基于图像域模板匹配的视频监控监管区域多设备联动方法与流程
本发明涉及图像处理、模式识别与深度学习,属于智能安防领域。
背景技术:
目前,在煤炭生产、危险品生成与存储、冶金等高危行业中,存在一些严禁人员靠近的高危险区域,如危险品容器设备、高压变电箱、皮带通廊、高温锅炉等,这些危险区域一旦有人员靠近,不仅容易发生安全事故,威胁工作人员生命安全,而且影响企业正常生产运营,降低企业运行效率。
防止人员靠近危险区最直接的方法是设立警示牌与围栏,但由于侥幸心理、麻痹心理和惰性心理的存在,一些安全意识薄弱的工作人员依然会不顾危险警示违规靠近危险区,为了保障人员安全,目前企业解决该问题的方法通常是采用实时视频监控的方式进行安全监管,但监管水平与视频监控值守人员的注意力息息相关,甚至值守人员工作态度消极懈怠,使监控视频仅能发挥事故追溯的作用,而且一般事故发生时间短,仅靠视频监控值守人员预判危险发生,存在着危险识别不准确、响应滞后等缺点。
技术实现要素:
本发明采用深度学习、模式识别与图像处理技术,实现实时目标监管区域判别与设备联动,应用于工业复杂高危作业环境下的安全保障,针对视频监控图像进行目标定位,对目标所属监管区域进行判别,可在第一时间发现险情,并紧急进行相应的设备联动处理,从而降低事故的发生概率,保障企业安全生产。
本发明的技术方案:
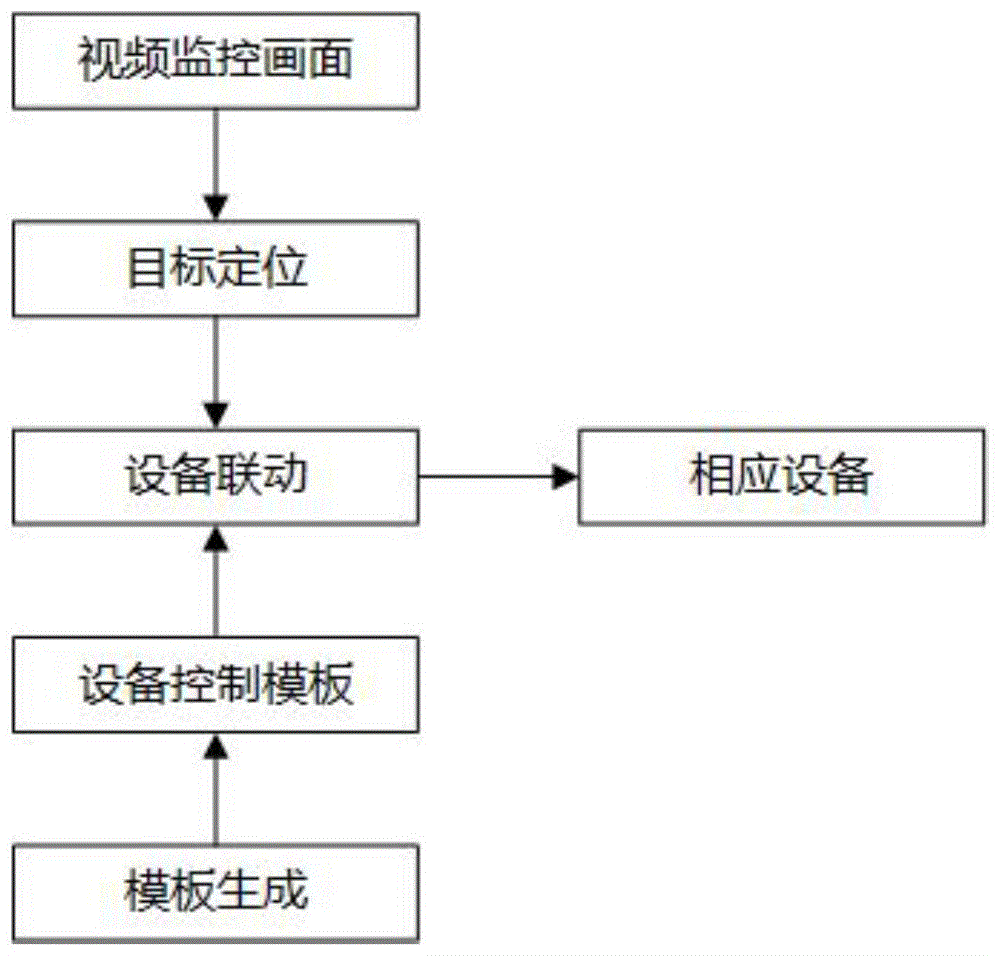
基于图像域模板匹配的视频监控监管区域多设备联动方法,包括模板生成、目标定位和设备联动,模板生成部分生成的图像域设备控制模板是设备联动的基础,目标定位部分对输入视频监控画面图像进行检测,定位出目标在视频监控画面中的坐标,并将坐标信息输入到设备联动部分,设备联动部分根据目标坐标信息,通过设备控制模板,判别出目标是否处于监管区域,并进行相应的设备联动。
进一步地、所述模板生成包括模板初始化和模板填充,模板初始化部分生成一个像素值全零的灰度图,该灰度图的尺寸与视频监控图像的尺寸一致,作为初始设备控制模板;模板填充部分在视频监控图像中选取一个封闭区域作为监管区域,得到该监管区域像素的坐标集合,将设备控制模板中属于该坐标集合的像素值设置为该监管区域相对应的设备编号,循环选取监管区域与设置像素值,直至模板生成结束,设备控制模板用于设备联动部分的模板匹配。
进一步地、所述目标定位包括视频画面获取模块、图像预处理模块和目标定位模块三部分,视频画面获取模块通过读取监控摄像头ip地址,获取摄像头实时视频监控画面图像,并将视频监控图像逐帧输入到图像预处理模块;图像预处理模块将获取的单帧视频监控图像进行去噪、去雾、增亮、对比度拉伸等预处理,获得更易于后续处理的高质量图像;目标定位模块通过基于深度学习的fasterr-cnn方法,利用已训练好的目标识别模型,进行目标检测,判断是否有目标出现,若目标出现,则定位出目标在图像中的坐标,获取目标在视频监控图像中的坐标信息。
进一步地、所述设备联动根据目标定位输入的目标在视频监控图像中的坐标,获取设备控制模板在相同坐标下的像素值n',若该像素值n'=0,则判断目标处于非监管区域,否则判断目标处于监管区域,且该监管区域对应的设备编号为n',进而可进行相应设备的联动。
进一步地、所述模板生成部分生成图像域设备控制模板中,监控区域是不规则的封闭区域,同一个视频监控下的对应设备数目可以是一个或者多个,模板生成部分生成的设备控制模板用于设备联动部分的模板匹配。
