用于处理声音的装置、方法及程序与流程
本技术涉及音频处理装置、方法及程序,并且更具体地涉及通过其能够获得更高质量的声音的音频处理装置、方法及程序。
背景技术:
通常,作为使用多个扬声器来控制声像的定位的技术,已知vbap(基于向量的幅值相移)(例如,参考npl1)。
在vbap中,通过从三个扬声器输出声音,声像可以被定位在由这三个扬声器限定的三角形的内侧的一个任意点处。
然而,在现实世界中,认为声像不是定位于一个点处,而是定位于具有一定扩散程度的部分空间中。例如,当从声带产生人声时,认为声音的振动传播到脸部、身体等,因此认为声音是从作为整个人体的部分空间发出的。
作为如上所述将声音定位在这种部分空间中的技术,即,作为延伸声像的技术,通常已知mdap(多方向幅值相移)(例如,参考npl2)。此外,mdap也用于mpeg-h3d(运动图像专家组-高质量三维)音频标准的渲染处理单元(例如,参考npl3)。
[引用列表]
[非专利文献(npl)]
[npl1]
villepulkki,“virtualsoundsourcepositioningusingvectorbaseamplitudepanning”,美国电化学协会期刊,第45卷,第6期,第456-466页,1997年
[npl2]
ville-pulkki,“uniformspreadingofamplitudepannedvirtualsources”,会议记录1999,关于信号处理对于音频和声学的应用的ieee研讨会,新帕尔茨,纽约,1999年10月17-20日
[npl3]
iso/iecjtc1/sc29/wg11n14747,2014年8月,札幌,日本,“textofiso/iec23008-3/dis,3daudio”
技术实现要素:
[技术问题]
然而,上述技术不能获得足够高质量的声音。
例如,在mpeg-h3d音频标准中,指示声像的扩散程度的信息(被称为扩展)包括在音频对象的元数据中,并且基于该扩展执行用于延伸声像的处理。然而,在延伸声像的处理中,存在声像的扩散相对于音频对象的位置的中心在上下方向和左右方向上对称的约束。因此,不能执行考虑到来自音频对象的声音的方向性(径向方向)的处理,从而不能获得足够高质量的声音。
鉴于上述情况作出了本技术,使得可以获得更高质量的声音。
[问题的解决方案]
根据本技术的一个方面的音频处理装置包括:获取单元,被配置成获取包括指示音频对象的位置的位置信息和由至少二维或更多维的向量构成并表示声像距该位置的扩散的声像信息的元数据;向量计算单元,被配置成基于表示由声像信息确定的声像的扩散的区域的水平方向角和竖直方向角来计算指示该区域中的位置的扩展向量;以及增益计算单元,被配置成基于扩展向量来计算提供给位于由位置信息指示的位置附近的两个或更多个声音输出单元的音频信号中的每个音频信号的增益。
向量计算单元可以基于水平方向角与竖直方向角之间的比率来计算扩展向量。
向量计算单元可以计算预先确定的数量的扩展向量。
向量计算单元可以计算任意可变数量的扩展向量。
声像信息可以是指示该区域的中心位置的向量。
声像信息可以是指示声像距该区域的中心的扩散程度的二维或更多维的向量。
声像信息可以是指示从位置信息指示的位置观看到的区域的中心位置的相对位置的向量。
增益计算单元可以计算关于声音输出单元中的每个声音输出单元的每个扩展向量的增益,计算针对声音输出单元中的每个声音输出单元的扩展向量所计算的增益的相加值,将相加值量化成关于声音输出单元中的每个声音输出单元的两个或更多个值的增益,以及基于量化的相加值来计算关于声音输出单元中的每个声音输出单元的最终增益。
增益计算单元可以选择要用于计算增益网格的数量,网格中的每个网格是由声音输出单元中的三个声音输出单元包围的区域,并且增益计算单元基于对网格的数量的选择结果和扩展向量来计算扩展向量中的每个扩展向量的增益。
增益计算单元可以选择要用于计算增益的网格的数量、是否要执行量化以及量化时的所述相加值的量化数量,并且响应于选择结果来计算最终增益。
增益计算单元可以基于音频对象的数量来选择要用于计算增益的网格的数量、是否要执行量化以及量化数量。
增益计算单元可以基于音频对象的重要性程度来选择要用于计算增益的网格的数量、是否要执行量化以及量化数量。
增益计算单元可以选择要用于计算增益的网格的数量,使得要用于计算增益的网格的数量随着音频对象的位置位于更靠近重要性程度高的音频对象而增加。
增益计算单元可以基于音频对象的音频信号的声压来选择要用于计算增益的网格的数量、是否要执行量化以及量化数量。
增益计算单元可以响应于对网格数量的选择结果来选择包括位于彼此不同高度处的声音输出单元的多个声音输出单元中的三个或更多个声音输出单元,并且基于由所选择的声音输出单元形成的一个或多个网格来计算增益。
根据本技术的一个方面的音频处理方法或程序包括以下步骤:获取包括指示音频对象的位置的位置信息和由至少二维或更多维的向量构成并且表示声像距该位置的扩散的声像信息的元数据;基于表示由声像信息确定的声像的扩散的区域的水平方向角和竖直方向角来计算指示该区域中的位置的扩展向量;基于扩展向量来计算提供给位于位置信息指示的位置附近的两个或更多个声音输出单元的音频信号中的每个音频信号的增益。
在本技术的一个方面中,获取包括指示音频对象的位置的位置信息和由至少二维或更多维的向量构成并且表示声像距该位置的扩散的声像信息的元数据。然后,基于表示由声像信息确定的声像的扩散的区域的水平方向角和竖直方向角来计算指示该区域中的位置的扩展向量。此外,基于扩展向量来计算提供给位于位置信息指示的位置附近的两个或更多个声音输出单元的音频信号中的每个音频信号的增益。
[发明的有益效果]
利用本技术的一个方面,可以获得更高质量的声音。
应当注意,这里描述的效果不一定是限制性的,而是可以表现出本公开中所描述的效果中的任一效果。
附图说明
图1是示出了vbap的图。
图2是示出了声像的位置的图。
图3是扩展向量的图。
图4是示出了扩展中心向量法的图。
图5是示出了扩散辐射向量法的图。
图6是示出了音频处理装置的配置的示例的图。
图7是示出了再现处理的流程图。
图8是示出了扩展向量计算处理的流程图。
图9是示出了基于扩展三维向量进行的扩展向量计算处理的流程图。
图10是示出了基于扩展中心向量进行的扩展向量计算处理的流程图。
图11是示出了基于扩展端向量进行的扩展向量计算处理的流程图。
图12是示出了基于扩展辐射向量进行的扩展向量计算处理的流程图。
图13是示出了基于扩展向量位置信息进行的扩展向量计算处理的流程图。
图14是示出了网格的数量的切换的图。
图15是示出了网格的数量的切换的图。
图16是示出了网格的形成的图。
图17是示出了音频处理装置的配置的示例的图。
图18是示出了再现处理的流程图。
图19是示出了音频处理装置的配置的示例的图。
图20是示出了再现处理的流程图。
图21是示出了vbap增益计算处理的流程图。
图22是示出了计算机的配置的示例的图。
具体实施方式
在下文中,参考附图描述应用本技术的实施方式。
<第一实施方式>
<vbap和延伸声像的处理>
当获取音频对象的音频信号和诸如音频对象的位置信息的元数据来进行渲染时,本技术使得能够获得更高质量的声音。应当注意,在下面的描述中,音频对象被简称为对象。
首先,下面描述vbap和以mpeg-h3d音频标准延伸声像的处理。
例如,如图1所示,假定欣赏具有声音的运动图像、音乐作品等的内容的用户u11正在收听从三个扬声器sp1至sp3输出的三声道声音作为内容的声音。
在刚刚描述的这种情况下,使用输出不同声道的声音的三个扬声器sp1至sp3的位置的信息将声像定位在位置p处得到检验。
例如,位置p由三维向量(在下文中也称为向量p)表示,该三维向量的起点是三维坐标系中的原点o,三维坐标系的原点o由用户u11的头部的位置给定。此外,如果其起点由原点o给定并且在朝向扬声器sp1至sp3的位置的方向上取向的三维向量分别被表示为向量i1至i3,则向量p可以由向量i1到i3的线性和表示。
换言之,向量p可以被表示为p=g1i1+g2i2+g3i3。
这里,如果与向量i1至i3相乘的系数g1至g3分别被计算和确定为从扬声器sp1至sp3输出的声音的增益,则声像可以被定位在位置p处。
使用三个扬声器sp1至sp3的位置信息来确定系数g1至g3并且以上述方式控制声像的定位位置的技术被称为三维vbap。特别地,在下面的描述中,将关于每个扬声器确定的增益例如系数g1至g3称为vbap增益。
在图1的示例中,声像可以被定位在包括扬声器sp1、sp2和sp3的位置的球体上的三角形形状的区域tr11中的任意位置处。这里,区域tr11是以原点o为中心并且经过扬声器sp1至sp3的位置的球体的表面上的区域,并且是由扬声器sp1至sp3包围的三角形区域。
如果使用这种三维vbap,则可以将声像定位在空间中的任意位置。应当注意,例如在‘villepulkki,“virtualsoundsourcepositioningusingvectorbaseamplitudepanning”,美国电化学协会期刊,第45卷,第6期,第456-466页,1997年’等中详细描述了vbap。
现在,描述根据mpeg-h3d音频标准延伸声像的处理。
在mpeg-h3d音频标准中,从编码装置输出通过以下处理而获得的比特流:对通过对每个对象的音频信号进行编码所获得的编码音频数据和通过对每个对象的元数据进行编码所获得的编码元数据进行复用。
例如,元数据包括:指示对象在空间中的位置的位置信息、指示对象的重要性程度的重要性信息、以及作为指示对象的声像的扩散程度的信息的扩展。
这里,指示声像的扩散程度的扩展是从0度到180度的任意角度,并且编码装置可以关于每个对象指定对于音频信号的每个帧而值不同的扩展。
此外,对象的位置由水平方向角方位角、竖直方向角仰角和距离半径表示。具体地,对象的位置信息由水平方向角方位角、竖直方向角仰角和距离半径的值来配置。
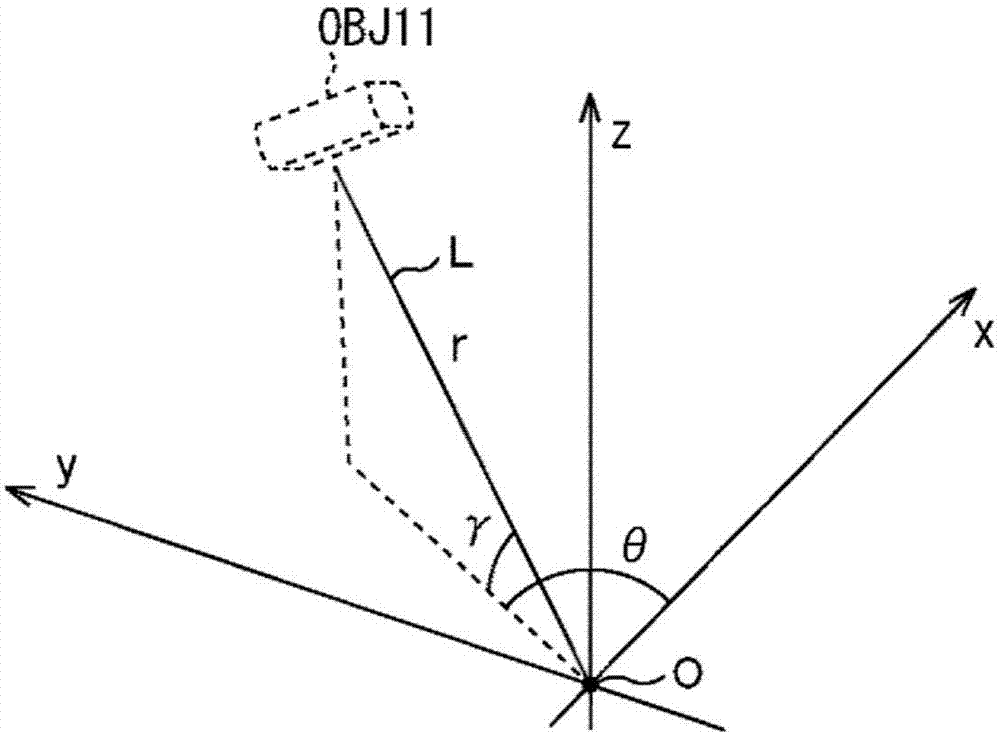
例如,考虑三维坐标系,如图2所示,在三维坐标系中,欣赏从未示出的扬声器输出的对象的声音的用户的位置被确定为原点o,并且图2中的右上方向、左上方向和向上方向被确定为彼此竖直的x轴、y轴和z轴。此时,如果一个对象的位置被表示为位置obj11,则声像可以被定位在三维坐标系中的位置obj11处。
此外,如果将位置obj11和原点o互连的线性线被表示为线l,则由线性线l和x轴在xy平面上限定的图2中的水平方向上的角度θ(方位角)为表示位置obj11处的对象在水平方向上的位置的水平方向角方位角,并且水平方向角方位角具有满足以下的任意值:﹣180度≤方位角≤180度
例如,x轴方向的正方向被确定为方位角=0度而x轴方向的负方向被确定为方位角=+180度或=﹣180度。此外,围绕原点o的逆时针方向被确定为方位角的正方向,而围绕原点o的顺时针方向被确定为方位角的负方向。
此外,由线性线l和xy平面限定的角度,即,图2中的竖直方向上的角度γ(仰角)是表示位于位置obj11处的对象在竖直方向上的位置的竖直方向角仰角,并且竖直方向角仰角具有满足以下的任意值:﹣90度≤仰角≤90度。例如,xy平面上的位置是仰角=0度,以及图2中的向上方向是竖直方向角仰角的正方向,而图2中的向下方向是竖直方向角仰角的负方向。
此外,线性线l的长度,即,从原点o到位置obj11的距离是到用户的距离半径,并且距离半径具有0或更大的值。具体地,距离半径具有满足以下的值:0≤(半径)≤∞。在下面的描述中,距离半径也称为径向方向的距离。
应当注意,在vbap中,从所有扬声器或对象到用户的距离半径相等,并且将距离半径归一化为1来执行计算是通用方法。
以该方式包括在元数据中的对象的位置信息由水平方向角方位角、竖直方向角仰角和距离半径的值来配置。
在下面的描述中,水平方向角方位角、竖直方向角仰角和距离半径也分别简称为方位角、仰角和半径。
此外,在接收包括编码音频数据和编码元数据的比特流的解码装置中,在执行编码音频数据和编码元数据的解码之后,响应于元数据中所包括的扩展的值来执行用于延伸声像的渲染处理。
具体地,解码装置首先将由对象的元数据中所包括的位置信息指示的空间中的位置确定为位置p。如上所述,位置p对应于图1中的位置p。
