一种录播系统中教师检测与跟踪方法及系统与流程
本发明涉及运动检测技术领域,具体涉及一种录播系统中教师检测与跟踪方法及系统。
背景技术:
随着教育和科技的发展,传统的语音教育已经不能满足教育方式多元化的需要。教师进行课堂教育教学方式越来越追求可视化,学生通过课堂学习能力要求探究合作化,然而对于这些问题要求的实现,很大程度上要借助于现代化的信息管理技术基础设施,特别是课堂实践教学的可视化。
现有可使用的技术主要是基于运动检测的方法和模式识别的方法。基于运动检测的方法主要是采用背景建模等方法确定目标区域,然后基于特征来检测行人,这种方法最大的缺点是特别容易受到光线的干扰,检测出错误的目标;基于模式识别的方法主要是采用人工设计的特征,经过少量样本的训练然后用分类器进行分类,典型的组合是hog特征和svm分类器结合,这种方法在识别人这种非刚性的物体时精准度也不高。
随着人工智能的发展,基于深度学习的方法广泛应用到目标检测与识别任务,其中最具代表性的有yolo、ssd等端到端的检测网络,这些网络基于图像的检测精准度高,但是在视频处理时由于运动模糊的原因检测率会降低,并且网络计算复杂度高。
技术实现要素:
本发明提出的一种录播系统中教师检测与跟踪方法及系统,是在保证教师检测准确率的情况下,降低检测模型的复杂度,并使用卡尔曼滤波对坐标进行校正和预测。
为实现上述目的,本发明采用了以下技术方案:
包括以下步骤:
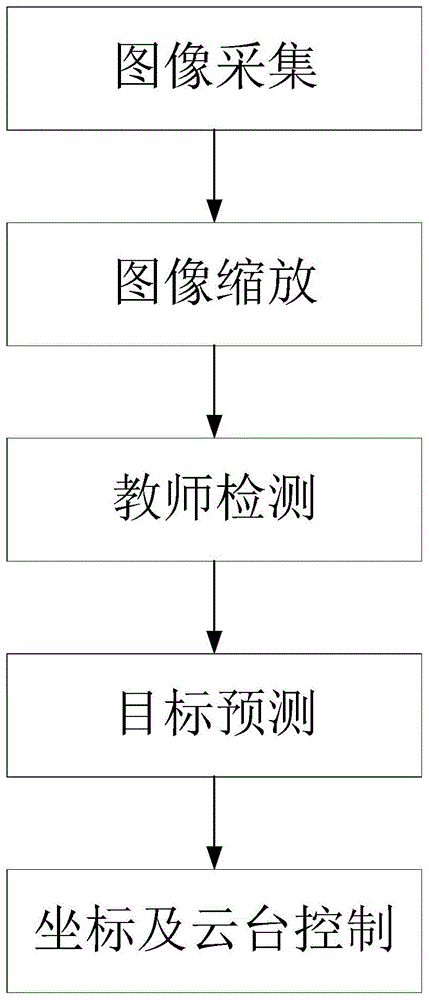
s100、通过固定在教室后方的摄像头获取教师上课的场景图像,并对图像进行预处理;
s200、对预处理的图像进行缩放;
s300、把缩放后的图像放入到训练好的教师检测网络进行检测,初步获取目标的坐标点;
s400、获取的目标点通过目标检测模块的修正与补充最终送入云台进行控制跟踪。
进一步的,所述s100中的对图像进行预处理为对图像做高斯滤波预处理操作。
进一步,所述s300中的训练好的教师检测网络,其中网络架构包含两个部分:backbone和extralayers;
backbone部分是对浅层特征的提取,所述backbone后面加入了rfb模块,rfb是一个多分支的卷积块,内部结构包含两部分:一、不同卷积核尺度的多分支卷积,用于模拟多尺度的人眼感受野;二、虫洞卷积操作,用于模拟人类视觉感知中感受野尺度与离心率间的关系;
其中多分支结构,具体地:先1×1卷积降低特征图的通道数,在每个分支上形成bottleneck结构,再接n×n卷积;把5×5卷积替换为两个堆叠的3×3卷积,不仅降低了参数量,也增加了模型的非线性能力,并进一步使用1×n+n×1卷积替换n×n卷积,增加shortcut设计;其次通过虫洞卷积来模拟人眼感受野,具体地,每个分支的常规卷积操作后,连接一个dilates卷积层,模拟人眼感受野的尺度与离心率。
进一步,s300中的教师检测网络整个网络的构建包含三个基本操作:basicconv层、池化层maxpool2d、rfb层;
basicconv层又包含三个基本操作:卷积层conv2d、批归一化层batchnorm2d、激活层relu;
backbone部分由4层basicconv和maxpool2d组合而成;
输入图像通过第一层basicconv得到32×300×300的特征图,然后通过maxpool2d把特征图处理成32×150×150,然后依次通过第二层、第三层basicconv和maxpool2d的组合处理得到128×38×38的特征图;
extralayers部分由rfb层和五层basicconv组合而成;
经过rfb处理后得到一个抽头f1,然后依次经过五层basicconv得到64×1×1的特征图并且分别得到五个抽头f2、f3、f4、f5、f6,最终把六个抽头送到检测层进行检测与定位。
进一步的,rfb模块划分成三个部分:一个分支结构、shortcut模块、激活单元relu;
