用于优化现场可编程门阵列的代码的方法和装置与流程
本申请要求于2018年8月9日提交的葡萄牙专利申请号20181000054166和2018年8月14日提交的欧洲专利申请号18189022.9的优先权和权益。本发明涉及一种用于优化硬件加速器的代码的方法和装置。
背景技术:
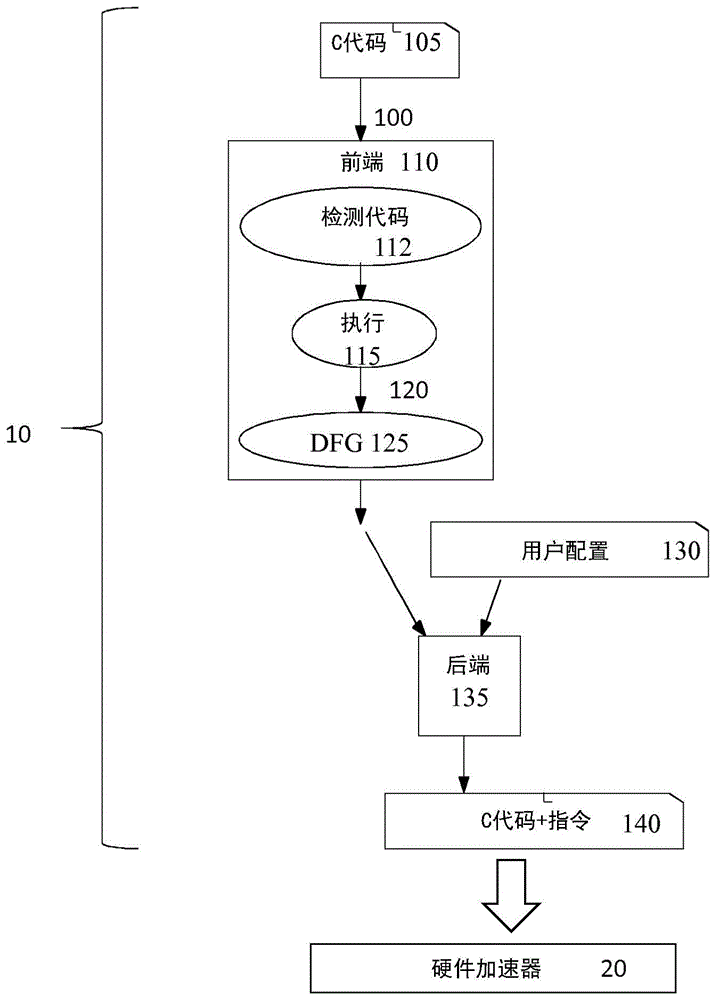
:现场可编程门阵列(fpga)成为用于加速软件应用程序的执行的流行解决方案。高级综合(hls)工具的使用旨在为软件开发人员提供抽象级别,以使软件开发人员能够开发用于在基于fpga的硬件加速器上使用的软件代码。但是,重组软件代码和有效使用指令的需求既需要掌握所使用的hls工具,也需要掌握要在其上运行软件代码的fpga硬件。本文档中描述的方法使用展开的图表示(其可以从程序执行轨迹生成),与基于图的优化(例如折叠)一起,来生成合适的c代码以输入到hls工具。实验表明,本文档中描述的方法能够生成只有使用手动重组输入软件代码和手动插入适当的指令才能实现的高效的硬件实现。使用fpga实现的硬件加速器可以提供许多系统所需的性能改进和/或节约能耗。经过优化后,这些基于fpga的硬件加速器将具有高性能和高效的能耗[1]。只要硬件提供足够的资源,应用程序的自定义硬件实现(也称为特定于应用程序的架构)就可以并发执行多个独立的运算。这种并发执行可加快具有高指令级并行性(ilp)的算法的执行。为了设计硬件以执行具有ilp程度的算法,当前的方法涉及不同的技能,并且需要了解非常不同的编程语言和工具。描述高效的硬件非常耗时。这些方面给使用和开发fpga作为硬件加速器设置了障碍。为了解决这些问题,在高级综合(hls)领域进行了许多努力。hls工具允许程序员使用高级抽象(例如,诸如c之类的软件编程语言中已知的抽象级别)来定位fpga硬件。这些高级抽象的目的是允许开发人员更轻松地对fpga进行编程,并且能够处理更复杂的应用程序,而无需其他方法所需的耗时的工作。但是,即使hls工具提高了抽象级别,hls工具仍需要程序员具备一定的硬件专业知识才能在fpga硬件上实现优化的解决方案。尽管hls工具可以接受编程语言(例如c),但是该软件代码的结构在很大程度上影响所得到的生成的硬件[2]。此外,hls工具中典型的hls工具可能需要其他指令或配置才能生成有效的实现。对于本领域普通技术人员而言,现有技术的hls工具具有进入壁垒,在这种情况下,本领域普通技术人员是软件程序员。通过降低这种进入壁垒,更多的软件开发人员将能够使用基于fpga的硬件的计算能力来加速应用程序和/或实现显著降低能耗。基于c的编程语言是许多hls工具的常见输入[1]。由于c编程模型是为cpu量身定制的,并且没有考虑硬件的并行性性质和可能的定制,因此这些现有的hls工具通过允许程序员通过提供配置或指令来指导综合,来弥补这些限制。众所周知,软件代码的结构对所生成硬件的性能影响很大。该硬件可以实现为fpga或asic。因此,在现有技术中,通常需要复杂的代码重组,并且hls工具和编译器可能既不提供这种优化,也不确保其自动应用。为了使基于c的hls更易于访问,需要一种轻松重组输入软件代码的方法。本文档介绍了一种针对目标专用硬件(例如,使用fpga实现的)生成自动优化的c代码的方法。该代码随后可用于使用fpga或asic来制造电子电路。现有技术源到源的优化一直是hls领域的研究主题。例如,cong等人.[5]简要介绍了代码重组的问题,并提出了一个框架,以促进软件开发人员进行代码重组。cardoso等人.[6]提出了一种方法,允许用户对策略进行编程以应用代码转换和指令插入。leguphls工具[8]也接受c作为输入,并通过修改后的llvm编译器[9]实现代码重组,以实现hls优化。同样相关的是专门处理流式bas计算的方法。例如,mencer在[7]中提出了一种使用称为asc的基于c语言的方法。asc已设计为在硬件中实现基于数据流的计算。max-compiler[10]是一种hls工具,用于以基于java的编程语言(称为maxj)来实现流计算,这些流计算被描述为数据流图。在[11]中,作者讨论了数据流图(dfg)优化,以在maxj编译器的上下文中生成更好的fpga实现。本文档中的方法与先前介绍的工作有所不同,因为本文档的方法侧重于源代码到源代码的重组,以为典型的基于c的hls工具提供更友好的代码。可以将其视为正交工作,因为所描述的方法可以为hls工具(诸如legup和vivadohls)提供有用的代码重组。与maxcompiler方法相比,所描述的方法也可以用于提供重组的maxj代码,但在这种情况下,该方法将需要maxj代码生成器作为后端。另外,我们还注意到该方法可以在其他输入编程语言的上下文中使用,因为通过检测应用程序的原始代码并通过获取修改后的应用程序执行的图表来获得所使用的dfg。使用图作为编译器和hls工具的中间表示很常见(例如,参见danield.gajski,nikild.dutt,allenc.-h.wu和stevey.-l.lin.1992.《高级综合:芯片和系统设计导论(high-levelsynthesis:introductiontochipandsystemdesign)》。美国马萨诸塞州诺威尔市的kluwer学术出版社m.p.cardoso,pedroc.diniz,markusweinhardt,“用于可重配置计算的编译:一项调查(compilingforreconfigurablecomputing:asurvey)”,acm计算出版社,42(4):13:1-13:65(2010)。通常,输入源代码的结构由控制数据流图(cdfg)或数据流图(dfg)或二者的扩展表示,然后使用这些图进行代码转换和优化。一种典型的情况是循环展开,其可以在通过复制子图在内部实现,并修改例如循环控制结构和归纳变量的值。这是hls工具应用某些优化的典型方式。这些图甚至用于分配、投标和调度(hls的三个重要任务,例如,参见philippecoussy,danield.gajski,michaelmeredith,andréstakach,“高级综合入门(anintroductiontohigh-levelsynthesis)”,ieee设计&计算机测试26(4):8-17(2009)m.p.cardoso,markusweinhardt,“高级综合(high-levelsynthesis)”,第2章,面向软件程序员的fpga2016,dirkkoch,frankhannig,danielziener(编辑),施普林格2016,23-47页。在源到源编译器处也从使用了这种方法(有些使用树表示,有些使用图表示)。