数据处理的方法与装置与流程
1.本技术涉及人工智能领域,具体涉及一种数据处理的方法与装置。
背景技术:
2.随着互联网技术快速发展,产生信息过载(information overload)的问题。为了解决信息过载的问题,推荐系统(recommender system,rs)应运而生。在推荐系统中,点击率 (click-through rate,ctr)预估是非常重要的一个环节,判断一个商品是否进行推荐,需要根据预估的ctr来进行。在进行ctr预估时,除了考虑单个特征外,还需要考虑特征之间的组合。为了表征特征之间的组合,因子分解机(factorization machine,fm)模型被提了出来,fm模型中包括单个特征的所有组合情况的特征组合项。现有技术,通常采用基于fm构建ctr预估模型。
3.fm模型中的特征组合项的数量随特征组合的阶数呈指数上升,因此,当特征组合的阶数越来越高,特征组合项的数量是巨大的,导致fm模型的训练的计算量超大。针对这个问题,特征组合筛选(feature interaction selection,fis)被提出来。由于手工进行特征组合筛选费时费力,业界提出自动特征组合筛选(automatic feature interaction selection, autofis)。
4.现有的自动特征组合筛选方案,通过在所有可能的特征组合子集构成的搜索空间中搜索最优的子集,来实现特征组合筛选,搜索过程耗能高,算力消耗大。
技术实现要素:
5.本技术提供一种数据处理的方法与装置,可以减小特征组合筛选的计算量和算力消耗。
6.第一方面,提供了一种数据处理的方法,该方法包括:为第一模型中的每个特征组合项添加架构参数,得到第二模型,其中,所述第一模型为基于因子分解机fm的模型,所述架构参数用于表征相应特征组合项的重要性;对所述第二模型中的所述架构参数进行优化学习,获得优化后的架构参数;根据所述优化后的架构参数,基于所述第一模型或所述第二模型,获得经过特征组合项删减后的第三模型。
7.基于fm的模型表示基于fm原理构建的模型,例如包括如下中任一种模型:fm模型、deepfm模型、ipnn模型、afm模型与nfm模型等。
8.第三模型可以是在第一模型基础上进行特征组合项删减后得到的模型。
9.或者,第三模型可以是在第二模型基础上进行特征组合项删减后得到的模型。
10.其中,可以采用多种方式,确定要删减的特征组合项,或者说,确定要保留(即筛选) 的特征组合项。
11.可选地,作为一种实现方式,可以将优化后的架构参数中取值小于阈值的架构参数对应的特征组合项删除。
12.其中,该阈值用于表征是否保留特征组合项的判断准则,例如,若一个特征组合项
的优化后的架构参数的取值小于该阈值,则表明,该特征组合项被删除,若一个特征组合项的优化后的架构参数的取值达到该阈值,则表明,该特征组合项被保留(即被筛选)。
13.该阈值可以根据实际应用需求确定。例如,可以通过模型训练的方式,获取该阈值的取值。本技术对该阈值的获取方式不作限定。
14.可选地,作为另一种实现方式,在一些架构参数在优化结束后取值变为零的情况下,可以直接将优化后取值不为零的架构参数所对应的特征组合项作为保留的特征组合项,得到第三模型。
15.可选地,作为又一种实现方式,在一些架构参数在优化结束后取值变为零的情况下,进一步地,在优化后取值不为零的架构参数所对应的特征组合项中,将取值小于阈值的架构参数对应的特征组合项删除,得到第三模型。
16.在现有的自动特征组合筛选的方案中,将所有可能的特征组合子集当作搜索空间 (search space),用离散算法在随机抽取的n个候选子集中选出最好的候选子集作为筛选后的特征组合。其中,在评估每个候选子集时,均需要执行一遍训练操作,导致计算量大,消耗算力大。
17.在本技术中,通过在基于fm的模型中引入架构参数,通过对架构参数的优化学习,可以实现特征组合项的筛选。也就是说,本技术只需执行架构参数的优化学习,这样的一次模型训练过程,就可以实现特征组合项筛选,而无需现有技术中针对多个候选子集的多遍训练,因此,可以有效减小特征组合筛选的计算量,从而可以节省算力,同时可以提高特征组合筛选的效率。
18.此外,现有的自动特征组合筛选方案由于计算量大,消耗算力大,导致无法应用于训练时间较长的深度学习模型。
19.在本技术中,只需通过架构参数的优化学习过程,就可实现特征组合筛选,或者说,只需一次端到端的模型训练过程,即可完成特征组合项的筛选,使得特征组合项的筛选(或搜索)的时间可以等价于一次模型训练的时间,因此,可以应用于训练时间较长的深度学习模型。
20.现有技术的fm模型,由于需要枚举所有特征组合情况,导致很难扩展到更高阶。
21.在本技术中,通过在基于fm的模型中引入架构参数,并通过架构参数的优化学习,可以实现特征组合筛选,因此,本技术的方案,可以支持基于fm的模型中的特征组合项扩展到更高阶。
22.可以采用多种优化算法(或优化器)对第二模型中的所述架构参数进行优化学习。
23.结合第一方面,在第一方面的一种可能的实现方式中,所述优化学习使得,所述优化后的架构参数呈现稀疏性。
24.在本技术中,通过对架构参数的优化学习,使得架构参数呈现稀疏性,有利于后续特征组合项的删减。
25.可选地,在所述优化学习使得所述优化后的架构参数呈现稀疏性的实现方式中,所述根据所述优化后的架构参数,基于所述第一模型或所述第二模型,获得经过特征组合项删减后的第三模型,包括:基于所述第一模型或所述第二模型,将所述优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得所述第三模型。
26.作为一种实现方式,在第一模型中,将所述优化后的架构参数中取值小于阈值的
架构参数所对应的特征组合项删减,获得所述第三模型。
27.作为另一种实现方式,在第二模型中,将所述优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得所述第三模型。
28.应理解,在第二模型的基础上经过特征组合项删减,获得第三模型,可以使得第三模型中具有优化后的表征特征组合项的重要性的架构参数,后续通过第三模型的训练,可以进一步学习特征组合项的重要性。
29.结合第一方面,在第一方面的一种可能的实现方式中,所述优化学习使得,至少一个特征组合项的架构参数的取值在优化结束后等于零。
30.假设将优化结束后取值为零的架构参数对应的特征组合项视为不重要的特征组合项,则所述优化学习使得,至少一个特征组合项的架构参数的取值在优化结束后等于零,可以视为,可以使得不重要的特征组合项的架构参数在优化结束后等于零。
31.可选地,所述优化学习,使用grda优化器对所述第二模型中的所述架构参数进行优化,所述grda优化器使得至少一个特征组合项的架构参数的取值在优化过程中趋向于零。
32.在本技术中,通过架构参数的优化学习使得一些架构参数趋向于零,相当于在架构参数的优化过程中就剔除了一些不重要的特征组合项,或者说,通过架构参数的优化学习,既实现了架构参数的优化,又实现了特征组合项的筛选,可以有效提高特征组合筛选的效率,进一步减少计算量和算力消耗。
33.此外,在架构参数的优化过程中,剔除一些不重要的特征组合项,还可以避免这些不重要的特征组合项所产生的噪声,从而可以使得在架构参数的优化过程中模型就逐渐接近理想模型,这样也可以使得模型中的其他参数(例如,未剔除的特征组合项的架构参数与模型参数)的估计更加准确。
34.可选地,在所述优化学习使得优化后的架构参数呈现稀疏性,并使得至少一个特征组合项的架构参数的取值在优化结束后等于零的实现方式中,所述根据所述优化后的架构参数,基于所述第一模型或所述第二模型,获得经过特征组合项删减后的第三模型,包括:将优化后的架构参数对应的特征组合项之外的特征组合项删除,获得第三模型。
35.可选地,在第一模型中,将优化后的架构参数对应的特征组合项之外的特征组合项删除,获得第三模型。即第三模型是在第一模型基础上进行特征组合项删减后得到的。
36.可选地,将完成架构参数优化后的第二模型作为第三模型。即第三模型是在第二模型基础上进行特征组合项删减后得到的。
37.应理解,在第二模型的基础上经过特征组合项删减,获得第三模型,可以使得第三模型中具有优化后的表征特征组合项的重要性的架构参数,后续通过第三模型的训练,可以进一步学习特征组合项的重要性。
38.可选地,在所述优化学习使得优化后的架构参数呈现稀疏性,并使得至少一个特征组合项的架构参数的取值在优化结束后等于零的实现方式中,所述根据所述优化后的架构参数,基于所述第一模型或所述第二模型,获得经过特征组合项删减后的第三模型,包括:将优化后的架构参数对应的特征组合项之外的特征组合项删除,再将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。
39.可选地,第一模型中,将优化后的架构参数对应的特征组合项之外的特征组合项
删除,再将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。