其中,分支结构首先通过三个1×1的basicconv操作,在每个分支下分别接不同的卷积处理,最左边的一个分支连接一个3×3的basicconv操作后使用rate=1的空洞处理;中间一个分支依次经过两个3×3的basicconv操作后使用rate=3的空洞处理;右边一个分支依次经过5×5和3×3的basicconv操作后使用rate=5的空洞处理,三个分支最终通过连接处理接一个1×1的basicconv操作;
shortcut模块就是在最右边的分支1×1的basicconv操作后与分支结构的处理结果连接送入到relu层进行处理。
进一步的,所述训练好的教师检测网络的训练步骤如下:
(c1)收集老师课堂场景图片,按照coco或者voc格式对图像进行标注;
(c2)把图片按照3:1:1分成训练集、测试集、验证集;
(c3)利用pytorch搭建设计好的网络结构;
(c4)调节学习率、批大小、训练次数这些超参数;
(c5)得到收敛后的网络权重文件。
进一步的,所述s300中的把缩放后的图像放入到训练好的教师检测网络进行检测,其中具体检测步骤如下:
利用前向推理网络加载训练好的权重文件;把输入图像scale变换为300*300的大小送入检测网络;检测网络逐层提取特征并在detectionconvlayers层给出目标的坐标位置及该目标的可能性得分;该得分跟预先设定的阈值0.6进行比较,如果大于0.6则判定该目标是老师并返回坐标位置,如果该得分小于0.6判定为没有目标。
进一步的,所述s400中的预测模块采用卡尔曼滤波算法,卡尔曼滤波算法包括预测与校正两个阶段;
在预测阶段,滤波器使用上一状态的估计,做出对当前状态的预测;
在校正阶段,滤波器利用对当前状态的观测值修正在预测阶段获得的预测值,以获得一个更接进真实值的新估计值;
其中,卡尔曼滤波器计算过程如下:
预测:
p′k=apk-1at+q
校正:
kk=p′kht(hp′kht+r)-1
更新协方差估计:
pk=(i-kkh)p′k
其中,xk表示真实值,
另一方面,一种录播系统中教师检测与跟踪系统,包括以下单元,
图像采集模块,用于通过固定在教室后方的摄像头获取教师上课的场景图像,并对图像进行预处理;
图像缩放模块,用于对预处理的图像进行缩放;
教师检测模块,把缩放后的图像放入到训练好的教师检测网络进行检测,初步获取目标的坐标点;
云台控制模块,用于获取的目标点通过目标检测模块的修正与补充最终送入云台进行控制跟踪。
进一步的,包括以下子单元,
目标预测模块,用于在预测阶段使滤波器使用上一状态的估计,做出对当前状态的预测;
在校正阶段,使滤波器利用对当前状态的观测值修正在预测阶段获得的预测值,以获得一个更接进真实值的新估计值。
由上述技术方案可知,本发明的录播系统中教师检测与跟踪方法具有以下有益效果:
1)、本发明采用卷积网络作为老师特征的提取,能够克服运动检测方法对光线敏感性,提高目标的检测率。
2)、与常见的检测网络相比,能够更好的平衡复杂度与精准度之间的关系。
3)、采用卡尔曼滤波处理,不仅能修正检测的目标,还能解决运动模糊带来的目标丢失的问题。
附图说明
图1是本发明方法的流程示意图;
图2是本发明的教师检测的网络结构示意图;
图3是本发明的rfb模块结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
如图1所示,本实施例所述的录播系统中教师检测与跟踪方法,包括:
通过固定在教室后方的摄像头获取教师上课的场景图像,并对图像进行预处理;对预处理的图像进行缩放;把缩放后的图像放入到训练好的教师检测网络进行检测,初步获取目标的坐标点;获取的目标点通过目标检测模块的修正与补充最终送入云台进行控制。
其中,
(a)图像采集模块
采集教室中老师上课场景的图像,并对图像做高斯滤波预处理操作。
(b)图像缩放模块
采集设备获取图像的分辨率大小为4k,要通过插值方法对图像进行缩放。
(c)教师检测模块
面对复杂的场景,多变的形态,行人检测仍然是一项具有挑战性的工作。目前深度学习方法展现了在视觉检测任务中的优秀表现,但是这些方法很难在实时性及精准度之间取得良好的平衡。特别是在视频处理中,由于运动的模糊性,给行人检测任务增加了难度。
