兴趣引导的旅行路线景点联动推荐规划系统的制作方法
1.本技术涉及一种旅游路线景点规划系统,特别涉及一种兴趣引导的旅行路线景点联动推荐规划系统,属于旅游智能推荐规划技术领域。
背景技术:
2.旅游业作为一个传统行业,一直以来保持着较高的热度和关注度,曾经这个行业存在信息极端不对等的情况,使得热爱旅行者出行满意度大打折扣。往往只能通过旅行社或者宣传广告的主观信息来了解旅行的目的地和行程。网络信息还没有成为打破这一壁垒的武器,几年,巨大的商机和行业缺口终于被发觉,旅行行业开始了迈向互联网化的重要一步。
3.旅行需求跨越了几乎所有的年龄层次,旅行是现代大部分的社会人的需求,与之相关的服务必不可少。由于传统落后的旅行观念和条件早已让人厌倦,与众不同的旅行路线,人少景美的精致景点,全面配套的旅行服务成为了现代旅行中的更优选择。同时,由于互联网的迅速发展,人们可以轻易从网络上搜寻各种旅行信息。然而信息爆炸带来的不是单纯的好处,如何去辨别其中的真伪信息,如何去寻找自己需要的有效信息成为了旅行者的巨大难题。于是,传统的旅行社模式升级换代,成为了互联网旅行信息与服务提供者继续为旅行者服务。旅行推荐系统也替代了以前的店面中坐着的工作人员来向旅行者们提供相关的信息服务。
4.旅行推荐系统分为一般性的推荐和个性化推荐,对于两个兴趣爱好不同的人来说,他们使用同一个系统得到的推荐结果可能截然不同的,亟需让个性化旅行推荐系统推荐的结果更加符合用户的需求。
5.旅游推荐系统与其它的图书、音乐等推荐系统不同,它的设计和应用更加复杂。旅行经历不仅仅包含了人的主观因素,还包括具体的情景;同时推荐对象比起书籍、电视、唱片、电影、音乐这些复杂度和价值不高的项目,要更为复杂。所需要考虑的因素非常多,而可以利用的信息却比较少。
6.综上,现有技术的旅行推荐规划系统存在若干问题和缺陷,本技术需要解决的问题和关键技术难点包括:
7.(1)旅游推荐系统与其它图书、音乐等推荐系统不同,它的设计和应用更复杂,旅行经历不仅包含了人的主观因素,还包括具体情景,同时推荐对象比起电视、唱片、电影这些复杂度和价值不高的项目,要更为复杂,要考虑的因素非常多,而可以利用的信息却较少。现有技术旅游推荐面临的关键问题及挑战包括:一是数据稀缺性,并不只是指没有数据或数据很少,数据来源的是海量的,互联网上充斥着大量复杂重复、无端的旅行景点数据,但实际只需要其中一部分有序有效的格式化数据,如何获取有效的数据,决定哪些数据是旅游推荐的一大难题。二是冷启动,对一个新用户,系统得知的信息很少,没有历史记录和搜索记录,旅行推荐涉及的因素很多,而获知很少,冷启动是不可避免的问题,因此这也是本技术必须要解决的问题,用户信息过少意味着用户画像模糊,难以匹配到合理的推荐结
果,这样推荐系统的意义就不存在了。三是算法设计的困难性,旅行推荐系统很大,其中的每一个环节都有难点,现有技术无法有效获取更多的用户个人偏好信息,无法设计贴近用户实际需求的个性化推荐算法。
8.(2)对于现有的旅行推荐系统,从相关的可靠用户信息中发现潜在兴趣点是一个重大挑战。对于提供给所有人的普遍适应的推荐,旅行者们越来越喜欢寻找那些满足他们特殊口味的信息。对于每一个用户,缺少剖析他的成分来决定更适合哪些推荐结果,缺少研究性别、年龄、职业等因素是否会对他的旅行观念和偏好造成影响,又会造成怎样的影响,无法建立一个普遍适用于各种用户群体的用户模型,现有技术缺少足够多组织良好的信息,无法根据用户的口味和兴趣进一步筛选设计个性化旅行推荐系统,缺少预先定义的用户偏好的资料,无法找出对于这个用户最具旅行欲望的目标,缺少从用户历史以及偏好信息中去挖掘他们的兴趣,导致现有技术用户模型构建不准确,无法实现个性化旅游推荐。
9.(3)旅行推荐系统区别与其它传统推荐系统是旅行数据的特殊元素包含了旅行景点、价格、季节、时间等一系列因素,现有技术无法将这些元素量化、模型化,转化为可以直接考量的数据,缺少建立一个庞大的景点标签和知识库,无法给每一个景点打上合适的标签,缺少评估各个因素有趣的等级,缺少有效的基于多重用户特殊属性来计划这些因素,造成景点标签及知识库设计不合理,制约旅游推荐效果。同时,现有技术也缺少可靠的个性化旅行推荐系统。
10.(4)旅行推荐由于其本身的复杂性,不能单纯采用一两种简单的推荐技术,往往需要多重推荐技术协同使用才能更好的达到推荐效果,现有技术缺少高效的协同多重推荐方法。首先是用户初次使用,即冷启动时数据无法处理得到推荐结果,存在用户每次的行为和推荐结果是如何影响下一次的推荐结果的,哪些数据应该作为的信息来源,各个部分的权重如何规定等一系列的问题需要解决.缺少多重协同推荐以获得最好的推荐效果。
技术实现要素:
11.本技术设计了一套高效的个性化旅游推荐规划方法,解决了数据稀缺性和冷启动问题,设计的第一个智能体是基于性格模型思想的算法来进行相似用户的选择,根据相似用户的偏好来对当前用户进行推荐,加入了基于内容方法来筛选相似用户,确保近邻集中的相似用户与当前用户对景点有相同偏好。第二个智能体从景点属性出发,采用粗略集的方法分析用户对于各种景点属性的偏好,得到各个景点的属性对于用户的效用程度,然后采用性格模型算法寻找近邻,结合效用权重和近邻偏好推荐景点。第三个智能体是为了解决系统的冷启动问题,采用联动规则的方法来为用户分类,通过用户本身的属性而非偏好寻找与当前用户相似的用户,同时寻找景点之间的内在关系,同时结合性格模型方法得到的景点相似度作为权重;结合相似度权重和联动规则挑选推荐的景点。对三个景点推荐子算法的效用进行了检验校核,并且结合各个智能体要解决的问题设置了最终的权重,以景点推荐和旅行行程规划的算法为基础,实现了一个个性化旅行推荐系统,能够根据用户的个人需求定制旅行行程。
12.为实现以上技术效果,本技术所采用的技术方案如下:
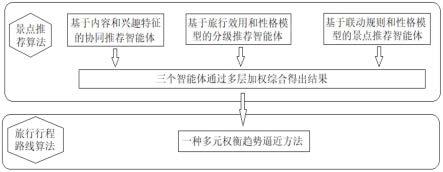
13.兴趣引导的旅行路线景点联动推荐规划系统,包括景点推荐算法和旅行行程路线算法,景点推荐算法采用一种全新的多智能体加权协同推荐模型,包含三层级智能体:
14.e1-基于内容和兴趣特征的分级协同推荐智能体:包括发掘用户近邻和通过特征矩阵筛选用户近邻加入,基于内容的方法来筛选相似用户,确保近邻集中的相似用户与当前用户对景点有相同偏好,根据相似用户的偏好来对当前用户进行推荐;
15.e2-基于旅行效用和性格模型的分级推荐智能体:从景点属性出发,通过基于粗略集的效用推荐算法,分析用户对于各种景点属性的偏好,得到各个景点的属性对于用户的效用程度,作为推荐的权重;基于变精度粗略集的用户偏好解析寻找近邻,结合效用权重和近邻偏好推荐景点,实现基于性格模型的旅行效用分级推荐;
16.e3-基于联动规则和性格模型的景点推荐智能体,基于矩阵的联动先验方法,通过用户本身的属性而非偏好寻找与当前用户相似的用户,同时寻找景点之间的内在关系,同时基于性格模型景点相似度权重算法得到的景点相似度作为权重;结合相似度权重和联动规则挑选推荐的景点;
17.三个智能体通过多层加权综合得出结果,行程路线算法基于最高推荐度景点为起始,采用一种多元权衡趋势逼近方法,每次选择最近的景点为下一个备选景点,根据推荐的景点以及旅行天数、每日游览时间、预算多个约束条件制订行程;
18.个性化旅行路线景点联动推荐规划系统:基于flask框架,以python实现后台,bootstrap框架实现前端,数据库基于mysql数据库,数据来源包括从各个旅行网站爬取的景点以及标签信息、用户提供的个人信息、用户行为信息,以结合内容、效用、联动规则、性格模型、多约束的协同推荐模型为用户推荐个性化的旅行行程,最终构建三大模块,包括用户注册登录与个人信息管理、行程定制与管理、景点信息查看,后台由注册登陆模块、用户信息管理模块、景点信息管理模块、行程信息管理模块、行程定制模块、搜索模块、数据采集模块、数据处理模块八大模块组成。
19.优选地,发掘用户近邻:以用户对景点的评分数量和分数来衡量景点热度,景点热度越高表明其越受旅行者亲睐,通过景点评分数据组成矩阵,定义景点p的热度ph计算式如下:
[0020][0021]
其中,m代表所有用户数量,r
s,p
代表用户s对于景点p的评分,热度由评分的人数和总分数共同决定,采用皮尔逊相关系数计算用户相似度;
[0022]
设用户集合为u,景点集合为p,用户的评分矩阵为r,表示全部用户对景点p评分的平均值(用户可以重复评分),则用户s1和用户s2的相似度表示如下:
[0023][0024]
由于热门景点很容易发生共同关注的情况,为消除景点热度的影响,对式2改良,加入景点热度参数ph,修正后的公式如下:
[0025]
[0026]
通过修正后的公式计算与当前用户相似的近邻,依据top-n规则选出前n个近邻。
[0027]
优选地,通过特征矩阵筛选用户近邻:通过用户真正感兴趣的内容来进行筛选,提取景点的特征组成特征引导标签,然后利用特征引导标签矩阵和用户的评分矩阵来构建用户偏好模型;
[0028]
1)提取景点特征
[0029]
通过文本处理,从各种旅行网站的用户对景点的评论中,以及搜索引擎搜索景点名称的结果文本中抽取关键词,每个景点归纳出若干符合的关键词为标签,并存放在景点信息表中,全体标签的集合称为景点标签库,存放在数据库标签表中,在建立标签矩阵时,根据不同的维度区分;
[0030]
2)构建用户偏好模型
[0031]
根据用户评分超过3的景点,记录每种类型出现的频次,在频度不小于一定值的情况下取前四个类型标签作为当前用户最喜爱的景点类型,同理获取其它维度的用户最喜爱标签,所有维度结合起来就是用户的偏好模型;
[0032]
3)计算相似度
[0033]
采用欧几里德距离计算空间中点之间的绝对距离,如式4:
[0034][0035]
通过用户偏好模型来计算用户的相似度,具体如下:
[0036][0037]
其中x代表标签,w代表权重,l代表两个用户喜欢的景点类型标签数量之和,对于其中的某种景点类型y,u
iy
代表它在用户si的兴趣模型中存在情况,存在为l,不存在为0,将所有维度的标签都代入公式,获取到两个用户的相似度;
[0038]
经过两层筛选后,得到该用户的近邻就是对景点偏好类似的真近邻用户。
[0039]
优选地,基于内容和兴趣特征的推荐流程:
[0040]
输入:用户对景点的评分矩阵;
[0041]
输出:包含景点和推荐评分的字典r;
[0042]
流程:
[0043]
1)根据用户对景点的评分形成的矩阵和式1计算每个景点的热度;
[0044]
2:计算当前用户的相似近邻用户,并基于top-n方法得出前n个用户组成近邻集;
[0045]
3)建立近邻集中所有用户和当前用户的兴趣模型,并计算出当前用户与近邻集中用户的偏好相似度,根据相似度从大到小对近邻集的用户重构新排序,并选择前m个用户作为最终的用户近邻;
[0046]
4)由m个用户来推测当前用户对未知景点的评分,设当前用户为s,被评分景点为p,则该用户对该景点的评分r的计算式如下:
[0047][0048]
5)所有用户对所有景点评分和top-n方法得到一个包含用户偏好的景点和评分r的字典集。
[0049]
优选地,基于粗略集的效用推荐算法:采用粗略集挖掘用户偏好,然后评价效用,最终得出用户的偏好排序,粗略集挖掘不需要了解先验知识;
[0050]
定义1:设四元组s={u,r,v,f}为一个旅行表达系统,其中u代表对象的集合,r代表属性的集合,由条件属性和决策属性组成,即r=c∪d,其中c代表条件属性的集合,d代表决策属性的集合,v代表所有属性可能取值的总集合,f是一个函数,代表的对象的属性在v中对应值。
[0051]
定义2:不可分辨关系,即分类时被归于同一类的类似个体间的关系,不可分辨关系简化粗略集将进行的运算,通过聚类将其转化为一个基本集,对于r的非空子集p,p在u上的不可分辨关系定义如下:
[0052]
ind(p)={(x,y)∈u
×
u:f(x,p)=f(y,p),p∈p}式7
[0053]
定义3:ind(p)将u划分为n个不相交的等价类,u|ind(p);
[0054]
定义4:变精度粗略集模型,引入噪音因素β,它的值代表数据中的噪音程度,设由c导出的等价类为设p为u的子集,则有:
[0055]
β正域:
[0056][0057]
β负域:
[0058][0059]
β边界:
[0060][0061]
其中:
[0062][0063]
定义5:基于定义4,定义c与d的相关性:
[0064][0065]
其中,posc(d)=∪iposc(di),negc(d)=∪inegc(di)
[0066]
优选地,基于变精度粗略集的用户偏好解析:首先建立决策信息表,其中s为用户偏好表,u为用户集合,c是条件属性集合,包括景点的所有标签类型,d是决策属性,包括用
户对景点的偏好,判定方式包括评分或收藏行为,通过该决策信息表计算用户对景点的偏好受各种属性的影响权重;
[0067]
基于变精度粗略集的景点属性权重算法:
[0068]
输入:决策表s=(u,c∪d,v,f),其中c={p1,p2,p3,
…
,pn],d={d},系数β;
[0069]
输出:属性权重向量;
[0070]
流程:
[0071]
1)根据式11计算kβ(c,d);
[0072]
2)计算
[0073]
3)根据1)、2)的结果计算impβ(pi,c,d);
[0074]
4)计算pi的权重:
[0075][0076]
5)将所有的属性权重计算出来,组成一个权重向量
[0077][0078]
算法结束。
[0079]
优选地,基于性格模型的旅行效用分级推荐流程:
[0080]
输入:属性权重向量w,近邻数目m,推荐经典数目n;
[0081]
输出:包含推荐景点和推荐评分的字典r;
[0082]
开始:
[0083]
1)计算用户距离,并得到最近的m个近邻;
[0084]
2)根据m个近邻的评分和收藏记录计算未评分的景点,并选出前n个组成后备集e;
[0085]
3)对于后备集e,建立效用矩阵a,其中,一行代表一个景点的所有属性,一列代表所有景点的同一属性:
[0086][0087]
4)通过极差变换法对矩阵a进行去量纲化,正指标使用式17处理,负指标使用式18处理:
[0088][0089][0090]
5)采用式19对矩阵a规范化处理:
[0091][0092]
6)采用属性权重向量通过式20对矩阵进行处理,得到加权矩阵a*:
[0093]vij
=wjv
ij
,(i=1,2,
…
,n),(j=1,2,
…
,m)式20
[0094]
7)根据值v
ij
得出正负理想解,其中j
+
j-于分别代表正负指标:
[0095][0096][0097]
8)si为e中元素,根据式23计算e中所有元素的理想接近度ki,值在0-1之间,数值越大越贴合理想推荐结果:
[0098][0099]
9)根据ki将e重新排序,得到字典r。
[0100]
优选地,基于矩阵的联动先验方法:只扫描数据库一次的情况下生成频繁项集,步骤包括:
[0101]
输入:行程-景点数据库、最小支持度s、最小置信度c;
[0102]
输出:联动规则库r;
[0103]
步骤1:首先建立事务矩阵,基于旅行特点,建立一个旅行行程-景点矩阵t,其中包含m个行程,n个景点:
[0104][0105]
其中,一行代表一个行程,一列代表一个景点,如果在第i个行程中包含景点j,则t
ij
=1,如果不包含则t
ij
=0,则矩阵每一列之和即为景点pj的支持度:
[0106][0107]
删除矩阵t中支持度小于s的景点列,得到频繁一项集t1;
[0108]
步骤2:由t1产生候选二项集c2,计算矩阵t的每一行之和,删除小于2的行,这些行不可能产生频繁二项集,计算c2中每个元素pipj的支持度:
[0109][0110]
删除支持度小于s的候选项得到频繁二项集t2:
[0111]
t2={c∈ck|sup(pipj)≥s}式27
[0112]
步骤3:设q≥3,由频繁q-1项集t
q-1
生成候选q项集cq,删除矩阵t中每行之和的值小于q的行以减少计算量,cq中元素的支持度为:
[0113]
[0114]
删除支持度小于s的候选项,得到频繁q项集tq:
[0115]
tq={c∈ck|sup(pipj...)≥s}式29
[0116]
步骤4:当不存在更多项的频繁集时,根据频繁项集生成联动规则库r。
[0117]
优选地,基于性格模型景点相似度权重算法:如果u代表给景点p1和景点p2评分的用户总集u,代表景点p1的平均得分,代表用户s对p1的评分,得到式29:
[0118][0119]
由式30计算任意景点间的皮尔逊相关系数,将其作为景点相似度权重。
[0120]
优选地,旅行行程路线推荐:旅行者每日的游玩时间为8个小时,包括通勤时间;不计算旅行者从所在地到目标城市的时间和路费;景点之间的路费以1rmb/2km计算,小于2km的不计算;通勤时间按照40km/h的速度计算;住宿餐食等费用按照平均每人每天300rmb计算;
[0121]
假设列表p是存放完整景点信息对象的栈,pq是一个零时存放景点信息对象的队列,初始为空,并设出行天数为d,人均预算为w,接下来的步骤包括:
[0122]
第1步:设置一个计数器count=0,设计时参数t=0,单位是小时,计费参数w=0,单位为元,设剩余预算c=w-300*d,单位为元,开始执行第2步;
[0123]
第2步:如果count<d,从pq和p中取出前x项放入集合x,使得x为满足的最大值,即取出游览时间总和不超过8小时的前x个景点,执行第3步;如果count≥d,中止;
[0124]
第3步:根据高德地图提供的api接口得到x个景点的地理位置,并抽象为一张具有x个顶点的完全无向图,选择推荐度最高的景点作为起点,采用多元权衡趋势逼近方法得到旅行路线;令t=通勤时长与景点耗时的总和,w=路程花费与门票花费的总和,若t<8且w>c,执行第4步;若t>8,执行第5步;若t<8且w<c,执行第6步;
[0125]
第4步:判定d-count的值,若d-count=1,判定8-t的值,若8-t>2,则将门票最贵的景点从集合x中移除,执行第3步;若d-count>1,则将门票最贵的景点从集合x中移除,执行第3步;
[0126]
第5步:将最末一个景点放入pq,执行第3步;
[0127]
第6步:搜索p中满足p.time<t-8的第一项,如果存在该项,则将其加入到x末尾,执行第2步;若rpd中没有符合p.time<t-8的项,则count增加1,c=c-w,参数t、w清零,将当前路线作为第count天的行程记录下来,执行第2步。