40.可选地,在完成架构参数优化后的第二模型中,将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。
41.应理解,在第二模型的基础上经过特征组合项删减,获得第三模型,可以使得第三模型中具有优化后的表征特征组合项的重要性的架构参数,后续通过第三模型的训练,可以进一步学习特征组合项的重要性。
42.结合第一方面,在第一方面的一种可能的实现方式中,所述方法还包括对所述第二模型中的模型参数进行优化学习,所述优化学习包括,对所述第二模型中的模型参数进行标量化处理。
43.模型参数表示,第二模型中除了架构参数之外,特征组合项本身的权重参数。或者说,模型参数表示第一模型中原有的参数。
44.作为一种实现方式,所述优化学习包括,对所述第二模型中的模型参数进行批量归一化(batch normalization,bn)处理。
45.应理解,通过对特征组合项的模型参数进行标量化处理,可以实现该特征组合项的模型参数与架构参数的去耦合,可以使得架构参数能更准确地体现该特征组合项的重要性,进而可以提高架构参数的优化准确度。
46.结合第一方面,在第一方面的一种可能的实现方式中,对所述第二模型中的所述架构参数进行优化学习和对所述第二模型中的所述模型参数进行优化学习,包括:使用相同的训练数据,对所述第二模型中的架构参数与模型参数同时进行优化学习,获得优化后的架构参数。
47.换句话说,在优化过程的每轮训练中,基于同一批训练数据,对架构参数与模型参数同时进行优化学习。
48.或者说,将第二模型中的架构参数与模型参数视为同一级别的决策变量,对第二模型中的架构参数与模型参数同时进行优化学习,获得优化后的架构参数。
49.在本技术中,通过对第二模型中的架构参数与模型参数进行一层优化处理,以实现第二模型中的架构参数的优化学习,可以实现架构参数与模型参数的同时优化,从而可以减小第二模型中的架构参数的优化学习过程的耗时,进而有助于提高特征组合项筛选的效率。
50.结合第一方面,在第一方面的一种可能的实现方式中,所述方法还包括:训练所述第三模型,以得到点击率ctr预估模型或转化率cvr预估模型。
51.第二方面,提供了一种数据处理的方法,该方法包括:将目标对象的数据输入点击率ctr预估模型或转化率cvr预估模型,获得所述目标对象的预估结果;根据所述目标对象的预估结果,确定所述目标对象的推荐情况。
52.其中,所述ctr预估模型或所述cvr预估模型通过第一方面的方法获得。
53.其中,训练第三模型的步骤包括:使用该目标对象的训练样本,训练第三模型,以得到ctr预估模型或cvr预估模型。
54.可选地,对架构参数进行优化学习的步骤包括:使用所述目标对象的训练样本中相同的训练数据,对所述第二模型中的架构参数与模型参数同时进行优化学习,获得优化
后的架构参数。
55.第三方面,提供一种数据处理的装置,该装置包括如下单元。
56.第一处理单元,用于为第一模型中的每个特征组合项添加架构参数,得到第二模型,其中,所述第一模型为基于因子分解机fm的模型,所述架构参数用于表征相应特征组合项的重要性。
57.第二处理单元,用于对所述第二模型中的所述架构参数进行优化学习,获得优化后的架构参数。
58.第三处理单元,用于根据所述优化后的架构参数,基于所述第一模型或所述第二模型,获得经过特征组合项删减后的第三模型。
59.结合第三方面,在第三方面的一种可能的实现方式中,所述第二处理单元对架构参数进行的优化学习使得,所述优化后的架构参数呈现稀疏性。
60.结合第三方面,在第三方面的一种可能的实现方式中,所述第三处理单元用于,基于所述第一模型或所述第二模型,将所述优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得所述第三模型。
61.结合第三方面,在第三方面的一种可能的实现方式中,所述第二处理单元对架构参数进行的优化学习使得,至少一个特征组合项的架构参数的取值在优化结束后等于零。
62.结合第三方面,在第三方面的一种可能的实现方式中,所述第三处理单元用于,使用广义正规对偶平均grda优化器对所述第二模型中的所述架构参数进行优化,所述grda 优化器使得至少一个特征组合项的架构参数的取值在优化过程中趋向于零。
63.结合第三方面,在第三方面的一种可能的实现方式中,所述第二处理单元还用于,对所述第二模型中的模型参数进行优化学习,所述优化学习包括,对所述第二模型中的模型参数进行标量化处理。
64.结合第三方面,在第三方面的一种可能的实现方式中,所述第二处理单元用于,对所述第二模型中的模型参数进行批量归一化bn处理。
65.结合第三方面,在第三方面的一种可能的实现方式中,第二处理单元用于,使用相同的训练数据,对所述第二模型中的架构参数与模型参数同时进行优化学习,获得优化后的架构参数。
66.结合第三方面,在第三方面的一种可能的实现方式中,所述装置还包括:训练单元用于,训练所述第三模型,以得到ctr预估模型或cvr预估模型。
67.第四方面,提供一种数据处理的装置,该装置包括如下单元。
68.第一处理单元用于,将目标对象的数据输入点击率ctr预估模型或转化率cvr预估模型,获得所述目标对象的预估结果。
69.第一处理单元用于,根据所述目标对象的预估结果,确定所述目标对象的推荐情况。
70.其中,所述ctr预估模型或所述cvr预估模型通过第一方面的方法获得。
71.其中,训练第三模型的步骤包括:使用该目标对象的训练样本,训练第三模型,以得到ctr预估模型或cvr预估模型。
72.可选地,对架构参数进行优化学习的步骤包括:使用所述目标对象的训练样本中相同的训练数据,对所述第二模型中的架构参数与模型参数同时进行优化学习,获得优化
后的架构参数。
73.第五方面,提供一种图像处理的装置,该装置包括:存储器,用于存储程序;处理器,用于执行存储器存储的程序,当存储器存储的程序被执行时,处理器用于执行上述第一方面或第二方面中的方法。
74.第六方面,提供一种计算机可读介质,该计算机可读介质存储用于设备执行的程序代码,该程序代码包括用于执行上述第一方面或第二方面中的方法。
75.第七方面,提供一种包含指令的计算机程序产品,当该计算机程序产品在计算机上运行时,使得计算机执行上述第一方面或第二方面中的方法。
76.第八方面,提供一种芯片,所述芯片包括处理器与数据接口,所述处理器通过所述数据接口读取存储器上存储的指令,执行上述第一方面或第二方面中的方法。
77.可选地,作为一种实现方式,所述芯片还可以包括存储器,所述存储器中存储有指令,所述处理器用于执行所述存储器上存储的指令,当所述指令被执行时,所述处理器用于执行上述第一方面或第二方面中的方法。
78.第九方面,提供一种电子设备,该电子设备包括上述第三方面、第四方面、第五方面或第六方面提供的装置。
79.基于上文描述可知,在本技术中通过在基于fm的模型中引入架构参数,并通过架构参数的优化学习,可以实现特征组合项的筛选。也就是说,本技术通过架构参数的优化学习可以实现特征组合项的筛选,而无需现有技术中针对多个候选子集的多遍训练,因此,可以有效减小特征组合筛选的计算量,从而可以节省算力,同时可以提高特征组合筛选的效率。
80.此外,采用本技术提供的方案,可以支持基于fm的模型中的特征组合项扩展到更高阶。
附图说明
81.图1是fm模型的架构示意图。
82.图2是fm模型的训练示意图。
83.图3是本技术实施例提供的数据处理的方法的示意性流程图。
84.图4是本技术实施例中的fm模型的架构示意图。
85.图5是本技术实施例提供的数据处理的方法的另一示意性流程图。
86.图6是本技术实施例提供的数据处理的方法的又一示意性流程图。
87.图7是本技术实施例提供的数据处理的装置的示意性框图。
88.图8是本技术实施例提供的数据处理的装置的另一示意性框图。
89.图9是本技术实施例提供的数据处理的装置的又一示意性框图。
90.图10是本技术实施例提供的一种芯片硬件结构示意图。
具体实施方式
91.下面将结合附图,对本技术中的技术方案进行描述。
92.随着当今技术的飞速发展,数据量与日俱增,为了解决信息过载(information overload) 的问题,推荐系统(recommender system,rs)被提了出来。推荐系统通过将用户
的历史行为或者用户的兴趣偏好或者用户的人口统计学特征送给推荐算法,然后推荐系统运用推荐算法来产生用户可能感兴趣的项目列表。
93.在推荐系统中,点击率(click-through rate,ctr)预估(或者还包括转化率(conversionrate,cvr)预估)是非常重要的一个环节。判断一个商品的是否进行推荐需要根据预估的点击率来进行。在进行ctr预估时,除了考虑单特征外,往往还要考虑特征之间的组合。特征组合对于推荐排序非常重要,因子分解机(factorization machine,fm)可以体现特征之间的组合。因子分解机可以简称为fm模型。
94.根据特征组合项的最大阶数,fm模型可以称为*阶fm模型。例如,特征组合项的阶数最大为二阶的fm模型可以称为二阶fm模型,特征组合项的阶数最大为三阶的fm模型可以称为三阶fm模型。
