明
图1为本发明的立体图;
图2为本发明的侧视图。
具体实施方式
下面结合附图及较佳实施例详细说明本发明的具体实施方式。
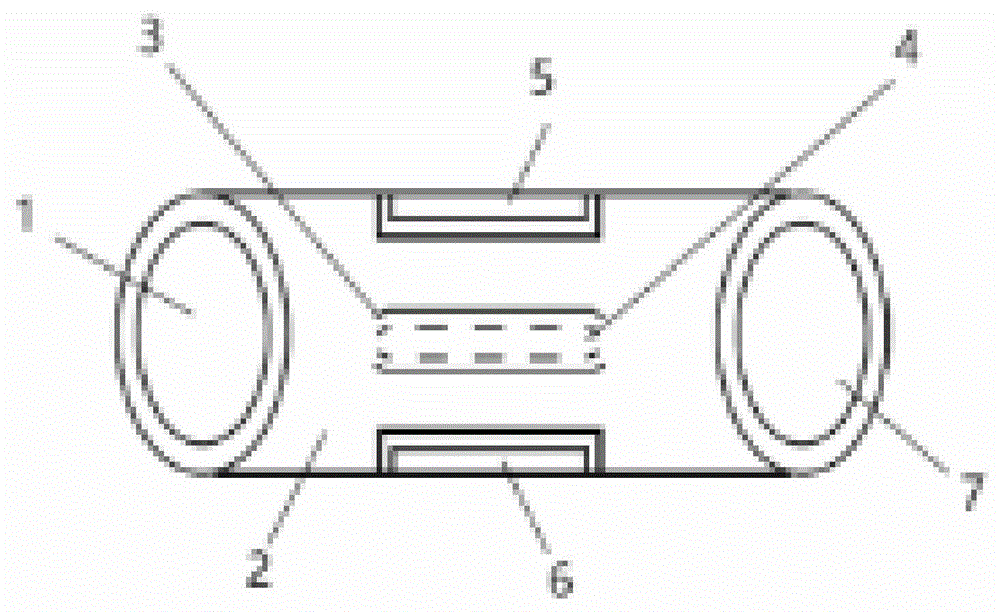
如图1和图2所示,一种基于数据融合的油井含水率在线测量装置,包括第一法兰1、测试管2、左部射频传感器3、右部射频传感器4、顶部射频传感器5、底部射频传感器6以及第二法兰7,所述第一法兰位于测试管左端,所述第二法兰位于测试管右端,所述底部射频传感器、顶部射频传感器、左部射频传感器、右部射频传感器位于测试管内部并沿测试管的轴向上下左右方向延伸设置,通过上下左右方向射频传感器获得管线内流体的4个方向的射频信号。一种基于数据融合的油井含水率在线测量装置的提高精度方法,其特征在于:包括以下步骤:
步骤一、对上下层含水率信号进行emd分解
1)利用采集到的数据建立油井含水率数据集为射频信号数据,
利用带通滤波器,采用经验模态方法对油井采出液含水率数据集
步骤二、定义射频信号的8个特征量
其中:xf表示射频信号的波动成分,即各个本证模态imf的和,r(j)表示射频信号的残差,cx-j(j)表示所有虚假模态分量的和,二者代表射频信号的平稳成分;m为数据点数。特征量d,波动成分均方根的值;特征量r,平稳成分的均值。上下左右方向射频信号各有自己的两个特征量,
即dup,dlow,dlt,drt,rup,rlow,rlt,rrt;
步骤三、基于emd分解的油井含水率的遗传算法优化支持向量机ga-svm回归模型。
在步骤一中,所述采用经验模态方法对油井采出液含水率数据集中的数据进行预处理的步骤如下:
(a)找
(b)、求取上下包络线的平均值,作为原始含水率信号的平均包络线m1(t),定义新数据序列h1(t)=x(t)--m1(t);由于h1(t)一般不满足作为imf分量的条件,一般需要经过重复不走一来找到符合条件的h1(t),本发明根据不同位置含水量数据的噪声特征分析和emd伪成分分析,上层含水率数据序列采用h2(t)作为下面计算要用的第一个imf分量c1(t),下层含水率数据序列采用h1(t)为c1(t);
(c)、从原始含水率信号x(t)分解出第一个imf后,r1(t)=x(t)-c1(t);
(d)、把滤除高频组分的差值信号r1(t)作为原始信号数据重复循环步骤1至3,求出r1、r2、r3、…,rn,直到rn成为一个单调函数(或rn很小)时结束循环;
(e)、通过上述过程,原始某层含水率信号x(t)被分解成若干个imf和一个余项rn,即
在步骤三中,具体步骤如下:
1)确定网络结构。把射频信号的8个特征量、气液比、温度、矿化度共11个特征量作为模型输入,输出为含水率。选择径向基核函数为svm的核函数。
2)初始种群的产生。群体规模n一般根据所求问题的非线性程度选取,非线性程度越大,n越大。初始种群由随机产生的n个染色体串构成,每个染色体由n个基因(即核参数σ和惩罚因子c)组成;
3)编码方案
传统二进制编码不便于遗传运算算子操作,影响学习精度。本发明采用实数编码,不存在编码和解码过程,可以提高解的精度和运算速度。实数编码形式如下所示;
其中k表示进化代数,kmax表示终止代数,
n=(4+2)*4+1=25
4)适应度函数设计与计算。本发明选择系统实际标定值和学习输出的误差平方和的倒数作为适应度函数。但是遗传算法是对适应度函数的最大化寻优,而支持向量机模型参数选择是最小化优化问题,因此作如下转换:
将染色体上各个基因分配到支持向量机结构中,以训练样本正向运行支持向量机,如下计算个体适应度f;
其中函数为支持向量机内部复杂计算函数,此处予以忽略;σ为核参数和c为惩罚因子;o为预测输出;t为期望输出;n为输出单元数;n为样本数。m是为保证适应度函数值不至于太小而引入的一个系数;
5)遗传算子设计选择、交叉、变异是遗传算法的三个基本算子。选择操作采用轮盘赌选择方式计算适应度fi的权值个体对应的选择概率为:
交叉操作采用非一致交叉算子,以一定的交叉概率随机选择一对父代个体
α∈(0,1)为均匀分布随机变量。
变异操作采用非一致变异,其算子定义为:
其中c′i为
6)存优策略
计算当前群体的适应度,并保留最优个体,再按照交叉概率和变异概率,选择不同的个体对其进行不同的交叉和变异操作,产生下一代个体,并对新生个体进行评价,直到达到终止代数100次结束,否则转第4)步,将全局最优结果映射为svm的参数;
7)用训练样本训练模型,获得相应的支持向量,从而确定该回归模型的结构。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!