一种图像特征点提取方法及系统与流程
1.本发明涉及图像处理技术领域,特别是涉及一种基于多尺度卷积和可变形卷积的图像特征点提取方法及系统。
背景技术:
2.随着计算机硬件的快速发展和大数据时代的来临,计算机视觉领域获得了蓬勃的发展。图像特征点检测任务是计算机视觉领域的底层任务,对许多更高层的任务起到至关重要的支撑作用,精确且鲁棒的特征点检测,能提升如三维重建、视觉slam、图像配准等任务的精度。因此,如何在复杂环境下精确鲁棒地检测图像中的特征点是计算机视觉技术在实际应用中亟待解决的难题。
3.随着深度学习的兴起,卷积神经网络在计算机视觉领域开始广泛应用,如何利用深度学习进行特征点检测、描述和匹配也成为了研究的热点。根据深度学习在这些研究中起到的作用,可以将其分为三类:使用传统算法检测的特征点作为监督信息进行训练的方法,采用自监督特征描述网络+手工筛选特征点的方法,和采用自监督方式同时训练特征点检测和描述网络的方法。由于采用sift等传统策略提取的特征进行监督会导致特征点检测网络的上限被选用作为监督的人工设计检测器所限制,无法取得更优的效果,因此,采用自监督方式训练网络完成特征提取成为了利用深度学习提取特征点任务中的主流方法。但在特征点的提取过程中,卷积神经网络每一层的尺度变化较大,且只能以固定尺寸的卷积核对输入的特征图进行卷积,缺乏多尺度信息的融合;同时,图像局部的纹理形状并不规则,导致卷积层提取时可能引入无关信息、破坏局部纹理的完整性。所以如何融合多尺度的图像特征信息、更好的描述图像局部特征成为提高特征点提取网络性能的关键。
4.基于此,亟需一种精确而鲁棒的特征点提取方法及系统。
技术实现要素:
5.本发明的目的是提供一种图像特征点提取方法及系统,通过在特征点提取模型中引入多尺度卷积层和可变形卷积层,能够融合多尺度的图像特征信息,并能够更好的描述图像局部特征,从而实现精确而鲁棒的特征点提取。
6.为实现上述目的,本发明提供了如下方案:
7.一种图像特征点提取方法,所述提取方法包括:
8.构建初始特征点提取模型;所述初始特征点提取模型包括特征提取模块;所述特征提取模块包括多尺度卷积层和可变形卷积层;
9.利用训练数据集对所述初始特征点提取模型进行训练,得到训练后特征点提取模型;所述训练数据集包括多张训练用图像;
10.将待处理图像输入所述训练后特征点提取模型,提取所述待处理图像的特征点。
11.一种图像特征点提取系统,所述提取系统包括:
12.模型构建模块,用于构建初始特征点提取模型;所述初始特征点提取模型包括特
征提取模块;所述特征提取模块包括多尺度卷积层和可变形卷积层;
13.训练模块,用于利用训练数据集对所述初始特征点提取模型进行训练,得到训练后特征点提取模型;所述训练数据集包括多张训练用图像;
14.提取模块,用于将待处理图像输入所述训练后特征点提取模型,提取所述待处理图像的特征点。
15.根据本发明提供的具体实施例,本发明公开了以下技术效果:
16.本发明用于提供一种图像特征点提取方法及系统,先构建初始特征点提取模型,初始特征点提取模型包括特征提取模块,特征提取模块包括多尺度卷积层和可变形卷积层。利用训练数据集对初始特征点提取模型进行训练,得到训练后特征点提取模型。将待处理图像输入训练后特征点提取模型,即可提取待处理图像的特征点。本发明通过在特征点提取模型中引入多尺度卷积层和可变形卷积层,能够融合多尺度的图像特征信息,并能够更好的描述图像局部特征,解决缺乏多尺度信息的融合且会破坏局部纹理的完整性的问题,从而实现精确而鲁棒的特征点提取,对图像特征提取的研究与实际应用具有重要的理论和实践价值。
附图说明
17.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
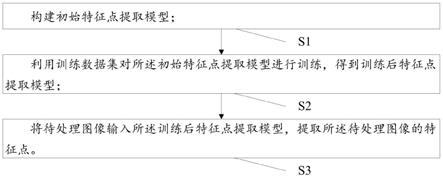
18.图1为本发明实施例1所提供的提取方法的方法流程图;
19.图2为本发明实施例1所提供的提取方法的原理图;
20.图3为本发明实施例1所提供的特征点提取模型的网络结构图;
21.图4为本发明实施例1所提供的卷积注意力子模块的网络结构图;
22.图5为本发明实施例1所提供的坐标注意力子模块的网络结构图;
23.图6为本发明实施例2所提供的提取系统的系统框图。