在这些编译器中,转换后的图随后输入到代码生成阶段,其负责生成最终代码(例如,c到c编译器中的c代码)。hls工具可能需要其他指令或配置来生成有效的实现。现有技术解决方案(诸如hls工具)在高度复杂的代码重组中表现不佳。实际上,所涉及的高复杂度实际上是由于没有代码重组工具的原因,该工具无法自动提供生成更高效硬件所需的重组程度,并且用户通常需要确定优化并应用这些优化序列(例如,参见m.p.cardoso,teixeira,joséc.alves,ricardonobre,pedroc.diniz,joségabrielf.coutinho,wayneluk,“为基于fpga的系统指定编译器策略(specifyingcompilerstrategiesforfpga-basedsystems),”fccm2012:192-199)。例如,基于选择的编译器优化来应用编译器优化的顺序分别称为阶段排序和阶段选择,甚至在传统编译器优化的情况下(而不是在代码重组方面)都需要进行设计空间探索(dse)计划以及由于不存在其他更有效的解决方案而被机器学习技术作为目标(例如,参见amirh.ashouri,williamkillian,johncavazos,gianlucapalermo,cristinasilvano,“使用机器学习进行编译器自动调整的调查(asurveyoncompilerautotuningusingmachinelearning)”,acmcomput.surv.51(5):96:1-96:42(2019)和zhengwang,michaelf.p.o'boyle,“编译器优化中的机器学习(machinelearningincompileroptimization)”,ieee106(11):1879-1901(2018)。当考虑到更深的代码重组和/或涉及循环和特定参数(例如,数据依赖性和迭代次数)的重组技术时,问题甚至更加复杂。一些现有技术解决方案可以通过从输入程序的结构开始并有效地将其表示为图(例如,cdfg)来解决该复杂的相位选择和相位排序问题。但是,这些现有技术解决方案非常依赖于编译器中是否存在特定优化的顺序,其在实现特定代码重组的顺序中可能需要,而缺少特定优化可能会阻止该工具生成更高性能的硬件。国际专利申请no.wo2018/078451(reconfigureioltd)教导了一种装置,该装置专门将并发异步程序加速到多个fpga,但是现有技术的装置没有将内核加速到单个fpga。该装置使用特定的输入模型–csp。a.lotfi和r.k.gupta,“rehls:用于高级综合的资源感知程序转换工作流(rehls:resource-awareprogramtransformationworkflowforhigh-levelsynthesis)”,doi10.1109/iccd.2017.92,公开了在减少由使用hls工具生成硬件导致的硬件资源的情况下使用代码转换。该文档教导了使用开源llvm中间表示ir为输入代码表示的基本块构建的dfg的使用。lotfi等人公开的方法搜索dfg中常见的模式,以识别可以共享的任何硬件资源,从而减少fgpa所需的设计面积。生成的输入到hls工具的代码将考虑为资源共享选择的模式,并使用hls指令来指导hls工具。lotfi等人描述的方法是一种优化类型的示例,可以将其应用于我们的发明中用于减少硬件资源的dfg。这种优化将允许使用相同的硬件资源或基于它们的相似性支持合并数据路径的硬件资源来实现子图的选择(例如,参见n.moreano,e.borin,ciddesouza和g。araujo,“针对部分可重新配置的架构的有效数据路径合并(efficientdatapathmergingforpartiallyreconfigurablearchitectures)”,载于2005年7月的ieeetransactions关于集成电路和系统的计算机辅助设计,第24卷,第7期,第969-980页,doi:10.1109/tcad。2005.850844)。但是,lotfi等人未能描述一种减少存储器传输的优化方案。lotfi等人也未添加检测代码。o.reiche等人,“使用hipacc生成基于fpga的图像处理加速器(generatingfpga-basedimageprocessingacceleratorswithhipacc)”,doi:10.1109/iccad.2017.8203894,公开了hipacc的使用,hipacc是一种领域特定的语言和用于图像处理的编译器。该文件公开了一种方法的示例,其中使用dsl(特定领域语言)中的程序作为输入,然后将dsl代码转换为编程语言。转换后的代码作为编译器和/或hls工具的输入。在reiche等人的示例中,公开了将hipaccdsl中的程序转换为c代码c/c++和opencl代码的示例。在转换过程中,根据目标(例如,fpga或gpu)执行典型的编译器优化(应用于抽象语法树(ast)级别)。reiche等人没有描述通过检测hipaccdsl代码或通过内部ast和数据相关性生成dfg可能生成的数据流图的展开和折叠。j.p.pinilla和s.j.e.wilton,“用于高级综合设计的fpga系统内调试的增强型源级检测(enhancedsource-levelinstrumentationforfpgain-systemdebugofhigh-levelsynthesisdesigns)”,doi:10.1109/fpt.2016.7929514教导了一种方法,用于检测代码以监视/验证由hls工具生成的硬件的行为。想法是将检测代码注入到程序的输入代码中,以便监视程序的行为。注入的检测代码被输入到hls工具中,生成的硬件包括用于实现输入原始程序行为的硬件和用于监视程序行为的电路。换句话说,pinilla等人的检测代码提供了监视点,以在运行时或仿真期间理解和/或验证所生成的硬件的行为。相似方法的另一个示例是joshuas.monson和bradl.hutchings2015年提出的方法。使用源级转换改善fpga上的高级综合调试和验证。在2015acm/sigda国际现场可编程门阵列研讨会(fpga'15)上的会议记录。美国纽约州纽约市,acm,5-8。doi:https://doi.org/10.1145/2684746.2689087。y.uguen,f.dedinechin和s.derrien的工作,“桥接高级综合和特定于应用的算术:浮点求和的案例研究(bridginghigh-levelsynthesisandapplication-specificarithmetic:thecasestudyoffloating-pointsummations)”,2017年第27届国际现场可编程逻辑大会和应用程序(fpl),根特,2017年,第1-8页。