一种基于双目视觉的三维目标运动跟踪方法
1.本发明属于移动机器人技术领域,具体为一种基于双目视觉的三维目标运动跟踪方法。
背景技术:
2.运动跟踪算法可以分为基于核函数追踪(kernel based tracking)和点追踪(point based tracking)。常见的基于核函数追踪的方法有均值漂移追踪(mean shift tracking)和支持向量机(support vector machine)。常见的点追踪的方法有:粒子滤波(particle filter)、多假设跟踪(multi hypothesis tracking)、卡尔曼滤波系列算法。其中卡尔曼滤波有两个假设条件:
①
系统是线性的;
②
影响测量的噪声属于白噪声。当这两个条件无法满足时卡尔曼滤波估计算法就不再适用了。实际情况下,由于目标运动估计受其他因素影响,运动具有非线性的特点。对进行非线性运动的目标进行运动估计的方法有:扩展卡尔曼滤波extended kalman filter(ekf),ekf首先将非线性模型通过泰勒展开实现线性化,然后再对非合作目标进行运动跟踪。ekf在进行非线性系统线性化时采用泰勒展开然后舍弃高阶项会引入截断误差,影响估计精度,无迹卡尔曼滤波(unscented kalman filter)则采用无迹变换来代替泰勒展开来实现非线性系统线性化,避免了截断误差,提高了运动估计的精度。
3.但是基于视觉图像的三维运动跟踪技术有两个技术难题,第一个难题是:对三维运动目标建立运动模型。第二个难题是实现运动跟踪算法必须要能克服由于光照、图像质量等问题导致的误检甚至漏检的现象,特别是对进行非线性运动运动目标实现运动跟踪。
技术实现要素:
4.本发明的目的在于:为了解决上述提出的问题,提供一种基于双目视觉的三维目标运动跟踪方法。
5.本发明采用的技术方案如下:一种基于双目视觉的三维目标运动跟踪方法,所述基于双目视觉的三维目标运动跟踪方法包括以下步骤:
6.步骤s1:双目相机检测目标;利用左右图像的视差进行三维重建,获取相机坐标系下目标的三维信息;
7.步骤s2:建立3d-ctrv模型;输入检测到的三维目标的位置信息,获取其在相机坐标系下的三维位置,计算相对于相机的方位角和俯仰角,得到三维目标的运动状态;
8.步骤s3:无迹卡尔曼滤波运动预测;根据当前帧检测到的三维目标状态和前一帧检测到的三维目标状态,对该目标在下一帧的运动状态进行估计;
9.步骤s4:无迹卡尔曼滤波观测更新;在获取下一帧的观测值后,根据预测值和预测观测值更新下一帧的目标运动状态,得到经过无迹卡尔曼滤波处理过后的滤波轨迹,实现基于双目视觉的三维目标运动跟踪。
10.在一优选的实施方式中,所述步骤s2中,建立3d-ctrv模型包括以下步骤:在双目
相机运动过程中预测动态目标的运动,然后得到运动目标的预测轨迹,首先需要建立观测坐标系;动态目标运动跟踪是在相机坐标系下进行的,以左相机的光心为相机坐标系的原点,相机坐标系的x轴平行于水平面,垂直于移动机器人前进方向,相机坐标系的y轴平行于水平面,以移动机器人前进方向为正,相机坐标系的z轴的定义通过右手法则来定义,垂直于水平面向上为正,由于每一帧的检测到的动态目标a的三维坐标是在当前时刻相机坐标系下的,双目相机在运动过程中相机坐标系时刻在变化,动态目标a的三维坐标也会随之变化;本发明将第一帧相机坐标系作为观测坐标系,首先需要将每一帧检测到的目标a三维坐标转换到观测坐标系下:将第1帧、第2帧和第n帧检测到的三维目标a都转换到第一帧相机坐标系下,基于检测结果可以得到一条运动轨迹,即图中的曲线轨迹。
11.在一优选的实施方式中,所述步骤s2中,选择恒转速恒速模型来描述动态目标的运动状态;
12.三维恒转速恒速模型(3d-ctrv)有两点假设,假设一:运动目标具有固定的转弯速率;假设二:动态目标具有恒定的速度大小;;
13.假设动态目标a在第k帧的三维坐标是(x
k y
k zk)
t
,动态目标a在第k帧的方位角为θk,俯仰角为动态目标a在第k帧的运动状态方程可以表示为:
[0014][0015]
其中动态目标a的方位角和俯仰角可以分别通过公式(2)、公式(3)求得:
[0016][0017][0018]