然后,解码装置设置18个扩展向量p1至p18,使得例如将位置p设置成位置p=中心位置p0,如图3所示,这些扩展向量在围绕中心位置p0的单位球体上在上下方向和左右方向上对称。应当注意,在图3中,与图1的情况下的部分对应的部分由相同的附图标记表示,并且将适当地省略对这些部分的描述。
在图3中,五个扬声器sp1至sp5布置在以原点o为中心半径为1的单位球体的球面上,以及由位置信息指示的位置p为中心位置p0。在下面的描述中,位置p也被具体地称为对象位置p,并且其起点为原点o且其终点为对象位置p的向量也被称为向量p。此外,其起点为原点o且其终点为中心位置p0的向量也称为向量p0。
在图3中,其起点为原点o并且由虚线绘制的箭头标记表示扩展向量。然而,虽然在图3中实际上有18个扩展向量,但是出于图3的可视性仅绘制了八个扩展向量。
这里,扩展向量p1至p18中的每一个是其终点位置位于以中心位置p0为中心的单位球面上的圆形的区域r11内的向量。具体地,由向量p0和其终点位置位于由区域r11表示的圆形的圆周上的扩展向量限定的角度是由扩展指示的角度。
因此,当扩展的值增加时,每个扩展向量的终点位置被设置在离中心位置p0较远的位置处。换言之,区域r11在尺寸上增加。
区域r11表示声像距对象的位置的扩散。换言之,区域r11是指示对象的声像延伸的扩散的区域。此外,可以认为,由于认为对象的声音是从整个对象发出的,所以区域r11表示对象的形状。在下面的描述中,与区域r11一样,指示对象的声像延伸的扩散的区域也被称为指示声像的扩散的区域。
此外,在扩展的值为0的情况下,18个扩展向量p1至p18的终点位置等于中心位置p0。
应当注意,在下面的描述中,扩展向量p1至p18的终点位置也分别特定地被称为位置p1至p18。
在如上所述确定在单位球面上沿向上下方向和左右方向对称的扩展向量之后,解码装置关于向量p和扩展向量,即关于位置p和位置p1至p18中的每一个通过vbap计算声道的扬声器中的每一个的vbap增益。此时,计算扬声器的vbap增益,使得声像被定位在诸如位置p和位置p1的位置中的每个位置处。
然后,解码装置将关于每个扬声器的位置所计算的vbap增益相加。例如,在图3的示例中,关于扬声器sp1和位置p1至p18所计算的位置p的vbap增益被相加。
此外,在为各个扬声器计算的加法处理之后,解码装置对vbap增益进行归一化。具体地,执行归一化,使得所有扬声器的vbap增益的平方和变成1。
然后,解码装置将对象的音频信号乘以通过归一化所获得的扬声器的vbap增益,以获得各个扬声器的音频信号,并将关于各个扬声器所获得的音频信号提供给扬声器,使得扬声器输出声音。
因此,例如,在图3的示例中,声像被定位,使得从整个区域r11输出声音。换言之,声像被延伸到整个区域r11。
在图3中,当不执行用于延伸声像的处理时,对象的声像被定位在位置p处,因此在这种情况下,基本上从扬声器sp2和扬声器sp3输出声音。相反,当执行用于延伸声像的处理时,声像被延伸到整个区域r11,因此当声音再现时,从扬声器sp1至sp4输出声音。
顺便提及,当执行如上所述的用于延伸声像的这种处理时,与不执行延伸声像的处理的替代情况相比,渲染时的处理量增加。因此,出现能够由解码装置处理的对象的数量减少的情况,或者出现由包含硬件规模小的渲染器的解码装置不能执行渲染的情况。
因此,在当渲染时执行用于延伸声像的处理的情况下,期望能够以尽可能小的处理量进行渲染。
此外,由于存在上述18个扩展向量在围绕中心位置p0=位置p的单位球面上在上下方向以及左右方向上对称的约束,所以不能执行考虑对象的声音的方向性(辐射方向)或者对象的形状的处理。因此,不能获得足够高质量的声音。
此外,在mpeg-h3d音频标准中,由于一种处理被规定为在渲染时用于延伸声像的处理,所以在渲染器的硬件规模小的情况下,不能执行用于延伸声像的处理。换言之,不能执行音频的再现。
此外,在mpeg-h3d音频标准中,不能执行切换执行渲染的处理,使得可以通过渲染器的硬件规模所允许的处理量来获得具有最高质量的声音。
考虑到如上所述的这种情况,本技术使得可以在渲染时减少处理量。此外,本技术使得可以通过表示对象的方向性或形状来获得足够高质量的声音。此外,本技术使得可以响应于渲染器等的硬件规模选择适当的处理作为进行渲染时的处理,以在允许的处理量的扩散内获得具有最高质量的声音。
下面描述本技术的概要。
<处理量的减少>
首先,描述在渲染时处理量的减少。
在不延伸声像的常见vbap处理(渲染处理)中,执行下面具体描述的处理a1至a3:
(处理a1)
对于三个扬声器计算与音频信号相乘的vbap增益。
(处理a2)
执行归一化,使得三个扬声器的vbap增益的平方和变成1。
(处理a3)
对象的音频信号乘以vbap增益。
这里,在处理a3中,由于对于三个扬声器中的每一个执行音频信号乘以vbap增益的乘法处理,因此刚刚描述的这种乘法处理最多执行三次。
另一方面,在执行用于延伸声像的处理的vbap处理(渲染处理)中,执行下面具体描述的处理b1至b5:
(处理b1)
对于向量p计算要与三个扬声器中的每个扬声器的音频信号相乘的vbap增益。
(处理b2)
对于18个扩展向量计算要与三个扬声器中的每个扬声器的音频信号相乘的vbap增益。
(处理b3)
对于每个扬声器使关于向量所计算的vbap增益相加。
(处理b4)
执行归一化,使得所有扬声器的vbap增益的平方和变成1。
(处理b5)
对象的音频信号乘以vbap增益。
当执行用于延伸声像的处理时,由于输出声音的扬声器的数量为三个或更多个,所以执行处理b5中的乘法处理三次或更多次。
因此,如果将执行用于延伸声像的处理的情况与不执行用于延伸声像的处理的另一情况进行相互比较,则当执行用于延伸声像的处理时,处理量特别是通过处理b2和b3增加了一定量,并且处理b5中的处理量也大于处理a3中的处理量。
因此,本技术使得可以通过对关于每个扬声器确定的向量的vbap增益的总和进行量化来减少上述处理b5中的处理量。
具体地,通过本技术执行如下所述的这种处理。应当注意,关于每个向量例如向量p或关于每个扬声器确定的扩展向量所计算的vbap增益的和(相加值)也被称为vbap增益相加值。
首先,在执行处理b1至b3并且关于每个扬声器获得vbap增益相加值之后,然后对vbap增益相加值进行二值化。在二值化中,例如,每个扬声器的vbap增益相加值为0和1中之一。
可以采用诸如四舍五入、上限(上舍入)、下限(截取)或阈值处理的任何方法作为用于对vbap增益相加值进行二值化的方法。
在以这种方式对vbap增益相加值进行二值化之后,基于二值化的vbap增益相加值执行上述处理b4。因此,每个扬声器的最终vbap增益是除了0之外的一个增益。换言之,如果对vbap增益相加值进行二值化,则每个扬声器的vbap增益的最终值为0或预定值。
例如,如果作为二值化的结果三个扬声器的vbap增益相加值为1而另一扬声器的vbap增益相加值为0,则三个扬声器的vbap增益的最终值为1/3(1/2)。
在以这种方式获得扬声器的最终vbap增益之后,执行将扬声器的音频信号乘以最终vbap增益的处理作为处理b5'来替代上述处理b5。
如果以如上所述的这种方式执行二值化,则由于每个扬声器的vbap增益的最终值变成0和预定值中之一,所以在处理b5'中,仅需要执行乘法处理一次,因此能够减少处理量。换言之,虽然处理b5要求执行乘法处理三次或更多次,但是处理b5'仅要求执行乘法处理一次。
应当注意,尽管这里给出了对vbap增益相加值进行二值化的情况作为示例,但是也可以以其他方式将vbap增益相加值量化成三个值或更多个值中之一。
例如,在vbap增益相加值为三个值中之一的情况下,在执行上述处理b1至b3并且对于每个扬声器获得vbap增益相加值之后,vbap增益相加值被量化成0、0.5和1中之一。然后,执行处理b4和处理b5'。在这种情况下,处理b5'中的乘法处理的次数最多为2次。
在以这种方式对vbap增益相加值进行x值转换的情况下,即在将vbap增益相加值量化成x增益中之一(其中x等于或大于2)情况下,则在处理b5'中执行乘法处理的次数最大变成(x-1)。
应当注意,虽然在前面的描述中描述了在执行用于延伸声像的处理时对vbap增益相加值进行量化以减少处理量的示例,但是同样在不执行用于延伸声像的处理的情况下,可以类似地通过对vbap增益进行量化来减少处理量。具体地,如果对对于向量p确定的每个扬声器的vbap增益进行量化,则通过归一化后的vbap增益进行的音频信号的乘法处理的执行次数可以减少。
<用于表示对象的形状和对象的声音的方向性的处理>
现在,描述通过本技术来表示对象的形状和对象的声音的方向性的处理。
在下文中,描述了包括扩展三维向量法、扩展中心向量法、扩展端向量法、扩展辐射向量法和任意扩展向量法的五种方法。
(扩展三维向量法)
首先,描述了扩展三维向量法。
在扩展三维向量法中,作为三维向量的扩展三维向量被存储在比特流中并与比特流一起被发送。这里,假设扩展三维向量例如被存储在每个对象的每个音频信号的帧的元数据中。在这种情况下,指示声像的扩散程度的扩展不存储在元数据中。
例如,扩展三维向量是包括以下三个因子的三维向量:指示声像在水平方向上的扩散程度的s3_azimuth、指示声像在竖直方向上的扩散程度的s3_elevation、指示声像的半径方向上的深度的s3_radius。
具体地,扩展三维向量=(s3_azimuth,s3_elevation,s3_radius)。
这里,s3_azimuth指示声像在位置p的水平方向上即在上述水平方向角方位角的方向上的扩展角。具体地,s3_azimuth指示由向量p(向量po)和从原点o朝向指示声像的扩散的区域的水平方向侧中的末端的向量限定的角度。
类似地,s3_elevation指示声像在位置p的竖直方向上即在上述竖直方向角仰角的方向上的扩展角。具体地,s3_elevation指示由向量p(向量po)和从原点o朝向指示声像的扩散的区域的竖直方向侧中的末端的向量限定的角度。此外,s3_radius指示在上述距离半径的方向上即在单位球面的法线方向上的深度。
应当注意,s3_azimuth、s3_elevation和s3_radius具有等于或大于0的值。此外,虽然这里的扩展三维向量是指示由对象的位置信息指示的位置p的相对位置的信息,但是扩展三维向量还可以另外是指示绝对位置的信息。
在扩展三维向量法中,使用如上所述的这种扩展三维向量来执行渲染。
具体地,在扩展三维向量法中,通过基于扩展三维向量计算下面给出的表达式(1)来计算扩展的值:
[表达式1]
扩展:max(s3_azimuth,s3_elevation)...(1)
应当注意,表达式(1)中的max(a,b)指示返回值a和b中的较高值的函数。因此,s3_azimuth和s3_elevation的较高值被确定为扩展的值。
然后,基于以这种方式获得的扩展的值和包括在元数据中的位置信息,与mpeg-h3d音频标准的情况类似地计算18个扩展向量p1至p18。
因此,将由包括在元数据中的位置信息指示的对象的位置p确定为中心位置p0,并且确定18个扩展向量p1至p18,使得它们在以中心位置po为中心的单位球面上在左右方向上和上下方向上对称。
此外,在扩展三维向量法中,其起点为原点o且其终点为中心位置po的向量po被确定为扩展向量p0。
此外,每个扩展向量由水平方向角方位角、竖直方向角仰角和距离半径表示。在下文中,特别地扩展向量pi(其中i=0至18)的水平方向角方位角和竖直方向角仰角分别被表示为a(i)和e(i)。
在以这种方式获得扩展向量p0至p18之后,基于s3_azimuth与s3_elevation之间的比率将扩展向量p1至p18变成(校正为)最终扩展向量。
具体地,在s3_azimuth大于s3_elevation的情况下,执行下面的表达式(2)的计算,以将作为扩展向量p1至p18的仰角的e(i)变成e’(i):
[表达式2]
e’(i)=e(0)+(e(i)–e(0))×s3_elevation/s3_azimuth...(2)
应当注意,对于扩展向量p0,不执行仰角的校正。
相反,在s3_azimuth小于s3_elevation的情况下,执行下面的表达式(3)的计算,以将作为扩展向量p1至p18的方位角的a(i)变成a’(i):