95.特征组合项的阶数表征特征组合项是几个特征的交互项。例如,2个特征的交互项可以称为二阶特征组合项,3个特征的交互项可以称为三阶特征组合项。
96.作为一个示例,二阶fm模型如下列公式(1)所示。
[0097][0098]
x表示特征向量,x
i
表示第i个特征,x
j
表示第j个特征。m表示特征维度,也可以称为特征的域(field)。w0表示全局偏置,w0∈r。w
i
表示第i个特征的强度,w∈r
m
。 v
i
表示第i个特征x
i
的辅助向量,v
j
表示第j个特征x
j
的辅助向量。k为v
i
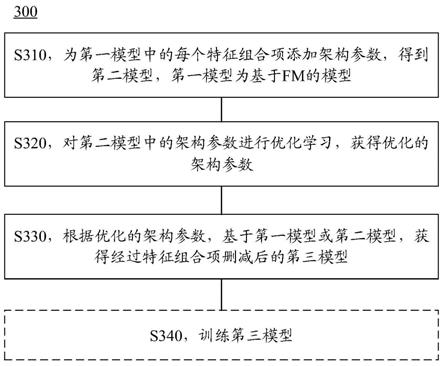
与v
j
的维度。二维矩阵v∈r
m
×
k
。
[0099]
其中,x
i
x
j
表示第i个特征x
i
与第j个特征x
j
的组合。
[0100]
<v
i
,v
j
>表示v
i
与v
j
的内积,表示第i个特征x
i
与第j个特征x
j
之间的相互作用。 <v
i
,v
j
>也可以理解为特征组合项x
i
x
j
的权重参数,例如,<v
i
,v
j
>可以记为w
ij
。
[0101]
在本文中,将<v
i
,v
j
>记为特征组合项x
i
x
j
的权重参数。
[0102]
可选地,公式(1)还可以表达为下列公式(2):
[0103][0104]
其中,公式(2)中的<e
i
,e
j
>表示公式(1)中的<v
i
,v
j
>x
i
x
j
,公式(2)中的<w,x>表示公式(1)中的
[0105]
作为另一个示例,三阶fm模型如下列公式(3)所示。
[0106][0107]
fm模型中包括单个特征的所有组合情况的特征组合项。例如,在公式(1)或公式(2) 所示的二阶fm模型中,包括单个特征的所有二阶特征组合情况的组合特征项。又例如,在公式(3)所示的三阶fm模型中,包括单个特征的所有二阶特征组合情况的组合特征项,以及所有三阶特征组合情况的组合特征项。
[0108]
例如,业界将获取特征x
i
的辅助向量v
i
的操作称为嵌入(embedding),将根据特征 x
i
及其辅助向量v
i
构造特征交互项的操作称为交互(interaction)。图1为fm模型的架构示意图。如图1所示,fm模型可以视为神经网络模型,包括输入(input)层、嵌入 (embedding)
层、交互(interaction)层与输出(output)层。输入层用于生成特征,域1、域、
…
、域m表示特征维度。嵌入层用于产生特征的辅助向量。交互层用于根据特征及其辅助向量生成特征组合项。输出层用于输出fm模型的输出。
[0109]
现有技术,通常基于fm进行ctr预估或cvr预估。
[0110]
当前技术中,基于fm的模型包括:fm模型、deepfm模型、ipnn模型、afm模型与nfm模型等。
[0111]
作为示例而非限定,建立fm模型的流程如图2所示。
[0112]
s210,枚举特征组合项进入fm模型。
[0113]
例如,使用公式(1)或公式(3)构建fm模型。
[0114]
s220,训练fm模型直至收敛,即获得可以投入应用的fm模型。
[0115]
完成fm模型的训练后,可以使用训练好的fm模型进行上线推理,如图2所示的步骤s230。
[0116]
如前文描述,fm模型中包括单个特征的所有组合情况的特征组合项。因此,fm模型的训练的计算量与耗时都是巨大的。
[0117]
此外,从公式(1)与公式(3)可以看出,fm模型中的特征组合项的数量随特征维度以及特征组合的阶数的增加而剧增。
[0118]
例如,在公式(1)中,当特征维度m增大,特征组合项的数量呈指数增大。再例如,从二阶fm模型到三阶fm模型,随着特征组合的阶数的增大,fm模型中特征组合项的数量的增加是巨大的。
[0119]
因此,特征维度以及特征组合的阶数的增大为fm模型的推理时延与计算量带来巨大负担,因此,限制了fm模型能够容纳的最大特征维度以及特征组合的阶数。例如,当前技术的fm模型很难扩展到更高阶。
[0120]
针对这个问题,特征组合筛选(feature interaction selection,fis)被提出来。
[0121]
一些现有技术采用手工筛选的方式进行特征组合筛选。筛选好的特征组合可能需要花费很多工程师若干年的探索。这种手工筛选的方式不但消耗巨大的人力,而且可能会漏掉重要的特征组合项。
[0122]
针对手工筛选的弊端,业界提出自动特征组合筛选(automatic feature interactionselection,autofis)的方案。相对于手工筛选,自动特征组合筛选可以在短时间内筛选到有价值的特征组合。
[0123]
当前技术中,提出一种自动特征组合筛选的方案。该方案将所有可能的特征组合子集当作搜索空间(search space),用离散算法在随机抽取的n个候选子集中选出最好的候选子集作为筛选后的特征组合。其中,在评估每个候选子集时,均需要执行一遍训练操作,因此,该方案的计算量较大,所需消耗的算力较大。此外,在评估每个候选子集时,若完整训练整个模型,可以提高评价精确度,但是会导致搜索能耗(search cost)巨大;若用小批量(mini-batches)训练做近似,则会导致评价不精确。此外,在该方案中,随着特征组合的阶数的增大,搜索空间呈指数级别增长,会加剧搜索过程能耗。
[0124]
因此,现有的自动特征组合筛选的方案,计算量大,算力消耗大,搜索过程耗能高。
[0125]
针对上述问题,本技术提出一种自动特征组合筛选的方案,相对于现有技术,可以降低自动特征组合筛选的算力消耗,提高自动特征组合筛选的效率。
[0126]
图3为本技术实施例提供的数据处理的方法300的示意性流程图,该方法300包括如下步骤s310、s320与s330。
[0127]
s310,为第一模型中的每个特征组合项添加架构参数,得到第二模型。
[0128]
其中,第一模型为基于因子分解机(factorization machine,fm)的模型,也就是说,第一模型中包括单个特征的所有组合情况的特征组合项,或者说,第一模型中枚举了所有组合情况的特征组合项。
[0129]
例如,第一模型可以为如下基于fm的模型中的任一种:fm模型、deepfm模型、 ipnn模型、afm模型与nfm模型。
[0130]
作为示例,第一模型为如公式(1)或公式(2)所示的二阶fm模型,或者第一模型为如公式(3)所示的三阶fm模型。
[0131]
本技术是要实现特征组合项的筛选,第一模型可以视为是待进行特征组合项删减的模型。
[0132]
为第一模型中的每个特征组合项添加架构参数,指的是,为第一模型中的每个特征组合项添加一个系数,本技术中,将该系数称为架构参数。该架构参数用于表征相应特征组合项的重要性。为第一模型中的每个特征组合项添加架构参数后得到的模型记为第二模型。
[0133]
作为一个示例,假设第一模型为如公式(1)所示的二阶fm模型,则第二模型可以如下列公式(4)所示。
[0134][0135]
x表示特征向量,x
i
表示第i个特征,x
j
表示第j个特征。m表示特征维度,也可以称为特征的域(field)。w0表示全局偏置,w0∈r。w
i
表示第i个特征的强度,w∈r
m
。 v
i
表示第i个特征x
i
的辅助向量,v
j
表示第j个特征x
j
的辅助向量。k为v
i
与v
j
的维度。二维矩阵v∈r
m
×
k
。
[0136]
其中,x
i
x
j
表示第i个特征x
i
与第j个特征x
j
的组合。
[0137]
<v
i
,v
j
>表示特征组合项x
i
x
j
的权重参数,α(
i,j
)表示特征组合项x
i
x
j
的架构参数。
[0138]
<v
i
,v
j
>表示v
i
与v
j
的内积,表示第i个特征x
i
与第j个特征x
j
之间的相互作用。 <v
i
,v
j
>也可以理解为特征组合项x
i
x
j
的权重参数,例如,<v
i
,v
j
>可以记为w
ij
。
[0139]
假设第一模型表达为公式(2)所示的二阶fm模型,则第二模型可以表达为下列公式(5)。
[0140][0141]
其中,α
(i,j)
表示特征组合项的架构参数。
[0142]
作为另一个示例,假设第一模型为如公式(3)所示的三阶fm模型,则第二模型可以如下列公式(6)所示。
[0143][0144]
其中,α
(i,j)
与α
(i,j,t)
表示特征组合项的架构参数。
[0145]
为了便于理解与描述,在本文中做如下约定,将第一模型中特征组合项原有的权
重参数(如公式(4)中的<v
i
,v
j
>)称为模型参数。
[0146]
也就是说,在第二模型中,每个特征组合项具有两类系数参数:模型参数与架构参数。
[0147]
图4为本技术实施例提供的特征组合项筛选的示意图。图4中的嵌入层与交互层的含义与图1中的嵌入层与交互层的含义相同。如图4所示,在本技术实施例中,为交互层中的每个特征组合项添加架构参数α
(i,j)
(如图4中所示的α
(1,2)
、α
(1,m)
、α
(m-1,m)
