基于深度信息与CNN的人眼检测方法与流程
本发明属于人眼检测技术领域,涉及一种人眼检测方法,尤其涉及一种基于深度信息与cnn的人眼检测方法。
背景技术:
随着裸眼3d显示器技术的日趋成熟,如何实时准确的检测观看者眼睛的位置,并根据观看者的眼睛位置输出最好的3d观看效果成为裸眼3d显示器的重要发展方向。目前人眼检测算法的实现主要通过训练cnn模型,在人脸区域分类的基础上,对人脸框与眼睛位置做回归,精确的实现人眼检测。
同时随着深度相机采集深度信息技术的发展,通过深度相机提取场景深度信息,可以得到图像中没有的深度特征。而且深度特征可以准确的分割出场景中的物体,并获取其对应的深度范围,大大减少了cnn提取人脸候选区域的计算复杂度。
有鉴于此,设计一种结合深度信息与cnn的方法实现人眼检测,满足裸眼3d显示器实时性与准确性的要求。
技术实现要素:
本发明提供一种基于深度信息与cnn的人眼检测方法,可提高检测精确度,减少计算复杂度,提高检测效率。
为解决上述技术问题,根据本发明的一个方面,采用如下技术方案:
一种基于深度信息与cnn的人眼检测方法,所述人眼检测方法包括:
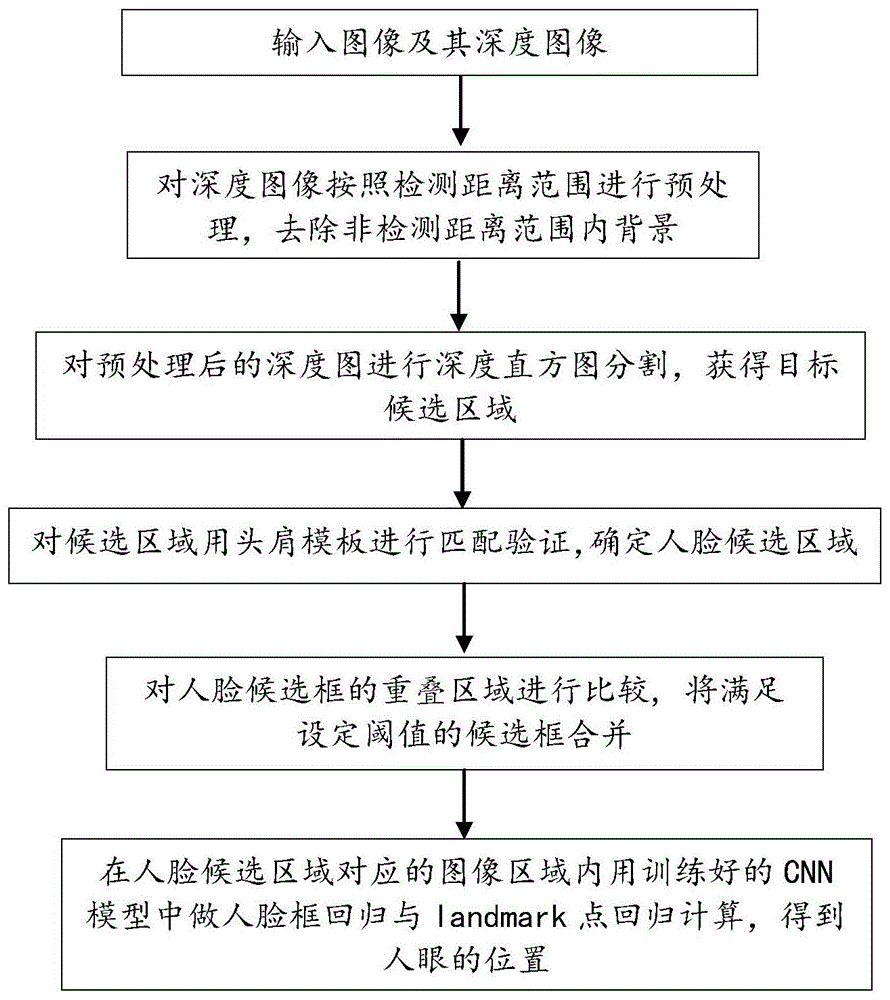
步骤s1、输入图像及其深度图像;
步骤s2、对深度图像按照检测距离范围进行预处理,去除非检测距离范围内背景;
步骤s3、对预处理后的深度图进行深度直方图分割,获得目标候选区域;
步骤s4、对候选区域用头肩模板进行匹配验证,确定人脸候选区域;
步骤s5、对人脸候选框的重叠区域进行比较,将满足设定阈值的候选框合并;
步骤s6、在人脸候选区域对应的图像区域内用训练好的cnn模型中做人脸框回归与关键点回归计算,得到人眼的位置。
作为本发明的一种实施方式,所述步骤s2中,将深度图中深度值提取出检测范围的像素点,转化为像素值设置为255,其余为0的掩膜,与深度图点乘,去除范围外的背景像素。
作为本发明的一种实施方式,所述步骤s3中,将经过掩膜后的深度图深度值转换到0-255,将深度图从屏幕坐标系的xy轴映射到xz轴平面,对映射后的图像分别对xz轴做投影,分割出物体范围;分割出的范围对应x轴区域范围与z轴区域范围,并根据对应的深度范围的中间值得到区域模板匹配对应尺度的模板图像。
作为本发明的一种实施方式,所述步骤s3中,充分利用不同物体位置深度值的差异,首先将xy轴的屏幕坐标系转换到xz轴,将场景中物体做了xz的二维垂直投影,再根据物体投影图上x轴的垂直投影,找出投影的波峰与波谷,认为每个波峰位置表示物体存在,在每个波峰前后的波谷作为分割的阈值,对场景上的物体做x轴的分割;
对分割出来的每个x轴区域做z轴上的垂直投影,找出投影的波峰波谷,将每个波峰作为物体所在深度,将波峰前后的波谷作为分割阈值,与x轴的分割组成每个物体的分割范围,将场景中每个物体分割开。
