一种无损自适应数据压缩和解压缩的系统的制作方法
本发明数据压缩和解压缩技术领域,尤其是涉及一种无损自适应数据压缩和解压缩的系统。
背景技术:
在很多环境下,数据的高速电子收集往往会存在很多问题。例如,当通过病人监护仪收集患者的临床数据时,大量的数据可在较短的时间间隔内完成收集。电脑系统则通过典型的方式将这些数据存储在计算机内存中等待后续处理。计算机内存是一种有限的资源,能够很快被所收集到的数据占满。
为了减少所收集数据对计算机内存的需求,一些计算机系统会在向内存中存储数据之前对数据进行压缩。当后续处理需要所收集的数据时,电脑系统再将这些数据解压缩。因此,当不需要对数据进行处理时,数据储存所需要的内存空间能够实现最小化。
目前有许多压缩和解压缩方法。不同的方法具有不同的优点。例如,一些方法能够大规模地减少数据储存规模。其他方法则能在压缩和解压缩过程中很好地保护原数据。这些方法又被称为无损压缩解压缩,因为在整个过程中数据没有发生损坏。其它方法能够很快地压缩或者解压缩数据。但是这些方法又存在着诸多不同的缺点。例如,一些方法不能大规模地减少数据储存规模。其它方法在压缩和解压缩过程中不能够保护原数据免于损失,因此解压缩后的数据只是原数据的近似值。另外,一些方法的压缩与解压缩速度过于缓慢。一些方法在压缩或者解压缩时,占用过多的计算机内存。
因此,开发一种能够实时快速、显著减少数据大小,并且在压缩和解压缩过程中对计算机内存占用需求较小的无损数据压缩和解压缩方法,是十分必要的。
技术实现要素:
本发明的目的在于提供一种无损自适应数据压缩和解压缩的系统。
为实现上述目的,本发明采用以下内容:
一种无损自适应数据压缩和解压缩的系统,所述系统包括:指示数据值频率的频率表;识别频率表中一组数值的方法;根据压缩频率表中的频率,为所识别集合中的每个数据值生成基于频率的编码;从分组中检索数据值的方法;当检索到的数据值在所识别的集合中时,输出所生成的基于频率的编码用于检索数据值的方法,或者当检索到的数据值不在所识别的集合中时,以不基于频率编码的格式输出检索的数据值;将输出产生的编码和输出数据值存储为压缩数据值分组的方法;以及根据多个分组中一个分组数据值的频率,更新频率表的方法。
进一步地,还包括:用于当连续检索数据值相等时,输出检索数据值游程编码的方法,游程编码包括相等数据值数量的一个指示符和相等数据值。
进一步地,还包括:用于当所识别的数据值集合包括一个数据值,该数据值等于游程编码中数据值数量的指示符,在游程编码中输出生成的基于频率编码的方法。
进一步地,还包括:用于以不基于频率编码的格式输出指示符的方法当所识别的数据值集合不包括一个数据值,该数据值等于游程编码中数据值数量的指示符。
进一步地,还包括:用于当游程编码中相等数据值在所述识别的组中时,输出所生成的基于频率的编码用于游程编码中相等数据值的方法。
本发明具有以下优点:
本发明的系统是通过以下方式来压缩数据的:首先计算相邻数据值之间的差异,识别确定出多个经常发生的差异性,并跟踪所识别出的差异的发生频率,同时对所识别出的差异性生成一次编码,该编码长度基于差异发生的频率;系统随后为除被识别出的差异以外的全部差异性生成二次编码,并在当计算差异不属于能够影响数据压缩的已识别差异时,使用一次编码进行差异编码识别,使用二次编码对每个计算差异性进行相应识别差异编码。优选地,系统根据被追踪到的发生频率再次生成一次编码。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细的说明。
图1是本发明系统压缩和解压缩技术原理的示意图。
图2是压缩和解压缩例程数据流示意图。
图3显示了ivalue、value以及count的样本数据结构。
图4显示了针对图3所示count数组数据而生成的编码。
图5显示了针对图3所示count数组数据而生成的编码树。
图6是压缩例程流程图。
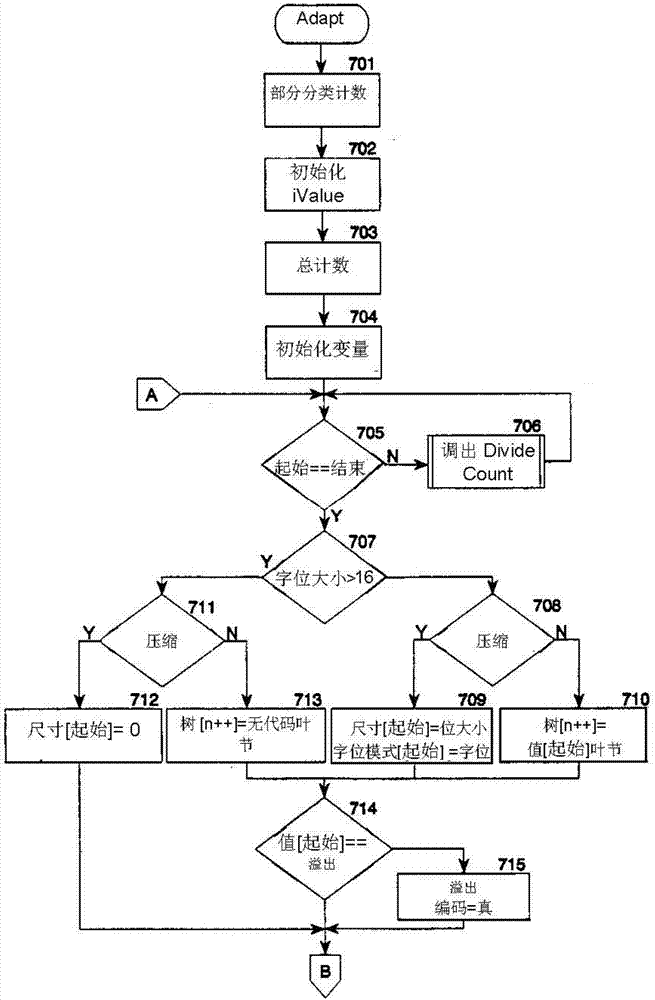
图7-1和图7-2是adapt例程流程图。
图8-1和图8-2是dividecount例程流程图。
图9是outrun例程流程图。
图10是outvalue例程流程图。
图11是解压缩例程流程图。
图12是getrun例程流程图。
图13是解码例程流程图。
具体实施方式
为了更清楚地说明本发明,下面结合优选实施例对本发明做进一步的说明。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。
实施例
