基于集成神经网络的河流污染物通量智能计算与预测方法与流程
1.本发明涉及河流污染技术领域,具体涉及一种基于集成神经网络的河流污染物通量智能计算与预测方法。
背景技术:
2.近年来,随着我国工业化进程的不断推进,河流污染问题也在不断显现, 以珠江流域为例,大量高消耗,高污染工业园区建立,这些园区与周围地区的 产业规划不完善,污水处理不到位,对珠江水质带来不利的影响。而治理河流 污染极其重要的一步,便是计算及预测各河流的污染通量,量化每条河流受污 染的严重程度,明确各河流主要污染物,用这些数据指导政府或相关企业进行 针对性的污染治理。然而,由于污染源类型(点源/面源)存在显著的时空变化, 各河流径流量变化率对污染物通量变幅影响亦存在显著差异,若针对不同河流、 不同污染物的通量计算采用同样的计算算法,会导致计算结果与实际情况产生 偏差。因此,不应通过某一种给定的计算公式去计算所有河流的污染通量,而 要结合污染物类型、河流径流量时均变化剧烈与否及其他客观条件和需求,选 择最合适的计算公式。
技术实现要素:
3.本发明提供一种基于集成神经网络的河流污染物通量智能计算与预测方法,包括以下步骤:
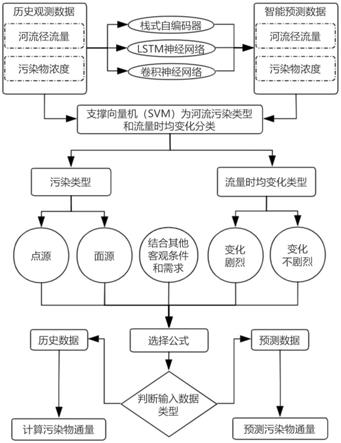
4.s1、输入污染物浓度与河流流量历史数据,判别河流主要污染物类型和流量时均变化类型,利用支撑向量机方法,实现河流主要污染物的污染源类型和流量时均变化程度的智能分类;
5.s2、依据s1中对于主要污染物和时均变化类型的判断,结合不同需求以及客观条件,调整污染物通量计算公式,进行污染物通量计算;
6.s3、应用卷积神经网络方法,结合长短期记忆人工神经网络和栈式自编码器预测污染物浓度与河流流量,将污染物浓度与河流流量预测数据输入s1进行智能分类,依据s1分类结果,结合预测数据,应用s2预测污染物通量。
7.本发明提供的技术方案带来的有益效果是:本发明实现了对河流污染源类型的智能判别,河流流量和污染物浓度的补缺与预测,具有精准量化河流污染程度的实际意义。
附图说明
8.图1为本发明一种基于集成神经网络的河流污染物通量智能计算与预测方法流程图;
9.图2为支撑向量机在高维空间构造超平面区分的两种样本;
10.图3为使用栈式自编码器、长短期记忆人工神经网络以及卷积神经网络处理历史数据流程图。
具体实施方式
11.为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地描述。
12.请参考图1,本发明提供一种基于集成神经网络的河流污染物通量智能计算与预测方法,针对现在对于河流污染物通量计算策略的不足做出改进,结合了人工智能深度学习的代表方法:支撑向量机(supportvectormachines,svm)、卷积神经网络(convolutional neuralnetworks,cnn)、长短期记忆人工神经网络(long
‑
short term memory,lstm)及栈式自编码器(stacked autoencoder, sae),实现对河流污染源类型的智能判别,河流流量和污染物浓度的补缺与预测,具有精准量化河流污染程度的实际意义,具体包括以下步骤:
13.s1、输入污染物浓度与河流流量历史数据,判别河流主要污染物类型和流量时均变化类型,利用支撑向量机方法,实现河流主要污染物的污染源类型和流量时均变化程度的智能分类;
14.综合污染指数是目前国际上评价河流时应用范围最广且成熟的一种方法,评价指标主要涵盖有机污染指标、氮和磷等;
15.污染指数包括以下指数:污染因子的污染指数、平均污染指数(average contaminative index,aci)和综合污染指数ici等,其公式分别为:
16.污染因子的污染指数:
[0017][0018]
式中,i为污染因子,c
i
为污染因子i的实测含量,s
i
为污染因子i的评价标准值,一般采用国家地表水环境质量标(gb3838
‑
2002)中的ⅲ类水质标准作为标准值。
[0019]
ici定义为:
[0020][0021]
式中,p
j
为平均污染指数,m为污染因子数。
[0022]
污染分担率表示单项污染因子指数对综合水质污染的贡献大小,污染分担率最高的因子即为水体的首要污染物;污染分担率定义为:
[0023][0024]
式中,p
ij
为某种污染因子的平均污染指数,k为综合污染指数。
[0025]
所述主要污染物类型包括点源和面源,流量时均变化类型包括明显和不明显。
[0026]
采用支撑向量机,根据数据构造最优超平面,在超平面中画出最优分类函数线,区分出污染物是点源还是面源,河流流量时均变化是明显还是不明显均被这一条函数线所区分,具体构造方法如下:
[0027]
假设训练样本集
[0028]
t={(x1,y1),(x2,y2),...,(x
n
,y
n
)}
[0029]
其中
[0030]
x
i
∈r
n
,y
i
∈{
‑
1,+1},i=1,2,...,n
[0031]
svm在特征空间中构造的超平面表示为:
[0032]
w
t
x+b=0
ꢀꢀ
(1)
[0033]
式中:w为法向量,决定超平面的方向;b为位移量,决定超平面与原点之间的距离;t为维度系数,若式(1)中超平面满足约束条件,式(2)则构成最优超平面。
[0034]
y
i
(w
t
x+b)≥1,i=1,2,...,n
ꢀꢀ
(2)
[0035]
假设训练数据集不是线性可分的,通常情况是训练数据集中有些特异点,将这些特异点除去后,剩下大部分的样本点组成的集合是线性可分的,对每个样本点引入松弛变量ξ
i
≥0,使函数间隔加上松弛变量大于等于1,式(2)转化为式(3)用于求解凸二次规划问题,目标值的最小函数为:
[0036][0037]
s.t. y
i
(w
t
x+b)≥1
‑
ξ
i
,ξ
i
≥0,i=1,2,...,n
ꢀꢀ
(3)
[0038]
式中,c为惩罚因子,c>0,控制对错分样本的惩罚程度,一般是由实际的应用问题来决定,c增大对误分类的惩罚增大,反之c减小则对于误分类的惩罚减小,按照最优化理论中凸二次规划的解法,加入拉格朗日乘法算子构造式(4)求解上述问题,同时寻找建立最优超平面函数,则:
[0039][0040]
式中,α
i
和μ
i
为拉格朗日乘子,α
i
≥0,μ
i
≥0,引入适当的内积函数k实现非线性变换,目的是将最优平面问题转化为对偶问题,则式(4)变为:
[0041][0042][0043]
假设最优解为a
*
,则最优分类函数f(x)为:
[0044][0045]
式(6)等价于将原来的输入空间的x
i
和x
j
的内积变换到新的特征空间用核函数k来代替,核函数将数据映射到一个高维线性空间中,使其在线性空间中线性可分,从而构造出最优超平面,完成数据分类。
[0046]
图2为svm在高维空间构造超平面区分的两种样本,采用不同的核函数可得到不同的分类效果,本实施例选择的是rbf核函数:
[0047]
k(x,x
i
)=exp(
‑
g||x
‑
x
i
||2)
ꢀꢀ
(7)
[0048]
式中:||x
‑
x
i
||2为2范数距离,g为核函数参数。
[0049]
将点源污染和面源污染区分的必要性在于,与点源污染集中排放废污水相比,面源污染具有许多显著不同的特点,表现为随机性、广泛性、滞后性、模糊性、潜伏性、研究和控制难度大。其主要特征概括如下:
[0050]
发生具有随机性,因为面源污染主要受水文循环过程主要为降雨以及降雨形成径流的过程的影响和支配,而降雨径流具有随机性,所以由此产生的面源污染从时空上都具有随机性。
[0051]
污染物的来源和排放点不固定,排放具有间歇性,而点源排放比较有规律如排放量、排放时间、排放地点等污染负荷的时间变化次降雨径流过程、年内不同季节及年际间和空间不同发生地点变化幅度大。
[0052]
采用svm的必要性在于,svm是一种二分类模型,它将实例的特征向量映射为空间中的一些点,svm的目的就是想要画出一条线,以“最好地”区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。
[0053]
s2、依据s1中对于主要污染物和时均变化类型的判断,结合不同需求以及客观条件,调整污染物通量计算公式,进行污染物通量计算;
[0054]
在估算河流污染物通量的研究中,尽管估算方法有许多种,均可用来进行估算,但由于不同估算方法计算出来的污染物年通量值相差悬殊,应该非常谨慎地选定估算方法。河流污染物入海通量通常以年为时段进行估算,与断面瞬间通量相比,估算时段通量的估算误差相对较为困难,时段的跨度越大,时段通量波动变化的方式也就越复杂,而用有限的瞬间实测数据进行估算误差也就越大。通量估算的实测误差来源包括:测流误差、水质采样误差、水质分析误差、断面离散采样的代表性不强、采样频率带来的误差等。估算流域河流污染物入海年时段通量,其误差主要由两点引起:点源与非点源差异引起的水质监测数据代表性不强;水文水质数据不同步引起的时均离散误差。针对这些存在的问题,需要根据分时段通量和、时段平均浓度与时段水量之积两类估算方法构造了5种时段通量的计算公式,具体如下:
[0055]
(1)采用瞬时浓度c
i
的平均值与瞬时流量q
i
的平均值的乘积进行通量计算, 该方法忽略径流量时均变化的影响;