doi:10.23919/fpl.2017.8056792提出了一种源到源编译器方法,该方法可使用浮点和定点数据类型以及特殊的求和减少模式来优化算术表达式。该方法为hls工具生成c/c++代码。所描述的方法是可以集成以进一步增强hls工具的代码生成功能的众多可能优化方法中的另一个。uguen等人的优化是针对涉及定点和浮点数据的求和运算的存在。s.cheng和j.wawrzynek的工作,“具有解耦的存储器访问的计算管线的架构综合(architecturalsynthesisofcomputationalpipelineswithdecoupledmemoryaccess)”,2014年现场可编程技术国际会议(fpt),上海,2014年,第83-90页。doi:10.1109/fpt.2014.7082758提出了一种重组输入代码的方法,以便利用存储器操作和数据访问与计算的解耦来提供管线实现。根据操作的种类,控制数据流图(cdfg)的部分被聚集在子图中,然后cheng等人考虑到每个子图的硬件单元解耦执行,教导了代码的生成。重构后的代码输入到hls工具中。这是增强对hls工具的代码生成的许多可能的优化方法中的又一个优化方法,在这种情况下,考虑了解耦行为(例如,在存储器访问和计算之间),以及使用粗粒度管线方案的结果增强。技术实现要素:本文档提出了一种用于生成硬件加速器的优化配置的方法。该方法基于通过执行先前添加了检测代码的应用程序的关键函数而当前获得的计算(在算术、逻辑、运算符级别)的数据流图(dfg)表示。该文档公开了一种代码重组(coderestructuring)方法,该方法能够在自动应用于输入程序代码的结构时提供,需要标识要应用的编译器优化(及其参数和目标代码元素的特定值)以及应用它们的顺序(通常还会多次应用其中的一些)。通过自动注入检测代码,本文档中概述的方法可以具有不同的输入编程语言。一个示例,在该实施例中将c代码视为输入。然而,本发明不限于c。该方法使用折叠和展开图操作以及变换图本身的结构。该方法已在能够完全重组关键应用程序内核代码的框架中实现。该框架由前端和后端两个阶段组成。前端通过将检测代码(instrumentationcode)注入原始版本来从执行跟踪生成dfg。该框架的后端能够自动重组dfg并生成以hls友好方式添加了指令的c代码。提出了一个针对xilinxfpga以及针对标准解决方案vivadohls进行基准测试的实施例,并说明了通过该方法获得的相关加速效果。当与原始c代码比较时,通过该方法生成的c代码优于原始未修改的c代码,并且实现了显著的加速。所实现的c代码甚至具有可比性,并且在大多数情况下,都比添加有指令的手动优化的c代码更好。与原始的未经修改的c代码相比,该方法获得的实现方式要快30到100倍。与使用vivadohls指令优化的c进行比较时,该方法获得的实现方式要快2到15倍。但是,由框架生成的带有指令的c代码始终可以通过专家应用的手动代码转换来复制。因此,该方法可以使软件开发人员能够针对高效的硬件加速器使用c代码作为输入,并使用典型的hls工具作为后端,而无需诸如vivadohls之类的hls专家的支持。附图说明图1示出了本发明的方法和装置的编译流。图2示出了点积内核的前端的输出。图3示出了后端的表示。图4示出了针对滤波器子带基准考虑nz,ns,nm和ny分别等于4、3、1024和2在前端处生成的dfg。图5示出了第一步考虑nz、ns、nm和ny分别等于4、3、1024和2之后的滤波器子带基准。图6示出了第二步考虑nz、ns、nm和ny分别等于4、3、1024和2之后的滤波器子带基准通用操作子图。图7示出了第二步考虑nz、ns、nm和ny分别等于4、3、1024和2之后的第一输出的滤波器子带基准唯一操作子图。图8示出了第二步考虑nz、ns、nm和ny分别等于4、3、1024和2之后的第二输出的滤波器子带基准唯一操作子图。图9示出了第二步考虑nz、ns、nm和ny分别等于4、3、1024和2之后的第三输出的滤波器子带基准唯一操作子图。图10示出了第四步管线考虑nz、ns、nm和ny分别等于4、3、1024和2之后的滤波器子带基准非循环数据流。图11示出了第四步管线考虑nz、ns、nm和ny分别等于4、3、1024和2之后的滤波器子带基准外循环数据流。图12示出了第四步考虑nz、ns、nm和ny分别等于4、3、1024和2之后的滤波器子带基准内循环数据流。图13示出了第五步考虑nz、ns、nm、ny和展开因子分别等于512、32、1024、64和4之后算术优化的滤波器子带基准内循环数据流。图14示出了第六步考虑nz、ns、nm、ny和展开因子分别等于512、32、1024、64和4之后展开的滤波器子带基准内循环数据流。图15示出了滤波器子带基准的加速。具体实施方式公开了一种针对hls工具自动重组c代码的方法和装置10,并在图1中进行了概述。该代码可以用作制造单元的输入,以配置硬件加速器20。硬件加速器20包括可以被编程的多个电子组件,例如逻辑门。该装置包括前端110,该前端110能够生成程序的执行轨迹(trace)作为数据流图(dfg)。然后在后端135中对dfg进行处理,以生成用于传递至硬件加速器20的输出程序。该输出程序包括软件代码,在该非限制性示例中,该软件代码使用c中用于hls工具的软件代码。发现dfg是应用程序中数据流的良好表示,并在应用程序中表达属性,例如并行性。这些属性的识别可以改进硬件的实现。前端110使得能够从多种不同的输入语言生成dfg。这可以允许不同语言的软件程序员使用基于c的hls工具。本文档描述了后端135以及后端135操纵和分析dfg以自动生成输出程序的方式。还将描述前端110生成的dfg的类型以及从输入应用程序源代码构建它们的方法。图1示出了本公开的用于应用代码重组的方法的编译流。在第一步100中,将c代码105输入到前端110中。前端110在步骤115中执行c代码105,并在步骤120中生成c代码105中算法的执行轨迹的dfg125。dfg125包括在步骤115中从原始执行开始的每个操作,并且必须保持任何数据依赖性。将理解的是,图仅记录算法的依赖性,而不记录c代码105的算法的实际执行顺序。因此,可以彼此并行执行的操作在dfg125的图中没有相互依赖性地出现。因此,有必要单独记录数据依赖性。前端110尽可能通用,以适合许多不同的输入,并且不限于c代码输入的实现,并且可以轻松移植到其他软件语言。用点图描述语言描述了到后端130的输入dfg125。已知点图描述语言具有由id和属性序列描述的节点。每个节点至少具有两个属性。属性中的第一属性是标签,属性中的另一属性是类型。