进一步地、所述目标定位部分,通过对视频监控图像进行处理,判断是否有目标出现,若目标出现,则定位出目标在图像中的坐标,并将坐标信息输入到设备联动部分。
进一步地、所述设备联动部分根据目标坐标信息,通过模板生成部分生成的图像域设备控制模板,判别目标是否处于监管区域,若目标处于监管区域,则获取设备编号,进行相应的设备联动。
进一步地、所述设备控制模板是一个灰度图,该灰度图与视频监控的尺寸一致。
进一步地、所述设备控制模板在视频监控图像中监管区域对应位置的像素值为相应设备编号,其余位置像素值为0。
进一步地、所述目标定位部分通过基于深度学习的fasterr-cnn方法判断视频监控画面中是否有目标出现,若有目标出现,则给出目标在视频监控画面中的坐标。
本发明相对于现有技术具有以下有益效果:
1.本发明创新性的利用模板匹配的方法进行视频监控监管区域多设备联动,并将匹配模板图像化,减少了计算量与逻辑判断复杂度,具有一定的方法优越性。
2.本发明所提的图像域设备控制模板,对视频监控画面的旋转、尺度缩放变化保持了一定程度的不变性,克服了传统模板匹配法的局限性。
3.本发明对目标所属监管区域进行判别,适合在工业高危环境下防止人员违规进入危险区域,可在第一时间发现险情,并紧急进行相应的设备联动处理,从而降低事故的发生概率,保障企业安全生产。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过发明的实践了解到。
附图说明
图1是基于图像域模板匹配的视频监控监管区域多设备联动方法的流程图;
图2是本发明的模板生成方法流程图;
图3是本发明的方法总体流程图。
具体实施方式
以下将结合附图对本发明进行详细说明。
结合图1-3所示,本实施例公开的基于图像域模板匹配的视频监控监管区域多设备联动方法,包括模板生成、目标定位和设备联动,模板生成部分生成的图像域设备控制模板是设备联动的基础,目标定位部分对输入视频监控画面图像进行检测,定位出目标在视频监控画面中的坐标,并将坐标信息输入到设备联动部分,设备联动部分根据目标坐标信息,通过设备控制模板,判别出目标是否处于监管区域,并进行相应的设备联动。
结合图1-3所示,本实施例公开的基于图像域模板匹配的视频监控监管区域多设备联动方法,所述模板生成包括模板初始化和模板填充,模板初始化部分生成一个像素值全零的灰度图,该灰度图的尺寸与视频监控图像的尺寸一致,作为初始设备控制模板;模板填充部分在视频监控图像中选取一个封闭区域作为监管区域,得到该监管区域像素的坐标集合,将设备控制模板中属于该坐标集合的像素值设置为该监管区域相对应的设备编号,循环选取监管区域与设置像素值,直至模板生成结束,设备控制模板用于设备联动部分的模板匹配,利用模板匹配的方法进行视频监控监管区域多设备联动,并将匹配模板图像化,减少了计算量与逻辑判断复杂度,具有一定的方法优越性。
结合图1-3所示,本实施例公开的基于图像域模板匹配的视频监控监管区域多设备联动方法,所述目标定位包括视频画面获取模块、图像预处理模块和目标定位模块三部分,视频画面获取模块通过读取监控摄像头ip地址,获取摄像头实时视频监控画面图像,并将视频监控图像逐帧输入到图像预处理模块;图像预处理模块将获取的单帧视频监控图像进行去噪、去雾、增亮、对比度拉伸等预处理,获得更易于后续处理的高质量图像;目标定位模块通过基于深度学习的fasterr-cnn方法,利用已训练好的目标识别模型,进行目标检测,判断是否有目标出现,若目标出现,则定位出目标在图像中的坐标,获取目标在视频监控图像中的坐标信息,图像域设备控制模板,对视频监控画面的旋转、尺度缩放变化保持了一定程度的不变性,克服了传统模板匹配法的局限性。