图1是本发明系统压缩和解压缩技术原理的示意图。系统通过病人监护仪110收集病患数据并在记录仪112上进行数据的记录。病人监护仪110能够收集多种病患信息,并能以每条通道每秒钟约448字节的传输速度,向中央处理单元111提供12条信息传输处理通道。有效整体数据传输速率约为5.376千字节/秒。当中央处理单元111从病人监护仪110处接收到字节数据信息时,其会将数据储存在原始数据随机存取存储器113中。当数据“包”存储在原始数据随机存取存储器113中之后,中央处理单元111发起存储在压缩软件随机存取存储器116中的压缩例程。在本发明的实施例中,数据包的大小由数据字节的多少预先确定。专业技术人员将会感受到本发明系统的这一好处,即数据包能够以其它方式进行定义,例如通过预先定义好的时间间隔来收集获取数据。压缩例程从原始数据随机存取存储器113中检索到数据包,进行压缩并将数据储存在压缩数据随机存取存储器114中。压缩数据随机存取存储器114可同时处理数个压缩数据包。当中央处理单元111决定记录读写某一数据包时,将会发起存储在解压缩程序随机访问内存ram117中的解压缩例程。
解压缩例程在压缩数据随机存取存储器114中检索到压缩数据,并进行解压缩,之后将其存储在解压数据随机存取存储器115中。中央处理单元111从解压数据随机存取存储器115中检索到已解压数据并将数据写入到记录器112中。本发明的压缩和解压缩技术能够用于其它系统实现中。例如,本发明的方法能够用于进行与医疗数据无关的其它数据压缩。此外,数据还可以在接收之时就进行压缩,无需先存储到原始数据随机存取存储器113中。同样地,压缩数据也可以直接在记录器112中读写,无需先存储到压缩数据随机存取存储器114中。被记录的数据可在完成处理之后再进行解压缩。
在一个优选实施方式中,压缩系统将数据包中的数据(16位字)转化为后缀有一系列“增量”的初始值。每个增量是数据包中两个相邻字之间的差异。如果生成了增量“运算”的指令,系统会将“运算”转化为一个运算指示器,一个运算计数,以及一个增量运算值。“运算”是一系列的相同数值的相邻增量。对于病患数据而言,其大多数增量已被确定属于-16到+16的范围中,该范围也就是所谓的编码范围。专业技术人员将会感受到本发明系统的这一好处,也就是编码范围能够满足不同类型的待压缩数据的需求。本发明的方法能够用于多种编码范围。系统通过采用哈夫曼编码的改良型版本,也就是香农-范诺编码方法来对编码范围以及换码符号进行编译。系统从-16到+16,以及加上换码符号,共编译34个值。系统会跟踪这34个编译值在压缩过程中相互遇见的频率。在每个数据包压缩之后(或者在数据包解压缩之前),系统根据更新后的频率数据生成了一种新的香农-范诺编码。因此,编码能够自适应于压缩数据。“溢出”符是在编码范围之外(也就是17)的数值,用来指示(1)后续数据不在编码范围之内,或者指示(2)某一“运行”已被编译。如果数据不在编码范围内,那么表明该数据是8位的或者16位的。例如,如果增量为64,那么系统将产生如下位流(比特流):
"01001000000”
在本例中,换码符号编译为“01.”。二进制数字“0”在换码符号之后,指示一个8位数值的开始。二进制数字“01000000”是十进制数字64的8位元表示。如果增量为512,那么系统将产生如下位流(比特流):
"01100000001000000000”
在本例中,换码符号编译为“01.”。二进制数字“10”在溢出符之后,指示一个16位数值的开始。二进制数字“0000001000000000”是十进制数字512的16位元表示。一个运算则被编译为换码符号、运算计数以及运算增量。例如,一个由10个等于5的增量组成的运算,系统会产生以下位流:
“01111111101001110110”
在本例中,换码符号编译为“01.”。二进制数字“11”在换码符号之后,指示一个运行编码。其中位数“111110100”是指计数为10的一个运算。位数“1110110”则是指运算增量为5。同样地,如果运算计数或者运算增量没有在编码范围内,系统将会为运算计数与运算增量编译相应的换码符号。例如,一个由32个等于5的增量组成的运算,系统会产生以下位流:
"0111010001000001110110”
在本例中,换码符号编译为“4)1”。位数“11”紧接换码符号,指示后续运算编码。之后的位数“01”代表换码符号,表示运算计数不在编码范围内。此换码符号后的“0”是指,在其之后的本运算计数系一个8位元数值。其中位数“00100000”是指计数为32的一个运算。位数则是指运算增量为5。如果运算增量不再编码范围内,那么它也会被编译有一个换码符号。
系统将根据运算增量值与最小可能运算长度来决定何时编译运算。如果运算增量不在编码范围内,那么系统将会对运算进行编码。如果最小可能运算编码长度小于运算计数与编译运算增量值所需位数的乘积,那么系统将会对运算进行编译。最小运算编码长度等于换码符号加2(用来指示运算的字位)加上2,再乘以最短编码的长度。专业技术人员将会感受到本发明系统的这一好处,也就是能够根据其它因素来决定是否对运算进行编码。在本发明的实施例中,一个运算被定义有两个或者多个增量,因此相应运算计数被编译为实际运算计数减去2。同样地,可通过将特定运算长度表示为负值的方法来对最长可达35位的运算进行编译。
