视频编码中的语法的二进制化和上下文自适应编码的方法和装置与流程
本申请要求下列申请的优先权:2014年6月20日递交的申请号为62/014,970的美国临时案;2014年6月26日递交的申请号为62/017,401的美国临时案;2014年7月3日递交的申请号62/020,518的美国临时案;以及2014年7月7日递交的申请号为62/021,287的美国临时案。在此合并参考这些申请案的申请标的。
技术领域
本发明有关于与视频编码相关的语法的熵编码。更具体地,本发明涉及与视频编码相关的语法的二进制化(binarization)和上下文自适应编码(context-adaptive coding)的技术。
背景技术:
高效率视频编码(High Efficiency Video Coding,HEVC)是近年来已经开发出来的新的编码标准。在高效率视频编码系统中,H.264/AVC的固定大小宏块被称为编码单元(coding unit,编码单元)的灵活块(flexible block)所替换。编码单元中的像素共享相同的编码参数以提高编码效率。编码单元可以从最大编码单元(largest CU,LCU)开始,其在HEVC中也被称为编码树单元(coded tree unit,CTU)。除了编码单元的概念,预测单元(PU)的概念也引入到了HEVC中。一旦编码单元层次树(CU hierarchical tree)的拆分(splitting)完成,则根据预测类型和预测单元分区(PU partition)将每个叶编码单元(leaf CU)进一步拆分成一个或多个预测单元。
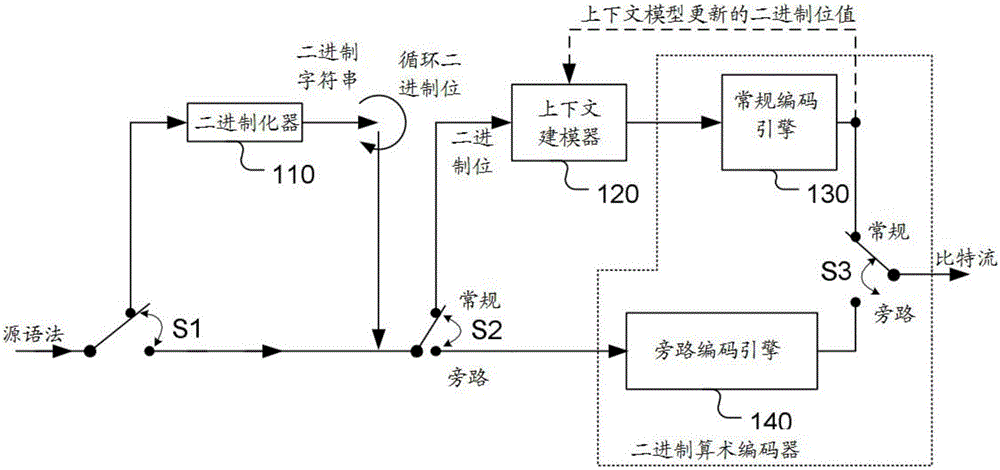
基于上下文的自适应二进制算术编码(Context-based adaptive binary arithmetic coding,CABAC)是已经广泛用于诸如H.264和HEVC的高级视频编码中的高效熵编码工具。举例来说,HEVC标准的各种语法元素是以CABAC模式来编码,其中基于与基础语法元素相关的上下文,来自适应地将熵编码应用于二进制化语法元素。图1为CABAC过程的示例性框图。由于CABAC引擎中的算术编码器只能对二进制符号值(binary symbol value)进行编码,因此CABAC过程需要使用二进制化器(110)来将语法元素的值转换为二进制字符串(binary string)。转换过程通常被称为二进制化。在编码过程中,从用于不同上下文的编码符号逐渐建立概率模型。上下文建模器(context modeler)(120)用于建模目的。在基于正常上下文的编码期间,使用对应于二进制算术编码器的常规编码引擎(130)。用于编码下一个二进制符号的建模上下文的选择,可以通过编码信息来确定。也可以在没有上下文建模阶段的情况下对符号进行编码,并且为了降低复杂度,而采用通常被称为旁路模式的相等概率分布(equal probability distribution)。对于旁路符号,可以使用旁路编码引擎(140)。如图1所示,开关(S1,S2和S3)用于在常规CABA模式和旁路模式之间引导数据流。当选择常规CABAC模式时,开关翻转到上触点。当选择旁路模式时,开关被翻转到下触点。如图1所示。
JCT标准化机构目前正在开发HEVC屏幕内容编码(screen content coding,SCC)扩展。与具有连续色调的常规自然视频相反,屏幕内容视频通常包含少量主导颜色(pilot colors)以及锐利边缘和边界。目前正在调查研究几种新工具,以便将来可能采用HEVC SCC扩展。