作为本发明的一种实施方式,所述步骤s3中,采用了一种自适应深度值匹配模板尺度的方法,避免了传统多尺度同时做检测的复杂性;根据不同物体得到的深度范围值,取范围的中间值作为该物体的深度,选择与其深度值匹配的头肩模板图像,实现了检测头肩模板最佳尺度匹配准确性的同时,也避免了多尺度模板同时检测的复杂性。
作为本发明的一种实施方式,所述步骤s4中,将深度图分成多个检测部分,对这多个深度区域并行做检测,采用模板匹配的方法,通过步长为1的滑窗,将当前深度值对应的头肩模板图像与输入的深度图进行相似度检测,得到的值存放到result图中。
作为本发明的一种实施方式,所述步骤s5中,采用非极大值抑制方法,将result图中的候选框做合并,将得到的候选框根据头肩比例做头部的分割,将深度图中分割的位置映射到图像中作为cnn模型的输入图像。
作为本发明的一种实施方式,所述步骤s6中,将图像分割得到的人脸区域resize到与训练图像相同的训练尺度的大小作为cnn模型的输入图像。
作为本发明的一种实施方式,所述步骤s6中,采用四层卷积层,两层全连接层的模型进行人脸二分类以及人脸框与关键点回归,人脸二分类采用softmaxloss函数,人脸框与人脸关键点回归采用最小均方误差函数训练出模型;将训练好的模型导入网络结构,结合深度信息分割出的人脸图像输入,得到新的人脸框位置与人脸关键点。
本发明的有益效果在于:本发明提出的基于深度信息与cnn的人眼检测方法,可提高检测精确度,减少计算复杂度,提高检测效率,保证检测实时性与准确性,满足裸眼3d显示器的要求。
本发明提出的人眼检测方法,首先利用了深度信息对人脸区域粗提取,再通过cnn方法对人脸位置及人眼位置细化。本发明根据场景物体水平间隔与深度间隔的特点,通过深度信息分割出场景中的物体,再对每个物体做头肩模板匹配,实现对人脸的快速定位,在保证人脸检测准确度的前提下,大大减少了人脸检测的复杂度,使本算法的耗时更少。本发明在分割出的人脸区域的基础上,采用4个卷积层,2个全连接层的网络结构,在人脸上做人脸框边缘回归及关键点(landmark)点的位置回归,通过预先训练好的模型参数,实现了对人眼的准确定位。
附图说明
图1为本发明一实施例中人眼识别方法的流程图。
具体实施方式
下面结合附图详细说明本发明的优选实施例。
为了进一步理解本发明,下面结合实施例对本发明优选实施方案进行描述,但是应当理解,这些描述只是为进一步说明本发明的特征和优点,而不是对本发明权利要求的限制。
该部分的描述只针对几个典型的实施例,本发明并不仅局限于实施例描述的范围。相同或相近的现有技术手段与实施例中的一些技术特征进行相互替换也在本发明描述和保护的范围内。
本发明揭示了一种基于深度信息与cnn的人眼识别方法,图1为本发明一实施例中人眼识别方法的流程图;请参阅图1,在本发明的一实施例中,所述方法包括:
步骤s1.通过深度相机拿到图像与对应的深度图;
步骤s2.将深度图中深度值提取出检测范围的像素点,转化为像素值设置为255,其余为0的掩膜,与深度图点乘,去除范围外的像素。