压缩例程通过递归算法的香农-范诺编码方法来生成34个字符的编码。在本发明的首选表现方案中,相关方法是通过一种迭代算法来实现的,详尽描述如下文所示。例程开始于一个待编译全部符号频率计数的分类数组。本发明中的该步骤编码方法将会计算总频率数。然后从最频繁的符号处开始,对数组中的频率进行求和,直到和数达到总数的一半。之后将符号划分为两组。第一组为上述求和过程中使用到的符号,第二组为除第一组符号以外的其它符号。第一组中的符号被分派指定一个值为“0”的字位,第二组中的符号则被分派指定一个值为“1”的字位。本发明中的该步骤编码方法将递归地运用该种算法来生成编码。表1展示了一个由采用了香农-范诺编码的混杂式c编程语言编写的递归例程。当例程完成,“字位模式”(bitpatten)数组中会包含有每个编码值的编码模式,并且“规模”(size)数组中会包含有相应字位模式(bitpatten)的长度。例程输入一个针对“计数”(count)数组中每个编译值的频率计数分类数组。当初次发起时,变量“起始”(start)与“结束”(end)划定了“计数”(count)数组的起始与终止处,变量“总计”(total)则含有频率的总数,变量“字位大小”(bitsize)以及变量“字位”(bits)设为0。例程将递归地根据条目的总和来划分数组,并对变量“字位”(bits)进行设定,以表明相应编码。当“count“数组被进一步细分为包含有1个条目(起始==结束)时,例程将“size”数组的【start】条目设为等于变量“bitsize”并将数组“bitpattem”的【start】条目设为等于变量“字位”(bits)。
表1
霍夫曼编码的主要特点是,即便每个符号的字位数目不尽相同,也不需要在符号之间进行界定。该编码方式能够确保,较短编码中所使用的字位模式将不会以较长编码中字位模式之起始的形式出现。
解压缩系统通过采用与建立编码时所使用的相同频率计数值,建立一个二叉树。在本发明的首选表现方案中,香农-范诺编码方法也被用于建立二叉树,当进行解压缩时,该方法将会创建二叉树上的节点,而非是创建字位。二叉树的形成将在下文进行详尽的描述。为了解码,系统输入被压缩数据的位流。在“0”字位上,例程跟随二叉树上的分支节点“0”,在“1”字位上,例程跟随二叉树上的分支节点“1”。如达到了叶节点,那么节点中则包含有相应的被解码数值,否则例程将输入下一个字位并通过二叉树继续执行。当34个符号被编译后,二叉树将包含有34个叶节点,以及33个非叶节点。在本发明的实施例中,一个字节表示一个节点。因此,解码二叉树中的长度为67个字节。二叉树通过一个长度为67的数组来进行表示。每个节点(或者数组中的字节)包含有是否该节点为叶节点的指示器。如果节点为叶节点,那么它将含有相应的解码数值。如果节点不是叶节点,那么它将含有指向分支节点“1”的相应偏移值。分支“0”处的节点被保存在二叉树的下一个字节中。
尽管该编码方法是自适应的,但它仍需要从首个数据包编码的默认频率值开始执行。在本发明的实施例中,通过生成数个数据包的频率来获得默认频率值。
在一个优选实施方式中,频率计数只是进行了部分分类,而不是完全分类。频率计数是通过建立一条穿过频率计数数组的通路,并在第二条目大于第一条目时交换相邻条目来实现部分分类的。该种部分分类减缓了自适应过程。一般而言,默认频率值相对于初始数据包的数据频率而言,具有更富代表性的频率特点。因此,在最初的少数几个数据包处理过程中,部分分类更能够反映出默认频率的更具代表性的频率特征。
图2是压缩和解压缩例程数据流示意图。“压缩202”例程将数组“源201”中的数据进行压缩,并生成数组“压缩源203”。“解压缩204”例程将“压缩源203”进行压缩,并生成“解压缩源205”。因为本发明中的压缩方法为无损压缩方法,数组“解压缩源205”中含有与数组“源201”中相同的数据。数组“计数206”以及“计数207”则分别包含有“压缩202”例程以及“解压缩204”例程的频率计数值。在每次压缩之后,“压缩202”例程会更新数组“计数206”中的频率值。相似地,在每次解压缩之后,“压缩204”例程会更新数组“count207”中的频率值。在最开始,数组“计数206”以及数组“count207”中包含有相同的默认频率值。在数据包被压缩又被解压之后,数组“count206”与数组“count207”中所包含的数据也是完全相同的。