[0128]
最后中止时系统获得最终的行程推荐。
[0129]
与现有技术相比,本技术的创新点和优势在于:
[0130]
(1)本技术采用一种全新的多智能体加权协同推荐模型,包含三层级智能体:一是基于内容和兴趣特征的分级协同推荐智能体,基于内容的方法来筛选相似用户,确保近邻集中的相似用户与当前用户对景点有相同偏好,根据相似用户的偏好来对当前用户进行推荐;有效筛选和抽取有关于旅行的有效信息,将用户的兴趣爱好性格特征等等结合到旅行中;二是基于旅行效用和性格模型的分级推荐智能体,从景点属性出发,将数据关联,分析
用户对于各种景点属性的偏好,得到各个景点的属性对于用户的效用程度,作为推荐的权重;结合效用权重和近邻偏好推荐景点,实现基于性格模型的旅行效用分级推荐;三是基于联动规则和性格模型的景点推荐智能体,通过用户本身的属性而非偏好寻找与当前用户相似的用户,寻找景点之间的内在关系,结合相似度权重和联动规则挑选推荐的景点;结合旅行领域的数据特点加以改进,三个智能体综合采用多个协同模型再次加权,以达到减小冷启动效应,提高算法的稳定性、有效性的作用,使得旅行推荐系统更加势能高效并满足个性化需求。
[0131]
(2)本技术设计了一套高效的个性化旅游推荐规划方法,解决了数据稀缺性和冷启动问题,设计的第一个智能体是基于性格模型思想的算法来进行相似用户的选择,根据相似用户的偏好来对当前用户进行推荐,由于单纯的性格模型算法会将某些不活跃用户误认为是当前用户的相似用户,为了避免这种情况,加入了基于内容方法来筛选相似用户,确保近邻集中的相似用户与当前用户对景点有相同偏好。第二个智能体从景点属性出发,采用粗略集的方法分析用户对于各种景点属性的偏好,以得到各个景点的属性对于用户的效用程度,作为推荐的权重;然后采用性格模型算法寻找近邻,结合效用权重和近邻偏好推荐景点。第三个智能体是为了解决系统的冷启动问题,对一个新用户来说,很难获知他的偏好从而寻找相似用户,因此采用联动规则的方法来为用户分类,通过用户本身的属性而非偏好寻找与当前用户相似的用户,同时寻找景点之间的内在关系,同时结合性格模型方法得到的景点相似度作为权重;结合相似度权重和联动规则挑选推荐的景点。为了确定各个子协同算法的权重设置,本技术对三个景点推荐子算法的效用进行了检验校核,并且结合各个智能体要解决的问题设置了最终的权重,以景点推荐和旅行行程规划的算法为基础,本技术实现了一个个性化旅行推荐系统,能够根据用户的个人需求定制旅行行程,并对推荐的景点进行评价。
[0132]
(3)本技术创造性的建立了一种个性化旅游推荐用户模型,从相关的可靠用户信息中发现潜在兴趣点,满足旅行者们特殊口味信息,对于每一个用户,剖析他的成分决定他更适合哪些推荐结果,考虑性别、年龄、职业等因素对他的旅行观念和偏好造成的影响,建立一个普遍适用于各种用户群体的模型,在之后的寻找相似用户的算法中起到非常重要的作用,获取足够多组织良好的信息,根据用户的口味和兴趣进一步筛选,从用户历史以及偏好信息中去挖掘他们的兴趣。
[0133]
(4)创造性设计了景点标签及知识库,将旅行推荐系统区别与其它传统的推荐系统的地方,特别是旅行数据包含的旅行景点、价格、季节、时间等一系列特殊元素,将这些元素量化、模型化,转化为可以直接考量的数据,预测标签库越丰富,最终的推荐结果也越精准,本技术建立了一个庞大的景点标签和知识库,给每一个景点打上合适的标签,一是评估各个因素的有趣的等级,二是有效的基于多重用户特殊属性来计划这些因素,同时考虑到多约束和计算效率,在景点标签和知识产生作用的方式上采用了以获取的评分和标签经过处理后得到的匹配度来处理,获得了高质量的景点标签及知识库,为高效的景点推荐规划打下的良好基础。
[0134]
(5)本技术以景点推荐和旅行行程规划算法为基础,实现了一个个性化旅行推荐系统,数据来源包括从各个旅行网站爬取的景点以及标签信息、用户提供的个人信息、用户行为信息,以结合内容、效用、联动规则、性格模型、多约束的协同推荐模型为用户推荐个性
化的旅行行程,最终构建三大模块,包括用户注册登录与个人信息管理、行程定制与管理、景点信息查看,后台由注册登陆模块、用户信息管理模块、景点信息管理模块、行程信息管理模块、行程定制模块、搜索模块、数据采集模块、数据处理模块八大模块组成。系统实现了用户注册、登陆、个人信息管理、查看与收藏景点信息等基本功能,同时能够根据用户的个人需求定制旅行行程,有用户兴趣引导,实现高效的旅行路线景点联动推荐规划,线路规划更加科学合理,并对推荐的景点进行评价,通过用户评价不断优化改进。
附图说明
[0135]
图1是多智能体加权协同推荐模型示意图。
[0136]
图2是检验校核三种子算法在采取不同大小的训练集时预测效果图。
[0137]
图3是旅行路线景点联动推荐规划系统用户模块结构图。
[0138]
图4是旅行推荐系统功能模块功能模块结构图。
[0139]
图5是用户定制信息采集表单交互示意图。
[0140]
图6是个人中心收藏景点信息页面示意图。
[0141]
图7是个人中心用户旅游定制信息界面示意图。
具体实施方式
[0142]
下面结合附图,对本技术提供的兴趣引导的旅行路线景点联动推荐规划系统的技术方案进行进一步的描述,使本领域的技术人员能够更好的理解本技术并能够予以实施。
[0143]
旅行推荐系统面临很多问题,如何有效的去筛选和抽取有关于旅行的有效信息,如何通过用户的兴趣爱好甚至性格特征等等结合到旅行中,如何建立有效的模型去将看似毫无关系的数据关联起来,如何设计有效的算法将用户当时最想要的东西呈现给它。结合现有技术算法的数据稀缺、冷启动等不足之处和难点,本技术构建一个多智能体协同推荐智能体,包括景点推荐算法和路线规划算法,重点是景点推荐算法,由三个子算法组成,其中包括基于内容和兴趣特征的分级协同推荐智能体、基于效用和性格模型的分级协同推荐智能体、基于联动规则和性格模型的分级协同推荐智能体。其中,基于内容和兴趣特征的分级协同推荐智能体,包括发掘用户近邻和通过特征矩阵筛选用户近邻;基于旅行效用和性格模型的分级推荐智能体,通过基于粗略集的效用推荐算法、基于变精度粗略集的用户偏好解析,实现基于性格模型的旅行效用分级推荐;基于联动规则和性格模型的景点推荐智能体,通过基于矩阵的联动先验方法、基于性格模型景点相似度权重算法,实现基于权重和联动规则的景点推荐,三个算法的结果通过线性加权算法综合到一起作为路线规划算法的输入,各个算法的权重通过实验得到的算法效果决定。