[表达式3]
a’(i)=a(0)+(a(i)–a(0))×s3_azimuth/s3_elevation…(3)
应当注意,对于扩展向量p0,不执行方位角的校正。
将s3_azimuth和s3_elevation中较大的一个确定为扩展来以如上所述的这种方式确定扩展向量的处理是以下处理:将指示声像在单位球面上的扩散的区域暂时设置为由s3_azimuth和s3_elevation中较大的一个的角度限定的半径的圆以通过类似于常规处理的处理来确定扩展向量。
此外,随后响应于s3_azimuth和s3_elevation之间的大小关系通过表达式(2)或表达式(3)来校正扩展向量的处理是以下处理:校正指示声像的扩散的区域即扩展向量,使得指示声像在单位球面上的扩散的区域变成由扩展三维向量指定的原始的s3_azimuth和s3_elevation限定的区域。
因此,之后上述处理全部变成以下处理:基于扩展三维向量即基于s3_azimuth和s3_elevation来计算指示声像在单位球面上的扩散的区域—其具有圆形形状或椭圆形形状—的扩展向量。
在以这种方式获得扩展向量之后,扩展向量p0至p18此后用于执行上述处理b2、处理b3、处理b4和处理b5',以生成要提供给扬声器的音频信号。
应当注意,在处理b2中,对于扩展向量p0至p18的19个扩展向量中的每一个计算每个扬声器的vbap增益。这里,由于扩展向量p0为向量p,所以可以认为对于扩展向量p0计算vbap增益的处理是执行处理b1。此外,在处理b3之后,根据需要执行每个vbap增益相加值的量化。
通过以这种方式由扩展三维向量将指示声像的扩散的区域设置成任意形状的区域,可以表示对象的形状和对象的声音的方向性,从而可以通过渲染获得更高质量的声音。
此外,虽然这里描述了将值s3_azimuth和s3_elevation中的较高值用作扩展的值的示例,但是另外可以将值s3_azimuth和s3_elevation中的较低值用作扩展的值。
在这种情况下,当s3_azimuth大于s3_elevation时,对每个扩展向量的方位角a(i)进行校正,但是当s3_azimuth小于s3_elevation时,对每个扩展向量的仰角e(i)进行校正。
此外,虽然这里给出了其中确定扩展向量p0至p18即预先确定的19个扩展向量并且对于这些扩展向量计算vbap增益的示例,但是要计算的扩展向量的数量是可变的。
在刚刚描述的这种情况下,可以例如响应于s3_azimuth和s3_elevation之间的比率来确定要生成的扩展向量的数量。根据刚刚描述的这种处理,例如,在对象水平伸长并且对象的声音在竖直方向上的扩散小的情况下,如果忽略在竖直方向上并列的扩展向量并且扩展向量基本上在水平方向上并列,则可以适当地表示声音水平方向上的扩散。
(扩展中心向量法)
现在,描述扩展中心向量法。
在扩展中心向量法中,作为三维向量的扩展中心向量被存储在比特流中并与比特流一起被发送。这里,假定扩展中心向量例如被存储在每个对象的每个音频信号的帧的元数据中。在这种情况下,指示声像的扩散程度的扩展也被存储在元数据中。
扩展中心向量是指示指示对象的声像的扩散的区域的中心位置po的向量。例如,扩展中心向量是由以下三个因子构成的三维向量:指示中心位置po的水平方向角的方位角、指示中心位置po的竖直方向角的仰角、和指示中心位置po在径向方向上的距离的半径。
具体地,扩展中心向量=(方位角,仰角,半径)。
当渲染处理时,由扩展中心向量指示的位置被确定为中心位置po,并且计算扩展向量p0至p18作为扩展向量。这里,例如,如图4所描绘的,扩展向量p0是其起点为原点o且其终点为中心位置po的向量p0。应当注意,在图4中,与图3的情况下的部分对应的部分由相同附图标记表示,并且适当地省略对它们的描述。
此外,在图4中,用虚线绘制的箭头表示扩展向量,以及同样在图4中,为了使图容易看出,仅描绘了九个扩展向量。
然而,在图3所描绘的例子中,位置p=中心位置po,在图4的示例中,中心位置p0是与位置p不同的位置。在该示例中,可以看出,相对于为对象的位置的位置p,指示声像的扩散并以中心位置po为中心的区域r21从图3的示例中的左侧移位至图4中的左侧。
如果能够以这种方式通过扩展中心向量指定任意位置作为指示声像的扩散的区域的中心位置po,则可以以更高的准确度表示对象的声音的方向性。
在扩展中心向量法中,如果获得扩展向量p0至p18,则之后对于向量p执行处理b1,并且对于扩展向量p0至p18执行处理b2。
应当注意,在处理b2中,可以对于19个扩展向量中的每一个计算vbap增益,或者可以仅对于除了扩展向量p0之外的扩展向量p1至p18计算vbap增益。在下文中,假定也对于扩展向量p0计算vbap增益来给出描述。
此外,在计算每个向量的vbap增益之后,执行处理b3、处理b4和处理b5'以生成要提供给扬声器的音频信号。应当注意,在处理b3之后,根据需要执行vbap增益相加值的量化。
通过如上所述的这种扩展中心向量法,也可以通过渲染获得足够高质量的声音。
(扩展端向量法)
现在,描述扩展端向量法。
在扩展端向量法中,作为五维向量的扩展端向量被存储在比特流中并与比特流一起被发送。这里,假定例如扩展端向量被存储在每个对象的每个音频信号的帧的元数据中。在这种情况下,指示声像的扩散程度的扩展不存储在元数据中。
例如,扩展端向量是表示指示对象的声像的扩散的区域的向量,并且是由以下五个因子构成的向量:扩展左端方位角、扩展右端方位角、扩展上限端面仰角、扩展下端仰角和扩展半径。
这里,构成扩展端向量的扩展左端方位角和扩展右端方位角分别表示水平方向角方位角的值,水平方向角方位角表示指示声像的扩散的区域的水平方向上的左端和右端的绝对位置。换言之,扩展左端方位角和扩展右端方位角分别指示以下角度:指示声像相对于指示声像的扩散的区域的中心位置po在向左方向和向右方向上的扩散程度。
同时,扩展上端仰角和扩展下端仰角分别表示指示竖直方向角仰角的值,竖直方向角仰角指示声像的扩散的区域的竖直方向上的上端和下端的绝对位置。换言之,扩展上端仰角和扩展下端仰角分别指示以下角度:表示声像相对于指示声像的扩散的区域的中心位置po在向上方向和向下方向上的扩散程度的角度。此外,扩展半径表示声像在径向方向上的深度。
应当注意,虽然这里扩展端向量是指示空间中的绝对位置的信息,但是扩展端向量可以另外是指示由对象的位置信息指示的位置p的相对位置的信息。
在扩展端向量法中,使用如上所述的这种扩展端向量进行渲染。
具体地,在扩展端向量法中,基于扩展端向量计算下面的表达式(4),以计算中心位置po:
[表达式4]
方位角:(扩展左端方位角+扩展右端方位角)/2
仰角:(扩展上端仰角+扩展下端仰角)/2
半径:扩展半径
…(4)
具体地,指示中心位置p0的水平方向角方位角是扩展左端方位角和扩展右端方位角之间的中间(平均)角度,以及指示中心位置po的竖直方向角仰角是扩展上端仰角和扩展下端仰角之间的中间(平均)角度。此外,指示中心位置po的距离半径是扩展半径。
因此,在扩展端向量法中,中心位置p0有时成为与位置信息所表示的对象的位置p不同的位置。
此外,在扩展端向量法中,通过计算下面的表达式(5)来计算扩展的值:
[表达式5]
扩展:max((扩展左端方位角-扩展右端方位角)/2,(扩展上端仰角-扩展下端仰角)/2)
…(5)
应当注意,表达式(5)中的max(a,b)表示返回值a和b中的较高值的函数。因此,由扩展端向量指示的作为与指示对象的声像的扩散的区域中的水平方向上的半径相对应的角度的(扩展左端方位扩-展右端方位角)/2和作为与该区域中的竖直方向上的半径对应的角度的(扩展上端方位-扩展右端方位角)/2的值中的较高值被确定为扩展的值。
然后,基于中心位置po(向量po)和以这种方式获得的扩展的值,与mpeg-h3d音频标准的情况类似地计算18个扩展向量p1至p18。
因此,确定18个扩展向量p1至p18,使得它们在以中心位置po为中心的单位球面上在上下方向和左右方向上对称。
此外,在扩展端向量法中,将其起点为原点o且其终点为中心位置po的向量po确定为扩展向量p0。
同样在扩展端向量法中,与扩展三维向量法的情况类似,每个扩展向量由水平方向角方位角、竖直方向角仰角和距离半径表示。换言之,扩展向量pi(其中i=0至18)的水平方向角方位角和竖直方向角仰角分别由a(i)和e(i)表示。
在以这种方式获得扩展向量p0至p18之后,基于(扩展左端方位-扩展右端方位角)和(扩展上端仰角-扩展下端仰角)之间的比率来改变(校正)扩展向量p1至p18以确定最终的扩展向量。
具体地,如果(扩展左端方位-扩展右端方位角)大于(扩展上端仰角-扩展下端仰角),则执行下面给出的表达式(6)的计算,并且将作为每个扩展向量p1至p18的仰角的e(i)变成e’(i):
[表达式6]
e’(i)=e(0)+(e(i)-e(0))×(扩展上端仰角-扩展下端仰角)/(扩展左端方位角-扩展右端方位角)...(6)
应当注意,对于扩展向量p0,不执行仰角的校正。
另一方面,当(扩展左端方位角-扩展右端方位角)小于(扩展上端仰角-扩展下端仰角)时,执行下面给出的表达式(7)的计算,并且将作为每个扩展向量p1至p18的方位角的a(i)变成a’(i):
[表达式7]
a’(i)=a(0)+(a(i)–a(0))×(扩展左端方位角-扩展右端方位角)/(扩展上端仰角-扩展下端仰角)
...(7)
应当注意,对于扩展向量p0,不执行方位角的校正。
应当注意,如上所述的扩展向量的计算方法基本上与扩展三维向量法的情况下计算方法相似。
因此,之后上述处理全部是以下处理:根据扩展端向量计算指示圆形或椭圆形的声像在由扩展端向量限定的单位球面上的扩散的区域的扩展向量。
在以这种方式获得扩展向量之后,使用向量p和扩展向量p0至p18来执行上述的处理b1、处理b2、处理b3、处理b4和处理b5',从而生成要提供给扬声器的音频信号。
应当注意,在处理b2中,对于19个扩展向量计算每个扬声器的vbap增益。此外,在处理b3之后,根据需要执行vbap增益相加值的量化。
通过以这种方式由扩展端向量将指示声像的扩散的区域设置成具有位于任意位置的中心位置p0的任意形状的区域,可以表示对象的形状和对象的声音的方向性,从而通过渲染可以获得更高质量的声音。
此外,虽然这里描述了将值(扩展左端方位角-扩展右端方位角)/2和(扩展上端仰角-扩展下端仰角)/2中的较高值用作扩展的值的例子,但是另外可以将这些值中的较低值用作扩展的值。
此外,虽然将对于扩展向量p0计算vbap增益的情况描述为示例,但是可以对于扩频向量p0不计算vbap增益。假定对于扩展向量p0也计算vbap增益给出了下面的描述。
可替代地,类似于扩展三维向量法的情况,可以例如响应于(扩展左端方位角-扩展右端方位角)与(扩展上端仰角-扩展下端仰角)之间的比例来计算要生成的扩展向量的数量。
(扩散辐射向量法)
此外,描述了扩展辐射向量法。
在扩展辐射向量法中,作为三维向量的扩展辐射向量被存储在比特流中并与比特流一起被发送。这里,假定例如将扩展辐射向量存储在每个对象的每个音频信号的帧的元数据中。在这种情况下,指示声像的扩散程度的扩展也存储在元数据中。
扩展辐射向量是表示指示对象的声像的扩散的区域的中心位置po到对象的位置p的相对位置的向量。例如,扩展辐射向量是由以下三个因子构成的三维向量:从位置p观看,指示中心位置po的水平方向角的方位角、指示中心位置po的竖直方向角的仰角、以及指示中心位置po的径向方向上的距离的半径。
换言之,扩散辐射向量=(方位角,仰角,半径)。
当渲染处理时,将由通过将扩展辐射向量和向量p相加而获得的向量指示的位置确定为中心位置po,并且计算扩展向量p0至p18作为扩展向量。这里,例如,如图5所示,扩展向量p0是其起点为原点o且其终点为中心位置po的向量po。应当注意,在图5中,与图5的情况中的部分对应的部分由相同的附图标记表示,并且将适当地省略对这些部分的描述。
此外,在图5中,用虚线绘制的箭头表示扩展向量,以及同样在图5中,为了使图容易看出,仅描绘了九个扩展向量。
然而,在图3所描绘的示例中,位置p=中心位置po,而在图5所描绘的示例中,中心位置po是与位置p不同的位置。在该示例中,通过向量p和由箭头标记b11指示的扩展辐射向量的向量相加而获得的向量的末端位置为中心位置po。