图3、4、5显示了在样本数据值压缩和解压缩例程中所采用的数据结构。图3显示了ivalue301、value302,以及count303的样本数据结构。数组“count303”中包含有编码范围以内的,以及包括换码符号在内的每个符号的频率计数值。数组“value302”包含有每个已编译符号的数值。在数组“count303”与数组“value302”之间存在着一一对应的数据关系。例如,数组“value”中的第5条目是符号3。数组“count”中第5条目是10197,这说明符号3的频率计数为10197。数组“ivalue301”包含有来自于已编译符号并指向“value”数组以及“count”数组中相应条目的映射。例如,数组ivalue【16+3】条目包含有a4,a4就是指向包含有符号3频率计数的“count”数组的指针。因此,符号3的频率就在“count”数组的【ivalue【16-f3】】条目中。当“ivalue”数组的索引位于0-33范围之内时,符号增加16。图4显示了针对count303所示计数数组数据而生成的编码。数组“bitpattem401”包含有针对每个已编译符号的相应编码。数组“size402”则包含有数组“bitpattem”中相应编码的长度。例如,正如数组“规模”条目【4】所显示的数值那样,数组“bitpattem”的第5条目“1100”其长度为4,在本发明的首选表现方案中,数组“bitpattem”所含条目长度为16位,这也就将最大编码长度限制在16位上。数组“字位模式”的【ivalue【16+3】】条目包含有符号3的字位模式。图5显示了针对数组“count303”中的数据而生成的解码二叉树数组“二叉树501”包含有67个单字节的条目,该解码二叉树中每个节点对应一个字节。每个节点包含有能够指示该节点是否为叶节点的状态标志。如果节点为叶节点,那么该节点则含有该叶节点的符号数值。如果节点非为叶节点,那么该节点则含有指向分支节点“1”的偏移量。分支节点“0”是数组“二叉树”中的紧随条目。为了将位流“1100”解码为符号3,系统将按照以下步骤进行处理。系统从数组“二叉树”索引为“0”的条目,也就是二叉树的根节点开始执行。当遇见首个字位“1”时,系统会通过对数组“二叉树”的当前位置加上数组“二叉树”条目【0】偏移值来对分支“1”进行跟踪。
这会将当前位置重置到“二叉树”条目【4】处。由于数组“二叉树”条目【4】不是叶节点,因此系统输入下一个字位,也就是字位“1”。系统通过对数组“二叉树”的当前位置加上数组“二叉树”条目【4】偏移值来对分支“1”进行跟踪。这会将当前位置重置到“二叉树”条目【8】处。由于数组“二叉树”的条目【8】不是叶节点,因此系统会输入下一个字位,也就是“0”。系统通过在数组“二叉树”的当前位置上加1来跟随分支节点“0”。这会将当前位置重置到“二叉树”条目【9】处。由于数组“二叉树”的条目【9】不是叶节点,因此系统会输入下一个字位,也就是“0”。系统通过在数组“二叉树”的当前位置上加1来跟随分支节点“0”。这会将当前位置重置到“二叉树”条目【10】处。由于数组“二叉树”的条目【10】是叶节点,因此系统将会检索恢复条目【10】的数值,也就是3。因此,字位“1100”就完成了对符号3的编码。
图6是压缩例程流程图。“压缩”例程输入原数据并输出压缩后的原数据。输入到“压缩”例程中的参数分别为“源”数组、“计数”count,以及“数组”value。例程返回至“destination”数组、“计数”count,以及“数组”value。“压缩”例程首先通过发起能够将编码储存在“bitpattem”以及“size”数组中的“adapt”例程来生成相应编码。之后,“压缩”例程在首次发起进程时将“count”数组设为零。清空默认频率计数,并初始化实际频率计数数组。随后,“压缩”例程计算增量值,并通过使用“bitpattem”数组中的编码、运算编码,并对位于编码范围之外的增量值进行编码,来储存压缩后的数据。在框601中,例程调用“adapt”例程来针对压缩生成自适应性编码,并将返回至“size”以及“bitpattem”数组。在框602中,如果“首次使用”状态标志为“真”,那么意味着这是第一次调用“压缩”例程且例程将会在框603中继续执行,否则例程将会在框604中继续执行。在框603中,例程初始化“count”数组的条目,并将“首次使用”状态标志设定为“假”。当第一次发起“adapt”例程时,“count”数组的值将被设定为默认频率计数。随后,“压缩”例程将“count”数组的值设定为实际频率计数,来影响自适应性。在框604中,例程将变量“minrunsize”设定为等于2加上溢出字位的大小再加上2,乘以最小字位模式的长度。这就是已编译运算的最小字位长度。在框605到块613中,例程循环并处理“源”数组中的每个条目。