节点可以具有三种类型,即常量、变量和运算。标签根据节点的类型存储变量的名称、常量的值或操作的类型。如果变量是数组,则节点还包括对该数组的访问索引。另外,变量节点还将变量的类型以及变量节点是局部变量还是函数的输入保持为属性。在本公开的初始方面,前端110仅使用基本操作来处理软件代码中的内核。变量的任何赋值都用不同节点之间的连接表示(例如,从常量类型节点到变量类型节点)。操作由节点类型操作和操作数表示,结果由相应的节点表示并且相应地进行连接。在本公开的这一方面,在软件代码中表示内核的执行的dfg125将在执行期间将点描述写出到文件中。通过将检测代码112(即,一旦执行该代码,则输出dfg的描述的部分的代码)注入原始c代码105,并编译和执行修改后的c代码,来生成输入dfg。基本的检测规则是在原始c代码的每个语句之前附加检测代码。添加的检测代码描述了dfg节点和表示关联c语句的操作和操作数的边。例如,对于没有操作的赋值语句,添加的检测代码112输出带有两个节点的dfg部分,即输入节点和输出节点以及连接边。dfg124中节点的值描述了当前操作。让我们举个例子。假设c代码105包含诸如a=b+c的语句,即变量a取变量b和c的值之和的值。检测代码的执行为变量c,b和a的每个节点生成点描述,并包括变量名称(例如a,b或c)、类型(例如整数)以及它们根据左操作数还是右操作数的标识作为节点的属性。另一个示例可能是该节点表示存储器访问。添加的检测代码将该节点描述为变量,而标签是具有显式存储器索引的存储器中的访问。需要考虑正确的依赖性。在由图1中的c代码105表示的软件代码的执行过程中,变量可以具有多个值。对于变量采用的每个新值,将在dfg125中的图中创建一个新节点。方法和装置还必须能够知道与具有多个值的变量的最新值而不是任何过时的值相对应的节点的id。为了确保这种依赖性,检测代码112使用变量名的重命名来反映最新的赋值。例如,检测代码112将代表该赋值的数字添加到变量名。因此,假设代码以序列开头:a=b;d=a+c;a=d+a;该方法和装置对于第一操作使用ida_1,b_0。随后是第二个操作的idd_1,a_1,c_0,最后一个操作的ida_2,d_1,a_1。图2示出了执行添加了检测代码112的点积内核后得到的dfg125。从应用程序的执行中构造dfg125,而不是生成执行轨迹,然后从轨迹构建dfg125,以避免另一步骤,并牢记将来可能会紧凑的dfg表示形式,而无需输出大的轨迹和后续dfg压缩。现在将描述后端135的结构及其实现。后端135包括图3中列出的解决由前端110生成的dfg125的分析和优化的各种步骤。所应用的确切优化取决于图和配置130。由硬件加速器20支持的同时加载/存储的数量(例如,通过使用可用的存储器端口的数量)可以由用户定义,使得该方法和装置在输出程序中显式地生成具有适当数量的加载/存储语句的代码。还设置了内核的输入和输出以及一些优化选项。优化选项包括但不限于数组分区或循环管线。后端135是方法和装置中最重、最复杂的部分,因为后端135实现了所有代码重组、优化并为hls工具注入了指令。如图3所示,将后端135划分为七个单独的步骤。该方法首先在dfg125中修剪图,并识别应用程序中的任何重复模式(pattern),并记录在dfg125中以压缩图。之后,该方法优化压缩描述以获得数据流的改进表示。重复模式可以在图中折叠。由于重复模式可能会出现多次,因此可以通过改善这些重复序列来优化大部分应用程序。图3所示的前三个步骤(即,图初始化步骤300,输出分析步骤310和并行匹配步骤320)涉及图处理和重复模式的识别。随后的三个步骤(步骤330、340和350)优化了数据流,最后步骤(步骤360)生成添加了hls指令的c代码。图初始化的第一步骤300专用于在下一个优化之前初始化、预处理和分析输入图的一些步骤。该第一步骤300包括修剪dfg125中的任何不必要的节点。该步骤300可以提高将来算法的效率。第一步骤300还从输入代码中删除任何局部数组(localarray)(每当可以将局部数组提升为标量变量),并在多个唯一变量中实现它们,从而避免使用fpga中的bram(片上ram,在xilinxfpga中称为blockram)。第二步骤310分析输出并为下一步骤320准备图。在一个方面,初始图可能非常大并且可以以许多方式进行压缩。该方法和装置通过确定生成不同输出的序列之间存在模式来压缩图。如果内核具有单个输出,则跳过该步骤310和随后的步骤320。在输出是数组的情况下,方法和装置在步骤310中识别用于数组中每个输出值的各个数据流。在前进到下一步骤320之前,该方法和装置将输出上的公共运算与每个输出唯一的运算分离。因此,在多个输出的情况下,该方法和装置将产生具有所有公共运算的图,然后产生具有生成每个输出的唯一运算的图的列表。第三步骤320比较在先前步骤310中识别出的单独的数据流。该步骤320的目标是将所有这些单独的数据流压缩成可以由单个序列表示的循环。如果此压缩成功,则图的大小将大大减小。由于此单个序列将被重复多次,因此,如果图被优化,那么还将优化应用程序执行的大部分。没有优化的情况下,则尽管序列是相似的,也必须分别优化所有序列。同样,如果没有循环,则得到的c代码可能会过于展开,导致无法实现(甚至考虑资源共享方案)。如果该步骤320成功,则该方法和装置具有公共运算的图,这导致描述循环的图。这种分层表示允许更复杂的代码结构的表示。参考图4,其示出了在ny、nz和ns分别为2、4和3的情况下,针对滤波器子带基准(请参见列表1)从前端得到的dfg。与列表1中的源代码相比,可以识别y值的计算和s数组的不同结果。经过第一步骤310(修剪不必要的节点)后,结果如图5所示。在新的dfg中,变量信息现在存储在边中,从而导致更紧凑的图。列表1过滤器子带源代码参考图6、图7、图8和图9,示出先前在图5中示出的dfg上的第二步骤310分离的结果。图7、图8和图9示出了对于三个输出中的每一个唯一的原始数据流的段。图6示出了常见的运算。与原始数据流相比,所有这些段都可以识别。分离(separation)是由原始dfg和列表1中的源代码组成的,因为给出了每个输出的y值,所以y值对于每个输出是公用的。另一方面,将这些y值应用于s数组对于每个输出都是唯一的。将第二步骤310应用于滤波器子带基准(其中ny、nz和ns分别为64、512和32)会导致列表1中的代码。第二步骤310的公共节点和唯一节点之间的分离对于第三步骤320的成功是必要的。如果这些数据流包含公共运算,则这些数据流将在第三步骤320中被平凡地匹配并包含在循环中,尽管数据流只需要在程序中完成一次,而每个输出不需要多次。例如,列表1所示的滤波器子带基准包含两个嵌套循环集。