基于改善的U-net的低剂量CT投影域中图像去噪方法与流程
基于改善的u-net的低剂量ct投影域中图像去噪方法
技术领域
[0001]
本发明涉及图像处理技术领域,尤其涉及一种基于改善的u-net的低剂量ct投影域中图像去噪方法。
背景技术:
[0002]
x射线计算机断层扫描技术(ct)迅速发展并广泛应用于医学诊断的各个领域。它在诊断人体内部细小病变有着很好的优势,因此在众多扫描仪器中有着不可替代的作用。在低剂量条件下,探测器由于接收到的光子数减少会导致投影数据被破坏,从而导致重建后的ct图像会有严重的噪声和伪影,影响放射科医生的判断。为了在保证病人安全的同时产生满足诊断需求的高质量图像,人们提出了很多与低剂量ct问题相关的研究方法。
[0003]
在传统的方法中,低剂量ct去噪的方法可以大致分为三类:正弦图修复,迭代重建(ir)技术和ct图像后处理。这些方法可以在一定程度上对低剂量ct问题产生积极的作用,但是由于扫描过程的复杂性,传统方法很难对噪声精确建模,并且各种算法会产生大量的计算开销。
[0004]
近年来,深度学习开始应用于去除低剂量ct图像的噪声问题,但这些基于网络的处理方法(例如,中国专利文献cn106600568a公开的一种低剂量ct图像去噪方法及装置)往往属于端到端图像域处理方法。噪声产生的源头位于投影域,经过重建算法后得到的ct图像中所包含噪声特征会变得更加复杂,使得端到端图像域处理方法不易精确识别噪声,去噪后可能会造成图像细节信息损失。
技术实现要素:
[0005]
针对现有的端到端图像域处理方法存在的噪声识别不准确、造成图像细节丢失的问题,本发明提供一种能够利用深度网络快速准确完成投影域低剂量ct图像噪声去除方法。
[0006]
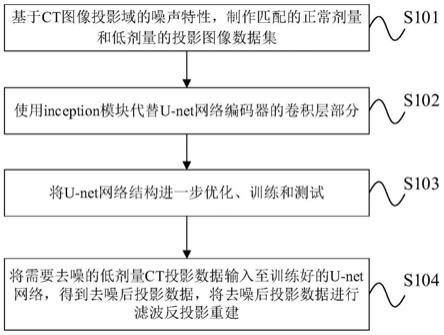
本发明提供一种基于改善的u-net的低剂量ct投影域中图像去噪方法,包括:
[0007]
步骤1:基于ct图像投影域的噪声特性,制作匹配的正常剂量和低剂量的投影图像数据集;
[0008]
步骤2:使用inception模块代替u-net网络编码器的卷积层部分;
[0009]
步骤3:将u-net网络结构进一步优化、训练和测试;
[0010]
步骤4:将需要去噪的低剂量ct投影数据输入至训练好的u-net网络,得到去噪后投影数据,将去噪后投影数据进行滤波反投影重建。
[0011]
进一步地,步骤1包括:
[0012]
步骤1.1:将正常剂量的ct图像利用siddon射线驱动方法生成扇形束几何投影数据;
[0013]
步骤1.2:在光源为单色x射线时,通过公式(1)所示的泊松噪声近似模拟低剂量ct投影中的噪声:
[0014]
z
i
~poisson{z
0i
exp(-s
i
)+r
i
}i=1,2
…
i
ꢀꢀ
(1)
[0015]
其中,z
i
是沿第i个x射线路径的入射光子数,z
0i
为x射线的初始入射强度,r
i
是沿第i个x射线路径的背景电子噪声,s
i
是衰减系数的线积分;
[0016]
步骤1.3:在正常剂量的投影数据中添加步骤1.2仿真得到的噪声,得到相应的低剂量的投影数据。
[0017]
进一步地,步骤2中,每层的inception模块包括3个分支;其中,第一个分支对输入进行1
×
1卷积;第二个分支先对输入进行1
×
1卷积,然后连接3
×
3卷积;第三个分支先对输入进行1
×
1卷积,然后连接5
×
5卷积。
[0018]
进一步地,每层的inception模块的3个分支最后通过聚合操作合并。
[0019]
进一步地,去除每层的inception模块中的池化层。
[0020]
进一步地,步骤3包括:
[0021]
步骤3.1:将原u-net网络中的编码器中的卷积层和解码器中的卷积层均加深为9层,且在每个卷积操作后都连接一个relu函数和一个用于替代池化的步长为2的卷积操作;
[0022]