例程计算增量值并向“destination”数组输出编码。在框605中,例程对在“源”数组中循环并向“destination”数组输出初始数据的相关变量进行初始化。例程将变量“runcount”设定为0,将“destination”数组中的【1】条目设为“源”数组中的【0】条目,并将变量“lastdelta”设为等于“源”数组中的【0】条目减去“destination”数组中的【1】条目。变量lastdelta包含有当前与先前“源”数组条目之间的差异。在框606中,如果“源”数组中的全部数据都已被处理过,那么例程将在框609中继续执行,以向“destination”数组输出最后编译的数据,否则例程将在框607中继续执行。在框607中,例程将变量“nextdelta”设定为当前与后续“源”数组条目之间的差异。如果变量“nextdelta”等于变量“lastdelta”,那么系统将发起一个运算,同时例程将会在框608中继续执行,否则例程将在框609中继续执行。在框608中,例程增加一个“runcount”变量并循环至框606中。在框609中,如果变量“runcount”等于0,那么意味着不存在任何运算,且例程将在框611中继续执行,否则例程会在框610中继续执行。在框610中,例程发起“outrun”例程以向“destination”数组中输出运算数据。在框611中,例程在变量lastdelta发起“outvalue”例程以向“destination”数组中输出运算数据。在框612中,如果“源”数组中的数据已被全部处理过,那么压缩过程完成、例程返回,否则例程将在框613中继续执行。在框613中,例程将变量“runcount”重置为0,将变量“lastdelta”设置为变量“nextdelta”,前进到“源”数组的下一个条目上,并循环至块606中以处理下一个增量值。
图7-1和图7-2是adapt例程流程图。在本发明的实施例中,编码以及解码数据的生成是在相同的例程中完成的。在压缩数据时,“adapt”例程根据“count”数组为相应数据生成编码,并将编码信息储存在“bitpattem”数组以及“size”数组中。在解压缩数据时,“adapt”例程根据“count”和value数组为相应数据生成编码,并将编码信息储存在数组树中。“adapt”例程的输入参数分别是“count”数组、“value”数组以及指示压缩或者解压缩的状态标志。当压缩数据时,例程将返回“bitpattem”数组以及“size”数组。当解压缩时,例程将返回“二叉树”数组。“adapt”例程是上述递归例程在压缩时的一种迭代实现。例程通过采用栈的方式来实现例程的递归性。在可选择的实施方案中,adapt程序作为直接插入码在压缩程序中执行。紧接着,当出栈时,出栈的数据保存在结构stack中。同样的,当入栈时,来自结构stack的数据存入栈中。数据结构stack中包含有各种要素:变量start(开始)、end(末尾)、total(总数)、bitsize(位大小)和n,下文有详细说明。与“1”分支有关的信息推进栈中。在对应的“0”分支处理完后,信息再从栈中弹出。在框701中,程序对count数组进行部分排序。程序将对比count数组,如一个条目小于后续的条目,则相互交换。如此,程序完成count数组排序。程序还交换value数组中的项,以便保持数组间的一致。在框702中,程序初始化ivalue数组。ivalue数组包含有编码符号与count数组和value数组中对应项索引的映射。-因此,数组条目count【ivalue【16+escape】】包含有换码符号的频率计数。在框703中,程序设置对应count数组中所有项之和的变量total(总数)。在优选的实施方案中,当变量total大于26000时,为防止溢出,程序将count数组中所有的计数分成两组,然后重新计算总数。在框704中,程序将变量start、n、bits和bitsize初始化为0,变量end初始化为33,escapeencoded标志设定为false。变量start和end是count数组的索引;变量bitsize包括编码字位模式的大小;变量bits包括有编码字位模式;变量n是树数组的索引;escapeencoded标志表明换码字符何时已被编码。从框705到721,程序根据输入的参数,循环进行编码或解码。在框705到706中,程序循环调用dividecount程序。