第一循环计算y向量,其值在第二循环中用于计算输出。在第三步骤320(并行匹配)中,该方法和装置匹配唯一的输出序列,并识别像第二循环一样的循环,其内部循环被展开。在第二步骤310中,在不分离公共节点和唯一节点的情况下,该方法和装置还将匹配y值的计算,并且该方法将生成循环,该循环针对输出中的每个单个输出再次计算那些值。基于所生成的代码,该实现将比原始实现差很多,因此分离是该方法的一部分。应用第三步骤320匹配前面的示例会导致三个单独的dfg成功匹配(图7、图8和图9),因此,所有这三个段都可以在循环中实现,并由图7表示,这是循环(loop)的第一次迭代。列表3示出了也通过应用第三步骤320匹配而得到的代码。列表3在该方法的第三步骤320之后过滤子带,并考虑nz、ns、nm和ny分别等于512、32、1024和64的执行。第四步骤330(顺序匹配)的目的是实现管线化。在第三步骤320中,我们处理输出的并行化。但是,此后仍然存在一个大型图,其中有很多优化的机会。在第四步骤330中,该方法和装置识别出满足某些标准的潜在变量,并沿着该变量将图管线化。一方面,该方法选择更经常写入的变量之一。这是一种尝试建立最长管线的启发式方法。然后,该方法和装置匹配生成所选变量的每个新值的序列,以识别可以进行管线处理的循环。匹配算法管线遍历在上一步中构建的图层次结构,并在图6和图7中进行了说明。如果管线中断了先前的循环,则该方法和装置在该第四步骤330中对该循环进行优先级排序。第四步骤330重构该图以实现所得到的管线。该第四步骤330具有进一步压缩图以及改善图的结构的益处。此步骤的影响的一个示例是将其应用于滤波器子带基准。通过分析列表1中的原始代码,很明显,每次计算出y值时,都可以立即使用该y值,同时正在计算其他y值。这种关系在原始代码中并不明确,因此hls工具可能很难识别这种并行性机会。但是,通过dfg表示,这种并行性更容易识别。当该基准的图到达第四步骤330时,该方法和装置选择沿向量s的管线,从而导致列表2中的代码。列表2中对算法的修改后的描述清楚地揭示了并行性,并实现了可以利用并行性的管线。列表2在该方法的第四步骤330之后过滤子带,并考虑nz、ns、nm和ny分别等于512、32、1024和64的执行。通过将第四步骤330管线应用于滤波器子带基准,该方法和装置获得图10、图11和图12所示的dfg。该图沿着数组s管线化。图11和图12中的子图表示管线的外循环和内循环的单次迭代。在每次迭代中,外循环都会计算出y值,然后将其用于内循环。在内循环中,每个y用于计算数组s的所有输出。图10中的子图示出了与管线不匹配的数据流。在这种情况下,数据流是数组s的初始化。第五步骤340专用于应用数据流优化。在一方面,该第五步骤340优化了存储器访问。在该第五步骤340处的优化的一个非限制性示例是存储器重用。该方法和装置分析当前循环以识别是否存在冗余存储器访问。如果该冗余遵循模式,则该方法和装置使用缓冲区来存储迭代之间的值,从而减少存储器读取的数量。这样可以极大地减少某些应用程序的存储器瓶颈。该存储器优化可以应用于第三步骤320和第四步骤330的循环。如果第三步骤320的循环符合标准,则跳过第四步骤330,并且应用该优化,因为优化访问改变了数据流,并阻止实现第四步骤330中的管线。可以选择的另一种优化是对数组进行完全分区以减少存储器瓶颈。先前描述的优化通过将值存储在缓冲区中来通过数据重用减少存储器访问。降低存储器瓶颈的另一种方法是通过hls工具提供的数组分区指令。在这种情况下,该方法和装置通过整个dfg实现最终传递(pass)。基于对存储器的单独并发访问的数量,该方法和装置能够设置适当的数组分区因子,使得可以在单个周期内调度检测到的并发存储器访问的最大数量。此优化可以大大增加资源使用率。首先,通过使用更多的bram,其次,通过降低存储器瓶颈,以便可以并行执行更多的操作。此优化不会更改图的结构,而只会导致不同的指令。当应用到滤波器子带(filtersubband)函数时,此优化将注入列表4中包含的数组分区指令。列表4示出了在完全通过该方法的第五步骤340和第六步骤350并考虑nz、ns、nm和ny分别等于512、32、1024和64的执行后的滤波器子带。一种优化类型集中在算术优化上。其中之一是累加优化,它可以将累加重组为部分和序列。后端首先检测累加链。然后,后端删除该链,而是通过平衡树(提供更多ilp)结构实现相同的计算。与图14中的链相比,图13示出了平衡的累加。新的数据流由具有两个并行加法的树组成,而不是四个顺序求和,后面是另一加法。然后将平衡树的结果与前一次迭代的s值相加。正是通过这种展开,方法和装置获得了列表4的代码中所见的部分和。第六步骤350展开该方法和装置生成的循环以暴露更多的ilp。通过复制循环的数据流来实现展开,同时确保维持迭代之间的依赖性。展开循环可以导致更多的优化,因此该第六步骤350之后可以是第五步骤340。该方法基于配置文件130中指示的同时加载/存储的数量来展开循环。一旦第六步骤350从第五步骤接收到dfg,不再有任何循环来展开它,则dfg被发送到最后一步。图14示出了展开图12所示的滤波器子带管线循环的内循环的结果。后端复制数据流(在这种情况下为求和与乘法),然后连接数据流以保持两个迭代之间的正确依赖性,形成累加链。在边中,可以看到对存储器的更新访问以及带有用于区分的附加标签的复制变量。该展开的数据流被发送回第五步骤340,该第五步骤340应用上述优化。正是通过这种展开,该方法获得了在列表4的代码中看到的展开代码。在这种情况下,外循环展开了4倍。最后步骤360专用于通过编写带有任何指令的输出c代码来输出用于硬件加速器的程序。该方法和装置写出生成的dfg125表示的c代码,并基于配置文件130中指定的并发存储器访问的次数来添加必要的指令,例如存储器分区。最后,在步骤370中,可以将输出程序提供给硬件加速器。在替代实施例中,该方法和装置还可以通过以下方式获得输入dfg:(a)在执行应用程序时,执行具有报告dfg的文本表示(例如graphviz的点)的检测代码的应用程序;(b)执行具有报告所执行的指令的检测代码的应用程序,然后软件工具可以从执行轨迹构建dfg;(c)报告或监视所执行的汇编、字节码或中间表示指令(这可能涉及反汇编和存储器歧义消除)。(d)可以完全展开循环和内联函数并生成结果代码的dfg的编译器(当处理依赖于输入数据的值时,编译器可以依赖于关于期望的典型值、最小值、平均值和最大值的信息)。当针对不同的计算平台时,本文档的方法和装置改善了执行时间、功率和能耗。