在HEVC范围扩展的早期开发期间,已经公开了若干建议来解决基于调色板的编码。例如,在JCTVC-N0247(Guo et al.,“RCE3:Results of Test 3.1on Palette Mode for Screen Content Coding”,Joint Collaborative Team on Video Coding(JCT-VC)of ITU-T SG 16WP 3and ISO/IEC JTC 1/SC 29/WG 11,14th Meeting:Vienna,AT,25July–2Aug.2013Do编码单元ment:JCTVC-N0247)和JCTVC-O0218(Guo et al.,“Evaluation of Palette Mode Coding on HM-12.0+RExt-4.1”,Joint Collaborative Team on Video Coding(JCT-VC)of ITU-T SG 16WP 3and ISO/IEC JTC 1/SC 29/WG 11,15th Meeting:Geneva,CH,23Oct.–1,Nov.2013,Do编码单元ment:JCTVC-O0218)中公开了调色板预测和共享技术。在JCTVC-N0247中,每个颜色分量(color component)的调色板被构造和发送。可以从其左边相邻的编码单元来预测(或共享)调色板以减小比特率。然后,使用它们的调色板索引来对给定块内的所有像素进行编码。根据JCTVC-N0247的编码处理的示例如下所示。
1.调色板的传输:首先传输颜色索引表大小,然后是调色板元素。
2.像素值的传输:编码单元中的像素以光栅扫描顺序编码。对于一个或多个像素的每个组,首先发送用于基于游程的模式(run-based mode)的标志,以指示是否正在使用“索引”模式或“复制上方”模式。
2.1 Index_Mode:在Index_Mode中,首先发信(signal)调色板索引,然后是表示游程值的“palette_run”(例如,M)。游程值指示总共M个样本都使用Index_Mode来编码。对于当前位置和随后的M个位置,不需要发送进一步的信息,因为它们具有与在比特流中发信的相同的调色板索引。调色板索引(例如,i)也可以由所有三个颜色分量共享,这意味着,对于YUV色彩空间的情况,重构的像素值是(Y,U,V)=(paletteY[i],paletteU[i],paletteV[i])。
2.2 Copy_Above_Mode:在Copy_Above_Mode中,发送值“copy_run”(例如,N),以指示对于随后的N个位置(包括当前位置),调色板索引与上方的行中的相应调色板索引相同。
3.残差(residue)的传输:在阶段2中传输的调色板索引被转换回像素值并且用作预测。使用HEVC残留编码(HEVC residual coding)来发送残差信息,并将残差信息添加到用于重构的预测中。
因此,期望开发用于进一步改善与在屏幕内容编码以及一般视频编码中的为调色板模式编码块而产生的语法元素相关的编码效率的方法。
技术实现要素:
公开了一种用于对在视频编码系统中产生的源符号进行熵编码和解码的方法和装置。根据本发明,首先确定当前符号值(current symbol value)的最高有效位索引和任何精细位。通过使用一元码或截断一元码来对与当前符号值的最高有效位索引相关的前缀部分进行二进制化,以生成第一二进制字符串。此外,如果存在任何精细位,则通过使用固定长度码或截断二进制码来对与当前符号值的一个或多个精细位相对应的后缀部分进行二进制化,来生成第二二进制字符串。如果存在第二二进制字符串,则使用上下文自适应二进制算术编码(CABAC)来对第一二进制字符串进行编码,并且使用CABAC来对第二二进制字符串进行编码。
前缀部分可以对应于最高有效位索引加1。此外,如果x大于0,则前缀部分可以等于(floor(log2(x)+1);并且如果x等于0,则前缀部分等于0,其中x表示当前符号值,floor(y)是输出小于或等于y的最大整数的floor函数,log2(x)是底数为2的log函数。如果二进制位具有小于或等于阈值T的二进制索引,则以常规CABAC模式编码第一二进制字符串的二进制未;如果二进制位具有大于阈值T的二进制指数,则以旁路模式进行编码。