dividecount程序的详细说明见下文。dividecount程序返回变量start和end来限定“0”分支,与“1”分支有关的数据进栈。在框705中,如果变量start等于变量end,则识别编码的叶,从框707继续,否则程序从706继续。在框706中,程序调用dividecount程序,并循环返回框705。在框707中,如果变量bitsize大于16,那么程序将从框711继续,否则程序从框708继续。因为bitpattern数组为16位,超过16位的编码作为转码编码压缩和处理。在框708中,如果是压缩处理,那么程序从框709继续,否则从框710继续。框709中,程序设定数组条目value【start】中符号的编码字位模式。程序设置数组条目size【start】等于变量bitsize,并设置数组条目bitpattern【start】等于变量bits。在框710中,程序设置数组项tree【n】等于数组条目value【start】,表明为叶结点,增加变量n,为数组tree的下一条目加索引。在框711中,如果是压缩处理,那么程序从框712继续,否则从框713继续。框712中,程序设置数组条目size【start】等于0,表明对应条目的delta值未编码。-在框713中,程序设置数组项tree【n】,表明无编码和叶结点,增加变量n,为数组tree的下一条目加索引。在框714中,如果数组条目value【start】等于换码符号,那么程序设置变量escapeencoded为true。变量escapeencoded负责跟踪换码符号是否已经被编码。换码符号必须编码。程序设置换码符号的频率计数,以便确保其编码不大于16位,并已编码完毕。在框716中,如果堆栈为空,程序将从框722继续,否则程序将从框717继续,在框717中,程序将弹出堆栈。在框718中,如果是压缩处理,那么程序从框719继续,否则从框721继续。在框719中,程序根据出栈值设置变量start、end、total、和bitsize的值。在框720中,程序用1左移(16减去变量bitsize次数)位对变量bits进行按位“或”操作,这将设置变量bits中的一个位来表明为“1”编码,并循环返回框705。在框722中,如果变量escapeencoded等于true,那么程序返回,否则程序从框723继续。换码字符必须编码。在框723中,程序设置数组条目countivalue【16+escape】】为高频率,以便换码符号将被编码,然后程序循环返回,重新开始adapt程序。
图8-1和图8-2是dividecount例程流程图。dividecount程序基于条目的总数,将count数组分为从以变量start为索引的项,到以变量end为索引的条目。dividecount程序重置变量end以便界定“0”分支,并将数据入栈来界定“1”分支。在框801中,程序增加bitsize的值,bitsize包括有编码字位模式的大小。在框802中,如果变量bitsize大于16,那么程序从框814继续,否则程序从框803继续。如上所述,如果编码位大小大于16,那么对应的符号未编码。从框803到807,程序将count数组中,从变量start指明的条目开始的项相加,直到总和接近变量total的一半,变量total包括有count数组中从变量start指明的条目到变量end指明的项之间各条目的总和。在框803中,程度将索引i初始化为变量start的值,变量a设置为0。索引i步进通过count数组,变量a包括有count数组中从变量start指明的条目开始到索引i指明的条目之间各项的总和。在框804中,如果索引i小于变量end,且变量a乘2加数组条目count【i】小于变量total,那么说明程序的步骤并非在所有项的中间计数点,程序从框805继续,否则程序从框806继续。在框805中,程序将数组条目count【i】与变量a相加,索引i加1,循环到框804。在框806和807中,程序确保变量a的设置和索引i增加。在框806中,如果索引i等于变量start,那么程序将从框807继续,否则程序从框808继续。在框807中,程序设置变量a等于count【i】,索引i加1。在框808中,程序设置了结构stack中的变量。程度设置stack。start等于索引i,stack。end等于变量end,stack。total等于变量total减去变量a,以及stack。bitsize等于变量bitsize。结构stack中包含处理“1”分支的数据。在框809中,程序设置变量total等于变量a,索引i的变量end减去1.变量start、end、total、和bitsize包含处理“0”分支的数据。在框810中,如果是压缩处理,那么程序从框811继续,否则从框812继续。在框811中,程序用1的补码左移(16减去变量bitsize)位对变量bits进行按位“与”操作,这将设置bits中的位为0,表明为“0”编码。在框812中,程序设置stack.n等于变量n,变量n加1,再加1。变量n的增加为tree数组增加了一个节点。stack.n设定跟踪“1”分支,以便“1”分支的节点增加时,为当前的节点增加偏移量。在框813中,程序将数据送入栈中并返回。在框814中,如果是压缩处理,那么程序从框815继续,否则从框817继续。在框815和816中,由于字位模式将大于16,程序将size数组中介于变量start和end索引之间的项清零。count数组数值为0时表明无对应符号的编码。在框815中,如果变量end大于变量start,那么程序从框816继续,否则完成清零,程序返回。在框816中,程序设置数组条目size[end]等于0,变量end加1,循环返回框815。在框817中,由于字位模式将大于16,因此程度设置变量end等于变量start并返回。