此外,可以认识到,指示声像的扩散并以中心位置po为中心的区域r31相对于为对象的位置的位置p超过图3的示例中的左侧被移位至图5中的左侧。
如果能够以这种方式使用扩展辐射向量和位置p将任意位置指定为指示声像的扩散的区域的中心位置po,则可以更准确地表示对象的声音的方向性。
在扩展辐射向量法中,如果获得扩展向量p0至p18,则对于向量p执行处理b1,而对于扩展向量p0至p18执行处理b2。
应当注意,在处理b2中,可以对于19个扩展向量计算vbap增益,或者可以仅对于除了扩展向量p0之外的扩展向量p1至p18计算vbap增益。在下面的描述中,假定对于扩展向量p0也计算vbap增益。
此外,如果计算每个向量的vbap增益,则执行处理b3、处理b4和处理b5'以生成要提供给扬声器的音频信号。应当注意,在处理b3之后,根据需要执行每个vbap增益相加值的量化。
此外,通过如上所述的这种扩散辐射向量法,可以通过渲染获得足够高质量的声音。
(任意扩展向量法)
随后,描述任意扩展向量法。
在任意扩展向量法中,指示用于计算vbap增益的扩展向量的数量的扩展向量数量信息和指示每个扩展向量的终点位置的扩展向量位置信息被存储在比特流中并与比特流一起被发送。这里,假定扩展向量数量信息和扩展向量位置信息例如被存储在每个对象的每个音频信号的帧的元数据中。在这种情况下,指示声像的扩散程度的扩展不存储在元数据中。
在渲染处理时,基于每片扩展向量位置信息,计算其起点为原点o且其终点为由扩展向量位置信息指示的位置的向量作为扩展向量。
此后,对于向量p执行处理b1,并且对于每个扩展向量执行处理b2。此外,在计算每个向量的vbap增益之后,执行处理b3、处理b4和处理b5'以生成要提供给扬声器的音频信号。应当注意,在处理b3之后,根据需要执行每个vbap增益相加值的量化。
根据如上所述的这种任意扩展向量法,可以任意地指定声像要被延伸的扩散以及该扩散的形状,因此可以通过渲染获得足够高质量的声音。
<处理的切换>
在本技术中,可以响应于渲染器的硬件规模等选择适当的处理作为进行渲染时的处理,并且在可允许的处理量的扩散内获得最高质量的声音。
具体地,在本技术中,为了能够在多个处理之间进行切换,用于处理切换的索引被存储在比特流中,并且与比特流一起从编码装置被发送至解码装置。换言之,用于切换处理的索引值索引被添加至比特流语法。
例如,响应于索引值索引的值来执行下面的处理。
具体地,当索引值索引=0时,解码装置,更具体地,解码装置中的渲染器执行与在常规mpeg-h3d音频标准的情况下执行的渲染类似的渲染。
另一方面,例如,当索引值索引=1时,在根据常规mpeg-h3d音频标准指示18个扩展向量的索引的组合中,预定组合的索引被存储在比特流中并与比特流一起被发送。在这种情况下,渲染器计算与由存储在比特流中并与比特流一起发送的每个索引指示的扩展向量有关的vbap增益。
此外,例如,当索引值索引=2时,指示在处理中要使用的扩展向量的数量的信息以及根据常规mpeg-h3d音频标准指示18个扩展向量中的哪一个由要用于处理的扩展向量指示的索引被存储在比特流中并与比特流一起发送。
此外,例如,当索引值索引=3时,根据上述任意扩展向量法执行渲染处理,以及例如,当索引值索引=4时,在渲染处理中执行上述vbap增益相加值的二值化。此外,例如,当索引值索引=5时,根据上述扩展中心向量法执行渲染处理。
此外,可以不指定用于在编码装置中切换处理的索引值索引,而是可以由解码装置中的渲染器选择处理。
在刚刚描述的这种情况下,例如,基于对象的元数据中包括的重要性信息来切换处理似乎是一个值得推荐的想法。具体地,例如,对于其由重要性信息指示的重要性高(等于或高于预定值)的对象,执行上述由索引值索引=0指示的处理。对于其由重要性信息指示的重要性低(低于预定值)的对象,可以执行上述由索引值索引=4指示的处理。
通过以这种方式适当地切换进行渲染时的处理,可以响应于渲染器的硬件规模等在可允许的处理量的扩散内获得最高质量的声音。
<音频处理装置的配置的示例>
随后,描述上述本技术的更具体的实施方式。
图6是描绘了应用本技术的音频处理装置的配置的示例的图。
分别对应于m个声道的扬声器12-1至12-m连接至图6中所描绘的音频处理装置11。音频处理装置11基于从外部提供的对象的音频信号和元数据来生成不同声道的音频信号,并将音频信号提供给扬声器12-1至12-m,使得扬声器12-1至12-m再现声音。
应当注意,在下面的描述中,在不需要将扬声器12-1至12-m彼此特定区分的情况下,它们中的每一个仅被称为扬声器12。每个扬声器12是基于提供给其的音频信号输出声音的声音输出单元。
扬声器12被布置成包围欣赏内容等的用户。例如,扬声器12布置在上述单位球面上。
音频处理装置11包括获取单元21、向量计算单元22、增益计算单元23和增益调整单元24。
获取单元21获取来自外部的对象的音频信号以及每个对象的音频信号的每一帧的元数据。例如,通过由解码装置对从编码装置输出的比特流中包括的编码音频数据和编码元数据进行解码来获得音频数据和元数据。
获取单元21将所获取的音频信号提供给增益调整单元24,并将所获取的元数据提供给向量计算单元22。这里,元数据例如根据需要包括指示对象的位置的位置信息、指示每个对象的重要性程度的重要性信息、指示对象的声像的空间扩散的扩展等。
向量计算单元22基于从获取单元21提供至此的元数据来计算扩展向量,并将扩展向量提供给增益计算单元23。此外,根据需要,向量计算单元22将由元数据中所包括的位置信息指示的每个对象的位置即指示位置p的向量p提供给增益计算单元23。
增益计算单元23基于从向量计算单元22提供的扩展向量和向量p通过vbap来计算与每个声道对应的扬声器12的vbap增益,并将vbap增益提供给增益调整单元24。此外,增益计算单元23包括用于对每个扬声器的vbap增益进行量化的量化单元31。
增益调整单元24基于从增益计算单元23提供的每个vbap增益对从获取单元21提供的对象的音频信号进行增益调整,并且将作为增益调整的结果而获得的m个声道的音频信号提供给扬声器12。
增益调整单元24包括放大单元32-1至32-m。放大单元32-1至32-m将从获取单元21提供的音频信号乘以从增益计算单元23提供的vbap增益,并将通过乘法获得的音频信号提供给扬声器12-1至12-m以便再现声音。
应当注意,在下面的描述中,在不需要将放大单元32-1至32-m彼此特定区分的情况下,它们中的每一个也仅被称为放大单元32。
<再现处理的描述>
现在,描述图6中描绘的音频处理装置11的操作。
如果从外部提供音频信号和对象的元数据,则音频处理装置11执行再现处理以再现对象的声音。
在下面,参照图7的流程图描述音频处理装置11的再现处理。应当注意的是,针对音频信号的每一帧执行该再现处理。
在步骤s11处,获取单元21从外部获取对象的一帧的音频信号和元数据,并且将该音频信号提供至放大单元32,同时它将元数据提供至向量计算单元22。
在步骤s12处,向量计算单元22基于从获取单元21提供的元数据执行扩展向量计算处理,并且将作为扩展向量计算处理的结果而获得的扩展向量提供至增益计算单元23。此外,根据需要,向量计算单元22还向增益计算单元23提供向量p。
应当注意的是,尽管在下文中描述了扩展向量计算处理的细节,但是在扩展向量计算处理中,扩展向量通过扩展三维向量方法、扩展中心向量方法、扩展端向量方法、扩展辐射向量方法或任意扩展向量法来计算。
在步骤s13处,增益计算单元23基于表示预先保存的扬声器12的位置的位置信息以及从向量计算单元22提供的向量p和扩展向量来计算各个扬声器12的vbap增益。
具体地,关于扩展向量和向量p中的每一个,计算每个扬声器12的vbap增益。因此,对于扩展向量和向量p中的每一个,获得位于对象的位置附近(即,位于由向量指示的位置附近)的一个或更多个扬声器12的vbap增益。应当注意的是,虽然必定计算扩展向量的vbap增益,但是如果通过步骤s12处的处理并未将向量p从向量计算单元22提供至增益计算单元23,则不计算向量p的vbap增益。
在步骤s14处,增益计算单元23将关于每个向量计算的vbap增益相加,以计算每个扬声器12的vbap增益相加值。具体地,计算针对同一扬声器12所计算的向量的vbap增益的相加值(总和)作为vbap增益相加值。
在步骤s15处,量化单元31决定是否要执行vbap增益相加值的二值化。
例如,可以基于在上文中描述的索引值索引来决定或者可以基于作为元数据的由重要性信息指示的对象的重要性程度来决定是否要执行二值化。
如果基于索引值索引来执行决定,则例如可以将从比特流读出的索引值索引提供至增益计算单元23。可替选地,如果基于重要性信息来执行决定,则可以将重要性信息从向量计算单元22提供至增益计算单元23。
如果在步骤s15处决定要执行二值化,则在步骤s16处,量化单元31对针对每个扬声器12决定的vbap增益的加法值(即,vbap增益相加值)进行二值化。此后,处理前进至步骤s17。
相反,如果在步骤s15处决定不执行二值化,则跳过步骤s16处的理,并且处理前进至步骤s17。
在步骤s17处,增益计算单元23对每个扬声器12的vbap增益进行归一化,使得所有扬声器12的vbap增益的平方和可以变为1。
具体地,对针对每个扬声器12所决定的vbap增益的相加值执行归一化,使得所有相加值的平方和可以变为1。增益计算单元23将通过归一化获得的扬声器12的vbap增益提供至与各个扬声器12对应的放大单元32。
在步骤s18处,放大单元32将从获取单元21提供的音频信号与从增益计算单元23提供的vbap增益相乘,并且将所得到的值提供至扬声器12。
然后在步骤s19处,放大单元32使扬声器12基于提供至其的音频信号来再现声音,从而结束再现处理。因此,对象的声像被定位在再现空间中的期望的部分空间中。
以如上所述这样的方式,音频处理装置11基于元数据来计算扩展向量,针对每个扬声器12计算每个向量的vbap增益,并且针对每个扬声器12决定和归一化vbap增益的相加值。通过以这种方式计算关于扩展向量的vbap增益,可以表示对象的声像的空间扩散,特别是对象的形状或声音的方向性,并且可以获得更高质量的声音。
此外,通过根据需要对vbap增益的相加值进行二值化,不仅可以减少渲染时的处理量,而且可以响应于音频处理装置11的处理能力(硬件规模)执行适当的处理以获得尽可能高质量的声音。
<扩展向量计算处理的描述>
在此,参照图8的流程图来描述与图7的步骤s12处的处理对应的扩展向量计算处理。
在步骤s41处,向量计算单元22基于扩展三维向量来决定是否要计算扩展向量。
例如,与图7的步骤s15处的情况类似,可以基于索引值索引来决定使用哪种方法计算扩展向量,或者可以基于由重要性信息指示的对象的重要性程度来决定使用哪种方法计算扩展向量。
如果在步骤s41处决定要基于扩展三维向量计算扩展向量,即,如果决定要通过扩展三维方法计算扩展向量,则处理前进至步骤s42。
在步骤s42处,向量计算单元22基于扩展三维向量来执行扩展向量计算处理,并且将所得到的向量提供至增益计算单元23。应当注意的是,在下文中描述基于扩展三维向量的扩展向量计算处理的细节。
在扩展向量被计算之后,扩展向量计算处理结束,此后,处理前进至图7的步骤s13。
另一方面,如果在步骤s41处决定不要基于扩展三维向量来计算扩展向量,则处理前进至步骤s43。
在步骤s43处,向量计算单元22决定是否要基于扩展中心向量来计算扩展向量。
如果在步骤s43处决定要基于扩展中心向量来计算扩展向量,即,如果决定要通过扩展中心向量方法来计算扩展向量,则处理前进至步骤s44。
在步骤s44处,向量计算单元22基于扩展中心向量执行扩展向量计算处理,并且将所得到的向量提供至增益计算单元23。应当注意的是,在下文中描述基于扩展中心向量的扩展向量计算处理的细节。
在扩展向量被计算之后,扩展向量计算处理结束,此后,处理前进至图7的步骤s13。
另一方面,如果在步骤s43处决定不要基于扩展中心向量来计算扩展向量,则处理前进至步骤s45。
在步骤s45处,向量计算单元22决定是否要基于扩展端向量来计算扩展向量。