具体实施方式
24.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
25.本发明的目的是提供一种图像特征点提取方法及系统,通过在特征点提取模型中引入多尺度卷积层和可变形卷积层,能够融合多尺度的图像特征信息,并能够更好的描述图像局部特征,从而实现精确而鲁棒的特征点提取。
26.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
27.实施例1:
28.本实施例用于提供一种图像特征点提取方法,其为一种采用自监督方式训练的特
征点提取方法,能实现多尺度、鲁棒的特征点提取。如图1和图2所示,本实施例的提取方法包括:
29.s1:构建初始特征点提取模型;所述初始特征点提取模型包括特征提取模块;所述特征提取模块包括多尺度卷积层和可变形卷积层;
30.s2:利用训练数据集对所述初始特征点提取模型进行训练,得到训练后特征点提取模型;所述训练数据集包括多张训练用图像;
31.s3:将待处理图像输入所述训练后特征点提取模型,提取所述待处理图像的特征点。
32.本实施例的待处理图像可以为以不同角度对同一自然场景进行拍照后得到的自然图像,具体可包括利用相机在第一角度下对自然场景进行拍照所得到的第一自然图像和利用相机在第二角度下对自然场景进行拍照所得到的第二自然图像,且第一自然图像和第二自然图像部分重叠。在s3中,将两张待处理图像均输入至训练后特征点提取模型,分别获取获取第一自然图像的第一特征点和第二自然图像的第二特征点。对第一特征点和第二特征点进行匹配,并利用匹配成功的特征点对计算第一自然图像和第二自然图像间的变换矩阵,根据该变换矩阵对第一自然图像和第二自然图像进行拼接,即可得到关于该自然场景的广角图像。
33.s1中,多尺度卷积的思想为:在同一层卷积层中,对不同的通道采用不同步长或空洞率的卷积核进行特征提取并进行融合。可变形卷积的思想为:在卷积层中额外预测卷积采样点的偏移量,以此实现不规则区域的特征提取。通过在特征点提取模型中引入多尺度卷积层和可变形卷积层,能够融合多尺度的图像特征信息,并能够更好的描述图像局部特征,进一步改善模型对多尺度特征和图像不规则区域的特征提取能力,从而实现精确而鲁棒的特征点提取。
34.本实施例的初始特征点提取模型还包括特征点检测模块和描述子提取模块,特征点检测模块和描述子提取模块均与特征提取模块相连接。特征提取模块用于提取输入图像的特征。特征点检测模块用于基于输入图像的特征确定输入图像中每一像素点为特征点的概率。按照概率从大到小的顺序对像素点进行排序,并选取前n个像素点作为特征点,即可确定输入图像的特征点的坐标。描述子提取模块用于基于输入图像的特征确定输入图像中每一像素点的特征描述符。本实施例包含特征点检测模块和描述子提取模块,能够同时输出特征点的坐标以及特征点的特征描述符,二者相辅相成,能够使模型最终获得更精准更鲁棒的结果。
35.具体的,特征点检测模块包括特征点重复度子模块和特征点置信度子模块,特征点重复度子模块和特征点置信度子模块均与特征提取模块相连接。特征点重复度子模块用于基于输入图像的特征计算输入图像中每一像素点对应的局部特征区域在图像范围内的重复程度。特征点置信度子模块用于基于输入图像的特征计算输入图像中每一像素点为特征点的置信度。每一像素点为特征点的概率即为该像素点对应的局部特征区域在图像范围内的重复程度和该像素点为特征点的置信度的乘积。
36.更为具体的,如图3所示,本实施例的特征提取模块还包括第一卷积层(3*3conv1)、第二卷积层(3*3conv2)和第三卷积层(3*3conv3),第一卷积层、第二卷积层、第三卷积层、多尺度卷积层和可变形卷积层顺序连接。特征点重复度子模块包括依次连接的第
四卷积层(1*1conv)和第一l2正则化层。特征点置信度子模块包括依次连接的第五卷积层(1*1conv)和第二l2正则化层。描述子提取模块包括第三l2正则化层。