)。可以将图4中交互层视为第一模型,为特征组合项添加了架构参数α
(i,j)
后的交互层可以视为第二模型。
[0148]
s320,对第二模型中的架构参数进行优化学习,获得优化后的架构参数。
[0149]
例如,使用训练数据,对第二模型中的架构参数进行优化学习,获得优化后的架构参数。
[0150]
例如,优化后的架构参数可以视为是得第二模型中架构参数的最优值α
*
。
[0151]
在本技术实施例中,架构参数表征相应特征组合项的重要性,因此,对架构参数的优化学习,相当于是,学习每个特征组合项的重要性或者每个特征组合项对模型预测的贡献度。也就是说,优化后的架构参数表征了学习到的特征组合项的重要性。
[0152]
换句话说,在本技术实施例中,每个特征组合项的贡献(或者重要性)可以采用端到端的方式由架构参数来学习。
[0153]
s330,根据优化后的架构参数,基于第一模型或第二模型,获得经过特征组合项删减后的第三模型。
[0154]
第三模型可以是在第一模型基础上进行特征组合项删减后得到的模型。
[0155]
或者,第三模型可以是在第二模型基础上进行特征组合项删减后得到的模型。
[0156]
其中,可以采用多种方式,确定要删减的特征组合项,或者说,确定要保留(即筛选) 的特征组合项。
[0157]
可选地,作为一种实现方式,可以将优化后的架构参数中取值小于阈值的架构参数对应的特征组合项删除。
[0158]
其中,该阈值用于表征是否保留特征组合项的判断准则,例如,若一个特征组合项的优化后的架构参数的取值小于该阈值,则表明,该特征组合项被删除,若一个特征组合项的优化后的架构参数的取值达到该阈值,则表明,该特征组合项被保留(即被筛选)。
[0159]
该阈值可以根据实际应用需求确定。例如,可以通过模型训练的方式,获取该阈值的取值。本技术对该阈值的获取方式不作限定。
[0160]
继续参见图4,假设优化后的架构参数α
(1,2)
小于阈值,则可以将架构参数α
(1,2)
对应的特征组合项删除,假设优化后的架构参数α
(1,m)
达到阈值,则可以将架构参数α
(1,m)
对应的特征组合项保留。根据优化后的架构参数进行特征组合项删减之后,获得下一层模型,如图4所示。图3实施例中的第三模型例如为图4中所示的下一层模型。
[0161]
作为示例而非限定,如图4所示,可以将根据优化后的架构参数决定相应的特征组合项是否删除的操作,记为选择门。
[0162]
需要说明的是,图4仅为示例而非限定。
[0163]
可选地,作为另一种实现方式,在一些架构参数在优化结束后取值变为零的情况下,可以直接将优化后取值不为零的架构参数所对应的特征组合项作为保留的特征组合项,得到第三模型。
[0164]
可选地,作为又一种实现方式,在一些架构参数在优化结束后取值变为零的情况下,进一步地,在优化后取值不为零的架构参数所对应的特征组合项中,将取值小于阈值的架构参数对应的特征组合项删除,得到第三模型。
[0165]
本文中的表述“经过特征组合项的删减后的模型”可以替换为“经过特征组合项的筛选后的模型”。
[0166]
如前文描述,在现有的自动特征组合筛选的方案中,将所有可能的特征组合子集当作搜索空间(search space),用离散算法在随机抽取的n个候选子集中选出最好的候选子集作为筛选后的特征组合。其中,在评估每个候选子集时,均需要执行一遍训练操作,导致计算量大,消耗算力大。
[0167]
在本技术实施例中,通过在基于fm的模型中引入架构参数,通过对架构参数的优化学习,可以实现特征组合项的筛选。也就是说,本技术只需执行架构参数的优化学习,这样的一次模型训练过程,就可以实现特征组合项筛选,而无需现有技术中针对多个候选子集的多遍训练,因此,可以有效减小特征组合筛选的计算量,从而可以节省算力,同时可以提高特征组合筛选的效率。
[0168]
此外,在现有的自动特征组合筛选方案中,是通过从搜索空间(search space)中搜索候选子集,来实现特征组合筛选。可以理解到,现有技术将特征组合筛选作为离散问题来解决的,即搜索离散的特征组合候选集。
[0169]
在本技术实施例中,是通过对引入基于fm的模型中的架构参数的优化学习,来实现特征组合筛选的。可以理解到,本技术实施例是将现有的搜索离散的特征组合候选集的问题连续化,或者说,将特征组合筛选作为一个连续问题来解决。例如,本技术提供的自动特征组合筛选方案可以表述为,基于连续搜索空间的组合特征搜索方案。换句话说,在本技术实施例中,在基于fm的模型中引入架构参数的这一操作,可以视为,是对特征组合项自动筛选这一问题进行的连续建模。
[0170]
此外,现有的自动特征组合筛选方案由于计算量大,消耗算力大,导致无法应用于训练时间较长的深度学习模型。
[0171]
在本技术实施例中,只需通过架构参数的优化学习过程,就可实现特征组合筛选,或者说,只需一次端到端的模型训练过程,即可完成特征组合项的筛选,使得特征组合项的筛选(或搜索)的时间可以等价于一次模型训练的时间,因此,可以应用于训练时间较长的深度学习模型。
[0172]
如前文描述,现有技术的fm模型,由于需要枚举所有特征组合情况,导致很难扩展到更高阶。
[0173]
在本技术实施例中,通过在基于fm的模型中引入架构参数,并通过架构参数的优化学习,可以实现特征组合筛选,因此,本技术实施例提供的方案,可以支持基于fm的模型中的特征组合项扩展到更高阶。
[0174]
例如,使用本技术实施例提供的方案构造的fm模型可以扩展到三阶或更高阶。
[0175]
再例如,使用本技术实施例提供的方案构造的deepfm模型可以扩展到三阶或更高阶。
[0176]
在本技术实施例中,通过在传统的基于fm的模型中引入架构参数,并通过对架构参数的优化学习,可以实现特征组合筛选。或者,换句话说,本技术实施例通过构建一种包
括架构参数的基于fm的模型,通过对架构参数进行优化学习,可以实现特征组合筛选。其中,构建这种包括架构参数的基于fm的模型的方法为,在传统基于fm的模型中的每个特征组合项前面添加架构参数。
[0177]
如图3所示,该方法300还可以包括步骤s340。
[0178]
s340,训练所述第三模型。
[0179]
步骤s340也可以理解为,重新进行模型训练。可以理解到,通过步骤s310、步骤s320 与步骤s330,实现了特征组合项的删减。在步骤s340中,对经过特征组合项的删减后的模型,重新进行训练。
[0180]
在步骤s340,可以直接对第三模型进行训练;或者,也可以是在第三模型上增加l1 正则项,和/或l2正则项之后,再进行训练。
[0181]
例如,可以根据应用需求,确定训练第三模型的训练目的。
[0182]
例如,假设要获得点击率(click-through rate,ctr)预估模型,则以获得ctr预估模型为训练目标,训练第三模型,以得到ctr预估模型。
[0183]
再例如,例如,假设要获得转化率(conversion rate,cvr)预估模型,则以获得cvr 预估模型为训练目标,训练第三模型,以得到cvr预估模型。
[0184]
在步骤s320中,例如,可以采用多种优化算法(或优化器)对第二模型中的架构参数进行优化学习。
[0185]
第一种优化算法。
[0186]
可选地,在步骤s320中,对架构参数的优化学习,使得优化后的架构参数呈现稀疏性。
[0187]
例如,在步骤s320中,采用套锁算子(least absolute shrinkage and selection operator,lasso)正则化(regularization)对第二模型中的架构参数进行优化学习。lasso也可以称为最小绝对值收敛和选择算子。
[0188]
以第二模型为公式(5)为例,在步骤s320中,可以采用如下公式(7)对第二模型中的架构参数进行优化学习:
[0189][0190]
其中,表示损失函数,y表示模型观测值,表示模型预测值。λ表示常数,可以根据具体需求赋值。
[0191]
应理解,公式(7)表示架构参数优化的约束条件。
[0192]
通过使得优化后的架构参数呈现稀疏性,有利于后续特征组合项的删减。
[0193]
可选地,作为一种实施例,在步骤s320中,对架构参数的优化学习,使得优化后的架构参数呈现稀疏性;在步骤s330中,基于第一模型或第二模型,将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。
[0194]
其中,该阈值用于表征是否保留特征组合项的判断准则,例如,若一个特征组合项的优化后的架构参数的取值小于该阈值,则表明,该特征组合项被删除,若一个特征组合项的优化后的架构参数的取值达到该阈值,则表明,该特征组合项被保留(即被筛选)。
[0195]
该阈值可以根据实际应用需求确定。例如,可以通过模型训练的方式,获取该阈值的取值。本技术对该阈值的获取方式不作限定。
[0196]
在本技术实施例中,通过对架构参数的优化学习,使得架构参数呈现稀疏性,有利于特征组合项的筛选。
[0197]