本发明借鉴ssd的检测框架,结合rfb模块设计出教师检测的网络结构,如图2所示;
网络架构主要包含两个部分:backbone和extralayers。backbone部分是对浅层特征的提取,这一部分的设计一般都是采用现有的网络设计,在此基础上进行微调,但是这样设计的网络不够灵活,一旦修改backbone的结构,从头训练的代价比较高,而且很难收敛。本设计在加入了rfb模块之后,可以对backbone部分通道进行裁减,而且从头开始训练很容易收敛。
整个网络的backbone部分是图中虚线箭头的部分,该部分是对ssd框架的backbone部分进行裁减,把通道数裁减为128,大大减小了计算复杂度。为了应对backbone的改变带来的收敛难的问题,在backbone后面加入了rfb模块,rfb模块结构如图3所示:
rfb模块受启发于人类视觉的感受野结构,将人眼感受野的尺度、离心率纳入考虑范围,不使用计算量大、层数深的主干网,即使通过轻量级的网络结构,也能提取到高判别性的特征;
rfb是一个多分支的卷积块,内部结构包含两部分:一、不同卷积核尺度的多分支卷积,用于模拟多尺度的人眼感受野;二、空洞卷积操作,用于模拟人类视觉感知中感受野尺度与离心率间的关系;
具体的说,图2所示的教师检测的网络结构,整个网络的构建包含三个基本操作:basicconv层、池化层(maxpool2d)、rfb层。basicconv层又包含三个基本操作:卷积层(conv2d)、批归一化层(batchnorm2d)、激活层(relu)。
backbone部分由4层basicconv和maxpool2d组合而成。输入图像通过第一层basicconv得到32×300×300的特征图,然后通过maxpool2d把特征图处理成32×150×150,然后依次通过第二层、第三层basicconv和maxpool2d的组合处理得到128×38×38的特征图。
extralayers部分由rfb层和五层basicconv组合而成。rfb层如图三介绍,经过rfb处理后得到一个抽头f1,然后依次经过五层basicconv得到64×1×1的特征图并且分别得到五个抽头f2、f3、f4、f5、f6。最终把六个抽头送到检测层进行检测与定位。
整个网络的构建包含三个基本操作:basicconv层、池化层(maxpool2d)、rfb层。basicconv层又包含三个基本操作:卷积层(conv2d)、批归一化层(batchnorm2d)、激活层(relu)。
backbone部分由4层basicconv和maxpool2d组合而成。输入图像通过第一层basicconv得到32×300×300的特征图,然后通过maxpool2d把特征图处理成32×150×150,然后依次通过第二层、第三层basicconv和maxpool2d的组合处理得到128×38×38的特征图。
extralayers部分由rfb层和五层basicconv组合而成。rfb层如图三介绍,经过rfb处理后得到一个抽头f1,然后依次经过五层basicconv得到64×1×1的特征图并且分别得到五个抽头f2、f3、f4、f5、f6。最终把六个抽头送到检测层进行检测与定位。
rfb模块如图三所示,可划分成三个部分:一个分支结构、shortcut模块、激活单元(relu)。
分支结构首先通过三个1×1的basicconv操作,在每个分支下分别接不同的卷积处理。最左边的一个分支连接一个3×3的basicconv操作后使用rate=1的空洞处理;中间一个分支依次经过两个3×3的basicconv操作后使用rate=3的空洞处理;右边一个分支依次经过5×5和3×3的basicconv操作后使用rate=5的空洞处理。三个分支最终通过连接处理接一个1×1的basicconv操作。
shortcut模块就是在最右边的分支1×1的basicconv操作后与分支结构的处理结果连接送入到relu层进行处理。
