LDPC码的编码方法与流程
本申请是原案的分案申请,原案的申请号201410458597.4,申请日2014年9月10日,发明创造名称“ldpc码的编码方法”。
本发明涉及编码方法领域,特别涉及一种ldpc码的编码方法。
背景技术:
低密度奇偶校验码字(lowdensityparitycheck,ldpc)根据其结构主要可以分为两类,一类是随机的码字,最经典的当属mackay码,他还有专门的网页给出他的各种码字(mackay1999)(richardson2001)(luby2001)(richardsonandurbanke2001);另外一类是基于代数组合结构(combinatorial)来设计的码字。随机码字能够非常好的逼近香农极限,但是由于‘1’分布的随机性,导致编码器的设计和译码器的设计并不具有并行或者规律性可遵循,所以不适合需要具备一定吞吐量系统,因此也就没有被广泛应用了。
而基于结构化的ldpc码字的出现很好的解决了这方面的问题,这其中,有一类基于有限域(finitegeometry)设计的码字具有很好的性能(y.kouands.lin2001),但是这类码字的缺点是由于其h矩阵密度比较高(大的行重列重),所以当使用基于置信传播的一类算法时,复杂度非常高。而另一类准循环码字(quasi-cyclicldpc,qc-ldpc)是一类非常重要的基于代数组合构造的码字。qc-ldpc码字主要的构造是基于准循环的单位子矩阵。(j.l.fan2000)(r.m.tanner2001)(r.m.tanner2001)(t.okamura2003)(r.m.tanner2004)这种准循环的单位子矩阵结构非常适合实现并行操作的硬件,比如译码实现并行度大、进而高吞吐率的译码器。传统的这种qc-ldpc码字尽管适合并行度高的译码器实现,提高了吞吐率,但是通过逆向方法得到了qc结构的生成矩阵可能并不稀疏,或者就算稀疏,其用生成矩阵来编码得到校验比特并不是显然的,要通过求线性方程组来获得,因此传统的qc-ldpc码字的编码器还是相对复杂的。为了解决这个问题,学者zhang和ryan首先提出的结构化的重复累积码(structuredirregularrepeataccumulatorcode,s-ira)ldpc码字(zhangandryan2006),该结构在适合高并行译码器的实现的同时,可以以非常简便高效的方法来完成编码。
该种码字结构有如下特点,信息比特所对应的矩阵部分由准循环子矩阵组成,而校验比特所对应的矩阵部分是由双对角阵组成的。
目前s-ira码字已经被广泛应用在各大通信标准中,主要包括,欧洲第二代数字广播电视传输标准dvb系列(etsi,2006,dvbt22009,dvb-c22009,dvb-ngh2012);ieee802.11n无线局域网标准(ieee802.11n2009);ieee802.11e无线广域网标准(ieee802.16e2006);中国数字电视地面传输标准(dttb)(gb20600-2006);移动多媒体广播(cmmb2006);北美ccsds的近地深空通信系统(ccsds2007);以及一些磁盘存储设备的标准等等。
分析现在最新标准中所采用的结构化的重复累加码,我们发现在中高码率,该种类的ldpc码字可以借助于密度进化理论或者外信息图(exit)来设计,并展现出逼近香浓限的性能。但是在低码率,比如1/5,1/4,1/3,1/2等码率,采用结构化的重复累加结构并不能很好的逼近香浓限。
技术实现要素:
本发明解决的问题是现有技术中,采用结构化的重复累加结构并不能很好的逼近香浓限。
为解决上述问题,本发明实施例提供一种ldpc码的编码方法,包括如下步骤:
基于信源编码后的比特流得到ldpc矩阵中的信息比特,并设定所述ldpc矩阵中校验部分的大小以及循环子阵的大小;其中,所述校验部分包括第一校验部分和第二校验部分;
初始化所述校验部分所对应的各校验比特;
依照所述循环子阵的大小将所述信息比特进行分组以得到多个信息比特组,其中每个信息比特组对应预设码表中的一行校验比特地址;