应理解,第二模型中的架构参数表征相应特征组合性的重要性或贡献度,若优化后的某个架构参数的取值小于阈值,例如接近于零,则表明该架构参数所对应的特征组合项不重要或者贡献度很小,将这样的特征组合项删除(或称为剔除或剪掉),不但可以去除其引入的噪声,还可以减小能耗,也可以提高模型的推理速度。
[0198]
因此,将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,是合理地的特征组合筛选操作。
[0199]
第二种优化算法。
[0200]
可选地,在步骤s320中,对架构参数的优化学习,使得优化后的架构参数呈现稀疏性,并且使得至少一个特征组合项的架构参数的取值在优化结束后等于零。
[0201]
假设将优化结束后取值为零的架构参数对应的特征组合项视为不重要的特征组合项,则步骤s320中对架构参数的优化学习,可以视为,可以使得不重要的特征组合项的架构参数在优化结束后等于零。
[0202]
换句话说,对架构参数的优化学习使得,至少一个特征组合项的架构参数的取值在优化过程中趋向于零。
[0203]
例如,在步骤s320中,使用广义正规对偶平均(generalized regularized dual averaging, grda)优化器对第二模型中的架构参数进行优化。grda优化器不仅可以实现架构参数的稀疏性,还可以使得至少一个特征组合项的架构参数的取值在优化过程中逐渐趋向于零。
[0204]
作为示例,在步骤s320中,采用如下公式(8)对第二模型中的架构参数进行优化学习:
[0205][0206]
其中,γ表示学习率。y
i+1
表示模型观测值。g(t,γ)=cγ
1/2
(tγ)
μ
,c与μ表示可调整的超参数,调整c与μ的目标是在模型准确度与架构参数α的稀疏性之间找到平衡。
[0207]
应理解,公式(8)表示架构参数优化的约束条件。
[0208]
还应理解,在本实施例中,在步骤s320中,完成架构参数优化后的第二模型已经为经过特征组合项筛选的模型。
[0209]
在本技术实施例中,通过架构参数的优化学习使得一些架构参数趋向于零,相当于在架构参数的优化过程中就剔除了一些不重要的特征组合项,或者说,通过架构参数的优化学习,既实现了架构参数的优化,又实现了特征组合项的筛选,可以有效提高特征组合筛选的效率,进一步减少计算量和算力消耗。
[0210]
此外,在架构参数的优化过程中,剔除一些不重要的特征组合项,还可以避免这些不重要的特征组合项所产生的噪声,从而可以使得在架构参数的优化过程中模型就逐渐接近理想模型,这样也可以使得模型中的其他参数(例如,未剔除的特征组合项的架构参数与模型参数)的估计更加准确。
[0211]
可选地,作为一种实施例,在步骤s320中,对架构参数的优化学习,使得优化后的架构参数呈现稀疏性,并且使得至少一个特征组合项的架构参数的取值在优化结束后等于
零;在步骤s330中,可以通过如下多种方式,获得第三模型。
[0212]
方式(1)
[0213]
在步骤s330中,可以直接将优化后的架构参数所对应的特征组合项作为筛选的特征组合项,基于所筛选的特征组合项获得第三模型。
[0214]
例如,在第一模型中,将优化后的架构参数所对应的特征组合项作为筛选的特征组合项,将其余特征组合项删除,获得第三模型。
[0215]
再例如,直接经完成架构参数优化的第二模型作为第三模型。
[0216]
方式(2)
[0217]
在步骤s330中,在优化后的架构参数所对应的特征组合项中,将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。
[0218]
该阈值可以根据实际应用需求确定。例如,可以通过模型训练的方式,获取该阈值的取值。本技术对该阈值的获取方式不作限定。
[0219]
例如,在第一模型中,将优化后的架构参数对应的特征组合项之外的特征组合项删除,再将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。
[0220]
再例如,在完成架构参数优化后的第二模型中,将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。
[0221]
在本技术实施例中,通过架构参数的优化学习使得一些架构参数趋向于零,相当于在架构参数的优化过程中就剔除了一些不重要的特征组合项,或者说,通过架构参数的优化学习,既实现了架构参数的优化,又实现了特征组合项的筛选,可以有效提高特征组合筛选的效率,进一步减少计算量和算力消耗。
[0222]
基于上述对步骤s320的描述可知,步骤s330中,获得经过特征组合项筛选后的第三模型的实现方式,可以根据步骤s320中对架构参数的优化方式而确定。下面描述在如下两种情况下,获得第三模型的实现方式。
[0223]
第一种情况,在步骤s320中,对架构参数的优化学习,使得优化后的架构参数呈现稀疏性。
[0224]
在步骤s330中,将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获取第三模型。该阈值如参见上文描述,这里不再赘述。
[0225]
作为示例而非限定,将架构参数的优化学习完成(即优选训练收敛)后得到优化后的架构参数记为架构参数的最优值α
*
。根据最优值α
*
,可以确定保留或删掉哪些特征组合项。例如,若一个特征交互项的架构参数的最优值α
*
(i,j)达到阈值,则该特征交互项应该保留;若一个特征交互项的架构参数的最优值α
*
(i,j)小于阈值,则该特征交互项应该删掉。
[0226]
作为示例,在第二模型中,对于每个特征交互项,设置一个表征该特征交互项是否保留在模型中的开关项ψ
(i.j)
,第二模型可以如下公式(9)所示:
[0227][0228]
其中,开关项ψ
(i.j)
的取值可以通过如下公式(10)表示:
[0229][0230]
其中,thr表示阈值。
[0231]
将开关项ψ
(i.j
)为0的特征组合项从第二模型中删掉,即可得到经过特征组合项筛选后的第三模型。
[0232]
在本实施例中,开关项ψ
(i.j)
的设置可以视为是否保留特征组合项的判断标准。
[0233]
可选地,第三模型可以是基于第一模型经过特征组合项删减后得到的模型。
[0234]
例如,将开关项ψ
(i.j)
为0的特征组合项从第一模型中删掉,得到经过特征组合项筛选后的第三模型。
[0235]
可选地,第三模型可以是基于第二模型经过特征组合项删减后得到的模型。
[0236]
例如,将开关项ψ
(i.j)
为0的特征组合项从第二模型中删掉,得到经过特征组合项筛选后的第三模型。
[0237]
应理解,在本实施例中,第三模型中具有优化后的表征特征组合项的重要性的架构参数,后续通过第三模型的训练,可以进一步学习特征组合项的重要性。
[0238]
第二种情况,在步骤s320中,对架构参数的优化学习,使得优化后的架构参数呈现稀疏性,并且使得至少一个特征组合项的架构参数的取值在优化结束后等于零。
[0239]
可选地,在步骤s330中,将优化后的架构参数对应的特征组合项之外的特征组合项删除,获得第三模型。
[0240]
作为一个示例,在步骤s330中,在第一模型中,将优化后的架构参数对应的特征组合项之外的特征组合项删除,获得第三模型。即第三模型是在第一模型基础上进行特征组合项删减后得到的。
[0241]
作为另一个示例,在步骤s330中,将完成架构参数优化后的第二模型作为第三模型。即第三模型是在第二模型基础上进行特征组合项删减后得到的。
[0242]
可选地,在步骤s330中,将优化后的架构参数对应的特征组合项之外的特征组合项删除,再将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。
[0243]
作为一个示例,在步骤s330中,在第一模型中,将优化后的架构参数对应的特征组合项之外的特征组合项删除,再将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。即第三模型是在第一模型基础上进行特征组合项删减后得到的。
[0244]
作为另一个示例,在步骤s330中,在完成架构参数优化后的第二模型中,将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。即第三模型是在第二模型基础上进行特征组合项删减后得到的。
[0245]
应理解,在第三模型是在第二模型基础上进行特征组合项删减后得到的实施例中,第三模型中具有优化后的表征特征组合项的重要性的架构参数,后续通第三模型的训练,可以进一步学习特征组合项的重要性。
[0246]
从公式(4)、公式(5)或公式(6)可以理解到,第二模型中包括两类参数:架构参数与模型参数。模型参数表示,第二模型中除了架构参数之外,特征组合项本身的权重参数。
例如,在第二模型如公式(4)的例子中,α
(i,j)
表示特征组合项的架构参数为,<v
i
,v
j
> 表示特征组合项的模型参数。例如,在第二模型如公式(5)的例子中,α
(i,j)
表示特征组合项的架构参数为,<e
i
,e
j
>可以表示特征组合项的模型参数。
[0247]