在一个实施例中,当前源符号指示用于屏幕内容编码(SCC)的调色板模式编码块中的连续重复调色板索引的游程长度减去1。通过使用具有等于(floor(log2((MaxPaletteRun))+1)的最大值的截断一元码对前缀部分进行二进制化,来导出第一二进制字符串,其中MaxPaletteRun等于剩余的待编码像素的数量减1。通过使用具有等于(MaxPaletteRun-(1<<(palette_run_msb_id_plus1-1)))的最大值的截断二进制码对后缀部分进行二进制化,来导出第二二进制字符串,其中MaxPaletteRun等于当前编码单元中剩余的待编码像素的数量减1,并且palette_run_msb_id_plus1表示前缀部分的值。
CABAC以连续重复调色板索引的游程类型为条件,并且常规CABAC模式被应用于第一二进制字符串或第二二进制字符串的一个或多个二进制位。例如,当前源符号可以对应于语法Copy_Above_Mode(表示上方行中的连续第一索引的第一游程长度减去1),或者对应于语法Index_Mode(表示同一行中的连续第二索引的第二游程长度减去1)。在具有三个上下文的常规CABAC模式中,对具有二进制索引等于0的第一二进制字符串的二进制位进行编码。此外,如果调色板索引小于第一阈值T1,则可选择第一上下文;如果调色板索引大于或等于第一阈值T1并小于第二阈值T2,则可选择第二上下文;并且如果调色板索引大于或等于第二阈值T2,则可以选择第三上下文,其中第二阈值T2大于第一阈值T1。例如,第一阈值T1可以等于2,第二阈值T2可以等于4或8。
当前源符号还可以对应于二维有符号或无符号源向量(two-dimensional signed or unsigned source vector)的第一分量或第二分量的绝对值。此外,前缀部分在后缀部分和任何符号位(sign bit)之前被编码。
在本发明的另一实施例中,对于索引模式,确定具有与当前块的扫描顺序中的当前调色板索引相同的调色板索引的连续像素的数量。使用二进制化方法将连续像素的数量减1转换为二进制字符串。根据取决于当前调色板索引来自适应地选择的上下文,通过将常规CABAC模式应用于二进制字符串的至少一个二进制位,使用CABAC来对二进制字符串进行编码。本发明还公开了相应的解码处理。例如,解码器可以接收包括对应于索引模式的当前源符号的当前块的压缩数据的输入编码比特流。可以确定与当前游程模式相关的当前调色板索引。然后,根据取决于当前调色板索引来自适应地选择的上下文,通过将常规CABAC模式应用于二进制字符串的至少一个二进制位,使用上下文自适应二进制算术编码(CABAC)来对二进制字符串进行解码。使用二进制化方法将二进制字符串转换为游程长度值,游程长度值与具有和当前调色板索引相同的调色板索引的多个连续像素相关。游程长度值对应于连续像素的数量减去1。对于解码器侧,当前调色板索引可对应于来自输入编码比特流或重构调色板索引的解析的调色板索引。
附图说明
图1为上下文自适应二进制算术编码(CABAC)的示例性框图,其中源语法(source syntax)可以使用常规CABAC模式或旁路模式来自适应编码。
图2为根据本发明实施例的源符号(source symbols)的熵编码系统的示例性流程图,其中源符号在前缀部分和后缀部分中表示,并且前缀部分和后缀部分的二进制字符串使用CABAC来编码。
图3为根据本发明实施例的源符号的熵解码系统的示例性流程图,其中源符号在前缀部分和后缀部分中表示,并且前缀部分和后缀部分的二进制字符串使用CABAC来编码。
具体实施方式
以下描述为本发明的较佳实施例。以下实施例仅用来举例阐释本发明的技术特征,并非用以限定本发明。本发明的保护范围当视权利要求书所界定为准。