尽管已经给出了一个示例,该示例着重于用于fpga的hls工具(特别是xilinxvivadohls工具)的代码重组和指令插入,但是本发明也可以用于以下场景:(a)其他针对fpga的hls工具(例如legup),其需要在指令输出方面进行可能的修改;(b)针对asic的hls工具;(c)针对fpga的opencl代码的代码生成;(d)针对多核和/或gpu的opencl或cuda代码的代码生成;(e)针对多核cpu和多个cpu的c代码生成,可能使用线程库或用指令驱动的编程模型(例如openm.p.和openacc)扩展的c代码,来生成多线程代码;(f)适用于simd架构并适用于向量化的c代码生成;实验结果本节介绍了通过本文档的方法和装置实现的第一个实验结果。使用了一系列基准。所有基准均由操作繁重的算法(几乎没有控制流)组成,并代表了dsp算法。基准来自德州仪器[3]的dsplib,utdspbenchmarksuite[4]或来自mpeg应用程序。所使用的最简单的基准是dsplib的点积(dotproduct)。还使用了dsplib的自相关基准。1dfir基准是典型的代码,其实现了具有n个抽头的fir(有限脉冲响应)滤波器。滤波器子带基准来自mpeg应用程序。2d卷积是最大的基准,它是执行2d卷积的内核。这种卷积是utdsp的sobel边缘检测应用程序的一部分。在表1中描述了用于多个优化级别的方法和装置的有效性。级别01不应用指令或代码重组。级别02经过图3所示的所有步骤,但未实现第五步骤340的优化。级别03将自动存储器分区指令添加到上一级。级别04在第五步骤350中应用存储器优化。级别05将算术优化添加到级别03,级别06将算术优化添加到级别04。级别07和08将完全数组分区分别应用于级别05和06。表1优化级别将考虑这些优化的c代码的结果与使用手动优化的输入c代码进行比较。表2简要总结了c代码基线。可以合理地假设软件程序员可以使用一些非常基本的指令。但是,不能假定典型的软件程序员精通所有类型的指令。因此,这种评估方法允许研究该方法的有效性以及不同级别的硬件设计知识。表2用于比较的输入代码的版本比较代码简述c原始代码,无任何修改c-中使用基本指令(例如管线指令)优化的输入代码c-高使用展开和存储器分区指令改进c-中的实现表3滤波器子带基准的资源使用情况在具有32gbram的intelcorei7-7700的pc中,通过用vivadohls2017.4合成c代码并针对artixtm-7fpga,85k逻辑单元(xc7z020clg4841)获得速度和资源值。除了滤波器子带基准的约束为20ns,所有基准的时间约束均为10ns。硬件实现的总时间计算为时钟周期与延迟之间的乘积。加速是表2中实现的总时间除以不同优化级别结果的总时间的结果。图15所示的滤波器子带基准是一个很好的示例,用于示出方法和装置的各个方面,即使与c-高相比,该方法和装置在每个级别上也都表现出加速增益。图15示出了相对于原始c实现(左轴)和优化的c-高实现(右轴)的加速。显式值显示在条和点的顶部。条形图示出了原始c的加速,而圆点示出了相对于c-高的加速。级别01具有较大的加速,因为级别01暴露的ilp最多,因为基准没有循环且已完全展开。但是,其资源使用量大大超过了所用fpga的最大资源。为了限制资源使用,该方法和装置将数据流折叠成循环。通过在级别02中折叠,与c-高相比,该方法和装置可获得更好的结果。这是由于该方法和装置生成的管线所致,如列表2所示,它可以更有效地执行算法。与c-高版本相比,级别03中的加速提高到2.81倍。与c-高相比,级别04的优化可将加速提高2.55倍。这种加速是由于方法和装置每次迭代将存储器读取的数据减半所致。这对管线有很大影响,因为该方法和装置可以通过减少存储器读取量来降低管线的初始值。优化的循环是第三步骤320循环,因此不能应用第四步骤330的优化。因此,加速低于级别03。对于此示例,获得的最大频率约为54.5mhz。与c-高相比,级别05获得的加速为3.28倍。与级别03的2.81倍相比,这是一个显著的增长。算法优化不会严重影响实现的延迟或迭代间隔。迭代间隔是后续迭代之间的时间。较低的迭代间隔表示并行完成更多计算,这导致较低的延迟和较低的时钟周期数。但是,通过分离累加链,vivadohls可以不同地合成代码。执行链式求和之前,vivadohls应用了链接在一起的加法器以提高效率。但是,对于部分和,vivadohls会并行合成加法。这些加法器的实现方式不同,因此结果的频率较低,从而导致较大的加速。通过在级别06中添加算法优化,可获得3.43倍的加速。由于先前所有和的结果都保存在输出向量中,因此vivadohls必须将每个不必要的中间值写入存储器。通过平衡该链并将结果存储在局部变量中,可以消除由存储器访问引起的延迟。与c-高相比,级别07可获得5.49倍的加速,因为通过对存储器进行分区,可以实现更多的ilp。级别08的加速非常大,但由于必需的资源远远超出了目标fpga的能力,因此不包括在内。当涉及资源使用时,所有实现都使用更多的资源,因为实现方式具有更多的ilp(请参见表3)。但是,由于输出代码不再使用局部数组,而是将值存储在寄存器中,因此实现使用的bram更少。在以前的方法中,vivadohls处理了两个不同的循环,因此hls工具必须在开始新循环之前将在第一个循环中计算出的值存储在存储器中。唯一的例外是使用大量bram的级别04。这是因为实现的代码将每个和的结果存储在输出向量中。因此,要允许管线化,hls工具需要实例化附加的bram来存储和的结果,以确保不会丢失值。但是,通过在级别06中对和进行分区,vivadohls仅在最后存储在输出向量中。因此,hls工具不需要任何附加bram,而是将它们保存在寄存器中。点积是一个简单的内核。第一优化级别不会带来更好的结果。一旦该方法和装置应用了存储器分区,则该方法和装置将与c-高版本的速度匹配(请参见表4)。输出级别03比输入的基本版本和中版本(具有16.8倍和5.6倍的加速)更快。没有存储器冗余,级别04不会更改结果。级别02的最大频率为156mhz,级别03的最大频率为112mhz。表4点积的资源使用情况1dfir基准示出了第五步骤340中优化的影响。仅通过将级别02和03折叠即可获得与c-高版本接近相同的结果。这是因为该方法产生的循环与原始循环相同。与c-中相比,级别03的输出仅具有1.86倍的增益。一旦方法和装置在级别04中优化访问,与c-高版本相比加速为14.39倍,与c-中版本相比加速为26.7倍。这是对已经优化的实现的重大改进。此fir基准使用n=32抽头(系数)。因此,我们需要32个输入来计算新的输出。但是,由于先前的迭代重复使用了31个输入,因此通过这种优化只能读取一个新值,从而显著提高了性能。与级别04相比,级别06的算法优化不会影响加速。与级别05的1倍相比,级别07的优化会产生很大的影响,达到了8倍的加速。