可以理解到,在对架构参数的优化学习过程中,不仅涉及架构参数的训练,还涉及模型参数的训练。换句话说,在步骤s320中对第二模型中的架构参数进行优化学习的过程中,伴随着对第二模型中的模型参数的优化学习。
[0248]
例如,在图3所示实施例中,该方法300还包括:对第二模型中的模型参数的优化学习,该优化学习包括对模型参数的标量化处理。
[0249]
在模型参数的优化学习过程中的每轮训练中,均对第二模型中的模型参数进行标量化处理。
[0250]
例如,通过对第二模型中的模型参数进行批量归一化(batch normalization,bn),实现对第二模型中的模型参数进行标量化处理。
[0251]
作为示例,以第二模型如公式(5)所示为例,可以采用如下公式(11)对第二模型中的模型参数进行标量化处理:
[0252][0253]
其中,<e
i
,e
j
>
bn
表示<e
i
,e
j
>的批量归一化。
[0254]
<e
i
,e
j
>
b
表示<e
i
,e
j
>的小批量(min batch)数据。
[0255]
μ
b
(<e
i
,e
j
>
b
)表示<e
i
,e
j
>的小批量(min batch)数据的平均值。
[0256]
表示<e
i
,e
j
>的小批量(min batch)数据的方差。
[0257]
θ表示扰动。
[0258]
继续参见图4,图4中所示的批量归一化(bn),表示对第二模型中的模型参数进行 bn处理。
[0259]
通过对特征组合项的模型参数进行标量化处理,可以实现该特征组合项的模型参数与架构参数的去耦合,从而可以使得架构参数能更准确地体现该特征组合项的重要性,进而可以提高架构参数的优化准确度。原因如下。
[0260]
应理解,e
i
是在模型训练过程中不断更新变化的。e
i
与e
j
做内积后,即<e
i
,e
j
>,其规格(scale)也是不断更新变换的。假设,α
(i,j)
<e
i
,e
j
>可以通过获得,其中,第一项与第二项(η
·
<e
i
,e
j
>)具有耦合。如果第二项(η
·
<e
i
,e
j
>)不作标量化处理,则第一项不能绝对代表第二项的重要性,这样会为系统带来很大的不稳定性。
[0261]
在本技术实施例中,通过对特征组合项的模型参数进行标量化处理,可以避免出
现α
(i,j)
<e
i
,e
j
>可以通过获得的现象,即可以实现该特征组合项的模型参数与架构参数的去耦合。
[0262]
通过特征组合项的模型参数与架构参数之间的去耦合,可以使得架构参数能更准确地体现该特征组合项的重要性,进而可以提高架构参数的优化准确度。
[0263]
换句话说,通过对特征组合项的模型参数进行标量化处理,可以实现该特征组合项的模型参数与架构参数的去耦合,可以避免特征组合项的模型参数与架构参数的耦合效应对系统带来较大不稳定性。
[0264]
如上文描述,第二模型中包括两类参数:架构参数与模型参数。在对架构参数的优化学习过程中,不仅涉及架构参数的训练,还涉及模型参数的训练。换句话说,在步骤s320 中对第二模型中的架构参数进行优化学习的过程中,伴随着对第二模型中的模型参数的优化学习。
[0265]
为了便于理解与描述,在下文描述中,将第二模型中的架构参数记为α,将第二模型中的模型参数记为w(对应上文公式(4)中的<v
i
,v
j
>)。
[0266]
可选地,在图3所示实施例中,对第二模型中架构参数α的优化处理和对第二模型中模型参数w的优化处理,包括:对第二模型中的架构参数α与模型参数w进行两层 (two-level)优化处理。
[0267]
换句话说,在步骤s320中,通过对第二模型中的架构参数α与模型参数w进行两层 (two-level)优化处理,获得优化后的架构参数α
*
。
[0268]
在本实施例中,将第二模型中的架构参数α作为模型超参数进行优化学习,将第二模型中的模型参数w作为模型的参数进行优化学习。也就是说,将架构参数α作为高级决策变量,将模型参数w作为低级决策变量。对于高级决策变量α的任一个取值,都对应一个不同的模型。
[0269]
可选地,对于高级决策变量α的任一个取值所对应的一个模型,评估这个模型时,通过完整训练这个模型来获得最优的模型参数w
optimal
。换句话说,每评估一个架构参数α的候选值,完整训练一遍该候选值对应的模型。
[0270]
可选地,对于高级决策变量α的任一个取值所对应的一个模型,评估这个模型时,用一个小批量(mini-batches)数据更新该模型一步得到的w
t+1
代替最优的模型参数w
optimal
。
[0271]
可选地,在图3所示实施例中,对第二模型中架构参数α的优化处理和对第二模型中模型参数w的优化处理,包括:使用相同的训练数据,对第二模型中的架构参数α与模型参数w同时进行优化学习。
[0272]
换句话说,在步骤s320中,通过使用相同的训练数据,对第二模型中的架构参数α与模型参数w同时进行优化学习,获得优化后的架构参数α
*
。
[0273]
在实施例中,在优化过程的每轮训练中,基于同一批训练数据,对架构参数α与模型参数w同时进行优化学习。或者说,将第二模型中的架构参数与模型参数视为同一级别的决策变量,对第二模型中的架构参数α与模型参数w同时进行优化学习,获得优化后的架构参数α
*
。
[0274]
在本实施例中,对第二模型中的架构参数α与模型参数w的优化处理,可以称为一层 (one-level)优化处理。
[0275]
例如,第二模型中的架构参数α与模型参数w在随机梯度下降(stochastic gradientdescent,sgd)优化中自由探索其可行域直到收敛。
[0276]
作为示例,采用如下公式(12)实现第二模型中架构参数α与模型参数w的优化学习:
[0277][0278]
其中,α
t
表示进行第t步优化后的架构参数。α
t-1
表示进行第t-1步优化后的架构参数。w
t
表示进行第t步优化后的模型参数。w
t-1
表示表示进行第t-1步优化后的模型参数。η
t
表示进行第t步优化时架构参数的优化学习率。δ
t
表示进行第t步优化时模型参数的学习率。l
train
(w
t-1
,α
t-1
)表示测试集上损失函数在第t步优化时的损失函数值。表示测试集上损失函数在第t步优化时对架构参数α的梯度。表示表示测试集上损失函数在第t步优化时对模型参数w的梯度。
[0279]
在本实施例中,通过对第二模型中的架构参数与模型参数进行一层优化处理,以实现第二模型中的架构参数的优化学习,可以实现架构参数与模型参数的同时优化,从而可以减小第二模型中的架构参数的优化学习过程的耗时,进而有助于提高特征组合项筛选的效率。
[0280]
完成步骤s330后,即完成了特征组合项的筛选,第三模型为完成特征组合项筛选后的模型。
[0281]
在步骤s340中,训练第三模型。
[0282]
其中,可以对第三模型进行训练,或者,也可以在第三模型上增加l1正则项,和/ 或l2正则项之后,再进行训练。
[0283]
可以根据应用需求,确定训练第三模型的训练目的。
[0284]
例如,假设要获得点击率(click-through rate,ctr)预估模型,则以获得ctr预估模型为训练目标,训练第三模型,以得到ctr预估模型。
[0285]
再例如,例如,假设要获得转化率(conversion rate,cvr)预估模型,则以获得cvr 预估模型为训练目标,训练第三模型,以得到cvr预估模型。
[0286]
可选地,第三模型是基于第一模型进行特征组合项删减后得到的模型。详见上文中对步骤s330的描述,这里不再赘述。
[0287]
可选地,第三模型是基于第二模型进行特征组合项删减后得到的模型。详见上文中对步骤s330的描述,这里不再赘述。
[0288]
应理解,在完成特征组合项删减(或筛选)后,在模型中保留架构参数,对模型进行训练,可以进一步学习特征组合项的重要性。
[0289]
基于上文描述可知,在本技术实施例中,通过在基于fm的模型中引入架构参数,并通过架构参数的优化学习,可以实现特征组合项的筛选。也就是说,本技术通过架构参数的优化学习可以实现特征组合项的筛选,而无需现有技术中针对多个候选子集的多遍训练,因此,可以有效减小特征组合筛选的计算量,从而可以节省算力,同时可以提高特征组合筛
选的效率。
[0290]
此外,采用本技术实施例提供的方案,可以支持基于fm的模型中的特征组合项扩展到更高阶。
[0291]
图5为本技术实施例提供的自动特征组合筛选的方法500的另一示意性流程图。
[0292]
首先获取训练数据。
[0293]
例如,假设特征维度为m,则针对m个域的特征,获取训练数据。
[0294]
s510,枚举特征组合项进入基于fm的模型。
[0295]
基于fm的模型的可以是如上述公式(1)或公式(2)所示的fm模型,也可以是下列基于fm的模型中的任一种模型:deepfm模型、ipnn模型、afm模型与nfm模型。
[0296]
枚举特征组合项进入基于fm的模型,指的是,基于m个特征的所有组合情况构造基于fm的模型的特征组合项。
[0297]