本发明公开了一种用于在诸如视频编码的源数据压缩系统中产生的源符号(source symbols)的通用熵编码方法。该方法表示与二进制形式的源符号相关的无符号数值(unsigned value),由二部分组成:最高有效位(most significant bits,MSB)部分和其值的精细位部分(refinement bits part)。为MSB部分中的每个成员分配一个索引。所得到的码字是前缀部分和后缀部分的级联(concatenation)。前缀部分与符号值(symbol value)的最高有效位索引相关。在一个实施例中,可以根据floor(log2(x))来确定MSB部分,其中x对应于与源符号相关的无符号数值,floor(y)是输出小于或等于y的最大整数的floor函数,以及log 2(x)是以底数为2的log函数。在该示例中,对应的MSB部分对于x=0将是无意义的。因此,引入表示MSB部分加上1的项,由msb_id_plus1来表示。MSB加一,无符号数值x的msb_id_plus1可以根据下列等式导出:
如果最大语法值是已知的,则前缀部分可以使用诸如一元码(unary code)或截断(truncated)一元码的可变长度码来编码。对于给定的符号值,后缀部分可以存在或可以不存在。如果msb_id_plus1>1,则后缀部分表示精细位,并且存在后缀部分。由refinement_bits来表示的精细位的值可以使用固定长度的二进制码或截断二进制码来二进制化。例如,如果最大语法值是已知的,精细位的值可以由具有字符串长度等于(msb_id_plus1-1)的字符串或者截断二进制码来表示。可以根据以下等式,基于解码的前缀部分(即,(msb_id_plus1-1))和解码的后缀部分(即,refinement_bits)来导出解码的语法值x:
表1为根据本发明的实施例包含的二进制化处理(binarization process)的对应于符号值0-31的码字二进制字符串(也称为二进制字符串)的示例。根据等式(1)导出msb_id_plus1值。精细位的长度根据(msb_id_plus1-1)来确定。可以通过对有符号符号值(signed symbol value)的绝对值加上符号信息(sign information)应用上述二进制化处理,根据本发明的二进制化处理也可以应用于有符号源符号(signed source symbols)。此外,可以通过对每个向量分量(vector component)使用二进制化处理,而将二进制化处理应用于诸如向量的多维源数据(multi-dimensional source data)。
表1
根据本发明,可以通过上下文自适应二进制算术编码(CABAC)来编码以获得二进制字符串(bin string),以代表msb_id_plus1。前缀部分可以使用更复杂的上下文建模方案来采用CABAC进行编码。根据本发明。可以使用较简单的上下文建模方案或旁路模式来对精细位和符号位(refinements and sign bits)进行编码。在一个实施例中,对于具有小于或等于阈值T的二进制索引值的二进制位(bins),在CABAC模式中对前缀二进制字符串进行编码,否则在旁路模式中编码。在一个实施例中,上下文选择是根据二进制索引。此外,具有相邻索引值的一些二进制位可以共享相同的上下文。在另一实施例中,可以根据比特流解析器的吞吐量约束和编码效率要求来自适应地选择T。由于较低的阈值T将导致在旁路模式中编码更多的符号,这将以降低的编码效率为代价来增加比特流解析器的吞吐量。还可以根据当前编码单元(CU)中的编码的CABAC二进制位的消耗来调整阈值T。例如,如果期望当前编码单元中CABAC编码的二进制位较少,则可以使用较小的阈值T。在一些实施例中,根据编码单元大小自适应地选择T。例如,如果调色板编码被应用于编码单元,则较大的编码单元大小将导致游程模式(run mode)的较长游程长度(runlength)。在这种情况下,可以使用较大的阈值以有利于更好的编码效率。