[0056][0057]
(2)采用瞬时浓度c
i
的平均值与时段平均流量的乘积进行通量计算,该方法突出径流量时均变化的影响;
[0058][0059]
(3)采用求瞬时浓度c
i
与瞬时流量q
i
乘积的平均值进行通量计算,该方法忽略径流量时均变化的影响,但突出了点源污染;
[0060][0061]
(4)采用瞬时浓度c
i
与代表时段平均流量q
i
乘积的平均值进行通量计算, 该方法突出径流量时均变化的影响,同时也突出了非点源污染;
[0062][0063]
(5)采用时段通量平均浓度与时段平均流量q的乘积进行通量计算,该方法突出总径流量时均变化的影响,同时也突出了非点源污染:
[0064][0065]
w为估算时间段的污染物通量;k为不同估算时间段的转换系数;n为估算时间段内的采样次数;c
i
为样品i的浓度值;
[0066]
s3、应用卷积神经网络方法,结合长短期记忆人工神经网络和栈式自编码器预测污染物浓度与河流流量,将污染物浓度与河流流量预测数据输入s1进行智能分类,依据s1分类结果,结合预测数据,应用s2预测污染物通量,请参考图3,具体如下:
[0067]
s31、利用栈式自编码器自主学习和挖掘数据的特性,通过数据降维从输入的数据中去除冗余信息,获得数据的真正特征,根据这些特征,就可以用河流污染物浓度和河流流量已有数据推测缺测数据,从而对缺测数据进行填补;
[0068]
s32、利用长短期记忆人工神经网络选择性遗忘历史信息,并且记忆新的记忆信息的特性,在历史信息中提取关键,遗忘其余部分,记忆新信息,随时间推移,新信息变为历史信息,再次选择关键部分记忆,遗忘其余部分,不断重复,找到数据随时间变化的规律,对河流污染物浓度和河流流量进行时间维度上的关联性提取,最终用历史数据推算预测数据;
[0069]
s33、利用卷积神经网络卷积层和池化层压缩数据,增强空间关键特征的特性,对河流污染物浓度和河流流量进行空间维度上的关联性提取,对上一步的预测数据进行修正。
[0070]
使用sae对数据缺失值进行预测和填充的具体步骤如下:
[0071]
s311、将原始数据作为sae的输入,训练第一个隐藏层的网络参数,并用训练好的参数算出第一个隐藏层的输出;
[0072]
s312、把上一层网络的输出作为其下一层网络的输入,用同样的方法训练该层网络的参数;重复这一步骤,直到训练完最后一个隐藏层;
[0073]
s313、将s312中的输出作为softmax分类器的输入,结合原始数据的标签来训练softmax分类器的网络参数;
[0074]
s314、计算整个网络(包括所有隐藏层和一个softmax分类器)的代价函数,以及该网络对每个参数的偏导函数值;
[0075]
s315、用s311、s312和s313的网络参数作为整个深度网络的初始化参数值,然后用优化算法迭代求出代价函数最小值附近的参数值,并作为整个网络最后的最优参数值。
[0076]
sae采用的是无监督学习特征的方式,而softmax是一种监督式的学习算法,二者结合构建的sae模型结合了无监督与有监督的优点,能够对缺测数据进行预测。
[0077]
然后,使用lstm处理输入数据时间关联性的问题,对时间序列输入的数据进行特征提取,解决河流污染物浓度时间依赖性的问题,lstm网络又因为同层神经元有耦合,且能够长时间记忆信息,从而可以在时间维度上,提取输入数据的时间特征,在时间序列问题的
处理上表现出了优越性,因而在自然语言处理领域得到了广泛的应用,而在河流污染物浓度预测领域中,则可以用于对河流污染物浓度进行时间维度上的关联性提取。
[0078]
最后则可以依靠cnn对空间纬度关联性进行提取,以及用非线性模型预测数据。基于传统机器学习方法的污染物浓度预测方法,较之于传统预测的方法,将非线性的因素纳入了预测体系,提高了预测的精度。
[0079]
传统的机器学习法将非线性引入预测过程,但是由于网络层少,只能对数据进行浅层学习;不能深度挖掘数据特征的时空关联。因此,我们构造了基于深度学习预测方法,基于深度学习预测方法能够解决传统方法中的瓶颈问题,能对大数据进行有效集成,并且其独特的网络结构能够实现对污染物数据在时空维度的联动性分析。
[0080]
对于一个cnn来说,卷积层的层数和池化层的层数是可以通过人为设定的。最终,通过对输入数据中关键特征的识别对污染物浓度进行空间维度上的关联性提取。通过对现有数据缺失的填补,数据时空关联性的分析,对河流流量数据和污染物数据进行预测,再进行其他操作。
[0081]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1