[0144]
一、多智能体加权协同推荐模型
[0145]
包括景点推荐算法和旅行行程路线算法,其中景点推荐算法采用一种全新的多智能体加权协同推荐方法,包含三层级智能体:基于内容和兴趣特征的协同推荐智能体、基于旅行效用和性格模型的分级推荐智能体、基于联动规则和性格模型的景点推荐智能体,各个智能体通过多层加权综合得出结果,行程路线算法采用一种多元权衡趋势逼近方法,根据推荐的景点以及旅行天数、每日游览时间、预算多个约束条件制订行程。整个算法的模型结构如图1所示。
[0146]
(一)基于内容和兴趣特征的协同推荐智能体
[0147]
1.发掘用户近邻
[0148]
以用户对景点的评分数量和分数来衡量景点热度,景点热度越高表明其越受旅行者亲睐,通过景点评分数据组成矩阵,定义景点p的热度ph计算式如下:
[0149][0150]
其中,m代表所有用户数量,r
s,p
代表用户s对于景点p的评分,热度由评分的人数和总分数共同决定,采用皮尔逊相关系数计算用户相似度;
[0151]
设用户集合为u,景点集合为p,用户的评分矩阵为r,表示全部用户对景点p评分的平均值(用户可以重复评分),则用户s1和用户s2的相似度表示如下:
[0152][0153]
由于热门景点很容易发生共同关注的情况,为消除景点热度的影响,对式2改良,加入景点热度参数ph,修正后的公式如下:
[0154][0155]
通过修正后的公式计算与当前用户相似的近邻,依据top-n规则选出前n个近邻。
[0156]
2.通过特征矩阵筛选用户近邻
[0157]
之所以要再次筛选用户,是因为通过性格模型算法选出的n个近邻中,有一部分用户与当前用户实际偏好差别很大,他们被选出来的原因是评分矩阵稀疏,这种匹配存在纰漏。
[0158]
为了筛选掉这一部分近邻,通过用户真正感兴趣的内容来进行筛选,提取景点的特征组成特征引导标签,然后利用特征引导标签矩阵和用户的评分矩阵来构建用户偏好模型。
[0159]
(1)提取景点特征
[0160]
通过文本处理,从各种旅行网站的用户对景点的评论中,以及搜索引擎搜索景点名称的结果文本中抽取关键词,每个景点归纳出若干符合的关键词为标签,并存放在景点信息表中,全体标签的集合称为景点标签库,存放在数据库标签表中,以北京的景点为例,故宫的前三个标签依次是名胜古迹、宫殿、历史文化。在建立标签矩阵时,根据不同的维度区分。例如每个景点的标签中包含一个景点类型标签,景点适宜人群标签、景点适宜季节标签等等。
[0161]
(2)构建用户偏好模型
[0162]
景点类型包括建筑、湖泊、公园、山岳、森林、海滨,根据用户评分超过3的景点,记录每种类型出现的频次。在频度不小于一定值的情况下取前四个类型标签作为当前用户最喜爱的景点类型,同理获取其它维度的用户最喜爱标签,所有维度结合起来就是用户的偏好模型。
[0163]
(3)计算相似度
[0164]
采用欧几里德距离计算空间中点之间的绝对距离,如式4:
[0165][0166]
通过用户偏好模型来计算用户的相似度,具体如下:
[0167][0168]
其中x代表标签,w代表权重,l代表两个用户喜欢的景点类型标签数量之和,对于其中的某种景点类型y,u
iy
代表它在用户si的兴趣模型中存在情况,存在为l,不存在为0,将所有维度的标签都代入公式,获取到两个用户的相似度;
[0169]
经过两层筛选后,得到该用户的近邻就是对景点偏好类似的真近邻用户。
[0170]
3.基于内容和兴趣特征的推荐流程
[0171]
输入:用户对景点的评分矩阵;
[0172]
输出:包含景点和推荐评分的字典r;
[0173]
流程:
[0174]
1)根据用户对景点的评分形成的矩阵和式1计算每个景点的热度;
[0175]
2)利用式3计算当前用户的相似近邻用户,并基于top-n方法得出前n个用户组成近邻集;
[0176]
3)建立近邻集中所有用户和当前用户的兴趣模型,并根据式5计算出当前用户与近邻集中用户的偏好相似度,根据相似度从大到小对近邻集的用户重构新排序,并选择前m个用户作为最终的用户近邻;
[0177]
4)由m个用户来推测当前用户对未知景点的评分,设当前用户为s,被评分景点为p,则该用户对该景点的评分r的计算式如下:
[0178][0179]
5)所有用户对所有景点评分和top-n方法得到一个包含用户偏好的景点和评分r的字典集。
[0180]
(二)基于旅行效用和性格模型的分级推荐智能体
[0181]
1.基于粗略集的效用推荐算法
[0182]
采用粗略集挖掘用户偏好,然后评价效用,最终得出用户的偏好排序,粗略集挖掘不需要了解先验知识,适合在数据库中直接使用。
[0183]
定义1:设四元组s={u,r,v,f}为一个旅行表达系统,其中u代表对象的集合,r代表属性的集合,由条件属性和决策属性组成,即r=c∪d,其中c代表条件属性的集合,d代表决策属性的集合,v代表所有属性可能取值的总集合,f是一个函数,代表的对象的属性在v中对应值。
[0184]
定义2:不可分辨关系,即分类时被归于同一类的类似个体间的关系,不可分辨关
系简化粗略集将进行的运算,通过聚类将其转化为一个基本集,对于r的非空子集p,p在u上的不可分辨关系定义如下:
[0185]
ind(p)={(x,y)∈u
×
u:f(x,p)=f(y,p),p∈p}式7
[0186]
定义3:ind(p)将u划分为n个不相交的等价类,u|ind(p)。
[0187]
定义4:变精度粗略集模型,引入噪音因素β,它的值代表数据中的噪音程度,设由c导出的等价类为设p为u的子集,则有:
[0188]
β正域:
[0189][0190]
β负域:
[0191][0192]
β边界:
[0193][0194]
其中:
[0195][0196]
定义5:基于定义4,定义c与d的相关性:
[0197][0198]
其中,posc(d)=uiposc(di),negc(d)=uinegc(di)
[0199]
定义6:属性p的重要程度:
[0200][0201]
粗略集共包括定义1至定义6。
[0202]
2.基于变精度粗略集的用户偏好解析
[0203]
首先建立决策信息表,其中s为用户偏好表,u为用户集合,c是条件属性集合,包括景点的所有标签类型,如景点类型,游客多少,门票是否免费,适宜的团体类型,适合年龄段等。d是决策属性,包括用户对景点的偏好,判定方式包括评分或收藏行为,通过该决策信息表计算用户对景点的偏好受各种属性的影响权重。
[0204]
基于变精度粗略集的景点属性权重算法:
[0205]
输入:决策表s=(u,c∪d,v,f),其中c={p1,p2,p3,
…
,pn],d={d},系数β;
[0206]
输出:属性权重向量;
[0207]
流程:
[0208]
1)根据式11计算k
β
(c,d);
[0209]
2)计算
[0210]
3)根据式13和1)、2)的结果计算imp
β
(pi,c,d);
[0211]
4)计算pi的权重:
[0212][0213]
5)将所有的属性权重计算出来,组成一个权重向量
[0214][0215]
算法结束。
[0216]
3.基于性格模型的旅行效用分级推荐流程
[0217]
输入:属性权重向量w,近邻数目m,推荐经典数目n;
[0218]
输出:包含推荐景点和推荐评分的字典r
[0219]
开始:
[0220]
1)计算用户距离,并得到最近的m个近邻;
[0221]
2)根据m个近邻的评分和收藏记录计算未评分的景点,并选出前n个组成后备集e;
[0222]
3)对于后备集e,建立效用矩阵a,其中,一行代表一个景点的所有属性,一列代表所有景点的同一属性:
[0223][0224]
4)通过极差变换法对矩阵a进行去量纲化,正指标使用式17处理,负指标使用式18处理:
[0225][0226][0227]
5)采用式19对矩阵a规范化处理:
[0228][0229]
6)采用属性权重向量通过式20对矩阵进行处理,得到加权矩阵a*:
[0230]vij
=wjv
ij
,(i=1,2,
…
,n),(j=1,2,
…
,m)式20
[0231]
7)根据值v
ij
得出正负理想解,其中j
+
j-于分别代表正负指标:
[0232]
[0233][0234]
8)si为e中元素,根据式23计算e中所有元素的理想接近度ki,值在0-1之间,数值越大越贴合理想推荐结果:
[0235][0236]
9)根据ki将e重新排序,得到字典r。
[0237]
(三)基于联动规则和性格模型的景点推荐智能体
[0238]
(一)基于矩阵的联动先验方法
[0239]
只扫描数据库一次的情况下生成频繁项集,步骤包括:
[0240]
输入:行程-景点数据库、最小支持度s、最小置信度c;
[0241]
输出:联动规则库r;
[0242]
步骤1:首先建立事务矩阵,基于旅行特点,建立一个旅行行程-景点矩阵t,其中包含m个行程,n个景点:
[0243][0244]
其中,一行代表一个行程,一列代表一个景点,如果在第i个行程中包含景点j,则t
ij
=1,如果不包含则t
ij
=0,则矩阵每一列之和即为景点pj的支持度:
[0245][0246]
删除矩阵t中支持度小于s的景点列,得到频繁一项集t1;
[0247]
步骤2:由t1产生候选二项集c2,计算矩阵t的每一行之和,删除小于2的行,这些行不可能产生频繁二项集,计算c2中每个元素pipj的支持度:
[0248][0249]
删除支持度小于s的候选项得到频繁二项集t2:
[0250]
t2={c∈ck|sup(pipj)≥s}式27
[0251]
步骤3:设q≥3,由频繁q-1项集t
q-1
生成候选q项集cq,删除矩阵t中每行之和的值小于q的行以减少计算量,cq中元素的支持度为:
[0252][0253]
删除支持度小于s的候选项,得到频繁q项集tq:
[0254]
tq={c∈ck|sup(pipj…
)≥s}式29
[0255]
步骤4:当不存在更多项的频繁集时,根据频繁项集生成联动规则库r。
[0256]
(二)基于性格模型景点相似度权重算法
[0257]
如果u代表给景点p1和景点p2评分的用户总集u,代表景点p1的平均得分,代表用户s对p1的评分,得到式30:
[0258][0259]
由式30计算任意景点间的皮尔逊相关系数,将其作为景点相似度权重。
[0260]
(三)基于权重和联动规则的景点推荐
[0261]
除了寻找景点间的联动规则,采用联动规则来进行用户分类,寻找到近邻用户,与另外两个智能体中的性格模型寻找相似用户不同,该智能体只考虑用户自身的元素,包括性别年龄以及在定制旅行行程时的选项,而不考虑用户可能的兴趣偏好,对于事务矩阵,以一次定制代表一行,即一个事务,以一个用户属性元素代表一列,然后求联动规则,将这些用户自身元素平等对待,所有元素权重相同,根据相同的元素数量决定用户相似度ls,得到包含前m个近邻的近邻集e。
[0262]
景点的推荐算法如下:
[0263]
输入:景点联动规则库r,相似近邻集e,推荐景点数量n;
[0264]
输出:景点推荐和推荐评分字典r;
[0265]
第一步:根据近邻集e中的近邻的景点评分,以每个近邻评分最高的n个景点组成景点集p,每个景点的重要度为:
[0266][0267]
其中r
mp
代表用户m对景点p的评分,lsm代表用户m与当前用户的相似度;
[0268]
第二步:通过式30计算联动规则库r中的景点相似度权重,结合联动规则中的支持度,得到权重支持度sw;
[0269]
第三步:结合景点集p中的景点,联动规则得到推荐景点集,其中推荐度为以sw为权重的景点重要度加权和,将其归一化后得到规范的推荐景点字典r。
[0270]
(四)子算法结果的融合加权
[0271]
为了确定各个子算法的权重,本技术首先对各子算法的效度进行检验校核,校核数据采用各大旅行网站的公开数据,将其中80%的数据用作训练集,剩下部分用作校核集,采用平均绝对误差作为评价指标,衡量预测值与实际值之间的误差,误差越大mae值也越大,mae的计算公式如下:
[0272][0273]
其中fi代表预测值,yi代表真实值,结果字典r中的推荐度是归一化处理,而网站的评分区间是[1-5],需要处理后进行计算。
[0274]
检验校核三种子算法在采取不同大小的训练集时的预测效果,结果如图2所示。
[0275]
综合考虑算法的稳定性和效度,确定三种子算法的权重分别为0.45、0.35、0.2,根据式33,将三个子算法的结果中的景点推荐度进行线性加权,得到最终的景点推荐度,然后
得到最终的景点推荐集:
[0276][0277]
其中,y为最终推荐度,m=3,wi是权重,xi是子算法的推荐度。
[0278]
(五)旅行行程路线推荐
[0279]
为了便于计算,进一步设定:旅行者每日的游玩时间为8个小时,包括通勤时间;不计算旅行者从所在地到目标城市的时间和路费;景点之间的路费以1rmb/2km计算,小于2km的不计算;通勤时间按照40km/h的速度计算;住宿餐食等费用按照平均每人每天300rmb计算。
[0280]
为了方便描述,假设列表p是存放完整景点信息对象的栈,pq是一个零时存放景点信息对象的队列,初始为空,并设出行天数为d,人均预算为w,接下来的步骤包括:
[0281]
第1步:设置一个计数器count=0,设计时参数t=0,单位是小时,计费参数w=0,单位为元,设剩余预算c=w-300*d(除去吃住的固定费用),单位为元,开始执行第2步;
[0282]
第2步:如果count<d,从pq和p中取出前x项(优先取pq)放入集合x,使得x为满足的最大值,即取出游览时间总和不超过8小时的前x个景点,执行第3步;如果count≥d,中止;
[0283]
第3步:根据高德地图提供的api接口得到x个景点的地理位置,并抽象为一张具有x个顶点的完全无向图,选择推荐度最高的景点作为起点,采用多元权衡趋势逼近方法得到旅行路线(每次选择最近的景点);令t=通勤时长与景点耗时的总和,w=路程花费与门票花费的总和,若t<8且w>c,执行第4步;若t>8,执行第5步;若t<8且w<c,执行第6步;
[0284]
第4步:判定d-count的值,若d-count=1,判定8-t的值,若8-t>2,则将门票最贵的景点从集合x中移除,执行第3步;若d-count>1,则将门票最贵的景点从集合x中移除,执行第3步;
[0285]
第5步:将最末一个景点放入pq,执行第3步;
[0286]
第6步:搜索p中满足p.time<t-8的第一项,如果存在该项,则将其加入到x末尾,执行第2步;若rpd中没有符合p.time<t-8的项,则count增加1,c=c-w,参数t、w清零,将当前路线作为第count天的行程记录下来,执行第2步。
[0287]
最后中止时系统获得最终的行程推荐。
[0288]
二、旅行路线景点联动推荐规划系统
[0289]
(一)系统结构
[0290]
用户模块包括用户注册、用户登陆、完善个人信息、修改个人信息、搜索和查看景点信息、查看历史定制行程、定制旅行行程、收藏景点,如图3所示。
[0291]
旅行推荐系统功能模块包括注册登陆模块、用户信息管理模块、景点信息管理模块、行程信息管理模块、行程定制模块、搜索模块、数据采集模块、数据处理模块。如图4所示。
[0292]
其中,注册登陆模块管理用户的注册登录;用户信息模块,维护用户的基本信息,其中包括用户首次使用时完善用户个人信息和之后修改用户个人信息的功能,也包含用户收藏的景点信息;景点信息管理模块维护景点相关信息,供用户查看;行程信息管理模块负
责维护用户的历史旅行定制记录,以及用户对各个行程推荐评分;行程定制模块负责用户定制功能,为用户定制个性化的旅行行程;搜索模块负责用户的搜索功能,包括搜索景点和历史行程;数据采集模块是后台模块,包括从旅行网站上采集景点相关信息,从用户日志中采集用户行为信息,直接向用户获取偏好信息;数据处理模块负责处理采集的数据,提供给行程定制模块、用户信息管理模块、景点信息管理模块使用。
[0293]
(二)数据库设计
[0294]
采用关系型数据库,包括以下基本表:用户表、用户信息表、景点信息表、定制行程信息表、行程表、用户行为表、标签表,各个表的详细设计包括:
[0295]
1)用户表user:存放用户最基本信息,包括用户名和密码;
[0296]
2)标签表tag:存放标签信息,用于标注景点特性;
[0297]
3)景点信息表poiinfo:存放景点情况信息;
[0298]
4)用户信息表userinfo:存放用户个人相关信息;
[0299]
5)定制行程表plantrip:存放用户定制旅行推荐时的相关信息;
[0300]
(三)系统基础结构实现
[0301]
系统后台的文件包括app.py、ext.py、forms.py、models.py,其中app.py包括系统基本内容、各个功能模块的视图函数、路由、主函数;ext.py包括额外内容、哈希密码、数据库连接方式及路线;forms.py包含所有的表单;models.py包含所有的数据库模型。
[0302]
采用扩展flask-wtf和wtforms、flask-bootstrap、flask-sqlalchemy,采用的flask方法包括render_template、redirect、url_for、request、flash:
[0303]
1)flask-wtf和wtforms用于处理系统中的表单,首先在表单文件form.py中导入flask-wtf:fromflask_wtfimportflaskform;然后,从wtforms中导入需要用到的数据类型,例如导入字符串、密码、提交类型数据:from wtforms importstringfield,submitfield,passwordfield;再然后,从wtforms的验证器中导入需要的验证类型,导入验证表单不为空和验证输入字符串长度的验证器:from wtforms.validatorsimport datarequired,length;接下来定义所需要的表单,定义表单时定义表单的名称、类型、表单中的项以及各项的数据类型和名称,还有各项的验证方法;在前端的模板文件中使用表单,然后在主文件app.py中定义视图函数,在视图函数中验证请求。