另外,定义动态目标俯仰角速度为ω,方位角速度为φ,根据三维恒转速恒速模型的假设一:运动目标具有固定的转弯速率,ω和φ在第k-1帧到第k帧时间间隔内恒定不变,可以分别通过公式(4)、公式(5)来求得:
[0019][0020][0021]
根据恒转速恒速模型的假设二:动态目标具有恒定的速度大小;定义动态目标a从第k-1帧到第k帧时间间隔内的速度大小为v,v恒定不变;可以通过公式(6)来获得:
[0022][0023]
根据公式(2)到公式(6),我们可以得到动态目标a在第k帧的速度vk:
[0024][0025]
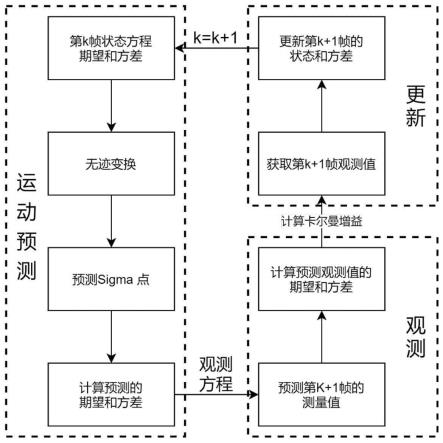
在一优选的实施方式中,所述步骤s3中,采用无迹卡尔曼滤波来对运动目标进行运动跟踪;无迹卡尔曼滤波算法可以分为三个阶段:运动预测阶段,观测阶段,更新阶段。
[0026]
在一优选的实施方式中,所述运动预测阶段在无迹卡尔曼滤波算法的动态预测阶段,首先要定义动态目标a的状态预测方程和观测方程:
[0027][0028]
其中,f(x)表示状态转移方程,状态方程由公式(1)定义,观测方程h(x)由公式(10)定义,根据恒转速恒速模型的假设,在连续两帧之间的状态转移方程可以由公式(9)来表示;
[0029]
f(xk)=xk+vk*δt
ꢀꢀ
(9)
[0030][0031]
公式(8)中,qk为第k帧的预测噪声,r
k+1
为第k+1帧的观测噪声,假设qk和r
k+1
是均值为0,方差为q和r的高斯白噪声,由于本文研究的状态方程包含了动态目标的三维位置、方位角和俯仰角,是一个5*1阶的矩阵,因此在实验中将方差矩阵q定义为5*5阶的对角阵;观测量为动态目标的三维位置,是一个3*1阶的矩阵,因此将其方差矩阵定义为3*3阶对角阵;
[0032]
接下来需要用无迹变换(unscented transform)生成sigma点来代替第k帧的状态方程xk,状态方程xk有5个变量,要生成11个sigma点,将第k帧生成的sigma点集定义为
[0033][0034]
这11个sigma点分别被定义为:
[0035][0036]
其中,和pk分别表示第k帧动态目标a的状态方程的均值和方差,均值可以定义为方差pk是一个5*5阶的对角阵,λ表示随机变量的均值和sigma采样点之间的距离的比例因子,是可以根据实际情况自定义的变量;
[0037]
下一步需要分别为公式(13)定义的11个sigma点赋予权重:
[0038][0039]
其中ω可以控制所取sigma点和均值之间距离,n表示状态方程的维度,本文的状态方程有五个变量,n的值取5;接下来对每一个sigma点进行预测,分别将11个sigma点带入公式(14)得到预测第k+1帧的sigma点x
k+1|k,i
:
[0040]
x
k+1|k,i
=x
k,i
+vk*δt
ꢀꢀ
(14)
[0041]
根据预测的sigma点x
k+1|k,i
和公式(15)赋予的权重可以分别求出运动状态预测的均值和方差p
k+1|k
:
[0042][0043][0044]
在一优选的实施方式中,所述观测阶段根据第k-1帧图像和第k帧图像上检测到的动态目标的三维坐标、方位角和俯仰角信息,可以得到状态预测方程的均值和方差p
k+1|k
,接下来需要将预测的sigma点x
k+1|k,i
带入到公式(4-11)观测方程h(x)中,预测第k+1帧时目标三维坐标的观测值z
k+1|k,i
:
[0045]zk+1|k,i
=h(x
k+1|k,i
)
ꢀꢀ
(17)
[0046]
结合公式(13)赋予的权重,可以求解出在第k帧中动态目标a在第k+1帧中预测的观测值的均值和方差s
k+1|k
:
[0047][0048][0049]
根据预测的sigma点x
k+1|k,i
、公式(15)求出的预测的sigma点在第k+1帧时的均值预测的观测的sigma点z
k+1|k,i
以及公式(18)得到的预测第k+1帧时目标三维坐标的观测值的均值可以求解出预测方程和观测方程的相关性函数t
k+1|k
;再利用预测观测值的方差s
k+1|k
和相关性函数t
k+1|k
便可以求解出卡尔曼增益kg
k+1|k
;
[0050][0051]
[0052]
在一优选的实施方式中,所述更新阶段需要根据第k+1帧对动态目标三维坐标的实际观测值z