图9是outrun例程流程图。outrun程序接收一个rundelta(行程delta)值、run计数、输出编码run数据,存入数组destination。在框901中,如果变量lastdelta的绝对值大于16,或数组项size【ivalue【16+lastdelta】】乘以变量runcount大于变量minrunsize,那么run(行程)就作为run编码,程序从框905继续,否则程序从框902继续。从框902到904,程序输出变量lastdelta到destination,次数由变量runcount指明。框902中,如果变量runcount等于0,则输出完成,程序返回,否则程序从框903继续。
在框903中,程序调用outvalue程序来输出变量lastdelta的值。在框904中,例程减少一个“runcount”变量并循环至框902中。在框905中,程序将数组条目bitpattem【ivalue【16-escape】】输出到数组destination,此项中包含有换码符号的编码。在框906中,程序增加数组条目count【ivalue【16+escape】】的值,以便跟踪换码符号的使用频率。在框907中,程序输出“11”,表示是一个编码run。在框908中,程序调用outvalue程序输出变量runcount减2,此值为run的长度(行程长度)。在框909中程序调用outvalue程序输出变量lastdelta,此值为rundelta值,然后程序返回。
图10是outvalue例程流程图。程序outvalue接收值,然后输出编码值到数组destination。在框1001中,如果变量value的绝对值大于16,那么此值无法编码,程序从框1005继续,否则程序从框1002继续。在框1002中,如果数组条目sizefiva-lue【16+value】】大于0,那么此值可以编码,程序从框1003继续,否则程序从框1005继续。在框1003中,程序将数组条目bitpattem【ivalue【16+value】】输出到数组destination,其包含变量value中的编码值。在框1004中,程序增加数组条目count【ivalue【16+-value】】的值,以便跟踪增值数值的频率和程序的返回。从框1005到1011中,程序输出范围在—16到+16之外的值。在框1005中,程序将数组条目bitpattem【ivalue【16+escape】】输出到数组destination,此项中包含有换码符号的编码。在框1006中,程序增加数组条目count-【ivalue【16+escape】】的值,以便跟踪换码符号的使用频率。在框1007中,如果变量value大于127或小于—128,那么value不适合8位,程序从框1008继续,否则程序从框1010继续。在框1008中,程序输出“10”来表明后续的16位包含有数值。在框1009中,程序输出16位的变量value,然后返回。在框1010中,程序输出“0”来表明后续的8位包含有数值。在框1011中,程序输出8位的变量value,然后返回。
图11是解压缩例程流程图。“解压缩”例程输入压缩源数据并输出压缩后的原数据。输入到“解压缩”例程中的参数分别为“源”数组、“计数”count,以及“数组”value。例程返回至“destination”数组、“数组”count,以及“数组”value。解压缩程序首先通过调用adapt程序来产生一个解码树,解码树保存在tree数组中。之后,“解压缩”例程在首次发起进程时将“count”数组设为零。清空默认频率计数,并初始化实际频率计数数组。解压缩程序调用getrun程序取回下一个数据,getrun程序返回一个delta值和一个run计数。然后解压缩程序使用delta值建立destination数组项。在框1101中,程序调用adapt程序来生成解码树,adapt程序返回tree数组。在框1102中,如果是压缩处理,那么程序从框1103继续,否则从框1104继续。在框1103中,程序将数组count中的每一项设置为0,如上文compress程序的说明。