37.作为一种可选的实施方式,本实施例的特征提取模块还包括卷积注意力子模块和坐标注意力子模块。卷积注意力子模块连接于多尺度卷积层和可变形卷积层之间,多尺度卷积层分别通过第一连接通道和第二连接通道与卷积注意力子模块相连接,卷积注意力子模块还与可变形卷积层相连接。坐标注意力子模块连接于可变形卷积层和特征提取模块的输出端之间,可变形卷积层分别通过第三连接通道和第四连接通道与坐标注意力子模块相连接,坐标注意力子模块还与特征提取模块的输出端相连接。在特征点提取模型中增加设置卷积注意力子模块和坐标注意力子模块,能够进一步提高特征点提取的位置精度和描述子可区分度。
38.如图4所示,其为卷积注意力子模块的网络结构图。卷积注意力子模块包括依次连接的全局平均池化层、全局最大池化层、全连接层、relu激活函数、1
×
1卷积层、sigmoid激活函数、第一拼接层通道域平均池化层、7
×
7卷积层和第二拼接层且输入特征还直接输入至第一拼接层,该输入特征即为多尺度卷积层的输出特征,输入特征与全局平均池化层之间的连接通道即为第一连接通道,输入特征与第一拼接层之间的连接通道即为第二连接通道。第一拼接层对输入至第一拼接层的特征进行拼接,第一拼接层的输出还直接输入到第二拼接层,第二拼接层用于对输入至第二拼接层的特征进行拼接,第二拼接层的输出即为卷积注意力子模块的输出特征。
39.如图5所示,其为坐标注意力子模块的网络结构图。坐标注意力子模块包括依次连接的池化层、拼接层、卷积层(conv2d)、归一化层(batchnorm)、relu激活函数、通道分离层、卷积激活层和第三拼接层池化层包括并联的x方向平均池化层和y方向平均池化层,x方向平均池化层和y方向平均池化层均与拼接层连接。卷积激活层包括由卷积层(conv2d)和sigmoid激活函数构成的两个支路,两个sigmoid激活函数均与第三拼接层连接。输入特征还直接与第三拼接层连接,该输入特征即为可变形卷积层的输出特征,输入特征与池化层之间的连接通道即为第三连接通道,输入特征与第三拼接层之间的连接通道即为第四连接通道,第三拼接层对输入至第三拼接层的特征进行拼接,第三拼接层的输出即为坐标注意力子模块的输出特征,也即为特征提取模块提取的输入图像的特征。
40.输入图像进入特征点提取模型后,依次经过32通道、64通道、128通道的3*3卷积层,得到128维的特征图,再经过一个结合通道注意力机制的多尺度卷积层(即多尺度卷积层和卷积注意力子模块)和一个结合坐标注意力机制的可变形卷积层(即可变形卷积层和坐标注意力子模块),得到输入图像的特征。输入图像的特征经过一个1*1卷积层和一个l2正则化层,将每个像素点的输出限制到0~1之间,得到像素点为特征点的置信度;输入图像的特征经过另一个1*1卷积层和另一个l2正则化层,将每个像素点的输出限制到0~1之间,得到像素点对应的局部特征区域在图像范围内的重复程度,最终每个像素点为特征点的概率由每个像素点为特征点的置信度与该像素点对应的局部特征区域在图像范围内的重复程度相乘得到;输入图像的特征直接经过一l2正则化层,即可得到每一像素点的128维的特征描述符。
41.作为一种可选的实施方式,本实施例的可变形卷积层为受单应矩阵约束的可变形卷积层,通过对可变形卷积层添加单应矩阵约束,仅需利用offset层预测该层四个采样点
的偏移量即可确定单应矩阵,将单应矩阵应用于可变形卷积层中,即可利用单应矩阵快速预测其他点的偏移量,获得不规则区域的特征图,可以节省计算量,简化可变形卷积层的计算过程。
42.其中,在计算可变形卷积层对应的单应矩阵的过程中添加归一化约束,单应矩阵的求取过程包括:
43.(1)对用于计算单应矩阵的多个采样点进行尺度标准化变换,得到变换后参数;
44.利用offset层预测多个采样点的偏移量,在本实施例只需选取4个采样点,依据4个采样点的偏移量即可计算得到单应矩阵。对多个采样点进行尺度标准化变换,得到变换后参数具体包括:对多个采样点的加偏移量之前的坐标pi=(xi,yi,wi)
t
施加一个相似变换,使得每一采样点到坐标原点的平均距离为1.414,得到每一采样点的相似变换后坐标,然后令每一采样点的相似变换后坐标加上该采样点对应的偏移量,得到每一采样点对应的偏移后坐标,再对偏移后坐标进行相似变换的逆变换,得到原坐标系下的每一采样点的加偏移量之后的坐标p'i=(x'i,y'i,w'i)
t
。变换后参数即包括每一采样点的加偏移量之前的坐标和加偏移量之后的坐标。
45.(2)基于变换后参数,利用dlt算法计算单应矩阵的参数,得到可变形卷积层对应的单应矩阵。