步骤s3.将经过掩膜后的深度图深度值转换到0-255,将深度图从屏幕坐标系的xy轴映射到xz轴平面,先对映射后的图像做x轴投影,找出波峰波谷的位置,将波峰位置的前后两个波谷值作为x轴一个分割区域。再对分割出来的区域分别做z轴投影,找出投影的波峰波谷,将波峰前后的波谷作为z轴的一个区域。分割出的范围对应x轴区域范围与z轴区域范围,并根据对应的深度范围的中间值得到区域模板匹配对应尺度的模板图像。
步骤s4.将深度图分成多个检测部分,对这多个深度区域并行做检测,采用模板匹配的方法,通过步长为1的滑窗,将当前深度值对应的头肩模板图像与输入的深度图进行相似度检测,得到的值存放到result图中。
步骤s5.对人脸候选框的重叠区域进行比较,将满足设定阈值的候选框合并。
在本发明的一实施例中,遍历result图的每个像素值,设置阈值,将符合阈值条件的作为候选框,将候选框采用非极大值抑制的方法,将满足一定iou阈值(交并比阈值)的候选框合并。
步骤s6.将合并后的候选框映射到图像,并对头部区域分割作为输入图像,在训练好的cnn模型中做人脸框回归与关键点回归计算,得到人眼的位置。
在本发明的一实施例中,步骤s6中,人脸框边缘及人脸关键点回归方法的步骤如下:
步骤s61:将输入的人脸区域resize到训练尺度,送入4层卷积层中,卷积核为3x3,每个卷积层后加一个prelu层,导入训练好的模型权值参数,提取出3x3x128的featuremap。
步骤s62:将得到的featuremap通过2层全连接层输出一个2+4+2xpointnum的向量,2代表是否人脸的分类,4表示人脸框的位置,pointnum表示人脸关键点个数。
步骤s63:将得到的人脸的关键点位置提取出人眼位置,并将人眼在人脸的位置映射回源图,实现人眼位置检测。
综上所述,本发明提出的基于深度信息与cnn的人眼检测方法,可以保证检测实时性与准确性,满足裸眼3d显示器的要求。
本发明提出的人眼检测方法,首先利用了深度信息对人脸区域粗提取,再通过cnn方法对人脸位置及人眼位置细化。本发明根据场景物体水平间隔与深度间隔的特点,通过深度信息分割出场景中的物体,再对每个物体做头肩模板匹配,实现对人脸的快速定位,在保证人脸检测准确度的前提下,大大减少了人脸检测的复杂度,使本算法的耗时更少。本发明在分割出的人脸区域的基础上,采用4个卷积层,2个全连接层的网络结构,在人脸上做人脸框边缘回归及关键点的位置回归,通过预先训练好的模型参数,实现了对人眼的准确定位。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
这里本发明的描述和应用是说明性的,并非想将本发明的范围限制在上述实施例中。这里所披露的实施例的变形和改变是可能的,对于那些本领域的普通技术人员来说实施例的替换和等效的各种部件是公知的。本领域技术人员应该清楚的是,在不脱离本发明的精神或本质特征的情况下,本发明可以以其它形式、结构、布置、比例,以及用其它组件、材料和部件来实现。在不脱离本发明范围和精神的情况下,可以对这里所披露的实施例进行其它变形和改变。
- 还没有人留言评论。精彩留言会获得点赞!