基于校验节点懒惰串行分层调度的LDPC译码算法的制作方法
本发明涉及一种低密度奇偶校验码(LDPC)的译码算法,具体来说涉及一种基于因子图中校验节点的懒惰串行分层调度(Check-Node Lazy Serial Layered Scheduling,CN-LSLS)的LDPC译码算法。
背景技术:
在通信系统中,信道编码是有效的减小噪声影响的错误检测与纠错技术,其中低密度奇偶校验码(Low-Density Parity-Check Code,LDPC Code)是目前最接近香农门限的编码技术。然而LDPC译码和迭代均衡的最优算法的复杂度太高,常常不可实现,为此需要寻找复杂度较低的次优算法。基于因子图的置信度传播(belief propagation)算法提供了一种复杂度较低且性能良好的译码方案,其中和积算法(sum-product algorithm,SPA)是一类广泛应用的置信度传播算法。
SPA采用局部运算,简化了边缘概率方程和后验概率方程的全局计算,从而降低了LDPC码和迭代均衡算法的复杂度。但是,基于因子图的算法存在以下问题:
(a)因子图中的短环增加了变量之间的相关性,容易造成误码扩散,从而降低置信度传播算法性能。
(b)置信度传播算法的运算复杂度与因子图中每个函数节点边的数目呈指数增长,因此因子图中存在的大量边增加了算法实现的复杂度。
(c)传统的置信度传播速度较慢,所需迭代次数较多,增加了译码器和均衡器的延时和功耗。这三个问题会降低通信系统的可靠性,增加接收系统的复杂度、延时和功耗,从而影响LDPC码的实用性。
目前主流的LDPC译码算法都是基于置信度传播的译码方式。LDPC码的置信度传播算法的调度算法主要有并行泛洪调度算法(PFS)、基于分层置信度传播的串行分层调度(SLS)算法和基于剩余置信度的动态调度(DS)算法。其中分层置信度传播算法因其简单的译码器结构和良好的性能而被广泛应用。
LDPC码的串行分层调度算法可在不影响误码性能的前提上,将译码算法的收敛速度提升大约1倍,串行分层译码器所需的复杂度和延时都被大大改善。然而在现代高速通信系统中,串行分层调度算法及其对应的译码器依然存在收敛较慢以及延时和功耗较大的缺点。
本专利的算法可在串行分层调度算法的基础上,进一步降低译码器的延时和功耗。
技术实现要素:
本发明的目的是基于因子图和置信度传播算法研究LDPC译码的低复杂度的高性能算法,可为改善通信系统的可靠性、延时、功耗和复杂度提供一种实用的解决方案。本发明是以串行分层调度算法为基础,根据校验节点的置信度来减少调度过程中有效性较差的更新过程,以减少不必要的运算,从而达到减少译码延时和功耗的目的。
为了实现以上目的,本发明提出一种基于校验节点懒惰串行分层调度的LDPC译码算法,即一种基于校验节点置信度的懒惰串行分层调度的低密度奇偶校验码(LDPC码)译码算法(CN-LSLS)。
在介绍译码算法之前,先定义LDPC码的校验矩阵为P,其大小为m×n,其中m为其行数,n为其列数。校验矩阵的每行对应因子图中的1个校验函数节点,每列对因子图中的一个变量节点。即该因子图中具有m个校验函数节点和n个变量节点。当校验矩阵中的元素P(i,j)(1≤j≤m,1≤i≤n)为1时,第i个校验函数节点和第j个变量节点之间建立一条路径。
基于校验节点置信度的懒惰串行分层调度的LDPC译码算法,其特征在于,包含以下步骤:
1)根据LDPC码的校验矩阵P,建立因子图;
2)初始化因子图中所有外信息为零;
3)初始化变量节点的后验概率信息;
4)初始化懒惰校验函数节点集合为空集;
5)如果懒惰校验函数节点集合为空集,则重置该集合,使其包含所有校验节点;
6)依此选择懒惰校验函数节点集合中的校验节点;
7)根据串行分层调度算法,更新步骤5)中所选校验节点的后验概率;
8)根据步骤6)中的校验节点后验概率判断懒惰条件是否满足,如果满足懒惰条件,则将步骤5)中所选的校验节点从懒惰校验函数节点集合中删除,否则保留该校验节点;
9)重复步骤5)~7),直至所有校验节点都被选择一次;
10)根据变量节点的置信度进行硬判决,得到二进制译码结果B;
11)判断译码停止条件是否满足,如果译码条件已满足,则终止译码过程,否则重复步骤4)~9)直至译码停止条件被满足。
步骤1)中LDPC码的校验矩阵P大小为m×n,其中m为其行数,n为其列数,其元素为0,1。
步骤1)中校验矩阵P的每行对应因子图中的1个校验函数节点,每列对应因子图中的一个变量节点,即该因子图中具有m个校验函数节点和n个变量节点,当校验矩阵中的元素P(i,j)(1≤j≤m,1≤i≤n)为1时,第i个校验函数节点和第j个变量节点之间建立一条边。