如果在步骤s45处决定要基于扩展端向量来计算扩展向量,即,如果决定要通过扩展端向量方法来计算扩展向量,则处理前进至步骤s46。
在步骤s46处,向量计算单元22基于扩展端向量执行扩展向量计算处理,并且将所得到的向量提供至增益计算单元23。应当注意的是,在下文中描述基于扩展端向量的扩展向量计算处理的细节。
在扩展向量被计算之后,扩展向量计算处理结束,此后,处理前进至图7的步骤s13。
此外,如果在步骤s45处决定不要基于扩展端向量来计算扩展向量,则处理前进至步骤s47。
在步骤s47处,向量计算单元22决定是否要基于扩展辐射向量来计算扩展向量。
如果在步骤s47处决定要基于扩展辐射向量来计算扩展向量,即,如果决定要通过扩展辐射向量方法来计算扩展向量,则处理前进至步骤s48。
在步骤s48处,向量计算单元22基于扩展辐射向量来执行扩展向量计算处理,并且将所得到的向量提供至增益计算单元23。应当注意的是,在下文中描述基于扩展辐射向量的扩展向量计算处理的细节。
在扩展向量被计算之后,扩展向量计算处理结束,此后,处理前进至图7的步骤s13。
另一方面,如果在步骤s47处决定不要基于扩展辐射向量来计算扩展向量,即,如果决定要通过扩展辐射向量方法来计算扩展向量,则处理前进至步骤s49。
在步骤s49处,向量计算单元22基于扩展向量位置信息来执行扩展向量计算处理,并且将所得到的向量提供至增益计算单元23。应当注意的是,在下文中描述基于扩展向量位置信息的扩展向量计算处理的细节。
在扩展向量被计算之后,扩展向量计算处理结束,此后,处理前进至图7的步骤s13。
音频处理装置11以这种方式通过多种方法中的适当方法来计算扩展向量。通过以这种方式经过适当的方法计算扩展向量,响应于渲染器的硬件规模等,可以获得在可允许的处理量的范围内的最高质量的声音。
<基于扩展三维向量的扩展向量计算处理的说明>
现在,参照图8来描述与在上文描述的步骤s42、s44、s46、s48和s49处的处理对应的处理的细节。
首先,参照图9的流程图来描述与图8的步骤s42对应的基于扩展三维向量的扩展向量计算处理。
在步骤s81处,向量计算单元22将由包括在从获取单元21提供的元数据中的位置信息指示的位置确定为对象位置p。换言之,表示位置p的向量是向量p。
在步骤s82处,向量计算单元22基于包括在从获取单元21提供的元数据中的扩展三维向量来计算扩展。具体地,向量计算单元22计算在上文中给出的表达式(1)以计算扩展。
在步骤s83处,向量计算单元22基于向量p和扩展来计算扩展向量p0至p18。
在此,向量p被确定为表示中心位置po的向量p0,并且向量p被原样确定为扩展向量p0。此外,与mpeg-h3d音频标准的情况类似,作为扩展向量p1至p18,向量被计算成在以下区域内沿上下方向和左右方向对称,所述区域以中心位置po为中心并且通过由单位球体上的扩展指示的角度来限定。
在步骤s84处,向量计算单元22基于扩展三维向量是否满足s3_azimuth≥s3_elevation,即,s3_azimuth是否大于s3_elevation做出决定。
如果在步骤s84处决定满足s3_azimuth≥s3_elevation,则在步骤s85处,向量计算单元22改变扩展向量p1至p18的仰角。具体地,向量计算单元22执行在上文中描述的表达式(2)的计算,以校正扩展向量的仰角以获得最终扩展向量。
在获得最终扩展向量之后,向量计算单元22将扩展向量p0至p18提供至增益计算单元23,从而结束基于扩展三维向量的扩展向量计算处理。由于图8的步骤s42处的处理随其结束,因此其后的处理前进至图7的步骤s13。
另一方面,如果在步骤s84处决定不满足s3_azimuth≥s3_elevation,则在步骤s86处,向量计算单元22改变扩展向量p1至p18的方位角。具体地,向量计算单元22执行在上文中给定的表达式(3)的计算,以校正扩展向量的方位角,从而获得最终扩展向量。
在获得最终扩展向量之后,向量计算单元22将扩展向量p0至p18提供至增益计算单元23,从而结束基于扩展三维向量的扩展向量计算处理。因此,由于图8的步骤s42处的处理结束,因此其后的处理前进至图7的步骤s13。
音频处理装置11以如上所述这样的方式通过扩展三维向量方法来计算每个扩展向量。因此,变得可以表示对象的形状以及对象的声音的方向性,并且获得较高质量的声音。
<基于扩展中心向量的扩展向量计算处理的说明>
现在,参照图10的流程图来描述与图8的步骤s44对应的基于扩展中心向量的扩展向量计算处理。
应当注意的是,步骤s111处的处理与图9的步骤s81处的处理类似,因此,省略对其的描述。
在步骤s112处,向量计算单元22基于扩展中心向量以及包括在从获取单元21提供的元数据中的扩展来计算扩展向量p0至p18。
具体地,向量计算单元22将由扩展中心向量指示的位置设置为中心位置po,并且将表示中心位置po的向量设置为扩展向量p0。此外,向量计算单元22将扩展向量p1至p18确定成使得它们在以下区域中沿上下方向和左右方向对称的定位,所述区域以中心位置po为中心并且通过由单位球体上的扩展指示的角度来限定。与mpeg-h3d音频标准的情况基本上类似地确定扩展向量p1至p18。
向量计算单元22将通过上述处理获得的扩展向量p0至p18和向量p提供至增益计算单元23,从而结束基于扩展中心向量的扩展向量计算处理。因此,图8的步骤s44处的处理结束,此后,处理前进至图7的步骤s13。
音频处理装置11以如上所述这样的方式通过扩展中心向量方法来计算向量p和扩展向量。因此,变得可以表示对象的形状以及对象的声音的方向性,并且获得较高质量的声音。
应当注意的是,在基于扩展中心向量的扩展向量计算处理中,扩展向量p0可以不被提供至增益计算单元23。换言之,可以不关于扩展向量p0来计算vbap增益。
<基于扩展端向量的扩展向量计算处理的说明>
此外,参照图11的流程图来描述与图8的步骤s46对应的基于扩展端向量的扩展向量计算处理。
应当注意的是,步骤s141处的处理与图9的步骤s81处的处理类似,因此,省略对其的描述。
在步骤s142处,向量计算单元22基于包括在从获取单元21提供的元数据中的扩展端向量来计算中心位置po,即,向量po。具体地,向量计算单元22计算在上文中给出的表达式(4)以计算中心位置po。
在步骤s143处,向量计算单元22基于扩展端向量来计算扩展。具体地,向量计算单元22计算在上文中给出的表达式(5)以计算扩展。
在步骤s144处,向量计算单元22基于中心位置po和扩展来计算扩展向量p0至p18。
在此,表示中心位置po的向量po被原样设置为扩展向量p0。此外,与mpeg-h3d音频标准的情况类似,扩展向量p1至p18被计算成使得它们在以下区域内沿上下方向和左右方向对称的定位,所述区域以中心位置po为中心并且通过由单位球体上的扩展指示的角度来限定。
在步骤s145处,向量计算单元22决定是否满足(扩展左端方位角-扩展右端方位角)≥(扩展上端仰角-扩展下端仰角),即,(扩展左端方位角-扩展右端方位角)是否大于(扩展上端仰角-扩展下端仰角)。
如果在步骤s145处决定满足(扩展左端方位角-扩展右端方位角)≥(扩展上端仰角-扩展下端仰角),则在步骤s146处,向量计算单元22改变扩展向量p1至p18的仰角。具体地,向量计算单元22执行在上文中给出的表达式(6)的计算,以校正扩展向量的仰角以获得最终扩展向量。
在获得最终扩展向量之后,向量计算单元22将扩展向量p0至p18和向量p提供至增益计算单元23,从而结束基于扩展端向量的扩展向量计算处理。因此,图8的步骤s46处的处理结束,此后,处理前进至图7的步骤s13。
另一方面,如果在步骤s145处决定不满足(扩展左端方位角-扩展右端方位角)≥(扩展上端仰角-扩展下端仰角),则在步骤s147处,向量计算单元22改变扩展向量p1至p18的方位角。具体地,向量计算单元22执行在上文中给出的表达式(7)的计算,以校正扩展向量的方位角以获得最终扩展向量。
在获得最终扩展向量之后,向量计算单元22将扩展向量p0至p18和向量p提供至增益计算单元23,从而结束基于扩展端向量的扩展向量计算处理。因此,图8的步骤s46处的处理结束,此后,处理前进至图7的步骤s13。
音频处理装置11如上所述通过扩展端向量方法来计算扩展向量。因此,变得可以表示对象的形状以及对象的声音的方向性,并且获得较高质量的声音。
应当注意的是,在基于扩展端向量的扩展向量计算处理中,扩展向量p0可以不被提供至增益计算单元23。换言之,可以不关于扩展向量p0来计算vbap增益。
<基于扩展辐射向量的扩展向量计算处理的说明>
现在,参照图12的流程图来描述与图8的步骤s48对应的基于扩展辐射向量的扩展向量计算处理。
应当注意的是,步骤s171处的处理与图9的步骤s81处的处理类似,因此,省略对该处理的描述。
在步骤s172处,向量计算单元22基于包括在从获取单元21提供的元数据中的扩展和扩展辐射向量来计算扩展向量p0至p18。
具体地,向量计算单元22将由通过将表示对象位置p的向量p与辐射向量相加而获得的向量指示的位置设置为中心位置po。指示该中心位置po的向量是向量po,并且向量计算单元22将向量po原样设置为扩展向量p0。
此外,向量计算单元22将扩展向量p1至p18确定成使得它们在以下区域中沿上下方向和左右方向对称的定位,所述区域以中心位置po为中心并且通过由单位球体上的扩展指示的角度来限定。与mpeg-h3d音频标准的情况基本上类似地确定扩展向量p1至p18。
向量计算单元22将通过上述处理获得的扩展向量p0至p18和向量p提供至增益计算单元23,从而结束基于扩展辐射向量的扩展向量计算处理。因此,由于图8的步骤s48处的处理结束,因此其后的处理前进至图7的步骤s13。
音频处理装置11以如上所述这样的方式通过扩展辐射向量方法来计算向量p和扩展向量。因此,变得可以表示对象的形状以及对象的声音的方向性,并且获得较高质量的声音。
应当注意的是,在基于扩展辐射向量的扩展向量计算处理中,扩展向量p0可以不被提供至增益计算单元23。换言之,可以不关于扩展向量p0来计算vbap增益。
<基于扩展向量位置信息的扩展向量计算处理的说明>
现在,参照图13的流程图来描述与图8的步骤s49对应的基于扩展向量位置信息的扩展向量计算处理。
应当注意的是,步骤s201处的处理与图9的步骤s81处的处理类似,因此,省略对其的描述。
在步骤s202处,向量计算单元22基于包括在从获取单元21提供的元数据中的扩展向量数量信息和扩展向量位置信息来计算扩展向量。
具体地,向量计算单元22计算以下向量,该向量在原点o处具有起点并且在由作为扩展向量的扩展向量位置信息指示的位置处具有终点。在此,计算等于由扩展向量数量信息指示的数量的扩展向量的数量。
向量计算单元22将通过上述处理获得的扩展向量和向量p提供至增益计算单元23,从而结束基于扩展向量位置信息的扩展向量计算处理。因此,由于图8的步骤s49处的处理结束,因此其后的处理前进至图7的步骤s13。
音频处理装置11以如上所述这样的方式通过任意扩展向量方法来计算向量p和扩展向量。因此,变得可以表示对象的形状以及对象的声音的方向性,并且获得较高质量的声音。
<第二实施方式>
<渲染处理的处理量减少>
顺便提及,如上所述,vbap被称为用于使用多个扬声器来控制声像的定位的技术,即,用于执行渲染处理的技术。
在vbap中,通过从三个扬声器输出声音,可以将声像定位在根据三个扬声器构成的三角形的内侧上的任意点处。在下文中,特别是根据这样的三个扬声器构成的三角形被称为网格。
由于通过vbap对每个对象执行渲染处理,因此在对象的数量大(如例如,在游戏中)的情况下,渲染处理的处理量大。因此,小硬件规模的渲染器可能不能对所有对象执行渲染,因此,可以再现仅有限数量的对象的声音。这可能在声音再现时损害呈现或声音质量。
因此,本技术使得可以减少渲染处理的处理量,同时抑制呈现或声音质量的劣化。
在下文中,描述了如刚刚描述的这样的技术。
在普通vbap处理中,即,在渲染处理中,对每个对象执行在上文中描述的处理a1至a3的处理,以产生扬声器的音频信号。
由于针对其大体上计算vbap增益的扬声器的数量是三个并且针对构成音频信号的每个采样来计算每个扬声器的vbap增益,因此在处理a3中的乘法处理中,将乘法执行等于(音频信号的采样数量×3)的次数。