这是由于存储器分区最小化了存储器瓶颈。与c-高相比,在级别08对存储器进行分区可将级别06的加速提高到16.18倍。同样,通过使用更多的ilp可以增加资源使用量(请参见表5)。最明显的增加是在触发器(ff)中存储更多的值,而在dsp(数字信号处理)中进行更多的并发乘法。对于每个级别,最大频率为114mhz。该表中的lut表示查找表。表51dfir的资源使用情况自相关是另一个显示非常有趣结果的内核。自相关包括一小型最外层循环和一大型内循环。该方法已经通过级别02获得了积极的结果,与c-高相比增益为1.3倍,与c-中相比增益为2.7倍。这是由于最内层的循环不考虑展开代码的循环融合,该最内层的循环展开了外循环上的指令。该指令生成内循环的多个独立副本。手动展开将它们组合在单个循环中,并暴露更多的ilp。它在具有大量冗余存储器使用的自相关应用程序中具有许多好处。如果管线是分开的,那么vivadohls将不会利用内核中的冗余访问,而是计划更多的存储器读取。这种改进的循环展开能力凸显了dfg方法的另一个优势,本文档的dfg方法允许生成更好的展开循环,因为仅需要复制数据流并继续具有单个内循环。如前所述,该应用程序具有很多冗余存储器,因此该应用程序是级别04优化的主要目标。当该方法和装置优化存储器使用时,可以看到速度大大提高,比c-高的速度快7.9倍。速度的大幅提高是以资源使用量的大幅增加为代价的(请参见表6)。这种增加是由于以下事实:通过将存储器优化应用于第三步骤320循环,在第四步骤330处没有折叠,因此生成的代码展开得更多。相对于级别04,级别06中的算法优化不会增大加速。与c-高相比,级别08达到47.49倍的加速,远远大于其余级别。这是因为该方法完全划分了输入数组,并且在级别06自相关基准的情况下,在开始循环之前,有许多周期专用于读取sd值。在单个周期内全部读取它们会极大地影响输出。但是,由于自相关向量是170整数值的小输入向量,因此该划分级别是可能的。较大的向量无法完全划分。与级别06相比,级别08不会增加很多资源使用。所有级别均获得130mhz的最大频率。表6自相关的资源使用情况与2d卷积基准的某些先前情况一样,级别02和03生成相同的循环,因此与c-高相比没有加速,而与c-中相比加速为1.6倍。使用3x3内核时,每次移至下一个像素时,都需要读取9个相邻像素。由于其中的6个用于前一个像素的计算,因此仅需要3个新值。表72d卷积的资源使用情况通过在级别04应用数据重用,我们实现了与c-高相比加速为1.36倍和与c-相比加速为2.25倍。在这种情况下,由于较少的存储器访问,内循环管线获得的迭代间隔为3而不是6。加速不如预期的那样大,因为通过增加存储器重用,我们改变了循环的结构。2d卷积使用两个嵌套循环遍历2d数组。在原始代码中,外循环和内循环之间没有任何操作,因此原始代码是一个完美的循环。通过优化存储器访问,可以在进入内循环之前加载缓冲区,因此外循环不再是完美的循环。以前,vivadohls自动拉平循环并优化执行。没有不可能的完美循环,并且改善也不如预期的高。资源使用量仅比c-高版本略大(请参见表7)。2d卷积比其他基准具有更多的操作,vivadohls无法完全实现它。因此,没有针对级别01的结果。在级别06中,通过结合加速和算法优化来提高这种加速。此处的差异点是优化循环中的除法。由于除数在每次迭代中都是通用的,因此该方法在循环外部计算倒数,并通过与该倒数相乘来代替除法。由于在硬件中乘法比除法更高效,因此管线深度减少了。因此,该级别的加速为1.64倍。级别05的结果表明,没有数据重用的算法优化不会仅仅因为循环变平而产生很大的影响。像在级别06中一样,迭代延迟减少了,但是由于循环变平,实现仅具有一个循环,而在具有许多步骤的大型管线中降低迭代延迟并没有太大影响,因为在开始管线之前仍然需要在循环外部实现除法。在没有循环变平的级别06上,较小的管线将在循环中执行多次,因此减少迭代延迟会产生更大的影响。分区优化的另一个好处是分区优化可以降低资源使用量(请参见表7)。在级别07和08中对数组进行分区时,加速分别达到2.99倍和2.5倍。与其他情况不同,级别07具有比级别08更好的实现。这是由于vivadohls在这种情况下实现了两种解决方案的方式。级别08的管线具有比级别07更低的交互间隔和更低的深度。08的分区实际上执行得更好,但是vivadohls的实现使结果恶化,因为内循环展开了2倍,而vivadohls以比单个乘法器更大的频率在单个单位中实施了最后两个乘法。这不会在07中发生,因此频率较低,从而导致更高的加速。对于级别07,如果应用存储器分区而不是算法分区,则加速将仅为2.27倍,因为累加链降低了实现的效率。因此,这不仅仅是使用指令对存储器进行分区的问题。还必须重组代码以解锁更多的ilp和更大的加速。该基准的每个优化级别均达到114mhz的最大频率。所有c代码都是由方法和装置完全生成的,而无需人工干预,所呈现的结果强烈表明了该方法的实用性,特别是本文的方法和装置的实用性。测量了后端135的执行时间。对于大多数基准,执行时间在1-2秒之间,但2d卷积基准平均要在11到12秒之间,因为2d卷积基准也是dfg最大的基准。另一个例外是自相关基准的级别04,其在5秒钟内执行。由于存储器优化,没有第四步骤330的折叠,并且大的dfg被输入到输出代码步骤370。最快的级别是02和03。尽管级别01没有实现优化,但是输出大的dfg导致较长的执行时间。级别04的执行时间的增加取决于优化循环的复杂度和大小。为了分析数据集大小以及输入dfg大小对后端执行时间的影响,针对2d卷积基准的不同输入大小,测量了后端的执行时间。为测量选择的优化级别是07。测量包括完成步骤310到360直到在步骤360中生成c代码以及输入图像大小为64x64、96x96、128x128和160x160时所需的执行时间。输入大小为96x96时,执行后端需要50秒。通过将此输入大小增加到128x128,后端执行需要近2.8分钟的时间。160x160的输入图像在后端处理大约需要7分钟。假设迭代之间的增长率保持一致,则处理256x256输入图像大约需要28分钟,这对于适度的像素分辨率是需要时间的。因此,该方法的当前实现对于大型输入轨迹不是非常可扩展的。分析每个步骤所需的时间,很明显,较大增加的原因是处理第二步骤310所需的时间。由于第三步骤320总是将输入dfg压缩为相同的大小的输入大小,因此第四至第七步骤330至360所需的时间不会改变,其取决于输入大小。对于较大的输入,第三步骤320也不会花费更长的时间。因为第二步骤310的处理允许第三步骤320的匹配被有效地应用。第二步骤310需要大量的执行时间。96x96像素的输出图像具有9216个输出,而128x128具有16384个输出,即几乎是输出的两倍。