46.本实施例通过直接线性变换算法(dlt)来求解单应矩阵。固定单应矩阵的平移为0,最后一个元素h
33
=1,将单应矩阵h∈r3×3展平为向量h∈r6×1,则有:
[0047][0048]
利用上述公式即可基于变换后参数计算得到单应矩阵。
[0049]
本实施例在计算可变形卷积层对应的单应矩阵的过程中添加归一化约束,能够提升单应矩阵计算的稳定性,使计算得到的单应矩阵更加鲁棒,精度更高。
[0050]
在s2之前,本实施例的提取方法还包括对训练数据集进行数据增强,得到增强后数据集,并以增强后数据集作为新的训练数据集。
[0051]
其中,对训练数据集进行数据增强,得到增强后数据集可以包括:对于训练数据集中的每一训练用图像,采用多种变换方式对训练用图像进行变换,得到训练用图像对应的多张变换后图像,所有变换后图像组成增强后数据集。变换方式包括图片缩放、水平翻转、随机平移、随机旋转、颜色通道缩放、添加噪声、随机单应矩阵扰动、色彩抖动、随机裁切和明暗度调节。对训练数据集提供的训练用图像进行随机裁切,能够获得大量训练数据,明暗度调节即为对图像明暗度进行随机变化,能够有效应对现实场景中光照的变化,通过添加随机单应矩阵扰动可以获得大量虚拟的不同视角下同一场景的图像,有助于模型训练。单应矩阵扰动的幅度可在10%以内。通过以上数据增强操作,能够获得大量的训练数据。
[0052]
本实施例针对现实情况下的复杂场景,采用了比现有技术更加多样化的数据增强
方式,实现对可能出现的各种类型场景的覆盖,基本覆盖了现实中的各种情况,同时极大地增大了数据量,有效提升了网络的泛化能力。
[0053]
利用上述得到增强后数据集作为训练数据集,s2可以包括:
[0054]
(1)从训练数据集中随机抽取若干张训练用图像组成第一数据集;
[0055]
(2)将第一数据集输入初始特征点提取模型,得到第一数据集中每一训练用图像的第一检测结果;所述第一检测结果包括训练用图像中每一像素点为特征点的概率和每一像素点的特征描述符;
[0056]
(3)对训练用图像施加一个随机的单应变换,得到每一训练用图像对应的变换后图像,该变换后图像与训练用图像为同一场景下的图像,所有变换后图像组成第二数据集;
[0057]
(4)将第二数据集输入初始特征点提取模型,得到第二数据集中每一变换后图像的第二检测结果;所述第二检测结果包括变换后图像中每一像素点为特征点的概率和每一像素点的特征描述符;
[0058]
(5)以所有第一检测结果和所有第二检测结果作为输入,基于损失函数计算损失值;
[0059]
具体的,本实施例所用的损失函数为:
[0060]
l
total
=λ
det
l
det
+λ
desc
l
desc
;
[0061]
其中,l
total
为损失函数;l
det
为特征点检测模块的检测子损失;l
desc
为描述子提取模块的描述子损失;λ
det
和λ
desc
分别为检测子损失和描述子损失对应的权重。
[0062]
检测子损失l
det
由余弦相似度损失l
cosim
和差异度损失l
peaky
构成。
[0063][0064]
其中,p为像素点p的邻域点所构成的集合;|p|为像素点p的邻域点的个数;p
′
为像素点p的邻域点;s[p]为像素点p为特征点的概率;s[p
′
]为邻域点p
′
为特征点的概率;cosim代表余弦角。
[0065]
为保证选出的特征点在局部区域内有显著的大小差异,本实施例采用差异度损失l
peaky
。
[0066][0067]
其中,i为训练用图像。
[0068][0069]
其中,i
′
为上述训练用图像对应的变换后图像;p1为像素点p1的邻域点所构成的集合,像素点p1为i
′
中与i中的像素点p相对应的像素点;|p1|为像素点p1的邻域点的个数;p
′1为像素点p1的邻域点;s[p
′1]为邻域点p
′1为特征点的概率。
[0070]
差异度损失l
peaky
=0.5(l
peaky
(i)+l
peaky
(i
′
))。
[0071]
检测子损失l
det
=l
cosim
+0.5(l
peaky
(i)+l
peaky
(i
′
))。
[0072]
描述子损失l
desc
用于衡量两幅图像中同一个特征点生成的特征描述符是否相似。