将各个信息比特组中的第一个信息比特与预设码表中对应的一行校验比特地址依照第一累加方式对校验比特进行处理,并将各个信息比特组中的其他信息比特根据对应的校验比特地址依照第二累加方式对校验比特进行处理,以得到经过累加处理后的校验部分;
针对经过累加处理后的校验部分中属于第一校验部分的校验比特依照第一处理方式进行处理,以得到编码后的第一校验部分;将编码后的第一校验部分按照循环子阵的大小进行分组,以得到多个校验比特组,其中每个校验比特组对应预设码表中属于所述第二校验部分的一行校验比特地址;
将各个校验比特组中的第一个校验比特与预设码表中属于所述第二校验部分的一行校验比特地址依照第一累加方式对第二校验部分进行处理,并将各个校验比特组中的其他校验比特对第二校验部分的该行校验比特地址依照第二累加方式对该第二校验部分进行处理,以得到编码后的第二校验部分;
基于所述编码后的第一校验部分和编码后的第二校验部分组成编码后的校验部分。
可选的,所述信息比特的个数为k、所述循环子阵的大小为q*q;所述依照所述循环子阵的大小将所述信息比特进行分组以得到多个信息比特组包括:设置所述信息比特为i=(λ0,λ1,...,λk-1);将所述信息比特按顺序以q个比特为一组进行分组以得到多个信息比特组。
可选的,所述将各个信息比特组中的第一个信息比特与预设码表中对应的一行校验比特地址依照第一累加方式对校验比特进行处理包括:
依序将每个信息比特组中的第一个信息比特分别对预设码表中对应行数字为地址的校验比特进行模2累加处理。
可选的,所述将各个校验比特组中的第一个校验比特与预设码表中属于所述第二校验部分的一行校验比特地址依照第一累加方式对第二校验部分进行处理包括:
依序将每个校验比特组中的第一个校验比特分别对预设码表中对应行数字为地址的属于第二校验部分的校验比特进行模2累加处理。
可选的,所述将各个信息比特组中的其他信息比特与预设码表依照第二累加方式进行处理包括:
将每个信息比特组中的其他信息比特分别对按照y1为地址的校验比特进行累加处理,其中,y1的表达式为:
其中,x1是指与每个信息比特组中第一个信息比特相关的校验比特对应的地址、q1为第一校验的大小与循环矩阵的大小的比值、q2为第二校验部分的大小与循环矩阵的大小的比值、m1表示第一校验部分的校验比特的数目、m2表示第二校验部分的校验比特的数目、i表示信息比特组中除了第一个信息比特之外的信息比特的序号,序号的数值范围为1到(q-1)之间。
可选的,所述将各个校验比特组中的其他校验比特根据对应的校验比特地址依照第二累加方式对第二校验部分进行处理包括:
将每个校验比特组中的其他校验比特分别对按照y2为地址的校验比特进行累加处理,其中,y2的表达式为:
其中,x2是指与每个校验比特组中第一个校验比特相关的校验比特对应的地址、q1为第一校验部分的大小与循环矩阵的大小的比值、q2为第二校验部分的大小与循环矩阵的大小的比值、m1表示第一校验部分的校验比特的数目(大小)、m2表示第二校验部分的校验比特的数目(大小)、i表示每个校验比特组中除了第一个校验比特(序号为0)之外的校验比特的序号,序号的数值范围为1到(q-1)之间。
可选的,所述预设码表的码率为1/5;码长n=57600;校验部分的大小m=46080,信息比特k=11520,其中第一校验部分的大小为m1=1600、第二校验部分的大小为m2=44480;循环矩阵的大小q=320,q1=m1/q=5;q2=m2/q=139;该预设码表为:
其中,属于所述第二校验部分的校验比特地址为所述预设码表中的最后q1行,其中q1根据第一校验部分的大小与循环矩阵的大小的比值来确定。
可选的,所述针对经过累加处理后的校验部分中属于第一校验部分的校验比特依照第一处理方式进行处理,以得到编码后的第一校验部分是指:
对于经过累加处理后的校验部分中属于第一校验部分的校验比特依照公式进行处理。
与现有技术相比,本发明技术方案具有以下有益效果:
通过大量仿真模拟,发现本发明实施例提出的低码率的码字具有比现有最新标准中的同码率码字更接近香浓限的性能。
附图说明
图1是本发明的一种ldpc码的编码方法的具体实施方式的流程示意图;
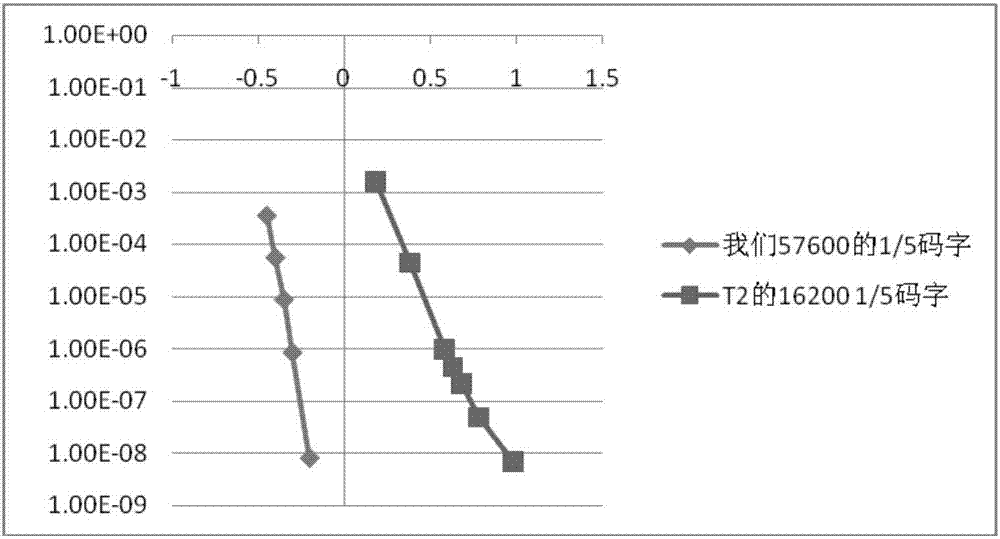
图2是采用本发明的一种ldpc码的编码方法获得的码字与采用dvb-t2标准的编码方法获得的码字的性能对比示意图。
