一种基于串行抵消列表极化码译码的动态分布排序算法的制作方法
本发明涉及一种基于串行抵消列表极化码译码的动态分布排序算法。
背景技术:
Arlkan提出,极性码是信道编码的第一类,几乎可实现对称的二进制输入离散无记忆信道的容量(B-DMCs)。由于其较低的计算复杂度为O(NlogN),其中N为极化码长度;以及快速傅氏变换Fast Fourier Transformation(FFT)形式的译码结构,串行抵消译码successive cancellation(SC)算法已经成为最有效的极化译码算法之一。然而相比于最大似然maximum likelihood(ML)解码器,串行抵消译码器的解码性能仍然有较大的衰落。为了缩小由传统的串行抵消译码器的次最优路径选择带来的性能差距,列表串行抵消译码算法(list SC polar decoder)应运而生。加入列表(L)后,带来了更多的路径选择的机会。
SCL译码算法的主要思想是在译码树扩展中选出最优的L条路径,并对最优的L条路径再一次扩展。级每一层译码都会涉及一个从2L个候选节点中筛选出最优的L个节点的排序操作。串行抵消列表译码器的主要缺点是,随着列表L大小的增大,译码器排序部分的的复杂度非线性增加。在路径扩展过程中,需要从2L个扩展路径中标选出L个具有最大路径度量值的路径作为候选路径。若选择类似于冒泡排序或者选择排序方法来实现,其运算复杂度为O(L2);若选择类似于堆排序方法来实现,其运算复杂度为O(Llog2L),但同时也增加了所需的内存单元。此外,两种算法的延时较大,不利于高速的硬件实现。
技术实现要素:
发明目的:本发明的目的是提供一种能够解决现有技术中存在的缺陷的基于串行抵消列表极化码译码的动态分布排序算法。
技术方案:为达到此目的,本发明采用以下技术方案:
本发明所述的基于串行抵消列表极化码译码的动态分布排序算法,包括以下步骤:
S1:针对L条路径进行扩展:每个父节点的两个扩展子节点分别设为FC和NC,其中FC为较优路径,NC为较差路径,并将得到的L个FC节点设为集合FCS,将得到的L个NC节点设为集合NCS;
S2:将L个FC节点设为L条最优路径,用集合C表示;
S3:初始化i=1,i为排序轮数;
S4:根据实际性能要求设定最大排序轮数n,且1≤n≤L-1;
S5:对于第i轮排序,将集合FCS中所剩的L-i+1个FC节点中选出最差的路径FCi,将集合NCS中所剩的L-i+1个NC节点中选出最优的路径NCi;
S6:比较FCi与NCi:如果FCi较优,则排序结束,跳转到步骤S12;否则,继续进行步骤S7;
S7:将集合C中的FCi路径替换为NCi节点;
S8:将集合FCS中的FCi元素删除,则集合FCS中的元素个数变为L-i;
S9:将集合NCS中的NCi元素删除,则集合NCS中的元素个数变为L-i;
S10:更新i值,i=i+1;
S11:如果i<n,则跳转到步骤S5进行下一轮排序;否则,则继续进行步骤S12;
S12:排序完成,最优的L条路径为集合C中的路径。
有益效果:与现有技术相比,本发明具有如下的有益效果:
1)本发明利用了SCL译码要求中,从2L条扩展路径中选取L条最优路径的特点,对于L条所选路径不需要知道顺序结果,避免了直接排序;
2)本发明利用了扩展节点中L个FCs节点很大可能性为最终的L条最优路径,以FC节点为基础,用替换掉较差FC的方式调整排序结果,极大降低了排序复杂度;