本发明被开发为通用编码工具,其可用于对应于不同编码统计的不同语法类型的熵编码。其对于具有混合视频内容类型和来自新编码工具的许多新的语法类型的屏幕内容编码特别有益,包括帧内块复制(Intra block copying)、调色板编码和帧内字符串复制(Intra string copying)。表2为本发明的实施例的使用基于上下文的编码对无符号源符号(unsigned source symbol)进行编码/解码的示例性语法表。对由输入参数syntaxType指定的不同语法类型可以采用不同的上下文建模方案。如表2所示,首先发信由语法msb_id_plus1表示的前缀部分。如果msb_id_plus1的值大于1,则发信语法refinement_bits。换句话说,如果msb_id_plus1的值为0或1,则不会发信后缀部分。
表2
上文公开的最高有效位索引的基于上下文的编码可以应用于在编码处理期间产生的各种语法元素。例如,在HEVC RExt中指定的屏幕内容编码(SCC)中,可以使用“游程”模式来对块中的颜色索引进行编码。当选择“游程”模式时,发信当前调色板游程模式的连续重复像素的数量减1。如前所述,有两种“游程”模式,如Index_Mode(索引模式)和Copy_Above_Mode(复制上方模式)。在一个实施例中,用于使用最大游程值MaxPaletteRun对前缀部分和后缀部分进行编码的截断信令(truncated signaling),其中MaxPaletteRun等于当前编码单元中剩余的待编码像素的数量减1。所得到的前缀语法palette_run_msb_id_plus1使用具有cMax=floor(log2((MaxPaletteRun))+1的截断一元码来编码,其中函数floor(x)输出小于或等于x的最大整数。后缀语法palette_run_refinement_bits使用具有cMax=MaxPaletteRun-(1<<(palette_run_msb_id_plus1-1))的截断二进制码来编码。此外,前缀语法palette_run_msb_id_plus1可使用基于上下文的编码来编码,其中上下文是基于二进制索引形成的。等于Copy_Above_Mode和Index_Mode的palette_run_type_flag可以分别采用两个不同的上下文集合。
旁路模式可以用于编码索引值大于阈值Tr的二进制位。例如,Tr可以等于4或6。当palette_run_type_flag等于Index_Mode并且当前调色板索引很大时,由于调色板游程长度减1通常等于0,所以对于Index_Mode游程类型,用于二进制索引0的上下文建模可以进一步以当前调色板索引paletteIndex为条件。在一个实施例中,对于(paletteIndex<T1),选择第一上下文(即,上下文索引=0);对于(T1<=paletteIndex<T2),选择第二上下文(即,上下文索引=1);对于(T2<=paletteIndex),选择第三上下文(即,上下文索引=2)。阈值T2大于阈值T1。可以适当地选择T1和T2的值。例如,T1可以等于2,并且T2可以等于4或8。
表3为用于前缀palette_run_msb_id_plus1的基于上下文的编码的上下文选择的示例性映射表。上下文选择以解析的调色板索引为条件,其对应于具有冗余移除的编码的修改调色板索引(coded modified palette index)。上下文选择也可以以重构的调色板索引为条件,其对应于调色板表使用的实际调色板索引。在一个实施例中,当palette_run_type_flag等于Copy_Index_Mode并且解析的调色板索引值大于阈值Ts时,可以跳过调色板游程编码。在这种情况下,调色板游程长度减1被推断为0。在一个实施例中,Ts是从当前编码单元中的调色板颜色的数量导出的。阈值Tr、T1、T2或Ts可在序列参数集(sequence parameter set,SPS)、图片参数集(picture parameter set,PPS)、切片标头(slice header)和/或调色板模式编码的编码单元中发信。