相反,在本技术中,通过对vbap增益执行相等的增益处理,即,vbap增益的量化处理以及用于在适当的组合中改变要在vbap增益计算时使用的网格数量的网格数量切换处理,渲染处理的处理量减少。
(量化处理)
首先,描述量化处理。在此,作为量化处理的示例,描述了二值化处理和三值化处理。
在执行二值化处理作为量化处理的情况下,在执行处理a1之后,对通过处理a1获得的每个扬声器的vbap增益进行二值化。在二值化中,例如,每个扬声器的vbap增益由0和1之一表示。
应当注意的是,用于对vbap增益进行二值化的方法可以是任何方法如四舍五入、上限(上舍入)、下限(截取)或阈值处理。
在以这种方式对vbap增益进行二值化之后,执行处理a2和处理a3以产生扬声器的音频信号。
此时,在处理a2中,由于基于二值化的vbap增益来执行归一化,因此与在上文中描述的扩展向量的量化时一样,扬声器的最终vbap增益类似地变为除0以外的一个值。换言之,如果vbap增益被二值化,则扬声器的最终vbap增益的值为0或预定值。
因此,在处理a3中的乘法处理中,可以将乘法执行(音频信号的采样数量×1)次,因此可以显著减少渲染处理的处理量。
类似地,在处理a1之后,可以对获得的扬声器的vbap增益进行三值化。在如刚刚描述的这样的情况下,通过处理a1获得的每个扬声器的vbap增益被三值化为值0、0.5和1中的一个值。然后,其后执行处理a2和处理a3以产生扬声器的音频信号。
因此,由于处理a3中的乘法处理中的乘法时间数量变为最大值(音频信号的采样数量×2),因此可以显著减少渲染处理的处理量。
应当注意的是,尽管在此给出的描述将vbap增益被二值化或三值化的情况作为示例,但是vbap增益可被量化为4个或更多个值。对此进行概括,例如,vbap增益被量化成使得其具有等于或大于2的x增益之一,或者换言之,如果对vbap增益进行x量化次数的量化,则处理a3中的乘法处理的次数变为最大值(x-1)。
可以以如上所述这样的方式通过对vbap增益进行量化来减少渲染处理的处理量。如果渲染处理的处理量以这种方式减少,则即使在对象的数量大的情况下,仍然变得可以对所有对象执行渲染,从而在声音再现时可以将呈现或声音质量的劣化抑制到低水平。换言之,可以减少渲染处理的处理量,同时抑制呈现或声音质量的劣化。
(网格数量切换处理)
现在,描述网格数量切换处理。
在vbap中,如在上文中描述的,例如,参照图1,通过沿三个扬声器sp1至sp3的方向指向的向量i1至i3的线性和来表示指示处理目标的对象的声像的位置p的向量p,并且与所述向量相乘的系数g1至g3是扬声器的vbap增益。在图1的示例中,由扬声器sp1至sp3包围的三角形区域tr11形成一个网格。
在计算vbap增益时,具体地通过以下表达式(8)通过从三角形形状的网格的逆矩阵l123-1以及对象的声像的位置p的计算来确定三个系数g1至g3:
[表达式8]
应当注意的是,表达式(8)中的p1、p2和p3指示笛卡尔坐标系上(即,图2中描绘的三维坐标系上)的表示对象的声像的位置的x坐标、y坐标和z坐标。
此外,i11、i12和i13是x分量、y分量和z分量在指向构成网格的第一扬声器sp1的向量i1被分解为x轴上的分量、y轴上的分量和z轴上的分量的情况下的值,并且分别对应于第一扬声器sp1的x坐标、y坐标和z坐标。
类似地,i21、i22和i23分别是x分量、y分量和z分量在指向构成网格的第二扬声器sp2的向量i2被分解为x轴上的分量、y轴上的分量和z轴上的分量的情况下的值。此外,i31、i32和i33分别是x分量、y分量和z分量在指向构成网格的第三扬声器sp3的向量i3被分解为x轴上的分量、y轴上的分量和z轴上的分量的情况下的值。
此外,如由下面的表达式(9)表示的,定义了从位置p的三维坐标系的p1、p2和p3到球坐标系的坐标θ、γ和r的转换,其中r=1,如下面的表达式(9)所示。在此,θ、γ和r分别是在上文中描述的水平方向角方位角、竖直方向角仰角和距离半径。
[表达式9]
[p1p2p3]=[cos(θ)×cos(γ)sin(θ)×cos(γ)sin(γ)]…(9)
如上所述,在内容再现侧的空间中,即,在再现空间中,多个扬声器设置在单位球体上,并且一个网格由多个扬声器中的三个扬声器构成。此外,单位球体的整个表面基本上被多个网格覆盖,而多个网格之间没有留下间隙。此外,网格被确定成使得它们彼此不交叠。
在vbap中,如果从设置在单位球体的表面上的扬声器中的对构成包括对象的位置p的一个网格的两个或三个扬声器输出声音,则可以将声像定位在位置p,因此,除了构成网格的扬声器以外的扬声器的vbap增益为0。
因此,在计算vbap增益时,可以指定包括对象的位置p的一个网格,以计算构成网格的扬声器的vbap增益。例如,可以从所计算的vbap增益来决定预定网格是否是包括位置p的网格。
具体地,如果关于网格计算的三个扬声器的vbap增益都是等于或高于0的值,则网格是包括对象的位置p的网格。相反,如果三个扬声器的vbap增益中至少之一具有负值,则由于对象的位置p位于扬声器构成的网格之外,因此所计算的vbap增益不是正确的vbap增益。
因此,在计算vbap增益时,一个接一个地选择网格作为处理目标的网格,并且对处理目标的网格执行在上文中给出的表达式(8)的计算,以计算构成网格的每个扬声器的vbap增益。
然后,根据vbap增益的计算结果,决定处理目标的网格是否是包含对象的位置p的网格,如果决定处理目标的网格是不包括位置p的网格,则将下一个网格确定为新的处理目标的网格,并且对该网格执行类似的处理。
另一方面,如果决定处理目标的网格是包括对象的位置p的网格,则将构成网格的扬声器的vbap增益确定为所计算的vbap增益,而将其他扬声器的vbap增益设置为0。因此,所有扬声器的vbap增益被获得。
以这种方式,在渲染处理中,同时执行用于计算vbap增益的处理以及用于指定包括位置p的网格的处理。
具体地,为了获得正确的vbap增益,重复以下处理:连续地选择处理目标的网格,直到构成网格的扬声器的所有vbap增益指示等于或高于0的值为止;以及计算网格的vbap增益。
因此,在渲染处理中,与单位球体的表面上的网格的数量一样,即为了获得正确的vbap增益,指定包括位置p的网格所需的处理的处理量增加。
因此,在本技术中,并不是实际的再现环境中的所有扬声器用于形成(构成)网格,而是来自所有扬声器中的仅一些扬声器用于形成网格,以减少网格的总数并且减少在渲染处理时的处理量。具体地,在本技术中,执行用于改变网格总数的网格数量切换处理。
具体地,例如,在22个声道的扬声器系统中,如图14中描绘的,将包括扬声器spk1至spk22的总共22个扬声器设置为单位球体的表面上的不同声道的扬声器。应当注意的是,在图14中,原点o与图2中描绘的原点o对应。
在以这种方式将22个扬声器设置在单位球体的表面上的情况下,如果使用所有22个扬声器来形成网格,使得它们覆盖单位球体表面,则单位球体上的网格总数为40。
相反,如图15中描绘的,例如,假定在总共22个扬声器spk1至spk22中,仅扬声器spk1、spk6、spk7、spk10、spk19和spk20总共这六个扬声器用于形成网格。应当注意的是,在图15中,用相同的附图标记表示与图14的情况中的那些对应的部分,因此适当地省略对它们的描述。
在图15的示例中,由于22个扬声器中的仅总共6个扬声器用于形成网格,因此单位球体上的网格总数为8,网格总数可以显著减少。因此,在图15中描绘的示例中,与如图14中描绘的所有22个扬声器用于形成网格的情况相比,当计算vbap增益时的处理量可以减少到8/40次,并且可以显著减少处理量。
此外,在本示例中,应当注意的是,由于单位球体的整个表面被八个网格覆盖而没有间隙,因此可以在单位球体的表面上的任意位置处定位声像。然而,由于每个网格的面积随着设置在单位球体表面上的网格总数的增加而减少,因此随着网格总数增加,可以以更高的精度来控制声像的定位。
如果通过网格数量切换处理来改变网格总数,则当选择要用于形成改变之后的数量的网格的扬声器时,期望选择如由位于原点o处的用户观察时其在竖直方向(上下方向)上的位置(即,其在竖直方向角仰角的方向上的位置)彼此不同的扬声器。换言之,期望使用三个或更多个扬声器,包括彼此位于不同高度的扬声器,来形成改变之后的数量的网格。原因是旨在抑制三维感觉(即,声音的存在)的劣化。
例如,考虑如图16中描绘的包括设置在单位球体表面上的扬声器sp1至sp5的五个扬声器中的一些或全部用于形成网格的情况。应当注意的是,在图16中,用相同的附图标记表示与图3的情况中的那些对应的部分,因此省略对它们的描述。
在图16中描绘的示例中所有五个扬声器sp1至sp5都用于形成覆盖在单位球体表面上的网格的情况下,网格的数量为3。具体地,包括由扬声器sp1至sp3包围的三角形形状的区域、由扬声器sp2至sp4包围的三角形形状的另一区域以及由扬声器sp2、sp4和sp5包围的三角形形状的再一区域的三个区域形成网格。
相反,例如,如果仅使用扬声器sp1、sp2和sp5,则网格不形成三角形形状,而形成二维弧。在这种情况下,可以仅在与单位球体的扬声器sp1和sp2互连的弧上或者在与单位球体的扬声器sp2和sp5互连的弧上定位对象的声像。
以这种方式,如果用于形成网格的所有扬声器是竖直方向上相同高度处的扬声器(即,同一层的扬声器),则由于对象的所有声像的定位位置的高度变为同一高度,因此存在劣化。
因此,期望使用三个或更多个扬声器,包括其在竖直方向(竖直方向)上的位置彼此不同的扬声器,来形成一个或多个网格,使得可以抑制存在的劣化。
在图16的示例中,例如,如果使用来自扬声器sp1至sp5中的扬声器sp1以及扬声器sp3至sp5,则可以形成两个网格,使得它们覆盖整个单位球体表面。在该示例中,扬声器sp1和sp5以及扬声器sp3和sp4位于彼此不同的高度处。
在这种情况下,例如,将由扬声器sp1、sp3和sp5包围的三角形形状的区域以及由扬声器sp3至sp5包围的三角形形状的另一区域形成为网格。
此外,在该示例中,也可以形成包括由扬声器sp1、sp3和sp4包围的三角形形状的区域以及由扬声器sp1、sp4和sp5包围的三角形形状的另一区域的两个区域作为网格。
在上述两个示例中,由于可以将声像定位在单位球体表面上的任意位置处,因此可以抑制存在的劣化。此外,为了形成网格,使得整个单位球体表面被多个网格覆盖,必定期望使用位于用户正上方的所谓的顶部扬声器。例如,顶部扬声器是图14中描绘的扬声器spk19。
与量化处理的情况类似,通过以如上所述这样的方式执行网格数量切换处理以改变网格的总数,可以减少渲染处理的处理量,此外,可以在声音再现时将呈现或声音质量的劣化抑制到低水平。换言之,可以减少渲染处理的处理量,同时抑制呈现或声音质量的劣化。
选择是否要执行这样的网格数量切换处理或者在该网格数量切换处理中将网格的总数设置为哪个数量可以被视为选择要用于计算vbap增益的网格的总数。
(量化处理和网格数量切换处理的组合)
在前面的描述中,作为用于减少渲染处理的处理量的技术,描述了量化处理和网格数量切换处理。
在执行渲染处理的渲染器侧,可以固定地使用被描述为量化处理或网格数量切换处理的一些处理,或者可以对这样的处理进行切换或者可以对这样的处理适当地进行组合。
例如,可以基于对象的总数(在下文中被称为对象数量)、包括在对象的元数据中的重要性信息、对象的音频信号的声压等来确定要组合地执行哪些处理。此外,可以针对每个对象或音频信号的每个帧执行处理的组合,即,处理的切换。
例如,在响应于对象数量执行处理的切换的情况下,可以执行如下所述这样的处理。
例如,在对象数量等于或大于10的情况下,针对所有对象执行vbap增益的二值化处理。相反,在对象数量小于10的情况下,照常仅执行在上文中描述的处理a1至处理a3。
通过在对象数量少时照常执行处理,但是在对象数量多时以这种方式执行二值化处理,即使通过小硬件规模的渲染器也可以充分地执行渲染,并且可以获得尽可能高质量的声音。
此外,当响应于对象数量执行处理的切换时,可以响应于对象数量执行网格数量切换处理,以适当地改变网格的总数。