步骤3.2:在编码器中,针对前4层卷积层中的每一个下采样操作,将特征通道的数量翻倍,后5层卷积层的特征通道数不变;
[0023]
步骤3.3:在解码器中,针对前5层卷积层中的每一个上采样操作,保持特征通道的数量不变,后4层卷积层的特征通道数减半。
[0024]
进一步地,解码器的每一层后面紧跟两个3
×
3的卷积,解码器最后一层的特征通道数为1,卷积核大小为1
×
1,用于输出经过处理的投影数据。
[0025]
进一步地,编码器中每层卷积层的特征通道的数量与解码器中对应层卷积层的特征通道的数量相同。
[0026]
本发明的有益效果:
[0027]
(1)考虑到噪声产生源头位于投影域,在最靠近噪声的区域来研究低剂量ct可能会更容易,并且条纹伪影在投影域上表现为分散噪声,本发明提供的基于改善的u-net的低剂量ct投影域中图像去噪方法,使用深度学习的方法对ct图像的投影数据直接进行处理,相较于端到端图像域处理方法,本发明主要利用投影域图像噪声特征的分布特性和u-net网络在处理小数据集方面的优势来完成投影图像的噪声去除,通过网络学习一种从包含噪声的低剂量ct正弦图到相应的无噪声正常剂量ct正弦图的端到端映射来去除噪声。
[0028]
(2)基于u-net网络本身能够融合高低层特征的结构,本发明引入inception模块可进一步加强低层区域对细节特征的提取能力,防止重要的结构信息被过度平滑,以确保网络在去噪的同时保存图像细节信息。本发明通过网络的结构改善,使得网络即使在数据集小的情况下,也能很好的进行网络训练,可以有效地去除低剂量ct中的图像噪声,提高图像质量,在保存重要结构信息和防止边缘模糊方面都有很好的优势。
[0029]
(3)每层的inception模块采用1
×
1、3
×
3、5
×
5的不同卷积核运算并行获取多尺度图像特征,在降低参数的同时增加了网络的深度和宽度。并且,inception模块的三个分支均使用了1
×
1卷积,通过多次使用1
×
1卷积,可以用很小的计算量就能增加一层特征变换和非线性化,实现了低成本的跨通道特征变换。
[0030]
(4)通过将编码器和解码器中卷积层加深为9层,使得u-net网络有更强的表征能力,可以更好地拟合图像特征。此外,利用快捷连接将低层区域获得多尺度特征与高层区域
的全局特征进行融合,在去噪的同时保持了图像的细节。
附图说明
[0031]
图1为本发明实施例提供的基于改善的u-net的低剂量ct投影域中图像去噪方法的流程示意图;
[0032]
图2为本发明实施例提供的改善的u-net网络结构图;
[0033]
图3为本发明实施例提供的inception模块的结构图。
具体实施方式
[0034]
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0035]
实施例1
[0036]
本发明实施例提供一种基于改善的u-net的低剂量ct投影域中图像去噪方法,包括:
[0037]
s101:基于ct图像投影域的噪声特性,制作匹配的正常剂量和低剂量的投影图像数据集;
[0038]
s102:使用inception模块代替u-net网络编码器的卷积层部分;
[0039]
s103:将u-net网络结构进一步优化、训练和测试;
[0040]
s104:将需要去噪的低剂量ct投影数据输入至训练好的u-net网络,得到去噪后投影数据,将去噪后投影数据进行滤波反投影重建。
[0041]
考虑到噪声产生源头位于投影域,在最靠近噪声的区域来研究低剂量ct可能会更容易,并且条纹伪影在投影域上表现为分散噪声,本发明实施例提供的基于改善的u-net的低剂量ct投影域中图像去噪方法,使用深度学习的方法对ct图像的投影数据直接进行处理,相较于端到端图像域处理方法,本发明主要利用投影域图像噪声特征的分布特性和u-net网络在处理小数据集方面的优势来完成投影图像的噪声去除,通过网络学习一种从包含噪声的低剂量ct正弦图到相应的无噪声正常剂量ct正弦图的端到端映射来去除噪声。
[0042]