具体实施方式
发明人发现现有技术中,采用结构化的重复累加结构并不能很好的逼近香浓限。
针对上述问题,发明人经过研究,提供了一种ldpc码的编码方法,通过大量仿真模拟,发现本发明实施例提出的低码率的码字具有比现有最新标准中的同码率码字更接近香浓限的性能。
为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。
如图1所示的是本发明的一种ldpc码的编码方法的具体实施方式的流程示意图。参考图1,该编码方法包括如下步骤:
步骤s1:基于信源编码后的比特流得到ldpc矩阵中的信息比特,并设定所述ldpc矩阵中校验部分的大小以及循环子阵的大小;其中,所述校验部分包括第一校验部分和第二校验部分;
步骤s2:初始化所述校验部分所对应的各校验比特;
步骤s3:依照所述循环子阵的大小将所述信息比特进行分组以得到多个信息比特组,其中每个信息比特组对应预设码表中的一行校验比特地址;
步骤s4:将各个信息比特组中的第一个信息比特与预设码表中该信息比特组对应的一行校验比特地址依照第一累加方式对校验比特进行处理,并将各个信息比特组中的其他信息比特根据对应的校验比特地址依照第二累加方式对校验比特进行处理,以得到经过累加处理后的校验部分;
步骤s5:针对经过累加处理后的校验部分中属于第一校验部分的校验比特依照第一处理方式进行处理,以得到编码后的第一校验部分;
步骤s6:将编码后的第一校验部分按照循环子阵的大小进行分组,以得到多个校验比特组,其中每个校验比特组对应预设码表中属于所述第二校验部分的一行校验比特地址;
步骤s7:将各个校验比特组中的第一个校验比特与预设码表中属于所述第二校验部分的一行校验比特地址依照第一累加方式对第二校验部分进行处理,并将各个校验比特组中的其他校验比特根据对应的校验比特地址依照第二累加方式对第二校验部分进行处理,以得到编码后的第二校验部分;
步骤s8:基于所述编码后的第一校验部分和编码后的第二校验部分组成编码后的校验部分。
下面结合具体实施例对上述编码方法的实施方式进行描述。
如所述步骤s1所述,基于信源编码后的比特流得到ldpc矩阵中的信息比特,并设定所述ldpc矩阵中校验部分的大小以及循环子阵的大小;其中,所述校验部分包括第一校验部分和第二校验部分。
所述ldpc矩阵包括信息比特部分和校验部分。
令ldpc的码字为c=(λ0,λ1,...,λk-1,p0,p1,...,pm,...,pm-1);其中,(λ0,λ1,...,λk-1)为信息比特,是已知的{1,0}序列。(p0,p1,p2,...,pm-1)为校验比特,为待计算的比特。
在本实施例中,所述ldpc矩阵中校验部分的校验比特有m个,包括第一校验部分m1和第二校验部分m2,即m=m1+m2。循环子阵的大小为q*q。通常所述校验部分位于所述低密度奇偶校验矩阵的右边部分。
如步骤s2所述,初始化所述校验部分所对应的各校验比特。在本实施例中,所述校验部分所对应的各校验比特的初始值为0。
如步骤s3所述,依照所述循环子阵的大小将所述信息比特进行分组以得到多个信息比特组,其中每个信息比特组对应预设码表中的一行校验比特地址。
本步骤包括:
1)设置所述信息比特为i=(λ0,λ1,...,λk-1);
2)将所述信息比特按顺序以q个比特为一组进行分组以得到多个信息比特组。
如步骤s4所述,将各个信息比特组中的第一个信息比特与预设码表中对应的一行校验比特地址依照第一累加方式对校验比特进行处理,并将各个信息比特组中的其他信息比特根据对应的校验比特地址依照第二累加方式对校验比特进行处理,以得到经过累加处理后的校验部分。
具体地,所述将各个信息比特组中的第一个信息比特与预设码表中对应的一行校验比特地址依照第一累加方式对校验比特进行处理包括:
依序将每个信息比特组中的第一个信息比特分别对预设码表中对应行数字为地址的校验比特进行模2累加处理。
所述将各个信息比特组中的其他信息比特与预设码表依照第二累加方式进行处理包括:
将每个信息比特组中的其他信息比特分别对按照y1为地址的校验比特进行累加处理,其中,y1的表达式为:
其中,x1是指与每个信息比特组中第一个信息比特相关的校验比特对应的地址、即为该组信息比特对应的预设码表中的一行校验比特地址,q1为第一校验的大小与循环矩阵的大小的比值、q2为第二校验部分的大小与循环矩阵的大小的比值、m1表示第一校验部分的校验比特的数目、m2表示第二校验部分的校验比特的数目、i表示信息比特组中除了第一个信息比特之外的其他信息的序号,值为1到(q-1)之间。
所述预设码表的码率为1/5;码长n=57600;信息比特k=11520,校验部分的大小m=46080,其中第一校验部分的大小为m1=1600、第二校验部分的大小为m2=44480;循环矩阵的大小q=320,q1=m1/q=5;q2=m2/q=139;该预设码表为:
其中,属于所述第二校验部分的校验比特地址为所述预设码表中的最后q1行,其中q1根据第一校验部分的大小与循环矩阵的大小的比值来确定。
如步骤s5所述,针对经过累加处理后的校验部分中属于第一校验部分的校验比特依照第一处理方式进行处理,以得到编码后的第一校验部分。
具体地,本步骤是指:对于经过累加处理后的校验部分中属于第一校验部分的校验比特依照公式
如步骤s6所述,将编码后的第一校验部分按照循环子阵的大小进行分组,以得到多个校验比特组,其中每个校验比特组对应预设码表中属于所述第二校验部分的一行校验比特地址。
具体地,本步骤类似于上述步骤s3中对信息比特进行分组以得到多个信息比特组的过程。需要注意的是,得到的每个校验比特组对应预设码表中属于所述第二校验部分的一行校验比特地址。
例如,参考上述预设码表,该码表中最后5行(即第一校验部分的大小m1=1600与循环子阵的大小q=320的比值)为属于所述第二校验部分的校验比特地址。
如步骤s7所述,将各个校验比特组中的第一个校验比特与预设码表中属于所述第二校验部分的一行校验比特地址依照第一累加方式对第二校验部分进行处理,并将各个校验比特组中的其他校验比特根据对应的校验比特地址依照第二累加方式对第二校验部分进行处理,以得到编码后的第二校验部分。
具体地,将各个校验比特组中的第一个校验比特与预设码表中属于所述第二校验部分的一行校验比特地址依照第一累加方式对第二校验部分进行处理包括:依序将每个校验比特组中的第一个校验比特分别对预设码表中对应行数字为地址的属于第二校验部分的校验比特进行模2累加处理。
所述将各个校验比特组中的其他校验比特根据对应的校验比特地址依照第二累加方式对第二校验部分进行处理包括:
将每个校验比特组中的其他校验比特分别对按照y2为地址的校验比特进行累加处理,其中,y2的表达式为:
其中,x2是指与每个校验比特组中第一个校验比特相关的校验比特对应的地址、q1为第一校验部分的大小与循环矩阵的大小的比值、q2为第二校验部分的大小与循环矩阵的大小的比值、m1表示第一校验部分的校验比特的数目、m2表示第二校验部分的校验比特的数目、i表示每个校验比特组中除了第一个校验比特之外的校验比特的序号,序号的数值范围为1到(q-1)之间。
如步骤s8所述,基于所述编码后的第一校验部分和编码后的第二校验部分组成编码后的校验部分。
基于上述ldpc码的编码方法,发明人经过提供了一个具体实例,并进行仿真模拟。该具体实例如下:
将信源编码后的比特流,拆分为一个个信息块,每个信息块由k个信息比特组成,表示为i=(λ0,λ1,...,λk-1)。
ldpc编码就是要根据i=(λ0,λ1,...,λk-1)生成(m1+m2)个校验比特
即得到n个比特的码字
首先,根据输入的信息比特流初始化λi,i=0,1,...,k-1。按全零方式初始化pj=0,j=0,1,...,m1+m2-1。
对信息比特λ0,对以码表1(即上文所述的预设码表)中的第一行数字为地址的校验比特进行累加,由于其第一行数字为:
71594157587001203012798188281903119441231402417727151285823518939097
对于接下来的(q-1)(例如,q=320)个信息比特,λm,i=1,2,....,q-1,将每个信息比特分别与按照如下y为地址的校验比特进行累加:
其中,x是指与λ0相关的校验位地址,参考码表1,x即码表1中第一行的数字:
71594157587001203012798188281903119441231402417727151285823518939097