在这种情况下,例如,当对象数量等于或大于10时,可以将网格的总数设置为8,而当对象数量小于10时,可以将网格的总数设置为40。此外,可以响应于对象数量在多个阶段中改变网格的总数,使得网格的总数随着对象数量增加而减少。
通过以这种方式响应于对象数量来改变网格的总数,可以响应于渲染器的硬件规模来调整处理量,从而获得尽可能高质量的声音。
此外,在基于包括在对象的元数据中的重要性信息来执行处理的切换的情况下,可以执行以下处理。
例如,当对象的重要性信息具有表示最高重要性程度的最高值时,仅照常执行处理a1至a3,但是在对象的重要性信息具有除了最高值以外的值的情况下,执行对vbap增益的二值化处理。
此外,例如,可以响应于对象的重要性信息的值来执行网格数量切换处理,以适当地改变网格的总数。在这种情况下,随着对象的重要性程度增加,可以增加网格的总数,并且可以在多个阶段中改变网格的总数。
在那些示例中,可以基于每个对象的重要性信息针对每个对象切换该处理。在在此描述的处理中,可以提高具有高重要性程度的对象的声音质量,但是降低具有低重要性程度的对象的声音质量,从而减少处理量。因此,当要同时再现各种重要性程度的对象的声音时,最大限度地抑制听觉上的声音质量劣化以减少处理量,并且可以考虑这是在确保声音质量与减少处理量之间得到了很好的平衡的技术。
以这种方式,当基于对象的重要性信息对每个对象执行处理的切换时,可以随着对象的重要性程度增加而增加对象的总数,或者可以避免当对象的重要性程度高时执行量化处理。
另外,对于重要性程度低的对象,即,对于其重要性信息的值低于预定值的对象,也可以针对位于靠近具有较高重要性程度的对象的位置处的对象(即,其重要性信息的值等于或高于预定值的对象)增加网格的总数或者可以不执行量化处理。
具体地,对于其重要性信息指示最高值的对象,将网格的总数设置为40,但是对于其重要性信息不指示最高值的对象,减少网格的总数。
在这种情况下,对于其重要性信息不是最高值的对象,可以随着对象与其重要性信息为最高值的对象之间的距离减小而增加网格的总数。通常,由于用户特别仔细地聆听高重要性程度的对象的声音,因此如果位于靠近所述对象的不同对象的声音的声音质量低,则用户将感到整个内容的声音质量不好。因此,通过还针对位于靠近具有高的重要性程度的对象处的对象来确定网格的总数,使得可以获得尽可能高质量的声音,可以抑制声音质量在听觉上的劣化。
此外,可以响应于对象的音频信号的声压而切换处理。在此,可以通过计算音频信号的渲染目标的帧中的采样的采样值的均方值的平方根来确定音频信号的声压。具体地,可以通过计算以下表达式(10)来确定声压rms:
[表达式10]
应当注意的是,在表达式(10)中,n表示构成音频信号的帧的采样数,xn表示帧中的第n(其中,n=0,...,n-1)个采样的采样值。
在响应于以这种方式获得的音频信号的声压rms而切换处理的情况下,可以执行以下处理。
例如,在对象的音频信号的声压rms为-6db或相对于0db(其为声压rms的满量程)的更大值的情况下,照例仅执行处理a1至a3,但是在对象的声压rms低于-6db的情况下,执行对vbap增益的二值化处理。
通常,在声音具有高声压的情况下,声音质量的劣化很可能突出,并且这样的声音通常是具有高重要性程度的对象的声音。因此,在此对于具有高声压rms的声音的对象,防止声音质量劣化,同时对于具有低声压rms的声音的对象,执行二值化处理,使得整体上减少处理量。由此,即使通过小硬件规模的渲染器,也可以充分地执行渲染,此外,可以获得尽可能高质量的声音。
可替选地,可以响应于对象的音频信号的声压rms而执行网格数量切换处理,使得适当地改变网格的总数。在这种情况下,例如,可以随着对象的声压rms增加而增加网格的总数,并且可以在多个阶段中改变网格的总数。
此外,可以响应于对象数量、重要性信息和声压rms来选择量化处理或网格数量切换处理的组合。
具体地,可以基于对象数量、重要性信息和声压rms、是否要执行量化处理、在量化处理中要将vbap增益量化为多少增益(即,在量化处理时的量化数量)以及要用于计算vbap增益的网格的总数通过根据选择的结果的处理来计算vbap增益。在这样的情况下,例如,可以执行如下面给出的这样的处理。
例如,在对象数量是10或更多的情况下,将网格的总数设置为10,此外,执行二值化处理。在这种情况下,由于对象数量大,因此通过减少网格的总数并且执行二值化处理来减少处理量。因此,即使在渲染器的硬件规模小的情况下,也可以执行所有对象的渲染。
同时,在对象数量小于10并且此外重要性信息的值为最高值的情况下,仅照常执行处理a1至a3。因此,对于具有高重要性程度的对象,可以再现声音却不使声音质量劣化。
在对象数量小于10并且此外重要性信息的值不是最高值并且此外声压rms等于或高于-30db的情况下,将网格的总数设置为10并且此外执行三值化处理。这使得可以将渲染处理时的处理量减少到以下程度:对于具有高声压的声音,虽然重要性程度低,但是声音的声音质量劣化不突出。
此外,在对象数量小于10并且此外重要性信息的值不是最高值并且此外声压rms低于-30db的情况下,将网格的总数设置为5并且此外执行二值化处理。这使得可以针对具有低重要性程度并且具有低声压的声音充分地减少渲染处理时的处理量。
以这种方式,当对象数量大时,减少渲染处理时的处理量,使得可以执行对所有对象的渲染,但是当对象数量小到一定程度时,选择适当的处理并且对每个对象执行渲染。因此,虽然对每个对象而言确保声音质量与减少处理装置得到了很好的平衡,但是整体上可以通过小的处理量以足够的声音质量再现声音。
<音频处理装置的配置的示例>
现在,描述执行渲染处理同时适当地执行上述量化处理、网格数量切换处理等的音频处理装置。图17是描绘如刚刚描述的这样的音频处理装置的特定配置的示例的视图。应当注意的是,在图17中,用相同的附图标记表示与图6的情况下的那些对应的部分,因此适当地省略对它们的描述。
图17中描绘的音频处理装置61包括获取单元21、增益计算单元23和增益调整单元71。增益计算单元23接收从获取单元21提供的对象的元数据和音频信号,针对每个对象计算扬声器12中的每个扬声器的vbap增益,并且将所计算的vbap增益提供至增益调整单元71。
此外,增益计算单元23包括执行vbap增益的量化的量化单元31。
增益调整单元71针对每个对象将从获取单元21提供的音频信号与从增益计算单元23提供的各个扬声器12的vbap增益相乘,以产生各个扬声器12的音频信号,并且将所述音频信号提供至扬声器12。
<再现处理的说明>
随后,描述图17中描绘的音频处理装置61的操作。具体地,参照图18的流程图来描述通过音频处理装置61的再现处理。
应当注意的是,在本示例中,假定针对每个帧将一个对象的音频信号和元数据或者多个对象中的每个对象提供至获取单元21,并且针对每个对象的音频信号的每个帧执行再现处理。
在步骤s231处,获取单元21从外部获取对象的音频信号和元数据,并且将音频信号提供至增益计算单元23和增益调整单元71,同时它将元数据提供至增益计算单元23。此外,获取单元21还针对在作为处理目标的帧中要同时再现哪些声音而获取对象的数量信息(即,对象数量的信息),并且将该信息提供至增益计算单元23。
在步骤s232处,增益计算单元23基于从获取单元21提供的表示对象数量的信息来决定对象数量是否等于或大于10。
如果在步骤s232处决定对象数量等于或大于10,则在步骤s233处,增益计算单元23将计算vbap增益时要使用的网格的总数设置为10。换言之,增益计算单元23选择10作为网格的总数。
此外,增益计算单元23响应于所选择的网格总数而从所有扬声器12中选择预定数量的扬声器12,使得在单位球体表面上形成数量等于总数的网格。然后,增益计算单元23将从所选择的扬声器12形成的单位球体表面上的10个网格确定为在计算vbap增益时要使用的网格。
在步骤s234处,增益计算单元23基于在步骤s233处确定的表示构成10个网格的扬声器12的位置的位置信息以及包括在从获取单元21提供的元数据中并且表示对象的位置的位置信息通过vbap来计算每个扬声器12的vbap增益。
具体地,增益计算单元23按顺序使用在步骤s233处确定的网格连续地执行表达式(8)的计算,作为处理目标的网格以计算扬声器12的vbap增益。此时,新的网格被连续地确定为处理目标的网格,直到针对构成处理目标的网格的三个扬声器12所计算的vbap增益都指示等于或大于0的值为止,以连续地计算vbap增益。
在步骤s235处,量化单元31对在步骤s234处获得的扬声器12的vbap增益进行二值化,然后处理前进至步骤s246。
如果在步骤s232处决定对象数量小于10,则处理前进至步骤s236。
在步骤s236处,增益计算单元23决定包括在从获取单元21提供的元数据中的对象的重要性信息的值是否为最高值。例如,如果重要性信息的值是指示重要性程度最高的值“7”,则决定重要性信息指示最高值。
如果在步骤s236处决定重要性信息指示最高值,则处理前进至步骤s237。
在步骤s237处,增益计算单元23基于表示扬声器12的位置的位置信息以及包括在从获取单元21提供的元数据中的位置信息来计算每个扬声器12的vbap增益,然后处理前进至步骤s246。在此,从所有扬声器12形成的网格被连续地确定为处理目标的网格,并且通过计算表达式(8)来计算vbap增益。
另一方面,如果在步骤s236处决定重要性信息不指示最高值,则在步骤s238处,增益计算单元23计算从获取单元21提供的音频信号的声压rms。具体地,针对作为处理目标的音频信号的帧执行在上文中给出的表达式(10)的计算,以计算声压rms。
在步骤s239处,增益计算单元23决定在步骤s238处计算的声压rms是否等于或高于-30db。
如果在步骤s239处决定声压rms等于或高于-30db,则执行步骤s240和s241处的处理。应当注意的是,步骤s240和s241处的处理分别与步骤s233和s234处的处理类似,因此省略对它们的描述。
在步骤s242处,量化单元31对在步骤s241处获得的每个扬声器12的vbap增益进行三值化,然后处理前进至步骤s246。
另一方面,如果在步骤s239处决定声压rms低于-30db,则处理前进至步骤s243。
在步骤s243处,增益计算单元23将计算vbap增益时要使用的网格的总数设置为5。
此外,增益计算单元23响应于所选择的网格总数“5”从所有扬声器12中选择预定数量的扬声器12,并且将从所选择的扬声器12形成的单位球体表面上的五个网格确定为计算vbap增益时要使用的网格。
在确定计算vbap增益时要使用的网格之后,执行步骤s244和s245处的处理,然后处理前进至步骤s246。应当注意的是,步骤s244和s245处的处理与步骤s234和s235处的处理类似,因此省略对它们的描述。
在执行步骤s235、s237、s242或s245处的处理并且获得扬声器12的vbap增益之后,执行步骤s246至s248处的处理,从而结束再现处理。
应当注意的是,由于步骤s246至s248处的处理分别与在上文参照图7描述的步骤s17至s19处的处理类似,因此省略对它们的描述。
然而,更具体地,针对各个对象基本上同时执行再现处理,并且在步骤s248处,将针对各个对象获得的扬声器12的音频信号提供至扬声器12。具体地,扬声器12基于通过将对象的音频信号相加而获得的信号来再现声音。因此,同时输出所有对象的声音。
音频处理装置61适当地对每个对象选择性地执行量化处理和网格数量切换处理。由此,可以减少渲染处理的处理量,同时抑制呈现或声音质量的劣化。
<修改1至第二实施方式>
<音频处理装置的配置示例>
此外,在第二实施方式的描述中,虽然描述了当不执行用于延伸声像的处理时选择性地执行量化处理或网格数量切换处理的示例,此外,当执行用于延伸声像的处理时,可以选择性地执行量化处理或网格数量切换处理。
在这样的情况下,音频处理装置11例如以如图19中描绘的这样的方式来配置。应当注意的是,在图19中,用相同的附图标记表示与图6或图17的情况下的那些对应的部分,因此适当地省略对它们的描述。
图19中描绘的音频处理装置11包括获取单元21、向量计算单元22、增益计算单元23和增益调整单元71。