并且,基于u-net网络本身能够融合高低层特征的结构,本发明实施例引入inception模块可进一步加强低层区域对细节特征的提取能力,防止重要的结构信息被过度平滑,以确保网络在去噪的同时保存图像细节信息。本发明通过网络的结构改善,使得网络即使在数据集小的情况下,也能很好的进行网络训练,可以有效地去除低剂量ct中的图像噪声,提高图像质量。
[0043]
实施例2
[0044]
在上述实施例的基础上,本发明实施例提供又一种基于改善的u-net的低剂量ct投影域中图像去噪方法,包括以下步骤:
[0045]
s201:将正常剂量的ct图像利用siddon射线驱动方法生成扇形束几何投影数据;
[0046]
s202:在光源为单色x射线时,通过公式(1)所示的泊松噪声近似模拟低剂量ct投影中的噪声:
[0047]
z
i
~poisson{z
0i
exp(-s
i
)+r
i
}i=1,2
…
i
ꢀꢀ
(1)
[0048]
其中,z
i
是沿第i个x射线路径的入射光子数,z
0i
为x射线的初始入射强度,r
i
是沿第i个x射线路径的背景电子噪声,s
i
是衰减系数的线积分;
[0049]
作为一种可实施方式,z
0i
被均匀的设置为105。
[0050]
s203:在正常剂量的投影数据中添加步骤s202仿真得到的噪声,得到相应的低剂量的投影数据。
[0051]
具体地,理论上,低剂量的ct投影数据可以看作是正常剂量的投影数据和噪声投影的一个近似叠加,低剂量的ct投影的噪声主要来源于量子噪声。因此,本发明实施例采用上述公式(1),直接对原始的投影数据进行处理,在正常剂量的投影数据中添加仿真的泊松噪声来模拟相对应的低剂量投影数据。
[0052]
s204:使用inception模块代替u-net网络编码器的卷积层部分;
[0053]
具体地,u-net网络的底层特征只经过单一的卷积操作就直接和高层特征进行融合,网络可能存在非线性学习能力不充分的问题。因此,本发明实施例为了更好的保存细节信息并且改善u-net浅层特征可能变换不充分的缺点,将编码器的卷积层全部替换为inception模块。
[0054]
如图3所示,每层的inception模块包括3个分支;其中,第一个分支对输入进行1
×
1卷积;第二个分支先对输入进行1
×
1卷积,然后连接3
×
3卷积;第三个分支先对输入进行1
×
1卷积,然后连接5
×
5卷积。每层的inception模块的3个分支最后通过聚合操作合并。为了保证经过卷积操作后,输入和输出大小一致,在卷积操作前,在原矩阵的边界上填充一些值,本实施例中使用“0”来进行填充。inception模块拥有多个分支的卷积操作,可以提高低层区域的线性变换能力,能够使网络更好的保存图像的细节信息。
[0055]
每层的inception模块采用1
×
1、3
×
3、5
×
5的不同卷积核运算并行获取多尺度图像特征,在降低参数的同时增加了网络的深度和宽度。并且,inception模块的三个分支均使用了1
×
1卷积,通过多次使用1
×
1卷积,可以用很小的计算量就能增加一层特征变换和非线性化,实现了低成本的跨通道特征变换。
[0056]
考虑到u-net网络本身就有池化层,并且过多的池化操作将会使特征提取不充分,导致重要的结构信息丢失,因此为了进一步优化u-net网络,去除每层的inception模块中的池化层。
[0057]
s205:将原u-net网络中的编码器中的卷积层和解码器中的卷积层均加深为9层,且在每个卷积操作后都连接一个relu函数和一个用于替代池化的步长为2的卷积操作;
[0058]
本步骤中,通过将编码器和解码器中卷积层加深为9层,使得u-net网络有更强的表征能力,可以更好地拟合图像特征。
[0059]
在步骤s204中已经使用inception模块代替u-net网络编码器的卷积层部分,为了使步骤s204加入的inception模块更好地融入u-net网络,通过步骤s206至步骤s207对网络的参数设置、结构分布和层数进行合理规划。