表3
在与语法元素相关的最高有效位索引的基于上下文的编码的另一实例中,使用具有cMax=floor(log2((MaxPaletteIdx))+1的截断一元码来编码所得的前缀语法palette_index_msb_id_plus1,且通过具有cMax=MaxPaletteIdx-(1<<(palette_index_msb_id_plus1-1))的截断二进制码来编码后缀语法palette_index_refinement_bits。熵编码前缀palette_index_msb_id_plus1的上下文建模可以以二进制索引为条件。熵编码前缀palette_index_msb_id_plus1的上下文建模可以进一步以MaxPaletteIdx为条件。MaxPaletteIdx表示对应于具有冗余移除的最大修改的调色板索引的最大解析的调色板索引。在另一实施例中,MaxPaletteIdx表示对应于调色板表所采用的最大实际调色板索引的最大重构调色板索引。图4为前缀palette_index_msb_id_plus1的基于上下文的编码的上下文选择的映射表的示例,其中不同的上下文集合可以用于具有不同的cMax=floor(log2((MaxPaletteIdx))+1的值的编码单元。
表4
上面公开的基于上下文的编码还可以应用于其他语法元素,该其他语法元素与屏幕内容编码(SCC)的帧内字符串复制(IntraBC)工具中使用的参考字符串相关,其中屏幕内容编码与HEVC RExt相关。例如,根据本发明的基于上下文的编码可以应用于语法元素dictionary_pred_length_minus1、dictionay_pred_offset_minus1和(dictionay_pred_offsetX,dictionay_pred_offsetY)。这三个语法元素分别表示长度减1、偏移减1和偏移向量。对于编码该长度,可以采用截断信令来编码前缀和后缀,其中前缀和后缀具有的最大游程值等于剩余的待编码像素的数量减1。对于编码该偏移向量,根据本发明的基于上下文的编码可以应用于每个矢量分量的绝对值。表5-7为分别用于上述长度减1、偏移减1和语法元素的偏移向量(x,y)的上下文选择的示例性映射表。
表5
表6
表7
对于索引模式,发信当前调色板索引和游程长度。通常在相关的游程长度之前发信调色板索引。在本发明的另一实施例中,相关的游程长度是基于调色板索引的上下文自适应编码的。例如,对于索引模式,确定具有与当前块的扫描顺序中的当前调色板索引相同的调色板索引的连续像素的数量。使用二进制化方法将连续像素的数量减1转换为二进制字符串。根据取决于相同调色板索引来自适应地选择的上下文,通过将常规CABAC模式应用于二进制字符串的至少一个二进制位,使用上下文自适应二进制算术编码(CABAC)来对二进制字符串进行编码。相应的解码处理将执行由编码器执行的这些步骤的相反步骤。例如,解码器可以接收包括对应于索引模式的当前源符号的当前块的压缩数据的输入编码比特流。可以确定与当前游程模式相关的当前调色板索引。然后,根据取决于当前调色板索引来自适应地选择的上下文,通过将常规CABAC模式应用于二进制字符串的至少一个二进制位,使用上下文自适应二进制算术编码(CABAC)来对二进制字符串进行解码。使用二进制化方法将二进制字符串转换为游程长度值,游程长度值与具有和当前调色板索引相同的调色板索引的多个连续像素相关。游程长度值对应于连续像素的数量减去1。可以使用当前块的扫描顺序中的当前调色板索引来重构编码的连续像素。在解码器侧,当前调色板索引可以基于来自输入编码比特流或重构调色板索引的解析的调色板索引。