如上所述,后端隔离了生成输出的每个数据流。对每个节点进行分级,然后比较公共节点。这意味着对于一个128x128的图像,后端将生成、分级和比较16384个数据流。一种加速后端并使该方法更具可扩展性的方式将是第二步骤310的更有效实现。例如,可以在生成输出的dfg时优化第二步骤310以分离公共节点和唯一节点。当前,该方法和装置尝试在给定配置的情况下优化速度。然而,该方法和装置除了增加折叠的水平或改变并发加载/存储的数量之外,没有提出处理资源使用的直接方式。但是,这些间接方式可能会不必要地限制优化。另外,一些优化(诸如第五步骤340的数据重用)可能导致高资源使用。因此,有可能考虑两个方面来控制资源使用:(a)选择后端优化;(b)选择指令来控制hls工具。对于vivadohls,减少资源使用的直接方式是通过资源分配指令。vivadohls允许限制资源数量或特定数量的并发操作。例如,通过将基准自相关的级别04的并发乘法数量限制为40,所得到的实现仅使用40个dsp(而不是160个),但是c-高的加速是6.09倍(而不是7.91倍)。因此,使用四分之一的dsp时,加速仅降低到原始实现的77%。该示例示出了一个直接限制资源而又不大大影响加速的简单情况。因此,可能实现潜在的更多配置以引导后端135插入指令以限制资源。本公开提出了一种转换软件代码以使其更适合于高级综合(hls)工具的方法。该方法基于通过执行先前添加了检测代码的应用程序的关键函数而当前获得的计算(在算术、逻辑、运算符级别)的数据流图(dfg)表示。该方法主要依赖于折叠和展开图操作,并已经以一种能够完全重组关键应用程序内核的代码的方法实现。尽管在当前工作中,c代码被认为是输入,但是这种方法有可能通过包含足够的检测代码来解决不同的输入编程语言。该方法的后端135能够以hls友好的方式自动重构dfg并生成添加有指令的c代码。取得的成果非常有希望。当与原始c代码比较时,由本公开的方法和装置生成的c代码优于它们,并且实现了显著的加速。所获得的c代码甚至可比较,并且在大多数情况下,都比带有指令的手动优化c代码更好。因此,该方法可以使软件开发人员能够使用典型的hls工具作为后端135来实现高效的硬件加速器,而无需hls专家的支持。致谢inesctec在这项工作的开发过程中,在“tec4growth-tl-smiles-5具有工业影响力的普及智能,增强和概念证明(tec4growth-tl-smiles-5pervasiveintelligence,enhancersandproofsofconceptwithindustrialimpact)”项目下提供了赠款(norte-01-0145-feder-00020),以及contextwa项目(poci-01-0145-feder-016883)的资金均由欧洲区域发展基金资助。参考文献[1]r.nane,v.m.sima,c.pilato,j.choi,b.fort,a.canis,y.t.chen,h.hsiao,s.brown,f.ferrandi,j.anderson和k.bertels。fpga高级综合工具的调查和评估(asurveyandevaluationoffpgahigh-levelsynthesistools)。ieee集成电路和系统计算机辅助设计学报,35(10):1591–1604,2016年10月。[2]m.p.cardoso和markusweinhardt。高级综合(high-levelsynthesis),第23-47页。施普林格国际出版公司(cham),2016年。[3]德州仪器(ti),tms320c6000dsp库(dsplib),于2018年6月16日访问。urlhttp://www.ti.com/tool/sprc265[4]corinag.lee,2002年8月15日,于2018年6月16日访问。网址http://www.eecg.toronto.edu/~corinna/dsp/infrastructure/utdsp.tar.gz[5]cong,jasonhuang,muhuanpan,peichenwang,yuxinzhang,peng.(2016)。hls的源到源优化(source-to-sourceoptimizationforhls),第137-163页。施普林格国际出版公司,cham,2016年。[6]j.m.p.cardoso,j.teixeira,j.c.alves,r.nobre,p.c.diniz,j.g.f.coutinho和w.luk。为基于fpga的系统指定编译器策略(specifyingcompilerstrategiesforfpga-basedsystems)。在2012年ieee第20届国际现场可编程定制计算机研讨会上,第192-199页,2012年4月。[7]o.mencer。asc:用于使用fpga计算的流编译器(asc:astreamcompilerforcomputingwithfpgas)。ieee集成电路和系统的计算机辅助设计学报,25(9):1603–1617,2006年9月。[8]andrewcanis,jongsokchoi,markaldham,victorvictor,ahmedkammoona,tomaszczajkowski,stephend.brown和jasonh.anderson。legup:一种用于基于fpga的处理器/加速器系统的开源高级综合工具(legup:anopen-sourcehigh-levelsynthesistoolforfpgabasedprocessor/acceleratorsystems)。acmtrans。嵌入。计算。syst,13(2):24:1-24:27,2013年9月。[9]llvm。llvm编译器基础结构项目(thellvmcompilerinfrastructureproject),2018年。urlhttps://llvm.org。[10]maxelertechnologies。maxcompiler白皮书,2017年。https://www.maxeler.com/media/documents/maxelerwhitepaperprogramming.pdf。[11]n.voss,s.girdlestone,o.mencer和g.gaydadjiev。自动数据流图合并(automateddataflowgraphmerging)。在2016年嵌入式计算机系统国际会议:架构,建模和仿真(samos16),第219-226页,2016年7月。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1