[0060]
s206:在编码器中,针对前4层卷积层中的每一个下采样操作,将特征通道的数量翻倍,后5层卷积层的特征通道数不变;
[0061]
例如,如图2所示,编码器中自上至下各卷积层的特征通道的数量依次为:32、64、128、256、256、256、256、256和256。
[0062]
s207:在解码器中,针对前5层卷积层中的每一个上采样操作,保持特征通道的数量不变,后4层卷积层的特征通道数减半。
[0063]
例如,如图2所示,解码器中自上至下各卷积层的特征通道数依次为:256、256、256、256、256、256、128、64和32。
[0064]
具体地,解码器的每一步都使用上采样操作,上采样操作是通过2
×
2的反卷积操作执行的。
[0065]
解码器的每一层后面紧跟两个3
×
3的卷积,解码器最后一层的特征通道数为1,卷积核大小为1
×
1,用于输出经过处理的投影数据。
[0066]
为了使网络的输入和输出准确匹配,编码器中每层卷积层的特征通道的数量与解码器中对应层卷积层的特征通道的数量相同。为了充分获取细节信息特征,将不同卷积操作获取的多尺度特征进行融合后,输入到解码器,和对应位置的特征图在通道上再次进行融合。由于在进行卷积操作前使用了填充操作,快捷连接(skip connection,如图2中的黑色箭头)两端的特征图大小一致,所以去除了剪切操作。利用快捷连接将低层区域获得多尺度特征与高层区域的全局特征进行融合,在去噪的同时保持了图像的细节。图2中,靠内的左右两列数字分别代表快捷连接的输入和输出的特征通道数。
[0067]
s208:在仿真数据集上进行网络的训练和测试。
[0068]
具体地,在步骤s201、步骤s203所获得的正常剂量的投影数据和对应的低剂量的投影数据中,随机选取数据作为训练集和测试集,利用仿真数据集进行网络的训练和测试,得到训练好的改善的u-net网络。
[0069]
作为一种可实施方式,训练和测试环境为:在amax工作站上的tensorflow(版本1.9.0)环境下完成网络的训练和测试。amax工作站的两个cpu型号均为intel xeon gold 5118,可用内存为128gb。网络训练和测试使用了一个型号为geforce rtx 2080ti的计算显卡。
[0070]
s209:将需要去噪的低剂量ct投影数据输入至训练好的u-net网络,得到去噪后投影数据,将去噪后投影数据进行滤波反投影重建。
[0071]
具体地,网络经过训练后获得网络参数,利用所得参数可以快速准确的完成投影域中图像噪声去除,具体为:首先低剂量投影图像经过编码器部分,从低层到高层逐层抑制噪声,以保证能够提取投影基本的信息,将低剂量投影转化到特征空间。然后经过解码器部分,网络可以根据卷积层从输入中提取的特征进行图像重建,最终输出去噪的投影,将去噪后的投影图进行滤波反投影重建可以获得校正后的ct图像。
[0072]
本发明提出的图像去噪方法主要利用投影域图像噪声特征的分布特性和u-net网络在处理小数据集方面的优势来完成投影图像的噪声去除,使用带有inception模块的u-net网络在ct图像投影域进行去噪,基于u-net网络本身能够融合高低层特征的结构,引入inception模块可进一步加强低层区域对细节特征的提取能力,以确保网络在去噪的同时保存图像细节信息。并且,为了进一步提高网络的性能,对网络进行了加深和优化。利用ct投影数据集对所提方法的性能进行了评估,证实了本发明所提方法的有效性,在视觉效果和定量指标均得到了满意的效果。本发明提出的方法能够快速准确的完成大批量的低剂量ct图像去噪。
[0073]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管
参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1