应理解,构造特征组合项时,会涉及到m个特征的辅助向量。
[0298]
例如,可以采用图1或图3所示的嵌入(embedding)层获取m个特征的辅助向量。通过嵌入(embedding)层获取m个特征的辅助向量的技术为现有技术,本文不作赘述。
[0299]
s520,在基于fm的模型中引入架构参数。具体来说,为基于fm的模型中的每个特征组合项添加一个系数参数,这个系数参数称为架构参数。
[0300]
步骤s520对应于上文实施例中的步骤s310,具体描述详见上文。
[0301]
图5所示实施例中的基于fm的模型对应图3所示实施例中的第一模型,图5所示实施例中基于fm的模型在添加架构参数后得到的模型对应图3所示实施例中的第二模型。
[0302]
s530,对架构参数进行优化学习,直至收敛,获得优化后的架构参数。
[0303]
步骤s530对应于上文实施例中的步骤s320,具体描述详见上文。
[0304]
s540,根据优化后的架构参数,进行特征组合项的删减,获得经过特征组合项删减后的模型。
[0305]
步骤s540对应于上文实施例中的步骤s330,具体描述详见上文。
[0306]
图5所示实施例中经过特征组合项删减后的模型对应图3所示实施例中的第三模型。
[0307]
s550,训练经过特征组合项删减后的模型,直至收敛,获得ctr预估模型。
[0308]
步骤s550对应于上文实施例中的步骤s340,具体描述详见上文。
[0309]
训练得到ctr预估模型后,可以对该ctr预估模型进行上线推理。
[0310]
例如,将目标对象的数据输入ctr预估模型,ctr预估模型的输出为该目标对象的点击率,根据该点击率,可以判断是否推荐该目标对象。
[0311]
本技术实施例提供的自动特征组合筛选的方案可以适用于任意基于因子分解机 (factorization machine,fm)的模型,例如,fm模型、deepfm模型、ipnn模型、afm 模型与nfm模型等。
[0312]
作为一个示例,本技术实施例提供的自动特征组合筛选方案可以应用于现有的fm模型。
[0313]
例如,在现有的fm模型中引入架构参数,通过架构参数的优化学习,获得各个特征组合项的重要性,然后基于各个特征组合项的重要性实现特征组合的筛选,最终得到经过特征组合筛选后的fm模型。
[0314]
应理解,通过将本技术应用于fm模型,可以高效实现fm模型的特征组合项筛选,从而可以支持fm模型的特征组合项扩展到更高阶。
[0315]
作为另一个示例,本技术实施例提供的自动特征组合筛选方案可以应用于现有的 deep-fm模型。
[0316]
例如,在现有的deepfm模型中引入架构参数,通过架构参数的优化学习,获得各个特征组合项的重要性,然后基于各个特征组合项的重要性实现特征组合的筛选,最终得到经过特征组合筛选后的deepfm模型。
[0317]
应理解,通过将本技术应用于deepfm模型,可以高效实现deepfm模型的特征组合项筛选。
[0318]
如图6所示,本技术实施例还提供一种数据处理的方法600。该该方法600包括如下步骤s610与s620。
[0319]
s610,将目标对象的数据输入ctr预估模型或cvr预估模型,获得目标对象的预估结果。
[0320]
例如,该目标对象为商品。
[0321]
s620,根据目标对象的预估结果,确定目标对象的推荐情况。
[0322]
其中,ctr预估模型或cvr预估模型通过如下上文实施例提供的方法300获得,即该ctr预估模型或cvr预估模型通过上文实施例中的步骤s310至步骤s340获得。详见上文描述,这里不再赘述。
[0323]
其中,在步骤s340中,使用该目标对象的训练样本,训练第三模型,以得到ctr预估模型或cvr预估模型。
[0324]
可选地,在步骤s320中,使用目标对象的训练样本中相同的训练数据,对第二模型中的架构参数与模型参数同时进行优化学习,获得优化后的架构参数。
[0325]
或者说,将第二模型中的架构参数与模型参数视为同一级别的决策变量,使用目标对象的训练样本,对第二模型中的架构参数与模型参数同时进行优化学习,获得优化后的架构参数。
[0326]
仿真测试:上线ab测试ctr预测精度显著提升,推理能耗明显降低。
[0327]
作为示例,仿真实验表明,将本技术提供的特征组合筛选方案应用于推荐系统的 deepfm模型,上线进行a/b测试,游戏下载率可以提升20%,ctr预估精确率可以相对提升20.3%,转化率(conversion rate,cvr)可以相对提升20.1%,因此,可以有效加快模型的推理速度。
[0328]
作为一个示例,在公开数据集avazu上使用本技术提供的方案获得fm模型与deepfm 模型,利用本技术的方案获得的fm模型与deepfm模型的性能与业界其他的模型的性能的比较结果如表1与表2所示。其中,表1表示二阶模型的比较,表2表示三阶模型的比较。二阶模式表示,模型的特征组合项的最高阶数是二阶。三阶阶模式表示,模型的特征组合项的最高阶数是三阶。
[0329]
表1
[0330][0331][0332]
表2
[0333][0334]
在表1与表2中,横向表头的含义如下。
[0335]
auc(area under curve)表示曲线下方的面积。log loss表示损失值的log。top表示进行特征组合项筛选后所保留的特征组合项的比例。time表示模型推理两百万个样本的时间。search+re-train cost表示,搜索耗时+重新训练耗时,其中,搜索耗时表示上文实施例步骤s320与步骤s330的耗时,重新训练耗时表示上文实施例中步骤s340的耗时。 rel.impr表示相对提升值。
[0336]
在表1中,纵向表头的含义如下。
[0337]
fm、fwfm、afm、ffm、deepfm表示现有技术中的基于fm的模型。gbdt+lr 与gbdt+ffm表示现有技术中采用手工特征组合筛选的模型。
[0338]
autofm(2nd)表示使用本技术实施例提供的方案获取的二阶的fm模型。autodeepfm (2nd)表示使用本技术实施例提供的方案获取的三阶的deepfm模型。
[0339]
在表2中,纵向表头的含义如下。
[0340]
fm(3rd)表示现有技术中的三阶的fm模型。deepfm(3rd)表示现有技术中的三阶的 deepfm模型。
[0341]
autofm(3rd)表示使用本技术实施例提供的方案获取的三阶的fm模型。 autodeepfm(3rd)表示使用本技术实施例提供的方案获取的三阶的deepfm模型。
[0342]
从表1与表2可知,相对于现有技术,采用本技术实施例提供的方案获取的fm模型或deepfm模型,进行ctr预测,可以显著提升ctr预测精度,并且可以有效降低推理时间与能耗。
[0343]
基于上文描述可知,在本技术实施例中,通过在基于fm的模型中引入架构参数,通过对架构参数的优化学习,可以实现特征组合项的筛选。也就是说,本技术只需执行架构参数的优化学习,这样的一次模型训练过程,就可以实现特征组合项筛选,而无需现有技术中针对多个候选子集的多遍训练,因此,可以有效减小特征组合筛选的计算量,从而可以节省算力,同时可以提高特征组合筛选的效率。
[0344]
此外,采用本技术实施例提供的方案,可以支持基于fm的模型中的特征组合项扩展到更高阶。
[0345]
本文中描述的各个实施例可以为独立的方案,也可以根据内在逻辑进行组合,这些方案都落入本技术的保护范围中。
[0346]
上文描述了本技术提供的方法实施例,下文将描述本技术提供的装置实施例。应理解,装置实施例的描述与方法实施例的描述相互对应,因此,未详细描述的内容可以参见上文方法实施例,为了简洁,这里不再赘述。
[0347]
如图7所示,本技术实施例还提供一种数据处理的装置700。该装置700包括如下单元。
[0348]
第一处理单元710,用于为第一模型中的每个特征组合项添加架构参数,得到第二模型,其中,第一模型为基于因子分解机fm的模型,架构参数用于表征相应特征组合项的重要性。
[0349]
第二处理单元720,用于对第二模型中的架构参数进行优化学习,获得优化后的架构参数。
[0350]
第三处理单元730,用于根据优化后的架构参数,基于第一模型或第二模型,获得经过特征组合项删减后的第三模型。
[0351]
可选地,第二处理单元720对架构参数进行的优化学习使得,优化后的架构参数呈现稀疏性。
[0352]
在本实施例中,第三处理单元730用于,基于第一模型或第二模型,将优化后的架构参数中取值小于阈值的架构参数所对应的特征组合项删减,获得第三模型。
[0353]
可选地,第二处理单元720对架构参数进行的优化学习使得,至少一个特征组合项的架构参数的取值在优化结束后等于零。
[0354]
例如,第三处理单元730用于,使用grda优化器对第二模型中的架构参数进行优化,grda优化器使得至少一个特征组合项的架构参数的取值在优化过程中趋向于零。
[0355]
可选地,第二处理单元720还用于,对第二模型中的模型参数进行优化学习,该优化学习包括,对第二模型中的模型参数进行标量化处理。
[0356]