[0304]
2)flask-bootstrap扩展:首先在主文件app.py中导入和加载,从模板库中获取模板,然后使用wtf.quick_form()来快速表单的宏功能;
[0305]
3)flask-sqlalchemy是将sqlalchemy封装的一个扩展,操作数据库,首先在ext.py中导入它,然后在app.py和models.py里直接从ext.py导入;直接在models.py里定义模型,用usermixin代表一个用户类,该用户类指定表名为user的数据库表,列名分别为id、username、password,column代表一列,它的第一个参数规定了各列的参数类型,第二个参数规定了id为主键,username和password否;接下来在app.py里导入user模型:from modelsimport user;在登陆的视图函数里,将表单里的数据中用户名及密码通过flask-sqlalchemy的query属性从数据库用户表中的用户名及密码数据进行对比,如果相同则登陆成功,不同则报错;
[0306]
4)render_template渲染模板,将视图中的数据返还给模板,渲染后显示给用户的过程,利用render_template渲染登陆页面,并传递其中的参数登陆表单:request处理请
求,redirect用于重定向,url_for构造url,flash发送提示信息。
[0307]
(四)景点数据采集与处理
[0308]
为获取景点相关信息,从互联网上特别是旅行网站爬取公开数据,并进行处理,获得可用数据,其中time操作时间相关部分、urllib下载网页、beautifulsoup处理html或者xml文件的库,从网页中提取需要的数据、webdriver模仿用户正常浏览网站。
[0309]
首先将该页面抓去并保存为方便处理的形式,以lxml解析器解析网页,对每个url指向的页面,即景点信息页进行操作,找到每一条需要的数据标签,然后提取其中的数据,将其写入一个txt文件中去,接下来对txt中的数据进行处理转换,存入数据库,txt中每一行为一个景点的数据,其格式是类似于键值对的形式,数据库导入转化为一张表,其中键为列名,值为数据,而其中一些不规范的数据手动修改,例如建议游玩时间中,然后利用各列与数据库中景点信息表的列对应关系,将景点数据迁移过去,数据中有项的值分别是景点封面图片和景色预览图片的网址,通过爬虫将其采集起来存放在pics文件夹里,并且文件名以数据库景点信息表中的景点编号加后缀的形式命名,封面后缀
“‑
o”,风景大图后缀
“‑
1、-2、-3”。
[0310]
(五)用户信息采集
[0311]
包括基本信息采集、行为信息采集和定制信息采集,其中,基本信息采集通过用户点击首页上的用户名称进入个人信息页面,在页面上可以选择填写或者修改个人信息,行为信息采集即记录用户收藏景点、浏览景点页面次数和时间长度信息。
[0312]
基本信息采集,在form.py中先定义个人基本信息表单userinfo_form以供用户填写,其中定义的项包括年龄、性别、兴趣爱好和确定提交,在app.py中定义用户填写和修改个人信息的视图函数user_profile,在model.py中定义了用户信息类userinfo,将表单项与数据库中用户信息表对接上,在前端页面采用bootstrap的模态框modal和表单结合,
[0313]
行为信息采集中,景点收藏操作在景点信息页面进行,用户进入一个景点信息页面时,首先按照该景点的编号和用户的编号以及用户行为类型去用户行为表userbehavior中查找用户是否已经收藏该景点,如果已经收藏,当用户点击这个button时,根据当前的收藏情况修改数据库,如果已经收藏,则删除该行,如果没有收藏则增加一行。
[0314]
用户行为表中的type代表用户行为类型,包括收藏、浏览两种类型,用户的浏览记录在用在景点信息页面模板中添加一个获取当前时间的功能,每次页面打开或者关闭,都将该页面的景点编号、在线用户编号和操作时间记录并存入数据库的用户行为表中。
[0315]
定制信息采集是在用户选择定制行程时直接向用户获取的,通过表单填写的形式进行,用户在主页点击开始定制后,即跳到定制页面,用户必须填写以下信息:行程名、是否有老人、是否有小孩、出游天数、人均预算、团体类型(单人、闺蜜、情侣、家庭、同事集体、朋友集体),风格(休闲、经典、深度、购物),在写入数据库时,同时写入定制的日期时间信息。采集页面如图5所示。
[0316]
(六)用户及行程信息管理和行程定制模块
[0317]
用户点击首页的定制后即可开始定制,输入系统需求的信息,点击提交定制即可。
[0318]
用户在首页点击自己在右上角的用户名即可进入用户信息管理页面,页面上会显示当前的用户名和用户基本信息、用户收藏景点、用户历史定制行程和时间。在页面上点击修改进入数据采集模块填写或者修改个人信息;点击收藏景点可以查看当前收藏的景点,
通过数据采集模块取消收藏的景点,点击景点进入景点信息模板查看景点信息;点击历史定制行程进入行程信息管理模块查看以前的行程定制推荐信息。如图6所示。
[0319]
行程信息管理模块提供用户查看定制完成的行程信息,定制时经过后台算法计算后得出的结果存入数据库的行程表中,然后根据模型提取出来,展示给用户,并将用户给推荐景点的评分填入数据库,之后每次需要查看行程定制信息时,行程信息视图函数就直接在这个表中提取信息渲染到行程信息页面供用户查看。
[0320]
行程信息页面包括推荐的行程,所有景点顺序概览以及大概的时间花费信息,以及用户对于该景点推荐的评分。例如做这样一个定制,定制者性别女、年龄23岁、爱好是文学艺术,选择的出行时间为3天,出行风格为休闲游,没有老人和小孩,预算1500,单人出游。定制的结果如图7所示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1