其中,
例如,
对于第q个信息比特λq(即第二个信息比特组的第一个信息比特),按照码表1中的第二行数字地址对校验比特进行累加。同样的对于第二信息比特组中其他的(q-1)个信息比特继续按照图1中所述步骤4中的公式对校验比特进行累加。需要说明的是,此时所述步骤4中的公式中,x即码表1中第二行的数字地址。
同理,对于第2q、3q、4q…iq…个信息比特,分别按照码表1中的第3行、第4行、第5行、…、第(i+1)行的数字地址对校验比特进行累加,而各个信息比特组中的其他(q-1)个信息比特分别按照上述步骤4中的公式对校验比特进行累加。类似的,此时所述步骤4中的公式中的x对应的是当前第iq个信息比特所对应的码表1中的行,比如第iq个信息比特之后的(q-1)个比特,其采用上述步骤4中的公式时,对应的x的地址为码表中的第(i+1)行。
然后,利用如下公式对经过累加处理后的第一部分校验比特进行处理,以得到编码后的第一部分校验比特。
之后将编码后的第一部分校验比特p=(p0,p1,...,pm1-1)按照q比特为一组进行分组,得到q1组校验比特,q1=5。根据本实施例码表给出的信息q1=m1/q=5。
该5组第一部分校验比特按顺序分别对应了码表中的最后5行数字。该最后5行数字对应着第二部分校验比特的地址。
然后将每个校验比特组中的第一个校验比特按照该组对应的码表中的一行地址,对第二部分校验比特进行模2累加。
举例来说,第一组校验比特为p=(p0,p1,...,pq-1),其对应数字:
64431178311893186301883919760260572628630709367203681736938
然后,拿p0对以该行数字为地址的属于第二校验部分的校验比特进行累加:
64431178311893186301883919760260572628630709367203681736938
然后对于第一组检验比特中除去第一个比特之外的比特按照同样的如下方式:
对以y为地址的属于第二校验部分的比特进行模2累加。其中,这里的x是指与p0相关的校验位地址,参考码表,x即码表1中的倒数第五行数字:
64431178311893186301883919760260572628630709367203681736938
以p1为例,这时候i=1,
对剩下的(p2,p3,...,pq-1),分别令i=2,3,…,q-1,代入公式,得到y,分别按照同样的方式对属于第二校验部分的校验比特进行模2累加即可。
同样的对于第2组,第3、4、5组校验比特,依照同样的方式对属于第二校验部分的校验比特进行模2累加,不同的只是换了一行地址而已。举例来说,第2组校验比特对应的属于第二校验部分的地址为:
153392067920789275262773528656349533518239605456164571345834
第3组校验比特对应的属于第二校验部分的地址为:
40211003210129102502423529575296853642236631375524384944078
第4组校验特比特对应的属于第二校验部分的地址为:
196882658494129171892819025191463313138471385814531845527
第5组校验比特对应的属于第二校验部分的地址为:
28872997973499431086417161173902181327824279212804242027
所有的操作完成之后即最终得到了编码后的
如图2所示的是采用本发明的一种ldpc码的编码方法获得的码字与采用dvb-t2标准的编码方法获得的码字的性能对比示意图。参考图2,采用本发明实施例提供的1/5码率的码字性能比dvb_t2标准中的1/5码率的码字性能好1db。虽然,本实施例中,码字的码长要比dvb_t2的码字的码长要长,但是,因码长带来的性能增益只有0.2db左右,所以在忽略码长因素的情况下,采用本发明实施例提供的1/5码率的码字的性能也比dvb_t2标准中的1/5码率的码字的性能要好0.8db。
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!