3)本发明将复杂度为O(L2)的冒泡排序或复杂度为O(Llog2L)的堆排序降低到了复杂度为O(L)的动态分布式排序;
4)本发明是动态排序,其排序延时不是固定的。由于FC节点大比例优于NC节点,在针对一帧极化码的每层动态排序中,大多数排序只需要一轮排序,即没有NC节点与FC节点的替换。
附图说明
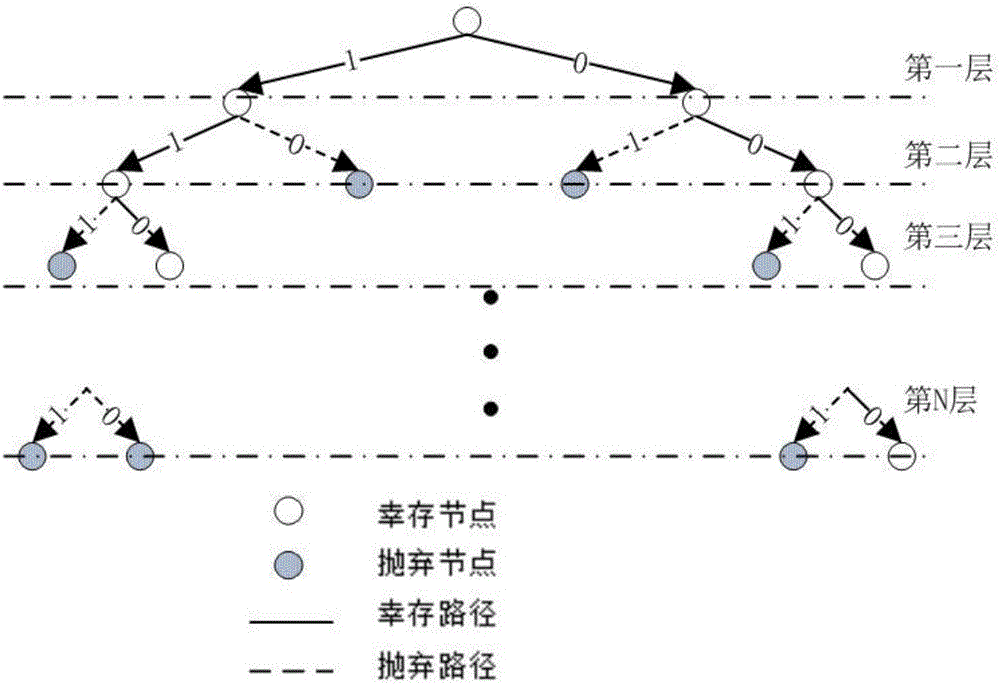
图1为N比特Polar码的搜索码树;
图2为采用本发明具体实施方式方法与采用一般SCL译码算法的误帧率性能对比图;
图3为本发明具体实施方式中DS2算法的平均计算周期;
图4为本发明具体实施方式中DS3算法的平均计算周期。
具体实施方式
下面结合具体实施方式对本发明的技术方案作进一步的介绍。
1、搜索码树
Polar码的SCL译码算法本质上是宽度优先的树形搜索算法,N比特Polar码的搜索码树如图1所示,L为保留路径数。图1中第N层中路径度量值(Path Metric,PM)最大的路径(幸存路径)即为译码输出次数表示向量,标号为1到N的N个译码结果。
2、SCL算法
对于参数为的Polar码,N为码长,K为信息位数量。对应信道WN的输出向量为表示接受的标号为1到N的N个接受数据。A为信息位分布情况集合。为冻结位的值,通常设为0。译码的路径度量值定义为信道转移概率常采用其对数形式。为了降低计算和存储的复杂度,我们采用等价的路径度量值定义如下:
其译码的递推公式如下:
其中表示N比特译码器的第i个译码PM值,表示对应节点的部分和。与表示连接节点上层迭代的两个部分和。表示异或计算,max*代表Jacobi对数:
初始化条件其中σ2为噪声方差。max(x1,x2)为取x1,x2中的最大值。
3、本具体实施方式
在路径扩展过程中,需要从2L个扩展路径中标选出L个具有最大路径度量值的路径作为候选路径。若选择类似于冒泡排序或者选择排序方法来实现,其运算复杂度为O(L2);若选择类似于堆排序方法来实现,其运算复杂度为O(Llog2L),但同时也增加了所需的内存单元。此外,两种算法的延时较大,不利于高速的硬件实现。
本具体实施方式公开了一种基于串行抵消列表极化码译码的动态分布排序算法包括以下步骤:
S1:针对L条路径进行扩展:每个父节点的两个扩展子节点分别设为FC和NC,其中FC为较优路径,NC为较差路径,并将得到的L个FC节点设为集合FCS,将得到的L个NC节点设为集合NCS;
S2:将L个FC节点设为L条最优路径,用集合C表示;
S3:初始化i=1,i为排序轮数;
S4:根据实际性能要求设定最大排序轮数n,且1≤n≤L-1;
S5:对于第i轮排序,将集合FCS中所剩的L-i+1个FC节点中选出最差的路径FCi,将集合NCS中所剩的L-i+1个NC节点中选出最优的路径NCi;
S6:比较FCi与NCi:如果FCi较优,则排序结束,跳转到步骤S12;否则,继续进行步骤S7;
S7:将集合C中的FCi路径替换为NCi节点;
S8:将集合FCS中的FCi元素删除,则集合FCS中的元素个数变为L-i;
S9:将集合NCS中的NCi元素删除,则集合NCS中的元素个数变为L-i;
S10:更新i值,i=i+1;
S11:如果i<n,则跳转到步骤S5进行下一轮排序;否则,则继续进行步骤S12;