步骤2)中的外信息(L(rij))为第i个校验函数节点传递给第j个变量节点的外部置信度信息。
在步骤3)的后验概率信息,在第j个变量节点的后验概率信息(L(Qj))的初始化方程为:
其中yj为第i个变量节点从加性高斯白噪声信道接收到数值,σn2为噪声的平均功率。
步骤5)中重置懒惰校验函数节点集合是为了确保译码结果的正确性,防止之前判决正确的置信度在后续的更新过程中发生变化。
在步骤7)中串行分层调度算法的计算过程为依此循环执行以下3个方程:
L(qji)=L(Qj)-L(rij)
L(Qj)=L(qji)+L'(rij)
其中,L(qji)为运算过程中的中间变量,表示为第j个变量节点传递给第i个校验函数节点的外信息;L'(rij)为更新后的外信息;N(i)表示与第i个校验节点相连接的变量节点集合,而N(i)\j表示N(i)中除去第j个变量节点的集合;tanh()为双曲正切函数。
步骤7)中校验节点的后验概率定义为L(Ri),其计算公式为:
其中α为近似因子,取值为0.75;同时定义两个中间变量si si和min(i),其计算公式分别如下:
si=Πk∈N(i)sign(L(qki))
min(i)=mink∈N(i)|L(qki)|
则第i个校验节点的置信度可以表示为:
L(Ri)=si×α×min(i)
在步骤8)中,懒惰判决条件为:
L(Ri)=si×α×min(i)>Lth
其中Lth为懒惰门限,其为一足够大的正数,以保证校验节点的置信度足够可靠,该值需通过仿真确定。
步骤11)中的译码终止条件为:
1)译码迭代次数达到设定的最大值,其中迭代次数为重复步骤4)~9)的次数;
2)所有校验方程都已满足,即P×B=0。
本发明与现有的LDPC译码算法相比,具有以下优点:
1、在传统的串行分层算法中,一次译码迭代过程会遍历处理m个校验函数节点。而在本发明的译码算法中,则会根据校验节点的置信度情况,实时减少处理的校验函数节点数,从而减少了不必要的迭代更新运算,降低了译码算法的复杂度,因此译码器的功耗和延时也会被降低。
2、根据懒惰算法,不必要的更新运算被跳过,因此译码器的延时会被大大降低,同时其功耗也会相应地降低,有助于接收机的低功耗和低延时设计,对于WiMAX和DVB-S2中的LDPC码译码器,该算法可将其译码器的延时和功耗最大降低45.39%。
3、从因子图角度看,由于不必要的更新运算被跳过,导致因子图中信息的传递路径的环变长了,从而可改善译码算法的误码性能,降低译码的信噪比门限。
总之,该译码算法在执行串行分层调度算法的过程中,如果某个校验函数节点的置信度大于某一门限值,则该校验函数节点被置为懒惰节点,不参与后续的迭代译码过程,以此达到降低LDPC码译码算法的复杂度、减少译码器延时和功耗的效果。对于DVB-S2中的LDPC译码器,该算法最多可将延时和功耗降低45.39%,并可降低LDPC码的误码平层。
附图说明
图1是本发明所述LDPC译码算法的流程图;
图2是在FPGA内实现本发明算法的功能框图;
图3是本发明LDPC译码算法与串行分层调度算法的迭代次数对比图;
图4是DVB-S2中的三种LDPC码采用本发明译码算法与采用传统串行分层调度算法的误码性能对比图。
具体实施方式
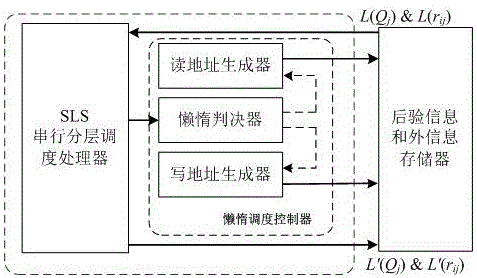
本发明中的LDPC码译码算法可在FPGA平台中进行实现,图2给出了其实现时的功能框图。该译码器包括串行分层调度处理器(SLS处理器)、懒惰调度控制器、后验信息(L(Qj))和外信息(L(rij))存储器。串行分层调度处理器(SLS处理器)根据后验信息和外信息更新校验节点相邻的变量节点的后验信息,其过程与传统的串行分层调度算法一致,并生成校验节点置信度L(Ri),以供懒惰调度控制器进行判决。懒惰调度控制器包含读地址生成器、写地址生成器和懒惰判决器。懒惰判决器根据串行分层调度处理器生成的中间变量来判断某一校验节点是否满足懒惰判决条件。读地址生成器和写地址生成器根据懒惰条件,控制后验信息和外信息的读写地址,以跳过懒惰校验节点相关的信息更新过程。后验信息和外信息存储器用于存储更新过程中的后验信息和外信息。
图1所示,基于校验节点置信度的懒惰串行分层调度译码器的实施过程,具体步骤如下:
1、初始化所有的外信息为0,并将其存储至外信息存储中。
2、根据信道接收到的信号值初始化对应变量节点的后验概率信息,并将其存储至后验信息存储器中。
3、在懒惰判决器中,初始化懒惰校验节点集合为全集,即该集合包含所有的校验节点,同时初始化后验概率和外信息存储器的读写地址表为顺序地址。