k+1
、预测第k+1帧时目标状态的均值和方差p
k+1|k
、预测第k+1帧的观测值的均值和方差s
k+1|k
以及卡尔曼增益kg
k+1|k
来更新状态方程和方差p
k+1|k+1
:
[0053][0054][0055]
最后,根据更新的第k+1帧的状态和观测方程h(x)便可以利用公式(24)得到第k+1帧的实际状态估计值x
k+1
:
[0056][0057]
综上所述,由于采用了上述技术方案,本发明的有益效果是:
[0058]
本发明中,将二维图像上的运动模型扩展到三维空间,对进行非线性运动的目标进行运动状态描述,并在此基础上进行运动跟踪。利用无迹卡尔曼滤波算法对检测的轨迹进行滤波处理,可以降低因误检或者漏检导致的误差,并且相比于每一帧检测结果形成的检测轨迹,无迹卡尔曼滤波估计的轨迹会更加平滑,更加接近于真实的运动轨迹。
附图说明
[0059]
图1为本发明的相机坐标系方向定义图;
[0060]
图2为本发明中动态目标坐标转换示意图;
[0061]
图3为本发明中无迹卡尔曼滤波(ukf)算法流程图。
具体实施方式
[0062]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0063]
参照图1-3,
[0064]
一种基于双目视觉的三维目标运动跟踪方法,所述基于双目视觉的三维目标运动跟踪方法包括以下步骤:
[0065]
步骤s1:双目相机检测目标;利用左右图像的视差进行三维重建,获取相机坐标系下目标的三维信息;
[0066]
步骤s2:建立3d-ctrv模型;输入检测到的三维目标的位置信息,获取其在相机坐标系下的三维位置,计算相对于相机的方位角和俯仰角,得到三维目标的运动状态;
[0067]
步骤s3:无迹卡尔曼滤波运动预测;根据当前帧检测到的三维目标状态和前一帧检测到的三维目标状态,对该目标在下一帧的运动状态进行估计;
[0068]
步骤s4:无迹卡尔曼滤波观测更新;在获取下一帧的观测值后,根据预测值和预测观测值更新下一帧的目标运动状态,得到经过无迹卡尔曼滤波处理过后的滤波轨迹,实现基于双目视觉的三维目标运动跟踪。
[0069]
所述步骤s2中,建立3d-ctrv模型包括以下步骤:在双目相机运动过程中预测动态目标的运动,然后得到运动目标的预测轨迹,首先需要建立观测坐标系;动态目标运动跟踪是在相机坐标系下进行的,以左相机的光心为相机坐标系的原点,相机坐标系的x轴平行于水平面,垂直于移动机器人前进方向,相机坐标系的y轴平行于水平面,以移动机器人前进方向为正,相机坐标系的z轴的定义通过右手法则来定义,垂直于水平面向上为正,由于每一帧的检测到的动态目标a的三维坐标是在当前时刻相机坐标系下的,双目相机在运动过程中相机坐标系时刻在变化,动态目标a的三维坐标也会随之变化;本发明将第一帧相机坐标系作为观测坐标系,首先需要将每一帧检测到的目标a三维坐标转换到观测坐标系下:将第1帧、第2帧和第n帧检测到的三维目标a都转换到第一帧相机坐标系下,基于检测结果可以得到一条运动轨迹,即图中的迹,即图中的曲线轨迹。
[0070]
所述步骤s2中,选择恒转速恒速模型来描述动态目标的运动状态;
[0071]
三维恒转速恒速模型(3d-ctrv)有两点假设,假设一:运动目标具有固定的转弯速率;假设二:动态目标具有恒定的速度大小;;
[0072]
假设动态目标a在第k帧的三维坐标是(x
k y
k zk)
t
,动态目标a在第k帧的方位角为θk,俯仰角为动态目标a在第k帧的运动状态方程可以表示为:
[0073][0074]
其中动态目标a的方位角和俯仰角可以分别通过公式(2)、公式(3)求得:
[0075][0076][0077]
另外,定义动态目标俯仰角速度为ω,方位角速度为φ,根据三维恒转速恒速模型的假设一:运动目标具有固定的转弯速率,ω和φ在第k-1帧到第k帧时间间隔内恒定不变,可以分别通过公式(4)、公式(5)来求得:
[0078][0079][0080]
根据恒转速恒速模型的假设二:动态目标具有恒定的速度大小;定义动态目标a从第k-1帧到第k帧时间间隔内的速度大小为v,v恒定不变;可以通过公式(6)来获得:
[0081][0082]
根据公式(2)到公式(6),我们可以得到动态目标a在第k帧的速度vk:
[0083][0084]
所述步骤s3中,采用无迹卡尔曼滤波来对运动目标进行运动跟踪;无迹卡尔曼滤波算法可以分为三个阶段:运动预测阶段,观测阶段,更新阶段。
[0085]
所述运动预测阶段在无迹卡尔曼滤波算法的动态预测阶段,首先要定义动态目标a的状态预测方程和观测方程:
[0086][0087]
其中,f(x)表示状态转移方程,状态方程由公式(1)定义,观测方程h(x)由公式(10)定义,根据恒转速恒速模型的假设,在连续两帧之间的状态转移方程可以由公式(9)来表示;
[0088]
f(xk)=xk+vk*δt
ꢀꢀ
(9)
[0089][0090]
公式(8)中,qk为第k帧的预测噪声,e
k+1
为第k+1帧的观测噪声,假设qk和r
k+1
是均值为0,方差为q和r的高斯白噪声,由于本文研究的状态方程包含了动态目标的三维位置、方位角和俯仰角,是一个5*1阶的矩阵,因此在实验中将方差矩阵q定义为5*5阶的对角阵;观测量为动态目标的三维位置,是一个3*1阶的矩阵,因此将其方差矩阵定义为3*3阶对角阵;
[0091]
接下来需要用无迹变换(unscented transform)生成sigma点来代替第k帧的状态方程xk,状态方程xk有5个变量,要生成11个sigma点,将第k帧生成的sigma点集定义为
[0092][0093]
这11个sigma点分别被定义为:
[0094][0095]
其中,和pk分别表示第k帧动态目标a的状态方程的均值和方差,均值可以定义为方差pk是一个5*5阶的对角阵,λ表示随机变量的均值和sigma采样点之间的距离的比例因子,是可以根据实际情况自定义的变量;
[0096]
下一步需要分别为公式(13)定义的11个sigma点赋予权重:
[0097][0098]
其中ω可以控制所取sigma点和均值之间距离,n表示状态方程的维度,本文的状态方程有五个变量,n的值取5;接下来对每一个sigma点进行预测,分别将11个sigma点带入公式(14)得到预测第k+1帧的sigma点x
k+1|k,i
:
[0099]
x
k+1|k,i
=x
k,i
+vk*δt
ꢀꢀ
(14)
[0100]
根据预测的sigma点x
k+1|k,i
和公式(15)赋予的权重可以分别求出运动状态预测的均值和方差p
k+1|k
:
[0101][0102][0103]
所述观测阶段根据第k-1帧图像和第k帧图像上检测到的动态目标的三维坐标、方位角和俯仰角信息,可以得到状态预测方程的均值和方差p
k+1|k
,接下来需要将预测的sigma点x
k+1|k,i
带入到公式(4-11)观测方程h(x)中,预测第k+1帧时目标三维坐标的观测值z
k+1|k,i
:
[0104]zk+1|k,i
=h(x
k+1|k,i
)
ꢀꢀ
(17)
[0105]
结合公式(13)赋予的权重,可以求解出在第k帧中动态目标a在第k+1帧中预测的观测值的均值和方差s
k+1|k
:
[0106][0107][0108]
根据预测的sigma点x
k+1|k,i
、公式(15)求出的预测的sigma点在第k+1帧时的均值预测的观测的sigma点z
k+1|k,i
以及公式(18)得到的预测第k+1帧时目标三维坐标的观测值的均值可以求解出预测方程和观测方程的相关性函数t
k+1|k
;再利用预测观测值的方差s
k+1|k
和相关性函数t
k+1|k
便可以求解出卡尔曼增益kg
k+1|k
;
[0109][0110]
[0111]
所述更新阶段需要根据第k+1帧对动态目标三维坐标的实际观测值z
k+1
、预测第k+1帧时目标状态的均值和方差p
k+1|k
、预测第k+1帧的观测值的均值和方差s
k+1|k
以及卡尔曼增益kg
k+1|k
来更新状态方程和方差p
k+1|k+1
:
[0112][0113][0114]
最后,根据更新的第k+1帧的状态和观测方程h(x)便可以利用公式(24)得到第k+1帧的实际状态估计值x
k+1
:
[0115][0116]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0117]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1