S12:排序完成,最优的L条路径为集合C中的路径。
本具体实施方式公开的分布式排序算法(DS)近似于一般的排序算法,但其存储和比较复杂度均低于一般排序算法。当前面的比较不满足条件时,算法退出,不再进行后续比较,大大降低了平均的比较复杂度。由分析及相关仿真可知,PMs中较大的i值对应的路径度量值越小,很有可能是需要丢弃的,对算法的影响因素占主导。仅取i=L-1~L-n完成路径的扩展及度量值排序,称为DSn,设定参数n为最大比较轮数。此时,算法1中对的排序操作是不需要的,只需要查找其最大、最小、次大及次小值等若干值即可。硬件实现中,我们可做进一步的变化,查找的最小、次小值来代替查找的最小、次小值,在复杂度相同的情况下,提高译码性能。通过仿真可知,基于DS2(L=4)或DS3(L=8)的SCL译码算法与CRC校验相结合后,译码的误诊率性能损失几乎可以忽略。当L较大时,如L=16、32,单纯的DS2或DS3算法带来的性能损失较大,对前N/2比特采用完全的DS算法,后N/2比特采用DS3算法来实现。
以L=4为例,基于DS2算法的路径扩展过程如下:1,将四条路径分别区分出四个FC节点与四个NC节点;2,在四个FC节点中找出最差的节点FC1,在四个NC节点中找出最优的节点NC1;3,比较FC1与NC1,如果FC1较大,则排序结束,选取的四条较优路径为四个FC对应的路径,不必进行下面的操作,反之进行下面的操作;4,用NC1对应的路径替换FC1,且这两个值不再进入比较操作;5,在剩下的三个FC中选出最差的节点FC2,在剩下的三个NC节点中找出最优的节点NC2;6,比较FC2与NC2,如果FC2较大,则排序结束,选取的四条较优路径为三个FC与NC1对应的路径,反之,选取的四条路径为剩下两个FC与NC1和NC2对应的路径,排序结束。DS2算法将度量值的比较复杂度由O(L2)降低为O(L)。DS2算法易于硬件的并行就流水线实现,可降低复杂度,提高数据处理速率。
对于不同的L值,改进的SCL译码与一般SCL译码的误帧率性能对比如图2所示,图2中为码长1024有效信息位512的极化码。L=4时,基于DS2算法的SCL译码与一般的SCL译码具有几乎一致的误帧率性能,可作为低复杂度硬件实现的一个较好选择;L=8时,基于DS3算法的SCL译码与一般的SCL译码具有几乎一致的误帧率性能,可作为低复杂度硬件实现的一个较好选。
本具体实施方式的另一个优势在于,本排序是一个动态的排序过程,排序所要进行的轮数是不确定的。由于SCL译码过程本身具有的性质,L条路径中的扩展下的各FC节点很大可能性就是最终的所筛选出的L条最优路径。故在译码过程中大多数分布式排序过程只需要进行一轮排序。通过仿真可以证明排序长度极低。
从图3仿真中可以看出当L=4时采用本具体实施方式中的DS2排序算法平均只需要进行1.075轮排序(8个周期),在时序上也比严格排序有了很大提升(若使用传统的冒泡排序需要的排序时钟为L2数量级,即16个周期)。从图4仿真中可以看出当L=8时采用本具体实施方式中的DS3排序算法平均只需要进行1.074轮排序(16个周期),在时序上也比严格排序有了很大提升(若使用传统的冒泡排序需要的排序时钟为L2数量级,即64个周期)。本具体实施方式中的分布式排序算法平均排序消耗在一轮左右,极大的降低了排序所浪费的延时。
- 还没有人留言评论。精彩留言会获得点赞!