4、依此从懒惰校验节点集合中的校验节点,然后从后验概率存储和外信息存储器中读取相邻变量节点的后验概率及其相关外信息。
5、执行串行分层调度算法,更新对应的变量节点的后验概率和外信息,并将更新后的值重新存储至后验概率和外信息存储器中。
6、在执行串行分层调度算法过程中,生成校验节点后验概率L(Ri),将其传递至懒惰判决器。
7、懒惰判决器根据校验节点后验概率进行懒惰判决,并更新懒惰校验节点集合和下次迭代过程中的后验概率和外信息存储器读写地址表。
8、当遍历完懒惰校验节点集合中的所有校验节点时,完成一次迭代过程。
9、进行下一次迭代过程,当懒惰校验节点集合为空集时,将其重置为全集,然后重复执行步骤4~8)。
10、当迭代次数达到设定的最大值或判决结果满足校验方程时,结束本次译码过程,并将判决结果进行译码输出。
图3以随机构造的三种LDPC码和DVB-S2标准中的三种LDPC码为例,图4以DVB-S2标准中的三种LDPC码为例,对本专利中的算法进行性能说明。LDPC码一般用(n,k)来表示,其中n为LDPC码的编码后的码长,k为LDPC码中的信息码长(编码前的码长)。
图3比较了6种码字采用本发明的CN-LSLS算法与传统的串行分层调度(SLS)算法的平均迭代次数。这6种码字分别为随机构造的码和DVB-S2标准,它们分别为(576,288)、(2106,1008)、(8064,4032)、(64800,32400)、(64800,48600)和(64800,58320)。不同算法的Tavg(平均迭代次数)是在相同的信噪比和相同的误码性能(BER=1E-6)条件下进行对比的。对于(576,288)码,在信噪比Eb/N0=3.5dB下,为了使得误码率达到1E-6,传统的串行分层调度算法(SLS)所需的平均迭代次数为2.55,而本发明中的CN-LSLS算法所需的平均迭代次数仅为2.49,迭代次数减少了2.35%。对于(2016,1008)码,在信噪比Eb/N0=3.0dB下,为了使得误码率达到1E-6,传统的串行分层调度算法(SLS)所需的平均迭代次数为3.65,而本发明中的CN-LSLS算法所需的平均迭代次数仅为3.43,迭代次数减少了6.03%。对于(8064,4032)码,在信噪比Eb/N0=2.5dB下,为了使得误码率达到1E-6,传统的串行分层调度算法(SLS)所需的平均迭代次数为5.46,而本发明中的CN-LSLS算法所需的平均迭代次数仅为4.85,迭代次数减少了11.17%。对于DVB-S2(64800,32400)码,在信噪比Eb/N0=2.0dB下,为了使得误码率达到1E-6,传统的SLS算法所需的平均迭代次数为13.68,而本发明中的CN-LSLS算法所需的平均迭代次数仅为7.47,迭代次数减少了45.39%。对于DVB-S2(64800,48600)码,在信噪比Eb/N0=3.0dB下,为了使得误码率达到1E-6,传统的SLS算法所需的平均迭代次数为8.35,而本发明中的CN-LSLS算法所需的平均迭代次数仅为5.05,减少了39.52%。对于DVB-S2(64800,58320)码,在信噪比Eb/N0=4.8dB下,为了使得误码率达到1E-6,传统的SLS算法所需的平均迭代次数为4.49,而本发明中的CN-LSLS算法所需的平均迭代次数仅为3.00,减少了33.18%。从图3中可以看出平均迭代次数改善了2.35%~45.39%。在硬件平台中,本发明中的CN-LSLS算法的功耗和延时也会相应地大约改善2.35%~45.39%。
图4从左至右依次对比了DVB-S2标准中(64800,32400)、(64800,48600)和(64800,58320)三个码字的采用本发明CN-LSLS算法与传统的串行分层调度(SLS)算法的误码率性能,其中最大迭代次数设置为50。其中实线+方框表示的是CN-LSLS算法的误码率性能,实线+圆圈表示的是SLS算法的误码率性能。例如对于DVB-S2(64800,32400)码字,CN-LSLS算法的门限信噪比为1.0dB,SLS算法的门限信噪比为1.1dB。对于DVB-S2(64800,48600)码字,CN-LSLS算法的门限信噪比为2.3dB,SLS算法的门限信噪比为2.4dB。对于DVB-S2(64800,58320)码字,CN-LSLS算法的门限信噪比为3.8dB,SLS算法的门限信噪比为4.1dB。从图4可以看出本发明的CN-LSLS的门限信噪比优于传统SLS的门限信噪比大约0.1~0.3dB,且误码平层有所改善。该仿真结果证明了CN-LSLS算法在降低迭代次数的同时,不仅没有恶化误码性能,同时还对误码性能有所改善。
- 还没有人留言评论。精彩留言会获得点赞!