按照像素点为特征点的概率对所有像素点进行排序,并选取前n个像素点作为特征点,即可得到训练用图像i对应的n个特征点和变换后图像i
′
对应的n个特征点。设(x1,x2,...,xn)为训练用图像i中的某一特征点与变换后图像i
′
中n个特征点匹配后的排序队列,其按照描述子距离从小到大的顺序进行排列,xi为训练用图像i中的特征点的特征描述符与变换后图像i
′
中第i个特征点的特征描述符之间的描述子距离。计算训练用图像与变换后图像之间的单应矩阵,训练用图像中的像素点通过该单应矩阵能够投影到变换后图像中。将(x1,x2,...,xn)分为正确匹配集合s
q+
和错误匹配集合s
q-,具体根据单应矩阵将训练用图像i中的特征点投影到变换后图像中,确定投影点的位置,如果变换后图像i
′
中第i个特征点与投影点在变换后图像中的距离在预设距离阈值内,则第i个特征点对应的描述子距离即属于正确匹配集合,否则,则第i个特征点对应的描述子距离即属于错误匹配集合。
[0073][0074]
其中,preck为比例系数,其含义为(x1,x2,...,xn)的前k个描述子距离中属于正确匹配集合的个数;k=1,2,...,n;ap(q)为平均精度损失,其代表第k个描述子距离属于正确匹配集合的情况下preck的平均取值,该值越大越好,其物理意义为,若第k个描述子距离属于正确匹配集合,则希望比它的描述子距离更小,排名更靠前的描述子距离属于正确匹配集合的个数越多越好。|s
q+
|代表正确匹配集合中元素的个数。
[0075]
其中,1[
·
]是一个函数,其表达式为:
[0076][0077]
描述子损失l
desc
=1-[ap(q)r[q]+k(1-r[q])]。
[0078]
其中,r[q]为特征点q对应的局部特征区域在图像范围内的重复程度;k为超参数。
[0079]
将每一相对应的训练用图像和变换后图像输入上述损失函数中,得到一个损失值,然后将所有损失值求平均,即可得到此次迭代的损失值。
[0080]
(6)基于损失值对初始特征点提取模型的网络参数进行优化调整,得到调整后特征点提取模型;
[0081]
(7)判断是否达到预设迭代终止条件;预设迭代终止条件可为迭代次数达到最大迭代次数或者损失值小于损失值阈值;若是,则以调整后特征点提取模型作为训练后特征点提取模型,结束迭代;若否,则以调整后特征点提取模型作为下一迭代中的初始特征点提取模型,返回“从所述训练数据集中随机抽取若干张训练用图像组成第一数据集”的步骤,继续迭代。
[0082]
本实施例通过上述损失函数,对整个特征点提取模型的各部分网络参数进行不断地迭代优化,从而端到端的对整个模型进行训练,优化方法采用adam(adaptive moment estimation,自适应矩估计)优化器,初始学习率为0.001,batch大小为4,每隔五个epoch将学习率衰减为原来的90%,训练25个epoch后得到最终的训练用特征点提取模型。
[0083]
s3可以包括:
[0084]
(1)将待处理图像输入训练后特征点提取模型,得到待处理图像的第三检测结果;所述第三检测结果包括待处理图像中每一像素点为特征点的概率和每一像素点的特征描述符;
[0085]
(2)按照概率值从大到小的顺序对所有像素点进行排序,并选取前n个像素点作为待处理图像的特征点。便可以同时得到待处理图像的特征点的坐标和特征描述符。
[0086]
实施例2:
[0087]
本实施例用于提供一种图像特征点提取系统,如图6所示,所述提取系统包括:
[0088]
模型构建模块m1,用于构建初始特征点提取模型;所述初始特征点提取模型包括特征提取模块;所述特征提取模块包括多尺度卷积层和可变形卷积层;
[0089]
训练模块m2,用于利用训练数据集对所述初始特征点提取模型进行训练,得到训练后特征点提取模型;所述训练数据集包括多张训练用图像;
[0090]
提取模块m3,用于将待处理图像输入所述训练后特征点提取模型,提取所述待处理图像的特征点。
[0091]
本说明书中每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0092]
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1