教师检测模块是训练好的,它的产生主要包含以下步骤:
(c1)收集老师课堂场景图片,按照coco或者voc格式对图像进行标注;
(c2)把图片按照3:1:1分成训练集、测试集、验证集;
(c3)利用pytorch搭建设计好的网络结构;
(c4)调节学习率、批大小、训练次数等超参数;
(c5)得到收敛后的网络权重文件。
具体检测步骤:利用前向推理网络加载训练好的权重文件;把输入图像scale变换为300*300的大小送入检测网络;检测网络逐层提取特征并在detectionconvlayers层给出目标的坐标位置及该目标的可能性得分;该得分跟预先设定的阈值0.6进行比较,如果大于0.6则判定该目标是老师并返回坐标位置,如果该得分小于0.6判定为没有目标。
(d)目标预测模块
当老师在上课移动的过程中会出现两种情况,一,由于老师是一种非刚体物体,使用教师检测模块检测出来的目标位置中心点会偏离;二,由于老师在运动过程中造成的运动模糊,会出现检测不到的情况。这两种情况分别会造成特写镜头的偏离与丢失,为了解决这两个问题,加入了目标预测模块。
目标预测模块采用卡尔曼滤波算法,卡尔曼滤波估计实际由两个过程组成:预测与校正,在预测阶段,滤波器使用上一状态的估计,做出对当前状态的预测。在校正阶段,滤波器利用对当前状态的观测值修正在预测阶段获得的预测值,以获得一个更接进真实值的新估计值。
卡尔曼滤波器计算过程如下:
预测:
p′k=apk-1at+q
校正:
kk=p′kht(hp′kht+r)-1
更新协方差估计:
pk=(i-kkh)p′k
其中,xk表示真实值,
在实际应用场景中,会有两种状态:一,老师在运动过程中,检测器检测到目标时,卡尔曼滤波器会预测当前帧的状态,然后用最新检测出来的状态来更新当前预测的状态,来获取最佳的检测位置;二,老师在运动过程中,检测器并未检测到目标,此时卡尔曼滤波会完全依赖之前的状态更新当前的检测状态。
(e)云台控制模块
经过预测模块得到的坐标最终发送给相机,相机通过visca协议控制云台转动,实现对老师的跟踪。
在使用时,教师检测与跟踪系统包括以下模块:
(1)图像采集单元,利用架设在教室后端的云台摄像机获取教师上课的场景图像并把图像送入图像缩放单元;
(2)图像缩放单元,根据设计好的检测网络,把上课的场景图像缩放到网络所需要的输入大小并把图像送入教师检测单元;
(3)教师检测单元,加载好预训练好的权重文件,根据权重参数与网络结构描述,提取老师特征并进行分类与定位,获取教师的坐标位置并把该坐标位置送入目标预测单元;
(4)目标预测单元,教师检测单元获取的初步位置通过卡尔曼滤波处理,得到修正后的目标位置并送入到云台控制单元;
(5)云台控制单元,根据目标的位置对云台进行控制,达到教师跟踪的目的。
由上可知,本发明采用卷积网络作为老师特征的提取,能够克服运动检测方法对光线敏感性,提高目标的检测率,与常见的检测网络相比,能够更好的平衡复杂度与精准度之间的关系,采用卡尔曼滤波处理,不仅能修正检测的目标,还能解决运动模糊带来的目标丢失的问题。
另一方面,一种录播系统中教师检测与跟踪系统,包括以下单元,
图像采集模块,用于通过固定在教室后方的摄像头获取教师上课的场景图像,并对图像进行预处理;
图像缩放模块,用于对预处理的图像进行缩放;
教师检测模块,把缩放后的图像放入到训练好的教师检测网络进行检测,初步获取目标的坐标点;
云台控制模块,用于获取的目标点通过目标检测模块的修正与补充最终送入云台进行控制跟踪。
进一步的,包括以下子单元,
目标预测模块,用于在预测阶段使滤波器使用上一状态的估计,做出对当前状态的预测;
在校正阶段,使滤波器利用对当前状态的观测值修正在预测阶段获得的预测值,以获得一个更接进真实值的新估计值。
可理解的是,本发明实施例提供的系统与本发明实施例提供的方法相对应,相关内容的解释、举例和有益效果可以参考上述方法中的相应部分。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!