结合图1-3所示,本实施例公开的基于图像域模板匹配的视频监控监管区域多设备联动方法,所述设备联动根据目标定位输入的目标在视频监控图像中的坐标,获取设备控制模板在相同坐标下的像素值n',若该像素值n'=0,则判断目标处于非监管区域,否则判断目标处于监管区域,且该监管区域对应的设备编号为n',进而可进行相应设备的联动。
更为具体地:所述模板生成部分生成图像域设备控制模板中,监控区域是不规则的封闭区域,同一个视频监控下的对应设备数目可以是一个或者多个,模板生成部分生成的设备控制模板用于设备联动部分的模板匹配。
更为具体地:所述目标定位部分,通过对视频监控图像进行处理,判断是否有目标出现,若目标出现,则定位出目标在图像中的坐标,并将坐标信息输入到设备联动部分。
更为具体地:所述设备联动部分根据目标坐标信息,通过模板生成部分生成的图像域设备控制模板,判别目标是否处于监管区域,若目标处于监管区域,则获取设备编号,进行相应的设备联动。
更为具体地:所述设备控制模板是一个灰度图,该灰度图与视频监控的尺寸一致。
更为具体地:所述设备控制模板在视频监控图像中监管区域对应位置的像素值为相应设备编号,其余位置像素值为0。
更为具体地:所述目标定位部分通过基于深度学习的fasterr-cnn方法判断视频监控画面中是否有目标出现,若有目标出现,则给出目标在视频监控画面中的坐标,本发明对目标所属监管区域进行判别,适合在工业高危环境下防止人员违规进入危险区域,可在第一时间发现险情,并紧急进行相应的设备联动处理,从而降低事故的发生概率,保障企业安全生产。
结合图1所示,本实施例公开的基于图像域模板匹配的视频监控监管区域多设备联动方法,模板生成部分的具体方法步骤为:
步骤1,模板初始化,生成一个像素值全零的灰度图,该灰度图的尺寸与视频监控图像的尺寸一致,作为设备控制模板;
步骤2,在视频监控图像中选取一个封闭区域作为监管区域,得到该监管区域像素的坐标集合(x,y);
步骤3,将设备控制模板中属于(x,y)坐标的数值设置为相应的设备编号;
步骤4,判断模板生成是否结束,若未结束,则执行步骤2,否则,方法运行结束。
结合图2所示,本实施例公开的基于图像域模板匹配的视频监控监管区域多设备联动方法,具体方法步骤为:
步骤a,通过读取摄像头ip地址,获取摄像头实时视频流;
步骤b,判断视频输入是否结束,若是,则方法运行结束,否则执行步骤c;
步骤c,获取下一帧摄像头视频监控图像;
步骤d,将获取的视频监控图像进行去噪、去雾、增亮、对比度拉伸等预处理;
步骤e,通过基于深度学习的fasterr-cnn方法,利用已训练好的识别模型,进行目标检测,若有目标则执行步骤f,否则执行步骤b;
步骤f,定位出目标在视频监控图像中的坐标(x,y);
步骤g,获取设备控制模板在(x,y)坐标下的数值s,若s≠0,则执行步骤h,否则执行步骤b;
步骤h,联动控制设备编号为s的设备,执行步骤b。
以上实施例只是对本专利的示例性说明,并不限定它的保护范围,本领域技术人员还可以对其局部进行改变,只要没有超出本专利的精神实质,都在本专利的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!