在框1104中,程序设置数组条目destination【0】等于数组项sourcefl],设定初始值。程序还将索引i设置为0。索引i为destination数组的索引。在框1105中,如果数组source中所有的数据都已被处理,那么程序返回,否则程序从框1106继续。在框1106中,程序调用getrun程序,取得下一个delta值和run计数。从框1107到1110,程序循环解压缩run中的数据。在框1107中,如果变量“runcount”等于0,那么意味着运算得到解压缩,且例程将在框1105中继续执行,否则例程会在框1108中继续执行。在框1108中,程序增加索引i的值。在框1109中,程序设置数组条目destina-tion【i】等于数组项destination【—1】减去delta的值,来解压缩数据。在框1110中,变量runcount减1,循环返回1107来确定是否所有的压缩数据已被解压缩。
图12是getrun例程流程图。getrun程序解码delta值(或下一个delta值)的下一个run,并返回delta值和run计数。在框1201中,程序调用decode程序,decode程序返回来自source数组的下一个解码值。在框1202中,例行程序将变量runcount设置为1。在框1203至1207中,例行程序识别并解码8位和16位增量值。在框1203中,如果变量value是换码符号,则例行程序在框1204继续,否则变量value包含增量值,并且例行程序返回。-在框1204中,如果数组source中的下一位是0,则8位增量值被编码,并且例行程序在框1205继续,否则例行程序在框1206继续。在框1205中,例行程序将变量value设置为数组source中的下一个8位,并且例行程序返回。在框1206中,如果数组source中的下一个位是0,则编码16位增量值,并且例行程序在框1207继续,否则运行被编码并且例行程序在框1208继续。在框1207中,例行程序将变量value设置为数组source中的下一个16位,并且例行程序返回。在框1208中,例行程序调用例行程序解码运行计数。在框1209中,如果例行程序decode返回值是换码符号,则运行计数以8位或16位编码,并且例行程序在框1210中继续,否则运行计数不被编码,并且例行程序在框1213中继续。解码运行计数加了2以指示实际游程。在框1210中,如果数组source中的下一个位是0,则运行数值以8位进行增量,并且例行程序在框1212继续,否则运行以16位被编码并且例行程序在框1211继续。在框1211中,例行程序将变量runcount设置为数组source中的下一个16位。在框1212中,例行程序将变量runcount设置为数组source中的下一个8位。在框1213中,例行程序调用例行程序decode来解码运行值。在框1214中,如果例行程序decode返回值是换码符号,则运行计数以8位或16位编码,并且例行程序在框1215中继续,否则运行计数不被编码,并且例行程序返回。在框1215中,如果数组source中的下一个位是0,则运行数值以8位进行解码,并且例行程序在框1217继续,否则运行数值以16位被编码并且例行程序在框1216继续。在框1216中,例行程序将变量value设置为数组source中的下一个16位,并且程序返回。在框1217中,例行程序将变量value设置为数组source中的下一个8位,并且例行程序返回。
图13是解码例程流程图。例行程序解码使用数组树在数组source中为下一个编码符号返回符号值。在框1301到1306中,例行程序在数组树中搜索叶节点。在框1301中,例程设置索引pto0;索引p指示数组树。在框1302中,例行程序从数组“源”获得下一位。在框1303中,如果该位是1,则指示“1”分支,并且例行程序在框1304继续,否则指示“0”分支,并且例行程序在框1305继续。在框1304中,例行程序添加数组入口树【p】。偏移到索引p跟随“1”分支。在框1305中,例行程序将索引p递增为跟随“0”分支。在框1306中,如果数组入口树【p】是叶,则该值被解码,并且例行程序在框1307继续,否则例行程序循环到框1302以获得下一位。在框1307中,例程将变量value设置为数组入口树【p】。数值。在框1308中,例行程序增量数组条目count【ivalue【16+值】】跟踪增量值频率,并且例行程序返回。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定,对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 还没有人留言评论。精彩留言会获得点赞!