例如,第二处理单元720用于,对第二模型中的模型参数进行批量归一化bn处理。
[0357]
可选地,第二处理单元720用于,使用相同的训练数据,对第二模型中的架构参数与模型参数同时进行优化学习,获得优化后的架构参数。
[0358]
可选地,该装置700还包括训练单元740,用于训练第三模型。
[0359]
可选地,训练单元740用于,训练第三模型,以得到ctr预估模型或cvr预估模型。
[0360]
该装置700可以集成在终端设备、网络设备或芯片上。
[0361]
该装置700可以部署在相关设备的计算节点上。
[0362]
如图8所示,本技术实施例还提供一种图像处理的装置800。装置800包括如下单
元。
[0363]
第一处理单元810用于,将目标对象的数据输入点击率ctr预估模型或转化率cvr 预估模型,获得所述目标对象的预估结果。
[0364]
第一处理单元820用于,根据所述目标对象的预估结果,确定所述目标对象的推荐情况。
[0365]
其中,所述ctr预估模型或所述cvr预估模型通过上文实施例中的方法300或500 获得。
[0366]
其中,训练第三模型的步骤包括:使用该目标对象的训练样本,训练第三模型,以得到ctr预估模型或cvr预估模型。
[0367]
可选地,对架构参数进行优化学习的步骤包括:使用所述目标对象的训练样本中相同的训练数据,对所述第二模型中的架构参数与模型参数同时进行优化学习,获得优化后的架构参数。
[0368]
该装置800可以集成在终端设备、网络设备或芯片上。
[0369]
该装置800可以部署在相关设备的计算节点上。
[0370]
如图9所示,本技术实施例还提供一种图像处理的装置900。该装置900包括处理器 910,处理器910与存储器920耦合,存储器920用于存储计算机程序或指令,处理器910 用于执行存储器920存储的计算机程序或指令,使得上文方法实施例中的方法被执行。
[0371]
可选地,如图9所示,该装置900还可以包括存储器920。
[0372]
可选地,如图9所示,该装置900还可以包括数据接口930,数据接口930用于与外界进行数据的传输。
[0373]
可选地,作为一种方案,该装置900用于实现上文实施例中的方法300。
[0374]
可选地,作为另一种方案,该装置900用于实现上文实施例中的方法500。
[0375]
可选地,作为又一种方案,该装置900用于实现上文实施例中的方法600。
[0376]
本技术实施例还提供一种计算机可读介质,该计算机可读介质存储用于设备执行的程序代码,该程序代码包括用于执行上述实施例的方法。
[0377]
本技术实施例还提供一种包含指令的计算机程序产品,当该计算机程序产品在计算机上运行时,使得计算机执行上述实施例的方法。
[0378]
本技术实施例还提供一种芯片,所述芯片包括处理器与数据接口,所述处理器通过所述数据接口读取存储器上存储的指令,执行上述实施例的方法。
[0379]
可选地,作为一种实现方式,所述芯片还可以包括存储器,所述存储器中存储有指令,所述处理器用于执行所述存储器上存储的指令,当所述指令被执行时,所述处理器用于执行上述实施例中的方法。
[0380]
本技术实施例还提供一种电子设备,该电子设备包括上述实施例中的装置700、装置 800或装置900中的任一种或多种。
[0381]
图10为本技术实施例提供的一种芯片硬件结构,该芯片上包括神经网络处理器1000。该芯片可以被设置在如下任一种或多种装置或系统中:
[0382]
如图7所示的装置700、如图8所示的装置800、如图9中所示的装置900。
[0383]
上文方法实施例中的方法300、500或600均可在如图10所示的芯片中得以实现。
[0384]
神经网络处理器1000作为协处理器挂载到主处理器(host cpu)上,由主cpu分配
任务。神经网络处理器1000的核心部分为运算电路1003,控制器1004控制运算电路1003 获取存储器(权重存储器1002或输入存储器1001)中的数据并进行运算。
[0385]
在一些实现中,运算电路1003内部包括多个处理单元(process engine,pe)。在一些实现中,运算电路1003是二维脉动阵列。运算电路1003还可以是一维脉动阵列或者能够执行例如乘法和加法这样的数学运算的其它电子线路。在一些实现中,运算电路1003 是通用的矩阵处理器。
[0386]
举例来说,假设有输入矩阵a,权重矩阵b,输出矩阵c。运算电路1003从权重存储器1002中取矩阵b相应的数据,并缓存在运算电路1003中每一个pe上。运算电路1003 从输入存储器1001中取矩阵a数据与矩阵b进行矩阵运算,得到的矩阵的部分结果或最终结果,保存在累加器(accumulator)1008中。
[0387]
向量计算单元1007可以对运算电路1003的输出做进一步处理,如向量乘,向量加,指数运算,对数运算,大小比较等等。例如,向量计算单元1007可以用于神经网络中非卷积/非fc层的网络计算,如池化(pooling),批归一化(batch normalization),局部响应归一化(local response normalization)等。
[0388]
在一些实现种,向量计算单元能1007将经处理的输出的向量存储到统一存储器(也可称为统一缓存器)1006。例如,向量计算单元1007可以将非线性函数应用到运算电路 1003的输出,例如累加值的向量,用以生成激活值。在一些实现中,向量计算单元1007 生成归一化的值、合并值,或二者均有。在一些实现中,处理过的输出的向量能够用作到运算电路1003的激活输入,例如用于在神经网络中的后续层中的使用。
[0389]
上文方法实施例中的方法300、500或600可以由1003或1007执行。
[0390]
统一存储器1006用于存放输入数据以及输出数据。
[0391]
权重数据直接通过存储单元访问控制器1005(direct memory access controller, dmac)将外部存储器中的输入数据搬运到输入存储器1001和/或统一存储器1006、将外部存储器中的权重数据存入权重存储器1002,以及将统一存储器1006中的数据存入外部存储器。
[0392]
总线接口单元(bus interface unit,biu)1010,用于通过总线实现主cpu、dmac和取指存储器1009之间进行交互。
[0393]
与控制器1004连接的取指存储器(instruction fetch buffer)1009,用于存储控制器1004 使用的指令;
[0394]
控制器1004,用于调用指存储器1009中缓存的指令,实现控制该运算加速器的工作过程。
[0395]
在本技术实施例中,这里的数据可以是待处理的图像数据。
[0396]
一般地,统一存储器1006,输入存储器1001,权重存储器1002以及取指存储器1009 均为片上(on-chip)存储器,外部存储器为该npu外部的存储器,该外部存储器可以为双倍数据率同步动态随机存储器(double data rate synchronous dynamic random accessmemory,ddr sdram)、高带宽存储器(high bandwidth memory,hbm)或其他可读可写的存储器。
[0397]
除非另有定义,本文所使用的所有的技术和科学术语与属于本技术的技术领域的技术人员通常理解的含义相同。本文中在本技术的说明书中所使用的术语只是为了描述具
体的实施例的目的,不是旨在于限制本技术。
[0398]
需要说明的是,本文中涉及的第一、第二、第三或第四等各种数字编号仅为描述方便进行的区分,并不用来限制本技术实施例的范围。
[0399]
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0400]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0401]
在本技术所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
[0402]
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0403]
另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
[0404]
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:通用串行总线闪存盘(usb flash disk,ufd)(ufd也可以简称为u盘或者优盘)、移动硬盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0405]
以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应以所述权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1