图2为根据本发明实施例的源符号的熵编码系统的示例性流程图,其中源符号在前缀部分和后缀部分中表示,并且使用CABAC来编码前缀部分和后缀部分的二进制字符串。在步骤210中,系统接收具有属于一组符号值(a set of symbol values)的当前符号值(current symbol value)的当前源符号。输入数据对应于将被编码的当前块的像素数据或颜色索引。可以从存储器(例如,计算机存储器、缓冲器(RAM或DRAM)或其他介质)或从处理器获得输入数据。在步骤220中,确定当前符号值的最高有效位索引和任何精细位。在步骤230中,通过使用一元码或截断一元码来对与当前符号值的最高有效位索引相关的前缀部分进行二进制化,来导出第一二进制字符串。在步骤230中,如果存在任何精细位,通过使用固定长度码或截断二进制码来对与当前符号值的一个或多个精细位相对应的的后缀部分进行二进制化,来导出第二二进制字符串。在步骤250中,使用上下文自适应二进制算术编码(CABAC)来对第一二进制字符串进行编码,并且如果存在第二二进制字符串,则也使用CABAC对第二二进制字符串进行编码。
图3为根据本发明实施例的源符号的熵解码系统的示例性流程图,其中源符号在前缀部分和后缀部分中表示,并且使用CABAC来编码前缀部分和后缀部分的二进制字符串。在步骤310中,系统接收包括当前源符号的压缩数据的输入编码比特流。可以从存储器(例如,计算机存储器、缓冲器(RAM或DRAM)或其他介质)或从处理器获得输入编码比特流。在步骤320中,使用上下文自适应二进制算术编码(CABAC)来解码所述编码比特流,以恢复第一二进制字符串和任何第二二进制字符串。在步骤330中,通过使用一元码或截断一元码来解码第一二进制字符串,以恢复与当前源符号的当前符号值的最高有效位索引相关的前缀部分。在步骤340中,如果存在任何第二二进制字符串,通过使用固定长度码或截断二进制码来解码第二二进制字符串,以恢复对应于当前符号值的一个或多个精细位的后缀部分。在步骤350中,如果存在任何精细位,则基于当前符号值的最高有效位索引和任何精细位来恢复当前源符号。
以上所述的流程图旨在示出根据本发明的使用前缀部分和后缀部分的熵编码的示例。本领域的技术人员可以修改每个步骤、重新安排步骤的顺序、拆分步骤或者结合某些步骤来实现本发明,而不例外本发明的精神。在本公开中,已经使用特定语法和语义来说明实现本发明的实施例。本领域技术人员可以通过用使用等同的语法和语义来代替本发明中的语法和语义,从而实践本发明,而不例外本发明的精神。
以上的描述是使本领域的技术人员在本文提供的特定应用和需求下能够实践本发明。本领域的技术人员将容易地观察到,在不例外本发明的精神和范围内,可以进行多种修改和变动。因此,本发明并非限定在所示和描述的特定的实施例上,而本发明公开是为了符合原则和新颖性的最广泛的范围。在上述详细的描述中,各种具体的细节,用以提供对本发明的透彻的了解。尽管如此,将被本领域的技术人员理解的是,本发明能够被实践。
如上述所述的本发明的实施例,可以使用硬件、软件或其组合来实现。例如,本发明的一实施例可以是集成到视频压缩芯片中的电路或集成到视频压缩软件中的程序代码,以执行所描述的处理。本发明的实施例也可以是将在数字信号处理器上执行的程序代码来执行所描述的处理。本发明还涉及一系列的由计算机处理器、数字信号处理器、微处理器和现场可编程门阵列(FPGA)执行的功能。根据本发明,这些处理器可以被配置为执行特定任务,通过执行定义特定方法的计算机可读软件代码或固件代码来实现。软件代码或固件代码可以用不同的编程语言和不同的格式或样式来开发。软件代码也可以为不同的目标平台所编译。然而,软件代码的不同的代码格式、风格和语言,以及配置代码的其他方式以执行任务,均不例外本发明之精神和范围。
本发明可以以其它具体形式实施而不背离其精神或本质特征。所描述的实施例在所有方面都仅是说明性的而不是限制性。本发明的范围因此由所附权利要求为准而不是由前面的描述所界定。因此,各种修改、改编以及所描述的实施例的各种特征的组合可以在不例外本发明的范围如权利要求书中阐述的情况下实施。
- 还没有人留言评论。精彩留言会获得点赞!