获取单元21针对一个或多个对象来获取对象的音频信号和元数据,并且将所获取的音频信号提供至增益计算单元23和增益调整单元71,并且将所获取的元数据提供至向量计算单元22和增益计算单元23。此外,增益计算单元23包括量化单元31。
<再现处理的说明>
现在,参照图20的流程图来描述由图19中描绘的音频处理装置11执行的再现处理。
应当注意的是,在本示例中,假定针对一个或多个对象,针对每个帧将对象的音频信号和元数据提供至获取单元21,并且针对每个对象的音频信号的每个帧来执行再现处理。
此外,由于步骤s271和s272处的处理分别与图7的步骤s11和s12处的处理类似,因此省略对它们的描述。然而,在步骤s271处,将获取单元21获取的音频信号提供至增益计算单元23和增益调整单元71,并且将由获取单元21获取的元数据提供至向量计算单元22和增益计算单元23。
当执行步骤s271和s272处的处理时,获得扩展向量或扩展向量和向量p。
在步骤s273处,增益计算单元23执行vbap增益计算处理以计算每个扬声器12的vbap增益。应当注意的是,虽然在下文中描述了vbap增益计算处理的细节,但是在vbap增益计算处理中,选择性地执行量化处理或网格数量切换处理,以计算每个扬声器12的vbap增益。
在执行步骤s273处的处理并且获得扬声器12的vbap增益之后,执行步骤s274至s276处的处理并且再现处理结束。然而,由于那些处理分别与图7的步骤s17至s19处的处理类似,因此省略对它们的描述。然而,更具体地,针对对象基本上同时执行再现处理,并且在步骤s276处,将针对各个对象获得的扬声器12的音频信号提供至扬声器12。因此,从扬声器12同时输出所有对象的声音。
音频处理装置11以如上所述这样的方式适当地对每个对象选择性地执行量化处理或网格数量切换处理。由此,在执行用于延伸声像的处理的情况下,也可以减少渲染处理的处理量,同时抑制呈现或声音质量的劣化。
<vbap增益计算处理的说明>
现在,参照图21的流程图来描述与图20的步骤s273处的处理对应的vbap增益计算处理。
应当注意的是,由于步骤s301至s303处的处理分别与图18的步骤s232至s234处的处理类似,因此省略对它们的描述。然而,在步骤s303处,针对扩展向量的向量或者扩展向量和向量p中的每一个来计算每个扬声器12的vbap增益。
在步骤s304处,增益计算单元23将针对向量计算的每个扬声器12的vbap增益相加,以计算vbap增益相加值。在步骤s304处,执行与图7的步骤s14处的处理类似的处理。
在步骤s305处,量化单元31对通过步骤s304处的处理获得的每个扬声器12的vbap增益相加值进行二值化,然后计算处理结束,此外处理前进至图20的步骤s274。
另一方面,如果在步骤s301处决定对象数量小于10,则执行步骤s306和s307处的处理。
应当注意的是,由于步骤s306和s307处的处理分别与图18的步骤s236和步骤s237处的处理类似,因此省略对它们的描述。然而,在步骤s307处,针对扩展向量的向量或者扩展向量和向量p中的每一个来计算每个扬声器12的vbap增益。
此外,在执行步骤s307处的处理之后,执行步骤s308处的处理,并且vbap增益计算处理结束,此后处理前进至图20的步骤s274。然而,由于步骤s308处的处理与步骤s304处的处理类似,因此省略其描述。
此外,如果在步骤s306处决定重要性信息不指示最高值,则执行步骤s309至s312处的处理。然而,由于所述处理与图18的步骤s238至s241处的处理类似,因此省略对它们的描述。然而,在步骤s312处,针对扩展向量的向量或者扩展向量和向量p中的每一个来计算每个扬声器12的vbap增益。
在针对向量获得扬声器12的vbap增益之后,执行步骤s313处的处理以计算vbap增益相加值。然而,由于步骤s313处的处理与步骤s304处的处理类似,因此省略其描述。
在步骤s314处,量化单元31对通过步骤s313处的处理获得的每个扬声器12的vbap增益相加值进行三值化,并且vbap增益计算结束,此后处理前进至图20的步骤s274。
此外,如果在步骤s310处决定声压rms低于-30db,则执行步骤s315处的处理,并且将计算vbap增益时要使用的网格的总数设置为5。应当注意的是,步骤s315处的处理与图18的步骤s243处的处理类似,因此省略其描述。
在确定计算vbap增益时要使用的网格之后,执行步骤s316至s318处的处理,并且结束vbap增益计算处理,此后处理前进至图20的步骤s274。应当注意的是,步骤s316至s318处的处理与步骤s303至s305处的处理类似,因此省略对它们的描述。
音频处理装置11以如上所述这样的方式适当地对每个对象选择性地执行量化处理或网格数量切换处理。由此,还在执行用于延伸声像的处理的情况下,可以减少渲染处理的处理量,同时抑制呈现或声音质量的劣化。
顺便提及,虽然上述一系列处理可以由硬件执行,但是其可以以其他方式由软件来执行。在一系列处理由软件执行的情况下,将构造软件的程序安装到计算机中。在此,计算机包括并入硬件中的专用计算机,例如,可以通过安装各种程序来执行各种功能的通用个人计算机等。
图22是描绘根据程序执行在上文中描述的一系列处理的计算机的硬件的配置的示例的框图。
在计算机中,cpu(中央处理单元)501、rom(只读存储器)502和ram(随机存取存储器)503通过总线504彼此连接。
输入/输出接口505还连接至总线504。输入单元506、输出单元507、记录单元508、通信单元509和驱动器510连接至输入/输出接口505。
输入单元506由键盘、鼠标、麦克风、图像拾取元件等构成。输出单元507由显示单元、扬声器等构成。记录单元508由硬盘、非易失性存储器等构成。通信单元509由网络接口等构成。驱动器510驱动可移除记录介质511(如磁盘、光盘、磁光盘或半导体存储器)。
在以如上所述这样的方式配置的计算机中,cpu501通过输入/输出接口505和总线504将例如记录在记录单元508中的程序加载到ram503中,并且执行程序以执行在上文中描述的一系列处理。
由计算机(cpu501)执行的程序可以记录在可移除记录介质511上并且被设置为可移除记录介质511(例如,如封装介质等)。此外,可以通过诸如局域网、因特网或数字卫星广播的有线或无线传输介质来提供程序。
在计算机中,可以通过将可移除记录介质511加载到驱动器510中,通过输入/输出接口505将程序安装到记录单元508中。可替选地,程序可以由通信单元509通过有线或无线传输介质来接收并且被安装到记录单元508中。可替选地,程序可以预先安装到rom502或记录单元508中。
应当注意的是,由计算机执行的程序可以是根据本说明书中描述的顺序按照时间序列执行处理的程序或者并行执行处理或在调用程序的定时处执行处理的程序等。
此外,本技术的实施方式不限于在上文中描述的实施方式,并且在不脱离本技术的主题的情况下,可以以各种方式被改变。
例如,本技术可以采用云计算的配置,通过该配置,一个功能由多个装置通过网络分担和协同处理。
此外,参考在上文中描述的流程图描述的步骤可以由单个装置执行,或者可以由多个装置分担执行。
此外,在一个步骤包括多个处理的情况下,包括在一个步骤中的多个处理可以由单个装置执行或者可以由多个装置分担执行。
本技术也可以采取以下配置。
(1)一种音频处理装置,包括:
获取单元,被配置成获取包括指示音频对象的位置的位置信息以及由至少二维或更多维的向量构成并且表示声像距所述位置的扩散的声像信息的元数据;
向量计算单元,被配置成基于表示由所述声像信息确定的声像的扩散的区域的水平方向角和竖直方向角来计算指示所述区域中的位置的扩展向量;以及
增益计算单元,被配置成基于所述扩展向量来计算提供给位于所述位置信息指示的位置附近的两个或更多个声音输出单元的音频信号中的每个音频信号的增益。
(2)根据(1)所述的音频处理装置,其中,
所述向量计算单元基于所述水平方向角与所述竖直方向角之间的比率来计算所述扩展向量。
(3)根据(1)或(2)所述的音频处理装置,其中,
所述向量计算单元计算预先确定的数量的扩展向量。
(4)根据(1)或(2)所述的音频处理装置,其中,
所述向量计算单元计算任意可变数量的扩展向量。
(5)根据(1)所述的音频处理装置,其中,
所述声像信息是指示所述区域的中心位置的向量。
(6)根据(1)所述的音频处理装置,其中,
所述声像信息是指示所述声像距所述区域的中心的扩散程度的二维或更多维的向量。
(7)根据(1)所述的音频处理装置,其中,
所述声像信息是指示从所述位置信息指示的位置观看到的所述区域的中心位置的相对位置的向量。
(8)根据(1)至(7)中任一项所述的音频处理装置,其中,
所述增益计算单元:
计算关于所述声音输出单元中的每个声音输出单元的每个扩展向量的增益,
计算针对所述声音输出单元中的每个声音输出单元的扩展向量所计算的增益的相加值,
将所述相加值量化成关于所述声音输出单元中的每个声音输出单元的两个或更多个值的增益,以及
基于量化的相加值来计算关于所述声音输出单元中的每个声音输出单元的最终增益。
(9)根据(8)所述的音频处理装置,其中,
所述增益计算单元选择要用于计算所述增益的网格的数量,所述网格中的每个网格是由所述声音输出单元中的三个声音输出单元包围的区域,并且所述增益计算单元基于对网格的数量的选择结果和所述扩展向量来计算所述扩展向量中的每个扩展向量的增益。
(10)根据(9)所述的音频处理装置,其中,
所述增益计算单元选择要用于计算所述增益的网格的数量、是否要执行量化以及量化时的所述相加值的量化数量,以及
响应于选择结果来计算最终增益。
(11)根据(10)所述的音频处理装置,其中,
所述增益计算单元基于所述音频对象的数量来选择要用于计算所述增益的网格的数量、是否要执行量化以及所述量化数量。
(12)根据(10)或(11)所述的音频处理装置,其中,
所述增益计算单元基于所述音频对象的重要性程度来选择要用于计算所述增益的网格的数量、是否要执行量化以及所述量化数量。
(13)根据(12)所述的音频处理装置,其中,
所述增益计算单元选择要用于计算所述增益的网格的数量,使得要用于计算所述增益的网格的数量随着所述音频对象的位置位于更靠近重要性程度高的音频对象而增加。
(14)根据(10)至(13)中任一项所述的音频处理装置,其中,
所述增益计算单元基于所述音频对象的音频信号的声压来选择要用于计算所述增益的网格的数量、是否要执行量化以及所述量化数量。
(15)根据(9)至(14)中任一项所述的音频处理装置,其中,
所述增益计算单元响应于对网格数量的选择结果来选择包括位于彼此不同高度处的声音输出单元的多个声音输出单元中的三个或更多个声音输出单元,并且基于由所选择的声音输出单元形成的一个或多个网格来计算增益。
(16)一种音频处理方法,包括以下步骤:
获取包括指示音频对象的位置的位置信息以及由至少二维或更多维的向量构成并且表示声像距所述位置的扩散的声像信息的元数据;
基于表示由所述声像信息确定的声像的扩散的区域的水平方向角和竖直方向角来计算指示所述区域中的位置的扩展向量;以及
基于所述扩展向量来计算提供给位于所述位置信息指示的位置附近的两个或更多个声音输出单元的音频信号中的每个音频信号的增益。
(17)一种使计算机执行以下处理的程序,所述处理包括以下步骤:
获取包括指示音频对象的位置的位置信息以及由至少二维或更多维的向量构成并且表示声像距所述位置的扩散的声像信息的元数据;
基于表示由所述声像信息确定的声像的扩散的区域的水平方向角和竖直方向角来计算指示所述区域中的位置的扩展向量;以及
基于所述扩展向量来计算提供给位于所述位置信息指示的位置附近的两个或更多个声音输出单元的音频信号中的每个音频信号的增益。
(18)一种音频处理装置,包括:
获取单元,被配置成获取包括指示音频对象的位置的位置信息的元数据;以及
增益计算单元,被配置成选择要用于计算要提供给所述声音输出单元的音频信号的增益的网格的数量,所述网格中的每个网格由三个声音输出单元包围,并且所述增益计算单元基于对网格的数量的选择结果和所述位置信息来计算增益。
[参考标记列表]
11音频处理装置,21获取单元,22向量计算单元,23增益计算单元,24增益调整单元,31量化单元,61音频处理装置,71增益调整单元。
- 还没有人留言评论。精彩留言会获得点赞!